一種基于SOM劃分的FP-growth算法
2018-04-13 01:12:55郟奎奎劉海濱
計算機技術與發展 2018年4期
郟奎奎,劉海濱
(中國航天系統科學與工程研究院,北京 100048)
0 引 言
數據挖掘被稱為數據集中的知識發現,是在大量數據集中提取對于決策過程有用的知識的過程。數據挖掘自20世紀90年代被提出后,在許多領域得到了很好的應用。關聯規則挖掘是數據挖掘的重要組成部分。1993年,R.Agrawal等[1]提出了關聯規則的概念及模型,該模型主要是對一個事物和其他事物相互關聯的一種描述。目前,主要的關聯規則挖掘算法有Apriori和FP-growth,二者都是串行化的算法。Apriori[2]算法需要多次掃描數據集,過程中產生了大量候選集,測試這些候選集需消耗大量時間。FP-growth算法是一種基于頻繁模式樹的挖掘算法。該算法可以有效挖掘頻繁模式,并且比Apriori算法快大約一個數量級。但是隨著數據量的增大和數據集中的有用信息變得越來越稀疏,在建立FP-tree時會消耗大量的內存空間,以至于內存不夠用,無法完成挖掘任務[3-4]。Park等[5]提出利用系統抽樣的方法進行數據挖掘,然而單純只依靠抽樣的數據進行數據挖掘很容易造成結果的畸形和不準確。因此,學者們開始考慮通過并行計算環境來解決上述問題。文獻[6]采用基于多線程的并行算法,雖然緩解了存儲及計算的壓力,但是內存資源的局限制約了算法的擴展能力;文獻[7-8]中對MPI并行環境進行了詳細的敘述,然而該環境使用進程間通信的方式協調并行計算,導致并行效率較低、內存開銷大并且很難解決多節點的擴展性問題。并行算法通常具有較大的進程間的調度和通信開銷,并且很難將構建FP-tree的任務進行分割。
在前人研究成果的基礎上,文中提出了一種改進的FP-growth算法。眾所周知,數據集中高頻率的項集是包含在每條事務中的,那么含有頻繁項集的事務之間的歐氏距離總是較小的,所以數據集中的事務會具有聚類現象。利用SOM等聚類算法對其做聚類分析,再在每個類別上并行執行數據挖掘算法就可以得到挖掘結果了。首先利用聚類算法對數據集進行分割,然后在每個數據子集上并行執行FP-growth算法,這樣就將算法所需要的大內存空間分割成小內存進行運算了,并且由于子集是根據聚類結果劃分的,所以在各個子集上能夠高效地挖掘出有用的關聯規則,而非由于隨機劃分數據集導致挖掘出具有不確定性的規則。由于數據量較大,對大數據集做聚類分析會耗費大量的計算資源,所以文中利用系統抽樣方法從大數據集中抽取出具有代表性的樣本,然后利用SOM算法對樣本進行聚類分析,得到分類模型,利用該模型將整個數據集分成若干個子集,并在各個子集上采用FP-growth算法挖掘出關聯規則,最后將關聯規則合并得到總的結果,并通過實驗驗證了該算法的有效性。
1 SOM算法相關研究
聚類分析是目前數據挖掘的研究熱點之一,聚類分析能夠將數據聚類成為多個類或簇,從而使得在同一個類中的數據具有比較高的相似度,而不同類的數據之間有比較大的差別[9]。聚類分析過程是無監督的分析過程,在對數據進行分類之前,對類別數據是未知的。經典的聚類分析算法有K-means、CURE等,這些算法需要提前設定聚類的類別數。這種事前設定類別數的做法大多基于程序設計經驗,并且需要經過不斷試驗才能得到比較正確的分類,這種做法具有一定的不確定性,在一定程度上降低了聚類分析結果的可信度。自組織映射(self-organizing map)是由芬蘭學者Kohonen提出的一種只有兩層神經網絡的算法。SOM的權值調整方法與其他神經網絡相似,都是采用梯度下降法不斷地調整權值。它比較特有的地方就是將高維數據點按照原有的順序拓撲關聯到二維平面網格節點上,這樣就實現了高維數據的二維結構可視化。此外,由于SOM的高維數據的低維表達能力,SOM在數據分類、聚類等應用領域有很多成功的應用案例。文中利用SOM聚類算法實現對海量數據的聚類分析,進而利用聚類模型對數據庫進行分割,并在各個子集上進行FP-growth數據挖掘。
1.1 SOM算法描述
SOM神經網絡算法是一種特殊的神經網絡,由輸入層和輸出層構成。在輸入層上只存在一個神經元節點,該神經元節點對應于輸入向量x=[x1,x2,…,xd],其中d是輸入數據維數;在輸出層上有一系列的組織在二維平面網格上的神經元節點。每個神經元節點都相應地有一個權矢量m=[m1,m2,…,md]。SOM神經網絡權值的訓練步驟如下:
(1)設定輸出層每個節點的初始權重值。通過預先定義一個訓練長度或者設定程序終止的誤差閾值,來判斷訓練的終止條件。
(2)在數據集中選取一個樣本x,計算樣本與每個輸出層神經元節點之間的歐氏距離,然后選取與樣本x距離最近的神經元節點,該神經元節點稱為該樣本的最佳匹配節點(best-match unit,BMU),記為mc。
‖x-mc‖=min{‖x-mi‖}
(1)
(3)依據預先設定的鄰域函數來確定BMU鄰域的范圍,進而利用調節函數調整BMU及其鄰域內神經元節點的權重值:
mi(t+1)=mi(t)+a(t)hci(t)[x(t)-mi(t)]
(2)
其中,mi(t)為第t步節點i的權值;a(t)為第t步的學習率;hci(t)為鄰域函數。
學習率一般伴隨著訓練的推進而逐漸變小,這里一般選擇按線性減小、指數減小的方式。這里的鄰域函數通常使用高斯函數或者氣泡函數。
(4)如果還沒有達到訓練結束的條件,則返回步驟(2)繼續訓練。
1.2 聚簇分布特征圖
人們通常難以從高維數據中區分出數據的分布特征,然而SOM算法能夠將高維數據拓撲保序地映射到二維平面網格上,映射后的數據結構具有顯著的聚類特征,從而能夠高效地識別出聚類數據。文中利用SOM算法的這一特征來實現大數據集的聚類分析。眾所周知,很多算法在進行聚類分析之前往往需要盲目地確定聚類的簇數,尤其隨著數據的增大,這種方法往往效果很差。針對這種情況,設計了一種聚類分布特征圖,這個特征用來在聚類前先對數據進行預處理,這樣就能快速獲得數據分布的特點,從而確定數據聚類的類別數目。
通常訓練好的SOM神經網絡的輸出層往往組織成一個網絡結構,然后對每個神經元節點按列優先進行編號。假定SOM輸出層共有m*n個神經元節點,則定義下面的距離矩陣(distance-matrix),簡稱D-matrix:
(3)
其中,dij表示第i個神經元節點與第j個神經元節點之間的歐氏距離。
接著將距離與一個顏色范圍建立一一對應的關系,一般在灰度模式下,距離自小到大,距離所對應的顏色由淺至深,所以就可以得到一個與距離矩陣相對應的顏色矩陣(color-matrix),簡稱C-matrix。
(4)
其中,cij表示與dij相對應的顏色取值。
對每個輸出層節點根據顏色矩陣進行灰度值的著色,那么就得到了一張聚類分布特征圖,根據聚類分布特征圖就可以確定聚類個數。
2 FP-growth算法研究
2.1 關聯規則挖掘的定義
關聯規則是對一個事物和其他事物相互關聯的一種描述。關聯規則的挖掘就是從大量的數據集中找出這些數據之間的相互聯系。衡量規則的2個度量是支持度和置信度。
定義1:規則A?B在事務集D中成立,具有支持度S(support),S是D中包含A∪B的事務數與所有事務數之比,記為support(A?B),它等于事務包含集合A和B的并的概率P(A∪B)。即
support(A?B)=P(A∪B)=D(X)/|D|
(5)
其中,D(X)是數據集D包含X的事務數。
定義2:規則A?B在事務集D中的置信度C(confidence)是指包含A和B的事務數與包含A的事務數之比,它是條件概率P(A|B)。即
confidence(A?B)=P(A|B)=support(A∪
B)/support(A)
(6)
關聯規則挖掘首先要找出所有滿足最小支持度的項集,再計算出置信度大于閾值的所有關聯規則。
2.2 FP-growth算法
FP-growth算法主要是利用一個樹型結構來存儲數據項之間的順序關系,它通常需要掃描兩次數據庫來構建FP-tree,第一次掃描獲得頻繁1-項集,并篩選出滿足支持度大小的頻繁項,根據頻繁項的支持度計數進行從高到低的排序。第二次掃描數據庫就是按照第一次的頻繁項排序對原始事務中的數據項重新排序,并將其添加到以“NULL”為根節點的FP-tree中。在構建FP-tree的過程中,通常會建立一個項頭表T,表中包括三部分信息,分別是頻繁項、對應的支持度計數和指向FP-tree節點的指針。根據FP-tree提取出條件模式基,滿足置信度閾值的條件模式基和后綴就是挖掘出的關聯規則。
FP-growth算法主要由三個模塊構成:FP-growth模塊主要是FP-growth算法執行的流程;Insert模塊主要完成FP樹的構建過程;Search模塊用來獲取條件模式基集合,該條件模式基集合可以用來確定最后的關聯規則。
(1)Insert模塊。
輸入:已排序的頻繁項集Li,FP(子)樹根節點Rr
輸出:FP(子)樹Rr
IfLi!=null then
取出Li的第一項i
IfRr存在某子節點N=ithen
++N.count
Else
創建Rr的子節點N,節點內容為i
N.count=l
將N加入項頭表中
Insert(Li-1,N)
(2)Search模塊。
輸入:FP樹T,后綴模式α
輸出:頻繁項集合L_S
IfT中只有一個分支Pthen
ForP上節點的每個組合β
β=α∪β
L_S=L_S∪{β}
Else
ForT中的每個頻繁項i
構造β的條件模式及條件FP樹Rβ
IfRβ≠? then
Search(Rβ,β)
(3)FP-growth模塊。
輸入:事務集合T,最小支持度min_sup,最小置信度min_conf
輸出:強關聯規則集合R_S
掃描T找出頻繁1-項集L
按支持度計數降序排序L
創建FP樹的根節點NULL
ForT中的每個事務t
找出t中的頻繁1-項集合Li
Li中的項按L中的順序排序
Insert(Li,NULL)
L_S=Search(FP,NULL)
在L_S中產生強關聯規則集合R_S
接下來用一個簡單的例子解釋如何構建FP樹。假設存在事務集合T,如表1所示。假定min_sup=20%,那么事務集支持度計數=20%×10=2次。首先掃描一遍事務集,統計各類項的支持度計數,去掉支持度計數小于2的項。然后將頻繁1-項按照支持度計數從高到低排序,生成排序的頻繁1-項集L1=[B:8,A:7,C:5,D:2,E:2]。
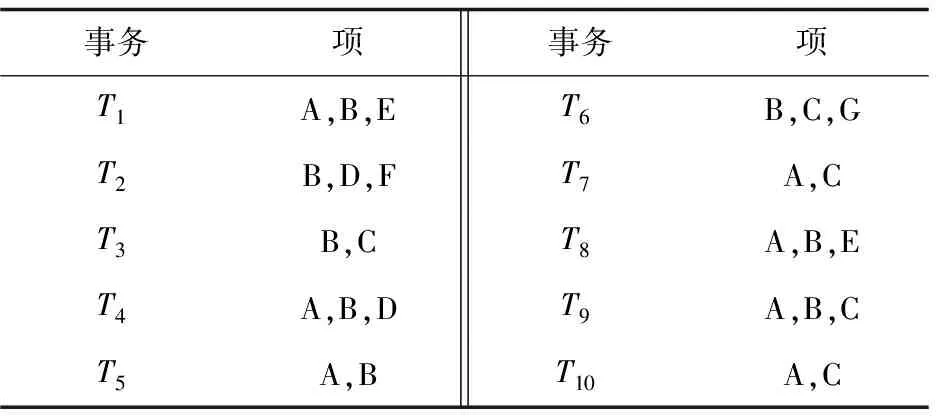
表1 事務集合T
根據排好序的頻繁1-項集集合創建項頭表,然后再遍歷一遍數據庫,構建FP樹。構建過程按照L1中項的順序創建,將頻繁項按照順序插入到以NULL為根節點的樹中,隨著事務中數據項的插入更新各個樹節點的支持度計數。根據Insert算法,遍歷所有事務之后得出圖1所示的FP-tree。故FP-growth算法是將事務中所有符合要求的項、項的計數以及項之間的相互關系都壓縮到一棵樹中。

圖1 FP樹與項頭表
3 基于SOM劃分的FP-growth算法
3.1 算法過程
FP-growth通過構造FP-tree來尋找頻繁模式,然而當數據集達到一定規模時,構造基于內存的FP-tree仍然是不現實的。文中提出的基于SOM劃分的FP-growth算法能解決上述問題。該算法利用SOM聚類方法得到信息較為聚集的數據子集,在各個子集上并行實施FP-growth算法,從而在大型數據集上挖掘出關聯規則。該算法總體分成5步:數據標準化;按照系統抽樣的方法從數據集中抽取樣本數據;利用SOM算法對樣本數據聚類,得到數據集事務的分類模型;將整個數據集中的事務按照分類模型分成若干個數據子集,在數據子集上并行執行FP-growth挖掘;匯總結果。算法流程如圖2所示。
(1)數據標準化。
數據集中的每條事務中包含的項都是離散的,為了便于求解事務之間的歐氏距離,需要把事務中的項改為用數字表示,含有對應的項記為1,不含的記為0。具體過程如下:

圖2 算法流程
(a)掃描一遍數據集,求出數據集中大于支持度的頻繁1-項集L1;

(2)抽取樣本。
(a)將數據庫D中事務編號,每條事務對應一個唯一的編號;
(b)將編號按某個間隔分成k段,當N/n(N表示數據集中的總的事務數,n表示樣本容量大小)是整數時,k=N/n;當N/n為小數時,從總的事務中去除一些事務,使剩下的事務數目能被n整除,這時k=N'/n(N'為剩下的事務數);
(c)在第一段中隨機確定一個編號l;
(d)從整體中按照編號l,l+k,…,l+(n-1)k抽取出來作為樣本。
(3)聚類分析。
利用SOM算法對樣本數據進行聚類分析,經過若干次迭代運算,得到自組織神經元間的距離數據,神經元之間距離小的為同一類,距離大的為不同類。神經元在二維平面上的分布情況很容易通過肉眼大概分辨出數據集中存在幾類數據。類別個數可以根據需要而定,一般情況下分得精細度越高,數據集中的類別數越多。文中在實驗驗證階段,依次提高數據劃分的精確度來驗證算法的加速程度。確定分類個數后,利用點集最小圓覆蓋法[12]確定每個類別的中心位置,得到中心位置集合:
C={c1,c2,…,cn}
(7)
其中,n為分類的類別數。
C中任何一個元素ck表示如下:
ck={ck1,ck2,…,ckm}
(8)
其中,m為中心坐標點的維數。
(4)FP-growth挖掘。
將數據集中的每條數據與C中的中心點進行比較,距離最小的中心點所屬的類別就是該條數據所屬的類別,即:
‖ti-cmin‖=min{‖ti-ck‖}
(9)
其中,ti表示任意一條事務數據;cmin表示與ti最近的中心點;ck表示C中任意一個中心點。
根據事務ti所屬的類別將其分配到對應的計算節點上,這個分配過程在分布式計算Spark框架內完成,在Spark平臺上編寫的數據分配程序依據事務數據與中心點的歐氏距離來分配數據所屬計算節點,詳細的Spark平臺的搭建和配置過程可參考文獻[13]。經過數據分割后,數據集D被分割成s個子集,表示為D=D1∪D2∪…∪Ds。
在每個計算節點上構建FP-tree,構建過程按照2.2節的算法。由于這個階段之前已經得到頻繁1-項集,并且該項集已按照支持度從大到小排序,所以只需將每條事務中的項添加到FP-tree上即可。
(5)結果匯總。
(a)在每個計算節點上,根據2.2節的Search()算法求出所有條件模式基;
(c)將(b)中得到的關聯規則合并就得到了整個數據集中蘊含的關聯規則。由于之前做了SOM聚類分析,所以每個數據子集上包含有相應類別的高密度頻繁項,那么也就包含了對應的關聯規則。假設數據集D中包含的關聯規則集R={r1,r2,…,rn}(n表示數據集中包含的關聯規則個數,ri表示任意一條關聯規則),任意一個數據子集所包含的關聯規則集RDi={rDi1,rDi2,…,rDim}(i=1,2,…,n,m表示子集中包含的關聯規則的個數,rDij表示子集中任意一條關聯規則),則有:RD1∪RD2∪…∪RDs=R={r1,r2,…,rn}。
3.2 算法復雜度分析
假設某挖掘任務中有s個關聯規則、m個符合最小支持度的項,事務有n個、平均每個事務中包含a個符合最小支持度的項。那么經典算法獲取s個關聯規則,忽略連接數據庫等開銷,算法需要計算的次數為m×n×a+m×s,由于n和m占主導作用,所以時間復雜度為O(mn)。假設抽取樣本的個數為b,聚類個數為c,改進算法的時間復雜度為m×n×a+m×s+c×b,由于b和c相較于其他項很小,可以忽略不計,所以時間復雜度也為O(mn)[14-15]。雖然改進算法與原算法的時間復雜度相同,但是由于改進算法將數據庫分割成小的子集,大大降低了算法的空間復雜度,減小了計算過程中的內存空間占用量,增大了對海量數據挖掘的可能性。而且在改進算法中各個子集并行進行數據挖掘,也大大縮減了運算時間。
4 實驗及結果分析
通過實驗對提出的基于SOM劃分的FP-tree算法進行驗證。實驗中的數據集均來自Frequent Itemset Mining Dataset Repository。
4.1 SOM聚類分析結果
實驗中使用的是connect.data數據集。對該數據集進行抽樣,對抽樣樣本進行SOM聚類分析,經過100次迭代后,二維平面上的神經元出現了聚簇,相似的神經元相互靠近,不同類的神經元相互遠離。每個神經元都與某些輸入點有著強連接,并且神經元之間也存在著連接權值,將距離較近的神經元歸為一類,它們對應的樣本點也屬于同一類。
為了凸顯聚類效果,在每一個類別上加入一個收縮因子,在收縮因子的作用下樣本點向各自的數據中心靠攏。為了更直觀地看到分類效果,在每個類別上分別標記不同的圖形:三角形、方形、菱形和圓形。經過多次調整參數,得到的聚類效果如圖3所示。由于這個過程需要比較復雜的編程,所以利用Java程序編程實現聚類的效果顯示。
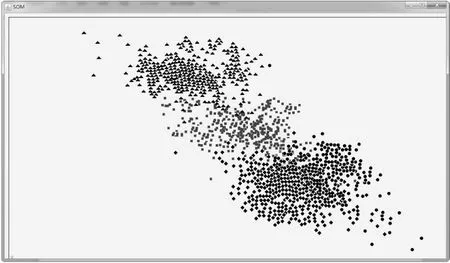
圖3 聚類效果
從圖中可以看出,經過SOM聚類分析,樣本數據分成了4類,雖然每個類別有一些數據相互重疊,但是總體上并不影響最后的聚類效果。
4.2 基于SOM劃分的FP-growth算法性能實驗
根據4.1中的聚類結果,將原數據集分割成4個子集,在每個子集上并行執行FP-growth算法。算法執行過程中單個計算節點的內存占用情況如圖4(a)所示。圖4(b)顯示的是未改進的FP-growth算法執行過程中的內存占用量。圖4中顯示的是加上計算機操作系統和其他進程所占的內存空間后的內存使用情況,并且是以60 s為一個時間片段顯示的。通過比較發現,改進算法內存占用量遠遠低于未改進算法,可以用來對大型數據集進行數據挖掘,而未改進的FP-growth在對大型數據集進行挖掘時,很快就會占用大量內存,以至于計算機物理內存空間不夠造成數據挖掘任務無法繼續進行。

圖4 內存占用量
將改進算法與Apriori算法和FP-growth算法進行速度上的比較,在支持度為5%的情況下,各個算法的運算時間如圖5所示。
從圖中可以看出,隨著數據量的增加,三種算法所消耗的時間都在增加,然而FP-growth算法的時間消耗明顯低于Apriori算法,主要因為隨著數據量的增大,Apriori算法會產生大量的候選項,這些候選項的處理耗費了大量時間。改進的FP-growth算法相較于沒有改進的FP-growth算法明顯降低了算法的運算時間。從圖中可以看出,未改進的FP-growth算法隨著數據量的增加所消耗的時間也在快速增長,而改進的FP-growth算法呈現平緩的增長趨勢,由此可見改進算法在性能上有明顯的提升。

圖5 執行時間對比
5 結束語
主要闡述了對FP-growth算法改進的過程。該算法利用SOM聚類算法對從大數據集中抽樣的樣本進行聚類分析,根據聚類結果將大數據集分解成若干個子集,這些子集具有較高密度的關聯規則,在各個子集上并行執行FP-growth算法就得到了數據集中所包含的關聯規則。實驗結果表明,改進算法降低了內存的占用率,縮短了數據挖掘時間。
參考文獻:
[1] AGRAWAL R,IMIELINSKI T,SWAMI A.Mining association rules between sets of items in large databases[C]//Proceedings of the 1993 ACM-SIGMOD international conference on management of data.New York,NY,USA:ACM,1993:207-216.
[2] AGRAWAL R,SRIKANT R.Fast algorithms for mining association rules[C]//Proceedings of the 1994 international conference on very large data bases.[s.l.]:[s.n.],1994:487-499.
[3] HAN J,PEI J,YIN Y.Mining frequent patterns without candidate generation[C]//Proceedings of 2000 ACM SIGMOD international conference on management of data.New York,NY,USA:ACM,2000:1-12.
[4] 楊 勇,王 偉.一種基于MapReduce的并行FP-growth算法[J].重慶郵電大學學報:自然科學版,2013,25(5):651-657.
[5] PARK J S,CHEN M,YU P S.Using a hash-based method with transaction trimming and database scan reduction for mining association rules[J].IEEE Transactions on Knowledge and Data Engineering,1997,9(5):813-825.
[6] 吳建章,韓立新,曾曉勤.一種基于多核微機的閉頻繁項集挖掘算法[J].計算機應用與軟件,2013,30(3):44-46.
[7] AOUADL M,LE-KHAC N A,KECHADI T M.Distributed
frequent itemsets mining in heterogeneous platforms[J].Journal of Engineering,Computing and Architecture,2007,1(2):1-12.
[8] 鄒 翔,張 巍,劉 洋,等.分布式序列模式發現算法的研究[J].軟件學報,2005,16(7):1262-1269.
[9] 李文棟.基于Spark的大數據挖掘技術的研究與實現[D].濟南:山東大學,2015.
[10] 王 樂,馮 林,王 水.不產生候選項集的TOP-K高效用模式挖掘算法[J].計算機研究與發展,2015,52(2):445-455.
[11] GOETHALS B,MOHAMMED J Z.Advances in frequent itemset mining implementations:report on FIMI'03[J].ACM SIGKDD Explorations Newsletter,2004,6(1):109-117.
[12] 楊中華.平面點列最小覆蓋圓的計算方法[J].北京工業大學學報,2000,26(2):96-97.
[13] 毛宇星,施伯樂.基于擴展自然序樹的概化關聯規則增量挖掘方法[J].計算機研究與發展,2012,49(3):598-606.
[14] HAN J W,MICHELINE K.數據挖掘:概念與技術[M].范明,孟小峰,譯.北京:機械工業出版社,2012.
[15] 易 彤,徐寶文,吳方君.一種基于FP樹的挖掘關聯規則的增量更新算法[J].計算機學報,2004,27(5):703-710.
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
大眾投資指南(2021年35期)2021-02-16 01:06:26
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
電力與能源(2017年6期)2017-05-14 06:19:37
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
信息通信技術(2015年6期)2015-12-26 01:16:46
