一種新的基于DTW的孤立詞語音識別算法
2018-04-13 01:12:25周炳良鄧立新洪民江
計算機技術與發展 2018年4期
關鍵詞:特征
周炳良,鄧立新,洪民江
(南京郵電大學 通信與信息工程學院,江蘇 南京 210003)
0 引 言
語音識別即讓機器接收、識別和理解語音信號,能夠“聽懂”會話中的語音語義并執行人類意圖。常用的識別方法包括動態時間規整(DTW)、隱馬爾可夫模型(HMM)和人工神經網絡(ANN)等。在孤立詞語音識別中,動態時間規整是最簡單有效的方法。DTW算法基于動態規劃(DP)的思想,能夠較好地解決孤立詞識別時說話速度不均勻的難題。相較于傳統的語音線性伸縮匹配的方法,DTW方法有效提高了孤立詞語音識別系統的識別率,因此在特定場合下得到了較好的應用。
近年來,為了提高孤立詞語音識別系統的效率,使其廣泛適用于市場和各類服務領域,科研人員提出了許多新的基于DTW的語音識別算法。
文獻[1]提出了基于音節個數的高效動態時間規整算法(SEDTW),該算法利用彝語語音信號音節個數從1個到7個不等的特點,預先檢測出彝語語音信號中的音節個數,并將其只與含有相同音節個數的模板進行最優匹配,減少了系統的計算開銷,提高了系統的識別效率。但該算法利用雙門限檢測法分辨語音信號的各個音節,對門限閾值精度要求很高,一旦閾值設置不準確,系統識別效率將大幅降低,且該算法只適用于彝語語音信號識別,適用率較低。
文獻[2]提出了改善局部路徑限制的DTW算法,該算法改善了局部路徑節點前進的范圍,有利于解決測試語音特征矢量與模板矢量均勻變化劇烈的匹配問題,加快了兩矢量匹配的過程。但該算法增加了系統局部路徑搜索的復雜度和內存消耗,且不利于解決兩矢量均勻變化平緩的匹配過程。
文獻[3]提出了增設參考模板閾值的DTW算法,該算法在進行測試語音特征矢量與模板矢量匹配時,一旦計算出部分失真度大于預先增設的模板閾值,將終止對該模板繼續運算,轉入對其他模板繼續匹配運算。由于是中途停止對模板的匹配運算,因此可以節省部分計算開銷,提高了系統的識別效率。該算法的識別效率優于文獻[2]的算法,但是算法必須要為每一個模板找到一個合理的閾值,否則將無法減少系統的運算量,甚至大幅度降低系統的識別率。
在識別階段,傳統的DTW算法在測試語音特征矢量與所有參考模板矢量之間進行的是全長度最優路徑匹配,一旦系統的參考模板數量較大,系統的計算量和內存消耗將加劇,從而嚴重影響識別系統的效率。針對上述問題,提出了一種加快DTW模板匹配的改進算法:預先對提取得到的測試語音特征矢量進行部分長度截取,并將得到的部分特征矢量與模板矢量進行最優路徑匹配,排除掉匹配度較小的部分模板。如此快速反復進行語音部分匹配和模板排除,直至模板數量唯一。通過實驗對該算法的識別效率進行了驗證。
1 DTW算法的基本原理
DTW技術是一種把時間規整和距離測度計算結合起來的非線性規整技術,通過不斷地計算測試語音特征矢量和模板特征矢量的距離來搜索兩者之間的最優時間規整(最優匹配路徑),保證它們之間存在最大的聲學相似特性。假設待測語音共有N幀矢量,參考模板共有M幀矢量,分別記為T和R,且N≠M,則動態時間規整就是要找一個時間規整函數m=w(n),將測試語音特征矢量的時間軸n非線性地映射到模板的時間軸m上,并使函數w滿足式(1):
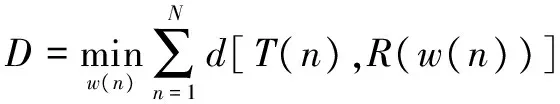
(1)
其中,d[T(n),R(w(n))]是第n幀矢量T(n)和第m=w(n)幀模板矢量R(m)之間的距離測度;D是處于最優時間規整情況下兩矢量的累積距離[4]。
實際上,DTW算法本質就是搜索測試語音特征矢量與模板矢量的最優匹配路徑并求出兩者之間最小累積距離D。現實應用中,由于說話人對同一語音的發音速率相差一般不超過2倍,為了滿足這一實際特性,搜索最優匹配路徑時,應該將最優匹配路徑全局(任意節點與起點或止點的連線)限制在兩邊斜率分別為1/2和2的平行四邊形中[5-6],如圖1所示,且止點(N,M)滿足式(2):
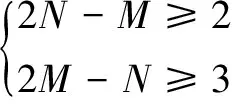
(2)

圖1 最優路徑全局限制示意圖
同時對其局部路徑(任意節點與前續節點的連線)也應加以限制,確保搜索路徑中節點的前續節點在一定范圍內,典型的一種局部路徑限制方式[7-8]如圖2所示。
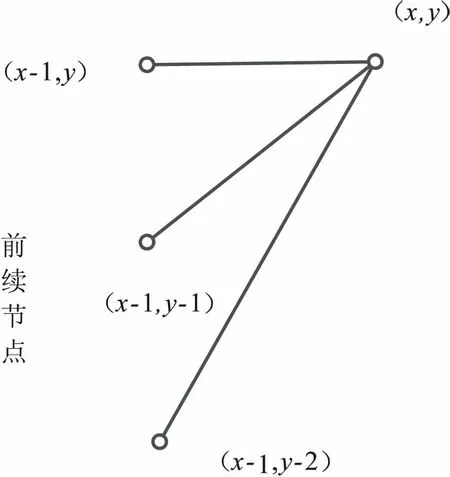
圖2 最優路徑局部限制示意圖
為了找到滿足最小測度距離D的最優匹配路徑,DTW算法采用逆序決策過程,即節點的前續節點決定該節點的最小累積距離。假設路徑的任意節點(x,y),搜尋出所有其可能的前續節點,并選擇其中累積距離最小節點作為前續節點,則到達該點路徑的最小累積距離計算公式為:
D(x,y)=d(T(x),R(y))+min{D(x-1,y),
D(x-1,y-1),D(x-1,y-2)}
(3)
式中節點滿足圖2的局部路徑限制方式,且測試語音特征矢量作為橫軸,模板矢量作為縱軸。這樣從起點(1,1)開始搜索路徑,利用式(2)反復遞推后續節點的最小累積距離,經過N步后到止點(N,M)結束,即兩矢量全長度最優路徑匹配,則D(N,M)為測試語音特征矢量與模板矢量的最小累積距離。
傳統孤立詞識別系統基于上述DTW算法,分別搜索出測試語音特征矢量與所有庫模板矢量的最優匹配路徑并計算出兩者的最小累積距離D,然后選擇其中D最小的模板所表示的語音作為判別結果[8-9],具體算法流程如圖3所示。
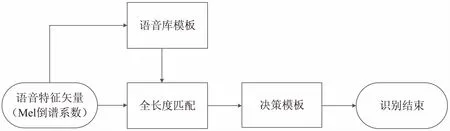
圖3 傳統全長度匹配流程
2 DTW算法的改進
由上一節知道,傳統孤立詞語音識別時,需要將測試語音特征矢量與所有的庫模板都進行全長度最優路徑匹配。如果孤立詞語音庫模板量較大,系統的計算量將急劇上升,嚴重影響系統的識別效率。這個現象在一詞多模板的非特定人識別系統中尤其突出。
2.1 改進思路
假設測試語音特征矢量表示的是實際孤立詞V,則與模板庫中其他孤立詞模板相比,它的起始部分長度與模板庫中同樣表示孤立詞V的模板的起始部分長度之間匹配失真度相對較小。反之,如果將測試語音特征矢量V的起始部分長度與所有庫模板矢量進行最優路徑匹配,那么只需要保留部分匹配失真度相對較小的庫模板矢量就可以將表示孤立詞V的模板矢量保留下來。由于匹配過程中只需要測試語音特征矢量的起始部分長度進行匹配運算,便可以排除匹配失真度較大的部分模板,因此系統減少了部分計算量。
綜合以上想法,提出了測試語音特征矢量與庫模板矢量部分長度最優路徑匹配的DTW算法,具體思路如下:先截取提取得到的測試語音特征矢量的起始部分長度(百分比),并從起點(1,1)開始搜索它們與各個模板矢量的最優匹配路徑,采用松弛端點檢測[10]的方法找到最優匹配路徑的止點并求出各自的最小累積距離D,即找出各模板矢量與截取語音特征矢量匹配度最大的起始部分長度并求出相應的D,然后選擇D相對較小的部分模板進行保留,排除D相對較大的模板。如此循環,采用這種方法對剩余的模板進行部分長度匹配和排除,直至剩余模板數量唯一,該算法流程如圖4所示。
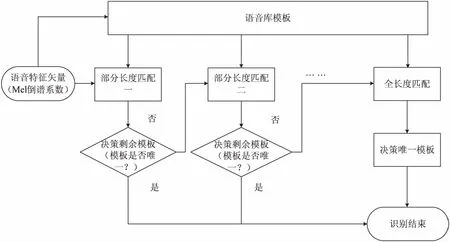
圖4 部分長度匹配流程
2.2 準備工作
改進的DTW算法中測試語音特征矢量的截取方式和模板矢量保留方式需要預先設置,具體方法如下:每次截取的語音特征矢量都從起點開始,長度逐次增加。由于每次截取的測試語音特征矢量表示的語音可能與多個模板矢量起始部分表示的語音相同,所以每次部分長度匹配后保留的剩余模板一般大于1個(最后一次除外)。假設系統中有2個庫模板矢量,分別表示語音“三”和“四”,它們的語音在起始端有相同的部分:‘s’。如果截取的語音特征矢量表示的語音在‘s’范圍內,一旦系統只保留一個模板,就有可能錯判。為了保證部分長度匹配算法的識別率,每次部分長度匹配后采用如下方法估計保留模板個數:假設庫模板總數為l,截取所有庫模板矢量的起始部分,截取長度(百分比)與此次截取測試語音長度(百分比)一致,并將截取的各個模板矢量的起始部分表示為語音,則語音總數為l。選擇其中一個截取語音,統計出庫模板表示的語音中首部包含該語音的總數,記為該語音與庫模板語音的相似數c1。同理,分別為其他截取語音統計出相似數,記為c2c3…cl。比較所有相似數并取其中最大值cmax,則cmax與l的比值就是該次部分長度匹配后保留模板的百分比。
2.3 改進算法的步驟
改進DTW算法的步驟如下所述:
(1)將訓練模板存入內存,總數記為c,同時進行識別階段預設工作:設置測試語音特征矢量的截取方式,包括截取次數m和各次截取長度a1,a2,…,am(百分比);設置各次最優路徑匹配后訓練模板的保留個數b1,b2,…,bm-1(百分比且最后一次取一個模板,bm可忽略);
(2)輸入測試語音信號,經過語音信號預處理(預加重、分幀加窗和端點檢測)之后,提取出測試語音特征矢量;
(3)利用式(2)的條件排除部分訓練模板,保留滿足條件的訓練模板;
(4)設某一保留訓練模板矢量與測試語音特征矢量的幀匹配失真度矩陣為d和累積失真度矩陣為D=Realmax,其中d和D的大小均為N*M且橫向表示待測語音幀,縱向表示訓練模板幀。計算該訓練模板矢量第一幀與測試語音特征矢量第一幀的失真度(歐氏距離),并保存到d(1,1)和D(1,1)中。同理,計算所有保留訓練模板矢量第一幀與測試語音特征矢量第一幀的失真度(歐氏距離),并分別保存到各自的幀失真度矩陣與累積失真度矩陣相同的位置;
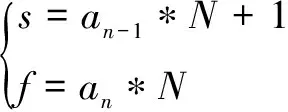
(6)計算搜索到的訓練模板矢量幀與待測語音s~f幀之間的幀失真度(歐氏距離),并利用式(3)遞推相交幀的累積失真度,分別保存到d與D相應的位置;
(7)找出累積失真度矩陣f列中最小的值,記為該訓練模板矢量的最優部分匹配失真度Dmin;
(8)重復步驟5~7,計算并找出所有保留訓練模板矢量的最優部分匹配失真度Dmin。將保留的訓練模板矢量按照各自的Dmin從小到大排序,并保留前c*bn(四舍五入取整)個模板;
(9)判決c*bn1?若是,則轉入步驟10執行;若否,則轉入步驟11執行;
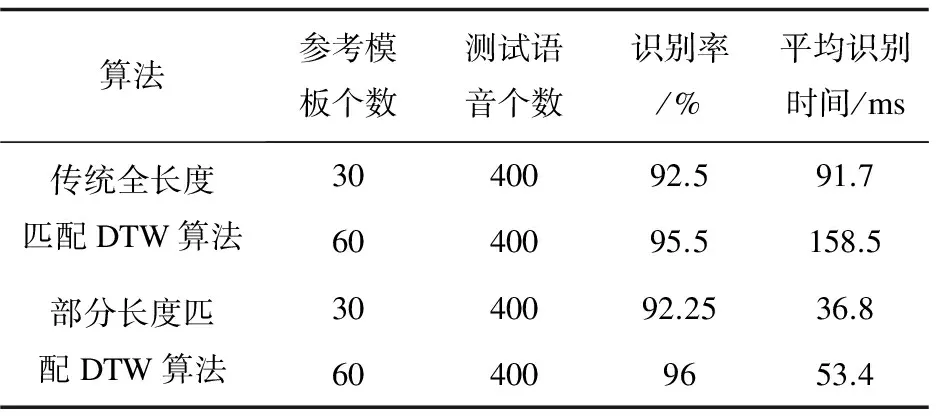
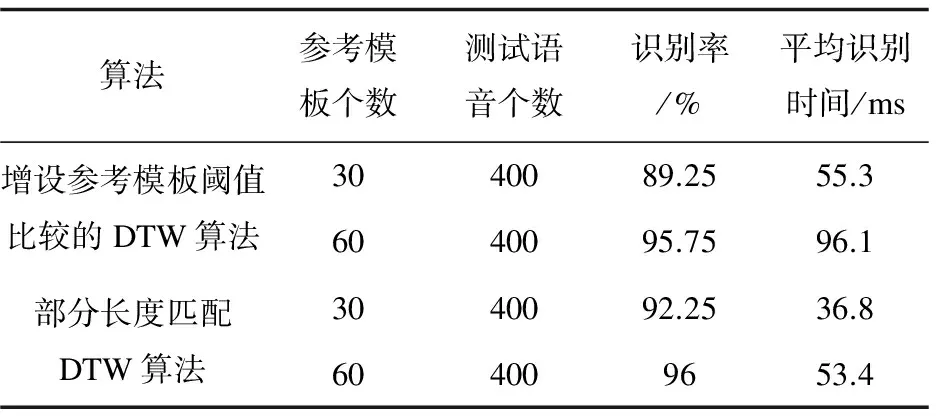
(10)判決n (11)將步驟8中已排序的訓練模板矢量中的第一個訓練模板矢量表示的語音判決為測試語音,結束。 假設孤立詞語音識別系統中有N個模板,平均測試語音提取參數的時間為t0,識別時間為t1,則全長度匹配需要的時間為N*(t0+t1)。在保證系統識別率基本不變的情況下,部分長度匹配需要的時間粗略計算如式(4): (4) 其中,a1,a2,…,am逐次增加且b1,b2,…,bm-1逐次減小。由式(4)可得,T的值始終小于N*(t0+t1)。當a1與b1取值很小時,系統采用部分長度匹配算法所需的識別時間接近N*(t0+t1*(a1+b1-a1*b1)),遠小于采用全長度匹配算法所需的時間N*(t0+t1)。 為了檢驗上述部分長度匹配DTW算法在降低系統識別時間方面的有效性,進行了兩組仿真實驗:比較部分長度匹配DTW算法與傳統全長度匹配DTW算法,以及部分長度匹配DTW算法與文獻[3]中增設參考模板閾值的DTW算法。實驗中語音數據采自于28位男生,12位女生,內容包括0~9十個漢語發音的數字。其中每個人對各個數字重復發音2次,總共800組數據。由于實驗數據來自于非特定人,實驗采用聚類的方法訓練模板[11-13],即對每個數字所有人的第一遍發音(40組數據)進行聚類訓練出3個或6個模板,10個數字共30個或60個模板。其中語音參數采用36維Mel系數(12維Mel系數+12維一階差分參數+12維二階差分參數)[14-17]。語音采樣頻率為16 kHz,預加重系數μ=0.937 5。采用漢明窗進行分幀,幀長256個樣點,幀移80個樣點。 實驗中部分長度匹配DTW算法采用將測試語音特征矢量依次截取3部分(10%,70%,100%)的方式進行匹配,同時每次匹配后保留部分模板(20%,10%)作為下次部分匹配的參考模板,截取過程中矢量長度或模板個數的小數部分四舍五入取整。仿真結果如表1和表2所示。 從表1中的數據可以看出,在保證系統識別率基本不變的情況下,采用部分長度匹配算法的識別時間大約是傳統全長度匹配DTW算法的1/3,大幅降低了孤立詞語音識別系統的識別時間。 從表2可以看出,相較于采用增設參考模板閾值的DTW算法,采用部分長度匹配DTW算法的識別時間也有明顯降低。而且采用部分長度匹配DTW算法避免了增設參考模板閾值的DTW算法額外設立合理閾值的問題,減少了識別系統的額外工作量。 表1 部分長度匹配算法與傳統DTW算法的識別性能比較 表2 部分長度匹配算法與文獻[3]中DTW算法的識別性能比較 為了提高孤立詞語音識別系統的識別效率,提出了測試語音特征矢量與模板矢量部分長度最優路徑匹配的算法。在算法中,每一次進行部分長度匹配時只需截取一段測試語音特征矢量與剩余的模板矢量進行匹配,便可以大量排除匹配失真度較大的模板。仿真結果表明,與傳統DTW算法相比,該算法在保證系統識別精度基本不變的情況下,減少了系統的工作運算量,有效降低了系統的識別時間。 參考文獻: [1] 余 煒,周 婭,萬代立,等.基于改進DTW的彝語孤立詞識別研究[J].昆明理工大學學報:自然科學版,2014,39(5):47-53. [2] ZHANG Z,TAVENARD R,BAILLY A,et al.Dynamic time warping under limited warping path length[J].Information Sciences,2017,393:91-107. [3] 張寶峰.基于DSP的語音識別算法研究與實現[D].蘭州:蘭州理工大學,2011. [4] 陳泉坤.基于DSP5509A的DTW語音識別系統設計與實現[D].成都:電子科技大學,2012. [5] 吳佳龍,李 坤,劉 中.孤立詞語音識別算法研究與設計[J].電子科技,2015,28(2):22-25. [6] 陳立萬.基于語音識別系統中DTW算法改進技術研究[J].微計算機信息,2006,22(2-2):267-269. [7] 朱淑琴,趙 瑛.DTW語音識別算法研究與分析[J].微計算機信息,2012,28(5):150-151. [8] 廖振東.基于DTW的孤立詞語音識別系統研究[D].昆明:云南大學,2015. [9] 蘇 昊,王 民,李 寶.一種改進的DTW語音識別系統[J].中國西部科技,2011,10(1):38-39. [10] 文 翰,黃國順.語音識別中DTW算法改進研究[J].微計算機信息,2010,26(7-1):195-197. [11] ABDULLA W H,CHOW D,SIN G.Cross-words reference template for DTW-based speech recognition systems[C]//Tencon conference on convergent technologies for the Asia-pacific Region.[s.l.]:[s.n.],2003:1576-1579. [12] 封伶剛,王秀萍.一種新的基于LBG和DTW的模板訓練算法[J].計算機工程與應用,2005,41(26):85-88. [13] 李 燕,陶定元,林 樂.基于DTW模型補償的偽裝語音說話人識別研究[J].計算機技術與發展,2017,27(1):93-96. [14] 甄 斌,吳璽宏,劉志敏,等.語音識別和說話人識別中各倒譜分量的相對重要性[J].北京大學學報:自然科學版,2001,37(3):371-378. [15] DHINGRA S D,NIJHAWAN G,PANDIT P.Isolated speech recognition using MFCC And DTW[J].International Journal of Advanced Research in Electrical Electronics & Instrumentation Engineering,2013,2(8):4085-4092. [16] LIMKARA M,RAOB R,SAGVEKARC V.Isolated digit recognition using MFCC And DTW[J].International Journal of Advanced Electrical & Electronics Engineering,2012,1(1):59-64. [17] MUDA L,BEGAM M,ELAMVAZUTHI I.Voice recognition algorithms using mel frequency cepstral coefficient (MFCC) and dynamic time warping (DTW) techniques[J].Journal of Computing,2010,2(3):138-143.2.4 改進算法的識別性能評估
3 實驗結果及分析
4 結束語
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
