國內外數字文獻資源聚合研究現狀及述評
2018-04-18 08:04:04遲海琭內蒙古農業大學圖書館哈爾濱工業大學圖書館
圖書館理論與實踐 2018年3期
克 非,遲海琭(.內蒙古農業大學圖書館;.哈爾濱工業大學圖書館)
1 數字資源聚合研究背景掃描
近年來,用戶對數字資源的需求向細粒度方向發展,用戶關注的是問題的直接解決,而非圖書館提供不同檢索途徑獲得的相關文獻。圖書館急需對現有資源進行深度組織和標引,并通過語義網技術和關聯數據技術實現資源組織向廣度不斷拓展、向深度不斷延伸。目前,數字資源中最大的一部分是商業數字資源,而各商業數字資源提供商之間的元數據和資源組織方式不同,對圖書館資源聚合和知識服務形成了制約。為此,業內開展了從資源整合、資源的單一維度聚合、資源多維度聚合、資源多維度聚合的有機融合以及資源的深度聚合等相關研究。
對圖書館館藏各類資源進行組織和標引,對數字資源進行深度挖掘,從大規模數據集中進行知識分析、知識獲取、知識挖掘、知識發現、知識創新和知識服務,是當今圖書館數字資源服務的核心。圖書館傳統資源服務的不足需要通過數字資源聚合提升圖書館知識組織和知識服務能力,通過數字文獻資源聚合實現資源的深度和廣度聚合已成為圖書館提供知識服務的必由之路。本研究通過對國內外現有相關文獻成果的梳理和分析,在此基礎上進行歸納和總結,以期發現國內外數字資源研究的進展及其不足,針對目前研究的不足提出相關對策和建議,為數字資源聚合的相關研究提供新的思路和視角。
2 國內數字資源聚合研究現狀
2.1 數據來源及獲取
國內研究選擇CNKI期刊總庫作為基礎數據源。為準確和有效地獲取相關的文獻資源,本研究圍繞數字資源聚合及其在實施過程中可能涉及的理論、技術和方法等關鍵詞進行相關文獻檢索、分析和獲取。為了實現此目的,中文文獻檢索式采用“(SU=聚合)AND(SU=文獻資源OR SU=數字資源OR SU=信息資源OR SU=數字文獻 OR SU=數據)”,[1]通過專業檢索,共檢索到172條記錄,去除不相關領域的文獻和會議通知廣告等信息,剩余162條。本研究的數據清洗不同于以往對數據結果的處理方式,而是保留了除上述提到的與本研究明確不相關的文獻外的其他相關文獻,為資源聚合研究的進一步深入分析奠定基礎。按照共詞分析的要求,以EndNote格式輸出檢索結果數據。
2.2 共詞頻次統計分析
對于不同研究領域的相關研究成果均會有作者著錄的關鍵詞。作者提供的關鍵詞對研究成果進行深度揭示,突出研究成果的研究主題、研究方法和研究結果。CNKI對研究成果按學科分類、主題分類、基金分類、期刊分類、期刊類別等進行聚合。共詞分析(Co-word Analysis)是通過對反映文獻主題內容的關鍵詞進行統計分析,研究文獻內在聯系和科學結構。[2]對關鍵詞列表、標題、摘要等進行提取,結合研究者的經驗在選詞個數和詞頻高度平衡的基礎上結合齊普夫第二定律輔助判定高頻詞。運用共詞分析工具對162篇論文關鍵詞進行共詞分析,出現4次以上的關鍵詞共20個(見表1)。
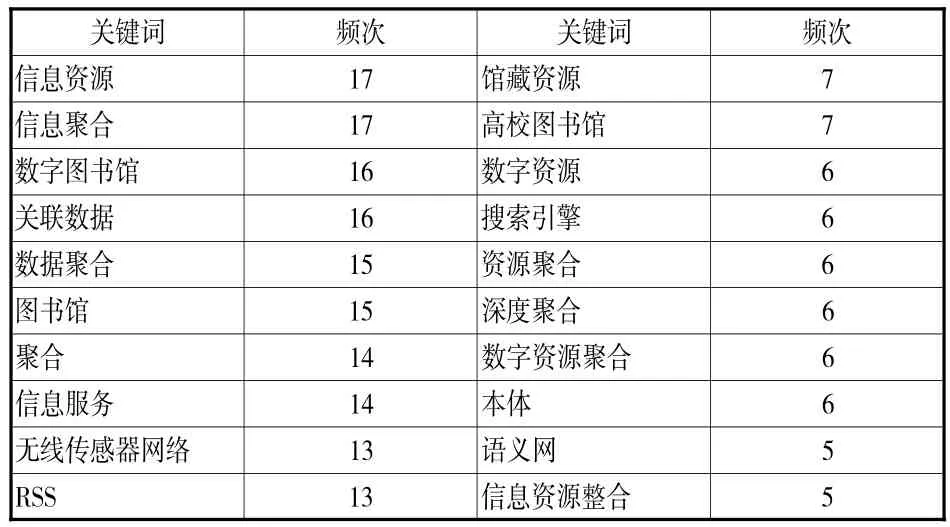
表1 頻次大于4的中文關鍵詞分布
通過表1可知,目前在國內資源聚合研究領域,成果較多的是“信息資源聚合”、“信息聚合”、“數字圖書館資源聚合”;運用的方法有“關聯技術”、“RSS技術”、“本體技術”和“語義網技術”;資源聚合研究主要集中在“圖書館資源聚合”、“高校圖書館資源聚合”、“館藏資源聚合”、“數字資源聚合”、“搜索引擎的資源聚合”;在資源聚合研究中“無線傳感器網絡資源聚合”是關注比較多的,另外關注度較多的是“資源的深度聚合”。
2.3 構建關鍵詞共詞圖譜
共詞分析通過高頻主題詞共現、關鍵詞共現、作者共現、甚至文獻內容的其他標識共現等為研究某學科領域的結構和特點、發現其研究前沿提供支持手段,所有方法均有一個共同的原理,即共現的聚類分析。[3]其原理是對一組詞兩兩統計它們在同一篇文獻中出現的次數,在此基礎上對這些詞進行聚類分析,聚類結果可以反映出這些詞之間的親疏關系,進而分析這些詞所代表的學科和主題的結構變化,也就是說選取的詞對中,兩個詞共同出現的頻率越高,則這兩個詞的關聯強度越高。通過運用共詞軟件繪制本研究的共詞關系圖譜,進一步對本研究的相關成果進行深入分析。在繪制共詞關系圖譜時,并沒有嚴格按照對頻次大于某一特閾值的關鍵詞進行共詞分析,而是對所有符合條件的關鍵詞進行共詞分析(見圖 1)。

圖1 相關中文文獻關鍵詞共現圖譜
從共現關鍵詞圖譜結構上看,96個關鍵詞分成了3個較為分明的版塊:① 共現集中區域,這一區域的研究成果多,共現關系復雜;② 孤立化呈現區域,這個區域有4個獨立的孤立化呈現區域;③ 單個關鍵詞區域,為了圖譜的整潔,圖1已去處獨立化呈現的關鍵詞。這3個版塊代表的研究領域的重點不同,對于實際研究拓展具有很好地指導作用。
2.4 共現關鍵詞圖譜分析
(1)研究成果較多的領域。現有研究成果較多的集中在圖1較小橢圓標注的領域,主要有:“聚合”、“RSS”、“網絡信息資源聚合”、“圖書館資源聚合”、“高校圖書館資源聚合”、“館藏資源聚合”、“數字文獻資源聚合”、“資源深度聚合”、“關聯數據聚合”、“語義網資源聚合”、“信息聚合”、“數字圖書館聚合”、“信息資源聚合”、“數字文獻資源聚合”、“本體聚合”。“無線傳感器網絡資源聚合”與其他文獻共現的次數也比較多,說明目前在該領域的研究中已被相關學者和專家關注,未來可能成為資源聚合研究的一個重要方向。在該領域中節能、能耗、分簇和網絡生命周期方向的成果已出現。
(2)分散不成關系的領域。現有研究成果分散沒有和資源聚合形成聯系的孤島研究領域主要集中在以下部門。① 海事部門,[4]有關云計算機平臺的構建意義和研究方法,如圖1左上角可以看出4個關鍵詞兩兩形成關系,共同組成一個小的研究領域,但是在現有文獻中并沒有與資源聚合主體文獻形成實質聯系。說明這一領域的研究也是未來研究的一個方向,在海事領域通過構建云計算平臺實現各類資源聚合,并應用到海事業務中。② 通信行業,[5]在圖1左上方第2個橢圓標注的是中國聯通和互聯網發展,說明在通信業務中也開始關注資源聚合,并進行相關研究,以期通過互聯網的發展推動通信業務的進程。③ 地理信息,[6]該領域研究也開始關注資源聚合,通過地理信息聚合繪制天地圖,從而為旅游服務系統應用,并為旅游業的發展改進創造條件。④ 報網行業,[7]通過報網互動研究聚合非專業性,實現受眾參與。可見傳統的報紙業也開始關注資源聚合,并通過網絡與受眾互動,在此期間注意非專業性的聚合,為報網互動提供理論基礎和實踐指導。
(3)共現未揭示出的領域。雖然通過表1揭示出了共現關鍵詞的主要部分,但是由于受到詞頻數的限制,一些關鍵的共現關系并未揭示出來。這些領域主要涉及到如下幾個方面。① 數據聚合,在資源聚合研究中,已開始出現細粒度資源聚合的相關文獻。這使得資源聚合向深度聚合方向邁進。該領域研究涉及到數據的采集、自組織等。通過圖譜發現該領域有兩個方向:一個是代表了傳統意義上的資源聚合,另一個代表了通信領域的數據聚合,在這兩個方向的研究已經形成了關聯關系。② 知識發現,資源聚合的目的之一是實現知識發現,不同類型的資源聚合研究領域都或多或少與知識發現形成了共現,如語義、信息聚合、關聯數據、信息共享等。③可視化研究,資源聚合結果的展示方式之一就是通過可視化方式呈現揭示出不同研究領域之間的相關關系,為理論研究和實證研究提供線索和思路。④ 社會網絡分析,已作為數字資源聚合的方法之一,在資源聚合中被逐漸關注和應用。⑤ 數據采集,作為聚合原料的數據,采用什么方法有效地采集也是研究中比較關注的一個方面。
(4)孤立化呈現的關鍵詞。由于在圖譜的制作中沒有去掉共現頻次較少的關鍵詞,所以在圖譜顯示中出現了孤立化的關鍵詞,分別是“低利用率文獻”、“信息資源聚合”、“南方報業”、“創新”和“媒介”。在以往的研究中更關注的是共現頻次較大的關鍵詞,本研究特意關注了孤立化形式呈現的關鍵詞。通過對孤立化關鍵詞的分析,我們可以發現在資源聚合的研究中個別學者對低利用文獻進行了關注,試圖通過資源聚合的方法提高低利用率文獻的利用率。信息資源聚合雖然以孤立化形式呈現,但在實際研究中已設計信息資源聚合,只是尚未在二者之間出現共現的關鍵詞。南方報業的孤立化現象表明了在報業中開始關注資源聚合,試圖通過資源聚合的方式更好地開展服務,迎來報業發展的又一個春天。創新和媒介的孤立化呈現表明,有關學者正在研究通過資源聚合實現創業或者媒介需要通過資源聚合進一步創新發展。
2.5 國內研究的主要內容
(1)資源聚合的理論研究。從目前現有研究成果來看,數字資源聚合的基礎理論和體系研究較少。畢強等[8]學者從哲學和圖書情報學視角探究數字資源聚合的思想和理論基礎。從概念聚類、概念關聯、知識關聯3個層次闡述數字資源聚合方法,構建數字資源聚合的方法體系。以柏拉圖、波普爾、布魯克斯、加菲爾德等人的思想為基礎,指出以本體、關聯數據、社會網路分析等方法為數字資源聚合研究提供方法支撐的研究,并提出數字資源聚合的科學系統發展需要兼顧理論和方法,同時還要兼顧技術創新、維度擴展、方法深度融合等問題,最終真正將數字資源聚合由理論轉向實際應用需要多學科、多領域、多維度、多視角、多方法的交叉融合。余厚強和邱均平[9]指出眾多替代計量指標處在離散狀態,不利于利益相關者對替代計量學的理解,也使得替代計量研究呈現非系統化特點。構建了學術成果影響力產生模型,發現了不同層次替代計量指標的轉化關系,并在每層增加了程度維度,使每個既有替代計量指標在整個分層體系中得到定位。總結了替代指標聚合的3種方法,指出數學處理的聚合強度最高。
(2)資源聚合的方法研究。郭少友和李慶賽[10]通過UMLS語義命題的抽取過程涉及淺層句法分析、概念映射、謂詞識別與語義命題生成等環節。兩種以UMLS語義命題為基礎的醫學信息資源聚合方法——用知識單元作為資源單位的聚合方法和用文檔關聯數據作為資源單位的聚合方法,其聚合結果分別是知識網絡和文檔網絡。邱均平和王菲菲[11]從共現與耦合的理論原理出發,著眼于計量學中共現與耦合方法在館藏資源聚合中的應用,從4個維角度探討了典型的八種館藏文獻資源聚合模式,串聯了資源與用戶之間的整個路徑。畢強等[12]在梳理基于語義的數字資源深度聚合研究現狀的基礎上,引入超網絡理論,分析數字資源超網絡中的語義關系類型,探討基于語義的數字資源超網絡深度聚合的流程和方法,總結基于語義的數字資源超網絡聚合的模式。王麗偉等[13]認為領域本體自身結構的復雜性和領域本體之間的異構性,使領域本體映射方法成為實現本體映射的難點之一。提出多領域本體映射與聚類理論模型,并以該模型為指導,選取藥物領域本體進行映射實例研究,提出了兩個領域本體之間映射的一種新方法,為數字資源的語義互聯提供新思路。
(3)資源聚合的深度研究。劉曉娟等[14]從語義網技術的視角探討了圖書館數字資源深度聚合對其資源利用的推動力。從本體和關聯數據技術出發,探索了圖書館的數字資源與外部資源在語義層次上進行深度聚合的過程,并對現有的數字資源深度聚合工具進行了調研。最后對圖書館數字資源深度聚合所面臨的挑戰及未來發展方向做了總結與展望。趙蓉英和柴雯[15]以計量分析中的耦合關系為例,探討了耦合關系的語義特性及其對數字資源深度聚合能力,提出了基于耦合關系的館藏數字資源語義化聚合模型,并進行實證研究。李勁等[16]針對“信息孤島”和“資源超載”在當今館藏數字資源建設中普遍存在的現象,提出了基于語義的館藏資源聚合模型,更好地滿足用戶的各種信息需求,進而提高了館藏資源的利用率。
(4)資源聚合的融合研究。馬鴻佳等[17]在對主題詞表、本體、關聯數據、文獻計量、分眾分類及社會網絡分析法進行特征及優劣勢分析的基礎上,從方法融合視角對數字資源聚合方法的融合趨向進行了歸總,并進一步梳理了方法融合的具體作用機理及應用領域,以拓展數字資源聚合方法融合研究的新方向。王偉和許鑫[18]在方法上綜合關聯數據聚合與分眾分類聚合的優勢,取其所長,試圖從宏觀與微觀上全面展現徽州文化數字資源的知識信息。同時在聚合內容上,實現內容來源多元化的徽州文化數據資源的關聯數據聚合,展示基于內容的多維度聚合。陳曉美等[19]從資源聚合方法的融合互補入手,在分析社會網絡分析和分眾分類法資源聚合的優劣勢基礎上,嘗試將社會網絡分析和分眾分類法結合起來,深入分析了兩者融合互補的機理,提出了實現兩者融合互補的主要方向。
(5)資源聚合的計量研究。王菲菲和邱均平[20]對計量分析與語義本體進行全面深入的類比分析,進而提出數字文獻資源計量語義化理論框架;對基于計量分析的語義化機理與模式進行分解闡述,進一步構建系統化的數字文獻資源計量語義化模型,該模型由數字文獻資源元數據構建、信息計量與統計分析、計量語義化分析、計量語義知識提取與發現、計量語義化應用五個模塊組成,具有易操作多功能、可擴展便推理、互操作廣應用等特點。王菲菲[21]從綜合發文與引文這兩個相互對應的角度,融合作者合作網絡分析、作者關鍵詞耦合分析、作者共被引分析、作者文獻耦合分析、作者互引網絡分析等方法,形成了一種綜合視角下的學術共同體與主題結構發現以及作者學術交流與貢獻影響力的比較分析框架,然后利用該思路對科學計量學這一領域進行探索研究;實現了科學計量學領域內核心作者所構成的不同層面的研究群體劃分以及主題結構發現,并利用社會網絡的中心性測度對他們在不同維度的影響力情況和綜合影響力進行了規范處理與測度分析,進而得出了該領域最有影響力的作者排序。
3 國外數字資源聚合研究現狀
3.1 數據來源及獲取
國外研究的數據源選擇湯森路透集團的Web of Science平臺進行文獻的搜集和整理,圍繞數字資源聚合及其在實施過程中可能涉及的Theory、Technology和Method等關鍵詞進行相關文獻的檢索、分析和獲取。為了實現這一目的,英文關鍵詞考慮到Aggregation、LinkData、Semantic、KnowledgeDiscovery、Bibliometric等。英文文獻檢索采用的檢索式為“TS=(“aggregation”) and TS= (“ information” or“ resource” or“data”) and TS= (“library”or“ontology”or“semantic*”or“knowledge organiz*”or“knowledge discover*”or“ co-occur*” or“ co-word*” or“ cite*” or“ citing”or“bibliometrics”or“informetrics”or“scientometrics”or“information retrieval”or“topmodel”or“LDA”) and文獻類型:(Article)”,共獲得核心合集相關文獻767篇。本研究對數據的清洗亦不同于以往數據結果的處理,保留了全部檢索結果。按照共詞分析的要求,按照純文本(TXT)格式輸出檢索結果數據。
3.2 共詞頻次統計分析
Web of Science平臺收錄的論文中除了由作者提供檢索詞外,還有湯森路透(Thomson Reuters)對作者的研究成果進行關鍵詞著錄,這兩類關鍵詞的標注均能揭示文章研究的關鍵詞,重點突出研究對象、研究方法、研究結果和研究領域。通過對關鍵詞的分析可以發現研究的主要結構布局和最重要的主題方向。運用共詞分析工具對上述294篇論文進行共詞分析(見表 2)。

表2 頻次大于5的英文關鍵詞分布
3.3 構建關鍵詞共詞圖譜
在繪制共詞關系時,未嚴格按照對頻次大于某一特定值的關鍵詞進行共詞分析,而是對所有符合條件的關鍵詞進行共詞分析(見圖2)。

圖2 相關外文文獻關鍵詞共現圖譜
共現關鍵詞的網絡結構圖譜從結構上看,96個關鍵詞分成了3個較為分明的版塊,分別是:主要集中區域,這一區域的研究成果多,共現關系復雜;較少關注區域,這個區域有2個獨立的孤立化呈現區域;獨立出現的關鍵詞。這3個版塊代表的研究領域不同,對于實際研究具有很好地指導作用。
3.4 共現關鍵詞圖譜分析
(1)研究成果集中的領域。現有研究成果較多的主要集中在如圖2橢圓標注的領域,這個領域的研究中涉及的關鍵詞有:“aggregation”(聚合)、“theory”(理論)、“web”(網絡)、“data”(數據)、“knowledge”(知識)、“ontology”(本體)、“information retrieve”(信息檢索)、“semantic”(語義)、“rank aggregation”(等級聚合)、“meta search”(元數據搜索)等。通過分析這些關鍵詞,發現目前國外對于資源聚合研究較多的集中在“資源聚合的理論”、“網絡資源聚合”、“數據聚合”、“知識聚合”、“知識發現”,資源聚合的方法主要有本體資源聚合方法、語義資源聚合”、“數字資源的等級聚合”,還有對資源聚合的“信息檢索”、“元數據檢索”等領域。在這些領域國外的研究成果較多,研究也相對成熟。數字資源聚合研究在國外注重理論和實踐兩個方面的研究,并取得了一定的成果,在實踐中也有了相關的應用。
(2)研究成果分散的領域。通過英文關鍵詞共現圖譜可知,國外相關研究除了集中在上述研究領域外,在以下領域也開展了研究,研究成果相對于集中研究區域較少,分別是:“link data”(關聯數據)、“acut coronari syndrome”(急性冠狀動脈綜合征)、“heart disea”(心臟病)、“antiplateletag”(抗血小板)、“myocardi revasular(心 肌 救 護)、“arrhythmiacardiac”(心律失常)、“drug therap”(藥物治療)、“anticoagul”(抗凝)、“coronary angiographi”(冠狀動脈造影)、“antiplateletag”(抗血小板聚集)、“coronari arterirevascular interventst”(科倫納動脈介入術的ST)等,這一區域的研究集中在醫學領域,目前在國外的相關研究中,醫學領域研究成果已集中了一定的規模,并與資源聚合形成了關聯關系。另外一個領域是蛋白的空間聚合。在國外相關研究中,資源研究的領域已有進一步拓寬。
(3)未揭示出的研究領域。雖然通過表2揭示出了共現關鍵詞的主要部分,但是由于受到詞頻數的限制,一些關鍵的共現關系并未揭示出來。這一研究領域主要的關鍵詞有:“digital library”(數字圖書館)、“cloud computer”(云計算)、“wireless sensor network”(無線傳感器網絡)、“textmin”(文本挖掘)、“map” (知識圖譜)、“web server”(網絡服務)、“semantic similar”(語義相似)、“datamining”(數據挖掘)、“cluster”(聚合)、“focus retrieve”(聚焦檢索)、“retrieve”(檢索)、“perform”(表現)、“relative database”(檢索數據庫)、“search”(檢索)、“evaluation”(評價)、“operation”(操作)、“hierarch structure”(等級結構)、“micro aggregation”(微聚合)、“language”(語種聚合)、“SmartWeb”(智能網)、“Retrieve”(檢索)等。其中,“wirelesssensornetwork”(無線傳感器網絡)和中文文獻中的研究相一致,但是研究成果同樣較少。
(4)孤立化呈現的關鍵詞。由于制作圖譜的過程中,并沒有去掉共現頻次較少的關鍵詞,所以在圖譜顯示中出現了孤立化的關鍵詞,這些領域主要涉及到“algebramultigrid”(代數多重網格)。在未來數字資源聚合的研究中有可能采用代數多重網格方法對資源進行聚合。
3.5 國外研究的主要內容
(1)資源聚合的理論研究。P.Kokkinos等[22]認為信息聚合是一種減少網格中信息的交換,便于資源管理和決策應用。當資源可被公共獲取時,可通過遍歷各個節點摘取詳細和敏感信息保存為私有信息。為了解決網格聚合的相關問題,設計了通用的信息聚合框架,提出了單點聚合和域聚合的關于靜態和動態信息資源的網格規則的主導技術,并討論了資源優化和選擇功能。聚合框架的測量是既通過對執行決策的效率和又通過減少它帶來的信息數量,并全面權衡。通過仿真證明合適的聚合框架可以顯著地減少信息和網格中信息交換。Vodel等[23]指出網絡產生大量的異構數據在動態變化的多通道無線傳感器中傳輸,特別是在無線低功耗的應用領域,能源效率和通信任務的優先級是關鍵。通過研究優化各自的硬件組成以及在物理層協議,MAC或網絡層處理這些問題。解決的關鍵是盡量減少數據傳輸量,同時又不降低信息質量,在數據融合領域提供了一個有效的數據處理技術。根據研究結果和相應的分析,提出了切實可行的數據聚合技術。
(2) 資源聚合的方法研究。VíctorFernáandez等[24]指出大數據狄拉克(DIRAC)是一種用大數據解決分布式基礎設施的遠程代理控制接入點。用戶可以獲得分散不同區域的大數據資源,通過運用狄拉克實現負載平衡。結果顯示了大數據狄拉克具有管理儲存在本地的Hadoop簇的系統文件的能力。大數據狄拉克可被用于收集可行性統計數據和執行的監控,從遠程上傳文件到Hadoop系統,結果存儲在機器中。大數據狄拉克可以有效地聚合資源。Kyungyong Lee等[25]提出了廣域資源發現的匹配樹方法。這種方法是建立在對等框架基礎之上,以提供可擴展和容錯資源發現。匹配樹方法利用一個自組織樹實施分布查詢處理和結果聚合。匹配樹本身相關的資源發現系統基于結構化的P2P,支持復雜的查詢(如匹配正則表達式),以及相關的非結構化P2P發現系統保證查詢的完整性。Hanane Zitouni等[26]提出了關于角色學習方法。該方法結合了協同過濾和電子學習的特點。一方面,當沒有明確的角色偏好基礎數據時,利用社區角色興趣聚合做一個初步的推薦。另一方面,借助于已有的基礎,通過元數據的描述對新學習資源進行推薦,其方法是通過計算的新資源的元數據和原有資源的元數據相似度來判斷角色感興趣的新資源,并進行推薦。
(3)資源聚合的效果研究。L.Canósa等[27]開發了一個柔性化的決策支持系統幫助管理者對用戶不同需求的決策定制功能。這一數據決策系統模仿專家使用平均順序權重方法,按照不同權重實現不同選擇標準的聚合操作,展示了一種基于按侯選項排序分析效率的聚合模型。P.Kokkinos等[28]提出了一種通過任務調度實現相關信息資源聚合方法。通過這種方法,可以統一表示一組資源的信息,同時減少在網格網絡中傳輸的信息量。描述了屬于同一層次的網格域的一系列信息資源聚合的技術。這些信息包括存放在中央處理器的存儲容量、隊列的任務數,以及其他資源的相關參數。聚合方法的質量會影響調度程序決策的效率。當任務執行時使用完整的資源信息,當任務延遲時,使用聚合方案。仿真實驗表明,所提出的聚合方案大大地減少了信息傳輸。
(4)資源聚合的過程研究。Gang Li等[29]針對無形網絡中有的大量有價值的信息資源存在卻難以使用的現狀,提出了一種稱為收割消息的系統,這是能夠使看不見的網絡變得可見,尤其是對于大量更新頻繁、時間敏感的實時信息。收割的方法是利用信息提取、文本分類、全文索引、RSS技術等聚合無形的網絡信息資源。分析了四種類型的無形網無形的原因,同時總結了無形網的特點。在此基礎上,建立了信息收割的結構體系。用校園招聘信息與通用搜索引擎測試相比驗證系統。隨著Web 2.0的興起,用戶生成的元數據或所謂的大眾分類便于萬維網管理數字內容。Ching-Chieh Kiu等[30]提出的分類和分眾分類算法有利于提高知識分類和導航。
(5)資源聚合成本的研究。Anass Nagih等[31]提出在資源消耗限制條件下尋找指定節點之間最小成本的路徑。用動態規劃算法求解其計算時間,計算時間隨資源數量的增加而增加。為此提出了一個啟發式解決方案,通過聚集資源的目標以減少狀態空間。Joel Cummings[32]通過EBSCO學術搜索對得到的菲沙河谷大學學院獲取全文內容的兩類全文列表比較研究。因為在菲沙河谷大學學院的工作人員和圖書館用戶依賴于這個數據庫的一部分館藏期刊,所以這項研究是比較全文內容的準確性。檢查館際互借工作人員經常使用學術搜索全文雜志列表是否可在學院的電子表格中獲取。從而發現從館際互借成本角度考慮,需要一個精確的圖書館電子期刊補充列表。
4 國內外數字資源聚合研究述評
從國內外相關研究成果的總體情況來看,與數字資源聚合直接相關的研究比較少。國外相關的研究最早起源于Bordogna G[33]提出一種軟化的硬布爾方案的信息檢索方法。在這種方法中,信息檢索是其中潛在的解決方案,即滿足條件的多準則決策活動,存檔的文件等都要求通過表達式檢索。每一個潛在的解決方案滿足由運營商匯總的信息需求匯總查詢具有整體的決策功能評估。語言量詞和連接器處理原發和可選的標準定義,并介紹了為查詢語言指定的單個查詢聚集標準要求。這些標準使得用戶可以用簡單的和自我解釋的方式來表達疑問。國內研究起源于何超和張玉峰[34]針對館藏數字資源深度開發與利用所存在的數字資源孤島問題和數字資源超載問題,構建了基于本體的館藏數字資源語義聚合與可視化模型。該模型利用本體提供的語義知識進行深層次的館藏數字資源語義聚合,解決數字資源孤島問題和數字資源超載問題;利用本體軟件提供的可視化插件將非空間數據轉換為視覺形式進行聚合結果展示,揭示館藏數字資源內部存在的錯綜復雜關聯和深層次內涵,加深館藏數字資源聚合結果的認知和理解。從國內外的相關研究可以總結為以下幾個方面。
4.1 理論研究與應用研究
國內外對于數字資源聚合研究的理論已向數據收集、信息整合、資源聚合和知識發現理論研究拓展。國外的相關研究主要集中在本體、語義數據、網絡、關聯數據、等級聚合、元數據檢索、聚合模型、聚合安全、等級結構、決策支持、語義網、不同語種間聚合、聚合結果、知識發現、數據聚合、信息檢索、模糊語言模型、聚合實驗、實證研究和各類系統,這些領域涉及到了數字資源聚合的各個方面,有理論、方法、應用等。國內的研究主要集中在信息聚合、圖書館、網絡信息資源、高校圖書館、館藏資源、RSS、數字圖書館、信息資源、語義網、本體、可視化、數字資源聚合、信息可視化、數據聚合、深度聚合、關聯數據、知識發現等。從國內外研究關注點來看各有不同,國外研究關注的范圍比較寬,國內研究關注的比較窄,但是都采用了關聯數據、本體、語義網等作為主要技術。值得一提的是,無論國內還是國外都在關注無線傳感器網絡的資源聚合。[35-36]
4.2 研究領域與應用領域
國外涉及的領域主要有生物領域和醫學領域,并且在這兩個研究領域的成果相對較多,兩個領域的各自成果之間的關鍵詞共現與耦合關系也比較明顯。國內的相關研究領域主要是集中在圖書情報檔案等文化服務領域,隨著這一主體領域研究成果的不斷豐富,理論體系不斷完善,應用不斷擴大,在海事部門、通訊部門、地理信息旅游業部門和報網行業引入了相關研究。[37]但是這幾個領域的研究比較分散,他們沒有與研究主體形成實質上的關聯關系,而且各自小領域的研究成果也不是很多。這一現象說明國內對于資源聚合的研究已滲透到多個領域,比國外的領域要廣泛,但是沒有國外研究成果豐富。從這點可以看出數字資源聚合的研究領域可以不斷拓展,特別是領域本體、關聯數據和語義網技術在不同領域的應用為領域應用資源聚合奠定了技術基礎。總體來看國外的相關研究應用比國內要成熟一些。
4.3 宏觀研究與微觀研究
從國內外相關研究總體涉及的關鍵詞詞頻、研究領域范圍的廣度等可以發現,國內外研究的側重點有所不同。國內研究注重于微觀對象的特性研究,研究數字圖書館或高校圖書館館藏資源聚合的比較多,對于網絡資源聚合研究的比較少,這與目前國內數字資源提供和利用情況密切相關。國外研究涉及的面比較廣泛,更接近于普適研究和宏觀研究,這與國外開展相關研究較早有密切關系。而國內相關研究是從2011年國家社科基金重大項目立項前后才開始進行的。從總體上看,國外研究具有分散集中的特點,在某個主題研究的比較深入,對于不同研究主題關聯關系的揭示較豐富,突出了數字資源聚合研究的深度延伸和廣度拓展的趨向。國內研究集中的主題比較少,其他主題與集中主題的關聯關系并不豐富和密切。但是研究的目的和所采用的方法具有共同點。
4.4 研究方向的發展趨勢
綜觀國內外相關研究可以發現,國內外積累了許多經驗,并取得了豐富的研究成果,但是研究理論體系尚不完善、理論和應用結合還不夠深入。目前,相關研究更多的聚焦在聚合的途徑和方法,對于聚合的結果處理以及可視化展示研究明顯不足;對于相關研究的實踐應用還停留在小范圍內的應用,并沒有形成大范圍的推廣;國內的數字資源來源渠道復雜,數據冗余量大,民族文獻數字化識別處理的復雜性等要求加劇了相關研究的難度。為此,數字資源聚合應從以下幾個方面進一步展開:① 理論研究,力求形成完整的理論體系;② 實證研究,進一步加強理論與實踐的結合研究,理論與應用的結合研究;③ 深刻理解和有效把握影響資源聚合的相關因素,如:資源聚合阻力、聚合摩擦、聚合粘度、聚合強度、聚合深度和聚合噪聲、聚合污染等。
[參考文獻]
[1]鄧君,陳麗君.國內外圖書館開源軟件研究現狀與展望[J].圖書情報工作,2015(14):135-142.
[2]王颯,包麗穎.基于文獻計量的共詞分析方法及應用述評[J].情報科學,2015(4):150-154.
[3]王小華,等.基于共詞分析的文本主題詞聚類與主題發現 [J].情報科學,2011(11):1621-1624.
[4]黃祖良.構筑平臺借外力借助外力保安全:江門海事局聚合社會資源解決海事監管難題[J].珠江水運,2009(11):56-57.
[5]高弋坤.聯通移動互聯應用產業峰會主打”開放牌”“Wo+開放體系”首次亮相談聚合[J].通信世界,2011(44):4.
[6]宋關福.Service GIS引發地理信息服務共享與聚合革命[J].地理信息世界,2008(6):82-85.
[7]湯代祿,韓建俊.基于報業信息網格的新聞信息聚合與挖掘[J].中國傳媒科技,2005(10):27-30.
[8]畢強,等.數字資源聚合的理論基礎及其方法體系建構 [J].情報科學,2015(1):9-14,24.
[9]余厚強,邱均平.替代計量指標分層與聚合的理論研究[J].圖書館雜志,2014(10):13-19.
[10]郭少友,李慶賽.以UMLS語義命題為基礎的醫學信息資源聚合[J].圖書情報工作,2014(3):99-105.
[11]邱均平,王菲菲.基于共現與耦合的館藏文獻資源深度聚合研究探析[J].中國圖書館學報,2013(3):25-33.
[12]畢強,等.基于語義的數字資源超網絡聚合研究 [J].情報科學,2015(3):8-12.
[13]王麗偉,等.領域本體映射的語義互聯方法研究——以藥物本體為例[J].圖書情報工作,2013(17):21-25,33.
[14]劉曉娟,等.語義網技術在圖書館數字資源深度聚合中的應用[J].圖書館雜志,2015(6):76-82.
[15]趙蓉英,柴雯.基于耦合關系的館藏數字資源語義化深度聚合研究[J].情報資料工作,2015(2):52-55.
[16]李勁,等.基于語義的館藏資源深度聚合方法研究[J].情報科學,2013(11):100-103.
[17]馬鴻佳,等.數字資源聚合方法融合趨勢研究[J].情報資料工作,2015(5):24-29.
[18]王偉,許鑫.融合關聯數據和分眾分類的徽州文化數字資源多維度聚合研究[J].圖書情報工作,2015(14):31-36,58.
[19]陳曉美,等.社會網絡分析法與分眾分類法融合機理研究 [J].情報資料工作,2015(5):11-17.
[20]王菲菲,邱均平.信息計量視角下的數字文獻資源語義化模型研究[J].情報資料工作,2015(4):62-69.
[21]王菲菲.發文與引文融合視角下的科學計量學領域核心作者影響力分析[J].科學學與科學技術管理,2014(12):45-55.
[22] Kokkinos P,Varvarigos E.Scheduling efficiency of resource information aggregation in grid networks[J].Future Generation Computer Systems,2012 (28) :9-23.
[23] VodelM,HardtW.Dataaggregation and data fusion techniques inWSN/SANET topologies-a critical discussion[C].IEEE Region 10 Conference(TENCON)-SustainableDevelopmentthrough Humanitarian Technology,2012:19-22.
[24] Víctor Fernández,et al.Federated big data for resource aggregation and load balancing with DIRAC[J].Procedia Computer Science,2015 (51):2769-2773.
[25] Kyungyong Lee,etal.Match tree:Flexible,scalable,and fault-tolerantwide-area resource discovery with distributed matchmaking and aggregation [J].Future Generation Computer Systems, 2013 (29):1596-1610.
[26] HananeZitouni,LlamiaBerkaniandOmarNouali.Recommendation of learning resourcesand usersusingan aggregation-based approach[C].2012 IEEE Second InternationalWorkshop on Advanced Information SystemsforEnterprises,2012:57-63.
[27] Canósa L,Liernb V.Softcomputing-based aggregation methods for human resourcemanagement[J].European JournalofOperationalResearch,2008 (189):669-681.
[28] KokkinosP,VarvarigosE.Resource information aggregation in hierarchicalgrid networks[C].9th IEE E/ACM InternationalSymposium on Cluster Computing and theGrid,IEEEComputerScience,2009:268-275.
[29] Gang Li,GuangzengKou.Aggregation ofinformation resourceson the invisibleweb[C].Second International Workshop on Knowledge Discovery and Data Mining,IEEEComputerSociety,2009:773-776.
[30] Ching-Chieh Kiu,Eric Tsui.Taxo folk:A hybrid taxonomy folksonomy structure for knowledge classi fication and navigation [J].Expert Systemswith Applications,2011 (38):6049-6058.
[31] AnassNagih,FrancζoisSoumis.Nodalaggregationof resourceconstraintsinashortestpath problem [J].European Journal of Operational Research,2006,172(2):500-514.
[32] Joel Cummings.Full-Text aggregation:An examinationmetadata accuracy and the implications for resourcesharing[J].SerialsReview,2003,29(1):11-15.
[33] Bordogna G,Pasi G.An ordinal information retrievalmodel[J].International JournalofUncertainty Fuzzinessand Knowledge-based Systems,2001,9(S):63-75.
[34]何超,張玉峰.基于Web鏈接挖掘的館藏資源語義聚合與可視化展示研究[J].情報科學,2015(2):115-120.
[35]張強,等.基于分簇的無線傳感器網絡數據聚合方案研究[J].傳感技術學報,2010(12):1778-1782.
[36]葉寧,王汝傳.基于蟻群算法的無線傳感器網絡數據聚合路由算法[J].南京郵電大學學報(自然科學版),2008(2):63-68.
[37]劉菲,楊興鋒.南方報業的聚合戰略[J].新聞與寫作,2011(4):49-50.
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
開放教育研究(2020年2期)2020-03-31 01:54:14
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
資源再生(2017年3期)2017-06-01 12:20:59
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
