面向動畫自動生成的中文短信關(guān)系抽取①
2018-04-20 01:16:26李笑妃
計算機(jī)系統(tǒng)應(yīng)用 2018年3期
李笑妃
(北京工業(yè)大學(xué) 信息學(xué)部,北京 100124)
1 引言
在審視了手機(jī)短信和3G通信技術(shù)的發(fā)展現(xiàn)狀后,中科院張松懋研究員于2008年提出將3D動畫自動生成技術(shù)應(yīng)用在手機(jī)短信上的想法,即將發(fā)送的中文短信經(jīng)系統(tǒng)處理分析后生成的3D動畫發(fā)送給接收方,命名為全過程計算機(jī)輔助手機(jī)3D動畫自動生成系統(tǒng)[1](簡稱為手機(jī)3D動畫自動生成系統(tǒng)). 處理過程大致分為四個階段,短信信息抽取,情節(jié)定性規(guī)劃,場景定量規(guī)劃,網(wǎng)絡(luò)渲染. 手機(jī)3D動畫自動生成技術(shù)將動畫自動生成技術(shù)應(yīng)用于中文手機(jī)短信領(lǐng)域,不僅立足于一個嶄新的應(yīng)用角度,并嘗試研究和解決過程中出現(xiàn)的問題,這在人工智能領(lǐng)域具有一定的研究意義和價值.
信息抽取處于手機(jī)3D動畫自動生成系統(tǒng)首要和關(guān)鍵的位置,而實體關(guān)系抽取作為信息抽取領(lǐng)域的重要研究課題[2],其主要目的是抽取句子中已標(biāo)記實體對之間的語義關(guān)系,即在實體識別的基礎(chǔ)上確定無結(jié)構(gòu)文本中實體對之間的關(guān)系類別,并形成結(jié)構(gòu)化的數(shù)據(jù)便于存儲和取用,例如,輸入一個帶有標(biāo)記實體的句子“< e1 > 曹德旺< /e2 > 任< e2 > 福耀玻璃集團(tuán)< /e2 > 董事長,是一名優(yōu)秀的中國民營企業(yè)家. ”,實體關(guān)系抽取系統(tǒng)能自動識別實體“曹德旺”和“福耀玻璃集團(tuán)”的關(guān)系是雇傭關(guān)系.
關(guān)系抽取技術(shù)對自然語言處理的許多應(yīng)用如本體構(gòu)建、自動文摘、自動問答、知識庫構(gòu)建等具有重要的意義. 傳統(tǒng)的關(guān)系抽取依賴于定義好的關(guān)系類型體系,如定義的雇傭關(guān)系、整體部分關(guān)系、位置關(guān)系等.目前的一系列研究也主要是圍繞內(nèi)容自動抽取會議(ACE)所設(shè)計的任務(wù)展開,所抽取的關(guān)系類型一般也同ACE定義的一致.
1998 年,美國國防高級研究計劃委員會(Defense Advanced Research Project Agency,DARPA) 資助的最后一屆消息理解會議(Message Understanding Conference,MUC) 首次引入了實體關(guān)系抽取任務(wù).1999 年,美國國家標(biāo)準(zhǔn)技術(shù)研究院(National Institute of Standards and Technology,NIST) 組織了自動內(nèi)容抽取(Automatic Content Extraction,ACE)評測,其中的一項重要評測任務(wù)就是實體關(guān)系識別[3]. 與MUC相比,ACE的實體關(guān)系語料的語種數(shù)量和數(shù)據(jù)規(guī)模都有了大幅度的增加. ACE 2008 的關(guān)系抽取任務(wù)共定義了Agent-Artifact、General-Affiliation、Metonymy、Organization-Affiliation、Part-Whole、Person-Social、Physical 7 個大類的實體關(guān)系,細(xì)分為User-Owner-Inventor-Manufacturer、Citizen-Resident-Religion-Ethnicity、Organization-Location等18 個子類的實體關(guān)系[4]. SemEval (Semantic Evaluation) 是繼MUC、ACE后信息抽取領(lǐng)域又一重要評測會議,該會議吸引了大量的院校和研究機(jī)構(gòu)參與測評. SemEval-2007 的評測任務(wù)4 定義了7 種普通名詞或名詞短語之間的實體關(guān)系,但其提供的英文語料庫規(guī)模較小. 隨后,SemEval-2010 的評測任務(wù)8 對其進(jìn)行了豐富和完善,將實體關(guān)系類型擴(kuò)充到9 種,分別是: Component-Whole、Instrument-Agency、Member-Collection、Cause-Effect、Entity-Destination、Content-Container、Message-Topic、Product-Producer和 Entity-Origin. 考慮到句子實例中實體對的先后順序問題,引入“Other”類對不屬于前述關(guān)系類型的實例進(jìn)行描述,共生成19種實體關(guān)系. SemEval-2010 評測引發(fā)了普通名詞或名詞短語間實體關(guān)系抽取研究的新高潮[5].
本文在句法語義分析的基礎(chǔ)上對中文短信文本進(jìn)行關(guān)系抽取,針對于手機(jī)3D動畫系統(tǒng)對動畫的表現(xiàn)情況將關(guān)系分為4種,包括: 顏色關(guān)系、形態(tài)關(guān)系、描述關(guān)系、位置關(guān)系,如短信“我想吃紅蘋果”,經(jīng)過本文處理得到“蘋果”和“紅”屬于顏色關(guān)系; 短信“雨下的真大啊”經(jīng)處理后得到“雨”和“大”屬于形態(tài)關(guān)系,形態(tài)關(guān)系即表示物體的大小、長短等的描述; 短信“我的心情很好; ”經(jīng)本文處理得到“心情”和“好”這樣的描述關(guān)系. 由于前三種關(guān)系可以同屬于描述類型,所以前三種關(guān)系用同一語料庫進(jìn)行訓(xùn)練,得到同一規(guī)則集,只是在用規(guī)則集進(jìn)行關(guān)系抽取的過程中細(xì)分為了三種關(guān)系. 短信“我書包在床上”,經(jīng)本文處理后得到“書包”和“床上”屬于位置關(guān)系. 位置關(guān)系單獨標(biāo)注,單獨訓(xùn)練.
2 相關(guān)研究
2.1 實體關(guān)系抽取技術(shù)
在傳統(tǒng)的語義關(guān)系抽取中,實體與實體之間的關(guān)系是預(yù)先定義好的. 在關(guān)系抽取中先后出現(xiàn)了基于規(guī)則的方法,其中有基于ontology實現(xiàn)信息抽取中的關(guān)系抽取[6],取得比較不錯的效果. 隨著機(jī)器學(xué)習(xí)的發(fā)展,人們將關(guān)系抽取看成一個分類問題,首先標(biāo)出句子中的實體,然后通過一個分類器判斷實體對之間的關(guān)系.目前,有監(jiān)督學(xué)習(xí)方法是最基本的實體關(guān)系抽取方法,其主要思想是在已標(biāo)注的訓(xùn)練數(shù)據(jù)的基礎(chǔ)上訓(xùn)練模型,然后對測試數(shù)據(jù)的關(guān)系類型進(jìn)行識別. 有監(jiān)督學(xué)習(xí)方法包括基于特征的方法、基于核函數(shù)的方法[7]和基于規(guī)則的方法.
基于特征向量的方法是一種簡單、有效的實體關(guān)系抽取方法,其主要思想是從關(guān)系句子實例的上下文中提取有用信息(包括詞法信息、語法信息)作為特征,構(gòu)造特征向量,通過計算特征向量的相似度來訓(xùn)練實體關(guān)系抽取模型. 該方法的關(guān)鍵在于尋找類間有區(qū)分度的特征,形成多維加權(quán)特征向量,然后采用合適的分類器進(jìn)行分類. 文獻(xiàn)[8]在詞法特征、實體原始特征的基礎(chǔ)上,融入依存句法關(guān)系、核心謂詞、語義角色標(biāo)注等特征,實驗結(jié)果表明該方法能有效提高實體關(guān)系抽取的性能.
基于核函數(shù)的實體關(guān)系抽取方法不需要構(gòu)造特征向量,而是把結(jié)構(gòu)樹作為處理對象,通過計算它們之間的相似度來進(jìn)行實體關(guān)系抽取. 在基于核函數(shù)的中文實體關(guān)系抽取研究方面,劉克彬[9]利用卷積核函數(shù)中的字符串序列核進(jìn)行實體關(guān)系抽取,并借用《知網(wǎng)》中的詞匯語義相似度計算方法計算中文特征詞串的相似度,實驗結(jié)果表明其F值達(dá)到了84%,這也說明語義信息能提高中文語義關(guān)系抽取系統(tǒng)的性能.
基于規(guī)則的方法需要對待處理語料通過人工或機(jī)器學(xué)習(xí)的方法總結(jié)歸納出相應(yīng)的規(guī)則或模板[10],然后采用規(guī)則或模板匹配的方法進(jìn)行實體關(guān)系抽取. 近年來,實體關(guān)系抽取研究者構(gòu)建了多個基于規(guī)則的實體關(guān)系抽取系統(tǒng)[11,12].
機(jī)器學(xué)習(xí)中規(guī)則歸納即“規(guī)則學(xué)習(xí)”是從訓(xùn)練數(shù)據(jù)中學(xué)習(xí)出一組能用于對未見實例進(jìn)行判別的規(guī)則. 與神經(jīng)網(wǎng)絡(luò)、支持向量機(jī)這樣的“黑箱模型”相比,規(guī)則學(xué)習(xí)具有更好的可解釋性,能使用戶更直觀地對判別過程有所了解. 另外,數(shù)理邏輯具有極強(qiáng)的表達(dá)能力,絕大多數(shù)人類知識都能通過數(shù)理邏輯進(jìn)行簡潔的刻畫和表達(dá). 如: “爸爸的爸爸是爺爺”這樣的知識不易用函數(shù)式描述,而用一階邏輯可以方便的寫成“爺爺(X,Y)← 爸爸 (X,Z)∧爸爸 (Z,Y)”. FOIL (First-Order Inductive Learner)[12]是著名的規(guī)則學(xué)習(xí)算法,首次由Quinlan在1993年提出,該算法分為正例和負(fù)例提取規(guī)則,FOIL算法采用信息增益來提取最好的一個屬性值生成規(guī)則,而且一次只生成一條規(guī)則,再生成規(guī)則之后,將被規(guī)則覆蓋的訓(xùn)練集刪除,繼續(xù)從剩余的訓(xùn)練集中尋找最好的屬性值. 因為它是把命題規(guī)則學(xué)習(xí)過程通過變量替換等操作直接轉(zhuǎn)化為一階規(guī)則學(xué)習(xí)的,因此比一般的歸納邏輯程序設(shè)計技術(shù)更高效. 文獻(xiàn)[13]結(jié)合了Apriori算法和FOIL算法實現(xiàn)文本分類,準(zhǔn)確率達(dá)到了99%.
2.2 句法、語義分析
句法分析[14]將句子由一個線性序列轉(zhuǎn)化為一棵結(jié)構(gòu)化的依存分析樹,通過依存弧上的關(guān)系標(biāo)記反映句子中詞匯之間的句法關(guān)系. 與短語結(jié)構(gòu)相比,句法結(jié)構(gòu)具有形式簡潔、易于標(biāo)注、便于應(yīng)用等優(yōu)點,逐漸受到學(xué)術(shù)界和工業(yè)界的重視. 語義分析默認(rèn)要建立在句法分析的基礎(chǔ)上,中文的句法是從西方引進(jìn)來的,而中文嚴(yán)重缺乏形態(tài)的變化,詞類與句法成分沒有嚴(yán)格的對應(yīng)關(guān)系,導(dǎo)致中文句法分析的精度始終上不去. 目前LTP-Cloud已經(jīng)聯(lián)合北京城市學(xué)院標(biāo)注了1萬句中文語義依存分析樹[15],且已經(jīng)有初步的實驗結(jié)果. 如句子“男孩跑步,女孩跳舞”得到的句法分析與語義分析分別如圖1和圖2所示,所以為了提高關(guān)系抽取的準(zhǔn)確率,本文采用句法分析與語義分析相結(jié)合的方式進(jìn)行訓(xùn)練與測試.

圖1 句法分析示例
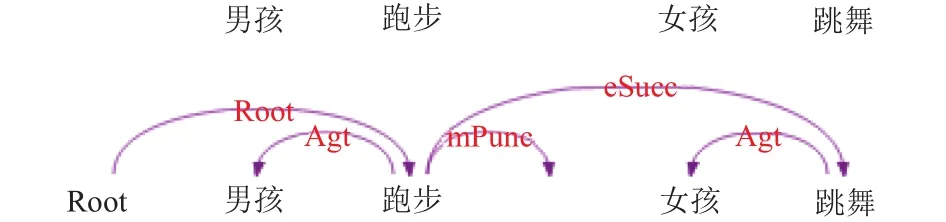
圖2 語義分析示例
2.3 同義詞詞林
《同義詞詞林》是一部漢語分類詞典,其中每一條詞語都用一個編碼來表示其語義類別. 本文所用的《同義詞詞林》為《同義詞詞林(擴(kuò)展版)》,是哈爾濱工業(yè)大學(xué)信息檢索研究室在《同義詞詞林》的基礎(chǔ)上研制的. 最終的詞表包含77 429條詞語,其中一詞多義的詞語為8860個,共分為12個大類,94個中類,1428個小類,小類下再以同義原則劃分詞群,最細(xì)的級別為原子詞群,這樣詞典中的詞語之間就體現(xiàn)了良好的層次關(guān)系. 不同級別的分類結(jié)果可以為自然語言處理提供不同顆粒度的語義類別信息,《同義詞詞林》語義信息能顯著提高中文關(guān)系抽取的性能,文獻(xiàn)[16]就是根據(jù)《同義詞詞林》完成了實體關(guān)系抽取,最高F值達(dá)到81.8%.
3 本文的方法
3.1 基本流程
LTP-Cloud是由哈爾濱工業(yè)大學(xué)社會計算與信息檢索研究中心研發(fā)的云端自然語言處理服務(wù)平臺. 后端依托于歷時10年形成的語言技術(shù)平臺,語言云為用戶提供了包括分詞、詞性標(biāo)注、依存句法分析、命名實體識別、語義角色標(biāo)注、語義依存分析在內(nèi)的豐富高效的自然語言處理服務(wù)[17]. 本文在哈爾濱工業(yè)大學(xué)LTP-Cloud平臺的基礎(chǔ)上,對語料進(jìn)行初步處理,獲取含有句法語義分析的XML文檔,對XML文檔進(jìn)行特征路徑的提取,然后經(jīng)過一階歸納學(xué)習(xí)器進(jìn)行訓(xùn)練,得到匹配規(guī)則. 最后通過規(guī)則進(jìn)行預(yù)測,得到關(guān)系抽取結(jié)果,并對實驗結(jié)果評估. 具體過程如圖3所示. 下面章節(jié)將對主要過程進(jìn)行詳細(xì)介紹.

圖3 基于句法語義分析的關(guān)系抽取過程
3.2 路徑特征形式化表示
短信中的實體本身以及實體之間有多方面的屬性,每一個屬性刻畫的信息可以將關(guān)系組合的具體化,所以關(guān)系抽取問題可以轉(zhuǎn)化成路徑特征組合問題,從短信文本中抽取出關(guān)于實體的路徑特征,然后使用一階歸納學(xué)習(xí)器的思想來組合這些路徑特征.
比如短信“黃色的蘋果”,經(jīng)過LTP-Cloud處理后得到如圖4所示結(jié)果.

圖4 LTP-Cloud處理結(jié)果示意
帶標(biāo)記的路徑提取結(jié)果為:
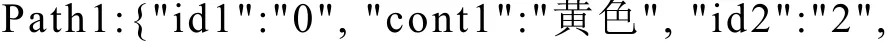

Path1-Path3表示短信各個分詞實體之間的關(guān)系以及實體本身的性質(zhì),path1 表示“黃色”詞性是“n”,“蘋果”詞性是“n”; “黃色”與“蘋果”之間的句法關(guān)系是“ATT”,語義關(guān)系是“Feat”; “id1”和“id2”分別表示實體在XML結(jié)果中的位置,是一種唯一性標(biāo)識. 如果把實體“黃色”、“蘋果”等變量替換成對應(yīng)的詞性,則得到帶標(biāo)記的路徑path1-path3泛化后的結(jié)果F1-F3即為路徑特征.

同樣對于短信“我看見有紅色的蘋果”得到帶標(biāo)記的路徑為:

泛化后的路徑特征為:


可以看到第一條短信的F1與第二條短信的F4是一樣的,并且F1與F4所對應(yīng)的帶標(biāo)記的路徑path1與path4就是表示顏色關(guān)系的實體對的組合. 所以(n,n,n,n,ATT,Feat) 可以作為一條匹配規(guī)則.
3.3 規(guī)則獲取
3.3.1 規(guī)則學(xué)習(xí)算法
類似于一階歸納學(xué)習(xí)器FOIL,使用從一般到特殊的策略來組合路徑特征,與FOIL不同的是,在學(xué)習(xí)規(guī)則的時候,不以單個實體作為規(guī)則中的基本單位,而是以路徑特征為基本單位. 規(guī)則獲取算法流程如下.
算法. 規(guī)則獲取(Acquire Rules)
Input: Training Set D=P∪N,P: positive dataset,N: negative dataset
Output: Mapping rules set R for D
1. Rule R←Φ
2. While |P|>min_message do
3. Selected path feature set Sf←Φ
4. P′←P N′←N
7. for message a∈P′ do
5. while |N′|>0 and r.length<Maxrule.length do
6. Candidate path feature Sp←Φ SN←Φ
8. and fato Sp
9. end for
10. for message b∈N′ do
11. and fbto Sp
14. Computer FoilGain of f
12. end for
13. for path feature f∈Spdo
15. end for
16. find feature foptfrom Spwith maximum FoilGain
17. add foptto Sf
19. end while
18. remove from P′、N′ all example not satisfied fopt
20. get rule r from Sfand add r to R
21. remove all the message that satisfied r from P
22. end while
其中第3-20行描述了如何通過組合路徑特征來學(xué)習(xí)匹配規(guī)則. 首先目標(biāo)特征路徑集合Sf初始化為空集,正負(fù)訓(xùn)練數(shù)據(jù)集P和N分別初始化為P′和N′; 再通過最大信息增益值獲取當(dāng)前最優(yōu)路徑特征,并把選擇的特征fopt添加到特征集合Sf中,循環(huán)該過程直到N′為空,即選擇的路徑特征組合沒有匹配到N′中的短信; 在內(nèi)層循環(huán)中第5-19行,當(dāng)N′為空時結(jié)束,得到一條規(guī)則,然后刪除所有的P′中的匹配短信,當(dāng)N′不為空時加特征進(jìn)行路徑特征組合,直到N′為空為止.
FoilGain即為信息增益,可以度量當(dāng)前路徑特征集合Sf添加路徑特征后所增加的信息量. 假設(shè)Sf是當(dāng)前選擇的路徑特征集合,|P|和|N|分別表示數(shù)據(jù)集中滿足Sf的正例與反例的個數(shù),如果添加一個新的路徑特征f,路徑特征集合變成Sf′,使得Sf′的正例個數(shù)和反例個數(shù)變成|P′|和|N′|則添加路徑特征f后獲得的信息增益是:
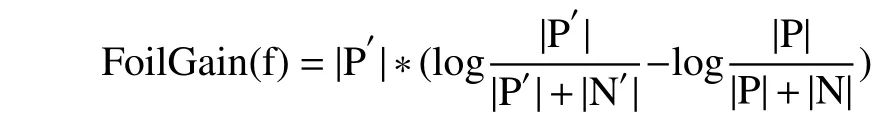
信息增益值最大的被選擇加入到路徑特征集合Sf中,路徑特征組成的集合則構(gòu)成了一條關(guān)系抽取規(guī)則.
4 實驗結(jié)果與分析
4.1 實驗結(jié)果評價指標(biāo)
根據(jù)手機(jī)3D動畫自動生成系統(tǒng)的表現(xiàn)能力將關(guān)系抽取分為顏色關(guān)系、位置關(guān)系、形態(tài)關(guān)系和描述關(guān)系四種,由于本文將關(guān)系抽取過程看作是分類的過程,所以這里的評價方式也采用常規(guī)的準(zhǔn)確率P、召回率R和F值. 準(zhǔn)確率使針對預(yù)測結(jié)果而言的,它表示的是預(yù)測為正的樣本中有多少是真正的正樣本. 公式表達(dá)如下:
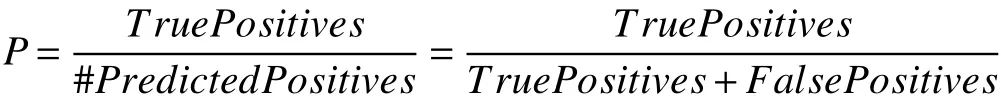
召回率是針對原來的樣本而言的,它表示的是樣本中的正例有多少被預(yù)測正確. 公式表達(dá)如下:

由于R和P指標(biāo)有時候會出現(xiàn)矛盾的情況,這樣就需要綜合考慮他們,最常見的方法就是F值,通過計算F值來評價結(jié)果,常見的F計算方法如下:

4.2 實驗設(shè)計
本文用同樣的設(shè)計方案對有無借助語義分析結(jié)果兩種情況做對比實驗,如下文所示.
4.2.1 訓(xùn)練實驗設(shè)計
本文的關(guān)系抽取包括顏色關(guān)系、形態(tài)關(guān)系、描述關(guān)系、位置關(guān)系四部分,考慮到符合前三者關(guān)系的短信中路徑特征相同,所以將顏色關(guān)系、形態(tài)關(guān)系和描述關(guān)系結(jié)合在一起進(jìn)行規(guī)則學(xué)習(xí),而位置關(guān)系則單獨處理.
使用Java語言實現(xiàn)了本文中的規(guī)則獲取算法考,慮到手機(jī)3D動畫自動生成系統(tǒng)處理的文本短小精悍,包羅萬象,所以語料庫主要來自三個方面:
(1) 手機(jī)3D動畫自動生成系統(tǒng)歷來的測試短信,經(jīng)處理去重隨機(jī)抽取1000條文本.
(2) 北京郵電大學(xué)處理后的10萬條短信中提取8000條.
(3) 1998年1月份《人民日報》隨機(jī)提取4000條句子.
其中表示顏色關(guān)系、位置關(guān)系和描述關(guān)系的短文本有8546條,表示位置關(guān)系的短文本有1697條. 使用LTP-Cloud對短文本進(jìn)行預(yù)處理,從中提取出路徑特征,用規(guī)則學(xué)習(xí)算法進(jìn)行學(xué)習(xí). 考慮到算法復(fù)雜度以及文本的特點,需要對路徑特征組合的最大長度做出限制,多次試驗最終把最大長度設(shè)置為8,即規(guī)則包含的路徑特征個數(shù)最大為8.
4.2.2 測試實驗設(shè)計
同樣使用Java語言設(shè)計實現(xiàn)測試系統(tǒng),該測試系統(tǒng)即為關(guān)系抽取系統(tǒng),該系統(tǒng)通過匹配規(guī)則集可以抽出短信中包含的關(guān)系以及關(guān)系組合. 系統(tǒng)主要分兩個部分,第一部分是顏色關(guān)系、形態(tài)關(guān)系、描述關(guān)系的抽取,本文把這三種關(guān)系統(tǒng)稱為描述型關(guān)系,第二部分是位置關(guān)系的抽取. 測試預(yù)料主要來自兩方面,一方面是手機(jī)3D動畫自動生成系統(tǒng)中除去訓(xùn)練集的部分短信300條,另一方面是北京郵電大學(xué)10萬條短信中抽取的550條,總共850條短文本.
描述型關(guān)系抽取過程如圖5所示,在顏色關(guān)系與形態(tài)關(guān)系的抽取過程中,需結(jié)合《同義詞詞林(擴(kuò)展版)》獲取表示顏色和形態(tài)的類別,同時得到該類別下的所有詞群. 如果帶標(biāo)記的路徑中所包含的實體能夠在詞群中找到所對應(yīng)的原子,則表示短信中含有顏色關(guān)系或者位置關(guān)系,然后結(jié)合帶標(biāo)記的路徑推導(dǎo)出相應(yīng)的關(guān)系組合; 否則可判定為描述關(guān)系,同樣結(jié)合帶標(biāo)記的路徑抽取出描述關(guān)系的組合. 與描述型關(guān)系抽取過程類似,位置關(guān)系的抽取首先是進(jìn)行規(guī)則匹配,得到帶標(biāo)記的路徑,然后再根據(jù)帶標(biāo)記的路徑分析結(jié)果,找到關(guān)系組合.

圖5 描述性關(guān)系抽取過程
4.3 實驗結(jié)果
本文根據(jù)不同的路徑特征進(jìn)行對比實驗,分析借助語義分析后的關(guān)系抽取效果. 通過訓(xùn)練實驗得到借助語義分析的描述型關(guān)系的規(guī)則集條數(shù)為126條,未借助語義分析的規(guī)則集條數(shù)為103條,位置關(guān)系的規(guī)則學(xué)習(xí)也得到兩個數(shù)據(jù)24條與32條,表1為得到的描述型關(guān)系與位置關(guān)系規(guī)則集示例.

表1 規(guī)則集示例
短信“看見桌子上有紅色蘋果和大西瓜,心情好呀”,通過帶語義分析的規(guī)則匹配,得到如圖6所示的IE輸出結(jié)果結(jié)果. 其中的Relation標(biāo)簽下的文本是本文關(guān)系抽取結(jié)果的結(jié)構(gòu)化表示形式. 短信包含有四種關(guān)系,其中顏色關(guān)系有兩個組合一個是“蘋果“與”紅”,表示形態(tài)關(guān)系的標(biāo)簽為Form,關(guān)系組合為“西瓜”與“大”; “心情”與“好”構(gòu)成描述關(guān)系的組合; 最后一條Location表示的是位置關(guān)系,即“蘋果; 西瓜”與“桌子上”構(gòu)成位置關(guān)系組合,表示前者的位置是“桌子上”.通過這些關(guān)系輸出可以為手機(jī)3D動畫系統(tǒng)提供可供動畫表現(xiàn)的信息,比如可以刻畫水果的顏色與大小,還能對物體出現(xiàn)在動畫中的位置做出規(guī)劃. 圖7(a)與圖7(b)即為手機(jī)3D動畫自動生成系統(tǒng)生成在關(guān)系處理前和處理后的動畫截圖,由圖7(b)可以看出蘋果是紅色的,并且在桌子; 西瓜也在桌子上. 表現(xiàn)了位置關(guān)系和顏色關(guān)系,更能表現(xiàn)短信所要表達(dá)的內(nèi)容. 并對預(yù)測結(jié)果進(jìn)行評估得到表2的評估結(jié)果. 另外,文獻(xiàn)[18]所提出的中文實體關(guān)系抽取方法是中文實體關(guān)系抽取領(lǐng)域較為經(jīng)典的方法之一,本文將關(guān)系分成兩類描述性關(guān)系與位置關(guān)系,同時變成了二分類問題. 將本文的基于語義分析的實驗結(jié)果與文獻(xiàn)[18]的研究結(jié)果進(jìn)行了比較得到圖8所示對比圖.

表2 實驗評估結(jié)果(單位: %)

圖6 短信關(guān)系抽取結(jié)果示例

圖7 手機(jī)3D動畫生成系統(tǒng)最終動畫截圖
4.4 結(jié)果分析
分析上述結(jié)果可以看出,本文所述方法在借助語義分析情況下顏色關(guān)系和形態(tài)關(guān)系抽取方面準(zhǔn)確率比較高,原因是在關(guān)系抽取過程中結(jié)合了《同義詞詞林(擴(kuò)展板)》,從而囊括了顏色與形態(tài)的幾乎所有情況,并且表示顏色和形態(tài)的實體詞詞性也比較單一,主要是名詞或者形容詞,所以準(zhǔn)確率比較高. 而位置關(guān)系抽取效果相對較差,召回率低,只有65%,造成這種情況的原因一方面是位置關(guān)系訓(xùn)練語料庫規(guī)模比較小; 另一方面是表示短文本的路徑特征的選取以及路徑特征間的順序不太合適; 再一方面就是在對語料庫的結(jié)果標(biāo)注存在很大的人為因素. 考慮到目前手機(jī)3D動畫自動生成系統(tǒng)的表現(xiàn)能力,關(guān)系抽取主要要求準(zhǔn)確率高.在使用經(jīng)典關(guān)系抽取算法得到的結(jié)果中,可以看出在手機(jī)3D動畫自動生成系統(tǒng)中,本文的方法取得了比較不錯的結(jié)果,可以應(yīng)用到目前的手機(jī)3D動畫系統(tǒng)中.

圖8 實驗結(jié)果對比圖
5 總結(jié)
本文研究的主要內(nèi)容是首次在手機(jī)3D動畫信息抽取系統(tǒng)中添加關(guān)系抽取. 提出了一種基于規(guī)則學(xué)習(xí)的短文本關(guān)系抽取方法. 首先結(jié)合手機(jī)3D動畫自動生成系統(tǒng),定義了顏色關(guān)系、形態(tài)關(guān)系、描述關(guān)系和位置關(guān)系四種類型,然后在句法、語義分析的基礎(chǔ)上,通過一階規(guī)則學(xué)習(xí)算法獲取關(guān)系抽取的規(guī)則集,測試集通過匹配規(guī)則集得到關(guān)系類型并抽取出對應(yīng)的關(guān)系組合,最后以結(jié)構(gòu)化的形式將關(guān)系輸出到信息抽取結(jié)果中,為手機(jī)3D動畫系統(tǒng)提供更多可供動畫表現(xiàn)的信息.
本文的研究是在句法分析、語義分析的基礎(chǔ)上進(jìn)行的,研究對象是中文的短文本,而目前中文的語義分析效果還不是很理想,這就降低了關(guān)系抽取的準(zhǔn)確率.另外,人為標(biāo)注語料庫存在很大的局限性和主觀性,限制了語料庫的規(guī)模,質(zhì)量也不高,進(jìn)而影響規(guī)則的學(xué)習(xí).針對以上不足,在后續(xù)關(guān)系抽取的研究過程中,需要充分利用自然語言處理的最新研究成果,實現(xiàn)自動化或半自動化標(biāo)注語料庫,提高關(guān)系抽取的準(zhǔn)確率.
1吳中彪. 全過程計算機(jī)輔助手機(jī)3D動畫自動生成系統(tǒng)的設(shè)計與實現(xiàn)[碩士學(xué)位論文]. 北京: 北京工業(yè)大學(xué),2011.11-38.
2陳宇,鄭德權(quán),趙鐵軍. 基于Deep Belief Nets的中文名實體關(guān)系抽取. 軟件學(xué)報,2012,23(10): 2572-2585.
3http://www.ldc.Upupenn.edu/Projects/ACE/.
4Chan YS,Roth D. Exploiting background knowledge for relation extraction. Proceedings of the 23rd International Conference on Computational Linguistics. Beijing,China.2010. 152-160.
5Hendrickx I,Kim SN,Kozareva Z,et al. SemEval-2010 task 8: Multi-way classification of semantic relations between pairs of nominals. Proceedings of the Workshop on Semantic Evaluations: Recent Achievements and Future Directions.Boulder,CO,USA. 2009. 94-99.
6Chen GC,Zhao JY,Cohen T,et al. Using ontology fingerprints to disambiguate gene name entities in the biomedical literature. Database,2015,(2015): bav034.
7王敏. 基于多代理策略的中文實體關(guān)系抽取[碩士學(xué)位論文]. 大連: 大連理工大學(xué),2011. 1-55.
8郭喜躍,何婷婷,胡小華,等. 基于句法語義特征的中文實體關(guān)系抽取. 中文信息學(xué)報,2014,28(6): 183-189.
9劉克彬,李芳,劉磊,等. 基于核函數(shù)中文關(guān)系自動抽取系統(tǒng)的實現(xiàn). 計算機(jī)研究與發(fā)展,2007,44(8): 1406-1411.
10Du XZ,Doermann D,Abd-Almageed W. Signature matching using supervised topic models. Proceedings of the 22nd International Conference on Pattern Recognition. Stockholm,Sweden. 2014. 327-332.
11McDonald DM,Chen H,Su H,et al. Extracting gene pathway relations using a hybrid grammar: The Arizona relation parser. Bioinformatics,2004,20(18): 3370-3378.[doi: 10.1093/bioinformatics/bth409]
12Quinlan JR,Cameron-Jones RM. FOIL: A midterm report.European Conference on Machine Learning: ECML-93.Vienna,Austria. 1993. 1-20.
13汪雪君. 基于規(guī)則的分類方法研究[碩士學(xué)位論文]. 漳州:閩南師范大學(xué),2013: 1-47.
14劉挺,車萬翔,李正華. 語言技術(shù)平臺. 中文信息學(xué)報,2011,25(6): 53-62.
15邵艷秋,邱立坤,梁春霞,等. 中文語義依存關(guān)系資源建設(shè)及分析技術(shù)研究. 第十一屆全國計算語言學(xué)學(xué)術(shù)會議. 洛陽,中國. 2011.
16劉丹丹,彭成,錢龍華,等. 《同義詞詞林》在中文實體關(guān)系抽取中的作用. 中文信息學(xué)報,2014,28(2): 91-99.
17http://www.ltpc loud.com/intro/.
18徐芬,王挺,陳火旺. 基于SVM方法的中文實體關(guān)系抽取.第九屆全國計算語言學(xué)學(xué)術(shù)會議論文集. 大連,中國.2007. 497-502.
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
小哥白尼(趣味科學(xué))(2021年12期)2021-03-16 05:40:38
小學(xué)科學(xué)(學(xué)生版)(2020年10期)2020-10-28 07:52:18
開放教育研究(2020年2期)2020-03-31 01:54:14
文苑(2019年22期)2019-12-07 05:28:56
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學(xué)報(哲學(xué)社會科學(xué)版)(2016年9期)2017-01-15 13:52:02
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
學(xué)生天地(2016年9期)2016-05-17 05:45:06
