基于詞語關聯的散文閱讀理解問題答案獲取方法
2018-05-04 07:26:32王素格譚紅葉王元龍
中文信息學報 2018年3期
喬 霈,王素格,2,陳 鑫,譚紅葉,陳 千,王元龍
(1. 山西大學 計算機與信息技術學院,山西 太原 030006;2. 山西大學 計算智能與中文信息處理教育部重點實驗室,山西 太原 030006)
0 引言
隨著國內外越來越多的機構投入到問答系統的研究中,使得自動問答技術取得了很大的進展。問答系統,即利用自然語言處理技術理解用戶所提出的問題,再返回給用戶正確的答案[1]。閱讀理解屬于問答任務中的一個重要分支,又與傳統的問答存在區別,它是通過機器理解一篇文章,再根據文中信息對所提的問題做出回答,主要側重于問題與閱讀材料的語義相關性。面向高考散文閱讀理解問答題,按照問題的提問方式我們將其歸納為特點(特色)類、感受類、認識(態度)類、原因類、列舉類、其他類共六類。為了解答這些問題,首先需要理解題干的相關信息,然后從閱讀材料中獲取與題干中信息相關的詞語或短語,最后將閱讀材料中與詞語或短語相關的句子作為答案句。表1所示為閱讀理解中問答題的問題、答案示例。

表1 閱讀理解中問答題的問題、參考答案示例
表1中問題的關鍵詞為“特色”,描述對象為魯迅的故鄉環境,理解“特色”一詞的抽象語義,需要從閱讀材料中尋找魯迅的故鄉環境與“特色”相關聯的詞語,構成答案句。
針對散文閱讀理解類問題中的詞語較為抽象,在語義上難以與閱讀材料中的信息聯系,需要將問題中具有抽象含義的詞語擴展為與其關聯的具體詞語,再進一步與閱讀材料中的句子進行聯系。
本文利用LDA方法將問題庫中的問題詞語與閱讀材料涉及的內容進行主題聚類,然后按照詞性、詞頻特征篩選出每個主題下相關的詞語作為問題詞語的主題關聯詞,再利用Word2Vec訓練散文語料,將得到的主題關聯詞語進一步擴展為語義關聯詞語。通過獲取語義關聯詞語,使問題關鍵詞語與閱讀材料中句子之間建立聯系,從而豐富問題關鍵詞語,提高問題答案句的抽取性能。
1 相關工作
自從1999年TREC(text retrieval conference)會議[2]開設QA Track以來,自動問答及閱讀理解的研究就備受關注。早期問答系統的研究主要有以下三個方面: (1)基于統計方法是從文本集中抽取答案返回給用戶。例如,IBM開發的基于統計的問答系統主要應用統計翻譯、詞匯模式等抽取方法。(2)基于知識庫的方法是從知識庫中抽取問題的答案。例如,芝加哥大學開發的FAQFinder[3],用于解決一些地理、歷史、文化等方面的簡單問題。(3)基于語義的方法是通過計算詞語間的語義相似度獲得答案句。例如,臺灣Sheng-YuanYang開發的FAQ-master[4]。目前閱讀理解方面的研究大多針對簡單文本和簡單問題,例如,微軟建立的一套面向兒童的開放域閱讀理解數據集MCTest[5],Smith等[6]針對此數據集提出了在文本上設置滑動窗口來與問題答案對中的詞匯匹配打分的方法,引用一種基于RTE的方法將問題與答案按照啟發式規則進行拼接,然后計算上述拼接結果與原文信息之間的相關性。Facebook的bAbI項目仿真生成了20個任務用于測試文本理解和推理[7],Sukhbaatar等[8]提出端到端的記憶網絡模型,用于解答上述20個任務中的短文本問題。由于問題和文本是自動生成,相應的數據簡單,使得結果準確率高,但是該實驗側重信息推理,未考慮文本的語義信息,因此,難以應用到中文閱讀理解任務中。王智強等[9]提出一種基于篇章框架語義分析的答案抽取方法,并將其應用于解答中文閱讀理解問題。該方法主要依賴框架結構,而散文本身用詞廣泛,隱含語義豐富,且問題中的詞語較抽象,框架關系中目前還未覆蓋散文領域的抽象詞語,因此,還難以利用框架關系建立問題中詞語與文章之間的關系。
對于機器閱讀理解問題,現有研究者的主要工作集中于問題分析、答案抽取及生成[10]。然而,由于問題中的關鍵詞與答案句中的詞語在表達方式上存在差異,導致問題中詞語未能與文章中的詞語相聯系,這將影響答案句抽取的準確性,因此,在散文問答題中有必要進行詞語關聯方法研究。
詞語關聯,即尋找詞語的潛在語義,解決詞語的一詞多義、多詞同義現象,用于提高檢索的準確率。目前,問答系統中采用的詞語關聯方法主要包括基于統計的方法和基于語義詞典或特定擴展詞表的方法。
基于統計的詞語關聯方法通常利用詞語之間的共現概率或互信息等統計信息來選取關聯詞,該方法并沒有深入分析原查詢詞與候選關聯詞間的語義關系。例如,Jones[11]提出詞的聚類算法,根據詞與詞之間在語料庫中的共現程度實現詞聚類,并將查詢詞所在簇中的其他詞作為關聯詞語。丁立愷[12]提出詞關聯度的概念,通過對文本語料庫中詞語出現的頻率,以及任意兩個詞語共同出現的頻率進行統計,獲得各個詞語之間的關聯度。
基于語義詞典的方法,需要借助詞典中的詞建立與查詢詞之間的語義關聯。張華平等[13]通過使用WordNet的語義體系對詞語進行語義關聯性的擴展。Rothe等[14]結合深度學習方法以WordNet作為語義資源提出自動擴展的方法,構造了一個使用詞嵌入擴展同義詞集和語義嵌入的系統。史俊冰等[15]建立了同義詞詞典,并在此基礎上實現了詞語擴展。萬靜等[16]通過構建領域知識詞典的方法擴展用戶輸入的關鍵詞。以上基于詞典的擴展方法依賴于完備的語義體系,而目前并沒有散文領域的相關體系。另外,基于語義詞典的方法不依賴語料集,難以聯系閱讀理解的文本內容的特性。陳建超等人[17]通過建立包含上下文信息的同義詞集解決文本中的一詞多義和多詞同義問題。他將詞語的上下文信息視為特征詞,根據特征詞之間存在的關聯性特點建立了一個評分機制,提取分數最高的特征詞集對應的詞匯作為一個同義詞集,該方法比直接提取近義詞或提取上下文相關詞的準確率有所提高,但是考慮閱讀材料中大多采用含蓄、隱式的詞語來表達作者的情感,因此,難以直接將該方法應用于閱讀理解當中。
上述研究主要側重將詞語擴展為與其表層語義相近的詞,從而忽略了詞語在特定語境和不同主題下的潛在語義信息。
LDA(latent dirichlet allocation)是Blei等[18]2003年提出的一種被廣泛使用的主題模型,能夠從海量語料庫中獲取核心語義或特征并對主題進行建模,它是一個離散數據集生成概率模型的過程[19],其工作原理是將語料庫中的每一個文檔與一組潛在主題的概率分布進行對應,而每一個潛在主題同時與文檔中詞語的概率分布相對應。該模型基于三點假設[20]: (1)詞袋模型,LDA認定每篇文檔是由一組詞匯構成,且詞匯之間無先后順序關系,詞語集合W={w1,w2,…,wn};(2)訓練集中的文檔順序也是隨意的,無指定順序,因此,每篇文檔可以表示成一個詞頻向量關系集合di=
2 面向問題解答的詞語關聯方法
考慮到問題與答案集、問題與閱讀材料中詞語間具有主題相關性和語義相關性,我們利用LDA主題聚類方法,確定各類別問題詞語的主題,再利用詞語重要度選擇各類別相應主題下重要度高的詞語作為該問題類別的主題關聯詞語。在此基礎上,利用Word2Vec對主題關聯詞語與材料中詞語進行向量表示,用于度量詞語間的語義相關性。最后利用上述兩種方法,擴展問題的抽象詞語,建立問題與散文材料中的詞語聯系。
2.1 基于LDA的問題主題詞語擴展
為了獲取主題相關的詞語,以散文閱讀理解為背景,從所有的閱讀材料—問題—答案集中整理出抽取類問答題(抽取類,即答案句是從文中摘取的句子),以這些問題-答案集為數據,通過LDA聚類方法將數據集下的詞語聚集在不同的主題之下,使各類別問題詞語對應各自的主題。例如,文本“作者故鄉植物的生命具有哪些特點?”其示意圖如圖1所示。
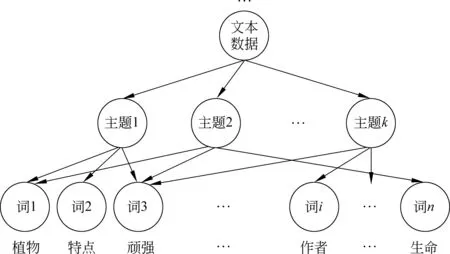
圖1 LDA聚類主題—詞匯分布舉例
通過LDA主題聚類,可以計算各數據(一條數據指的是一個問題—答案對)在每個主題下的概率,計算方法如式(1)、式(2)所示。
其中,Wi表示第i條數據的詞集,TWj表示主題j中的詞集,N(Wi,TWj)為第i條數據與主題j中共同出現的詞語,R(i,k)表示第i條數據對應的主題為k。
針對上文引言中提到的閱讀理解中六類問題所關聯的詞語,可以確定各數據所屬的類別,利用各類別數據在不同主題下的比例可以獲取類別為tyn對應的最優主題k(tyn),如式(3)所示。
(3)
其中,n(tyn)是tyn類的數據總數,m(k,tyn)表示tyn類中的主題為k的數據個數。
根據式(3),可將各類問題與主題對應,然而通過對大量數據考察,發現各主題下的部分詞語集與該類問題中詞語關聯性不強,例如,各類問題的描述性詞語一般多為名詞和形容詞,而動詞“分析”“具有”“選擇”等為不具有特定意義的詞語。因此,需要進一步對六類問題中的詞語進行篩選。各類問題的形容詞和名詞部分描述如表2所示。
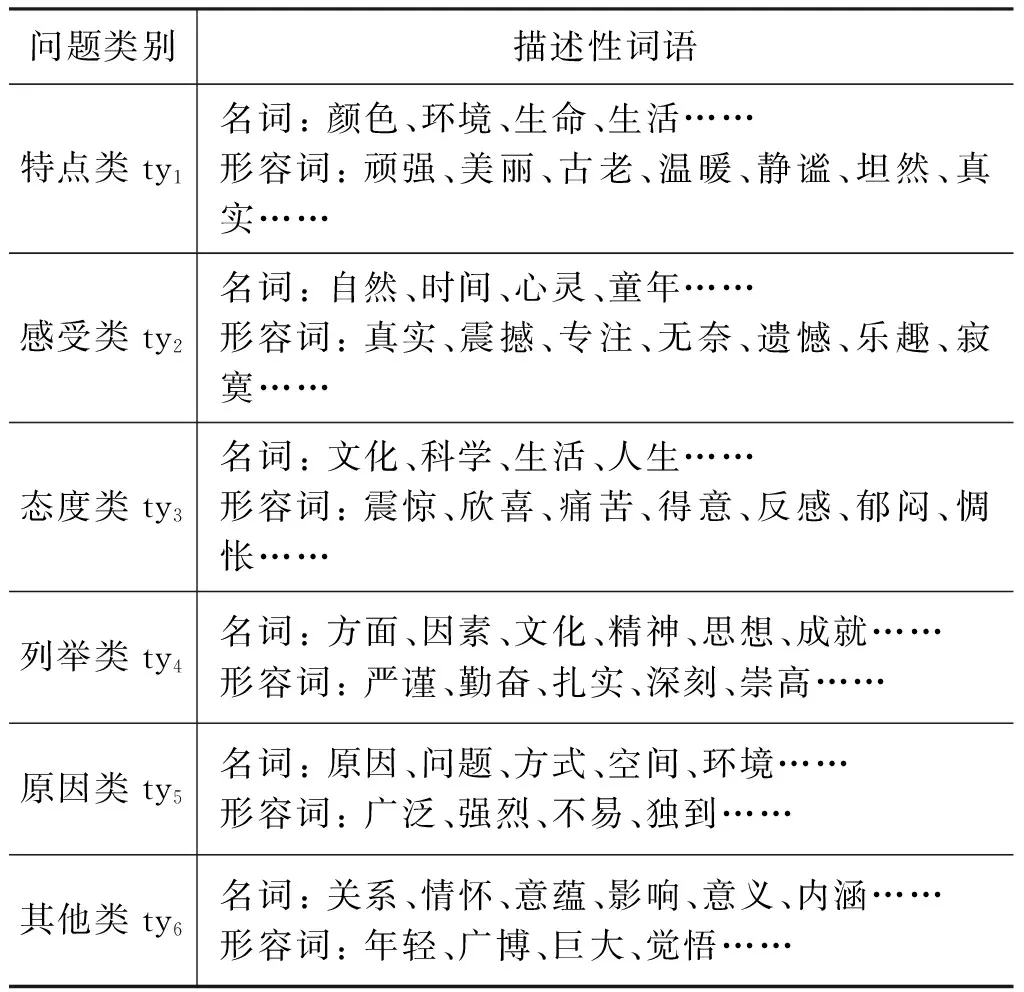
表2 各類問題的部分描述性詞語
為了準確地獲得與解題相關的關聯詞語,分別統計六類問題中的詞語對應的主題下的名詞和形容詞出現的次數。按照高頻詞數均值法確定主題中抽取詞語的數量tn,計算方法如式(4)所示。
(4)
其中,m表示問題類別總數,ftyn表示tyn類問題對應的主題中頻次高于l的詞語集。
由于每類詞語中名詞和形容詞的重要度不同,進一步設置參數α和1-α分別代表名詞和形容詞在每類問題詞中所占的比重,以此獲得每個類別中名詞和形容詞保留的個數,計算方法如式(5)所示。
(5)
其中,N′(tyn,wn.)為tyn類下名詞的數量,N′(tyn,wadj.)為tyn類下形容詞的數量。
2.2 基于Word2Vec的問題語義詞語擴展
由于高考閱讀材料的有限性,僅僅利用2.1節中方法獲得每類詞語的主題關聯詞語不能滿足問題解答的要求,需要進一步獲取與散文領域中詞語語義相關聯的詞語。Word2Vec是2013年由Google公司開發的將詞表示為向量形式的工具[22],這些向量中含有潛在豐富的語義信息。本文將散文閱讀材料與主題相關的詞語通過Word2Vec訓練,使它們轉化為特定維度的向量表示,然后再計算詞語間相關性,該方法記為TWE。
假設PC為散文材料庫,T為主題詞語集合。
詞語相似度計算過程: 利用Word2Vec,將詞語p∈PC和主題關聯詞語q∈T分別表示成向量w(p),w(q),PC中所有詞語的向量集合記為PC′。通過計算w(p)與w(q)之間的余弦夾角,可獲得w(p)與w(q)的相似度矩陣{cos(w(p),w(q)}|T||PC|。
詞語關聯度排序函數: 為了獲取PC中與q語義相似度高的詞語,我們定義w(p)與w(q)余弦值的排序函數Rank,具體如式(6)所示。
(6)
這里Top-h(w(q))為余弦值排序在前h個對應的詞語序列。
3 散文問答題答案抽取方法
根據高考語文相關專家分析,通常閱讀理解問答題的得分是按照給出的答案要點進行評判。因此,針對散文問答題的答案抽取任務,需要計算詞語間的相關性。通常采用詞語的詞形匹配和語義相似計算,而詞形匹配一般使用詞語匹配的句子相似度計算方法[23],語義相似計算采用HowNet的句子相似度計算[24]方法。
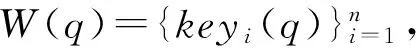
(1) 詞語的詞形匹配計算方法sim1
問題句q與閱讀材料中句子s的相似度算法如式(7)所示。
(7)
(2) 詞語的語義相似計算方法sim2
對于問句q與閱讀材料中句子s的相似度計算,如式(8)所示。
(8)
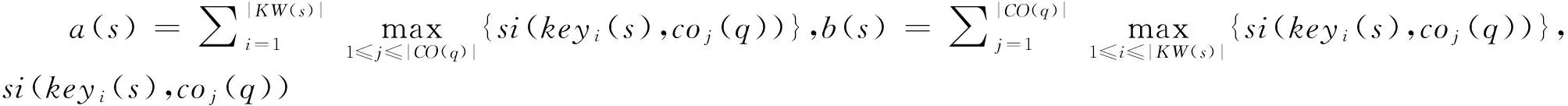
(3) 詞語的詞形匹配與語義相似混合計算方法sim
對于詞語的詞形匹配,僅利用詞語的表層信息,而詞語的語義相似計算方法考慮詞語的深層語義信息,因此,本文將兩者有機結合。利用式(7)和式(8),獲得問句q與閱讀材料中句子s的詞語的詞形匹配與語義相似混合計算方法sim=sim1(q,s)+sim2(q,s),選擇問句q與閱讀材料中句子相似度高的N個句子作為答案句。
4 實驗結果與分析
4.1 實驗數據及評價指標
本文的實驗數據分為訓練數據和測試數據。
訓練數據: 主題聚類所用的數據集是從人工整理的各省高考題(不包含北京卷)共1 647篇文章,包含6 117個問題—答案集中的約600個抽取類試題的問題—答案集;內容關聯詞語擴展所用的數據集是從網絡爬取的近七萬篇文學作品的閱讀理解,規模大約320 MB。
測試數據: 選擇北京市近12年的高考題和網上收集的1 000套高考模擬題作為方法驗證,其中抽取類問答題有400個。
評價指標: (1)本文采用信息熵來度量聚類結果對各類問題的影響;(2)根據題目所給的參考答案人工從材料中尋找對應的句子,并記為答案句集合A,T為使用本文方法得到的答案句子集合,按如下公式計算準確率(P)、召回率(R)和F值。其中,
(9)
4.2 參數設置
4.2.1 主題個數的選擇
利用2.1節中介紹的方法進行聚類,實驗分別選擇主題數k=5,7,10,用于比較聚類結果中六類問題詞語在不同主題下的分布比例,實驗結果如表3~表5所示。
根據表3~表5,獲得六類問題在不同主題下聚類結果。首先,計算各類問題在各主題中的信息熵,然后加和取平均作為該主題數聚類下的整體信息熵值,最終得到主題數k=5,7,10時信息熵值分別為H(k=5)=2.14、H(k=7)=2.35,H(k=10)=2.94。熵值越小,說明聚簇結果越好。因此,選擇主題數k=5最佳。下面的實驗主題數均為k=5。
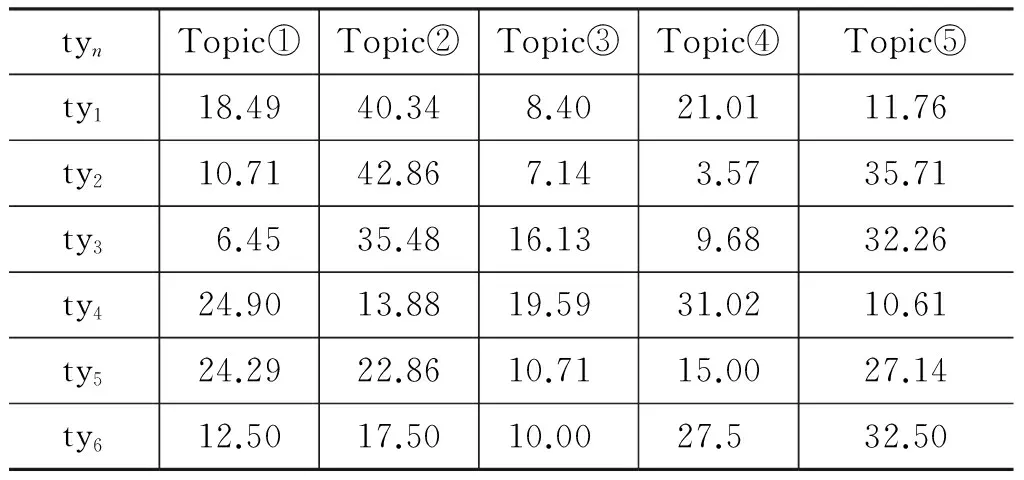
表3 各類問題在主題數k=5的聚類結果的分布比例/%
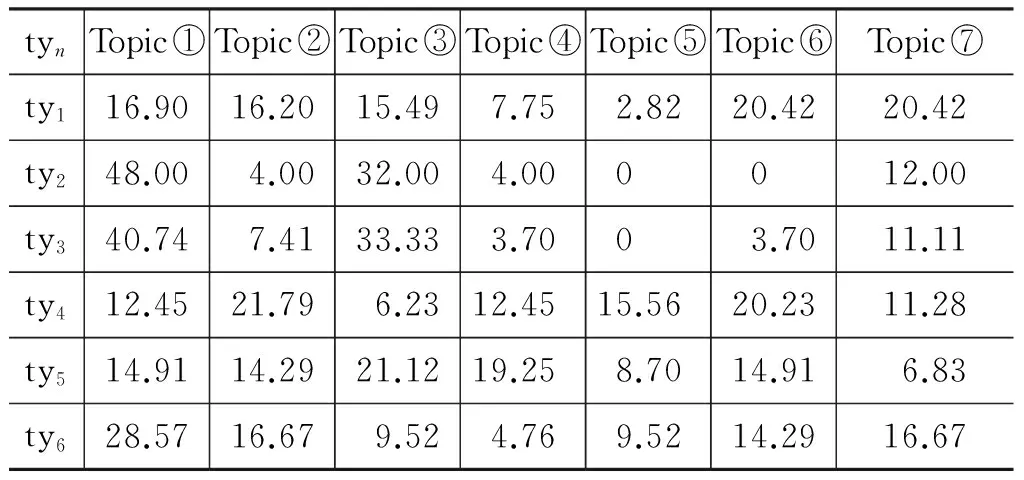
表4 各類問題在主題數k=7的聚類結果的分布比例/%

表5 各類問題在主題數k=10的聚類結果的分布比例/%

續表
4.2.2 詞語篩選
考慮詞語的覆蓋度,本實驗設置主題下高頻詞閾值l=6, 4, 2三組實驗,利用2.1節中式(4)獲得主題關聯詞語數tn=13,24,60,而實驗中主題關聯詞語的數量tn=24時答題效果最好,因此,本實驗將高頻詞的閾值設置為l=4。
當tn確定后,利用2.1節中式(5)確定每類問題中名詞和形容詞的比例,本實驗取α= 0,0.1,0.2,…,0.9,1,共11組實驗,針對每類問題的答題準確率,選擇各類別主題下名詞和形容詞的最優個數,結果如圖2所示。
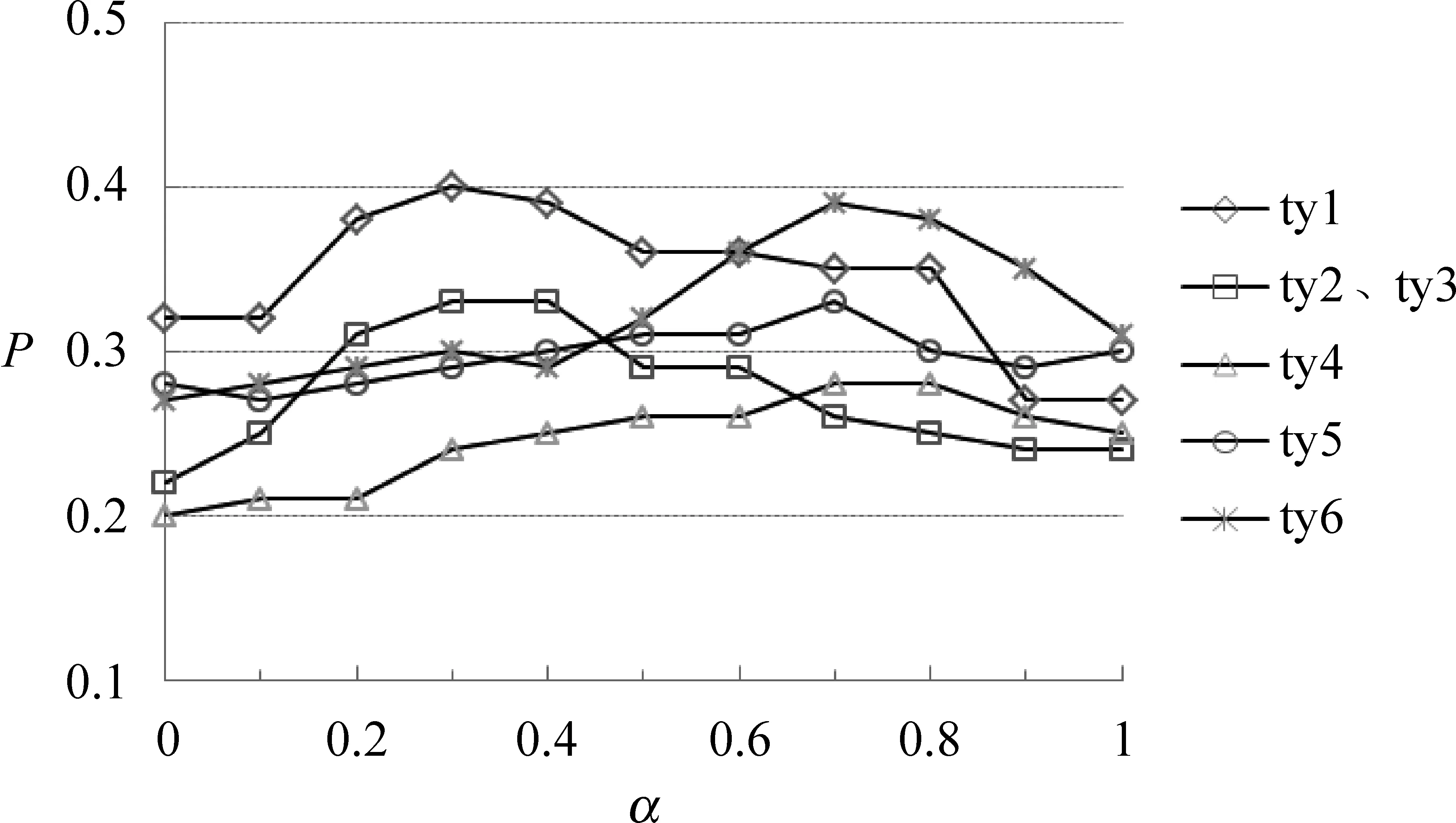
圖2 詞語重要度參數α選擇實驗結果
從圖2可以看出ty1、ty2、ty3的問題在α=0.3時效果最好,ty4、ty5和ty6在α=0.7時效果最好。
4.2.3 語義關聯詞語Top-h(w(q))中h的選擇
散文語料中詞向量的訓練選取了Word2Vec的Skip-gram模型[25],參數設定為默認值,即文本窗口為5,向量維度為300維。訓練后得到80 000多個詞向量。
利用2.2節中介紹的方法擴展詞語,詞匯的數量h分別取5,10,15,20,25,30,方法驗證時答案句的個數取N=4,6,8,通過測試,得到最好結果為N=6。因此,抽取答案句子數N=6計算準確率,結果如圖3所示。
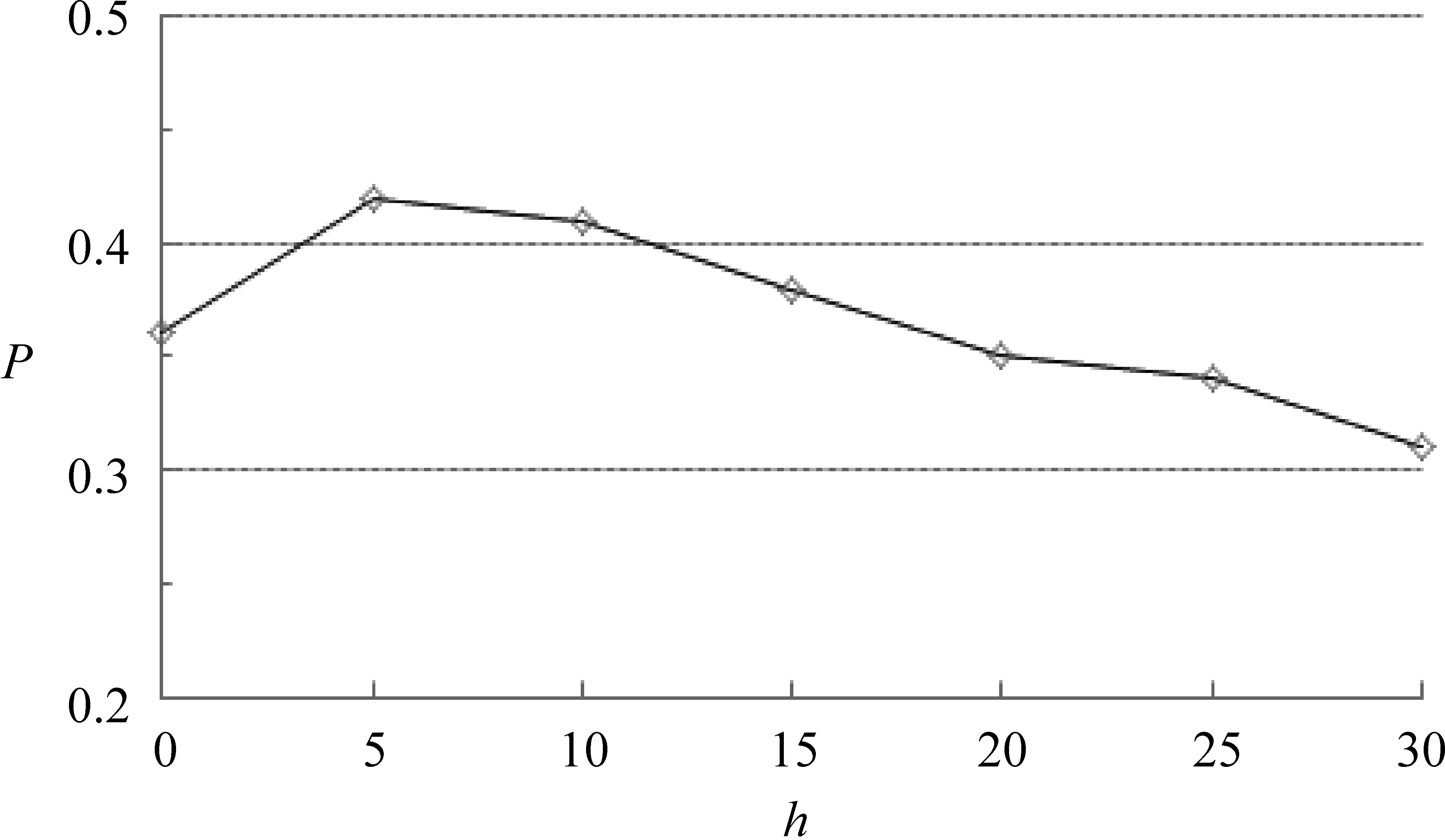
圖3 擴展詞匯數量h的選取
由圖3可知,當最終確定擴展詞匯數量h=5時,實驗結果較好。
4.3 答案句抽取實驗結果與分析
為了驗證本文擴展詞語對答案句抽取的有效性,設置了三個Baseline方法進行對比。
(1) 直接抽取答案句(DE): 即問題中的關鍵詞不進行詞語擴展。
(2) 基于Word2Vec的詞語關聯抽取答案(WE): 將問題詞集W(q)直接利用Word2Vec余弦相似度得到擴展詞集WV(q),不進行主題聚類。
(3) 基于同義詞詞林的詞語關聯抽取答案句(SE): 將問題詞集W(q)利用同義詞詞林擴展詞集SW(q)。
利用DE、WE、SE以及本文方法TWE獲取關聯詞語,再分別使用第三節的三種答案抽取方法獲得前六個答案句子數,得到不同詞語關聯方法和不同的答案抽取方法間的比較結果,如表6所示。
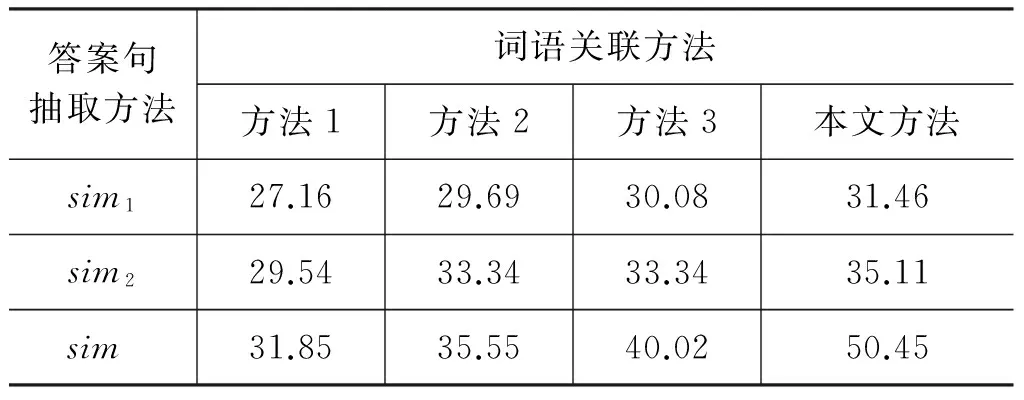
表6 不同詞語關聯與不同的答案句抽取方法的F值結果比較/%
由表6中結果可知:
① 詞語的詞形匹配方法sim1抽取答案句的F值比詞語語義相似方法sim2抽取答案句的F值低,主要原因是由于散文問答題的特殊性,它更強調抽象詞語的語義。
② 詞語的詞形匹配與語義相似混合計算方法sim,得到的結果比單獨的方法sim1(sim2)抽取答案句的F值高,主要原因是同時考慮了詞語的詞形和語義。因此,本文答案句抽取方法選擇sim方法。在此基礎上,不同詞語關聯方法在抽取前六句答案句時的準確率、召回率和F值如表7所示。
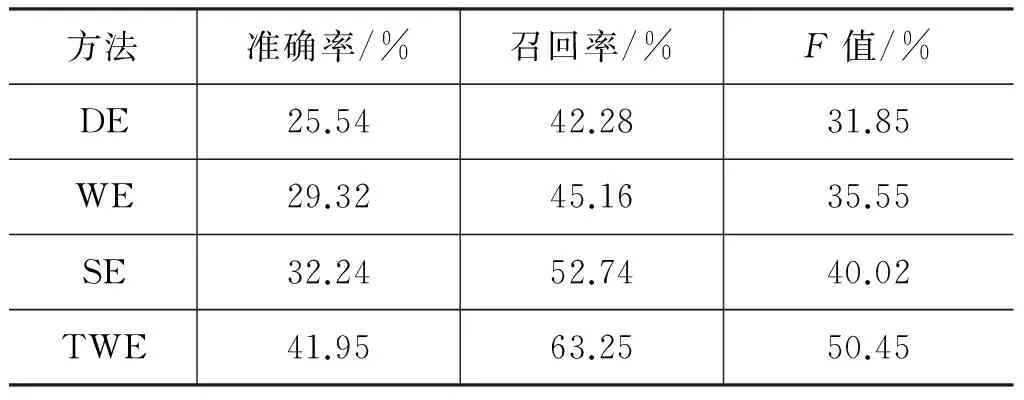
表7 不同詞語關聯方法抽取答案句的結果比較
由表7中實驗結果可知:
(1) 本文方法TWE比Baseline方法在答案句抽取的三項指標結果均好。方法DE沒有對問題中的關鍵詞擴展,使問題與閱讀材料中相關句子難以聯系。方法WE和方法SE雖然對解題起到一定作用,但是問題中抽象詞語擴展為其抽象的近義詞,未從根本上解決抽象詞與具體詞之間的語義鴻溝,導致準確率不及方法TWE。
(2) 與方法DE、WE、SE相比,本文方法TWE從主題角度擴展抽象詞的關聯詞語,使得答題準確率和召回率有了顯著提升,說明詞語關聯方法對散文抽取類問題的解答確實起到了作用。
(3) 為了驗證方法TWE的顯著性,從統計學角度分析,采用配對樣本的t檢驗方法衡量數據的統計意義,當p小于0.05時,說明兩組數據的平均值在小于5%的概率上是相等的,在大于95%的幾率上不相等,兩組實驗存在顯著性差異。將方法DE、WE、SE與TWE對比,分別獲得的概率值為:
p(1)=0.012<0.05
p(2)=0.036<0.05
p(3)=0.043<0.05
由于三組數據的概率p均小于0.05,因此,方法TWE的實驗結果具有統計顯著性。
4.4 高考題答題結果及分析
對于引言中表1的高考題,利用TWE方法,可以獲得問題的解答結果,如表8所示。

表8 本文方法解答問答題示例
由表8結果可知,利用本文方法TWE擴展問題詞語,再抽取答案句,可以獲得“空間……;物件……”兩句正確答案。
如果采用方法DE解答本題,未能獲得正確答案句。方法WE和方法SE均獲得一句正確答案。因此,本文方法TWE在一定程度上提高了散文閱讀理解的答題準確率。
5 總結
散文閱讀理解問題中的關鍵詞具有抽象含義,導致問題與答案句之間具有較大的語義鴻溝,為了解決該類問題,本文提出詞語關聯方法。首先基于LDA聚類的主題—詞匯分布,確定各數據的主題,然后根據各類數據在主題下的分布比例為每類數據分配最優主題,對該主題下的詞語重要度進行選擇,得到各問題類別的主題關聯詞語;接著,利用Word2Vec相似度方法將主題關聯詞語擴展為語義關聯詞語,最后利用詞形匹配和語義相似混合計算方法抽取答案句。方法TWE有效提高了散文問答題的答題準確率和召回率。另外,方法TWE不僅適用于高考閱讀理解的問題解答,也可以應用于信息檢索任務中。
由于散文閱讀材料往往帶有作者的情感信息,因此在未來工作中,將考慮情感詞的重要性,結合句子中的情感信息進一步獲得詞語的關聯詞語。
備注本文使用了哈爾濱工業大學計算與信息檢索中心研發的LTP進行分詞及詞性標注;使用了知網提供的語義相似度計算方法。
[1] 張寧, 朱禮軍. 中文問答系統問句分析研究綜述[J]. 情報工程, 2016, 2(1): 32-42.
[2] Katz B. Annotating the World Wide Web using natural language[C]//Proceedings of Computer-Assisted Information Searching on Internet,1997: 136-155.
[3] Hammond K, Burke R, Martin C, et al. FAQ Finder: A case-based approach to knowledge navigation[C]//Proceedings of Conference on Artificial Intelligence for Applications,1995: 80-86.
[4] Yang S Y. An ontological multi-agent system for web FAQ query[C]//Proceedings of the 2007 International Conference on Machine Learning and Cybernetics,2007: 2964-2969.
[5] Matthew R, Christopher J C Burges, Eric Renshaw. MCTest: A challenge dataset for the open-domain machine comprehension of Text[C]//Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing,2013: 193-203.
[6] Smith E, Greco N, Bosnjak M, et al. A strong lexical matching method for the machine comprehension test[C]//Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing,2015: 1693-1698.
[7] Weston J, Bordes A, Chopra S, et al. Towards ai-complete question answering: A set of prerequisite toy tasks[J]. arXiv preprint arXiv: 1502.05698, 2015.
[8] Sukhbaatar S, Weston J, Fergus R. End-to-end memory networks[C]//Proceedings of Advances in Neural Information Processing Systems,2015: 2440-2448.
[9] 王智強, 李茹, 梁吉業,等. 基于漢語篇章框架語義分析的閱讀理解問答研究[J]. 計算機學報, 2016, 39(4): 795-807.
[10] 吳友政, 趙軍, 段湘煜,等. 問答式檢索技術及評測研究綜述[J]. 中文信息學報, 2005, 19(3): 1-13.
[11] Jones S. Automatic keyword classification for information retrieval[J]. The Library Quarterly: Information, Community, Policy, 1971, 25(4): 33-98.
[12] 丁立愷. 基于詞關聯度的信息檢索系統[D]. 上海: 復旦大學碩士學位論文, 2010.
[13] 張華平. 語言淺層分析與句子集新信息檢測研究[D]. 北京: 中國科學院研究生院博士學位論文, 2005.
[14] Rothe S, Schütze H. Autoextend: Extending word embeddings to embeddings for synsets and lexemes[J]. arXiv preprint arXiv: 1507.01127, 2015.
[15] 史俊冰.問答系統中詞義消歧與關鍵詞擴展研究[D].太原: 太原理工大學碩士學位論文,2011.
[16] Wan J, Wang W C, Jun-Kai Y I. Semantic extended search approach based on ontology in knowledge base[J]. Computer Engineering, 2012, 38(6): 19-24.
[17] 陳建超, 鄭啟倫, 李慶陽,等. 基于特征詞關聯性的同義詞集挖掘算法[J]. 計算機應用研究, 2009, 26(7): 2517-2519.
[18] Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2003(3): 993-1022.
[19] Blei D, Carin L, Dunson D. Probabilistic topic models[J]. IEEE Signal Processing Magazine, 2010, 27(6): 55-65.
[20] 魏強, 金芝, 許焱. 基于概率主題模型的物聯網服務發現[J]. 軟件學報, 2014(8): 1640-1658.
[21] 董婧靈. 基于LDA模型的文本聚類研究[D].武漢: 華中師范大學碩士學位論文, 2012.
[22] 寧建飛, 劉降珍. 融合Word2Vec與TextRank的關鍵詞抽取研究[J]. 現代圖書情報技術, 2016(6): 20-27.
[23] 王榮波, 池哲儒, 常寶寶,等. 基于詞串粒度及權值的漢語句子相似度衡量[J]. 計算機工程, 2005, 31(13): 142-144.
[24] 劉青磊,顧小豐.基于《知網》的詞語相似度算法研究[J]. 中文信息學報, 2010, 24(6): 31-37.
[25] Mikolov T, Chen K, Corrado G, et al.Efficient estimation of word representations in vector space[J]. arXiv: 1301.3781.
猜你喜歡
當代陜西(2021年17期)2021-11-06 03:21:36
開放教育研究(2020年2期)2020-03-31 01:54:14
學苑創造·A版(2018年11期)2018-02-01 06:29:20
讀者(2017年5期)2017-02-15 18:04:18
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年2期)2011-01-23 06:39:12
