基于Spark的大規模語義規則后向鏈推理系統
2018-05-04 06:46:28王善永袁春風黃宜華
中文信息學報 2018年3期
顧 榮,王善永,郭 晨,袁春風,黃宜華
(1. 南京大學 計算機軟件新技術國家重點實驗室,江蘇 南京 210093; 2. 江蘇省軟件新技術與產業化協同創新中心,江蘇 南京 210093)
0 引言
1998年,創建萬維網聯盟(W3C)的蒂姆·伯納斯·李(Tim BernersLee)前瞻性地提出了語義網(semantic web)的概念,希望通過給萬維網上的文檔添加語義(meta data),使得萬維網成為一個能被計算機理解的通用信息交換媒介。2001年,萬維網聯盟制定了語義網行動計劃,經過十多年的發展,語義網相關的理論基礎和技術規范逐漸得到完善,符合語義網數據模型規范的語義數據快速積累。與此同時,語義技術不斷地在商業和研究等領域獲得應用。例如,在商業領域,全球最大的搜索引擎公司Google創建了Google知識圖譜(Google Know-ledge Graph)[1],使用語義檢索從多種信息源獲取信息,輔助提高Google搜索引擎的搜索質量;在醫學領域,藥物研究者利用語義技術來發現藥物之間的聯系,輔助藥物開發。另一方面,語義推理技術受軟硬件環境所限,還無法非常高效地推理大規模語義數據,尤其是大規模并行化的后向鏈語義推理問題還沒有高效的處理方法。
自MapReduce[2]被提出以來,大數據處理技術在存儲、查詢和計算方面都取得了快速的突破性發展。近幾年來,以Spark[3]為代表的內存計算技術逐漸成熟,其典型的吞吐量大、可靠性高、部署成本低廉等特點,為大規模數據處理提供了可靠的平臺,成為大規模語義推理的一個新的研究方向。
傳統的后向鏈語義推理是一種單機串行的推理方法,目前已有并行化的后向鏈語義推理方法出現,但大多是支持簡單規則的弱推理。本文在研究了后向鏈語義推理算法和總結前人方法的基礎之上,提出了一種基于Spark大數據計算平臺的大規模并行化語義規則后向鏈推理方法,歸納為以下三個方面。
(1) 針對大規模推理問題,設計了實時預計算本體數據閉包的策略,避免了頻繁出現的本體模式在實時推理階段的重復計算。
(2) 在后向鏈語義推理的過程中設計了優化措施,進一步提高了推理的效率。在逆向推理階段,根據推理模式在不同層次間的數據依賴關系,盡早剪除無效推理分支。在查詢階段,利用Spark SQL優化查詢過程。
(3) 設計并實現了基于Spark 平臺的大規模分布式RDFS/OWL后向鏈語義推理系統。
本文第一節簡要介紹了語義推理的相關概念;第二節介紹了后向鏈語義推理的相關工作;第三節分析并設計了后向鏈語義推理的框架流程;第四節介紹了后向鏈推理的逆向推理和查詢優化;第五節分別在LUBM和DBpedia數據集上對系統進行了實驗;最后對全文進行了總結。
1 背景知識
1.1 語義推理相關概念
資源描述框架(resource description framework, RDF)是萬維網聯盟指定的一種靈活且領域無關的數據模型。在使用RDF描述某一特定領域知識時,需要專門定義一套領域相關的詞匯表,并以某種語言來刻畫詞匯表的語義,這就是RDF Schema[4],簡稱為RDFS。RDFS在RDF的基礎上,給用戶描述特定領域中的類和屬性提供了標準語義。
RDFS主要包含類、屬性、子類、子屬性、值域和定義域等幾個核心概念,其表達能力相對有限,難以描述萬維網中更加復雜的結構關系,于是W3C又制定了描述能力更強的網絡本體語言OWL(web ontology language)[5],提供了更強大的知識表示和推理能力。但同時我們也看到,OWL的每個版本都有幾個精簡子集(OWL Lite,OWL2 QL,OWL2 RL等),更強的表達能力意味著更高的計算復雜度,甚至不可判定,即不能夠推理出符合復雜本體描述語言語義的結論(比如 OWL Full)。目前已實現的推理引擎中,大部分是實現了對OWL精簡子集的推理或者是僅支持部分語義,OWL Horst就是這樣一種被廣泛接受的具有較強表達能力并能大幅度降低計算復雜度的規則集。基于OWL Horst規則集的推理又稱為pD*推理,涵蓋了所有RDFS蘊涵(RDFS entailment)和D蘊涵(D entailment),成為語義推理中使用最廣泛的規則集[6]。OWL Horst規則集包含了RDFS規則集。另外OWL Horst規則集中的某些規則,例如,規則rdfp5a: (v,p,w)=>(v, owl: sameAs,v)和rdfp5b: (v,p,w)=>(w, owl: sameAs,w)表達了任意三元組的主語和賓語都是和自身相似的,這對推理應用以及用戶來說都沒有意義。在大多數語義推理系統[6-8]中,都沒有考慮這些沒有意義的規則的推理。在此,忽略掉RDFS規則集和OWL Horst規則集中對推理沒有意義的規則,把其他規則列于表1中并重新編號,便于后文對這些規則的引用,其中規則R1到規則R6屬于RDFS規則集。
表1RDFSOWLHorst規則集

基于規則的推理方法又分為前向鏈推理和后向鏈推理[9]。
前向鏈推理就是根據規則推導出結論的過程,在推理發生時,推理機應用規則到要推理的數據上,并把推理結果存儲到數據庫中,一旦推理完成,知識庫將是完整的,即所有隱式數據都被顯式化了。這樣,語義推理問題就變成了單純的查詢問題。其缺點也是顯而易見的,隱式知識顯式化要額外占用大量存儲空間,同時數據庫也不可能一直保持不變,一旦數據庫有新知識插入,那么推理任務就需要重新做一遍,這是非常耗時的。
后向鏈推理就是反向應用規則,例如,命題A1,A2,…,An→B,要證明B只要去證明規則的前件A1,A2,…,An。從推理發生的時機來說,后向鏈推理就是有查詢請求的時候針對這個查詢請求執行的推理。后向鏈推理不需要額外存儲隱式知識,它只是在查詢時才挖掘隱含知識,這降低了存儲空間開銷,并且在數據庫更新時不需要額外的操作。不過,處理的代價也是顯然的,就是查詢請求因為附帶上推理而造成響應時間的延長。后向鏈推理特別適合應用在知識庫更新頻繁的場景下。本文主要研究基于Spark的并行化后向鏈推理算法。
1.2 分布式系統Spark介紹
Spark是由UC Berkeley AMPLab實驗室于2009年發布的分布式內存計算框架,它是Berkeley Data Analysis Stack(BDAS)中的核心項目。RDD[3](resilient distributed dataset)是Spark中的核心數據結構。Spark定義了RDD上的三種操作: 轉換(transformation)、動作(action)和控制(control)。轉換包括map、join、filter、union等Spark內置函數,它從一個RDD計算出另一個RDD,比如模式匹配操作相當于RDD上filter操作,合并兩個集合的操作相當于RDD上的union操作,而把一個數據集合內的每一個元素映射成另一種形式的操作,相當于RDD上的map操作。
RDD上的動作包含reduce、count、collect、saveAsTextFile等Spark內置函數,比如合并一個集合里所有元素的操作相當于RDD上的reduce操作,統計一個數據集合里有多少個元素的操作相當于RDD上的count操作,把數據保存到存儲系統的操作相當于RDD上的saveAsTextFile操作。RDD上的轉換仍然得到RDD,而RDD上的動作是返回一個本地數據類型給Driver進程,或者把RDD寫入文件系統。控制操作包括cache、persist、checkpoint等Spark內置函數,控制操作不改變RDD,也不返回本地數據類型,而是緩存RDD、設置檢查點等,用于Spark程序的性能調優。
2 相關工作
前向鏈推理在RDF數據更新后需要重新計算,計算整個閉包時間較長,但在查詢時不需要查詢以外的開銷;而后向鏈語義推理是一種推理發生在查詢時的推理方法,對RDF數據更新不敏感,但增加了查詢的時間開銷。隨著RDF數據增長速度越來越快,前向鏈語義推理的弊端逐漸顯現出來,后向鏈語義推理開始進入人們的視野。RDF數據管理系統Jena[10]使用一個類似于Prolog引擎的邏輯程序來提供對后向鏈語義推理的支持,允許自定義推理規則集,但功能較弱,單機的架構難以處理大規模RDF數據。AllegroGraph[11]是一個商用的大規模圖數據庫,它的后向鏈語義推理引擎RDFS++支持RDFS規則集和OWL規則集中的部分規則,并且有較高的性能表現。但為了提高性能,它犧牲了推理的完備性和對規則集的完整支持。Virtuoso[12]是一種基于列存儲系統的后向鏈語義推理系統,但該系統沒有進行特殊的優化,并且只支持RDFS和OWL的少部分規則。
文獻[13]和文獻[14]提出了一種對規則條件的執行次序進行優化選擇,從而提高推理效率的方法。文獻[15]提出了OLDT,這是一種避免推理樹過深和避免規則擴展陷入死循環的方法。文獻[16]和文獻[17]提出了查詢策略選擇函數,并綜合了規則條件執行次序的優化方法[13-14]、OLDT[15]和sameAs 優化方法,提出了一種優化的后向鏈推理方法。該方法是一種在單機上遞歸執行的方法,不能處理大規模RDF數據。文獻[18]提出了一種RDF數據存儲與查詢系統,支持后向鏈推理,但只支持rdfs: subClassOf、rdfs: subPropertyOf和owl: EquivalentProperty三種語義的推理。文獻[7]提出了QueryPIE,這是一種基于高性能計算平臺DAS4 的后向鏈語義推理方法,它通過對推理樹的剪枝和把RDF數據映射為數字ID來加速推理過程,支持OWL Horst規則集的后向鏈推理,具有很高的處理能力。但是,該方法存在兩個方面的不足: (1)高性能硬件加速不具有普適性;(2)把大規模RDF數據映射為數字ID存在著更新數據開銷大和推理前后的RDF數據與數字ID相互映射開銷大的問題。
3 后向鏈語義推理分析和系統設計
3.1 后向鏈語義推理過程分析
后向鏈語義推理是一種目標驅動的推理方式。表2給出了一個簡單推理規則集的例子,該規則集包含三條規則,定義了子屬性關系、對稱關系和傳遞關系。
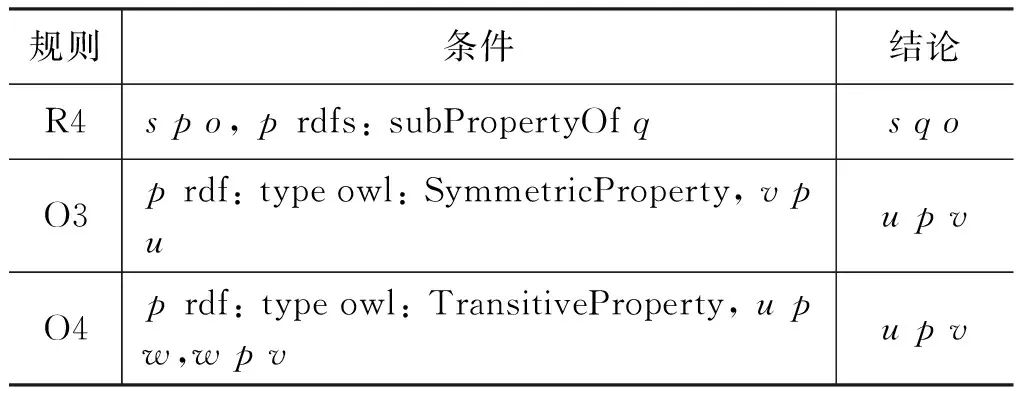
表2 簡單規則集舉例
假設要求解Lliy為誰工作,推理查詢模式是(Lily, worksFor,?who),記為Q,推理規則使用表2的簡單規則集。除了直接到知識庫里查找符合結論的三元組之外,還要考慮應用規則推導出結論。首先觀察規則,發現Q比規則R4的結論更具體,即Q是將R4結論三元組中的若干變量替換成具體RDF數據得到的。所以在推理過程中,有可能通過規則R4推理出三元組T,使得T比Q更具體。于是,將Q的主語、謂語和賓語與規則R4的結論一一對應,并實例化規則R4 的條件(即把變量s替換為“Lily”,把變量q替換為“worksFor”),就能得到兩條新的三元組模式(Lily,?p,?who)、(?p, rdfs: subPropertyOf, worksFor),這兩條三元組模式又作為新的推理查詢,同時滿足這兩條推理查詢模式的三元組將應用規則R4推導出滿足模式Q的結論。同理,規則O3和O4也能用來推導出三元組模式Q。使用表2中給出的規則集進行三元組模式Q的推理,其過程可以用一顆推理樹來表示(圖1)。
圖1中,推理樹中根節點表示推理模式Q,圓角矩形框代表所運用的規則,直角矩形框代表新的推理查詢模式。每條三元組模式下應用的規則屬于“或”的關系,而每條規則下展開的三元組模式屬于“與”的關系。這樣每個推理模式從上至下依次展開,對于每個矩形節點的三元組模式,將對知識庫進行查詢,查詢的結果從下往上使用規則推導出上層結論。在最頂層得到的推理結果就是最終的查詢結果。
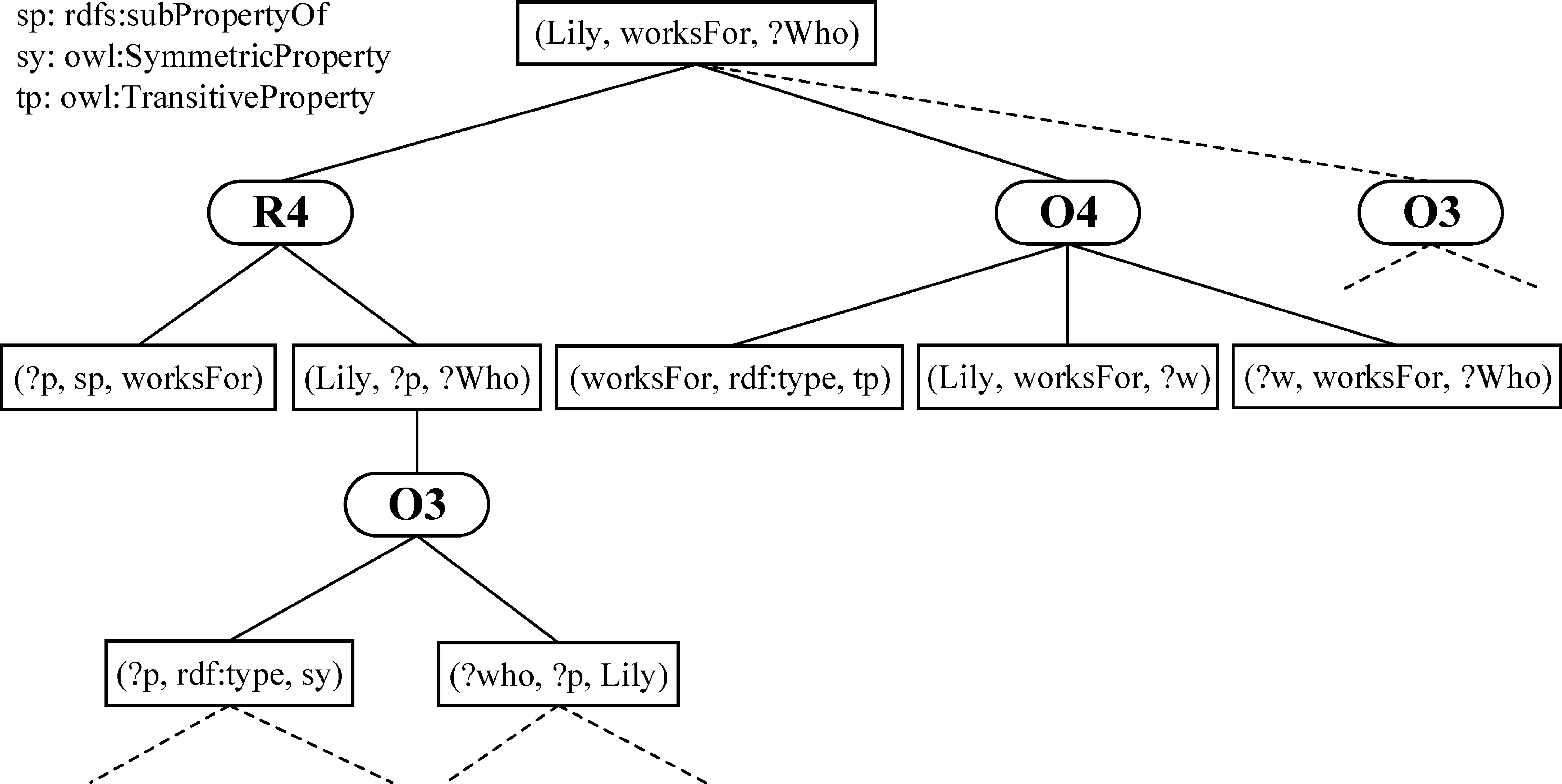
圖1 簡單規則集上的推理樹示例
3.2 后向鏈語義推理的并行化和系統設計
通過3.1節對后向鏈推理的過程分析,我們發現整個算法可以分成三個主要階段: (1)逆向推理(推理模式擴展); (2)查詢(查詢模式匹配); (3)正向推理(根據規則合并結果集)。
在逆向推理階段,推理樹被自上而下創建(圖1)。逆向推理找出能夠證明結論的隱式證據,這一過程根據給定的規則集擴展出新的推理模式,不需要操作大規模語義數據。在查詢階段,查詢模式在大規模語義數據上匹配滿足條件的三元組。這一階段需要全局地過濾語義數據,時間開銷比較大。在正向推理階段,規則應用在查詢結果集上,從而推導出結論。
結合對后向鏈語義推理過程的分析,我們把后向鏈語義推理中的查詢過程用RDD上的filter操作來實現,由各個計算節點并行計算,加快查詢過程。假設語義數據已經載入內存并以RDD表示,圖2演示了RDD上的查詢過程。
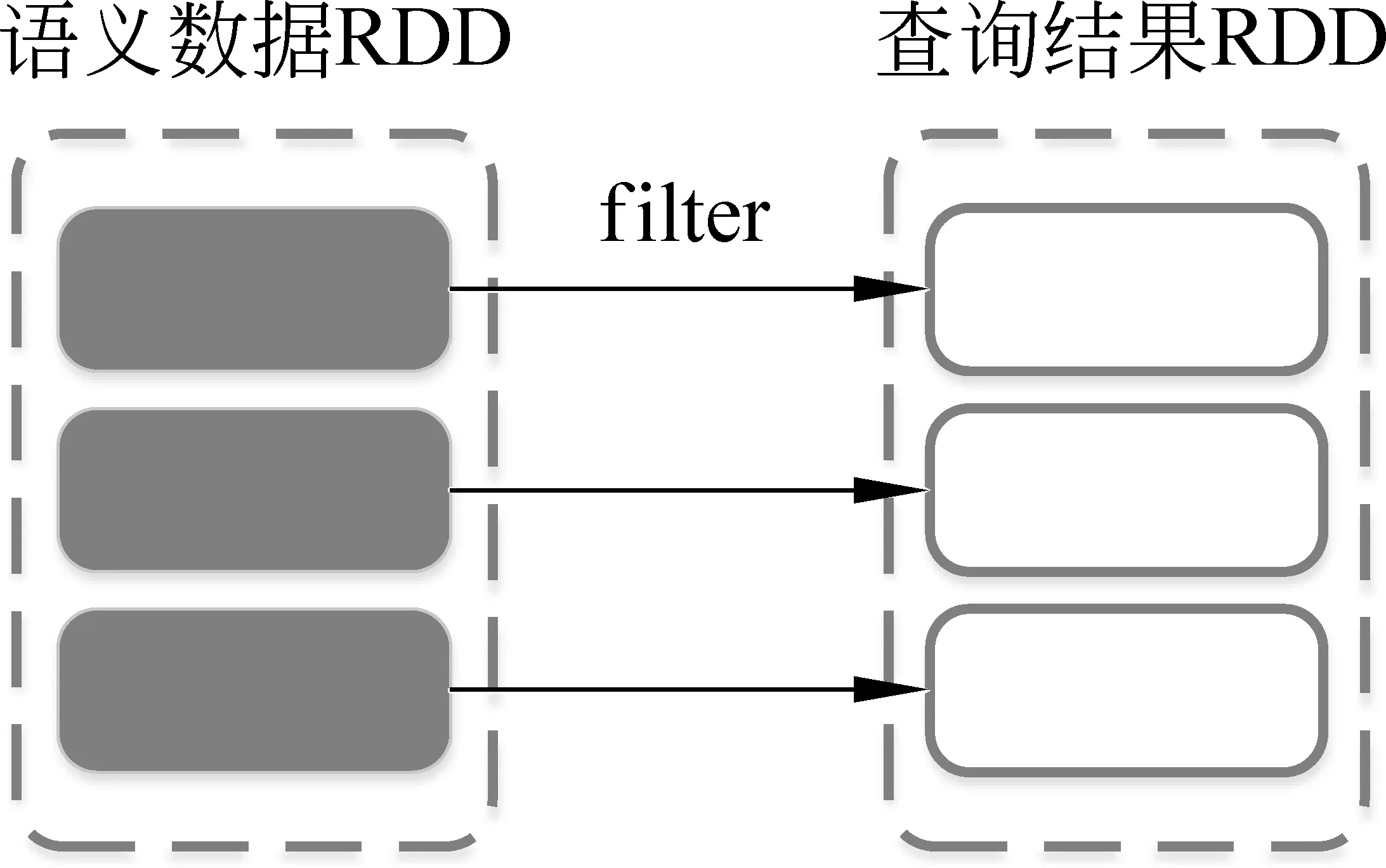
圖2 用RDD表示的查詢過程
查詢完成之后,需要在多個查詢結果上應用規則推導結論,用Spark的RDD模型來刻畫的話,就是在多個結果RDD上使用join操作,如圖3所示。
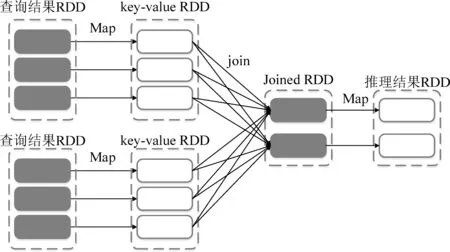
圖3 用RDD表示的正向推理過程
結合Spark大數據計算平臺的特點,本文提出了大規模并行化后向鏈語義推理方案,如圖4所示。系統架構圖中主要包含逆向推理層、存儲與查詢層、正向推理層。逆向推理層實現規則擴展,在Driver端串行執行,其中圓角矩形表示規則,直角矩形表示三元組模式,帶陰影的直角矩形是本體三元組模式。存儲與查詢層實現存儲與查詢優化,存儲上采用RDD的高級封裝形式DataFrame,虛線框表示DataFrame,查詢使用Spark SQL模塊加速。正向推理層實現在查詢結果上推導結論,根據應用的規則不同,分別使用了不同的優化方法。
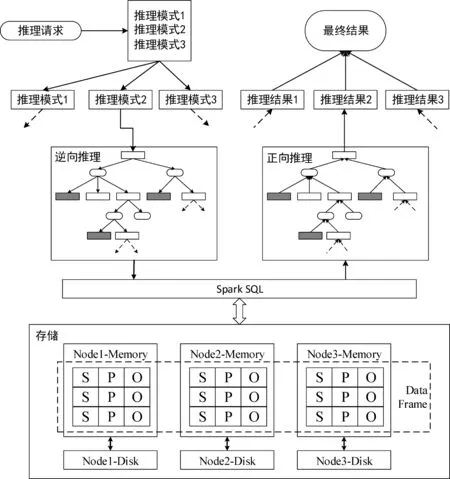
圖4 大規模并行化后向鏈語義推理系統架構
4 逆向推理與查詢優化
4.1 本體數據閉包共享
表1中,不管是RDFS還是OWL規則集,每條規則的條件總是包含至少一條本體三元組輸入,因此本體三元組模式在規則擴展的推理樹里會頻繁出現。另一方面,本體術語詞匯來自于本體描述語言,數量有限,這限制了本體模式的數量,因此在大量的后向鏈推理請求中,本體模式會被重復推理。所以本文提出了共享本體推理查詢結果的優化方法,以此降低推理查詢時的計算開銷。
4.1.1 RDFS規則集上的本體數據閉包算法
RDFS規則集中,規則R3推導出的結論可以作為規則R4的條件,而規則R4推導出的結論又可能是規則R1和規則R2的條件,分析RDFS規則間的這種依賴關系可以發現,推理結論是本體三元組的規則,規則條件都是本體三元組,因此RDFS本體三元組的推理不依賴于實例數據,在本體數據上即可完成。RDFS本體數據閉包的計算用偽代碼描述見算法1。

算法1 RDFSOntologyClosure輸入:本體三元組onto_triples輸出:本體三元組閉包rdfs_closuresc=onto_triples.filter(t=>t._2.equals(“rdfs:subClas-sOf”)) .map(t=>(t._1,t._3))DO{ inferredTriples=sc.map(t=>(t._2,t._1)) .join(sc) .filter(t=>t._2._1!=t._2._2) .map(t=>(t._2._1,t._2._2)) sc=sc.union(inferredTriples) .distinct}WHILE(schaschanged)//rdfs:subPropertyOf的計算和以上類似rdfs_closure=onto_triples.union(sc).union(sp)RETURNrdfs_closure
4.1.2 RDFS規則集上的本體數據閉包算法
從表1中OWL Horst規則集來看,OWL Horst規則集的依賴關系比RDFS規則集復雜得多,不存在一個拓撲序,并且本體三元組的推理涉及實例數據,因此不能用RDFS本體數據閉包的計算方法。在OWL本體數據閉包的計算方法中,用所有的本體三元組模式做推理查詢,這時候本體數據閉包可能缺失一些隱式的本體三元組,導致推理結果不完整。此時,把推理出來的本體三元組模式插入到本體閉包中,重新用本體三元組模式做推理查詢,并把推理結果插入到本體閉包中,如此循環,直到推理不出更多新的本體三元組,本體數據閉包就完整地計算出來了[19]。OWL本體數據閉包的計算方法用偽代碼描述如下。

算法2 OWLOntologyClosure輸入:Ontologytriples:OTKnowledgeBase:KB //instancetriplesOntologytriplepatterns:Qs輸出:Ontologyclosure:owl_closureDO Inferred-triples={} FORqINQsDO Inferred-triples+=Backward-chaining-reasoner(q) END OT.insertAll(Inferred-triples)WHILEInferred-triplesisnotemptyowl_closure=OTRETURNowl_closure
4.2 使用本體數據閉包優化的規則擴展過程
根據RDFS規則的輸出中謂語是否是rdf: type、本體詞匯或可綁定變量,可以把RDFS規則分為以下三類。
(1) 輸出三元組的謂語是本體詞匯的規則: R3、R6。
(2) 輸出三元組的謂語是rdf: type的規則: R1、R2、R5。
(3) 輸出三元組的謂語是可綁定變量的規則: R4。
在接下來的分析中,將引用4.1.1節計算的RDFS本體數據閉包rdfs_closure,并記為G1。
對于第一類規則,即規則R3 和R6,在本體三元組數據閉包已經計算出來的情況下,推理樹生長到本體三元組模式的節點,可以直接從本體閉包中讀取本體三元組模式的推理結果,因而推理樹在擴展到本體三元組模式的節點時不需要繼續擴展。
對于第二類規則,以規則R1: (p, rdfs: domain,x)&(s,p,o)=>(s, rdf: type,x)為例,根據推理模式的主語、謂語、賓語是已知還是可綁定變量,分為七種組合情況。這里,對于主、謂、賓都是自由變量的完全查詢模式不予討論。其原因一是沒有限制條件的查詢沒有實際意義,二是這將導致后向鏈推理引擎推理出所有蘊涵知識,相當于做了前向鏈推理的事情,失去了后向鏈推理的意義。實際上,在應用規則擴展查詢的過程中,也不會產生主、謂、賓全都是變量的模式(規則擴展過程中被優化掉了)。所以在本文中不再討論推理模式中主、謂、賓都是變量的情況。
(1) 推理模式中只有主語為變量(?subj, pred, obj)。這種情況下,將推理模式帶入規則R1,發現推理模式的謂語pred一定是rdf: type,否則無法由規則R1推出。在謂語是rdf: type的情況下,規則R1可擴展該查詢,得到兩個新的推理模式(?p, rdfs: domain, obj)和(?subj, ?p, ?o)。這些新的推理模式作為推理樹的分支,即推理樹在該分支生長,生成的分支也就是新的推理模式,可以繼續遞歸地做推理查詢。
(2) 推理模式只有謂語為變量(subj, ?pred, obj)。這種情況下,規則R1推導的結論里謂語是rdf: type,即如果規則R1對該推理模式有貢獻,貢獻一定是(subj, rdf: type, obj)。而(?p, rdfs: domain, obj)&(subj, ?p, ?o)=>(subj, rdf: type, obj),本體三元組模式(?p, rdfs: domain, obj)在本體閉包G1中找出所有?p的集合p_set,對每一個p∈p_set,有新的推理模式(subj, p, ?o),這些新模式作為推理樹的分支,即推理樹在該分支生長,生成的每個分支繼續遞歸地做推理查詢。
(3) 推理模式只有賓語為變量(subj, pred, ?obj)。這種情況下,推理模式的謂語pred等于rdf: type,否則規則R1對該推理模式沒有貢獻。推理模式代入規則R1后,有: (subj, pred, ?obj)<=(?p, rdfs: domain, ?obj)&(subj, ?p, ?o)。對這兩個新的推理模式的處理有兩種方式,一種是綁定變量方式,另一種是自由變量方式。
(4) 推理模式中主語和謂語都是變量(?subj, ?pred, obj)。這種情況下,應用規則R1把推理模式的謂語綁定為rdf: type,推理模式變為(?subj, rdf: type, obj),即退化為(1)中的情況。
(5) 推理模式中主語和賓語都是變量(?subj, pred, ?obj)。這種情況下,推理模式的謂語pred一定等于rdf: type,否則不能由規則R1推導出來。對每一個pi,rdfs: domain,obji∈G1(pi, rdfs: domain, obji)∈G1,代入規則R1后,有(?subj,pi,?o)=>(?subj,rdf: type,obji)(?subj, pi,?o)=>(?subj, rdf: type,obji),即在該節點將產生新的分支(?subj,pi,?o)(?subj, pi, ?o)。
(6) 推理模式中謂語和賓語都是變量(subj, ?pred, ?obj)。這種情況下,綁定推理模式中的謂語“?pred”為rdf: type,推理模式變為(subj, rdf: type, ?obj),即退化為(3)中的情況。
(7) 推理模式是無參三元組模式(subj, pred, obj)。這種情況下,推理模式謂語pred一定等于rdf: type,否則規則R1不能推導出該模式。代入規則R1后,有(?p, rdfs: domain, obj)&(subj, ?
p, ?o)=>(subj, rdf: type, obj)。對于每一個pi,rdfs: domain,obj∈G1(pi, rdfs: domain, obj)∈G1,有(subj,pi,?o)=>(subj,rdf: type,obj)(subj,pi,?o)=>(subj,rdf: type,obj),其中,(subj,pi,?o)(subj,pi,?o)是推理樹的新分支。
對于第三類規則,即規則R4: (s,p,o)&(p, rdfs: subPropertyOf,q)=>(s,q,o),規則的結論是完全推理模式,與任意推理模式兼容。三元組推理模式pattern根據主語、謂語和賓語是已知量還是自由變量,可以分為七種情況進行類似的處理: 推理模式中只有主語為變量(?subj, pred, obj)、推理模式中只有謂語為變量(subj, ?pred, obj)、推理模式中只有賓語為變量(subj, pred, ?obj)、推理模式中主語和謂語都是變量(?subj, ?pred, obj)、推理模式中主語和賓語都是變量(?subj, pred, ?obj)、推理模式中謂語和賓語都是變量(subj, ?pred, ?obj)、推理模式是無參三元組模式(subj, pred, obj)。
4.3 快速剪枝優化
在一個三元組模式擴展的推理樹中,同一條分支上的不同節點可能擁有相同的變量,同一個變量在不同節點上必須滿足不同的三元組模式。如果不同節點上的三元組模式推理出的該變量集合沒有交集,那么該分支不會產生最終的有效推理結果。例如,對于圖1中最深層的規則O3擴展出的兩個新的三元組模式(?p, rdf: type, owl: SymmetricProperty)和(?who, ?p, Lliy)。其中的變量?p 和 ?who 與上層規則R4的兩個條件模式(?p, rdfs: subPropertyOf, worksFor)和(Lyli, ?p, ?who)中的變量?p 和 ?who指代相同。如果某兩個模式中的同一變量的解空間沒有交集,則該分支的推理結果也是空集。
對于較為容易判斷的本體三元組模式(?p, rdfs: subPropertyOf, worksFor)和(?p, rdf: type, owl: SymmetricProperty),如果推理中能快速判斷出沒有同時滿足這兩個模式的RDF數據項,那么該推理分支就可以直接丟棄,省去了進一步的推理計算過程。實際上,在4.2節基于本體閉包的規則擴展優化基礎上,對于同一推理分支上的兩個本體三元組模式,可以快速判斷結果集是否有交集。利用這一優化方案能夠快速剔除一些無效的計算分支。
4.4 基于Spark SQL的查詢優化
針對后向鏈語義推理中涉及多次查詢,并且正向推理階段需要在查詢結果上做連接的需求,本節提出一種基于底層分布式計算框架Spark的RDF數據存儲方案和使用Spark SQL進行查詢的執行方案。
Spark SQL[20]是Apache Spark的一個組件,使得用戶可以在Spark上進行數據的關系操作。Spark SQL對RDD進行了更高級的封裝,稱為DataFrame,用來支持數據的存儲和操作。另外在查詢作業的各個階段,Spark SQL也設計了若干優化方式提升查詢作業的性能。
Spark的核心數據結構是RDD,RDD可以看作是Java對象的集合,Spark并不能看到Java對象內部的細節。與RDD類似,DataFrame也是一個分布式數據容器,但是DataFrame內部除了數據以外,還維護了數據的結構信息,即Schema,兩者組合使得DataFrame看起來更像傳統數據庫中的一張二維表。這兩種組織結構的區別見圖5。
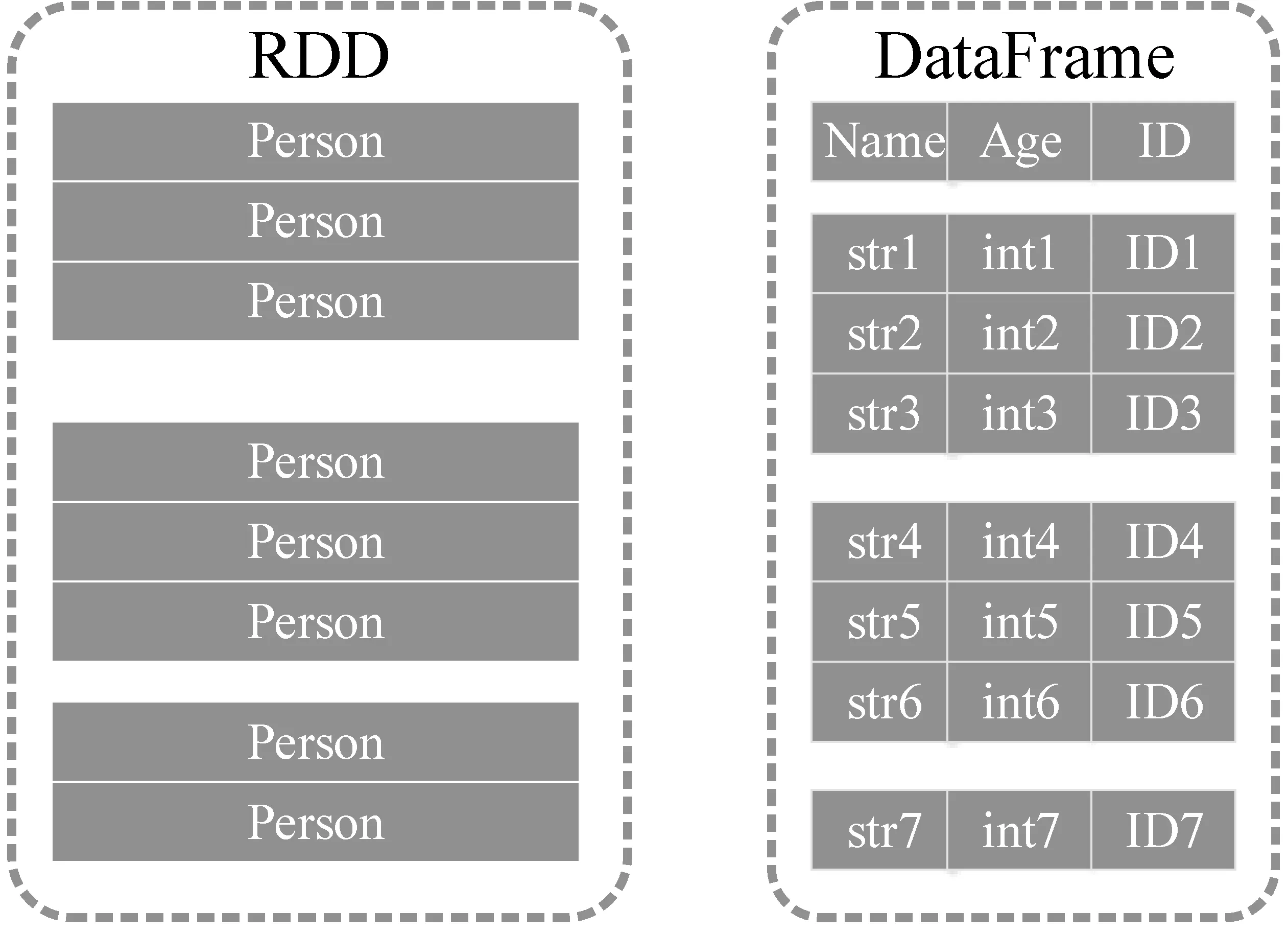
圖5 RDD與DataFrame結構的差異
由于Spark對RDD元素的內部細節一無所知,所以RDD包含的數據進入內存(觸發計算或者cache)時是按行存儲的。而DataFrame的數據進入內存時,是按列存儲的,這樣做有兩個好處。
(1) Spark可以根據DataFrame中列的類型信息,用更有針對性的結構存儲每列的數據,有利于壓縮數據以提升操作性能。Spark SQL的查詢優化器還能對查詢列的類型進行針對性的優化。
(2) 在行存儲的情況下,數據的每一行會生成一個Java對象;在大數據的情況下,行存儲會生成數量繁多的小對象,對Java GC造成巨大壓力。而使用列存儲的方式,每列數據只會生成一個或幾個對象(在大數據情況下為了防止單個對象過大,每列會生成幾個對象),對象的數目顯著降低,Java GC的壓力也會隨之減輕。
此外,Spark SQL在查詢作業的不同階段設計了若干優化方式。謂詞下推是一個使得過濾操作提前進行的優化措施。由于DataFrame也具有RDD惰性計算的特性,這就使得Spark SQL可以分析整個查詢作業,將過濾操作(filter等)盡可能前推,甚至可以前推到讀取數據時,從而有效地減少參加運算和傳輸的數據量。列剪枝也是一種精簡數據量的技術,由于DataFrame是按列組織的,同時具有Schema信息,使得Spark SQL可以分析查詢作業,精簡掉查詢過程中不需要的列,減少參與運算和傳輸的數據量。
由于Spark SQL和DataFrame的上述優勢,本文將后向鏈語義推理的查詢和正向推理階段表達成一系列對DataFrame的查詢作業。
本系統將經過規則作用擴展出的若干相互之間為“與”關系的三元組包裝為一個請求。在3.1節的例子中,三元組(Lily,?p,?who)和(?p, rdfs: subPropertyOf, worksFor)是被規則R4作用擴展出來的,于是會被包裝為一個請求。當請求中的所有三元組都不能利用規則進行擴展時,就應觸發查詢與正向推理。若三元組中存在本體術語詞,則直接在本體閉包中查詢,否則應在實例數據中查詢。
得到每個請求的結果后,結果就可以沿著推理樹向上前進,與其他分支產生的結果進行合并。如此循環往復,直到所有結果前進到樹根,原問題得解。
基于Spark SQL的查詢過程用偽代碼描述如下。

算法3 基于SparkSQL的查詢過程輸入:一個查詢請求:query:Set
5 性能評估
5.1 實驗環境與設置
本節我們從推理時間、數據可擴展性和計算節點可擴展性三個方面對本文提出的系統進行評估,實驗使用的集群節點配置如表3所示。
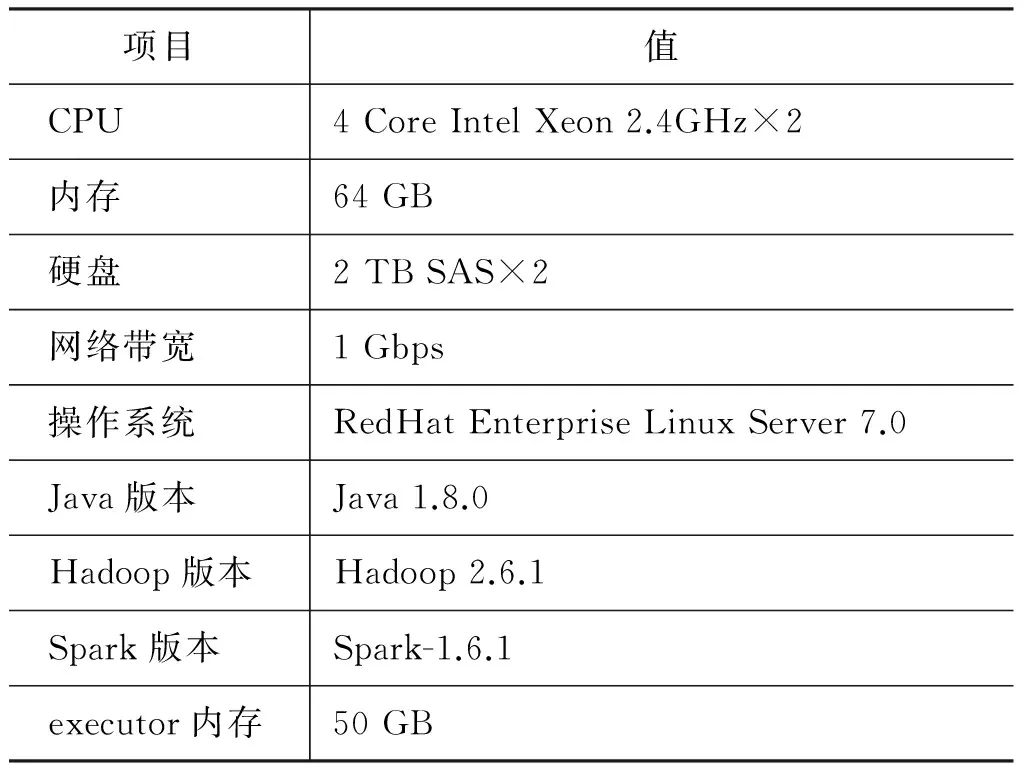
表3 計算節點配置表
5.2 實驗環境與設置
5.2.1 合成數據集及測試樣例
The Lehigh University Benchmark(LUBM)[21]提供標準的本體數據集和用于生成實例數據集的數據生成工具,并且包含一組標準查詢測試樣例,可用于測試查詢性能也可以用于測試后向鏈語義推理性能。使用LUBM可以生成任意規模的模擬數據集,給語義推理系統的性能測試帶來了方便。
實驗中使用了LUBM-100、LUBM-200、LUBM-400、LUBM-600、LUBM-800、LUBM-1000六種規模不同的LUBM數據,分別包含13 million、25 million、50 million、78 million、100 million、133 million條三元組。下文將此數據集簡稱為LUBM數據集。實驗使用LUBM Benchmark提供的14條標準查詢樣例進行測試。
5.2.2 真實數據集及測試樣例
DBpedia[22]是在社區共同努力下從Wikipedia抽取的結構化數據集,數據來源多領域、多語言,允許用戶從中查詢維基百科的數據以及從維基百科連接到的其他數據源。本文實驗使用DBpedia英文版數據,包含DBpedia-50、DBpedia-100、DBpedia-150和DBpedia-200四組數據,分別包含50 million、100 million、150 million和200 million條三元組。下文將此數據集簡稱為DBpedia數據集。本文篩選了四個用于DBpedia測試的樣例,包含兩個簡單推理模式和兩個復雜推理模式。DBpQ1用于推理Alanthurai所屬的國家;DBpQ2用于推理英文DBpedia中所有的游戲;DBpQ3用于推理意大利制作的所有電影;DBpQ4用于推理所有國家及其首都。
5.3 實驗環境與設置
5.3.1 推理性能測試
性能實驗使用的Spark和HDFS集群由一個主節點和12個計算節點組成,每個節點的軟件和硬件配置見表3。本系統在LUBM數據集上的推理查詢性能實驗結果如圖6和圖7所示。
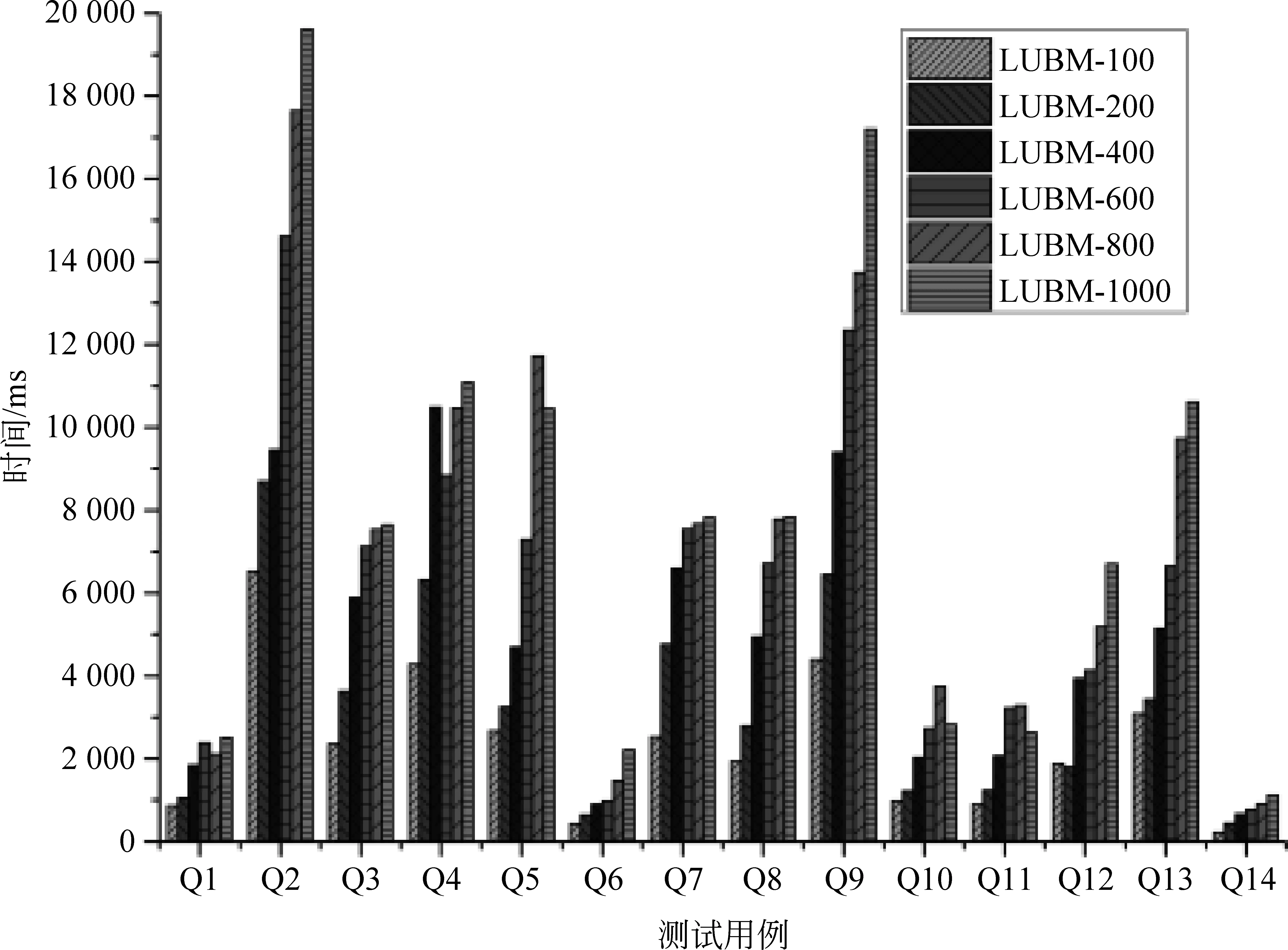
圖6 在LUBM數據集上基于RDFS規則集的推理性能
由圖6和圖7所示的實驗數據可見,在兩個規則集上本系統的性能表現差異不大。在一千萬條LUBM數據規模上,簡單推理查詢(如Q1、Q6、Q10、Q11、Q14)都可以在幾百毫秒的時間級別上完成推理,復雜的推理查詢(如Q2、Q4、Q9等)都可以在秒級完成;在一億三千萬條LUBM數據規模上,推理時間有所升高,但也都可以在32s內完成推理。
本系統在DBpedia數據集上的推理查詢性能實驗結果如圖8和圖9所示。
由實驗數據可見,本系統在推理實驗選取的四個推理模式時,可以在一兩億條三元組的真實數據集上完成秒級的后向鏈推理。
觀察兩個規則集下處理推理請求的時間,發現處理基于OWL規則集的推理請求要比基于RDFS規則集的推理請求更為耗時。這是因為OWL后向鏈推理是在RDFS后向鏈推理的基礎上提出的,不僅完全包含RDFS規則集,而且OWL規則集的復雜度就像其描述能力一樣比RDFS規則集高出許多。但是在實驗中發現,OWL的后向鏈推理性能與RDFS相比雖有差異,但并沒有差太多。原因有兩點,一是數據集的復雜度不高,二是OWL規則集比RDFS規則集多出來的規則沒有像RDFS規則集那么廣泛地被應用。
對比LUBM數據集和DBpedia數據集上的實驗后發現,基于Spark的并行化語義后向鏈推理系統不管是在合成數據集上還是在真實數據集上,都能在幾秒到幾十秒的時間內完成后向鏈語義推理,表現出了很好的推理性能。對于數據頻繁更新的知識庫來說,后向鏈語義推理每次幾十秒的開銷相對于前向鏈推理動輒幾十分鐘甚至幾個小時[23]來說進步很大。
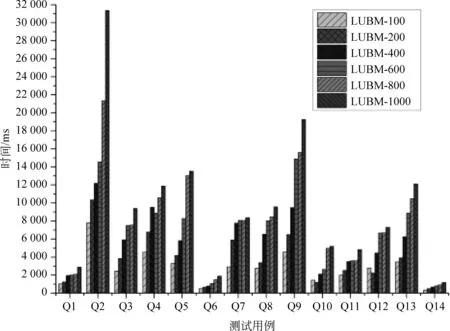
圖7 在LUBM數據集上基于OWL規則集的推理性能
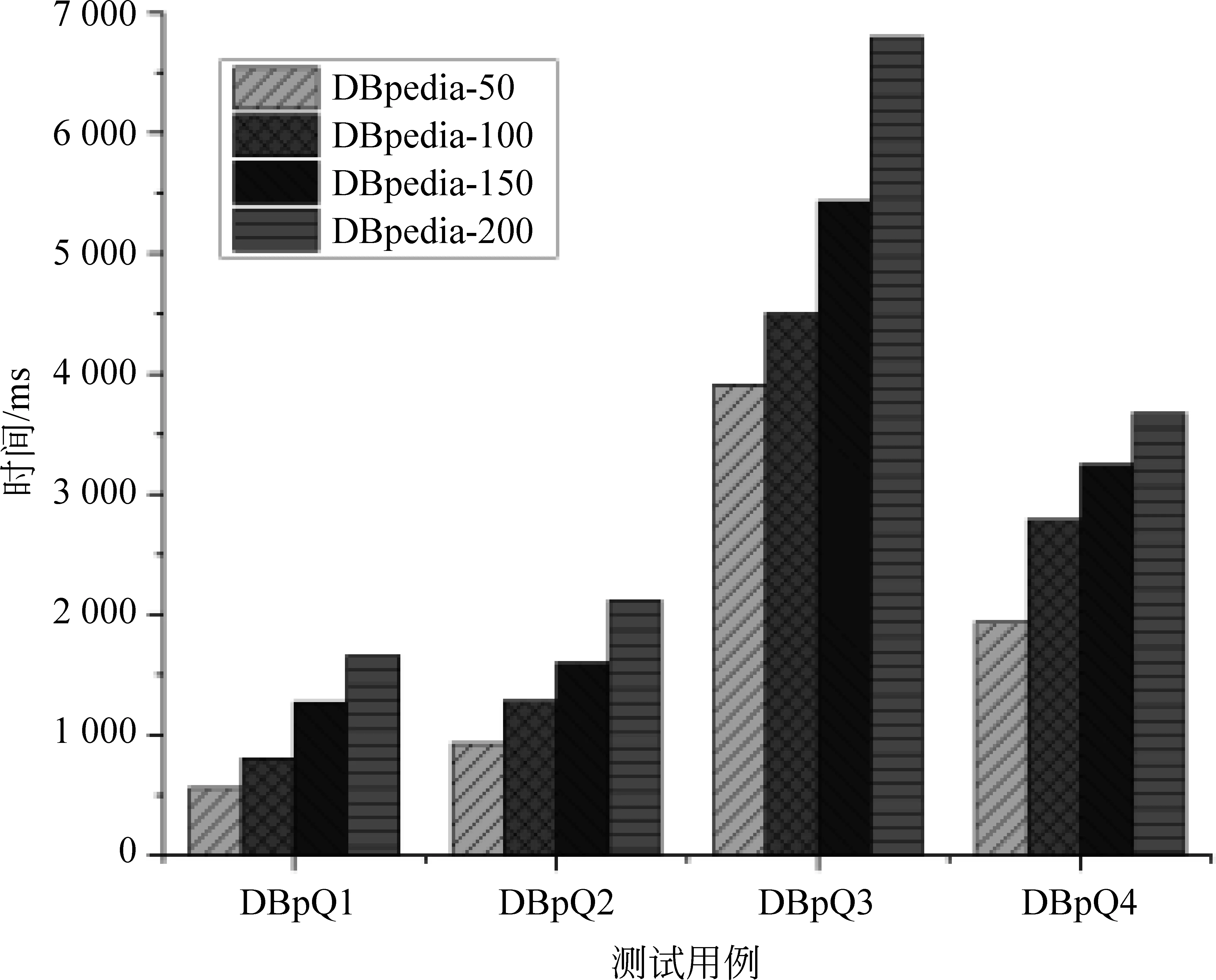
圖8 在DBpedia數據集上基于RDFS規則集的推理性能
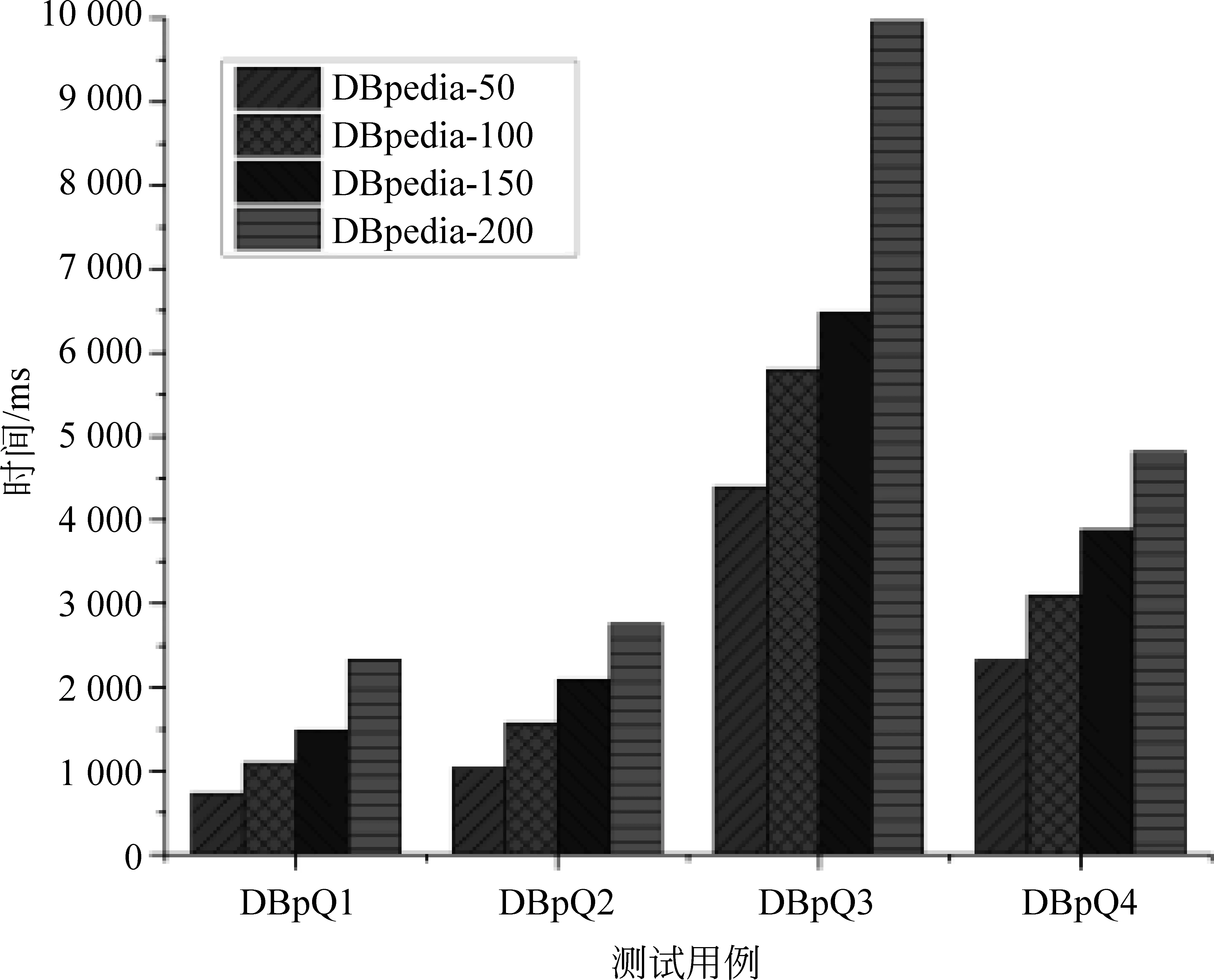
圖9 在DBpedia數據集上基于OWL規則集的推理性能
5.3.2 數據可擴展性測試
一個設計良好的大規模語義推理系統應當能夠處理各種規模的數據。為了考察系統的數據可擴展性,在保證計算集群的環境配置不變的情況下,測試本系統在不同數據規模下的執行時間。同時,語義推理不只對規則復雜度敏感,數據的復雜度也會對結果產生影響。實驗中選用的LUBM大學數據由工具生成,數據復雜度不隨規模變化。下面,本系統會基于RDFS和OWL規則集,分別進行數據擴展性實驗。在LUBM數據集上,本系統的數據可擴展性如圖10和圖11所示。
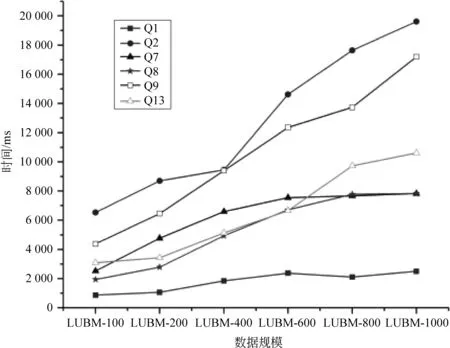
圖10 數據擴展性實驗(LUBM+RDFS)
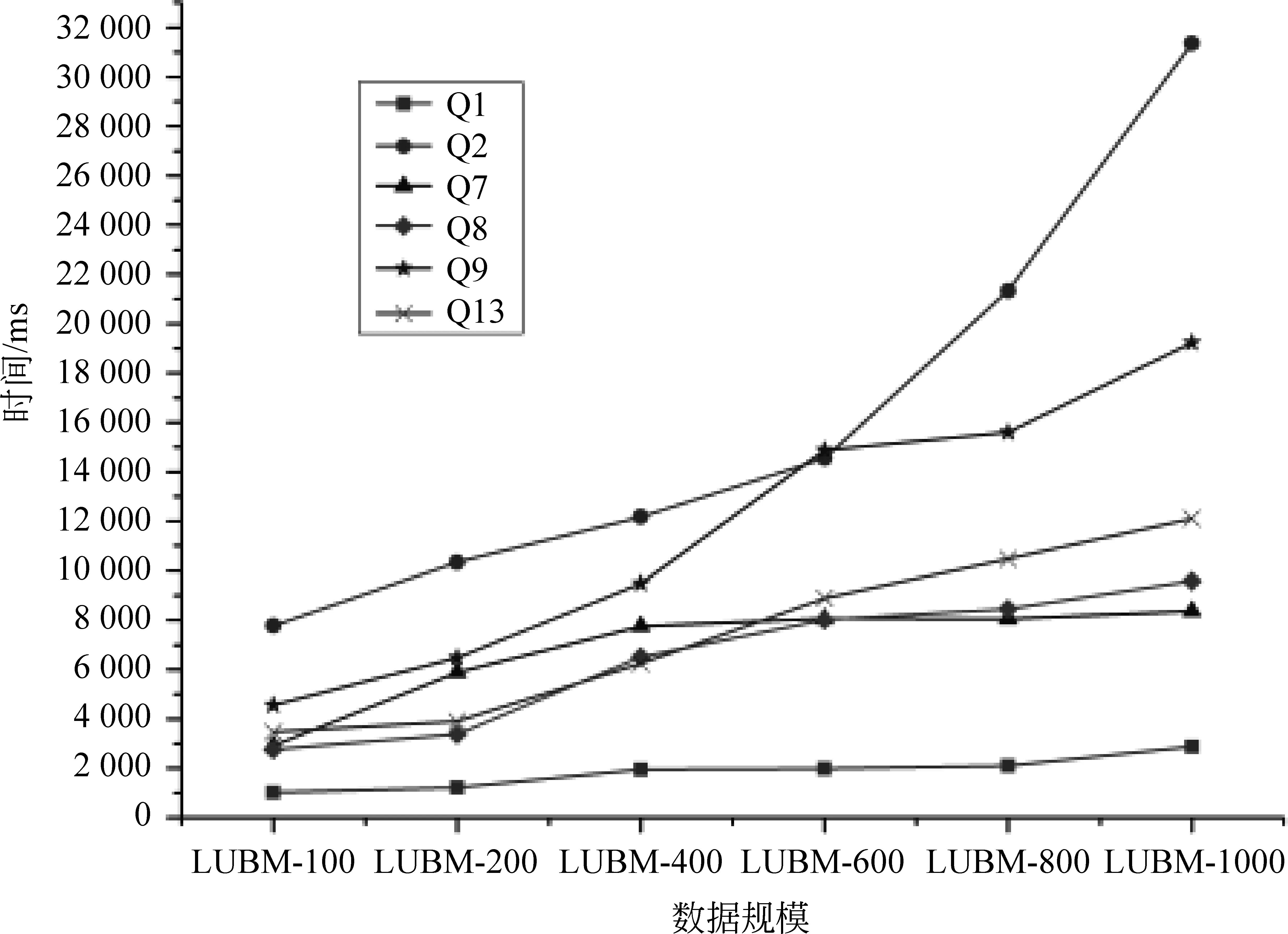
圖11 數據擴展性實驗(LUBM+OWL)
實驗數據顯示,本系統在兩個規則集下再次表現出了類似的趨勢。在LUBM benchmark的14條標準查詢里,Q2和Q9是非常復雜的推理模式,分別包含了六條簡單推理模式,在折線圖中可以看出,這兩條查詢隨著數據規模變大,推理時間明顯增長。Q7和Q8屬于中等難度的推理模式,Q1和Q13都是包含兩條簡單推理模式的復合模式,復雜度較Q7和Q8低,所以Q1的推理時間隨數據規模變化最不明顯,而Q13的推理時間升高應該是推理結果隨著數據規模變大而變化的原因。
由此可見,基于Spark的并行化語義后向鏈推理系統的推理時間隨著數據規模的擴大都是近線性上升,表現出了很好的數據可擴展性。
5.3.3 節點可擴展性測試
大規模語義推理使用分布式并行計算技術進行加速,一個擴展性好的系統,應該在增加節點時能提高處理速度,而在減少節點時則會增加處理時間。本文實驗使用LUBM 1 000個大學數據集,在計算節點從一個增加到16個時觀察系統的推理性能,得到系統推理時間隨計算節點數的變化關系,實驗結果見圖12、圖13。
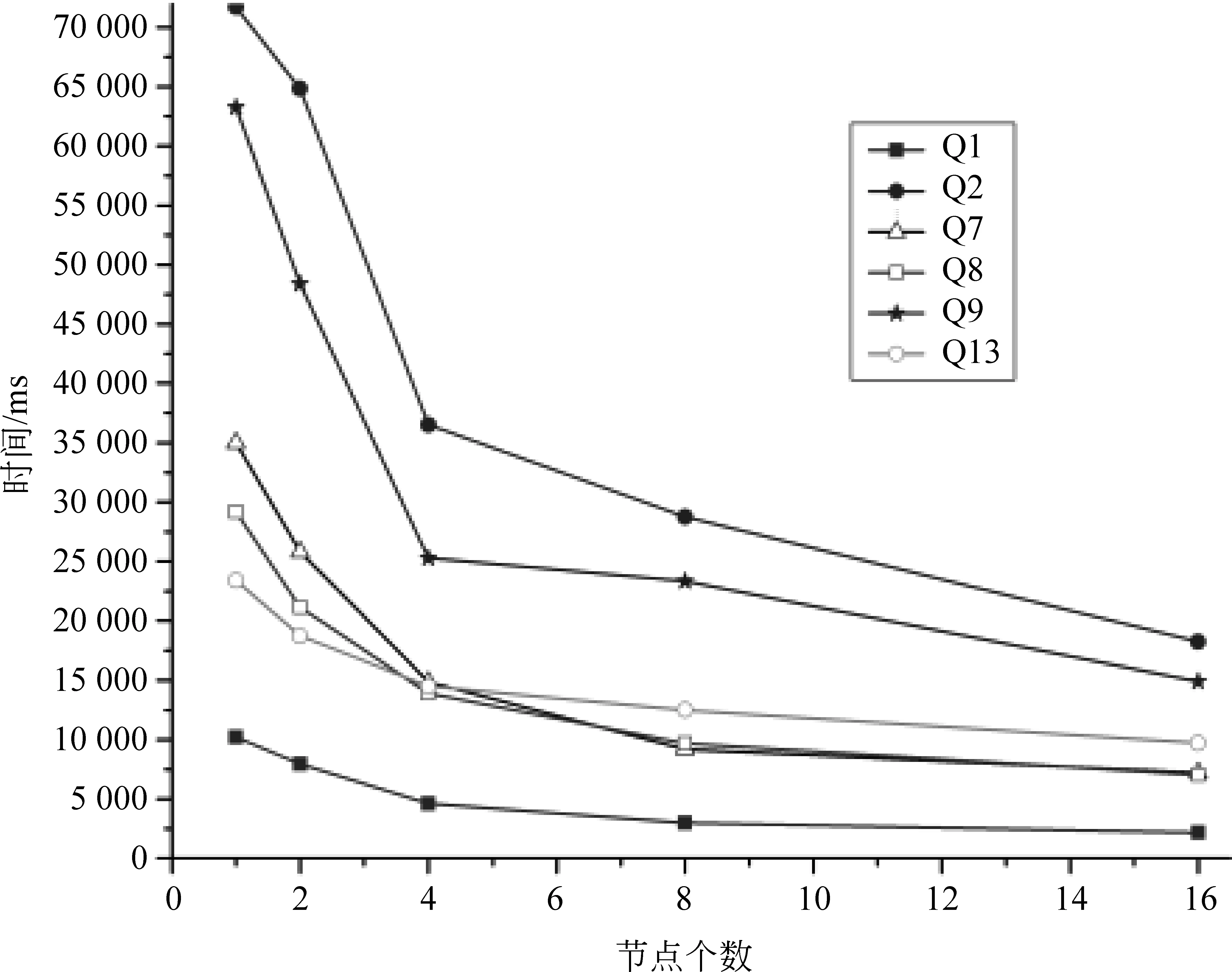
圖12 基于RDFS規則集的節點可擴展性
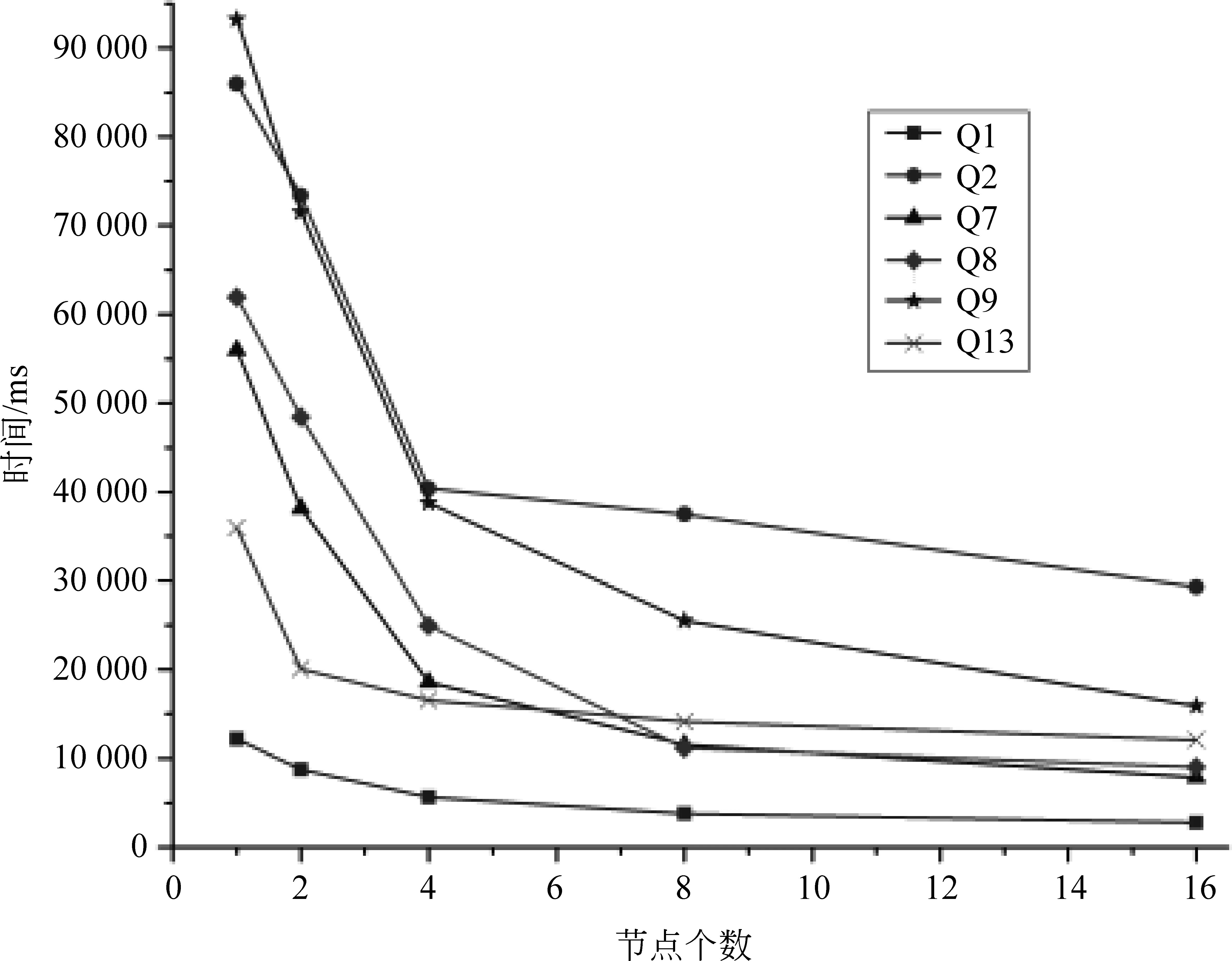
圖13 基于OWL規則集的節點可擴展性
由實驗數據可知,越是耗時的推理,增加計算節點獲得的性能提升越明顯。將實驗結果整理成相對加速比,如圖14和圖15所示。相對加速比(S)是指同一算法在單節點環境下的執行時間(T1)和多節點(n個)環境下的執行時間(Tn)的比值,即s=T1/Tn。
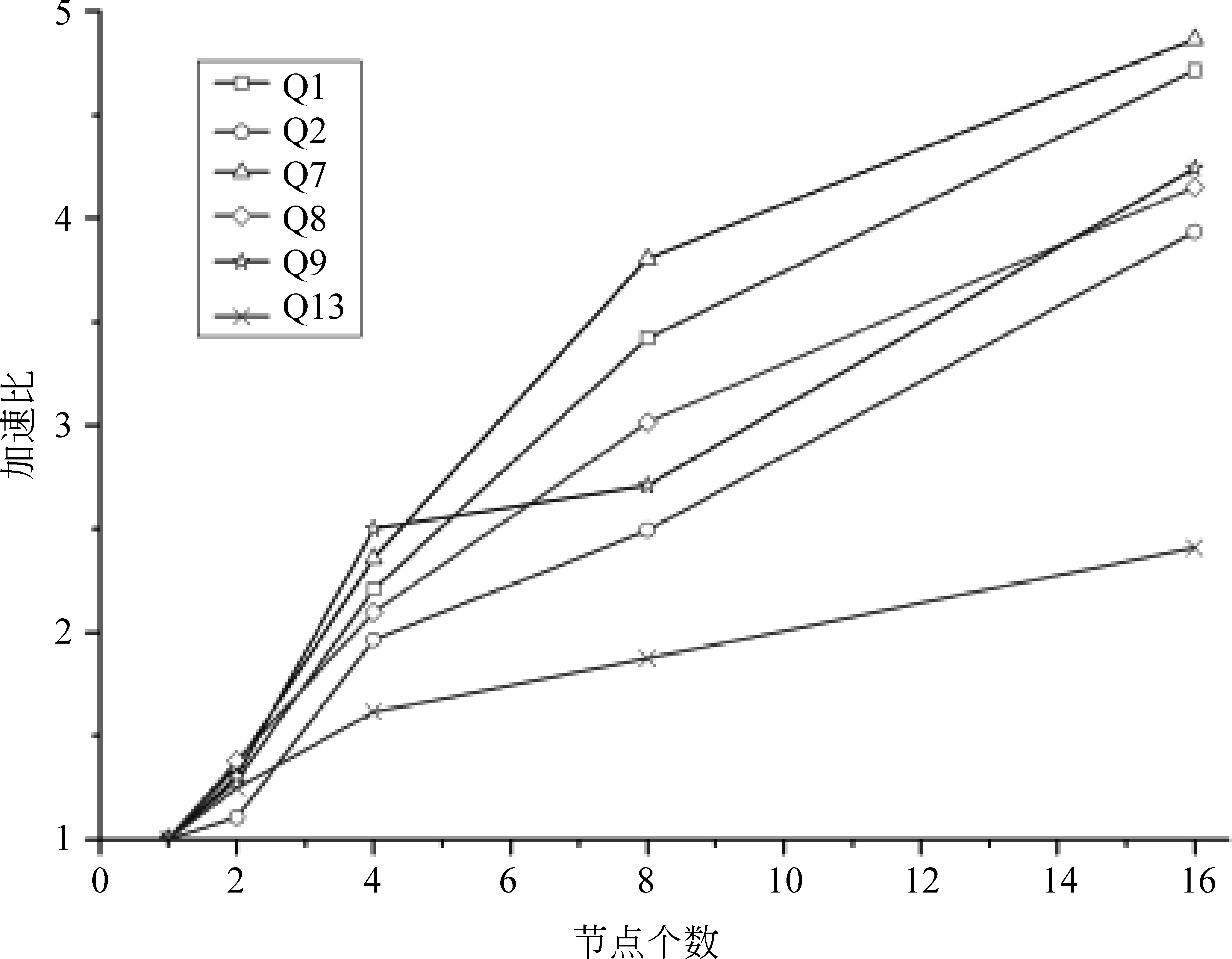
圖14 基于RDFS規則集的加速比
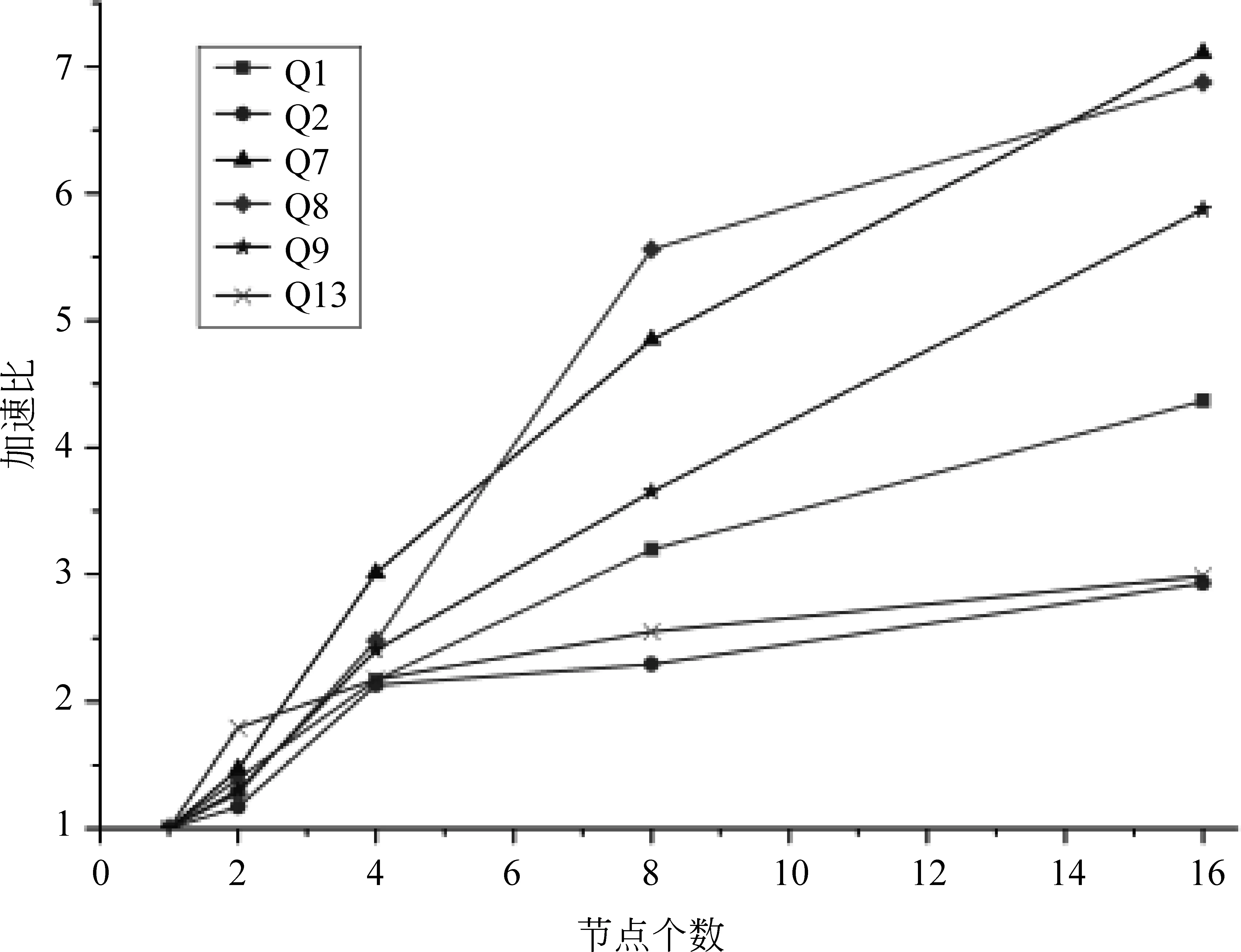
圖15 基于OWL規則集的加速比
加速比曲線顯示,多數推理模式隨著計算節點數的增加,表現出了明顯的加速趨勢,所以本文提出的基于Spark的并行化語義后向鏈推理系統具有較好的節點可擴展性。
6 總結
語義推理是語義網技術體系中的高級分析技術,得到了工業界和學術界的廣泛關注和研究,在輔助藥物開發、社交關系分析等領域已經有成功應用。雖然前向鏈和后向鏈語義推理的目的相同,但到目前為止,人們提到語義推理主要還是指前向鏈語義推理,對語義推理的研究也主要集中在前向鏈方法上,后向鏈語義推理的研究因為推理過程復雜而進展緩慢。如今的互聯網信息日新月異,前向鏈語義推理對于知識庫更新而帶來高昂代價的缺點逐漸顯露,后向鏈語義推理的準實時推理查詢、對知識庫更新不敏感等特點恰好適用于知識快速更新的場景。因而設計實現高效的大規模后向鏈語義推理系統成為了新的研究課題。本文提出的基于Spark的大規模并行化語義規則后向鏈推理方法實現了并行化的后向鏈語義推理,并且在多方面進行了優化,實現了較好的推理性能。
在將來的工作中,我們將繼續研究在更加復雜的規則集上進行后向鏈推理,并研究大規模RDF數據的快速編碼和解碼方法,進一步提高推理系統的表達能力和推理速度。
[1] Pelikánová Z. Google Knowledge Graph[DB/OL]. https: //www.google.com/intl/es419/insidesearch/features/search/knowledge.html[2014].
[2] Dean J, Ghemawat S.MapReduce: Simplified data processing on large clusters[J]. Communications of the ACM, 2008, 51(1): 107-113.
[3] Zaharia M, Chowdhury M, Franklin M J, et al. Spark: Cluster computing with working sets[J]. HotCloud, 2010(10): 10-10.
[4] W3C. RDF vocabulary description language 1.0: RDF schema[S]. https: //www.w3.org/TR/2004/REC-rdf-schema-20040210/
[5] McGuinness D L, Van Harmelen F. OWL web ontology language overview[J]. W3C Recommendation, 2004, 10(10): 10-20.
[6] Urbani J, Oren E, Van Harmelen F. RDFS/OWL reasoning using the MapReduce framework[J]. Science, 2009: 1-87.
[7] Urbani J, Van Harmelen F, Schlobach S, et al. QueryPIE: Backward reasoning for OWL Horst over very large knowledge bases[J]. The Semantic Web-ISWC 2011, 2011: 730-745.
[8] 施惠俊.基于云計算的海量語義信息并行推理方法研究[D].上海: 上海交通大學碩士學位論文,2012.
[9] 瞿裕忠,胡偉,程龔. 語義網技術體系[M]. 北京: 科學出版社, 2015: 32-60.
[10] Carroll J J, Dickinson I, Dollin C, et al. Jena: Implementing the semantic web recommendations[C]//Proceedings of the 13th International World Wide Web Conference on alternate Track Papers & Posters. ACM, 2004: 74-83.
[11] Franz Inc. Allegro graph: RDF triple database. [DB/OL] https: //franz.com/agraph/allegrograph/
[12] Erling O. Virtuoso, a hybrid RDBMS/Graph column store[J]. IEEE Data Eng. Bull., 2012, 35(1): 3-8.
[13] Marriott K, Stuckey P J. Programming with constraints: An introduction[M].Cambridge: MIT press, 1998: 4-9.
[14] Santos J, Muggleton S. When does it pay off to use sophisticated entailment engines in ILP?[M]. Inductive Logic Programming. Berlin: Springer Berlin Heidelberg, 2010: 214-221.
[15] Tamaki H, Sato T. OLD resolution with tabulation[C]//Proceedings of the 3rd International Conference on Logic Programming.Berlin: Springer Berlin Heidelberg, 1986: 84-98.
[16] Shi H, Maly K, Zeil S. Optimized backward chaining reasoning system for a semantic web[C]//Proceedings of the 4th International Conference on Web Intelligence, Mining and Semantics(WIMS14). ACM, 2014: 34.
[17] Shi H, Maly K, Zeil S. Query optimization in cooperation with an ontological reasoning service[C]//Proceedings of the fifth International Conferences on Advanced Service Computing.Valencia: SERVICE COMPUTATION, 2013: 26-32.
[18] Punnoose R, Crainiceanu A, Rapp D. Rya: a scalable RDF triple store for the clouds[C]//Proceedings of the 1st International Workshop on Cloud Intelligence. ACM, 2012: 4.
[19] Jacopo Urbani. Proof of correctness of QueryPIE closure algorithm[DB/OL]. http: //citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.419.3998
[20] Armbrust M, Xin R S, Lian C, et al. Spark SQL: Relational data processing in spark[C]//Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data. ACM, 2015: 1383-1394.
[21] Guo Y, Pan Z, Heflin J. LUBM: A benchmark for OWL knowledge base systems[J]. Web Semantics: Science, Services and Agents on the World Wide Web, 2005, 3(2): 158-182.
[22] Auer S, Bizer C, Kobilarov G, et al. Dbpedia: A nucleus for a web of open data[M].Berlin: Springer Berlin Heidelberg, 2007.
[23] Urbani J, Kotoulas S, Oren E, et al. Scalable distributed reasoning using mapreduce[M].Berlin: Springer Berlin Heidelberg, 2009.
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
開放教育研究(2020年2期)2020-03-31 01:54:14
幸福(2018年33期)2018-12-05 05:22:42
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
中國科技信息(2016年14期)2016-07-31 21:16:32
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
