基于半參數估計的非隨機缺失樣本分類
2018-05-11 07:36:53夏利宇劉賽可
統計與決策 2018年8期
夏利宇,王 蕾,劉賽可
(中國人民大學 應用統計科學研究中心,北京100872)
0 引言
因變量非隨機缺失在統計應用領域較為常見,例如信用評級領域的拒絕推斷難題、市場營銷中無偏好客戶的不響應問題、微觀調查中敏感問題的無回答現象等。實踐中,相比樣本中的完備數據,人們對非隨機缺失數據分析更感興趣,例如預測貸款客戶違約概率、不響應客戶的消費偏好、無回答者的真實特征,這可以拓展業務領域和研究范圍,往往能成為創造經濟利益和解答關鍵問題的途徑。學界中,非隨機缺失問題因為樣本的刪失結構破壞了其他完備樣本對總體的代表性,進而導致參數估計的有偏與非一致而受到普遍關注。引入數據缺失機制來預測非隨機缺失樣本的特征,解決樣本代表性偏差帶來的問題,探尋效果優良的統計模型對非隨機缺失數據分析至關重要。
Rubin(1976)[1]根據因變量和自變量對因變量缺失的影響,將缺失機制分為隨機缺失(MAR)、完全隨機缺失(MCAR)和非隨機缺失(MNAR)三類。在MAR和MCAR情況下,因變量缺失與其自身無關,可以直接刪除含缺失數據的樣本推斷總體性質;而在MNAR情況下,因變量缺失與其自身有關,建模時必須考慮數據的缺失機制。Graham和Donaldson(1993)[2]證明,直接刪除非隨機缺失樣本建模將導致參數估計的有偏與非一致,填補非隨機數據后,建模效果將顯著提升。Heckman(1979)[3]提出了處理因變量非隨機缺失的Heckman兩步法,通過兩個Probit模型還原了樣本選擇過程和結果發生過程,該方法思路清晰,但在實際應用中效果不佳。Banasik和Crook(2007)[4]詳細說明了處理非隨機缺失問題的擴張法,該方法因假定缺失數據與非缺失數據具有相同的數據分布而無法得到學界的廣泛認可。
本文將借鑒Kim和Yu(2011)[5]非隨機缺失數據均值泛函估計的思想,將其一元核函數拓展成多元核函數,運用基于指數傾斜的半參數模型預測樣本屬于各類的發生概率,解決MNAR情形下的樣本二分類問題。
1 研究方法
1.1 非隨機數據的半參數估計模型
非隨機缺失數據均值泛函的半參數估計方法因其非參數部分而具有穩健性,結合實際應用的要求,本文將其模型中一元協變量的設定調整為多元協變量。
(x1i,…,xpi,yi),i=1,…,n 是隨機變量 (X1,…,Xp,Y)的樣本,其中,yi是可能缺失的因變量,(x1i,…,xpi)是總可以被觀測到的協變量,n為樣本容量,p為協變量個數。τi是示性函數,服從響應概率為πi(x1i,…,xpi,yi)的Bernoulli分布,當 τi=1 時,yi可觀測,當 τi=0 時,yi缺失。τi=1時,yi的條件密度是時,yi的條件密度是 f0(yi|x1i,…,xpi)。 K(?)是核密度函數,其窗寬是h,滿足當n→∞時,h→0,nh→∞。本文中采用高斯核密度函數,其最優窗寬為h=xn-1/(p+4),x為 xi的標準差。
當πi與 yi獨立時,缺失機制是MAR,此時:
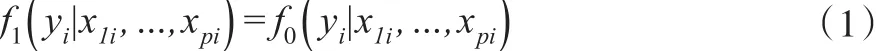
當πi與 yi相關時,缺失機制是MNAR,此時的條件密度關系為:
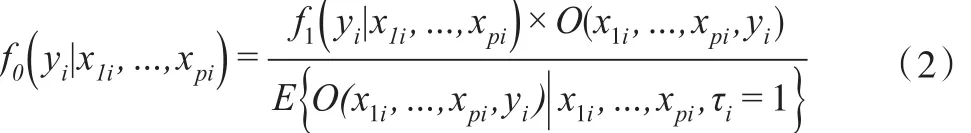
其中,O(x1i,…,xpi,yi)是優勢比函數,形式為:
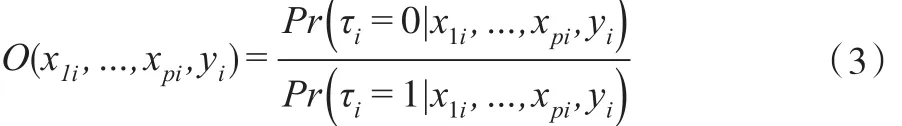
假定響應概率πi來自服從Logit分布的半參數模型,即:
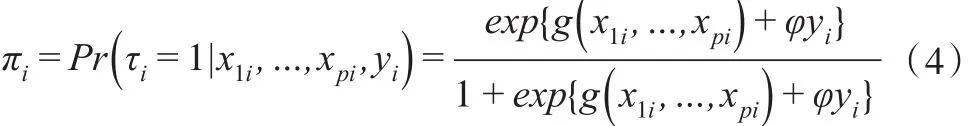
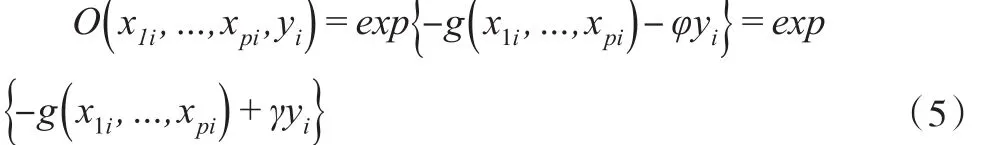
進而式(2)條件密度關系可以表示為:
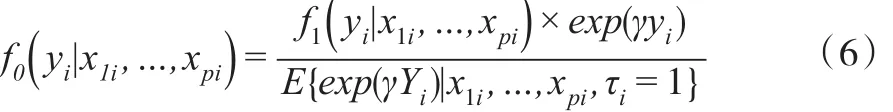
式(6)稱為指數傾斜模型,γ為傾斜參數,表明非隨機缺失機制對隨機缺失機制的偏離程度。在實際問題中,γ一般未知,可通過獨立調查或驗證樣本來估計。
對于可觀測的樣本,其非參數估計m1(x1i,…,xpi)=可通過最小化式(7)求得其估計值,其中是權重。
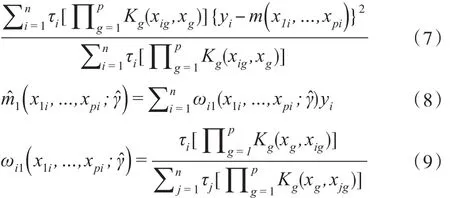
可以證明:
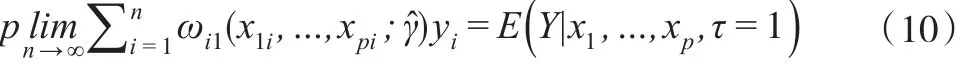
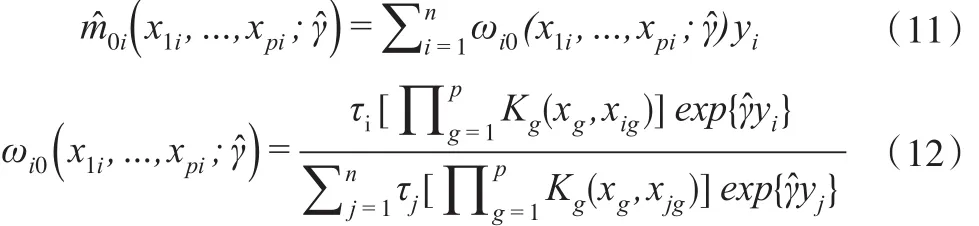
可以證明:
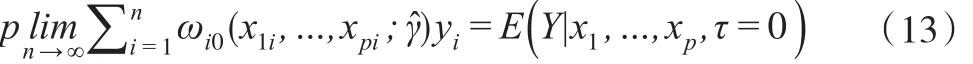
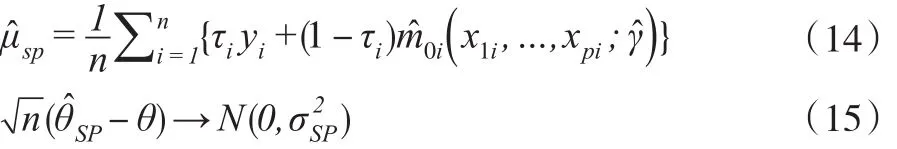
基于指數傾斜的半參數模型在估計中引入了因變量非隨機缺失的機制,借助非參數模型兼具靈活性和可解釋性的優勢,以廣義非參數模型估計傾斜參數γ,獲得因變量均值的一致估計。可以利用式(11)獲得τi=0時 yi的估計值。結合式(11),當 yi是二分類變量時,yi=1的預測概率為,yi=0的預測概率為1-,當>0.5 時,可預測樣本屬于 yi=1 的一類,反之屬于yi=0的一類。
1.2 分類評價標準
對于非隨機缺失數據的二分類問題,不同類別的誤判成本往往存在較大差別,例如信用評級中誤判違約客戶的成本大于誤判履約客戶的成本,因此,在二分類模型優劣的評價中僅僅考慮整體分類精度是不夠的,需要根據誤判成本差異同時參考其他評價指標。本文考察分類模型的精度(Accuracy)、召回率call(Recall)、準確率(Precision)、G 均值(G_mean)、Fβ得分(Fβ_Score):
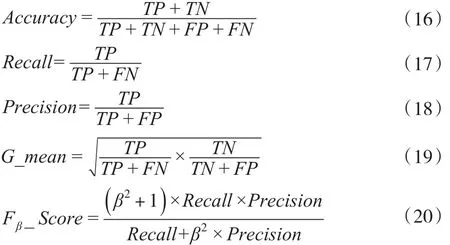
其中,TP、TN、FP、FN分別是混淆矩陣中的真正、真負、假正、假負。Accuracy表示模型正確預測非隨機缺失樣本的比例,Recall表示所有高誤判代價樣本被正確預測的比例,Precision表示被正確預測為高誤判代價樣本的比例,G_mean表示高誤判代價樣本和低誤判代價樣本被正確預測比例的幾何平均數,Fβ_Score表示由參數β調整指標Recall和Precision的組合,β反應指標的相對重要性。本文對模型優劣的判斷主要依據Recall、G_mean、F1_Score和 F2_ScoreFβ_Score。
2 數值模擬
情形1:
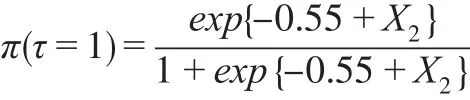
情形2:
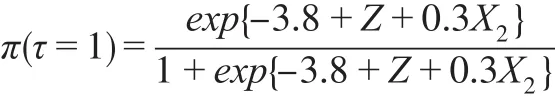
情形3:
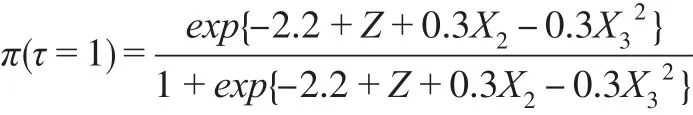
情形4:
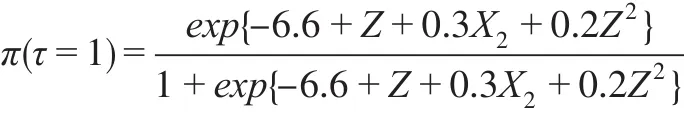
情形5:
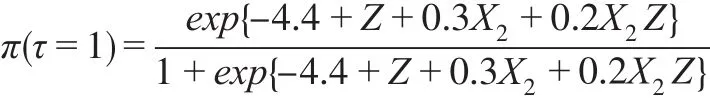
情形6:
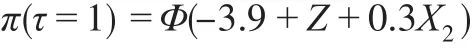
情形7:
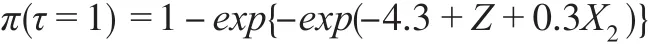
情形8:
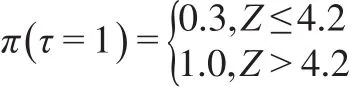
其中,Φ(?)是標準正態分布的累積密度函數。以上8類因變量缺失情形中,情形1是隨機缺失,其他情形是非隨機缺失。設定樣本容量n=1000,每類缺失情形重復模擬100次,以消除隨機性。半參數模型中γ的估計,首先利用可觀測數據建立非參數模型,粗略估計非隨機缺失樣本的分類插補到原始數據中構成完備數據,然后根據式(4),利用完備數據建立廣義半參數模型,得到參數估計值為對比半參數模型的分類效果,本文同時建立Logit模型、SVM模型和決策樹模型對非隨機缺失樣本進行分類,計算模型在各類缺失情形下評價指標的均值,數值模擬結果如表1。
當樣本隨機缺失(情形1)時,半參數模型的召回率和F1得分在四個模型中最大,但其G均值和F2得分僅優于決策樹模型,預測精度不及Logit模型和SVM模型,半參數模型的分類效果沒有顯著優勢。當樣本非隨機缺失(情形2—情形8)時,半參數模型的精度、召回率、G均值、F1得分在四個模型中最大,除情形3和情形5外,其F2得分在四個模型中也最大,半參數模型的分類效果明顯優于其他其他三個模型。在情形3和情形5中,由于決定π的模型中有平方項X32和交互項X2Z,他們提升了協變量X對π的影響,降低了潛變量Z對π的影響,在此二類情形下,半參數模型的F2得分低于Logit模型。綜合各類非隨機缺失情形的指標值,除本文的半參數模型外,Logit模型的分類效果優于SVM模型和決策樹模型,這可能是非隨機缺失的機制設計上假定響應概率服從Logit分布或正態分布。模擬研究表明,本文的半參數模型并不適合因變量隨機缺失情形下樣本的分類,但該模型是處理非隨機缺失樣本分類的有效方法。
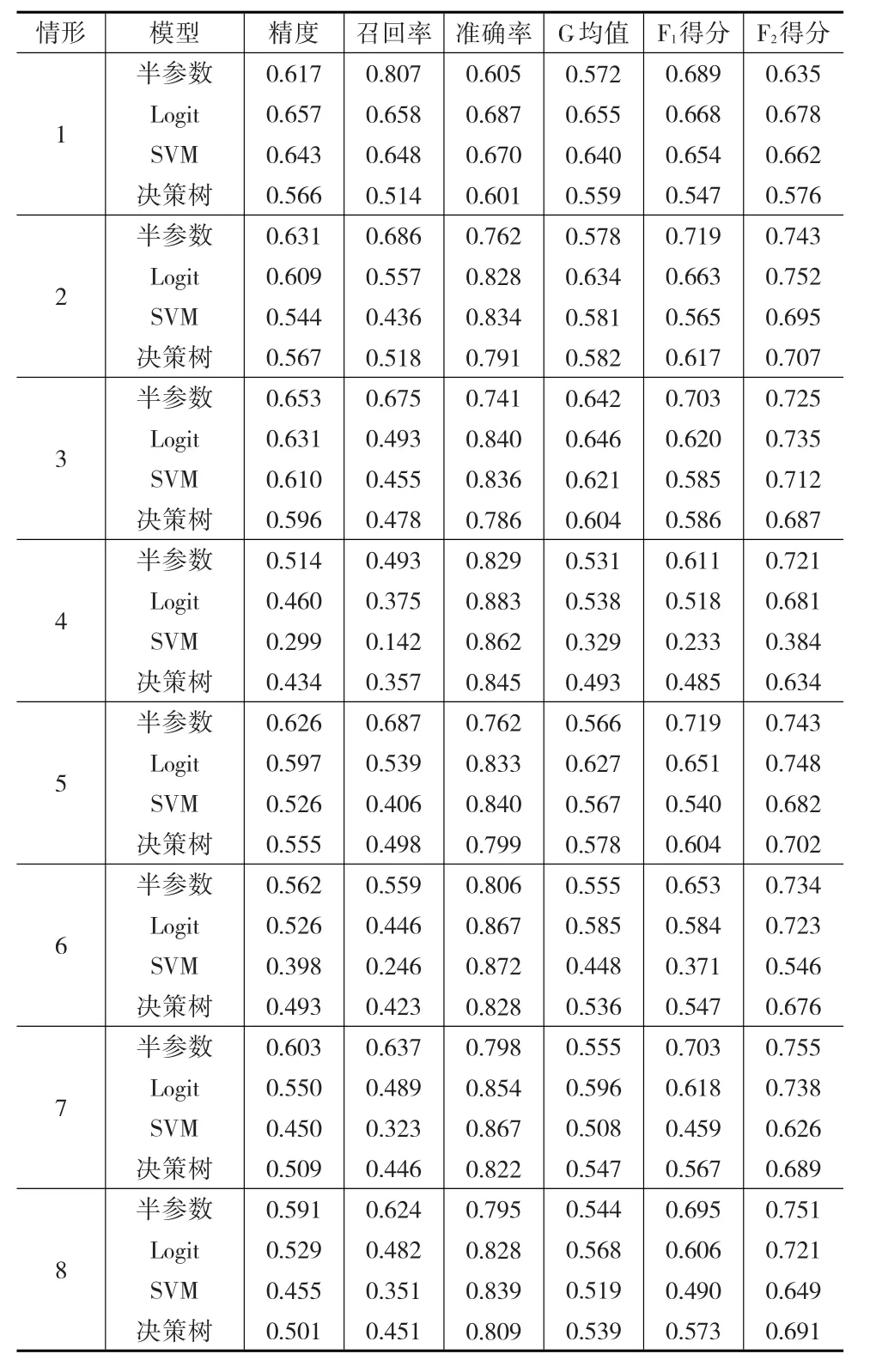
表1 數值模擬結果
3 實證
實證數據來源于 BankScope數據庫,它是 BνD(Bureau νan Dijk)與評級機構惠譽(FitchRatings)合作開發的銀行信息數據庫,提供全球主要銀行及重要金融機構的經營與信用數據。本文的研究內容是通過銀行的主要財務指標對銀行經營狀態非隨機缺失的樣本進行分類,將經營狀態分為“正常”(Y=1)和“異常”(Y=0)二類,“正常”指銀行當前正在經營,“異常”指銀行撤并、解散或倒閉等。協變量選擇總資本比率(X1)、貸款損失準備金/貸款總額(X2)、股東權益/總資產(X3)三個指標。決定其是否缺失的潛在變量選擇存款及短期資金(T1)、所有者權益(T2)、凈利息收益率(T3)。
對原始數據進行篩選和整理后,建模數據的樣本容量為1115,其中正常銀行769家,異常銀行346家。設定因變量非隨機缺失的比例為30%,將潛在變量標準化,令,Z0.3是Z的30%分位數,當 Zi<Z0.3時,第 i家銀行經營狀態缺失(τi=0)。因為缺失狀況根據ε的隨機性而不同,故重復此缺失機制100次。結合BankScope數據庫中的真實數據,建立半參數模型、Logit模型、SVM模型和決策樹模型,計算各類分類評價指標的均值,結果見表2。
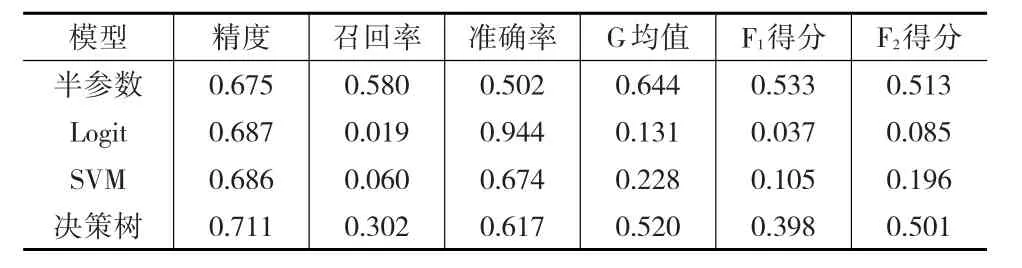
表2 實證結果
結合銀行真實數據的實證研究結果表明,當缺失機制不是由Logit分布或正態分布決定時,半參數模型的召回率、G均值、F1得分、F2得分在四個模型中仍最大,分類效果最佳,這說明半參數模型對于更復雜的非隨機缺失機制具有良好的適應性。相比之下,由于缺失機制分布的改變,決策樹模型的分類效果明顯優于Logit模型和SVM模型。
4 結論
本文主要應用基于指數傾向的半參數模型解決非隨機缺失樣本的二分類問題,引用均值泛函的半參數方法估計樣本屬于某一類別的概率。模擬研究表明,與Logit模型、SVM模型、決策樹模型相比,本文的半參數方法對于隨機缺失樣本的分類效果欠佳,但在處理非隨機缺失樣本的二分類問題上有明顯優勢,對處理非隨機缺失問題具有針對性。實證研究表明,半參數模型對處理實際問題中非隨機缺失樣本的二分類問題同樣具有適用性。
由于模型中使用了核函數建模,當樣本容量過小或數據中有異常值時,分類效果可能會受到影響。在本文的研究中,協變量均為數值型變量,協變量間相互獨立,并未對模型中的特征選擇問題進行研究。在未來的研究中,可以考慮協變量為定性變量且協變量間相關的情況,討論適合非隨機缺失樣本分類的半參數模型的特征選擇方法,并將二分類模型向多分類模型拓展。
參考文獻:
[1]Rubin D B.Inference and Missing Data[J].Biometrika,1976,(63).
[2]Graham J W,Donaldson S I.Evaluating Interventions With Differential Attrition:The Importance of Nonresponse Mechanisms and Use of Follow-up Data[J].Journal of Applied Psychology,1993,(78).
[3]Heckman J J.Sample Selection Bias as a Specification Error[J].Econometrica,1979,(47).
[4]Banasik J,Crook J.Reject Inference,Augmentation and Sample Selection[J].Eur J Opl Res,2007,(183).
[5]Kim J K,Yu L C.A Semi-parametric Estimation of Mean Functionals With Non-ignorable Missing Data[J].Journal of the American Statistical Association,2011,(106).
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
文苑(2018年21期)2018-11-09 01:23:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
中國衛生(2015年9期)2015-11-10 03:11:12
