基于深度學習的音樂推薦系統
2018-05-29 09:18:05湯敬浩李劍
移動信息 2018年2期
湯敬浩 李劍
?
基于深度學習的音樂推薦系統
湯敬浩 李劍
北京郵電大學,北京 100876
為了提高音樂推薦系統的推薦質量,提出一種基于深度學習的推薦系統。使用自動編碼器并結合卷積神經網絡,挖掘音頻、歌詞本身的非線性特征,并將內容特征與協同過濾共同作用,訓練緊耦合模型。在Kaggle的百萬音樂比賽數據集上,MAP可以達到0.232?83,通過對比實驗,證明該模型的表現相比傳統的協同過濾方法有顯著提升。
推薦系統;深度學習;自動編碼器;協同過濾
引言
推薦系統用來向用戶推薦用戶可能感興趣的產品。一個優秀的推薦系統可以大幅提高公司的收入,也可以提高用戶體驗,讓用戶駐留。推薦系統主要用于估計用戶對于他們未知的物品的項目的偏好[1]。推薦系統使用的方法一般分為三類:協同過濾(collaborative filtering),基于內容的推薦(content-based)和混合推薦系統(hybrid recommendation system)。協同過濾的原理是根據歷史使用數據確定用戶的喜好。純粹的協同過濾方法,除了相關的消費模式信息以外,不涉及被推薦物品本身的任何信息。協同過濾方法的優點是不涉及具體推薦物品本身的信息,設計簡單,但其最大問題在于“冷啟動”以及新用戶或者新物品添加進來后的算法健壯性。基于內容的推薦主要根據用戶的消費行為、生活習慣或者社會屬性等信息為其抽象出標簽化的用戶畫像(Persona),并根據物品的內容抽取物品的特征來表示該物品,最后根據用戶畫像和物品特征建立模型,在候選集中為用戶推薦相關性最高的物品。
本文主要集中推薦在音樂領域的應用,音樂推薦系統可以自動匹配用戶的興趣,給其推薦符合其口味的音樂。與歌曲相關的因素中,旋律以及歌詞至關重要。在大多數情況下,我們是否喜歡一首歌,取決于它本身的音頻內容,如聲音、旋律、節奏、音色、流派、樂器、情緒或者歌詞。因此,音頻以及歌詞可以為推薦提供很好的預測能力。
深度學習應用在推薦學習起源于Netflix Prize競賽后半程出現的受限玻爾茲曼機算法(Restricted Boltzmann Machine)。近幾年,基于深度學習的推薦方法的相關研究也急劇增加。Covington等人[2]提出了一種基于dnn的Youtube視頻推薦系統。Cheng 等人[3]使用深度模型為Google Play做推薦。 Shumpei等人[4]展現了RNN在Yahoo新聞推薦上的應用。
本文主要做了基于深度學習的音樂推薦系統,探索深度學習在提取音頻特征以及深度學習在特征提取上的優勢,提出一種基于卷積自動編碼器的混合推薦系統,通過實驗對結果進行分析,與傳統的協同過濾算法比較優劣,并闡述本文方法能取得更好效果的深層次原因。
1 數據集
1.1 數據獲取
實驗數據來自于哥倫比亞大學的研究網站上的Million Song Dataset[5]。Million Song Data(MSD)共包含超過380?000首音樂,結合本文,共用到以下三類數據。
(1)音頻數據。梅爾頻率倒譜系數(MFCC)特征以及色度向量(Chroma)特征,MFCC被廣泛應用在語音識別領域,例如鑒別說話人、語音轉文字等應用,同樣其也應用在音樂信息檢索領域,例如曲風分類、音頻相似性計算等。色度向量(Chroma Vector)是另一種特征。它是一個含有12個元素的向量。每個元素表示著一段時間(例如一幀)內12個音級中的能量,不同八度的同一音級能量累加。該特征在和弦檢測中是一種很典型的方法,可以判斷音頻在某一段時間內的主要音級。
(2)評分數據。100萬用戶對歌曲收聽次數的數據。
(3)歌詞數據。因版權問題,歌詞以詞袋模型(bag of words)的格式給出,即給出了每首歌出現的詞語和詞語的頻數。為了充分利用歌詞特征,我們另外從380?000+ lyrics from MetroLyrics[6]中獲取了多達380?000首音樂的歌詞。盡管我們不能將該數據中的歌曲與Million Song Dataset中的歌曲對應,但我們可以通過word2vec模型為每個詞語進行向量化,為模型提供歌詞層面的特征。
1.2 實驗評估標準
為了評估模型,我們選用Kaggle的比賽Million Song Dataset Challenge[7]。該比賽主要以MSD中100萬用戶對38萬首音樂的收聽次數作為訓練數據(其他數據也可以使用,例如38萬首音樂的音頻、歌詞等數據),并提供了其他11萬個評估用戶(與訓練數據中的100萬用戶不重復)對該38萬首音樂的共300萬條收聽記錄,其中一半的收聽數據可見,另一半數據作為測試集合。比賽中使用了平均精度均值(Mean Average Precision,縮寫MAP)作為評估標準,平均精度均值是一種兼顧召回以及排序的評估方式,其計算方式如下:
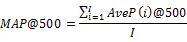
1.3 特征提取
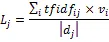
2 混合推薦模型
2.1 模型定義
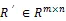
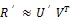
2.2 自動編碼器
自動編碼器是一種前饋神經網絡算法,包括編碼器和解碼器兩部分。編碼器函數將輸入壓縮為低維度的特征,解碼器將低維度的特征解壓,目標是使輸出和輸入最相近。為了讓自動編碼器能夠提取、編碼出更魯棒性的特征,文獻[8]提出了降噪自動編碼器(Denoising Autoencoder)。降噪的方式是將輸入矩陣污染,以一定概率添加噪音,盡管將輸入添加了噪音,但是自動編碼器還是盡力還原了輸入,因此這種方式學習的模型更有魯棒性。仿照DBN和RBM的關系,堆疊式自動編碼器(Stacked Autoencoder)的提出,為深度學習中的生成模型新添了一員。同樣堆疊式自動編碼器是一個多層的神經網絡,但是每層的訓練是逐層的。首先訓練第一層,得到第一層的輸出,然后作為第二層autoencoder的輸入,然后層層堆疊。
AutoRec[9]使用自動編碼器(Autoencoder)來學習評分矩陣。該文獻使用自動編碼器來預測評分矩陣中缺失的值。該模型的輸入是評分矩陣中的一行(User-based)或者一列(Item-based),目標是讓模型的輸出等于模型的輸入,使用反向傳播算法訓練。因此評分矩陣中缺失的評分值以通過模型的輸出預測,從而進行推薦。
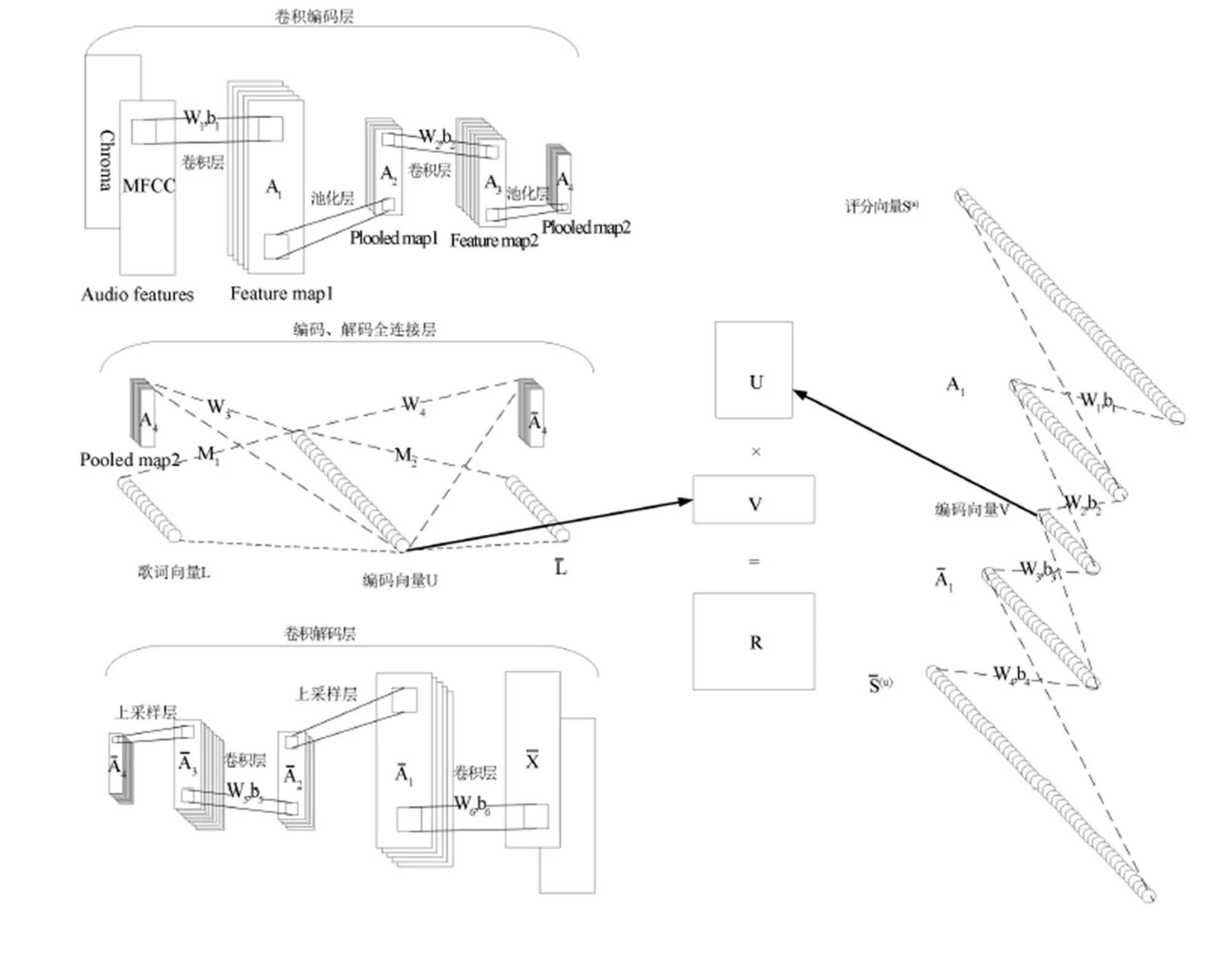
圖1 模型的整體架構
音樂本身的音頻內容是決定用戶是否喜歡的最關鍵因素,因此對于音頻特征的處理是重中之重。Van den Oord A[10]的工作已詳細證明了卷積神經網絡在抽取音頻特征的實力。因此,對于這種多維度的音頻特征,結合卷積神經網絡,本文提出一種卷積自動編碼器結構,用于提取音頻特征。
2.3 混合推薦模型
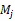
2.4 物品側卷積自動編碼器
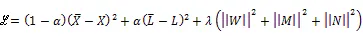
2.5 用戶側自動編碼器
2.6 緊耦合模型
首先預訓練用戶側和物品側兩個自動編碼器,隨后將其連接建立緊耦合的矩陣分解的模型,將網絡連接成如圖1所示。一起訓練緊耦合的模型。那么我們模型整體的損失函數為:
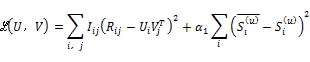
3 實驗以及結果分析
3.1 數據預處理

3.2 實驗及結果分析
為了對比本文算法的優劣,我們分別做了矩陣分解(ALS),堆疊式降噪自動編碼器(AutoRec)[9]以及我們提出的混合推薦模型三個實驗,用以評估我們的模型優劣。實驗均使用Tensorflow編寫。
在訓練時,最主要的訓練數據是評分矩陣,但該數據是高度稀疏的數據。為了可以應用梯度下降等最優化方法訓練,在Tensorflow中,可以使用tf.gather取出對應維度以及下標數據,使其連續。
三種實驗均可得到每首音樂的隱含特征向量,隨后擬合測試評分矩陣的可見部分,進而計算測試數據的MAP值。
首先,統計了三種實驗在Kaggle比賽數據中的平均精度均值,如表1所示。
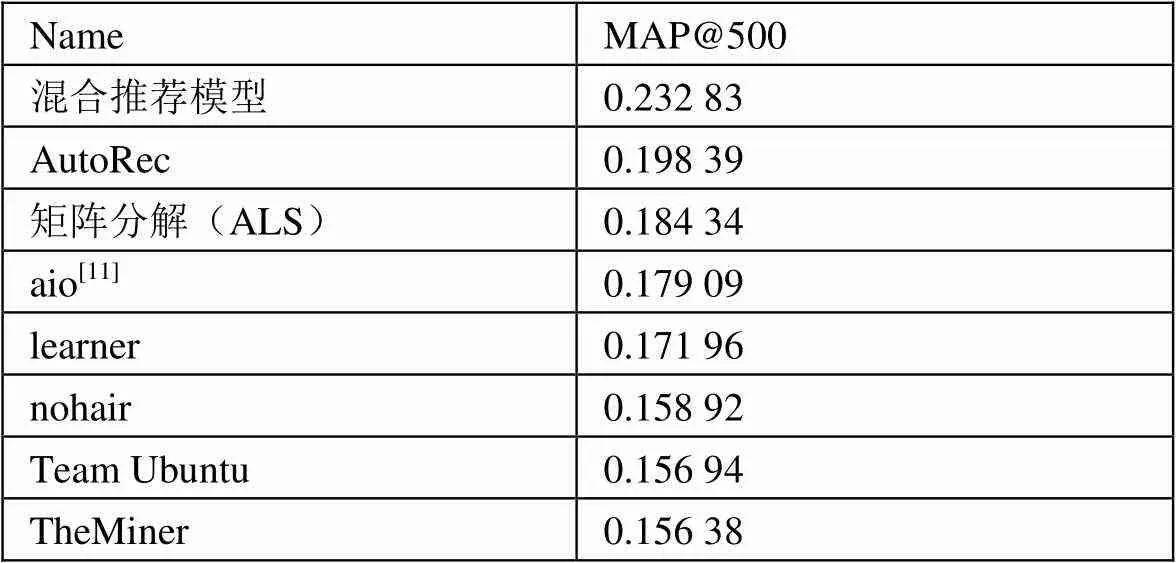
表1 三個實驗以及Kaggle比賽中Top5成績的MAP@500
如表1所示,由于該比賽為2012年的比賽,而當時比賽的第一名[11]使用的算法是基于物品的協同過濾方法。
從結論中可以看出,矩陣分解(ALS)這種基于模型的協同過濾要比傳統的基于用戶或者基于物品的效果更高,但由于ALS只能捕捉到用戶和物品之間的線性關系,而降噪自動編碼器(AutoRec)使用了自動編碼器實現的協同過濾,由于神經網絡激活函數的非線性,其相當于評分矩陣的非線性變換,可以捕捉到用戶和物品之間的非線性關系,結果也符合期望,要優于ALS實現的矩陣分解。本文提出的混合推薦模型,結合了音頻特征,以及word2vec預訓練的歌詞特征,使用卷積自動編碼器以及矩陣分解實現了一種混合推薦模型,其MAP@500可以達到0.232?83,遠高于僅使用基于物品的協同過濾的推薦效果。
對于本文提出的混合推薦模型,不僅融入了協同過濾,而且還通過卷積和全連接的方式學習音頻、歌詞特征。在訓練混合推薦模型時,均使用了線性整流函數(ReLU)作為激活函數,卷積輸入的維度為12×120×2,卷積層1使用了16個卷積核,輸出維度為12×120×16,隨后池化層1將其縮減為6×60×16。卷積層2仍然是十六個卷積核,那么輸出維度為6×60×16,經過池化層2后,輸出維度為3×30×16。將其展開為一維特征1?440×1,與歌詞向量500×1貼合一起經過一層全連接層后,輸出音樂的隱含特征向量,隱含特征向量的維度設置為500,以上為編碼部分,接下來的解碼部分與編碼部分反向,不再贅述。
4 結論
本文提出了一種混合推薦模型,用以推薦音樂,在傳統的協同過濾的方式之上,添加了音頻特征以及歌詞特征的學習。實驗證明,該方法比一些傳統的協同過濾方式表現更優異。
[1]GB/T 7714 Adomavicius G,Tuzhilin A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions[J]. IEEE transactions on knowledge and data engineering,2005,17(6):734-749.
[2]Covington P,Adams J,Sargin E. Deep neural networks for youtube recommendations[C]// Proceedings of the 10th ACM Conference on Recommender Systems. ACM,2016:191-198.
[3]GB/T 7714 Cheng H T,Koc L,Harmsen J,et al. Wide & deep learning for recommender systems[C]// Proceedings of the 1st Workshop on Deep Learning for Recommender Systems. ACM,2016:7-10.
[4]Okura S,Tagami Y,Ono S,et al. Embedding- based News Recommendation for Millions of Users[C]// Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM,2017:1933-1942.
[5]Bertin-Mahieux T,Ellis D P W,Whitman B,et al. The Million Song Dataset[C]//Ismir. 2011,2(9):10.
[6]Mishra G. (2016). 380,000+ lyrics from MetroLyrics. [online] Available at: https://www.kaggle.com/gyani95/ 380000-lyrics-from-metrolyrics [Accessed 27 Nov. 2017].
[7]Kaggle. (2017). Million Song Dataset Challenge. [online] Available at:https://www.kag-gle.com/c/ msdchallenge [Accessed 27 Nov. 2017].
[8]Vincent P,Larochelle H, Bengio Y, et al. Extracting and composing robust features with denoising autoencoders[C]//Proceedings of the 25th international conference on Machine learning. ACM,2008:1096-1103.
[9]Sedhain S, Menon A K, Sanner S, et al. Autorec: Autoencoders meet collaborative filtering[C]//Procee- dings of the 24th International Conference on World Wide Web. ACM, 2015: 111-112.
[10]Van den Oord A, Dieleman S, Schrauwen B. Deep content-based music recommendation[C]//Advances in neural information processing systems, 2013:2643-2651.
[11]Aiolli F. A Preliminary Study on a Recommender System for the Million Songs Dataset Challenge[C]//IIR. 2013:73-83.
Deep learning based music Recommendation System
Tang Jinghao Li Jian
Beijing University of Posts and Telecommunications, Beijing 100876
In order to improve the efficiency of the music recommendation system, a deep learning based on recommendation system is proposed. A convolutional stack autoencoder model is used to mining the non-linear features of audio and lyrics. Then, a tightly coupled model is trained using side information combined with collaborative filtering. On Kagg’s million song dataset challenge, the MAP score can reach 0.232?83. The experimental results show that the performance of the model compared to traditional collaborative filtering method is improved significantly.
recommendation system; deep learning; autoencoder; collaborative filtering
TP391.3
A
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
兒童繪本(2017年24期)2018-01-07 15:51:37
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
東方藝術·大家(2016年6期)2016-09-05 07:30:56
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
河南科技(2014年23期)2014-02-27 14:19:15
