基于時空分析的突發事件檢測方法
2018-05-30 01:26:05梁月仙陳自巖
計算機工程 2018年5期
梁月仙,陳自巖,王 洋,張 躍,郭 智
(1.中國科學院 空間信息處理與應用系統技術重點實驗室,北京 100190; 2.中國科學院電子學研究所,北京 100190;3.中國科學院大學,北京 100190)
0 概述
近年來,世界各地頻繁地發生地震、恐怖襲擊等突發事件,突發事件的發生嚴重影響社會秩序的安定和人們生命的安全。互聯網上呈現的突發事件信息通常被淹沒在眾多的普通事件中,人們難以發現潛在的突發性事件,因此,迫切需要一種有效的工具檢測出突發性事件。突發事件指在短時間內出現,且其信息量迅速膨脹并隨后消亡的事情。突發事件檢測旨在從文本中抽取出相關的事件信息并檢測其突發性,包括事件抽取和突發性檢測兩部分。事件抽取指從非結構化的文本中抽取出事件信息并以結構化的形式呈現。
事件抽取主要實現特定事件類型的識別以及事件元素的發現,現有事件抽取方法可分為基于規則匹配的方法、基于監督學習的方法和基于無監督學習的方法。基于規則匹配或監督學習的方法[1-4]依賴于標注語料,存在領域移植性問題,無法有效地運用于開放領域的網絡文本。面向開放領域的非監督學習方法采用離線的方式進行事件抽取[5-7],無法實時地處理在線的網絡數據流。
突發事件檢測主要實現事件的突發權重、突發時間段和突發空間區域的識別,已有工作基于事件的詞頻信息進行突發性檢測[8-10],忽略了事件的重要性。另外,事件的突發性不僅與時間序列有關,而且也受地理位置的影響,但是現有大多數工作只考慮事件的突發時間性或突發空間性[11-15]。雖然一些研究[16-17]同時考慮了事件的時空突發性,但是它們以孤立的方式看待事件的突發時間域和突發空間域,未能充分挖掘事件的時空關聯性。
針對上述方法存在的問題,本文提出一種聯合時空要素綜合分析的突發事件檢測方法。該方法通過引入數據立方體結構存儲事件詞,綜合分析事件的時空要素并且挖掘事件的時空關聯性。同時,給出一種基于語義相似性的實時事件聚類算法,可實時地處理在線的網絡數據流,從而擺脫特定領域的限制。在聚類過程中,采用GloVe模型挖掘事件詞之間的語義關聯性,使同一事件類的事件詞具有較強的語義相關性,并基于事件類在時空維度上的出現權重,采用有限狀態機-高斯分布模型識別時空突發事件。
1 研究方法
本文基于時空要素綜合分析的框架,提出一種新穎的突發事件檢測方法。該方法首先利用爬蟲技術獲取大規模的未標注網絡文本數據,并通過數據預處理獲取時間表達式、地名實體和事件詞。其次基于事件詞的時空特性,采用數據立方體存儲事件詞。然后提出一種基于語義相似性的實時事件聚類算法抽取出重要事件。最后基于事件在時空維度上的出現權重,采用有限狀態機-高斯分布模型,建模事件的突發特性。突發事件檢測的系統框架如圖1所示。
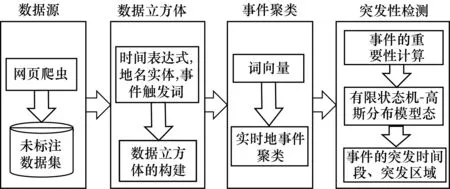
圖1 突發事件檢測系統
1.1 數據立方體的構建
通過數據預處理,從網絡文本中抽取出事件詞、時間表達式和地名實體。
事件觸發詞是表達事件發生的性質或狀態的詞[18],例如“由于電池門問題,三星Galaxy Note7 發生爆炸”,本文將事件觸發詞作為事件詞。為了抽取出事件觸發詞,將事件觸發詞的識別視為一個二分類任務。首先隨機選取200篇新聞文檔作為訓練語料,這些文檔涵蓋政治、社會、經濟、體育、軍事等領域。為了確保訓練語料的可靠性,按照Timebank Corpus[19]標注指導對語料進行人工標注。在眾多的分類器中,CRF模型考慮了文本的語境特征和詞性特征,在序列標注任務和分類任務中能夠取得較好的效果,因此本文采用CRF(Conditinal Random Fields)模型[20]抽取出最合適的事件觸發詞。
一篇文檔通常包含多個時間表達式、多個地名實體,新聞媒體或社交網絡網站是一個實時報道當天事件的平臺,本文將文檔的生成時間作為事件詞的發生時間,將距離事件詞最近的地名實體作為該事件詞的發生地點。為了將地名實體轉換成空間信息,構建一個完善且全面的地理空間知識庫,該知識庫包括地名本體子庫、規則子庫等輔助數據源,并提供相應的查詢接口。在地名-空間信息轉換過程中,采用了地名消歧和地名經緯度轉換等技術。地名消歧通過啟發式的規則方法實現[21],通過計算地名和上下文地名之間的地理關聯度進行地名的消歧,首先識別出文檔中的所有地名,并確定歧義地名對應的所有地理位置,構成候選位置集合,然后設置啟發式規則方法,從候選位置集合中確定唯一的地理位置。地名經緯度轉換通過啟發式的規則匹配方法實現。將事件詞的時間信息和空間信息結合,即可獲取事件詞的時空信息。最后基于事件詞的時空信息,將事件詞存儲于數據立方體中,如圖2所示。
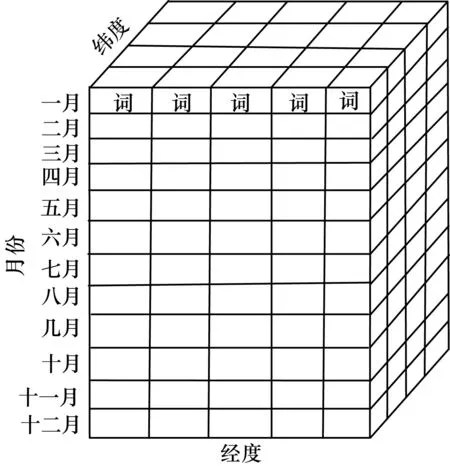
圖2 數據立方體示意圖
1.2 基于語義相似性的事件聚類
在1.1節的基礎上,由于事件詞已存儲于立方體中,但立方體的事件詞是雜亂無章的,需要對這些事件詞進行有效的聚類以抽取出重要事件。現有方法研究事件聚類通常采用K-means和Latent Dirichlet Allocatio等的改進方法[5-7],但它們都是離線的批處理聚類方式,不適用于動態的網絡數據流。近年來,隨著網絡文本數據的興起,研究者提出了許多在線的聚類算法[22-24],但是當涉及到相似性計算時,這些方法通常只考慮詞之間的空間距離,未挖掘詞的語義關聯性。
針對現有聚類方法存在的問題,本文提出一種基于語義相似性的實時事件聚類算法,該算法是一種增量式的聚類方式。隨著數據流的到來,聚類結果將會動態地改變,該聚類算法如算法1所示。
算法1事件聚類(E,w)
輸入詞w,現有事件集E={e1,e2,…,eK}
輸出更新事件集E
If E is null
e1=w,c1=w
Else
For each event eiin the E do
Si=Sim(ci,w)
Return the biggest Sb
If Sb>threshold T then
Add w to the existing event eb
Update the center vector cbof event eb
For word wiin the ebdo
Else
add w to E as a new event
考慮一個新到達的事件詞w,假如w是第一個到來的事件詞,那么將其作為第一個事件類;否則,將w分別與已有的事件類進行相似性計算,然后對所有相似值做降序排序,獲得最大的相似值Sb,假設Sb為w與事件類eb的相似值,如果Sb大于閾值T,w被聚到事件類eb中,同時更新事件類eb的質心向量cb,否則w被作為一個新的事件類添加到事件集E中,算法1中的相似性計算采用余弦相似度公式:
(1)
上述聚類算法的一個核心環節為事件詞間的相似性計算。目前最流行的計算詞相似性的方法為詞向量的方式。已有的許多表證詞的向量空間法,例如文獻[25]提出一種全局向量模型(GloVe)訓練詞向量。GloVe模型充分利用詞的全局共現統計和語境特征來挖掘詞之間的語義關聯性,在語義相似性任務上,GloVe模型的實驗結果優于Word2Vec模型[26],因此,本文采用GloVe模型挖掘事件詞之間的語義關聯性。GloVe模型的詳細推導過程見文獻[25]。
1.3 突發事件的檢測
在突發性檢測中,具有代表性的方法為文獻[9]提出的有限狀態機模型,該模型基于文檔的到達時間間隔,使用有限狀態機建模事件的突發性,從而識別出突發的開始時間和結束時間。該模型為一個隱馬爾可夫鏈,模型的隱變量是詞所處的狀態(突發態或普通態),其假設文檔的到達速率服從指數分布,當文檔的到達速率加快時,模型會依據狀態轉換代價判定是否發生狀態轉換,通過對模型的狀態序列進行推理最終獲得一條最優的狀態序列,序列中2個時間點的狀態改變代表著突發時間段的邊界。文獻[8]借鑒Kleinberg的思想,基于時間序列中話題的出現頻率,假設話題的出現頻率服從泊松分布,并采用有限狀態機-泊松分布模型識別突發性話題。Kleinberg和Diao的方法研究重點在于檢測突發事件和突發時間段,未考慮事件的突發區域性,并且它們依據事件的頻率信息進行突發性檢測,忽略了事件的重要性。本文基于Kleinberg和Diao識別突發性的方法,提出綜合分析事件的時間要素和空間要素,依據事件在時空維度上的出現權重,采用有限狀態機-高斯分布模型建模事件的時空突發特性。
1.3.1 事件在時空維度上的重要性計算
現有方法通常依據特征項在時間序列上的出現頻率,構建相應的模型判斷事件是否為突發性事件。但是特征項的頻率信息并不能有效地將某一個特征與其他特征區分開,即頻率統計法并不具備很好的區分能力。事件間的重要程度有一定的差異,現有方法考慮事件的出現頻率而忽略了事件的重要性,因此,無法有效突顯事件的重要程度。詞頻反文檔頻率(TFIDF)則可克服該缺點,TFIDF是一種有效體現特征重要性的值。TFIDF的思想是:如果詞w在某一類別中出現的頻率高,而在別的類別中出現的頻率低,則說明該詞能夠很好地代表該類別的特征,即可以有效地將某一類別與別的類別區分開。
本文采用TFIDF計算事件在時間維度、空間維度上的出現權重,用以評估事件在整個事件集中的重要程度。對于事件集E={e1,e2,…,ei,eN}中的事件ei,計算其在不同的地理位置r,不同的單位時間點t上的權重Weights(ei,t,r)。其中,t∈[1:T]為時間序列中某個單位時間點,r∈[1:R]為空間區域中某個地理位置。假設一個事件ei由K個事件詞{w1,w2,…,wi,wk}組成,考慮事件元素wj,令Weights(wj,t,r)為事件詞在單位時間點t、地理位置r上的權重值,則有:
(2)
1.3.2 事件突發性的檢測
本文提出采用有限狀態機-高斯分布模型對事件的狀態進行建模。該模型是一個隱馬爾可夫鏈,模型中的隱變量是詞所處的狀態,觀測數據是事件在時間序列上單位時間點的權重值。該有限狀態機模型如圖3所示,其中,qt為自動機的隱狀態,“0”代表正常態,“1”代表突發態,模型處在不同的隱狀態,就以不同強度的概率來生成觀測數據,即狀態轉移鏈的發射概率服從高斯分布。
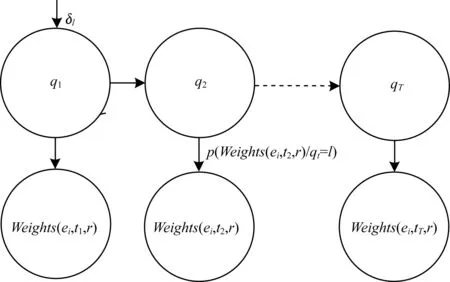
圖3 有限狀態機模型
p(Weights(ei,t,r)/qt=l)=
(3)
其中,qt為事件在單位時間點t的狀態,l=0或者l=1,qt=0為正常態,qt=1為突發態。高斯分布的4個參數為u0、u1、σ0、σ1。設置u0為事件在時序上的權重均值:
(4)
其中,設置u1=3u0,σ0為事件在時序上的權重均方差,σ1=σ0。
狀態序列Q={q1,q2,…,qT}為狀態機的狀態轉移鏈,其轉移規律服從隱馬爾科夫假設,由狀態轉移矩陣M和先驗概率θ控制。在狀態q1之前,假設有一個虛擬的正常態q0,則狀態機的先驗概率為θl=(p00,p01),狀態轉移矩陣為:
(5)
其中,設置超參數θ0=0.7,θ1=0.6。
采用維特比算法獲取最優的狀態轉移序列Q*。序列中的突發態對應的連續時間段為突發時間段。對于突發時間段T=[t1:t2],其突發權重為:
p(Weights(ei,t,r)/qt=0))
(6)
為了識別出合理的突發時空區域,采用矩形R表征事件的突發空間區域,時空窗W表征事件的突發時空域。定義事件e在突發時間段T矩形區域R上的突發權重值為事件詞落在時間段T和矩形R上的突發權重值之和,并取多個區間的交疊區段為事件的突發時空域,突發權值為多個區間的權重值之和。事件e在時間序列和空間區域上的突發區間如圖4所示,突發區間在時序上是非交疊的,而在空間區域上存在著交疊。對于突發時間段T=[t1:t2]、突發區域R=[r1:r2],獲取事件的突發時空窗權重分數為:
(7)
通過式(7)可獲取任意時空窗的權重分數,對權重分數排序,即可獲取Top-rank 突發事件。

圖4 事件在多個地理位置上的突發時間段示意圖
2 實驗結果與分析
2.1 數據集與實驗設置
采用網絡爬蟲技術抓取2015年3月1日—2015年8月30日的121篇、157篇新聞文檔。這些文檔涵蓋政治、經濟、體育等領域。通過數據預處理,獲取184個事件的發生時間、7 494個地名實體和10 022個事件詞,然后基于事件詞的時空信息構建立方體。在事件聚類中,基于數據集的相似性統計分析,設置相似度閾值為0.76。在事件突發性檢測中,設置時序上的單位時間為d。
2.2 事件抽取結果與分析
2.2.1 對比方法
為了證明本文提出的事件抽取方法的有效性,設置基于StreamCube方法[27]和DTM(Dynamic Topic Models)模型[28]的對比實驗。StreamCube方法基于層級時空的hashtags聚類實現事件搜索,該方法將hashtags作為事件詞,考慮了hashtags之間的時空關聯性,采用在線的聚類算法實現事件搜索。在聚類過程中,StreamCube采用one-hot模型表征詞的向量空間,因此未能充分挖掘hashtags之間的語義相似性。DTM是一種離線的主題生成模型,旨在研究基于時間維度的話題演化過程,體現話題隨時間變化的特性。DTM關注了話題隨時間變化的演化過程,但是它忽略了話題的空間特性。
2.2.2 評價分析
本文引入3個評價聚類質量的指標:NMI(Normalized Mutual Information),RI(Rand Index)和F1值。這3個評價指標的含義及計算公式如下所示。
NMI(X,Y)=2×I(X,Y)/(H(X)+H(Y))
(8)
其中,I(X,Y)為向量X與向量Y的互信息,H(X)為向量X的信息熵,同理,H(Y)為向量Y的信息熵。
RI=(TP+TN)/(TP+FP+FN+TN)
(9)
F1=2TP/(2TP+FP+FN)
(10)
表1列舉了每種方法的測評結果,StreamCube方法在聚類過程中,采用one-hot模型表征事件詞的詞向量,即只考慮事件詞之間的空間距離,沒有挖掘出事件詞的語義關聯性,因此聚類效果最差。另外,one-hot模型產生的將是一個高維度的稀疏共現矩陣,容易導致維數災難的問題。DTM對隨著時間變化的文檔集進行主題建模,由文檔-詞語-主題的生成過程判明出時間片段內文檔所包含的主題。從聚類結果可以看出,DTM可以較為有效地抽取出文檔所包含的事件類。但是DTM需在整個數據集上迭代計算,是一種離線的抽取方式,因此并不能有效地處理動態的網絡數據流。另外,DTM忽略了話題的空間概念,無法處理事件的空間信息。本文事件抽取方法采用Glove模型訓練事件詞之間的語義相關性,使聚在同一事件類的事件詞具有強的語義關聯性,因此聚類效果優于StreamCube方法和DTM方法。另外,本文方法能夠用較少的向量維度(200維、300維、400維等)表征事件詞的向量空間,因此占用較少的內存空間和聚類時間。
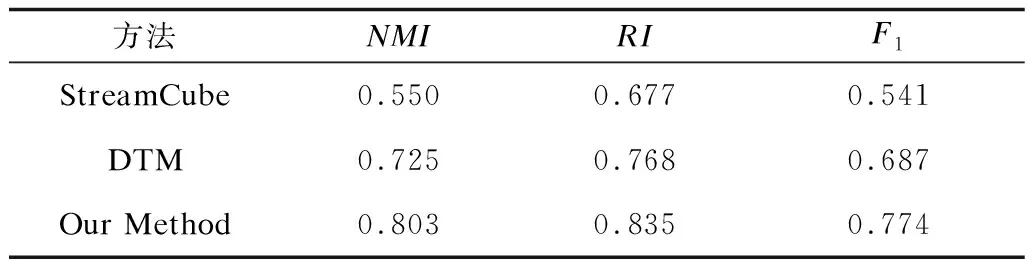
表1 3種方法的事件聚類效果
2.3 突發事件檢測結果與分析
2.3.1 對比方法
為了證明本文提出的突發事件檢測方法的有效性,與Diao的方法進行對比,Diao的方法旨在研究從微博數據流中發現突發性話題,其通過結合用戶對話題的關注度以及話題在時序上的出現頻率,采用基于有限狀態機-泊松分布模型檢測出突發性話題。
2.3.2 評價分析
采用本文的突發事件檢測方法進行實驗,列舉了Top-5突發事件的實驗結果,其中,每個事件列舉了Top-8個事件詞,如表2所示。可以看出,所有的突發事件都是有意義的,這些突發事件不僅具有一定的突發時間段,而且還具有一定的突發區域。另外,不同突發事件的突發時間段和突發區域都是不同的,表明了突發時空特性的重要性。

表2 突發事件檢測結果
設置基于Diao的方法的對比實驗。圖5和圖6分別為自然災難事件基于時間序列的事件強度變化過程,其中,圖5為Diao的方法基于事件在單位時間內的出現頻率以及,建模有限狀態機-泊松分布模型獲取的事件強度變化過程。圖6為STBEvent模型中基于事件的TFIDF權重以及建模有限狀態機-高斯分布模型獲取的事件強度變化過程。從圖5、圖6可以看出,采用Diao的方法檢測出該自然災害事件有4個異常高頻段,模型認為此事件并非一個突發事件,而是一個周期性事件。而采用STBEvent模型可正確檢測出一個異常高頻段,并認為其是一個突發事件。因此,采用STBEvent模型檢測事件的突發性更為有效。
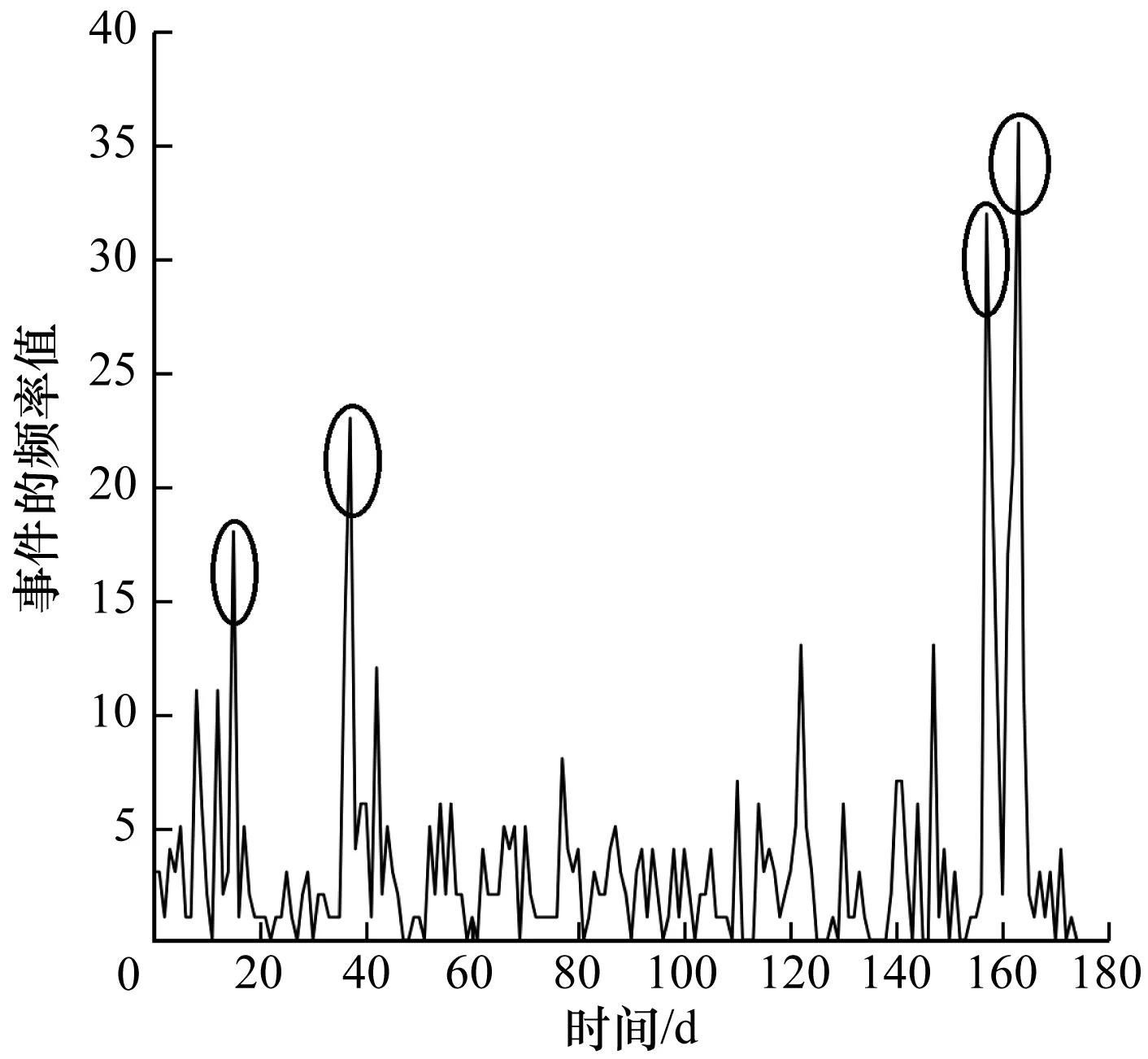
圖5 采用有限狀態機-泊松分布模型獲取的坍塌事件強度
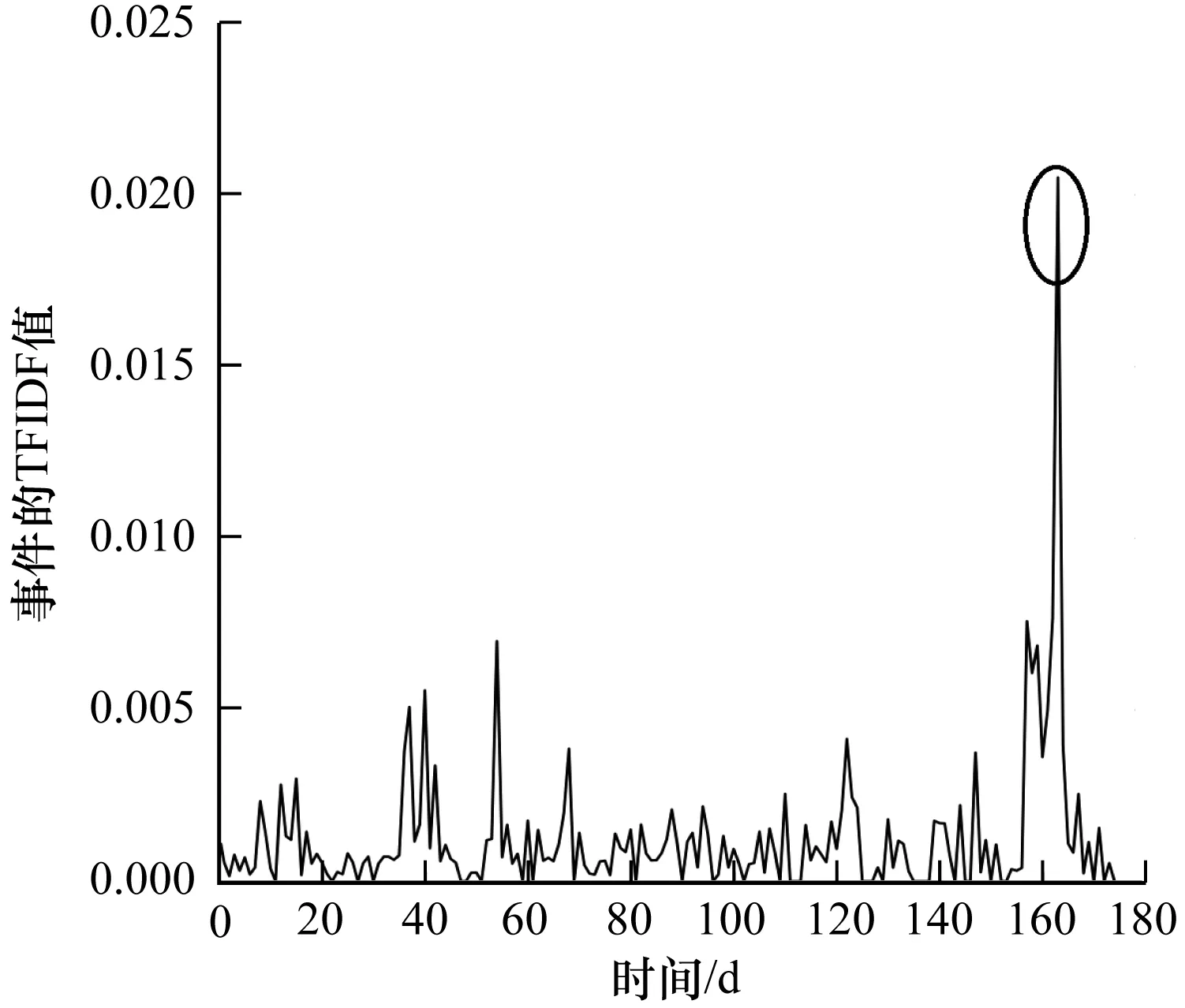
圖6 采用有限狀態機-高斯分布模型獲取的坍塌事件強度
圖7為采用有限狀態機-泊松分布模型獲取的坍塌災難事件(突發事件)和體育競技事件(非突發事件)分別基于時間序列的事件強度變化過程,其中,實線為自然災難事件的事件強度變化過程,虛線為體育競技事件的事件強度變化過程圖。圖8為采用STBEvent基于事件的TFIDF權重,以及建模有限狀態機-高斯分布模型獲取的坍塌災難事件(突發事件)和體育競技事件(非突發事件)分別基于時間序列的事件強度變化過程,其中,實線為自然災難事件的事件強度變化過程,虛線為體育競技事件的事件強度變化過程。Diao的方法對于突發事件,其與普通事件的頻率分布并不具有很強的區分性。而STBEvent模型,對于坍塌災難事件,在非突發態,其TFIDF值是低的;在突發態,其TFIDF值驟然增高,并急劇降低,符合突發事件的定義,這表明了STBEvent模型檢測出的突發性事件與普通事件具有更為明顯的區分性。
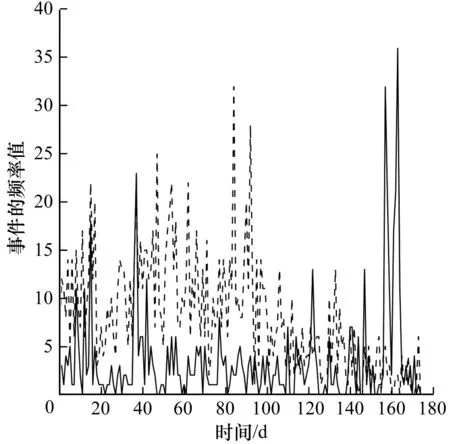
圖7采用有限狀態機-泊松分布模型獲取的坍塌事件(突發事件)與體育競技事件(非突發事件)強度
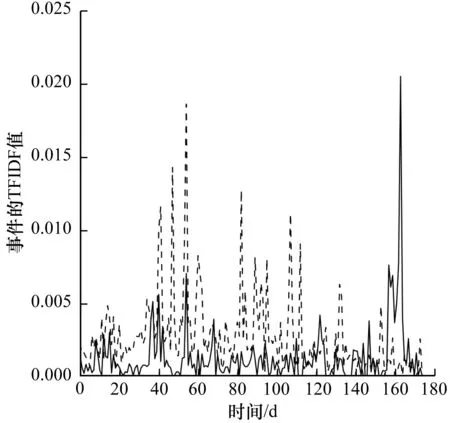
圖8采用有限狀態機-高斯分布模型獲取的坍塌事件(突發事件)與體育競技事件(非突發事件)強度
本文方法不僅能識別出突發時間段,而且可以識別出突發空間區域。圖9為坍塌事件(突發事件)在不同地理位置序號的TFIDF值變化情況,圖10為體育競技事件(非突發事件)在不同地理位置序號的TFIDF值變化情況。可以看出,坍塌事件的突發區域為3個(上海、遼寧、山西),而體育競技事件無明顯的突發區域。
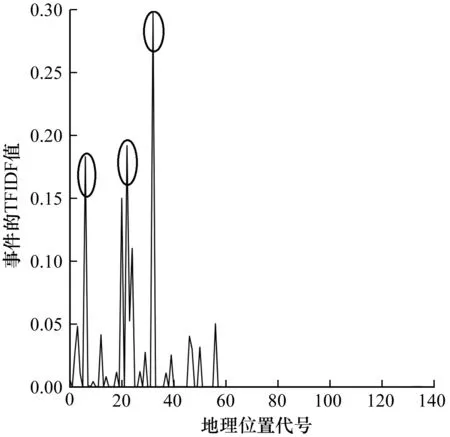
圖9 坍塌事件(突發事件)基于地理區域的權重值變化
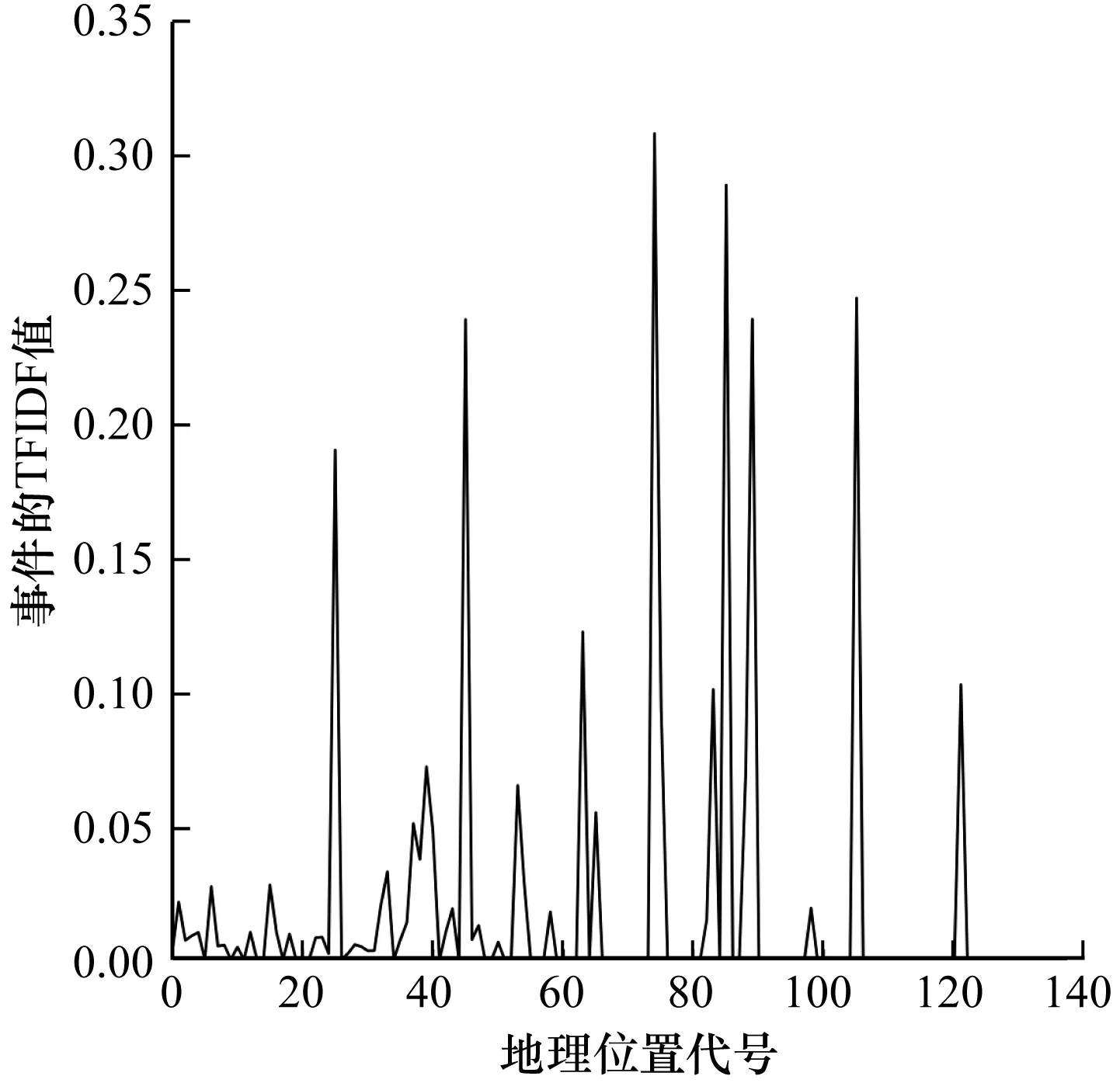
圖10 體育競技事件(非突發事件)基于地理區域的權重值變化
3 結束語
傳統的突發事件檢測方法依賴人工標注數據集,以孤立的方式看待事件的時空要素,且忽略事件的重要性等問題。為此,本文提出一種基于時空要素綜合分析的突發事件檢測方法。該方法首先引入數據立方體結構存儲事件詞,綜合分析事件的時空要素,并且挖掘出事件的時空關聯性。然后給出一種基于語義相似性的實時事件聚類算法,實時地處理在線的動態網絡數據流,從而擺脫了特定領域的限制。同時,采用GloVe模型挖掘出事件詞之間的語義關聯性,使聚在同一事件類的事件詞具有強的語義相關性。其次采用TFIDF計算事件的出現權重,評估某一事件在整個事件集中的重要程度。最后采用有限狀態機-高斯分布模型識別出時空突發事件。實驗結果表明,該方法能夠較為準確地抽取出重要的事件,并取得77.4%的抽取準確率;在突發性檢測時,該方法比現有方法更能準確地檢測出突發事件,且能夠有效地識別出事件的突發時間段和突發空間區域。下一步將研究事件抽取和突發性檢測的聯合學習算法。
[1] BETHART S,MARTIN J H.Identification of event mentions and their semantic class[C]//Proceedings of Conference on Empirical Methods in Natural Language Processing.Sydney,Australia:[s.n.],2006:146-154.
[2] LI P,ZHOU G,ZHU Q.Minimally supervised Chinese event extraction from multiple views[J].ACM Transactions on Asian and Low-resource Language Information Processing,2016,6(2):13.
[3] NGUYEN M T,NGUYEN T T.Extraction of disease events for a real-time monitoring system[C]//Proceedings of Symposium on Information and Communication Technology.Washington D.C.,USA:IEEE Press,2013:139-147.
[4] 侯立斌,李培峰,朱巧明.基于CRFs和跨事件的事件識別研究[J].計算機工程,2012,38(24):191-195.
[5] TSOLMON B,LEE K S.An event extraction model based on timeline and user analysis in latent dirichlet allocation[M].New York,USA:ACM Press,2014.
[6] SILVA J D A,HRUSCHKA E R.A support system for clustering data streams with a variable number of clusters[J].ACM Transactions on Autonomous & Adaptive Systems,2016,11(2):11.
[7] LIN C X,ZHAO B,MEI Q.PET:a statistical model for popular events tracking in social communities[C]//Proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2010:929-938.
[8] DIAO Q,JIANG J,ZHU F,et al.Finding bursty topics from microblogs[C]//Proceedings of Association for Computational Linguistics.[S.1.]:Association for Computational Linguistics,2012:536-544.
[9] KLEINBERG J.Bursty and hierarchical structure in streams[J].Data Mining & Knowledge Discovery,2003,7(4):373-397.
[10] LAPPAS T,ARAI B,PLATAKIS M,et al.On burstiness-aware search for document sequences[C]//Proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2009:477-486.
[11] ALVES R A D S,ASSUNCAO R M,STANCIOLI V D M P O.Burstiness scale:a parsimonious model for characterizing random series of events[C]//Proceedings of ACM SIGKDD International Conference on Knowledge Discovery & Data Mining.New York,USA:ACM Press,2016:1405-1414.
[12] KALOGERATOS A,ZAGORISIOS P,LIKAS A.Improving text stream clustering using term burstiness and co-burstiness[C]//Proceedings of Hellenic Conference on Artificial Intelligence.Athens,Hellenic:[s.n.],2016:1-9.
[13] ZHAO L,CHEN F,LU C T,et al.Online spatial event forecasting in microblogs[J].ACM Transactions on Spatial Algorithms & Systems,2016,2(4):15.
[14] SCHUBERT E,WEILER M,KRIEGEL H P.SPOTHOT:scalable detection of geo-spatial events in large textual streams[C]//Proceedings of International Conference on Scientific & Statistical Database Management.Washington D.C.,USA:IEEE Press,2016:1-12.
[15] QUEZADA M,POBLETE B.Location-aware model for news events in social media[C]//Proceedings of International ACM SIGIR Conference.New York,USA:ACM Press,2015:935-938.
[16] LAPPAS T,VIEIRA M R,GUNOPULOS D,et al.On the spatiotemporal burstiness of terms[J].Proceedings of the VLDB Endowment,2012,5(9).
[17] TAMURA K,MATSUI T,KITAKAMI H,et al.Identifying local temporal burstiness using MACD histogram[C]//Proceedings of IEEE International Conference on Systems,Man,and Cybernetics.Washington D.C.,USA:IEEE Press,2015:2666-2671.
[18] DODDINGTON G,MITCHELL A,PRZYBOCKI M,et al.The automatic content extraction program-tasks,data,and evaluation[C]//Proceedings of LREC’04.Washington D.C.,USA:IEEE Press,2004:158-165.
[19] PUSTEJOVSKY J,HANKS P,SAURI R,et al.The timebank corpus[C]//Proceedings of Corpus Linguistics Conference.Washington D.C.,USA:IEEE Press,2003:215-222.
[20] LAFFERTY J D,MCCALLUM A,PEREIRA F C N.Conditional random fields:probabilistic models for segmenting and labeling sequence Data[J].Machine Learning 2002,3(2):282-289.
[21] 馬雷雷,李宏偉,連世偉,等.地名知識輔助的中文地名消歧方法[J].地理與地理信息科學,2016,32(4):5-10.
[22] SILVA J A,FARIA E R,BARROS R C,et al.Data stream clustering:a survey[J].ACM Computing Surveys,2014,46(1):13.
[23] 蔡偃武.面向大規模數據的在線新事件檢測[D].上海:華東理工大學,2014.
[24] YIN J,WANG J.A text clustering algorithm using an online clustering scheme for initialization[C]//Proceedings of ACM SIGKDD International Conference.New York,USA:ACM Press,2016:1995-2004.
[25] PENNINGTON J,SOCHER R,MANNING C.Glove:global vectors for word representation[C]//Proceedings of Conference on Empirical Methods in Natural Language Processing.Washington D.C.,USA:IEEE Press,2014:1532-1543.
[26] MIKOLOV T,CHEN K,CORRADO G,et al.Efficient estimation of word representations in vector space[EB/OL].[2013-01-12].https://www.mendeley.com.
[27] FENG W,ZHANG C,ZHANG W,et al.STREAMCUBE:hierarchical spatio-temporal hashtag clustering for event exploration over the twitter stream[C]//Proceedings of IEEE International Conference on Data Engineering.Washington D.C.,USA:IEEE Press,2015:1561-1572.
[28] BLER D M,LAFFERTY J D.Dynamic topic models[C]//Proceedings of DBLP’06.Washington D.C.,USA:IEEE Press,2006:113-120.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
開放教育研究(2020年2期)2020-03-31 01:54:14
現代語文(2016年21期)2016-05-25 13:13:44
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
