基于OLAP 的車輛器材數據倉庫數據挖掘
2018-05-30 01:51:12郭江強
物流技術 2018年5期
郭江強
(陸軍軍事交通學院 學員四大隊,天津 300161)
1 引言
建立數據倉庫的功能之一是為了能夠對管理活動中的相關決策問題提供支持。OLAP是在多維數據的基礎之上,利用數據聚合技術,針對數據倉庫中的大量數據進行重組并匯總,再采用聯機分析(Online Analysis)以及可視化工具對數據進行評估,最后將分析結果返回并呈現給用戶。建立器材庫存數據倉庫,最基本應用為利用其進行數據的OLAP分析。OLAP分析的目的是為了實現決策支持的功能或者是在進行多維數據的的查詢并實現報表功能。根據所建立的多維數據集,可以在此基礎上采用OLAP的分析操作,例如切片、切塊、上卷、下鉆、旋轉操作等。通過OLAP進行多維度的分析,可以多角度地展示數據之間的關系。
2 OLAP技術概述
2.1 OLAP特性
OLAP技術支持管理人員在多維數據環境下進行決策時的數據分析和查詢操作,OLAP技術一般具有以下四個特性:
(1)多維性。利用OLAP技術進行多維數據分析,通常為面向主題,其主題可以涉及到業務流程的各個方面,體現在數據集上則為不同的數據維度。管理人員和分析人員通過OLAP技術可以從多個角度來觀察數據,并通過不同的主題維度分析數據,以得到最終的直觀且有效的信息。
(2)可理解性。OLAP所基于的數據倉庫或數據集市可以處理與應用相關的所有統計分析和業務邏輯,并且使其對目標用戶具有較好的可理解性。
(3)交互性。OLAP可以通過對比的方式,為用戶提供個性化的查看方式。對模型中的過往數據以及計算數據進行分析。使用者可以在分析中定義運算并以所希望的方式報告數據。
(4)快速性。OLAP系統應通過使用各種技術以盡可能的提高響應的速度。即使在數據庫中的數據較為復雜且規模十分大的情況下,也能夠提供快速的查詢響應。
基本的OLAP體系結構如圖1所示,而OLAP中的數據組織方式對分析的效率和靈活度具有重要的作用,效率和靈活度也是反應OLAP技術的重要指標。
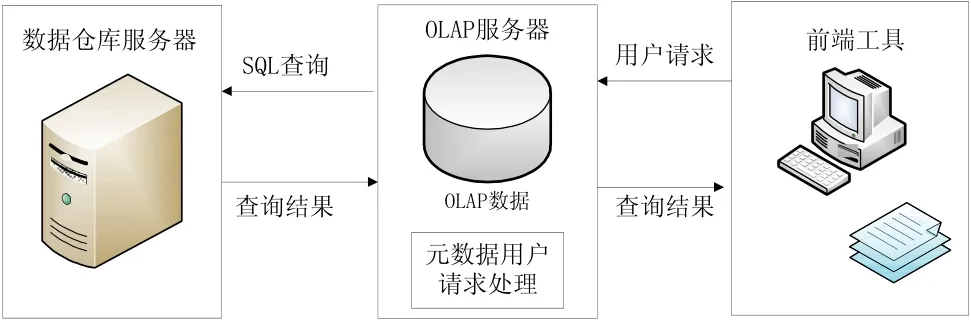
圖1 OLAP體系結構
2.2 OLAP基本分析操作
OLAP基本分析操作一般是指通過數據的切塊操作、切片操作、旋轉操作以及上卷和下鉆操作等對多維數據集實現不同層次、不同角度的瀏覽,通過這些數據分析手段,用戶能夠進行全方位多角度的數據瀏覽。
(1)數據切片。數據的切片操作是通過選擇多維數據集中某一個維度成員得到一個子集,例如,在多維數據集(維1,維2,…,維i,…,維n,度量列表)選定一個維度i,選取其中的維度成員vi,得到子集(維1,…,維i-1,維成員vi,維i+1,…,維n,度量列表)則是維度i上的切片。
(2)數據切塊。數據切塊操作是通過選擇多維數據集(維1,維2,…,維n,度量列表)中兩個或以上的維度,由其構成子集。例如,選擇其中的維度i中的vi和vj,維度j中的ui和uj所得到子集(維1,維2,…,vi或vj…,ui或uj,…,維n,度量列表)為數據的切塊。
(3)數據旋轉。數據的旋轉也被稱為轉軸,是一種視圖操作。通過改變頁面或報告顯示維方向,從不同的視角對數據進行觀察,通過對觀察數據視角進行轉動來改變現有的數據表示。數據的旋轉可以包含交換數據行和數據列,體現在數據維度位置的變換,如二維表中行與列進行交換、將行移動到列的位置、將在當前所顯示的維與未顯示的維進行互換。
(4)數據上卷。數據的上卷操作是利用維度的分層對底層的數據進行向上歸攏。如某一個維度是器材的分類,則由具體器材型號向小類上卷,得到小類的聚集數據,再由小類向大類上卷,得到大類的聚集數據。
(5)數據下鉆。數據的下鉆作為數據上卷的逆操作,其目的是進一步細化數據,確保用戶能夠在多層數據中通過信息導航獲得大量細節更加詳盡的數據。
2.3 數據挖掘系統結構及設計思想
圖2是一個較為通用的數據挖掘系統結構示意圖。
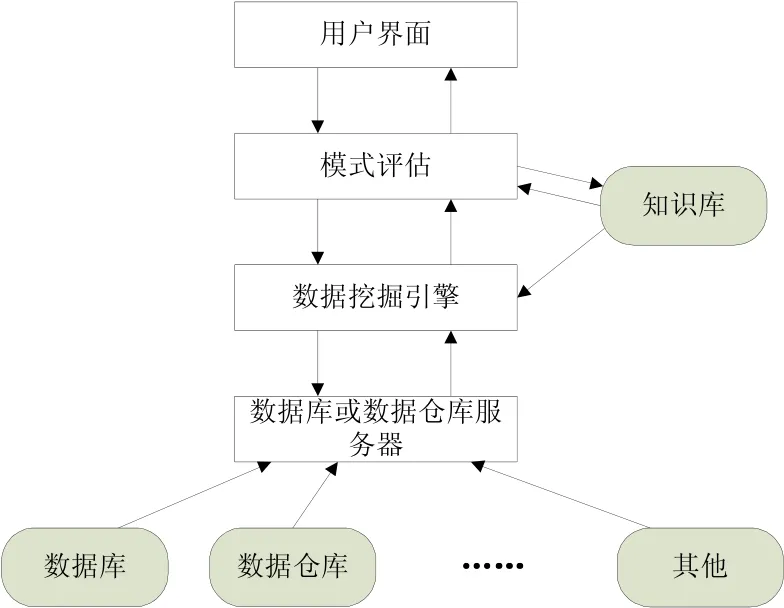
圖2 數據挖掘系統結構
數據挖掘所使用的數據可以來源于業務數據庫,也可以直接從數據倉庫中提取,即利用數據庫或是數據倉庫服務器,向數據挖掘系統提供目標數據集。數據挖掘引擎處于整個系統的核心位置,負責為系統提供挖掘分析模塊,并執行數據挖掘的一系列功能。用戶界面負責實現用戶與整個系統的交互,使用戶可以指定數據挖掘任務并設定模式評估參數,并且可以向用戶提供數據挖掘的結果。知識庫負責提供領域知識,指導數據挖掘的過程以及結果模式的興趣度。
3 基于車輛器材數據倉庫QCDW的OLAP分析
對通用的車輛器材數據倉庫,分別利用決策樹分類預測模型、BP人工神經網絡預測模型、時序數據挖掘模型三種模型對其進行深入的挖掘分析,利用挖掘的結果對車輛器材倉庫的訂貨計劃、發貨量等指標進行預測以輔助倉庫管理人員進行決策。
本文的挖掘分析基于Microsoft SQL Server中集成的決策樹挖掘模型,利用SSAS(SQL Server Analysis Service)所提供的回歸及分類算法進行預測性建模。
3.1 建立模型實例
(1)挖掘問題的提出。為了能夠清晰的反映出各項屬性指標對倉庫是否進行訂貨造成的影響,研究選取了若干個指標,并導入已建立數據倉庫中的相關數據。
在此基礎上,通過決策樹挖掘方法發現這幾個因素之間存在怎樣的約束關系。在進行數據挖掘操作之前,需要先進行數據挖掘所要使用的數據庫表結構的設計。進行數據挖掘使用的主要數據表結構見表1。
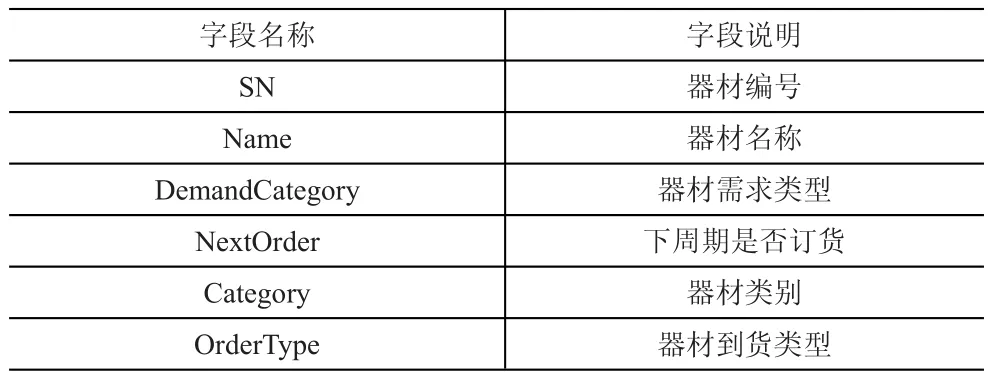
表1 數據庫表結構
上表中,SN為各項器材的編號,對于某一特定型號的器材其編號為唯一,將其設置為鍵列,NextOrder表示下一周期是否需要進行訂貨,其中的數據來源于其余列數據的下一周期數據。Name表示器材的中文名稱。Category為器材的種類,所使用的分類方法是基于前文構建的多因子綜合分類模型,可將器材分為Ⅰ、Ⅱ、Ⅲ共三類。DemandCategory表示需求方對器材的需求種類,根據需求的緊急程度可以分為一、二、三共三個等級。OrderType表示器材訂貨的到貨種類,可分為瞬時到貨(一次性到貨)與持續到貨(分批到貨)兩類。
(2)指定數據列的用法。根據挖掘算法的要求和需求分析,規定列的用法見表2。
(3)挖掘參數的設置。SSAS決策樹模型算法通過對相關模型參數進行定義,對樹的生長以及形狀進行控制。通過調整參數可以使模型最終的預測結果更加精準。參數主要有以下幾個:
Complexity_Penalty,該參數主要用于對決策樹的生長過程進行控制。Complexity_Penalty是一個浮點參數,其定義區間在0至1。若參數的設置越趨近于0,則意味著模型在訓練過程中對樹的生長越不做限制,最終有可能會出現一顆十分龐大的決策樹。如果對參數的設置越趨近于1,則樹在訓練過程中的每次生長都會受到更大的限制,最終得到的決策樹規模也會相對較小。本文的決策樹輸入的屬性少于10個,所以Complexity_Penalty的取值默認設置為0.5。Minimum_Support,用于指派每個分類中的最小實例數。默認值設置為1。
Score_Method,其用于指定決策樹在生長過程中的分裂指數。SSAS使用Bayesian Dirichlet Equivalent with Uniform prior(BDEU)方法,基于節點的層次可以為每一個可預測的狀態增加加權支持度。BDEU方法的默認值設置為4。
Split_Method,通過對該參數的設置,可以調整決策樹的形狀。取值為1則代表樹以二叉的方式進行拆分,取值為2表示采用完全拆分的形式進行拆分。通常情況下將其設置為3,表示決策樹能夠根據具體的問題自動選擇其中更為合適的形式進行拆分。

表2 數據列的用法
3.2 挖掘預測過程
在進行數據挖掘之前,先在SQL Management Studio中的數據庫中建立表DecisionTree,結構如圖3所示,并將之前數據倉庫中的相關數據進行轉換并導入。
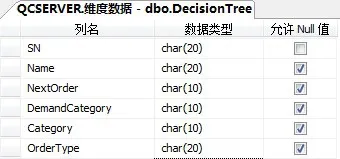
圖3 數據庫表結構
同時再創建一個具有相同結構的表Decision-Tree_1,用于分類預測。表中輸入待預測的數據。其中的類別屬性,即NextOrder設置為空。
做好數據準備之后,開始數據挖掘工作,整個挖掘的流程包含數據源的設置、數據源視圖設置和創建數據挖掘的結構三個步驟。
(1)數據源的設置。啟動SQL Server Business Intelligence Development Studio,打開創建的項目,然后新建數據源并連接管理器,進行模擬信息的選擇。
(2)數據源視圖的設置。在解決方案資源管理器界面中,進入之前已創建項目QCDW,進行數據源的選擇,并選擇已創建的QcForecast表。
在選擇完數據表之后,在名稱輸入框中輸入名稱創建“決策樹.dsv”,完成數據源視圖設置。同時新建立一個數據源視圖,并選擇QcForecast_1數據表。
(3)創建數據挖掘結構。根據數據挖掘向導流程,進行數據挖掘結構的創建。選擇Microsoft決策樹挖掘技術,然后選擇已創建好的數據源視圖。
在指定定型數據的頁面,在各個選項的右邊勾選,可分別把不同的表和列數據設置為輸入列、預測列、鍵表和鍵列,在本挖掘模型中,將NextOrder(是否訂貨)作為預測列,SN(器材編號)作為鍵列,其余列作為輸入列進行預測。
(4)進行算法相關參數的設置。由于本模型中的事件數據量較少,且葉子節點中最小事件數為2,進入“挖掘模型”頁面中,將COMPLEXITY_PENALTY設置為0.01,將MINIMUM_SUPPORT設置為2。
(5)部署決策表分類項目并瀏覽挖掘結果。在設置完挖掘參數后,對系統執行部署,完成后可以在挖掘結構窗口中對挖掘模型進行查看,如圖4所示。算法將具有顯著聯系的屬性進行回歸,可得三層的決策樹結構。其中,第二層的分支為器材訂貨的到貨類型,第三層的分支為器材的種類。將鼠標移動到相應的決策樹節點位置,會出現對應的分類決策結果。例如當選擇決策樹第三層的最下方節點時,表示器材到貨類型為分批到貨,器材類別為Ⅲ類,則下一周期需要進行訂貨,且在所有樣本中對應該類型的事件個數為2。
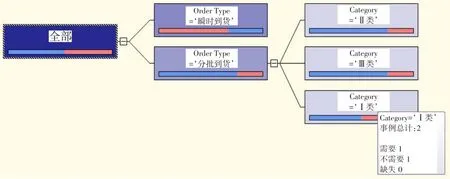
圖4 挖掘模型所創建的決策樹
3.3 利用決策樹進行分類預測
利用已建立的決策樹模型,可以根據器材的各項輸入信息對其下一周期內是否需要訂貨進行預測。
進入“挖掘模型預測”選項卡頁面中,選擇數據源“決策樹1”中的事例表DecisionTree_1表。保持各字段之間的默認連接關系,將DecisionTree_1表中的各列拖入到下方,進行相應設置,如圖5所示。
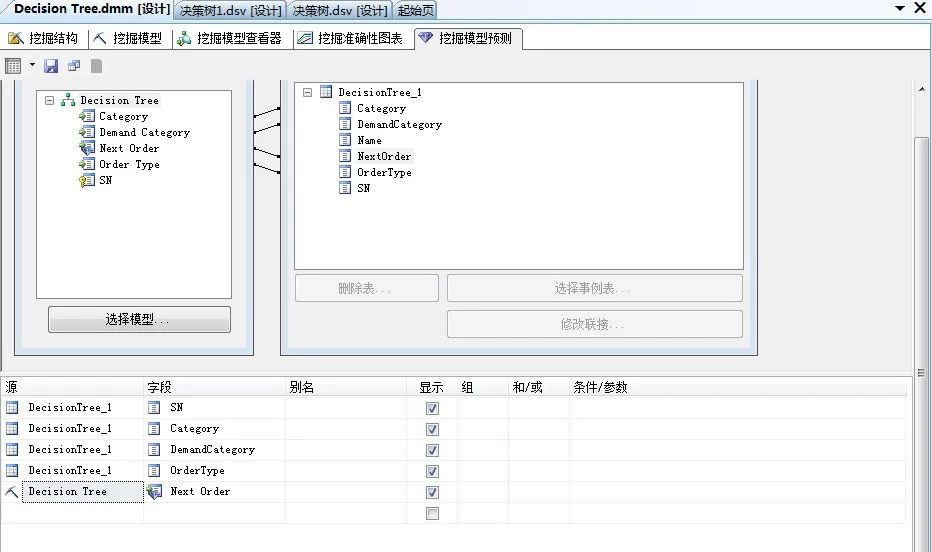
圖5 創建挖掘預測結構
對挖掘分析的結果進行查看,可得到如圖6所示的分類預測結果,預測結果的第一列至第四列分別為器材編號、器材種類、器材需求的類型、器材的到貨方式,最后一列為同時滿足器材種類、器材需求種類和器材到貨方式分類條件的器材在下一周期內是否需要進行訂貨。例如第一行所示,器材編號為152101010200,對應器材為發動機總成帶變速,其器材種類為Ⅰ類,需求類型為二級,到貨類型為分批到貨,則對于該類器材,在下一個訂貨周期內,倉庫的管理決策人員不需要對其做訂貨計劃。
對于挖掘預測所得的結果,倉庫的管理人員可以將預測所得數據存放于一個新建數據庫表,作為制定決策計劃的參考或是用于進一步的分析。
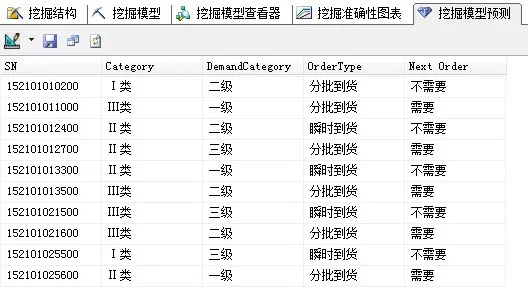
圖6 決策樹預測結果
4 Microsoft時序算法的倉庫發貨量預測分析
Microsoft時序算法將自回歸模型與決策樹模型相結合,因此該也通常被稱為自回歸樹算法(ART)。
xt=?1xt-1+?2xt-2+...+?pxt-p+et,xt表示用于分析的時間序列,p和?i分別表示自回歸的階數與系數,et表示數據噪聲。一般用于計算自回歸系數的較為常用的方法是,通過最小化建模,計算出序列xnmodel與實際觀測的序列xn間的平方差。
在所建立的模型里,函數f表示回歸樹,通常被稱為自回歸樹(ART)。大多數時間序列都存在季節性的因素,在不同季節的月份里其數據往往存在一定的差別。ART算法在處理過程中通過事例的轉換,在考慮初始的幾個時間片段之外,還同時參考了與季節因子有關的參數。在一個時間序列中可以包含多個周期的標志,如一個器材倉庫的月出庫量可以按照一年12個月作為周期,也可以以一個季度作為周期,在同時存在多個不同周期時,ART算法則通過季節性轉換,在事例表中添加多個不同列。當周期不確定時,Microsoft所提供的算法可以對季節性因素進行自動檢測。
時序算法是基于Microsoft SQL Server Analysis Services內置的模型算法,實現對挖掘模型的創建,并利用預測函數實現連續型時間序列的預測。區別于決策樹依靠輸入列進行預測,在使用時序模型進行預測時,以從模型的原始數據集中所產生的衍生趨勢作為預測的依據。
4.1 建立模型實例
本研究試圖通過SQL Server Analysis Service建立一個隨機時序模型,對倉庫的發貨量進行模擬預測。
首先獲取倉庫某型器材從2013年1月至2014年12月的發貨量數據,最后四個月的數據沒有給出,建立隨機型時間序列模型,對最后四個月內的發貨量進行預測,見表3。
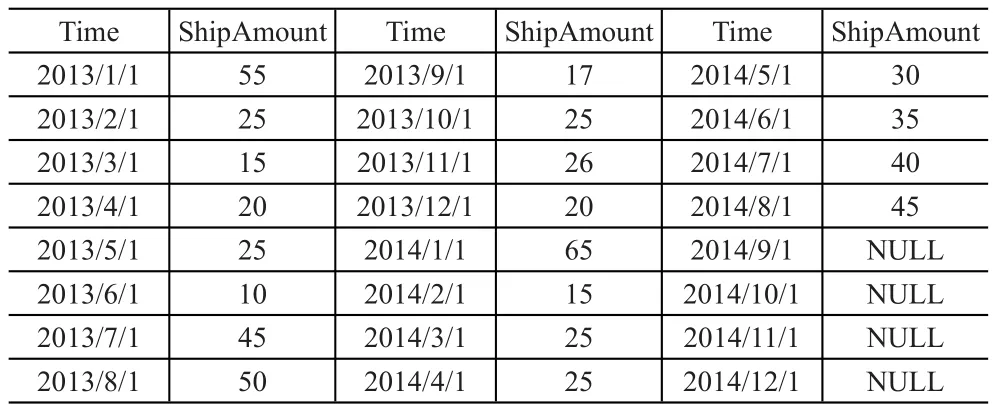
表3 倉庫各月份某器材發貨量數據表
在SQL Server Mnagement Studio中建立數據表TimeSeq,表結構如圖7所示。

圖7 TimeSeq表結構
4.2 挖掘預測過程
利用SSAS平臺,首先進行數據源視圖的創建,并進一步建立挖掘結構。
4.3 挖掘預測結果分析
如圖8所示,橫軸為統計的時間,用年月日進行表示。縱軸為XXX車輛器材倉庫的發貨量統計,在橫軸方向2014/8/1左側用實現表示為已給出的統計數據,在2014/8/1右側使用虛線表示2014/9/1至2014/12/1的器材發貨量預測值。將光標指針至于虛線處,可以直觀的顯示出具體的預測數據值,如圖中所展示的,2014年十月份的出庫量預測值為31。

圖8 預測值的展示
在進行隨機時間序列的預測時,由于實際的出庫量會受到各種不可控因素的制約,因此不可避免的會出現與實際數據的預測偏差,鑒于此,模型提供對歷史預測信息和預測偏差的展示,如圖9所示,虛線與實線之間的豎線為預測的偏差,可以從圖中直觀的看出預測模型的準確程度,決策人員可以針對存在的誤差再做進一步的分析和調整。
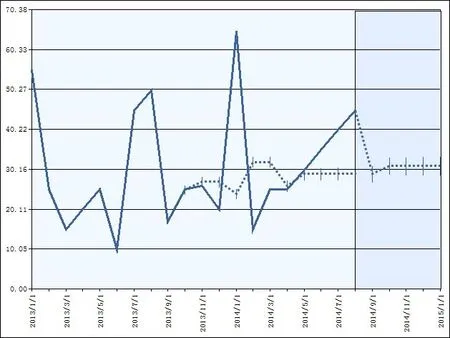
圖9 預測偏差展示
5 小結
本文主要通過OLAP聯機分析處理和基于車輛器材數據倉庫QCDW的數據挖掘,針對車輛器材倉庫中的存在的部分管理決策問題進行了重點分析。具體包括利用OLAP技術對數據倉庫中的多維數據進行了切塊、切片等立方操作,實現了多角度、多層次的數據查看,為決策者提供了直觀的參考;利用決策樹分類預測和時序挖掘分析預測了倉庫的發貨量,使用預測的結果為管理人員提供決策支持。
[]
[1]袁長河,吳永明.基于數據倉庫的決策支持系統研究和建設[J].計算機工程與應用,2013,(16):75-79.
[2]謝民主,王加陽,蔣外文.數據倉庫的多維數據模型的研究[J].計算機工程與應用,2004,40(25):182-185.
[3]侯筱婷.基于數據倉庫、OLAP和數據挖掘技術的數據分析、展現與預測[D].西安:西安電子科技大學,2007.
[4]呂洪敏.基于Oracle數據倉庫應用技術的研究與實現[D].武漢:武漢科技大學,2007.
[5]王麗珍,周麗華,陳江梅,等.數據倉庫與數據挖掘原理及應用(第二版)[M].北京:科學出版社,2009.
[6]董翔英.SQL Server基礎教程[M].北京:科學出版社,2005.
猜你喜歡
少先隊活動(2021年4期)2021-07-23 01:46:22
大眾投資指南(2021年35期)2021-02-16 01:06:26
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
電力與能源(2017年6期)2017-05-14 06:19:37
山東工業技術(2016年15期)2016-12-01 05:31:22
沈陽醫學院學報(2015年1期)2015-12-27 13:44:40
信息通信技術(2015年6期)2015-12-26 01:16:46
醫學教育管理(2015年3期)2015-12-01 06:43:16
電子設計工程(2014年18期)2014-02-27 12:00:13
