人工智能研究的新前線:生成式對抗網(wǎng)絡(luò)
2018-06-07 16:21:31林懿倫戴星原李力王曉王飛躍
自動化學(xué)報(bào) 2018年5期
林懿倫 戴星原 李力 王曉 王飛躍
近年來,人工智能領(lǐng)域,特別是機(jī)器學(xué)習(xí)方面的研究取得了長足的進(jìn)步.得益于計(jì)算能力的提高,信息化工具的普及以及數(shù)據(jù)量的積累,人工智能研究的迫切性和可行性都大為提高.以Google等為代表的IT企業(yè),利用其掌握的海量數(shù)據(jù)資源,結(jié)合新的硬件結(jié)構(gòu)和人工智能算法,實(shí)現(xiàn)了一系列新突破和新應(yīng)用,并獲得了可觀的收益.這些企業(yè)獲得的成功進(jìn)一步帶動了機(jī)器學(xué)習(xí)的研究熱度,使得人工智能的研究進(jìn)入了一個(gè)新的高潮時(shí)期.
在此次的人工智能浪潮中,以統(tǒng)計(jì)機(jī)器學(xué)習(xí),深度學(xué)習(xí)為代表的機(jī)器學(xué)習(xí)方法是主要的研究方向之一.相比符號主義的研究方法,基于機(jī)器學(xué)習(xí)的人工智能系統(tǒng)降低了對人類知識的依賴,轉(zhuǎn)而使用統(tǒng)計(jì)的方法從數(shù)據(jù)中直接習(xí)得知識.機(jī)器學(xué)習(xí)理論是一次重要的范式革命,使人工智能領(lǐng)域的研究重點(diǎn)從算法設(shè)計(jì)轉(zhuǎn)向了特征工程與優(yōu)化方法.
一般而言,依據(jù)數(shù)據(jù)集是否有標(biāo)記,機(jī)器學(xué)習(xí)任務(wù)可被分為有監(jiān)督學(xué)習(xí)(又稱預(yù)測性學(xué)習(xí),數(shù)據(jù)集有標(biāo)記)與無監(jiān)督學(xué)習(xí)(又稱描述性學(xué)習(xí),數(shù)據(jù)集無標(biāo)記)[1].隨著數(shù)據(jù)收集手段,算力與算法的不斷發(fā)展,在諸多監(jiān)督學(xué)習(xí)任務(wù)中,如圖像識別[2?3],語音識別[4?5],機(jī)器翻譯[6?7]等,機(jī)器學(xué)習(xí)方法,特別是深度學(xué)習(xí)方法都取得了目前最好的成績.
然而,有監(jiān)督學(xué)習(xí)需要人為給數(shù)據(jù)加入標(biāo)簽.這帶來了兩個(gè)問題:一是數(shù)據(jù)集采集后需要大量人力物力進(jìn)行標(biāo)注,大規(guī)模數(shù)據(jù)集的構(gòu)建十分困難;二是對于許多學(xué)習(xí)任務(wù),如數(shù)據(jù)生成,策略學(xué)習(xí)等,人為標(biāo)注的方法較為困難甚至不可行.研究者普遍認(rèn)為,如何讓機(jī)器從未經(jīng)處理的,無標(biāo)簽類別的數(shù)據(jù)中直接進(jìn)行無監(jiān)督學(xué)習(xí),將是AI領(lǐng)域下一步要著重解決的問題.
在無監(jiān)督學(xué)習(xí)的任務(wù)中,生成模型是最為關(guān)鍵的技術(shù)之一.生成模型是指一個(gè)可以通過觀察已有的樣本,學(xué)習(xí)其分布并生成類似樣本的模型.深度學(xué)習(xí)的研究者在領(lǐng)域發(fā)展的早期就極為關(guān)注無監(jiān)督學(xué)習(xí)的問題,基于神經(jīng)網(wǎng)絡(luò)的生成模型在神經(jīng)網(wǎng)絡(luò)的再次復(fù)興中起到了極大的作用.在計(jì)算資源還未足夠豐富前,研究者提出了深度信念網(wǎng)絡(luò)(Deep belief network,DBN)[8],深度玻爾茲曼機(jī)(Deep Boltzmann machines,DBM)[9]等網(wǎng)絡(luò)結(jié)構(gòu),這些網(wǎng)絡(luò)將受限玻爾茲曼機(jī)(Restricted Boltzmann machine,RBM)[10],自編碼機(jī)(Autoencoder,AE)[11]等生成模型作為一種特征學(xué)習(xí)器,通過逐層預(yù)訓(xùn)練的方式加速經(jīng)網(wǎng)絡(luò)的訓(xùn)練[12].
然而,早期的生成模型往往不能很好地泛化生成結(jié)果.隨著深度學(xué)習(xí)的進(jìn)一步發(fā)展,研究者提出了一系列新的模型.生成式對抗網(wǎng)絡(luò)(Generative adversarial networks,GAN)是生成式模型最新,也是目前最為成功的一項(xiàng)技術(shù),由Goodfellow等在2014年第一次提出[13].
GAN的主要思想是設(shè)置一個(gè)零和博弈,通過兩個(gè)玩家的對抗實(shí)現(xiàn)學(xué)習(xí).博弈中的一名玩家稱為生成器,它的主要工作是生成樣本,并盡量使得其看上去與訓(xùn)練樣本一致.另外一名玩家稱為判別器,它的目的是準(zhǔn)確判斷輸入樣本是否屬于真實(shí)的訓(xùn)練樣本.一個(gè)常見的比喻是將這兩個(gè)網(wǎng)絡(luò)想象成偽鈔制造者與警察.GAN的訓(xùn)練過程類似于偽鈔制造者盡可能提高偽鈔制作水平以騙過警察,而警察則不斷提高鑒別能力以識別偽鈔.隨著GAN的不斷訓(xùn)練,偽鈔制造者與警察的能力都會不斷提高[14].
GAN在生成逼真圖像上的性能超過了其他的方法,一經(jīng)提出便引起了極大的關(guān)注.尤為重要的是,GAN不僅可作為一種性能極佳的生成模型,其所啟發(fā)的對抗學(xué)習(xí)思想更滲透進(jìn)深度學(xué)習(xí)領(lǐng)域的方方面面,催生了一系列新的研究方向與應(yīng)用[15].
本文梳理了生成式對抗網(wǎng)絡(luò)的最新研究進(jìn)展,并對其發(fā)展趨勢進(jìn)行展望.第1節(jié)介紹了GAN的提出背景、基本思想與原始GAN存在的缺陷;第2節(jié)介紹了GAN在生成機(jī)制方面的改進(jìn);第3節(jié)介紹了GAN在判別機(jī)制方面的改進(jìn);第4節(jié)對GAN的應(yīng)用發(fā)展進(jìn)行了介紹;最后總結(jié)了GAN領(lǐng)域研究的內(nèi)在邏輯與存在的問題,并對其下一步發(fā)展做出展望.
1 GAN的背景與提出
GAN是在深度生成模型的基礎(chǔ)上發(fā)展而來,但又與以往的模型有顯著區(qū)別.本節(jié)首先簡要介紹深度學(xué)習(xí)與深度生成模型的基本思想與發(fā)展歷史,然后介紹原始GAN的模型結(jié)構(gòu)與訓(xùn)練方法,最后討論原始GAN中存在的不足.
1.1 深度學(xué)習(xí)
深度學(xué)習(xí)是機(jī)器學(xué)習(xí)的一種實(shí)現(xiàn)方法.相比一般的機(jī)器學(xué)習(xí)方法,深度學(xué)習(xí)最主要的區(qū)別是不依賴人工進(jìn)行特征工程.研究者認(rèn)為,手工設(shè)計(jì)的特征描述子往往過早地丟失掉有用信息,直接從數(shù)據(jù)中學(xué)習(xí)到與任務(wù)相關(guān)的特征表示,比手工設(shè)計(jì)特征更加有效[16].
深度學(xué)習(xí)使用多層神經(jīng)網(wǎng)絡(luò)(Multilayer neural network)[17]對數(shù)據(jù)進(jìn)行表征學(xué)習(xí).相比傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)方法,深度學(xué)習(xí)主要在四方面進(jìn)行了突破:1)使用了卷積神經(jīng)網(wǎng)絡(luò)(Convolutional neural network,CNN)[18?19],遞歸神經(jīng)網(wǎng)絡(luò) (Recurrent/recursive neural network,RNN)[20?22]等特殊設(shè)計(jì)的網(wǎng)絡(luò)結(jié)構(gòu),這些新的網(wǎng)絡(luò)結(jié)構(gòu)大大加強(qiáng)了神經(jīng)網(wǎng)絡(luò)的建模能力;2)使用了整流線性單元(Recti fied linear unit,ReLU)[23]、Dropout[24]、Adam[25]等新的激活函數(shù)、正則方法與優(yōu)化算法,這些新的訓(xùn)練技術(shù)有效提高了神經(jīng)網(wǎng)絡(luò)的收斂速度,使得大規(guī)模的神經(jīng)網(wǎng)絡(luò)訓(xùn)練成為可能;3)使用了圖形處理器(Graphics processing unit,GPU)[2,26]、現(xiàn)場可編程邏輯門陣列(Field-programmable gate array,FPGA)[27]、應(yīng)用定制電路(Application-speci fic integrated circuit,ASIC)[28]以及分布式系統(tǒng)[29]等新的計(jì)算設(shè)備與計(jì)算系統(tǒng),這些設(shè)備使得神經(jīng)網(wǎng)絡(luò)的訓(xùn)練時(shí)間大大縮短,從而具有被實(shí)際部署的可能性;4)形成了較為完善的開源社區(qū),出現(xiàn)了Theano[30],Torch[31?32],Tensor flow[33]等被廣泛使用的算法庫,開源社區(qū)的發(fā)展降低了深度學(xué)習(xí)的應(yīng)用門檻,提高了該領(lǐng)域新發(fā)現(xiàn)的可重復(fù)性,吸引了越來越多的研究者加入研究行列.
深度學(xué)習(xí)在模型、算法、硬件設(shè)施與開發(fā)社區(qū)四方面的突破改變了過往神經(jīng)網(wǎng)絡(luò)優(yōu)化困難,應(yīng)用受限,計(jì)算緩慢,認(rèn)可度不高的問題,使得該技術(shù)的影響力不斷擴(kuò)大.目前,深度學(xué)習(xí)已成為人工智能研究中的一種主流方法.深度學(xué)習(xí)在監(jiān)督學(xué)習(xí)任務(wù),尤其是在圖像識別[34]任務(wù)上的突破尤為令人矚目.
1.2 深度生成模型
無監(jiān)督學(xué)習(xí)具有重要的研究與應(yīng)用價(jià)值.其一是有標(biāo)記的數(shù)據(jù)較為稀缺,或是數(shù)據(jù)的標(biāo)注與所希望研究的問題不直接相關(guān),此時(shí)必須使用無監(jiān)督或半監(jiān)督學(xué)習(xí)的方法[35];其二是高層次的表征學(xué)習(xí)有助于其他任務(wù)的學(xué)習(xí),可以幫助模型避免陷入局部最優(yōu)點(diǎn),或是添加一定的限制使得模型泛化能力提高[36];其三是在一些強(qiáng)化學(xué)習(xí)的場景下,我們無法得知未來任務(wù)的具體形式,而僅知道這些任務(wù)與環(huán)境有較為確定性的關(guān)系.無監(jiān)督學(xué)習(xí)可提高代理(Agent)對環(huán)境的預(yù)測能力,從而有效提高代理的表現(xiàn)水平[37];最后,對于一些問題我們希望有多樣化的回答而不僅僅是返回一個(gè)確定性的答案,有監(jiān)督學(xué)習(xí)到的模型無法實(shí)現(xiàn)這一要求[14,36].
生成模型是無監(jiān)督學(xué)習(xí)的核心任務(wù)之一.雖然深度學(xué)習(xí)在早期研究中使用了自編碼機(jī),受限玻爾茲曼機(jī)等一系列生成模型,但這些模型往往會出現(xiàn)過擬合現(xiàn)象,不能很好地泛化以生成多樣性樣本.
為了解決這一問題,研究者提出了一種名為隨機(jī)反向傳播(Stochastic back-propagation)[38]的方法.通過加入額外的獨(dú)立于模型的隨機(jī)輸入z,我們可以將確定性的神經(jīng)網(wǎng)絡(luò)f(x)轉(zhuǎn)化為具有隨機(jī)性的f(x,z),并使用反向傳播的方法進(jìn)行訓(xùn)練.這一方法可以提高生成模型輸出樣本的多樣性.
以變分自編碼機(jī)(Variational auto-encoder,VAE)[39]為例.如圖1所示,VAE的一種簡單實(shí)現(xiàn)是假設(shè)生成樣本x為高斯分布,即


圖1 變分自編碼機(jī)Fig.1 Variational auto-encoder
若將某一隨機(jī)變量直接輸入網(wǎng)絡(luò)中,由于此時(shí)與輸入x的關(guān)系不唯一,網(wǎng)絡(luò)可能出現(xiàn)優(yōu)化困難的問題.我們可以通過設(shè)置隨機(jī)變量z~N(0,1),并構(gòu)建編碼器網(wǎng)絡(luò)μ=g1(x),σ=g2(x),原網(wǎng)絡(luò)轉(zhuǎn)化為

通過反向傳播算法,網(wǎng)絡(luò)可以獲得更好的均值與標(biāo)準(zhǔn)差估計(jì),不斷提高生成模型的生成效果.在VAE的工作中,這一方法被稱為重參數(shù)化技巧(Reparameterization trick).
深度學(xué)習(xí)與隨機(jī)反向傳播方法的出現(xiàn)使得使用神經(jīng)網(wǎng)絡(luò)生成復(fù)雜隨機(jī)樣本成為可能,如何使得生成樣本在具備多樣性的同時(shí)保持原樣本的模式特征成為了主要的研究問題.
1.3 生成式對抗網(wǎng)絡(luò)
Goodfellow等提出了生成式對抗網(wǎng)絡(luò)模型.GAN由一組對抗性的神經(jīng)網(wǎng)絡(luò)構(gòu)成(分別稱為生成器和判別器),生成器試圖生成可被判別器誤認(rèn)為真實(shí)樣本的生成樣本.與其他生成模型相比,GAN的顯著不同在于,該方法不直接以數(shù)據(jù)分布和模型分布的差異為目標(biāo)函數(shù),轉(zhuǎn)而采用了對抗的方式,先通過判別器學(xué)習(xí)差異,再引導(dǎo)生成器去縮小這種差異.生成器G接受隱變量z作為輸入,參數(shù)為θ.判別器D的輸入為樣本數(shù)據(jù)x或是生成樣本=G(z),參數(shù)為φ.GAN的網(wǎng)絡(luò)結(jié)構(gòu)如圖2所示:

圖2 生成式對抗網(wǎng)絡(luò)Fig.2 Generative adversarial networks
GAN中的生成器與判別器可被視作博弈中的兩個(gè)玩家.兩個(gè)玩家有各自的損失函數(shù)J(G)(θ,φ)與J(D)(θ,φ),訓(xùn)練過程中生成器和判別器會更新各自的參數(shù)以極小化損失.GAN的訓(xùn)練實(shí)質(zhì)是尋找零和博弈的一個(gè)納什均衡解,即一對參數(shù)(θ,φ)使得θ是J(G)的一個(gè)極小值點(diǎn),同時(shí)φ是J(D)的一個(gè)極小值點(diǎn).兩個(gè)玩家的損失函數(shù)都依賴于對方的參數(shù),但是卻不能更新對方的參數(shù),這與一般的優(yōu)化問題有很大的不同.
在GAN的原始論文中,Goodfellow將判別器的損失函數(shù)定義為一個(gè)標(biāo)準(zhǔn)二分類問題的交叉熵.真實(shí)樣本對應(yīng)的標(biāo)簽為1,生成樣本對應(yīng)的標(biāo)簽則為0.J(D)的形式為

對于生成器的損失函數(shù),根據(jù)博弈形式的不同有所區(qū)別.對于最簡單的零和博弈,生成器的損失即為判別器所得:

在這一設(shè)定下,我們可以認(rèn)為,GAN的關(guān)鍵在于優(yōu)化一個(gè)關(guān)于判別器的值函數(shù):

此時(shí),GAN的訓(xùn)練可以看作一個(gè)min-max優(yōu)化過程:

相比以往的生成模型,GAN模型具有以下幾點(diǎn)明顯的優(yōu)勢:一是數(shù)據(jù)生成的復(fù)雜度與維度線性相關(guān),對于較大維度的樣本生成,僅需增加神經(jīng)網(wǎng)絡(luò)的輸出維度,不會像傳統(tǒng)模型一樣面臨指數(shù)上升的計(jì)算量;二是對數(shù)據(jù)的分布不做顯性的限制,從而避免了人工設(shè)計(jì)模型分布的需要;三是GAN生成的手寫數(shù)字、人臉、CIFAR-10等樣本較VAE、PixelCNN等生成模型更為清晰[14].然而,原始GAN模型也存在許多問題.
1.4 GAN存在的問題
阻礙原始GAN發(fā)展的首要問題是不收斂問題.對于有明確目標(biāo)函數(shù)的深度學(xué)習(xí)問題,一般可以使用基于梯度下降的優(yōu)化算法加以訓(xùn)練.GAN的訓(xùn)練與這類問題不同,其目的是要找到一個(gè)納什均衡點(diǎn).由于一個(gè)玩家沿梯度下降的更新過程可能導(dǎo)致另一個(gè)玩家的誤差上升,在二者行為可能彼此抵消的情況下,目前沒有理論分析證明GAN總可以達(dá)到一個(gè)納什均衡點(diǎn).在實(shí)踐中,生成式對抗網(wǎng)絡(luò)通常會產(chǎn)生振蕩,這意味著網(wǎng)絡(luò)在生成各種模式的樣本之間徘徊,從而無法達(dá)到某種均衡.一種常見的問題是GAN將若干不同的輸入映射到相同的輸出點(diǎn),如生成器輸出了包含相同顏色與紋理的多幅圖片,這種非收斂情形被稱為模式坍塌(Model collapse,又稱the Helvetica scenario).
其次,原始GAN只能用于生成連續(xù)數(shù)據(jù),無法生成離散數(shù)據(jù)(如自然語言).從直觀上理解,由于生成器每次更新后的輸出是之前的輸出加判別器回傳的梯度,其輸出必須是連續(xù)可微的.更進(jìn)一步地,有研究者指出,是由于原始GAN論文中使用了Jensen-Shannon(JS)散度JSD(Pr||Pg)作為衡量生成樣本的度量標(biāo)準(zhǔn)[40],即使使用詞的分布或embedding等連續(xù)的表示方法也無法實(shí)現(xiàn)很好的離散數(shù)據(jù)生成.
最后,相比其他的生成模型,GAN的評價(jià)問題更加困難.與VAE不同,GAN的輸入僅有隨機(jī)數(shù)據(jù),無法使用MAE等重構(gòu)指標(biāo)進(jìn)行衡量.一般而言,除了通過人類測試員對生成樣本進(jìn)行評價(jià)外,研究者還使用Inception score(IS)[41],Frechet inception distance(FID)[42?43]等方法評價(jià)生成圖像,使用BLEU分?jǐn)?shù)評判機(jī)器翻譯質(zhì)量[44].由于這種方式可以自動進(jìn)行大規(guī)模的評估與展示,研究者往往將在這些自動化評價(jià)指標(biāo)上的提升作為主要的貢獻(xiàn).
然而,有研究指出,在評價(jià)分?jǐn)?shù)上的提升更可能來自計(jì)算資源與調(diào)參技巧上的改進(jìn),而非算法上的突破[45].此外,對于圖像生成任務(wù)而言,基于概率估計(jì)的評價(jià)方法與視覺評價(jià)方法相互獨(dú)立,一個(gè)具有更高評價(jià)分?jǐn)?shù)的模型并不能必然地產(chǎn)出更高質(zhì)量的樣本[46].在實(shí)際中,研究者需要根據(jù)具體目的去選擇合適的評價(jià)指標(biāo).
2 GAN生成機(jī)制的發(fā)展
面對原始GAN的種種不足,研究者從多個(gè)方面嘗試加以解決.在生成機(jī)制方面,研究者主要利用了深度學(xué)習(xí)在有監(jiān)督學(xué)習(xí)任務(wù)上取得的成果對GAN加以改進(jìn).主要包括了使用新的網(wǎng)絡(luò)結(jié)構(gòu)、添加正則約束、集成多種模型、改變優(yōu)化算法等改進(jìn).需要說明的是,這四類方法往往會同時(shí)出現(xiàn)在一個(gè)工作中,本文根據(jù)它們的主要貢獻(xiàn)作為分類依據(jù).
2.1 網(wǎng)絡(luò)結(jié)構(gòu)
DCGAN[47]是GAN發(fā)展早期比較典型的一類改進(jìn).卷積神經(jīng)網(wǎng)絡(luò)(Convolutional neural network,CNN)是圖像處理任務(wù)中常用的一種網(wǎng)絡(luò)結(jié)構(gòu),被認(rèn)為可以自動提取圖像的特征[36].DCGAN將生成器中的全連接層用反卷積(Deconvolution)層[48]代替,在圖像生成的任務(wù)中取得了很好的效果,其參數(shù)設(shè)置如圖3所示.此后,使用GAN進(jìn)行圖像生成任務(wù)時(shí),默認(rèn)的網(wǎng)絡(luò)結(jié)構(gòu)一般都與DCGAN類似的設(shè)置.目前,GAN在網(wǎng)絡(luò)結(jié)構(gòu)方面的改進(jìn)主要通過添加額外信息或是對隱變量進(jìn)行特殊處理來實(shí)現(xiàn).研究人員發(fā)現(xiàn)使用半監(jiān)督的方式,如添加圖像分類標(biāo)簽的方法會極大地提高GAN生成樣本的質(zhì)量[41].這可能是由于添加了圖像標(biāo)簽等信息后,GAN會更關(guān)注對于闡釋樣本相關(guān)的統(tǒng)計(jì)特征,并忽略不太相關(guān)的局部特征.
基于這種猜想,條件生成式對抗網(wǎng)絡(luò)(Conditional GAN,CGAN)[49]提出了一種帶條件約束的GAN,在生成模型G和判別模型D的建模中均引入條件變量c,使用額外信息對模型增加條件,以指導(dǎo)數(shù)據(jù)的生成過程.CGAN結(jié)構(gòu)如圖4所示.
CGAN中的條件變量c一般為含有特定語義信息的已知條件,如樣本的標(biāo)簽.生成器接受噪聲z與條件變量c,生成樣本G(z|c)與相同條件變量c控制下的真實(shí)樣本一起用于訓(xùn)練判別器.相應(yīng)的,CGAN的目標(biāo)函數(shù)為:

ACGAN[50]是CGAN作者的后續(xù)工作.它在判別器D的真實(shí)數(shù)據(jù)x也加入了類別c的信息,進(jìn)一步告訴G網(wǎng)絡(luò)該類的樣本結(jié)構(gòu)如何,從而生成更好的類別模擬.

圖3 DCGAN的拓?fù)浣Y(jié)構(gòu)[47]Fig.3 Schematic of DCGAN architecture[47]

圖4 CGAN的拓?fù)浣Y(jié)構(gòu)Fig.4 Schematic of CGAN architecture
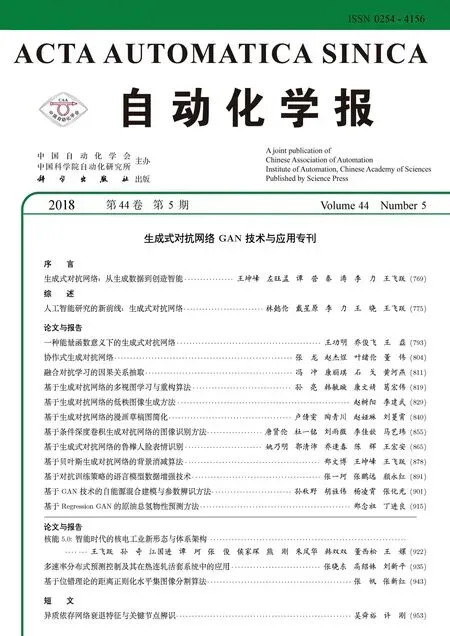
InfoGAN[51]發(fā)展了這種思想.通過引入互信息量,InfoGAN不僅免去了使用標(biāo)注數(shù)據(jù)的必要性,還使得GAN的行為具有了一定的可解釋性.InfoGAN的結(jié)構(gòu)如圖5所示

圖5 InfoGAN的拓?fù)浣Y(jié)構(gòu)Fig.5 Schematic of InfoGAN architecture
InfoGAN的生成器與CGAN類似,同時(shí)接受噪聲z與服從特定分布的隱變量c作為輸入.與CGAN不同的是,InfoGAN接受的隱變量并非已知信息,其含義需要在訓(xùn)練過程中去發(fā)現(xiàn).判別器會輸出與原始GAN類似的判斷,同時(shí)InfoGAN還有一個(gè)額外的解碼器Q,用于輸出解碼后的條件變量Q(c|x).InfoGAN的目標(biāo)函數(shù)為原始GAN的目標(biāo)函數(shù)加上條件變量與生成樣本間的互信息,即:
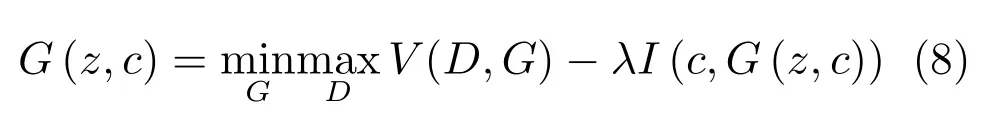
其中第二項(xiàng)為互信息量約束:

λ是該約束項(xiàng)的超參數(shù).互信息量約束使得輸入的隱變量c對生成數(shù)據(jù)的解釋性越來越強(qiáng).
除了有助于提高GAN的生成質(zhì)量,該類網(wǎng)絡(luò)還可實(shí)現(xiàn)生成指定類隨機(jī)樣本的功能.CGAN通過直接在網(wǎng)絡(luò)輸入中加入條件信息c以達(dá)到輸出特定類別樣本的目的.InfoGAN可以通過調(diào)整隱變量實(shí)現(xiàn)改變生成數(shù)字的傾斜角度,對人臉的三維模型進(jìn)行旋轉(zhuǎn)等操作.
除了在目標(biāo)函數(shù)中對隱變量添加約束外,部分工作利用自編碼機(jī)可學(xué)習(xí)隱變量表示的性質(zhì)對GAN進(jìn)行了改進(jìn).以VAE-GAN[52]為例,該模型將變分自編碼機(jī)與GAN結(jié)合,其結(jié)構(gòu)如圖6所示.
該類模型同時(shí)訓(xùn)練GAN與VAE模型,其目標(biāo)函數(shù)由三部分組成:

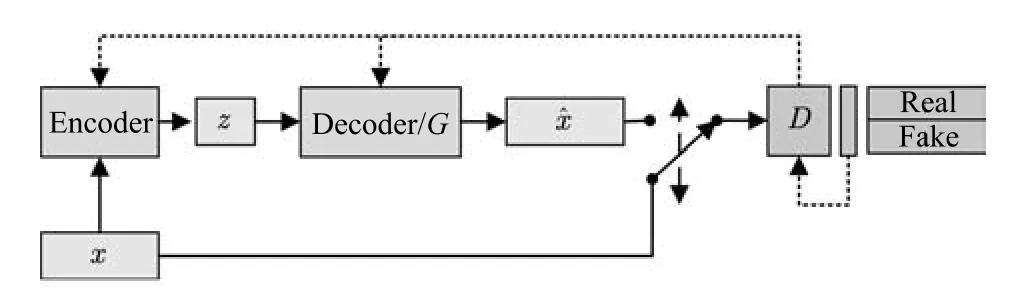
圖6 VAE/GAN的拓?fù)浣Y(jié)構(gòu)Fig.6 Schematic of VAE/GAN architecture
其中,LGAN為GAN模型的目標(biāo)函數(shù),Lprior為VAE的先驗(yàn)約束

p(z)為隱變量z的先驗(yàn)分布,q(z|x)為編碼器Encoder(x)的輸出分布.
Llike為VAE的重構(gòu)損失函數(shù),根據(jù)具體的目的往往有不同形式.通過AE+GAN的設(shè)計(jì)模式,該類方法可以提供具有更豐富信息的隱變量以提高生成質(zhì)量.通過設(shè)計(jì)不同的自編碼機(jī)目標(biāo)函數(shù),研究者還提出了Denoise-GAN[53]、Plug&Play GAN[54]、α-GAN[55]等模型變體.該類模型可以獲得較高清晰度的生成圖像,并在3D模型的生成工作中得到較好應(yīng)用[56].
2.2 正則方法
對原始GAN的另一項(xiàng)重要改進(jìn)是使用新提出的一系列正則方法.批量規(guī)范化(Batch normalization,BN)[57]是深度學(xué)習(xí)中常用的一種正則方法.其基本思想是每次更新權(quán)值時(shí)對相應(yīng)的輸入做規(guī)范化操作,使得mini-batch輸出結(jié)果的均值為0,方差為1.具體而言,給定一批某中間層網(wǎng)絡(luò)的輸入U(xiǎn)={u1,···,um},在使用激活函數(shù)對其進(jìn)行非線性轉(zhuǎn)換前,首先做如下轉(zhuǎn)換:

其中,γ、β為待學(xué)習(xí)的參數(shù),?為一極小常數(shù).正則化后,網(wǎng)絡(luò)使用轉(zhuǎn)換過的hi進(jìn)行下一步操作.BN可以極大地提高神經(jīng)網(wǎng)絡(luò)有監(jiān)督學(xué)習(xí)的速度.DCGAN首先將這一技術(shù)引入GAN的訓(xùn)練中,并取得了很好的效果.
權(quán)值規(guī)范化(Weight normalization,WN)[58]是在有監(jiān)督學(xué)習(xí)中常用的另一種正則化技術(shù).與BN不同的是,WN主要針對神經(jīng)網(wǎng)絡(luò)的權(quán)值進(jìn)行歸一化,常用的方法是將網(wǎng)絡(luò)權(quán)值除以其范數(shù).在GAN中,常見的形式是

其中,W是網(wǎng)絡(luò)的權(quán)值,γ、β為待學(xué)習(xí)的參數(shù).實(shí)驗(yàn)表明,在GAN網(wǎng)絡(luò)中使用WN可以取得比BN更好的效果[59].
除了在有監(jiān)督學(xué)習(xí)中常用的BN、WN等方法,有研究者還針對GAN提出了譜規(guī)范化(Spectral normalization,SN)[43].該方法對判別器的各層施加操作

其中,σ(W)是權(quán)值的譜范數(shù),其值等于矩陣的最大奇異值.SN可以極大地提高GAN的生成效果,SN-GANs是少數(shù)幾種可以使用單一網(wǎng)絡(luò)生成ImageNet全部1000類物體的GAN結(jié)構(gòu).
除此以外,研究者還使用了Minibatch discrimination[41]的方法,通過對批量生成樣本(區(qū)別于原始GAN對單個(gè)生成樣本)施加多樣性約束以克服模式崩潰問題.
2.3 集成學(xué)習(xí)
集成學(xué)習(xí)(Ensemble learning)是通過構(gòu)建并結(jié)合多個(gè)學(xué)習(xí)器來完成學(xué)習(xí)任務(wù)的一種方法[60?61],一般分為兩類.一類是提升(Boosting)方法,通過調(diào)整樣本權(quán)重,級聯(lián)網(wǎng)絡(luò)等方法將弱學(xué)習(xí)器提升為強(qiáng)學(xué)習(xí)器,另一類則是使用多個(gè)同類學(xué)習(xí)器對數(shù)據(jù)的不同子集進(jìn)行學(xué)習(xí)后,再將學(xué)習(xí)結(jié)果通過某種方式整合(Bagging)起來.
基于Boosting思想的集成方法可以大致分為兩類.一類工作為同構(gòu)網(wǎng)絡(luò)合并.此類的典型工作是AdaGAN[62].該方法通過與AdaBoost類似的算法依次訓(xùn)練T個(gè)生成器模型.在第t步訓(xùn)練過程中,前一次未能成功生成的模式會被加大權(quán)重.每次訓(xùn)練后輸出的模型為為一給定的超參數(shù).訓(xùn)練結(jié)束后得到一系列生成模型G1,G2,···,GT及其相應(yīng)權(quán)重α1,α2,···,aT,最終的生成模型為
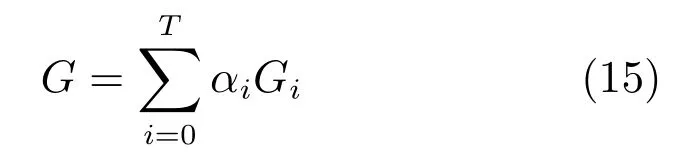
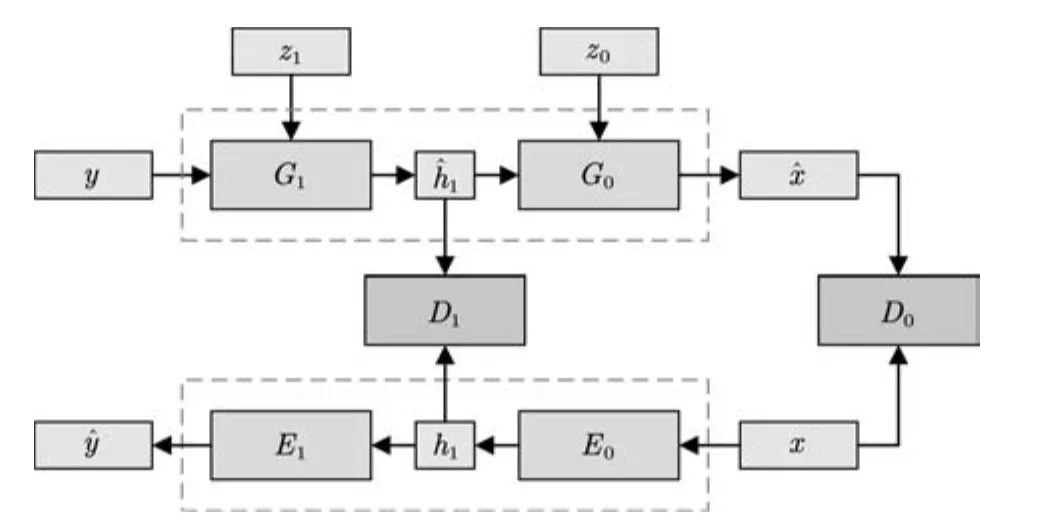
圖7 Stack GAN的拓?fù)浣Y(jié)構(gòu)Fig.7 Schematic of stack GAN architecture
另一類工作的主要方法為網(wǎng)絡(luò)疊加.該類方法的主要模式是串聯(lián)多個(gè)GAN,將上層生成器的輸出作為隱變量輸入下層生成器.Stack GAN[63]是其中較為典型的工作.如圖7所示,該模型的生成器由多個(gè)子模型串聯(lián)構(gòu)成,每級生成器Gi接受上一級生成器的輸出i+1及一個(gè)隨機(jī)變量zi作為輸入.在訓(xùn)練時(shí),該方法同步訓(xùn)練一個(gè)編碼器Ei,并使用其中間層的輸出hi和生成器的中間輸出一起訓(xùn)練.
該類工作的另一種常見方式則通過疊加不同分辨率的生成器網(wǎng)絡(luò)來實(shí)現(xiàn).以LAP-GAN[64]為例.
如圖8所示,該模型中上一層生成器的輸出Ii+1在放大后(記為li)與隨機(jī)變量zi一同輸入下一層網(wǎng)絡(luò),下一層的輸出i與li合并為i,i經(jīng)過放大后作為再下一層的輸入.

圖8 LAP-GAN的拓?fù)浣Y(jié)構(gòu)Fig.8 Schematic of LAP-GAN architecture
后繼的PG-GAN (Progressgrowingof GANs)[65]通過不斷加深網(wǎng)絡(luò)層數(shù)的方法改進(jìn)了這一模式.在訓(xùn)練過程中首先訓(xùn)練可輸出低分辨率圖像的淺層網(wǎng)絡(luò),再在淺層網(wǎng)絡(luò)上增加層數(shù).該方法可生成目前最高清晰度的圖像.
基于Bagging思想的集成方法主要針對模式坍塌(Mode collapse)這一GAN訓(xùn)練中最常見的不收斂情況,通過使用多個(gè)網(wǎng)絡(luò),每個(gè)網(wǎng)絡(luò)針對不同的模式進(jìn)行訓(xùn)練,之后再將這些網(wǎng)絡(luò)的輸出進(jìn)行整合.
這類模型中較為典型的是CoGAN[66]與MADGAN[67].兩者均通過集成多個(gè)共享部分權(quán)值的生成器以實(shí)現(xiàn)生成多樣性樣本的目的.兩者的區(qū)別主要在于,CoGAN使用了與生成器同樣數(shù)量的判別器,而MAD-GAN使用了多輸出的單判別器,通過判別目標(biāo)函數(shù)和基于相似性的競爭性目標(biāo)函數(shù)來引導(dǎo)生成器.
相較于基于Boosting的集成方法,基于Bagging的GAN集成方法并沒有在一般性的任務(wù)中取得顯著效果.但由于Bagging方法較為直接,在個(gè)性化任務(wù)中能以較小的代價(jià)獲得較大的提升.
2.4 優(yōu)化算法
GAN的優(yōu)化算法是另一個(gè)重要的改進(jìn)方向.GAN使用同步梯度下降(Simultaneous gradient ascent)的方法優(yōu)化網(wǎng)絡(luò),一般可以定義兩個(gè)效用函數(shù)f(φ,θ) 與g(φ,θ),其中 (φ,θ)∈?1×?2.玩家1的目標(biāo)是最大化效用函數(shù)f,玩家2的目標(biāo)則是最大化效用函數(shù)g.?i(i=1,2)為對應(yīng)玩家的可能行動空間,在GAN中,它們對應(yīng)著生成器與判別器的參數(shù)取值空間.GAN博弈的相關(guān)梯度向量場(Associated gradient vector field)為

對于零和博弈,有f(φ,θ)=?g(θ,φ).在一些情況下,如v(φ,θ)=φ·θ時(shí),使用同步梯度下降方法的參數(shù)軌跡為

該式對應(yīng)一個(gè)圓軌跡,具有無窮小學(xué)習(xí)速率的梯度下降將在恒定半徑處環(huán)繞軌道運(yùn)行,使用更大的學(xué)習(xí)率則軌跡有可能沿螺旋線發(fā)散.在這種情況下,同步梯度下降無法接近均衡點(diǎn)θ=φ=0.
解決這一問題可以使用共識優(yōu)化(Consensus optimization)[68]的方法.
定義有修正的效用函數(shù)

正則化因子L(φ,θ)鼓勵(lì)玩家間達(dá)成“共識”,這種方法較同步梯度下降方法具有更好的收斂性.
除了從優(yōu)化方法的角度,研究者還通過改變優(yōu)化的形式對GAN加以改進(jìn).最為常見的方法是使用強(qiáng)化學(xué)習(xí)中的策略梯度方法[69?70]以實(shí)現(xiàn)生成離散變量的目的.

圖9 GAN與Actor-critic模型Fig.9 GAN and actor-critic models
GAN與強(qiáng)化學(xué)習(xí)領(lǐng)域的Actor-critic模型[70]的關(guān)系引起了許多研究者的注意[71].強(qiáng)化學(xué)習(xí)(Reinforcement learning)[72]研究的問題是如何將狀態(tài)映射為行動,以最大化執(zhí)行者的長期回報(bào).Actorcritic模型是強(qiáng)化學(xué)習(xí)中常用的建模方法,在這一模型中,存在行動者(Actor)與批評家(Critic)兩個(gè)子模型,其中,行動者根據(jù)系統(tǒng)狀態(tài)做出決策,評價(jià)者對行動者做出的行為給出估計(jì).如圖9所示.
可以看出,GAN模型與Actor-critic具有結(jié)構(gòu)上的相似性,兩者均包含了一個(gè)由隨機(jī)變量到另一空間的映射,以及一個(gè)可學(xué)習(xí)的評價(jià)模型.兩者均通過迭代尋求均衡點(diǎn)的方式求解.Goodfellow甚至認(rèn)為GAN實(shí)質(zhì)是一種使用RL技巧解決生成模型問題的方法,兩者的區(qū)別主要在于GAN中回報(bào)是策略的已知函數(shù)且可對行動求導(dǎo)[73].
Actor-critic的優(yōu)化方法主要是基于REINFORCE算法[74]改進(jìn)的策略梯度方法.該方法的主要思想是:行動者為一參數(shù)化的函數(shù)π(s;θ),每次行動的動作為at=π(st|θ).若一個(gè)動作可以獲得較大的長期回報(bào)Q(st,at)則提高該行動的出現(xiàn)幾率,否則降低該行動的出現(xiàn)幾率.長期回報(bào)一般由批評家給出.每次行動后更新策略函數(shù)的參數(shù):

其中,?θ被稱為策略梯度.
在原始GAN中,生成器的學(xué)習(xí)依賴判別器回傳的梯度.由于離散取值的操作不可微,原始GAN無法解決離散數(shù)據(jù)的生成問題.通過借鑒Actor-critic模型的思想,研究者提出了一系列基于策略梯度優(yōu)化的GAN變體以解決這一問題.
SeqGAN[75]是這一系列工作中較早出現(xiàn)的模型之一.它的生成器結(jié)構(gòu)及更新方式與用于圖像生成的GAN類似.其模型結(jié)構(gòu)如圖10所示:

圖10 SeqGAN的拓?fù)浣Y(jié)構(gòu)Fig.10 Schematic of SeqGAN architecture
SeqGAN將序列生成問題視為序列決策問題進(jìn)行處理,使用RNN作為生成網(wǎng)絡(luò).以已生成的語素(Tokens)Y1:t?1作為當(dāng)前狀態(tài),生成器輸出的下一個(gè)詞匯yt為行為,生成器網(wǎng)絡(luò)為策略π,行為的回報(bào)rt為判別器D對生成Tokens的置信概率.為了提高對整句輸出的判別準(zhǔn)確度,SeqGAN在每次生成一個(gè)Token后,使用蒙特卡洛搜索(Monte Carlo search,MC search)的方法對句子進(jìn)行補(bǔ)齊,再將補(bǔ)齊后的句子輸入判別器D.SeqGAN的值函數(shù)見式(20),每次更新的策略梯度見式(21):

通過這一方式,SeqGAN克服了原始GAN無法生成離散數(shù)據(jù)序列的問題.
后續(xù)工作通過改進(jìn)網(wǎng)絡(luò)結(jié)構(gòu),結(jié)合更豐富的數(shù)據(jù)類型等方法進(jìn)一步強(qiáng)化了GAN的離散數(shù)據(jù)生成能力.如MaskGAN[76]使用Seq2Seq[7]作為生成網(wǎng)絡(luò),使得GAN具備了填詞能力.SPIRAL[77]使用藝術(shù)生成的序列數(shù)據(jù)作為樣本,可控制機(jī)械臂生成藝術(shù)圖像.
3 GAN判別機(jī)制的發(fā)展
如何合理選擇目標(biāo)函數(shù)是深度學(xué)習(xí)中至關(guān)重要的一個(gè)問題.一個(gè)好的目標(biāo)函數(shù)需要在刻畫任務(wù)本質(zhì)的同時(shí),提供良好的數(shù)值優(yōu)化特性.在GAN的訓(xùn)練過程中,目標(biāo)函數(shù)設(shè)計(jì)的主要目標(biāo)是有效地定義可區(qū)分性,并使得博弈過程可解[78?79].
原始GAN使用分類誤差作為真實(shí)分布與生成分布相近度的度量.當(dāng)判別器為最優(yōu)判別器時(shí),生成器的損失函數(shù)等價(jià)于真實(shí)分布與生成分布之間的JS散度.然而,已被證明,當(dāng)真實(shí)分布與生成分布的重疊區(qū)域可忽略時(shí),JS散度為一常數(shù),此時(shí)生成器的獲得梯度為0,無法進(jìn)一步學(xué)習(xí)[40].
有研究者認(rèn)為,這一問題的根源在于原始GAN假設(shè)了判別網(wǎng)絡(luò)具有無限建模能力,可以對于任意的樣本分布進(jìn)行判別.然而對于一般的分布而言,真實(shí)分布與生成分布不重疊的概率無限趨于1[80].為了克服這一問題,研究者提出對樣本分布進(jìn)行限制的方法,通過假設(shè)樣本服從某類特殊的函數(shù)族以避免梯度消失的問題.
3.1 Lipschitz密度
一類較有代表性的限制是假設(shè)樣本分布服從Lipschitz連續(xù),即其概率密度分布f(x)服從

使不等式成立的最小K值被稱為Lipschitz常數(shù).
這類方法的典型代表是Wasserstein GAN(WGAN)[81].WGAN使用Wasserstein-1距離(又稱Earth-Mover(EM)距離)作為真實(shí)分布與生成分布相近度的度量.定義如下:

其中,相當(dāng)于在真實(shí)與生成樣本的聯(lián)合分布γ的條件下,將真實(shí)分布變換為生成分布所需要“消耗”的步驟.W(Pr,Pg)是這一“消耗”的最小值.
由于取下界的操作無法直接求解,根據(jù)Kantorovich-Rubinstein對偶性[82],EM 距離被轉(zhuǎn)化為如下的形式:

其中,f(·)是一個(gè)滿足 Lipschitz連續(xù)條件的函數(shù).我們可以使用神經(jīng)網(wǎng)絡(luò)對f(·)進(jìn)行擬合,因此WGAN的目標(biāo)函數(shù)為:
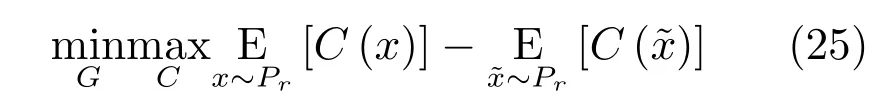
其中評價(jià)函數(shù)C需要滿足Lipschitz連續(xù)條件,一般采用權(quán)值裁剪或軟約束的方式保證.在WGAN中,判別器(稱為評價(jià)網(wǎng)絡(luò)C)的目的是逼近Pr與Pg的EM 距離,生成器的目的則是最小化兩者的EM距離.WGAN的網(wǎng)絡(luò)結(jié)構(gòu)如圖11所示.

圖11 WGAN的拓?fù)浣Y(jié)構(gòu)Fig.11 Schematic of WGAN architecture
WGAN的可收斂性遠(yuǎn)強(qiáng)于原始GAN,一經(jīng)提出就引起了極大的關(guān)注.后繼的改進(jìn)版本W(wǎng)GANGP通過添加梯度懲罰的方式[83],進(jìn)一步提高了網(wǎng)絡(luò)的穩(wěn)定性,在多種網(wǎng)絡(luò)結(jié)構(gòu)上都可實(shí)現(xiàn)收斂,是目前性能最佳,使用最廣泛的GAN變種之一.
3.2 能量函數(shù)
除了使用Lipschitz連續(xù)假設(shè)對樣本分布進(jìn)行約束,還可以使用非概率形式作為度量的GAN結(jié)構(gòu),較為典型的是基于能量的GAN(Energy-based GAN,EBGAN)[84].EBGAN將判別器D視為一個(gè)能量函數(shù),該函數(shù)得賦予真實(shí)樣本較低的能量,而賦予生成樣本較高的能量.其網(wǎng)絡(luò)結(jié)構(gòu)如圖12所示.

圖12 EBGAN的拓?fù)浣Y(jié)Fig.12 Schematic of EBGAN architecture
在論文中,EBGAN使用了一個(gè)自動編碼機(jī)作為判別網(wǎng)絡(luò),并將自動編碼機(jī)的重構(gòu)誤差作為樣本的能量,即:

相應(yīng)的損失函數(shù)為

其中 [·]+=max(0,·),m是一個(gè)預(yù)定義的邊界(Margin),主要作用在于避免判別器過強(qiáng)導(dǎo)致生成器無法獲得有用的信息,該參數(shù)也可以通過自適應(yīng)的方式學(xué)習(xí)[85].
為了使得生成的樣本具有更好的多樣性,EBGAN還提出了一種約束方法,稱為Pullingaway term(PT),其形式為
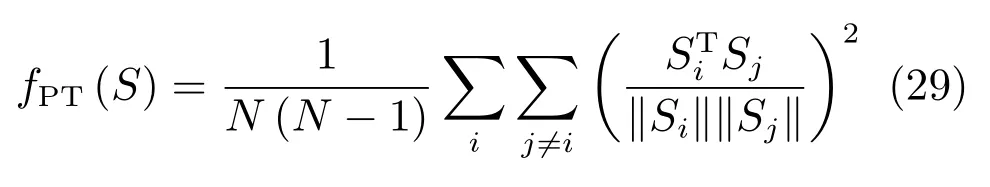
其中,S為判別器中編碼層的輸出.通過增大PT值,EBGAN可以有效地提升生成樣本的多樣性.EBGAN為理解GAN提供了一種全新的視角.
4 GAN的應(yīng)用
GAN在生成逼真圖像上的性能遠(yuǎn)超以往,一經(jīng)提出便引起了極大的關(guān)注.隨著研究的深入,研究者逐漸認(rèn)識到其作為一種表征學(xué)習(xí)方式的潛力,并進(jìn)一步地發(fā)展了其對抗的思想,將GAN的結(jié)構(gòu)設(shè)計(jì)用于模仿學(xué)習(xí)與圖像翻譯等新興領(lǐng)域.
一般而言,GAN的應(yīng)用遵循這樣的設(shè)計(jì)模式:首先定義一個(gè)模型用于將某一空間中的數(shù)據(jù)映射至另一空間,再定義一個(gè)模型用于評估這一映射的質(zhì)量.通過迭代訓(xùn)練兩模型得到理想的映射模型或評價(jià)模型.本文將GAN的應(yīng)用依據(jù)其映射的性質(zhì)分為三類:數(shù)據(jù)生成與增強(qiáng),廣義翻譯模型,以及廣義生成模型.
4.1 數(shù)據(jù)生成與增強(qiáng)
作為生成模型,GAN最為直接的作用是對訓(xùn)練數(shù)據(jù)進(jìn)行增強(qiáng).根據(jù)增強(qiáng)后的數(shù)據(jù)性質(zhì),這一類應(yīng)用可以分為數(shù)據(jù)集內(nèi)增強(qiáng)與數(shù)據(jù)集外增強(qiáng)兩類.前者是對訓(xùn)練集內(nèi)數(shù)據(jù)進(jìn)行填補(bǔ),清晰化,變換等操作,主要目的是增強(qiáng)數(shù)據(jù)集質(zhì)量.后者則主要是結(jié)合外部知識或無標(biāo)簽數(shù)據(jù)對數(shù)據(jù)集進(jìn)行調(diào)整和猜測,使其具備原數(shù)據(jù)集不具備的信息.
在有監(jiān)督的深度學(xué)習(xí)訓(xùn)練中,研究者常常要對原始數(shù)據(jù)進(jìn)行平移、縮放、旋轉(zhuǎn)等操作.這些數(shù)據(jù)增強(qiáng)操作一方面擴(kuò)大了數(shù)據(jù)集的樣本量,另一方面也有助于神經(jīng)網(wǎng)絡(luò)學(xué)到輪廓,紋理等特征,以收斂到更好的(局部)最優(yōu)解[2].
數(shù)據(jù)集內(nèi)提升是對這一工作的擴(kuò)展.典型的應(yīng)用包括缺失數(shù)據(jù)填補(bǔ)[86?87]、超分辨率圖像生成[88]、視頻預(yù)測[89?90]、圖像清晰化[91]等.該類工作的主要模式是將有缺陷的數(shù)據(jù)或歷史數(shù)據(jù)輸入生成器,通過使用GAN的訓(xùn)練方式替代均方根誤差(Mean square error,MSE)等人工設(shè)計(jì)的損失函數(shù),從而實(shí)現(xiàn)更好的修復(fù)或預(yù)測效果.
以缺失數(shù)據(jù)填補(bǔ)為例.給定一個(gè)信息有缺失的數(shù)據(jù),如部分像素丟失的圖像,我們希望根據(jù)同類別的其他圖像訓(xùn)練一個(gè)模型,該模型可將丟失的信息補(bǔ)全.如圖13所示,相比傳統(tǒng)方法(Image melding)[92],基于GAN的數(shù)據(jù)填補(bǔ)可以更好地考慮圖像的語義信息,并填充符合當(dāng)前場景的內(nèi)容.
許多計(jì)算機(jī)視覺任務(wù)都可以通過GAN增強(qiáng)圖像以提高性能.除了圖像分類,目標(biāo)檢測等常用任務(wù),GAN也被用于對抗樣本[93?94]的生成[95]與抵抗任務(wù),如APE-GAN[96]通過將對抗樣本轉(zhuǎn)化為可被目標(biāo)模型正確識別的樣本,Generative adversarial trainer[97]使用GAN生成對抗性擾動(Adversarial perturbation)后將經(jīng)過污染的樣本與標(biāo)記樣本一起學(xué)習(xí),等等.
GAN在數(shù)據(jù)集外擴(kuò)展方面的工作,主要集中在使用仿真數(shù)據(jù)擴(kuò)大真實(shí)數(shù)據(jù)相關(guān)的工作.在許多問題中,真實(shí)數(shù)據(jù)的收集十分困難或緩慢,但在仿真數(shù)據(jù)上訓(xùn)練的模型又無法很好地泛化以用于現(xiàn)實(shí)任務(wù)[98].研究者提出了PixelDA[99]、SimGAN[100]、GraspGAN[101]等模型以解決該問題.該類模型的基本想法是通過使用GAN中的生成器作為精煉器(Re finer),對仿真數(shù)據(jù)進(jìn)行修飾后,使其與真實(shí)數(shù)據(jù)相接近.該類方法使得以往需要大量樣本的任務(wù),如人眼識別、自動駕駛、機(jī)械臂控制等,現(xiàn)在通過少量真實(shí)樣本與仿真環(huán)境即可完成訓(xùn)練[102?104].
GAN還可以用于提升開放集分類(Opencategory classi fication,OCC,即將與訓(xùn)練集內(nèi)數(shù)據(jù)類型不一致的樣本區(qū)分為單獨(dú)一類)問題的性能[105].通過生成接近集內(nèi)數(shù)據(jù)但被判別器認(rèn)為是集外數(shù)據(jù)的樣本,GAN可以較大地提升分類器在開放集分類問題上的性能.

圖13 GAN[86]與傳統(tǒng)方法[92]的數(shù)據(jù)填補(bǔ)效果Fig.13 Image completion by GAN[86]and traditional method[92]
數(shù)據(jù)生成與增強(qiáng)的工作往往與半監(jiān)督學(xué)習(xí)相聯(lián)系,其目的在于提高后續(xù)的監(jiān)督學(xué)習(xí)或強(qiáng)化學(xué)習(xí)性能.一部分半監(jiān)督學(xué)習(xí)方面工作還使用了GAN本身的結(jié)構(gòu)特性.如后文IRGAN對判別式信息檢索(Information retrieval,IR)模型的提升,使用CGAN模型中的判別器作為圖像分類器[106],Professor forcing[107]方法中使用GAN提高RNN的訓(xùn)練質(zhì)量,等等.由于這部分研究尚不豐富,限于篇幅本文不做詳細(xì)介紹.
4.2 廣義數(shù)據(jù)翻譯
不同領(lǐng)域的數(shù)據(jù)往往具有各自不同的特征和作用.如自然語言數(shù)據(jù)具有易獲取,具有較為明確的意義,但缺乏細(xì)節(jié)信息的特點(diǎn).圖像數(shù)據(jù)具有細(xì)節(jié)豐富,但難以分析語義的特點(diǎn).同類數(shù)據(jù)間如何翻譯,不同類型的數(shù)據(jù)間如何轉(zhuǎn)化,不僅具有相當(dāng)?shù)膶?shí)用價(jià)值,而且對于提高神經(jīng)網(wǎng)絡(luò)的可解釋性具有重要的意義.GAN已被用于一些常見的數(shù)據(jù)翻譯工作中,如從語義圖生成圖像[108]、圖文翻譯[109]等.本節(jié)主要介紹一些GAN所特有或表現(xiàn)顯著優(yōu)于傳統(tǒng)方法的應(yīng)用.
根據(jù)用戶修改自動對照片進(jìn)行編輯和生成是一個(gè)極具挑戰(zhàn)的任務(wù).研究人員提出了iGAN模型,通過類似InfoGAN等模型調(diào)整隱變量改變輸出樣本的方法,將用戶輸入作為隱變量,實(shí)現(xiàn)了圖像的自動修改與生成[110?111].效果如圖14所示.受該工作啟發(fā),研究者提出了“圖對圖翻譯”的新問題[112].
如圖15所示,許多常見的圖像處理任務(wù)都可以看作是將一張圖片“翻譯”為另一張圖片,如將衛(wèi)星圖像轉(zhuǎn)換為對應(yīng)的路網(wǎng)圖,將手繪稿轉(zhuǎn)換為照片,將黑白圖像轉(zhuǎn)換為彩色圖片等.Isola等提出了一種名為Pix2Pix[112]的方法,利用GAN實(shí)現(xiàn)了這種翻譯,模型結(jié)構(gòu)如圖16所示.

圖14 iGAN的生成樣例[110]Fig.14 Images generated by iGAN[110]
圖16中F與G均為翻譯器.Pix2Pix需要成對的數(shù)據(jù)集(x,y),例如在衛(wèi)星圖像轉(zhuǎn)換的任務(wù)中,x是衛(wèi)星圖像,y是對應(yīng)的路網(wǎng)圖像.在x向y轉(zhuǎn)換的過程中,翻譯器接受x的樣本,生成對應(yīng)的樣本,判別器Dx:y判別x與是否配對,并將梯度回傳給翻譯器.y向x的轉(zhuǎn)換也照此進(jìn)行.
Pix2Pix取得了非常驚艷的效果,后續(xù)的Pix2PixHD[113]等工作進(jìn)一步提高了其生成樣本的分辨率和清晰度.不過,該模型的訓(xùn)練必須有標(biāo)注好的成對數(shù)據(jù),這限制了它的應(yīng)用場景.為了解決這一問題,結(jié)合對偶學(xué)習(xí)[114],研究者提出了Cycle-GAN[115],使得無須建立訓(xùn)練數(shù)據(jù)間一對一的映射,也可以在源域和目標(biāo)域之間實(shí)現(xiàn)轉(zhuǎn)換.CycleGAN的結(jié)構(gòu)如圖17所示.

圖15 圖對圖翻譯舉例[112]Fig.15 Examples of image to image translation[112]

圖16 Pix2Pix的拓?fù)浣Y(jié)構(gòu)Fig.16 Chematic of Pix2Pix architectur
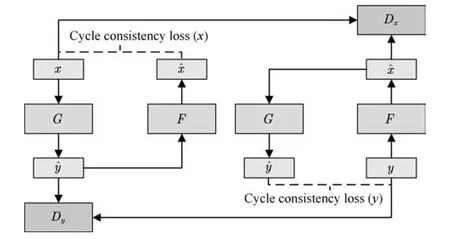
圖17 CycleGAN的拓?fù)浣Y(jié)構(gòu)Fig.17 Schematic of CycleGAN architecture
為了使用非配對數(shù)據(jù)進(jìn)行訓(xùn)練,CycleGAN會首先將源域樣本映射到目標(biāo)域,然后再映射回源域得到二次生成圖像,從而消除了在目標(biāo)域中圖像配對的要求.為了保證經(jīng)過“翻譯”的圖像是我們所期望的內(nèi)容,CycleGAN還引入了循環(huán)一致性的約束條件.
以x向y的轉(zhuǎn)換為例,翻譯器G接受x的樣本,生成對應(yīng)的樣本,翻譯器F再將翻譯為.判別器Dy接受樣本y與,并試圖判別其中的生成樣本.應(yīng)與x相似,以保證中間映射有意義.為此,文中將循環(huán)一致性約束定義為

在訓(xùn)練GAN的同時(shí)保證循環(huán)一致性約束最小化,CycleGAN就可以通過非配對數(shù)據(jù)實(shí)現(xiàn)較好的映射效果.該方法生成的圖像與Pix2Pix十分接近.除了用于數(shù)據(jù)增強(qiáng)任務(wù)外,該模型也被廣泛用于神經(jīng)風(fēng)格轉(zhuǎn)換(Neural style transfer)[116]等藝術(shù)性工作中.
4.3 廣義生成模型
以上討論的工作主要關(guān)于圖像,自然語言等具體數(shù)據(jù).實(shí)際上,我們可以考慮更為廣義的數(shù)據(jù),如狀態(tài)、行動、圖網(wǎng)絡(luò)等.
該類研究的典型工作之一為生成式模仿學(xué)習(xí)(Generative adversarial imitation learning,GAIL)[117].模仿學(xué)習(xí)(Imitation learning)是強(qiáng)化學(xué)習(xí)中的一個(gè)重要課題,其目的是解決如何從示教數(shù)據(jù)中學(xué)習(xí)專家策略的問題.由于狀態(tài)對行動的映射具有不確定性,直接使用示教數(shù)據(jù)進(jìn)行監(jiān)督訓(xùn)練得到的策略模型往往不能很好地泛化.研究者一般使用反向強(qiáng)化學(xué)習(xí)(Inverse reinforcement learning,IRL)[118]來解決這一問題.通過學(xué)習(xí)一個(gè)代理回報(bào)函數(shù)(Surrogate reward function)(s),并期望該函數(shù)能最好地解釋觀察到的行為,再由此從數(shù)據(jù)中習(xí)得類似的策略.IRL成功解決了一系列的問題,如預(yù)測出租車司機(jī)行為[119],規(guī)劃四足機(jī)器人的足跡[120]等.
然而,IRL算法的運(yùn)算代價(jià)高昂,且方法過于間接.對于模仿學(xué)習(xí)而言,真正的目的是使得Agent可以習(xí)得專家的策略,內(nèi)在的代價(jià)函數(shù)并非必要.研究者從GAN的思想中得到啟發(fā),提出了生成式模仿學(xué)習(xí)(Generative adversarial imitation learning,GAIL)[117]的方法.GAIL的一般結(jié)構(gòu)如圖18所示.
與GAN類似,GAIL的目的是訓(xùn)練一個(gè)策略網(wǎng)絡(luò)πθ,其輸出的狀態(tài)–行為對Xθ={(s1,a1),···,(sT,aT)}可以欺騙判別器Dφ,使其無法區(qū)分Xθ與由專家策略πE輸出的XE.GAIL的目標(biāo)函數(shù)為

策略的代理回報(bào)函數(shù)為

使用策略梯度方法更新行動者π(生成器),最終使得行動者的決策與專家的決策一致.該方法被用于模仿駕駛員[121],機(jī)械臂控制[122]等任務(wù)中,取得了較好的效果.
與GAIL相類似,IRGAN[123]使用對抗方式提高信息檢索(Information retrieval,IR)模型質(zhì)量.一般而言,IR模型可分為兩類.一類為生成式模型,其目標(biāo)是學(xué)習(xí)一個(gè)查詢(Query)到文檔(Document)的關(guān)聯(lián)度分布,利用該分布對每個(gè)查詢返回相關(guān)的檢索結(jié)果.另一類為判別式模型,該模型可以區(qū)分有關(guān)聯(lián)的查詢對hqueryr,docri與無關(guān)聯(lián)的查詢對hqueryf,docfi.對于給定的查詢對,該模型可返回該查詢對內(nèi)元素的關(guān)聯(lián)程度[124].由于這兩類模型的對抗性質(zhì),IRGAN將兩個(gè)或多個(gè)生成式IR模型與判別式IR模型整合為一個(gè)GAN模型,再通過策略梯度優(yōu)化的方式提升兩類模型的檢索質(zhì)量.

圖18 生成式模仿學(xué)習(xí)Fig.18 Generative adversarial imitation learnin
此外,GAN還被用于專業(yè)領(lǐng)域數(shù)據(jù)的生成任務(wù).如用于生成惡意軟件的MalGAN[125]模型,用于生成DNA序列的FBGAN[126],用于學(xué)習(xí)圖嵌入表示(Graph embedding)[127]的GraphGAN等.限于篇幅,本文不再詳細(xì)介紹.
5 總結(jié)與展望
自2014年提出以來,生成式對抗網(wǎng)絡(luò)獲得了極大的關(guān)注與發(fā)展.GAN的相關(guān)工作越來越多地出現(xiàn)在機(jī)器學(xué)習(xí)的各類會議和期刊上,LeCun甚至將其稱為“過去十年間機(jī)器學(xué)習(xí)領(lǐng)域中最讓人激動的點(diǎn)子”.
本文綜述了GAN在理論與應(yīng)用方面的成果,總體來看可分為兩個(gè)大的方向.
第一個(gè)研究方向集中在生成機(jī)制方面,主要的問題是如何設(shè)計(jì)一個(gè)有效的結(jié)構(gòu),以學(xué)習(xí)一個(gè)從隱變量到目標(biāo)空間的映射.在理論上主要包括了如何設(shè)計(jì)更好的網(wǎng)絡(luò)結(jié)構(gòu)和相應(yīng)的優(yōu)化方法以提高生成數(shù)據(jù)質(zhì)量,如何集成多模型以提高生成效率.在應(yīng)用上主要是考慮半監(jiān)督學(xué)習(xí)問題以及復(fù)雜數(shù)據(jù)間的映射問題.
第二個(gè)研究方向集中在判別機(jī)制方面,主要的問題是如何更好地將生成問題轉(zhuǎn)化為一個(gè)較易學(xué)習(xí)的判別問題.在理論上主要包括了如何設(shè)計(jì)博弈形式以提高學(xué)習(xí)效率,在應(yīng)用上主要是如何利用GAN中的判別模型輔助下游任務(wù),以及如何設(shè)計(jì)整體結(jié)構(gòu),將其他問題轉(zhuǎn)化為一個(gè)可判別的生成問題.
GAN在數(shù)據(jù)生成,半監(jiān)督學(xué)習(xí),強(qiáng)化學(xué)習(xí)等多方面任務(wù)中起到了重要作用.但也應(yīng)看到,該領(lǐng)域的發(fā)展仍處于早期階段,許多問題仍在制約GAN的發(fā)展.最為突出的是GAN的評價(jià)與復(fù)現(xiàn)問題,目前尚未有關(guān)于如何科學(xué)評價(jià)GAN的共識.其次,GAN的博弈與收斂機(jī)制背后的數(shù)學(xué)分析仍有待建立,現(xiàn)有的研究主要是利用深度學(xué)習(xí)在有監(jiān)督任務(wù)中積累的經(jīng)驗(yàn)進(jìn)行擴(kuò)展.最后,大部分GAN的工作仍然缺乏實(shí)用價(jià)值,僅可在特定的數(shù)據(jù)集上使用.如何建立類似ImageNet等標(biāo)準(zhǔn)化任務(wù)以評價(jià)GAN方法;如何建立和分析GAN的數(shù)學(xué)機(jī)制,并在此基礎(chǔ)上進(jìn)一步實(shí)現(xiàn)GAN特有的,與有監(jiān)督學(xué)習(xí)任務(wù)不同的深度學(xué)習(xí)構(gòu)件;如何拓展GAN的應(yīng)用范圍;這些問題仍有待研究者進(jìn)一步探索.
從更高的角度看,GAN的成功實(shí)質(zhì)反映了人工智能的研究進(jìn)入深水區(qū),研究的重點(diǎn)從視覺、聽覺等感知問題向解決決策、生成等認(rèn)知問題轉(zhuǎn)移.與機(jī)器感知問題相比,這些新的問題往往人類也無法很好解決,對這類問題的解決必須依賴新的研究方法.
這兩類問題的區(qū)別可以使用強(qiáng)化學(xué)習(xí)中的“探索與利用兩難(Explore and exploit dilemma)”問題進(jìn)行類比,如圖19所示.對于感知問題,我們有一個(gè)足夠明確的目標(biāo)以及目標(biāo)臨近域的數(shù)據(jù),所需要的是足夠高效的利用方法.然而,對于認(rèn)知問題,我們只能通過比較局部目標(biāo)的方法來定義問題,且數(shù)據(jù)往往過于稀疏或處于局部最優(yōu)點(diǎn)附近.如在圍棋AI的研究中發(fā)現(xiàn),使用人類數(shù)據(jù)訓(xùn)練的智能體會收斂到局部最優(yōu)值,反而無法勝過不學(xué)習(xí)人類經(jīng)驗(yàn)的智能體[128].此時(shí),需要尋找一種方法充分探索可能性空間,以更好地確定實(shí)際需要學(xué)習(xí)的目標(biāo).

圖19 探索與利用Fig.19 Explore and exploit
實(shí)現(xiàn)這種探索的一個(gè)方式是將真實(shí)世界的互動機(jī)制引入模型.GAN可以看作是這樣的一個(gè)系統(tǒng),通過在生成模型上添加判別模型,GAN模仿了現(xiàn)實(shí)世界中人類判斷圖片的機(jī)制,進(jìn)而將難以定義的樣本差異轉(zhuǎn)化為一個(gè)博弈問題.與之類似的是AlphaZero,通過自我對弈的形式積累大量數(shù)據(jù),再從中探索出一個(gè)更優(yōu)的策略.在這一新的研究范式中,模型從分析的工具變?yōu)榱藬?shù)據(jù)的“工廠”[129].
這類方法的思路與國內(nèi)學(xué)者提出的平行思想有很多相似之處.平行思想是指,通過將真實(shí)系統(tǒng)與人工系統(tǒng)融合,在兩個(gè)平行的系統(tǒng)中迭代實(shí)現(xiàn)對另一系統(tǒng)的描述、預(yù)測與引導(dǎo)[129].有研究者結(jié)合平行思想與機(jī)器學(xué)習(xí)提出了平行學(xué)習(xí)的概念[130].通過在平行系統(tǒng)中綜合描述學(xué)習(xí)、預(yù)測學(xué)習(xí)與引導(dǎo)學(xué)習(xí),可以更好地提高機(jī)器學(xué)習(xí)方法的樣本效率,擴(kuò)大學(xué)習(xí)的探索空間,實(shí)現(xiàn)一條從小數(shù)據(jù)產(chǎn)生大數(shù)據(jù),再由大數(shù)據(jù)煉成“小定律”的精準(zhǔn)知識之路,從而更好地分析和解決決策、生成等難以明確定義優(yōu)化目標(biāo)的問題.目前,平行學(xué)習(xí)己在自動駕駛中得到了成功的應(yīng)用[131?132].
GAN可被視為一個(gè)最簡單且無引導(dǎo)學(xué)習(xí)功能的平行學(xué)習(xí)系統(tǒng),它用判別器逼近真實(shí)系統(tǒng),利用生成器逼近人工系統(tǒng),為虛實(shí)一體的智能“平行機(jī)”構(gòu)造提供了一個(gè)例子[133].GAN為平行學(xué)習(xí)中的博弈提供了一個(gè)初步示例,更為人工智能的下一步發(fā)展提供了一種全新的思路.
1 Murphy K P.Machine Learning:A Probabilistic Perspective.Cambridge:MIT Press,2012.
2 Krizhevsky A,Sutskever I,Hinton G E.ImageNet classification with deep convolutional neural networks.In:Proceedings of the 25th International Conference on Neural Information Processing Systems.Lake Tahoe,Nevada,USA:ACM,2012.1097?1105
3 Farabet C,Couprie C,Najman L,LeCun Y.Learning hierarchical features for scene labeling.IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(8):1915?1929
4 Mikolov T,Deoras A,Povey D,Burget L,Cernocky J.Strategies for training large scale neural network language models.In:Proceedings of the 2011 IEEE Workshop on Automatic Speech Recognition and Understanding.Waikoloa,HI,USA:IEEE,2011.196?201
5 Hinton G,Deng L,Yu D,Dahl G E,Mohamed A R,Jaitly N,et al.Deep neural networks for acoustic modeling in speech recognition:The shared views of four research groups.IEEE Signal Processing Magazine,2012,29(6):82?97
6 Collobert R,Weston J,Bottou L,Karlen M,Kavukcuoglu K,Kuksa P.Natural language processing(almost)from scratch.Journal of Machine Learning Research,2011,12:2493?2537
7 Sutskever I,Vinyals O,Le Q V.Sequence to sequence learning with neural networks.In:Proceedings of the 27th International Conference on Neural Information Processing Systems.Montreal,Canada:MIT Press,2014.3104?3112
8 Hinton G E,Osindero S,Teh Y W.A fast learning algorithm for deep belief nets.Neural Computation,2006,18(7):1527?1554
9 Salakhutdinov R,Hinton G.Deep Boltzmann machines.In:Proceedings of the 12th International Conference on Arti ficial Intelligence and Statistics.Clearwater Beach,Florida,USA:AISTATS,2009.448?455
10 Smolensky P.Information processing in dynamical systems:Foundations of harmony theory.Parallel Distributed Processing:Explorations in the Microstructure of Cognition.Cambridge,MA,USA:MIT Press,1986.
11 Hinton G E,Zemel R S.Autoencoders,minimum description length and Helmholtz free energy.In:Proceedings of the 6th International Conference on Neural Information Processing Systems.Denver,Colorado,USA:Morgan Kaufmann Publishers Inc.,1994.3?10
12 Bengio Y,Lamblin P,Popovici D,Larochelle H.Greedy layer-wise training of deep networks.In:Proceedings of the 21st Annual Conference on Neural Information Processing Systems.Vancouver,BC,Canada:MIT Press,2007.153?160
13 Goodfellow I J,Pouget-Abadie J,Mirza M,Xu B,Warde-Farley D,Ozair S,et al.Generative adversarial nets.In:Proceedings of the 27th International Conference on Neural Information Processing Systems.Montreal,Canada:MIT Press,2014.2672?2680
14 Goodfellow I.NIPS 2016 tutorial:Generative adversarial networks.arXiv preprint arXiv:1701.00160,2016
15 Wang Kun-Feng,Gou Chao,Duan Yan-Jie,Lin Yi-Lun,Zheng Xin-Hu,Wang Fei-Yue.Generative adversarial networks:The state of the art and beyond.Acta Automatica Sinica,2017,43(3):321?332(王坤峰,茍超,段艷杰,林懿倫,鄭心湖,王飛躍.生成式對抗網(wǎng)絡(luò)GAN的研究進(jìn)展與展望.自動化學(xué)報(bào),2017,43(3):321?332)
16 LeCun Y,Bengio Y,Hinton G.Deep learning.Nature,2015,521(7553):436?444
17 Rumelhart D E,Hinton G E,Williams R J.Learning representations by back-propagating errors.Nature,1986,323(6088):533?536
18 Le Cun Y,Boser B,Denker J S,Howard R E,Habbard W,Jackel L D,et al.Handwritten digit recognition with a back-propagation network.In:Proceedings of the 1990 Advances in Neural Information Processing Systems.San Francisco,CA,USA:Morgan Kaufmann Publishers Inc.,1990.396?404
19 Lecun Y,Bottou L,Bengio Y,Haffner P.Gradient-based learning applied to document recognition.Proceedings of the IEEE,1998,86(11):2278?2324
20 HochreiterS.Untersuchungen zu dynamischen neuronalen Netzen[Ph.D.dissertation],Technische Universitt München,München,Germany,1991
21 Bengio Y,Simard P,Frasconi P.Learning long-term dependencies with gradient descent is difficult.IEEE Transactions on Neural Networks,1994,5(2):157?166
22 Hochreiter S,Schmidhuber J.Long short-term memory.Neural Computation,1997,9(8):1735?1780
23 Nair V,Hinton G E.Recti fied linear units improve restricted Boltzmann machines.In:Proceedings of the 27th International Conference on Machine Learning.Haifa,Israel:Omni Press,2010.807?814
24 Srivastava N,Hinton G E,Krizhevsky A,Sutskever I,Salakhutdinov R.Dropout:A simple way to prevent neural networks from over fitting.Journal of Machine Learning Research,2014,15(1):1929?1958
25 Kingma D P,Ba J.Adam:A method for stochastic optimization.arXiv preprint arXiv:1412.6980,2014
26 Chellapilla K,Puri S,Simard P.High performance convolutional neural networks for document processing.In:Proceedings of the 10th International Workshop on Frontiers in Handwriting Recognition.La Baule,France:Suvisoft,2006.
27 Lacey G,Taylor G W,Areibi S.Deep learning on FPGAs:Past,present,and future.arXiv preprint arXiv:1602.04283,2016
28 Jouppi N P,Young C,Patil N,Patterson D,Agrawal G,Bajwa R,et al.In-datacenter performance analysis of a tensor processing unit.In:Proceedings of the 44th Annual International Symposium on Computer Architecture.Toronto,ON,Canada:ACM,2017.1?12
29 Dean J,Corrado G S,Monga R,Chen K,Devin M,Le Q V,et al.Large scale distributed deep networks.In:Proceedings of the 25th International Conference on Neural Information Processing Systems.Lake Tahoe,Nevada,USA:Curran Associates Inc.,2012.1223?1231
30 Bergstra J,Bastien F,Breuleux O,Lamblin P,Pascanu R,Delalleau O,et al.Theano:Deep learning on GPUs with python.Journal of Machine Learning Research,2011,1:1?48
31 CollobertR,Kavukcuoglu K,FarabetC.Torch7:A Matlab-like environment for machine learning.In:BigLearn,NIPS Workshop.Martigny,Switzerland:Idiap Research Institute,2011
32 Paszke A,Gross S,Chintala S,Chanan G.PyTorch:Tensors and dynamic neural networks in Python with strong GPU acceleration[Online],available:http://pytorch.org/,April 31,2018
33 Abadi M,Agarwal A,Barham P,Brevdo E,Chen Z F,Citro C,et al.TensorFlow:Large-scale machine learning on heterogeneous distributed systems.arXiv preprint arXiv:1603.04467,2016
34 Li F F,Deng J.ImageNet:Where are we going?and where have we been?.In:Presented at the 2017 Conference on Computer Vision and Pattern Recognition[Online],available:https://www.youtube.com/watch?v=jYvBmJo7qjc,April 31,2018
35 Hastie T,Tibshirani R,Friedman J.Unsupervised learning.The Elements of Statistical Learning:Data Mining,Inference,and Prediction.New York,NY,USA:Springer,2009.485?585
36 Bengio Y.Learning deep architectures for AI.Foundations and Trends in Machine Learning,2009,2(1):1?127
37 Werbos P J.Learning how the world works:Speci fications for predictive networks in robots and brains.In:Proceedings of IEEE International Conference on Systems,Man and Cybernetics.New York,NY,USA:IEEE,1987.
38 Opper M,Archambeau C.The variational Gaussian approximation revisited.Neural Computation,2009,21(3):786?792
39 Kingma D P,Welling M.Auto-encoding variational Bayes.arXiv preprint arXiv:1312.6114,2013
40 Arjovsky M,Bottou L.Towards principled methods for training generative adversarial networks.arXiv preprint arXiv:1701.04862,2017
41 Salimans T,Goodfellow I,Zaremba W,Cheung V,Radford A,Chen X.Improved techniques for training GANs.arXiv preprint arXiv:1606.03498,2016
42 Heusel M,Ramsauer H,Unterthiner T,Nessler B,Hochreiter S.GANs trained by a two time-scale update rule converge to a local Nash equilibrium.arXiv preprint arXiv:1706.08500,2017
43 Miyato T,Kataoka T,Koyama M,Yoshida Y.Spectral normalization for generative adversarial networks.arXiv preprint arXiv:1802.05957,2018
44 Papineni K,Roukos S,Ward T,Zhu W J.BLEU:A method for automatic evaluation of machine translation.In:Proceedings of the 40th Annual Meeting on Association for Computational Linguistics.Philadelphia,PA,USA:ACL,2002.311?318
45 Lucic M,Kurach K,Michalski M,Gelly S,Bousquet O.Are GANs created equal?A large-scale study.arXiv preprint arXiv:1711.10337,2017
46 Theis L,van den Oord A,Bethge M.A note on the evaluation of generative models.arXiv preprint arXiv:1511.01844,2015
47 Radford A,Metz L,Chintala S.Unsupervised representation learning with deep convolutional generative adversarial networks.arXiv preprint arXiv:1511.06434,2015
48 Zeiler M D,Taylor G W,Fergus R.Adaptive deconvolutional networks for mid and high level feature learning.In:Proceedings of the 2011 IEEE International Conference on Computer Vision.Barcelona,Spain:IEEE,2011.2018?2025
49 Mirza M,Osindero S.Conditional generative adversarial nets.arXiv preprint arXiv:1411.1784,2014
50 Odena A,Olah C,Shlens J.Conditional image synthesis with auxiliary classi fier GANs.arXiv preprint arXiv:1610.09585,2016
51 Chen X,Duan Y,Houthooft R,Schulman J,Sutskever I,Abbeel P.Infogan:Interpretable representation learning by information maximizing generative adversarial nets.In:Proceedings of the 30th Conference on Neural Information Processing Systems.Barcelona,Spain:NIPS,2016.2172?2180
52 Larsen A B L,Sonderby S K,Larochelle H,Winther O.Autoencoding beyond pixels using a learned similarity metric.arXiv preprint arXiv:1512.09300,2015
53 Warde-Farley D,Bengio Y.Improving generative adversarial networks with denoising feature matching.In:International Conference on Learning Representations.2017
54 Nguyen A,Clune J,Bengio Y,Dosovitskiy A,Yosinski J.Plug&play generative networks:Conditional iterative generation of images in latent space.In:Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition.Honolulu,Hawaii,USA:IEEE,2017.3510?3520
55 Rosca M,Lakshminarayanan B,Warde-Farley D,Mohamed S.VariationalApproachesforauto-encoding generative adversarial networks.arXiv preprint arXiv:1706.04987,2017
56 Wu J J,Zhang C K,Xue T F,Freeman B,Tenenbaum J.Learning a probabilistic latent space of object shapes via 3D generative-adversarial modeling.In:Proceedings of the 30th Conference on Neural Information Processing Systems.Barcelona,Spain:NIPS,2016.82?90
57 Ioffe S,Szegedy C.Batch normalization:Accelerating deep network training by reducing internal covariate shift.In:Proceedings of the 32nd International Conference on Machine Learning.Lille,France:PMLR,2015.448?456
58 Salimans T,Kingma D P.Weight normalization:A simple reparameterization to accelerate training of deep neural networks.In:Proceedings of the 30th Conference on Neural Information Processing Systems.Barcelona,Spain:NIPS,2016.901?909
59 Xiang S T,Li H.On the effects of batch and weight normalization in generative adversarial networks.arXiv preprint arXiv:1704.03971,2017
60 Dietterich T G.Ensemble methods in machine learning.Multiple Classi fier Systems.Berlin,Heidelberg,Germany:Springer,2000.1?15
61 Zhou Z H,Wu J X,Tang W.Ensembling neural networks:Many could be better than all.Arti ficial Intelligence,2002,137(1):239?263
62 Tolstikhin I,Gelly S,Bousquet O,Simon-Gabriel C J,Sch?lkopf B.AdaGAN:Boosting generative models.arXiv preprint arXiv:1701.02386,2017
63 Huang X,Li Y X,Poursaeed O,Hopcroft J,Belongie S.Stacked generative adversarial networks.In:Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition.Honolulu,HI,USA:IEEE,2017.
64 Denton E,Chintala S,Szlam A,Fergus R.Deep generative image models using a Laplacian pyramid of adversarial networks.In:Proceedings of the 29th Annual Conference on Neural Information Processing Systems.Montreal,Canada:Curran Associates,Inc.,2015.1486?1494
65 Karras T,Aila T,Laine S,Lehtinen J.Progressive Growing of GANs for improved quality,stability,and variation.arXiv preprint arXiv:1710.10196,2017
66 Liu M Y,Tuzel O.Coupled generative adversarial networks.In:Proceedings of the 30th Conference on Neural Information Processing Systems.Barcelona,Spain:NIPS,2016.469?477
67 Ghosh A,Kulharia V,Namboodiri V,Torr P H S,Dokania P K.Multi-agent diverse generative adversarial networks.arXiv preprint arXiv:1704.02906,2017
68 Mescheder L,Nowozin S,Geiger A.The Numerics of GANs.arXiv preprint arXiv:1705.10461,2017
69 Sutton R S,McAllester D A,Singh S P,Mansour Y.Policy gradient methods for reinforcement learning with function approximation.In:Proceedings of the 12th International Conference on Neural Information Processing Systems.Denver,CO,USA:MIT Press,1999.1057?1063
70 Grondman I,Busoniu L,Lopes G A D,Babuska R.A survey of actor-critic reinforcement learning:Standard and natural policy gradients.IEEE Transactions on Systems,Man,and Cybernetics,Part C(Applications and Reviews),2012,42(6):1291?1307
71 Pfau D,Vinyals O.Connecting generative adversarial networks and actor-critic methods.arXiv preprint arXiv:1610.01945,2016
72 Sutton R S,Barto A G.Reinforcement Learning:An Introduction.Cambridge,UK:MIT Press,1998.
73 Goodfellow I.AMA(Ask Me Anything)about the GANs(Generative Adversarial Nets)paper[Online],available:https://fermatslibrary.com/arxiv_comments?url=https%3A%2F%2Farxiv.org%2Fpdf%2F1406.2661.pdf,April 31,2018
74 Williams R J.Simple statistical gradient-following algorithms for connectionist reinforcement learning.Machine Learning,1992,8(3?4):229?256
75 Yu L T,Zhang W N,Wang J,Yu Y.SeqGAN:Sequence generative adversarial nets with policy gradient.arXiv preprint arXiv:1609.05473,2016
76 Fedus W,Goodfellow I,Dai A M.MaskGAN:Better text generation via filling in the.arXiv preprint arXiv:1801.07736,2018
77 Ganin Y,Kulkarni T,Babuschkin I,Eslami S M A,Vinyals O.Synthesizing programs for images using reinforced adversarial learning.arXiv preprint arXiv:1804.01118,2018
78 Goodfellow I J.On distinguishability criteria for estimating generative models.arXiv preprint arXiv:1412.6515,2014
79 Arora S,Ge R,Liang Y Y,Ma T Y,Zhang Y.Generalization and equilibrium in generative adversarial nets(GANs).arXiv preprint arXiv:1703.00573,2017
80 Qi G J.Loss-sensitive generative adversarial networks on Lipschitz densities.arXiv preprint arXiv:1701.06264,2017
81 Arjovsky M,Chintala S,Bottou L.Wasserstein GAN.arXiv preprint arXiv:1701.07875,2017
82 Rachev S T,R M.Duality Theorems For Kantorovich-Rubinstein And Wasserstein Functionals.Warszawa:Instytut Matematyczny Polskiej Akademi Nauk,1990.
83 Gulrajani I,Ahmed F,Arjovsky M,Dumoulin V,Courville A.Improved training of wasserstein GANs.arXiv preprint arXiv:1704.00028,2017
84 Zhao J B,Mathieu M,LeCun Y.Energy-based generative adversarial network.arXiv preprint arXiv:1609.03126,2016
85 Wang R H,Cully A,Chang H J,Demiris Y.MAGAN:Margin adaptation for generative adversarial networks.arXiv preprint arXiv:1704.03817,2017
86 Iizuka S,Simo-Serra E,Ishikawa H.Globally and locally consistent image completion.ACM Transactions on Graphics,2017,36(4):Article No.107
87 Li Y J,Liu S F,Yang J M,Yang M H.Generative face completion.In:Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition.Honolulu,Hawaii,USA:IEEE,2017.5892?5900
88 Ledig C,Theis L,Huszar F,Caballero J,Cunningham A,Acosta A,et al.Photo-realistic single image superresolution using a generative adversarial network.arXiv preprint arXiv:1609.04802,2016
89 Lotter W,Kreiman G,Cox D.Unsupervised learning of visual structure using predictive generative networks.arXiv preprint arXiv:1511.06380,2015
90 Lotter W,Kreiman G,Cox D.Deep predictive coding networks for video prediction and unsupervised learning.arXiv preprint arXiv:1605.08104,2016
91 Kupyn O,Budzan V,Mykhailych M,Mishkin D,Matas J.DeblurGAN:Blind motion deblurring using conditional adversarial networks.arXiv preprint arXiv:1711.07064,2017
92 Huang J B,Kang S B,Ahuja N,Kopf J.Image completion using planar structure guidance.ACM Transactions on Graphics,2014,33(4):Article No.129
93 Goodfellow I J,Shlens J,Szegedy C.Explaining and harnessing adversarial examples.arXiv preprint arXiv:1412.6572,2014
94 Papernot N,Carlini N,Goodfellow I,Feinman R,Faghri F,Matyasko A,et al.cleverhans v2.0.0:An adversarial machine learning library.arXiv preprint arXiv:1610.00768,2016
95 Yang C F,Wu Q,Li H,Chen Y R.Generative poisoning attack method against neural networks.arXiv preprint arXiv:1703.01340,2017
96 Shen S,Jin G,Gao K,Zhang Y.APE-GAN:Adversarial Perturbation Elimination with GAN.arXiv preprint arXiv:1707.05474,2017.
97 Lee H,Han S,Lee J.Generative adversarial trainer:Defense to adversarial perturbations with GAN.arXiv preprint arXiv:1705.03387,2017
98 Johnson-Roberson M,Barto C,Mehta R,Sridhar S N,Rosaen K,Vasudevan R.Driving in the matrix:Can virtual worlds replace human-generated annotations for real world tasks?In:Proceedings of the 2017 IEEE International Conference on Robotics and Automation.Singapore:Institute of Electrical and Electronics Engineers Inc.,2017.746?753
99 Bousmalis K,Silberman N,Dohan D,Erhan D,Krishnan D.Unsupervised pixel-level domain adaptation with generative adversarial networks.In:Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition.Honolulu,Hawaii,USA:IEEE,2017.95?104
100 Shrivastava A,P fister T,Tuzel O,Susskind J,Wang W D,Webb R.Learning from simulated and unsupervised images through adversarial training.In:Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition.Honolulu,Hawaii,USA:IEEE,2017.2242?2251
101 Bousmalis K,Irpan A,Wohlhart P,Bai Y F,Kelcey M,Kalakrishnan M,et al.Using simulation and domain adaptation to improve efficiency of deep robotic grasping.arXiv preprint arXiv:1709.07857,2017
102 Santana E,Hotz G.Learning a driving simulator.arXiv preprint arXiv:1608.01230,2016
103 Huang V,Ley T,Vlachou-Konchylaki M,Hu W F.Enhanced experience replay generation for efficient reinforcement learning.arXiv preprint arXiv:1705.08245,2017
104 Wang K F,Gou C,Zheng N N,Rehg J M,Wang F Y.Parallel vision for perception and understanding of complex scenes:Methods,framework,and perspectives.Arti ficial Intelligence Review,2017,48(3):299?329
105 Yu Y,Qu W Y,Li N,Guo Z M.Open-category classification by adversarial sample generation.arXiv preprint arXiv:1705.08722,2017
106 Odena A.Semi-supervised learning with generative adversarial networks.arXiv preprint arXiv:1606.01583,2016
107 Lamb A M,Goyal A,Zhang Y,Zhang S Z,Courville A,Bengio Y.Professor forcing:A new algorithm for training recurrent networks.In:Proceedings of the 29th Conference on Neural Information Processing Systems.Barcelona,Spain:NIPS,2016.4601?4609
108 Johnson J,Gupta A,Fei-Fei L.Image generation from scene graphs.arXiv preprint arXiv:1804.01622,2018
109 Reed S,Akata Z,Yan X C,Logeswaran L,Schiele B,Lee H.Generative adversarial text to image synthesis.arXiv preprint arXiv:1605.05396,2016
110 Zhu J Y,Kr?henbühl P,Shechtman E,Efros A A.Generative visual manipulation on the natural image manifold.In:Proceedings of the 2016 European Conference on Computer Vision.Amsterdam,The Netherlands:Springer,2016.597?613
111 Brock A,Lim T,Ritchie J M,Weston N.Neural photo editing with introspective adversarial networks.arXiv preprint arXiv:1609.07093,2016
112 Isola P,Zhu J Y,Zhou T H,Efros A A.Image-to-image translation with conditional adversarial networks.arXiv preprint arXiv:1611.07004,2016
113 Wang T C,Liu M Y,Zhu J Y,Tao A,Kautz J,Catanzaro B.High-resolution image synthesis and semantic manipulation with conditional GANs.arXiv preprint arXiv:1711.11585,2017
114 He D,Xia Y,Qin T,Wang L W,Yu N H,Liu T Y,et al.Dual learning for machine translation.In:Proceedings of the 30th Conference on Neural Information Processing Systems.Barcelona,Spain:NIPS,2016.820?828
115 Zhu J Y,Park T,Isola P,Efros A A.Unpaired image-toimage translation using cycle-consistent adversarial networks.arXiv preprint arXiv:1703.10593,2017
116 Gatys L A,Ecker A S,Bethge M.A neural algorithm of artistic style.arXiv preprint arXiv:1508.06576,2015
117 Ho J,Ermon S.Generative adversarial imitation learning.arXiv preprint arXiv:1606.03476,2016
118 Ng A Y,Russell S J.Algorithms for inverse reinforcement learning.In:Proceedings of the 17th International Conference on Machine Learning.San Francisco,CA,USA:Morgan Kaufmann Publishers Inc.,2000.663?670
119 Ziebart B D,Maas A L,Bagnell J A,Dey A K.Maximum Entropy Inverse Reinforcement Learning.In:Proceedings of the 23rd National Conference on Arti ficial Intelligence.Chicago,Illinois:AAAI,2008.1433?1438
120 Ratli ffN D,Silver D,Bagnell J A.Learning to search:Functional gradient techniques for imitation learning.Autonomous Robots,2009,27(1):25?53
121 Kue fler A,Morton J,Wheeler T,Kochenderfer M.Imitating driver behavior with generative adversarial networks.In:Proceedings of the 2017 IEEE Intelligent Vehicles Symposium.Los Angeles,CA,USA:IEEE,2017
122 Wang Z Y,Merel J,Reed S,Wayne G,de Freitas N,Heess N.Robust imitation of diverse behaviors.arXiv preprint arXiv:1707.02747,2017
123 Wang J,Yu L T,Zhang W N,Gong Y,Xu Y H,Wang B Y,et al.IRGAN:A minimax game for unifying generative and discriminative information retrieval models.In:Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval.Shinjuku,Tokyo,Japan:ACM,2017.515?524
124 Frakes,W B,Baeza-Yates R,(Eds.).Information Retrieval:Data Structures And Algorithms(Vol.331).Englewood Cliffs,New Jersey:prentice Hall,1992.
125 Hu W W,Tan Y.Generating adversarial malware examples for black-box attacks based on GAN.arXiv preprint arXiv:1702.05983,2017
126 Gupta A,Zou J.Feedback GAN(FBGAN)for DNA:A novel feedback-loop architecture for optimizing protein functions.arXiv preprint arXiv:1804.01694,2018
127 Wang H W,Wang J,Wang J L,Zhao M,Zhang W N,Zhang F Z,et al.GraphGAN:Graph representation learning with generative adversarial nets.arXiv preprint arXiv:1711.08267,2017
128 Silver D,Schrittwieser J,Simonyan K,Antonoglou I,Huang A,Guez A,et al.Mastering the game of Go without human knowledge.Nature,2017,550(7676):354?359
129 Wang F Y,Zhang J J,Zheng X H,Wang X,Yuan Y,Dai X X,et al.Where does AlphaGo go:From church-turing thesis to AlphaGo thesis and beyond.IEEE/CAA Journal of Automatica Sinica,2016,3(2):113?120
130 Li L,Lin Y L,Zheng N N,Wang F Y.Parallel learning:A perspective and a framework.IEEE/CAA Journal of Automatica Sinica,2017,4(3):389?395
131 Lin Y L,Li L,Dai X Y,Zheng N N,Wang F Y.Master general parking skill via deep learning.In:Proceedings of the 2017 IEEE Intelligent Vehicles Symposium.Los Angeles,CA,USA:IEEE,2017.
132 Wang F Y,Zheng N N,Cao D P,Martinez C M,Li L,Liu T.Parallel driving in CPSS:A uni fied approach for transport automation and vehicle intelligence.IEEE/CAA Journal of Automatica Sinica,2017,4(4):577?587
133王飛躍.生成式對抗網(wǎng)絡(luò)的研究進(jìn)展與展望.中國計(jì)算機(jī)學(xué)會通訊,2017,13(11):58?62
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
兒童故事畫報(bào)(2019年5期)2019-05-26 14:26:14
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56