一種能量函數(shù)意義下的生成式對(duì)抗網(wǎng)絡(luò)
2018-06-07 16:21:35王功明喬俊飛王磊
自動(dòng)化學(xué)報(bào) 2018年5期
王功明 喬俊飛 王磊
生成式對(duì)抗網(wǎng)絡(luò)(Generative adversarial network,GAN)是由Goodfellow等[1]于2014年根據(jù)對(duì)抗競(jìng)爭(zhēng)思想提出來的一種優(yōu)化生成模型.GAN要解決的問題是如何從訓(xùn)練樣本中學(xué)習(xí)到概率分布特征,并進(jìn)一步生成新樣本數(shù)據(jù),訓(xùn)練樣本是圖片即生成新圖片,訓(xùn)練樣本是文字即輸出新文字.GAN在學(xué)習(xí)算法上受博弈論中的零和博弈(參與博弈的各方在嚴(yán)格競(jìng)爭(zhēng)下,一方的收益必然意味著另一方的損失,博弈各方的收益和損失相加總和永遠(yuǎn)為零,雙方不存在合作的可能)的啟發(fā),網(wǎng)絡(luò)由一個(gè)生成模型(Generative model)和一個(gè)判別模型(Discriminative model)構(gòu)成.生成模型的訓(xùn)練目的是試圖生成與訓(xùn)練樣本具有一致概率分布的新樣本,并作為判別模型的輸入;判別模型的訓(xùn)練目的是判斷生成模型生成的樣本是否是真實(shí)的訓(xùn)練樣本[2?4].GAN的優(yōu)化和訓(xùn)練過程是一個(gè)極小極大的博弈問題,最終的目的是判別模型無法分辨出生成樣本的真?zhèn)?即極大化判別模型的判斷能力,極小化生成模型輸出被判斷為偽造的概率[5?6].
然而,GAN的優(yōu)化和訓(xùn)練過程中也存在一些缺陷.一方面,基于傳統(tǒng)深度學(xué)習(xí)方法的生成模型無法快速地學(xué)習(xí)并生成樣本數(shù)據(jù),即學(xué)習(xí)效率低、算法收斂慢.另一方面基于梯度下降算法的訓(xùn)練存在梯度消失的問題,即當(dāng)真實(shí)樣本和生成樣本之間具有極小重疊甚至沒有重疊時(shí),其目標(biāo)函數(shù)的Jensen-Shannon散度是一個(gè)常數(shù),導(dǎo)致優(yōu)化目標(biāo)不連續(xù)[1,7?8].為了解決以上問題,Arjovsky等[9]提出了一種Wasserstein GAN(W-GAN)模型,利用Earth-Mover代替Jensen-Shannon散度來表征真實(shí)樣本和生成樣本分布之間的差異,用一個(gè)評(píng)價(jià)函數(shù)來對(duì)應(yīng)GAN的判別模型,而且評(píng)價(jià)函數(shù)需要建立在Lipschitz連續(xù)性假設(shè)上.盡管W-GAN避開了優(yōu)化目標(biāo)不連續(xù)的障礙,但是其存在的最大問題是模型的收斂性無法保證.Donahue等[10]提出一種Bi-GAN模型,將復(fù)雜數(shù)據(jù)映射到隱變量空間,從而實(shí)現(xiàn)特征學(xué)習(xí),并且引入了一個(gè)解碼器用于將真實(shí)數(shù)據(jù)映射到隱變量空間,成功地實(shí)現(xiàn)了優(yōu)化問題的等效轉(zhuǎn)移.盡管能夠部分地解決問題,但是Bi-GAN的訓(xùn)練耗時(shí)相對(duì)較長(zhǎng).
LeCun等[11]提出了能量模型的概念,并將待優(yōu)化參數(shù)的每一種取值對(duì)應(yīng)于一個(gè)能量取值,通過最小化能量來獲取對(duì)應(yīng)的參數(shù)取值.這種能量模型概念的提出有助于提高GAN的學(xué)習(xí)效率,因?yàn)樵摲椒o需在損失函數(shù)中加入正則化項(xiàng)也能較精確地完成訓(xùn)練目標(biāo).同時(shí),能量函數(shù)模型無需計(jì)算復(fù)雜的配分函數(shù)(Partition functions).當(dāng)傳統(tǒng)淺層神經(jīng)網(wǎng)絡(luò)用作判別模型時(shí),能量函數(shù)的選擇相對(duì)簡(jiǎn)單,即將實(shí)際輸出和期望輸出的差值作為能量函數(shù).然而,當(dāng)判別模型用深度學(xué)習(xí)模型表述時(shí),由于深度學(xué)習(xí)模型的訓(xùn)練方式大都采用無監(jiān)督學(xué)習(xí)[12],所以能量函數(shù)的選取及其穩(wěn)定性分析比較困難.
針對(duì)以上問題,本文提出一種基于重構(gòu)誤差的能量函數(shù)的GAN模型(Energy reconstruction error GAN,E-REGAN).生成模型由基于深度學(xué)習(xí)模型的自適應(yīng)深度信念網(wǎng)絡(luò)(Adaptive deep belief network,ADBN)來實(shí)現(xiàn),判別模型由自適應(yīng)深度自編碼器(Adaptive deep auto-encoder,ADAE)來實(shí)現(xiàn).其中,ADBN的輸入是真實(shí)樣本x和噪音z的組合,自適應(yīng)學(xué)習(xí)率能夠加快生成模型和判別模型的學(xué)習(xí)速度[13?15],ADAE的重構(gòu)誤差作為能量函數(shù).在MNIST和CIFAR-10標(biāo)準(zhǔn)數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果表明,與現(xiàn)有的幾種類似GAN模型相比,EREDBN模型在學(xué)習(xí)速度和數(shù)據(jù)生成能力兩方面均有較大提高.
本文結(jié)構(gòu)安排如下:第1節(jié)介紹介紹生成式對(duì)抗網(wǎng)絡(luò);第2節(jié)介紹E-REGAN模型,包括學(xué)習(xí)過程和網(wǎng)絡(luò)性能分析;第3節(jié)給出實(shí)驗(yàn)研究;第4節(jié)對(duì)本文工作進(jìn)行總結(jié).
1 生成式對(duì)抗網(wǎng)絡(luò)
GAN學(xué)習(xí)原理啟發(fā)于博弈論中的二人零和博弈(Two-player game).GAN模型中的博弈雙方分別由生成式模型和判別式模型來實(shí)現(xiàn).生成模型G用來學(xué)習(xí)已有樣本的概率分布,并試圖生成與已有樣本一致分布的數(shù)據(jù),通常用到的方法的是利用服從某一分布(高斯分布或均勻分布)的噪聲z生成一個(gè)類似真實(shí)訓(xùn)練數(shù)據(jù)的樣本,越逼近真實(shí)樣本越好.判別模型D是一個(gè)二分類器,估計(jì)一個(gè)樣本來自于訓(xùn)練數(shù)據(jù)(而非生成數(shù)據(jù))的概率.如果樣本來自于真實(shí)的訓(xùn)練數(shù)據(jù),D輸出大概率;否則,D輸出小概率.GAN的訓(xùn)練過程即不斷的調(diào)整G和D,直到D不能把生成的樣本從真實(shí)樣本中區(qū)分出來為止.在調(diào)整過程中,需要做到:1)優(yōu)化G,使它盡可能地生成讓D無法區(qū)分的樣本;2)優(yōu)化D,使它盡可能地區(qū)分出生成的樣本.當(dāng)D無法區(qū)分出生成的樣本時(shí),可以認(rèn)為G達(dá)到最優(yōu)狀態(tài).
假定已有的樣本數(shù)據(jù)為x,生成的樣本數(shù)據(jù)為G(z),那么生成模型G和判別模型D的損失函數(shù)定義如下:
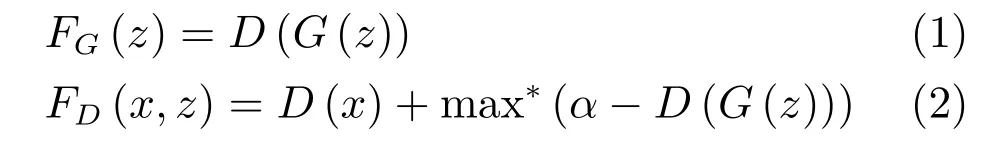
其中,max?(·)=max(0,·),α是一個(gè)正實(shí)數(shù).
由式(1)和式(2)可知,最小化FG(z)就是最大化FD(x,z)中的第二項(xiàng),即GAN的優(yōu)化過程就是一個(gè)極小極大化問題.
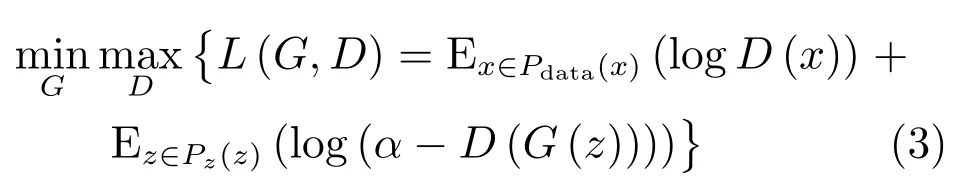
其中,Pdata(x)和Pz(z)分別表示真實(shí)樣本數(shù)據(jù)的概率分布和初始噪音數(shù)據(jù)的概率分布(可視為一種先驗(yàn)分布),E(·)表示計(jì)算期望值.
2 E-REGAN模型
2.1 基于能量的模型
假設(shè)一個(gè)預(yù)測(cè)問題:一個(gè)概率模型利用觀測(cè)到的輸入數(shù)據(jù)X來預(yù)測(cè)輸出數(shù)據(jù)Y.要想完成此任務(wù)需要學(xué)習(xí)X到Y(jié)的映射規(guī)律,并求取能夠使得P(Y/X)最大化的映射權(quán)值參數(shù)W.當(dāng)給定輸入數(shù)據(jù)X和映射權(quán)值參數(shù)W時(shí),必然會(huì)得到一個(gè)對(duì)應(yīng)的輸出Y,定義E(W,Y,X)為此時(shí)概率模型的能量.在有監(jiān)督學(xué)習(xí)框架下,這種基于能量模型的學(xué)習(xí)原理是對(duì)于訓(xùn)練集中每一個(gè)輸入樣本X,輸入輸出組合(X,Y)對(duì)應(yīng)的能量當(dāng)且僅當(dāng)Y是期望輸出時(shí),取得最小值;Y越偏離期望輸出,能量值越大.
2.2 E-REGAN結(jié)構(gòu)及其學(xué)習(xí)過程
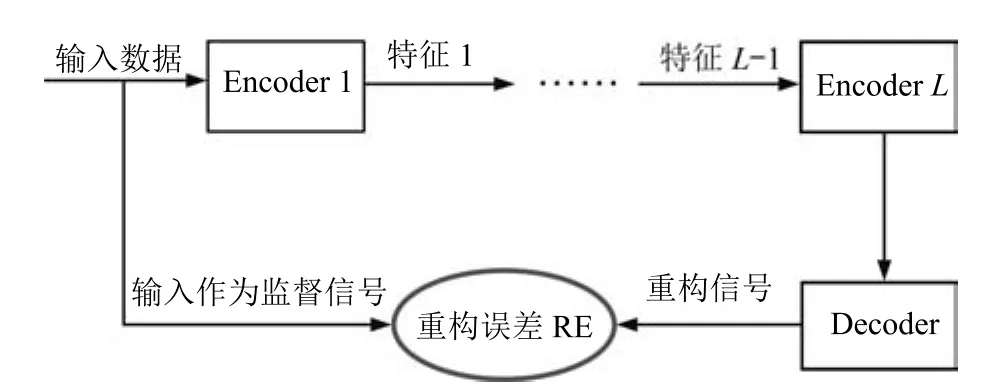
E-REGAN模型由自適應(yīng)深度信念網(wǎng)絡(luò)(ADBN)和自適應(yīng)深度自編碼器(ADAE)構(gòu)成,ADBN和ADAE分別充當(dāng)生成模型G和判別模型D.ADBN和ADAE的訓(xùn)練交替進(jìn)行展開,先訓(xùn)練生成模型G,優(yōu)化判別模型D,看是否滿足能量函數(shù)指標(biāo)要求;然后固定判別器D,繼續(xù)訓(xùn)練生成模型G,使得D的判別準(zhǔn)確率最小化.當(dāng)且僅當(dāng)Pdata=Pg(納什均衡)[1]時(shí),達(dá)到全局最優(yōu)解.E-REGAN的結(jié)構(gòu)原理如圖1所示.

圖1 E-REGAN結(jié)構(gòu)原理圖Fig.1 Structure and scheme of E-REGAN
2.2.1 自適應(yīng)深度信念網(wǎng)絡(luò)
ADBN由若干個(gè)順序堆疊的自適應(yīng)受限玻爾茲曼機(jī)(Adaptive restricted Boltzmann machine,ARBM)和一個(gè)輸出層構(gòu)成,前一個(gè)ARBM的輸出作為后一個(gè)ARBM的輸入.ARBM只有兩層神經(jīng)元,一層為可視層,由顯性神經(jīng)元組成,用于輸入訓(xùn)練數(shù)據(jù);另一層為隱含層,由隱性神經(jīng)元組成,用于提取訓(xùn)練數(shù)據(jù)的特征.ARBM的結(jié)構(gòu)如圖2所示,其中可視層有m個(gè)節(jié)點(diǎn),隱含層有n個(gè)節(jié)點(diǎn),W是連接權(quán)值矩陣.
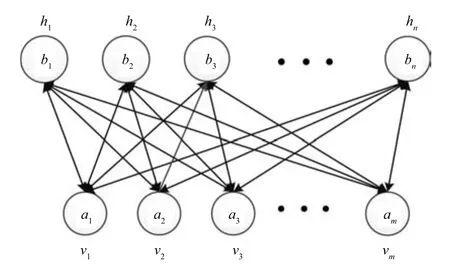
圖2 ARBM結(jié)構(gòu)圖Fig.2 Structure of ARBM
給定模型參數(shù)θ={W,a,b},那么可視層和隱含層的聯(lián)合概率分布P(v,h;θ)用能量函數(shù)E(v,h;θ)定義為
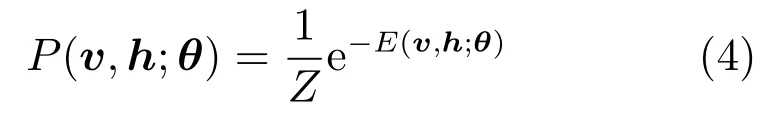
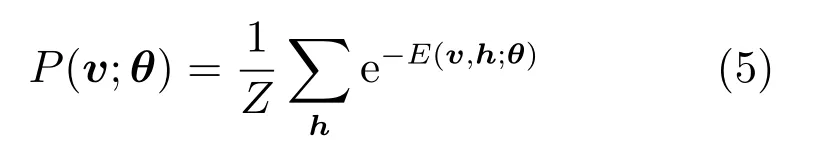
對(duì)于一個(gè)伯努利(可視層)分布–伯努利(隱含層)分布的RBM,能量函數(shù)定義為

其中,wij是RBM 的連接權(quán)值,ai和bj分別表示可視層節(jié)點(diǎn)和隱含層節(jié)點(diǎn)的偏置.那么條件概率分布可表示為
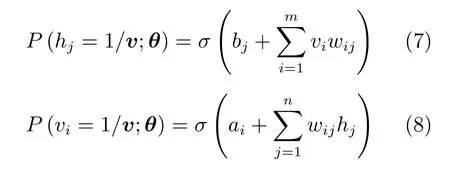
其中,σ(·)是一個(gè)Sigmoid函數(shù).
可視層和隱含層是二值狀態(tài),判斷其二值概率取值的標(biāo)準(zhǔn)常通過設(shè)定一個(gè)閾值來實(shí)現(xiàn)[16],以隱含層為例,可表示為
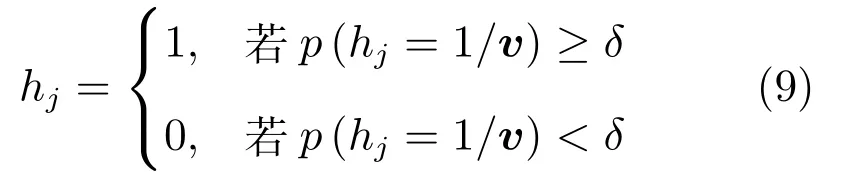
其中,δ為一個(gè)介于0.5~1的常數(shù).
通過計(jì)算對(duì)數(shù)似然函數(shù)logP(v;θ)的梯度,并根據(jù)ARBM訓(xùn)練過程連續(xù)兩次迭代后的參數(shù)更新方向的異同[13,15]設(shè)計(jì)自適應(yīng)學(xué)習(xí)率η的方法,可以得到ARBM權(quán)值更新公式為
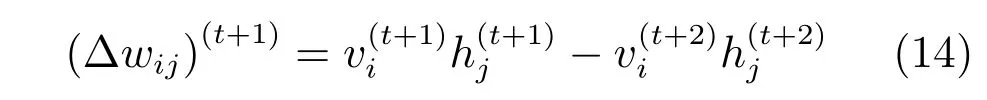
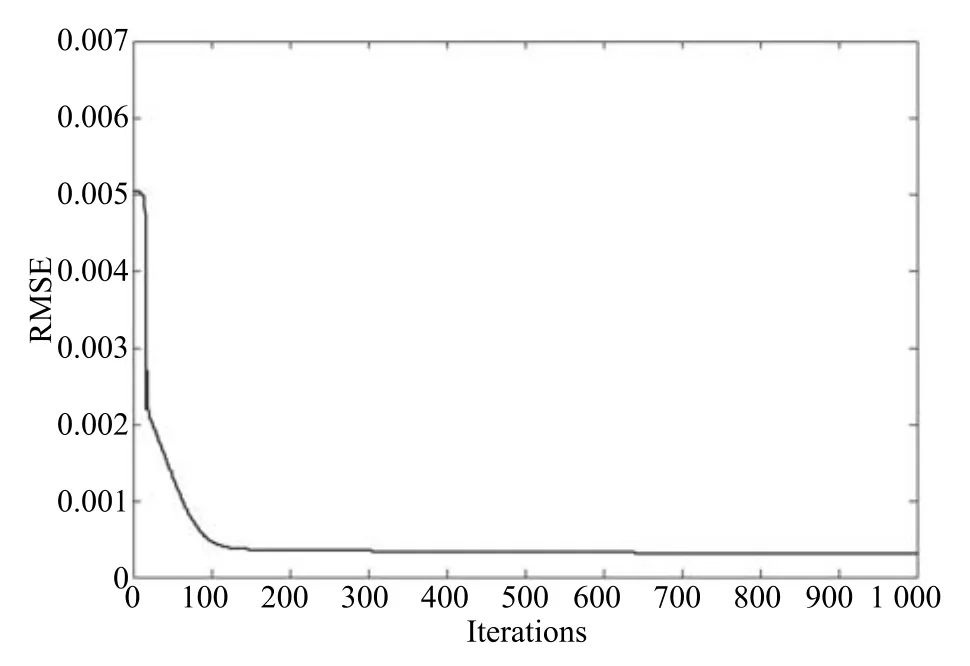
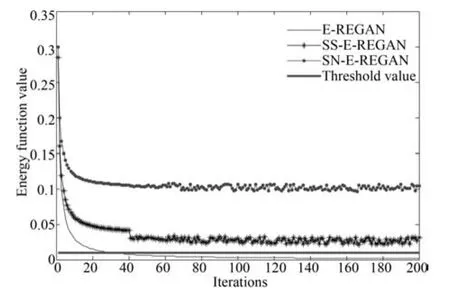
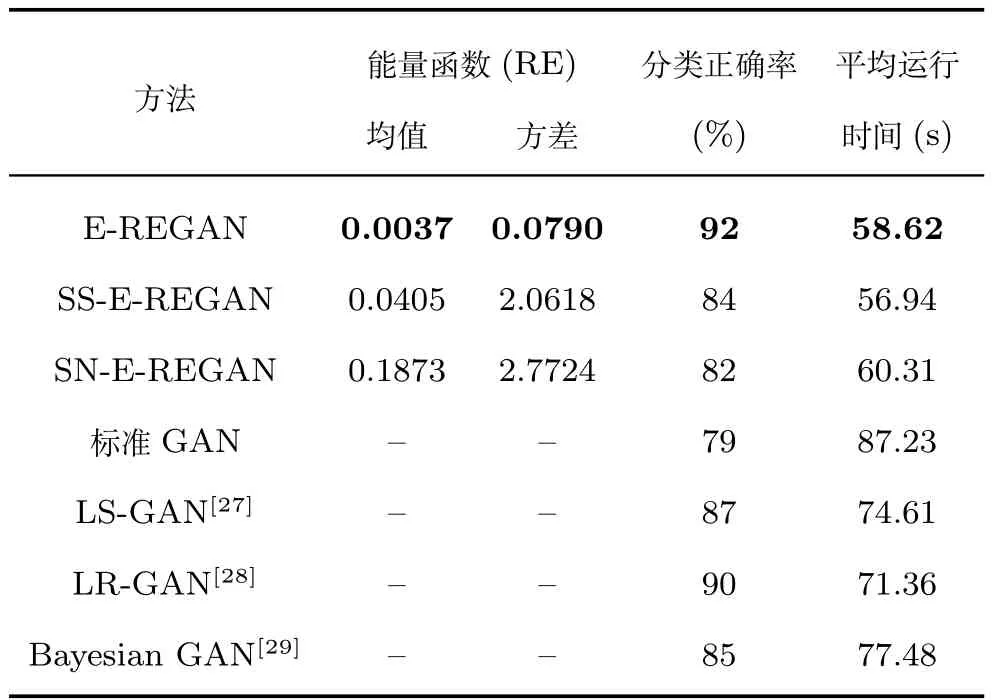
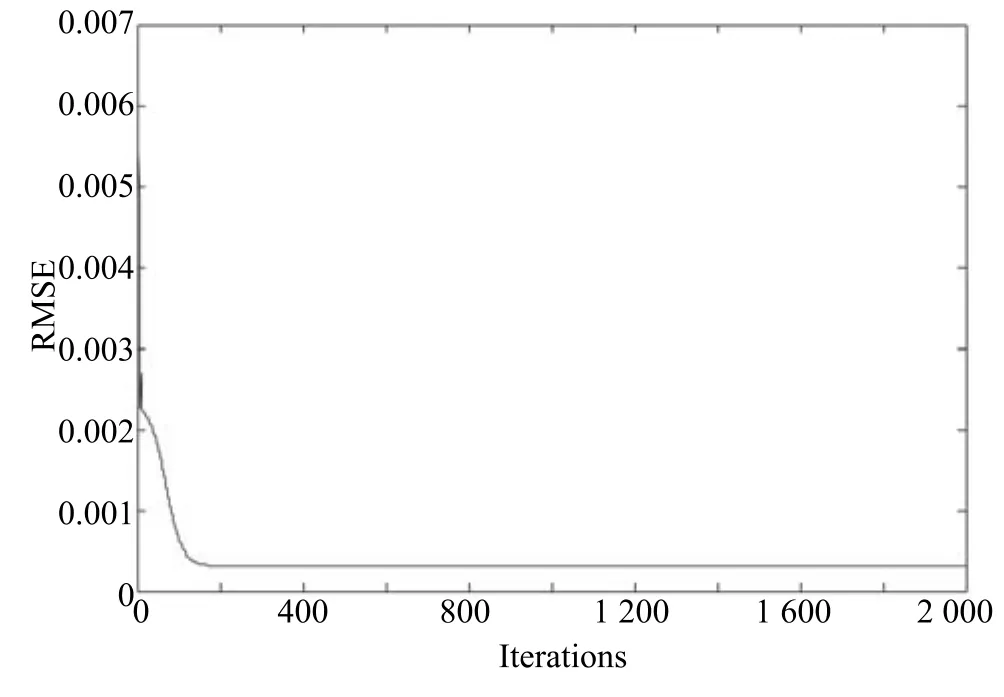
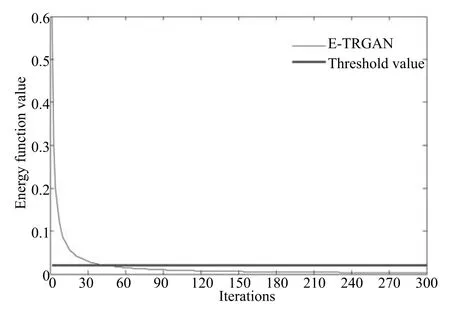
其中,τ和η分別表示ARBM 的迭代次數(shù)和學(xué)習(xí)率,Edata(vihj)和Emodel(vihj)分別表示訓(xùn)練集中觀測(cè)數(shù)據(jù)的期望和模型確定的分布上的期望,t是吉布斯采樣步數(shù)[17].通常情況下,Emodel(vihj)可由吉布斯采樣近似得到[17].ARBM 的這種訓(xùn)練稱為自適應(yīng)對(duì)比散度(Adaptive contrastive divergence,ACD)算法[13,15,18].u和v分別表示學(xué)習(xí)率增大系數(shù)和減小系數(shù),且0 堆疊的ARBM訓(xùn)練結(jié)束后,再利用BP算法從輸出層開始由上到下對(duì)整個(gè)ADBN的權(quán)值進(jìn)行微調(diào)(Fine-tuning)[18]. 2.2.2 自適應(yīng)深度自編碼器 ADAE由若干個(gè)ARBM順序堆疊而成,是一種用于對(duì)數(shù)據(jù)進(jìn)行無監(jiān)督特征提取和原始數(shù)據(jù)復(fù)原的深度模型.ADAE與ADBN的區(qū)別在于ADAE沒有監(jiān)督信號(hào)層[19?20],其結(jié)構(gòu)如圖3所示.可用ACD算法快速訓(xùn)練ADAE并實(shí)現(xiàn)判別模型對(duì)真實(shí)樣本和生成樣本的正確判別.由于ADAE是一種無監(jiān)督學(xué)習(xí)模型,所以基于逼近誤差的能量函數(shù)模型選取方法不再適用.在此,開創(chuàng)性地將ADAE的重構(gòu)誤差(Reconstruction error,RE)作為能量函數(shù)模型,RE定義如下所示: 其中,Ns和Nd分別表示樣本數(shù)據(jù)個(gè)數(shù)和樣本數(shù)據(jù)維數(shù);vij和ij分別表示原始輸入樣本集的數(shù)據(jù)點(diǎn)值和輸入樣本集的重構(gòu)數(shù)據(jù)點(diǎn)值. 圖3 ADAE結(jié)構(gòu)原理圖Fig.3 Structure and scheme of ADAE 用作判別模型時(shí),ADAE首先對(duì)真實(shí)樣本數(shù)據(jù)進(jìn)行特征提取,經(jīng)過快速有效地編碼,得到對(duì)真實(shí)樣本數(shù)據(jù)的抽象特征表述F并保存下來;然后對(duì)抽象表述進(jìn)行復(fù)原處理(解碼),得到真實(shí)樣本數(shù)據(jù)的重構(gòu)信息.在此過程中,將重構(gòu)誤差作為一種能量函數(shù),能量函數(shù)越小,對(duì)應(yīng)的判別模型學(xué)習(xí)的越充分,理想情況下能量函數(shù)為0.但在實(shí)際應(yīng)用中,考慮到判別模型的訓(xùn)練成本問題,經(jīng)常設(shè)置一個(gè)能量函數(shù)指數(shù)λ(0<λ<1). 訓(xùn)練結(jié)束后,將生成模型的生成數(shù)據(jù)作為ADAE的輸入,得到對(duì)生成數(shù)據(jù)的抽象特征表述F0.當(dāng)F和F0的絕對(duì)誤差|F?F0|小于或等于能量函數(shù)閾值γ(0<γ<λ),需要穩(wěn)定判別模型,繼續(xù)訓(xùn)練生成模型,然后再以同樣的原理利用判別模型檢驗(yàn)生成模型的生成能力.由于以能量函數(shù)閾值和能量函數(shù)指數(shù)作為評(píng)價(jià)指標(biāo)的優(yōu)化問題不需要求梯度校正信號(hào),所以只需通過判斷是否滿足指標(biāo)要求來做更進(jìn)一步的迭代優(yōu)化即可.E-REGAN的成功之處在于,只要滿足充足的訓(xùn)練迭代步數(shù),ADBN和ADAE將無限接近理想狀態(tài)[21?23].在此,自適應(yīng)學(xué)習(xí)率對(duì)加速訓(xùn)練過程起著重要作用. GAN的基本思想源自博弈論的二人零和博弈,由一個(gè)生成模型G和一個(gè)判別模型D構(gòu)成,通過對(duì)抗學(xué)習(xí)的方式來迭代訓(xùn)練,直至逼近納什均衡.因此,E-REGAN的穩(wěn)定性主要取決于G和D在迭代訓(xùn)練過程中能否達(dá)到納什均衡. 假設(shè)PG是生成樣本G(z)的概率密度分布,定義納什均衡函數(shù)為 訓(xùn)練判別模型D來最小化f,訓(xùn)練生成模型G來最小化g,那么納什均衡的平衡點(diǎn)即為G和D的最優(yōu)組合對(duì)(G?,D?),且滿足 定理1.如果(G?,D?)是一個(gè)納什均衡的平衡點(diǎn),那么當(dāng)PG?=Pdata時(shí),滿足f(G?,D?)=α. 證明.對(duì)式(16)作展開處理 現(xiàn)給出式(2)的一般形式如下所示: 其中,A,B≥0,0≤D<∞.那么ψ(D)的導(dǎo)數(shù)為 由式(22)可知,當(dāng)A 由于ψ(D)在[0,∞)上是收斂的,所以存在以下兩種情況: 1)如果D?(x)>α且(x)=min(D?(x),α),那么不難得到f(G?,) 2)用ψ(D)的最小值代替D?(x)可得f(G?,)的上界[24],即 根據(jù)式(19)可得 聯(lián)立式(20)和式(24)可得 由于D?(x)≤α,所以有 通過式(23)和式(26)可知,α≤f(G?,D?)≤α,即f(G?,D?)=α. 分析E-REGAN模型結(jié)構(gòu)可知,ADBN具有可靠的穩(wěn)定性[13,15],所以生成模型G穩(wěn)定.接下來討論判別模型D的穩(wěn)定性問題,即重構(gòu)誤差RE的收斂性問題. RE是對(duì)ADAE的重構(gòu)輸入數(shù)據(jù)和原始輸入數(shù)據(jù)計(jì)算絕對(duì)誤差的方法,計(jì)算過程中需要提前知道每一個(gè)隱含層(ARBM)的狀態(tài)(中間變量).所以,要證明RE的收斂性問題必須保證ADAE中間變量的有界性.不失一般性,將式(7)和式(8)中激活函數(shù)的上下漸近線設(shè)為AH和AL,那么對(duì)于任何一個(gè)ARBM,分別表示可視層的輸入狀態(tài)和經(jīng)過t次采樣得到的重構(gòu)狀態(tài),分別表示由得到的隱含層狀態(tài)和對(duì)模型經(jīng)過t次采樣得到的隱含層狀態(tài).那么經(jīng)過t次采樣后有 由式(27)~(30)可以看出,在每個(gè)ARBM 的吉布斯采樣過程中,網(wǎng)絡(luò)輸出與采樣過程的中間狀態(tài)有關(guān). 定理2.假設(shè)分別是ARBM的輸入狀態(tài)、中間狀態(tài)和輸出狀態(tài),那么ADAE中間變量有界的充分必要條件是所有狀態(tài)滿足 證明.由于組成ADAE的ARBM是順序疊加的,所以當(dāng)時(shí),由式(27)~(30)可知,最后一個(gè)ARBM的隱含層在經(jīng)過t次吉布斯采樣后,狀態(tài)范圍必定為[AL,AH],即所以滿足整個(gè)ADAE在訓(xùn)練過程中輸入輸出有界性,網(wǎng)絡(luò)穩(wěn)定.充分性得證. 若ADAE穩(wěn)定,則每個(gè)ARBM的可視層和隱含層狀態(tài)均滿足輸入輸出有界性.由于Sigmoid函數(shù)具有單調(diào)遞增性,且隨著二值神經(jīng)元中取1的神經(jīng)元個(gè)數(shù)不斷增加.可得不等式 即中間狀態(tài)滿足 必要性得證. 通過以上分析及對(duì)兩個(gè)定理的證明可知,EREGAN具有可靠的穩(wěn)定性. 為了驗(yàn)證所提E-REGAN模型的對(duì)抗學(xué)習(xí)能力,分別在MNIST數(shù)據(jù)集和CIFAR-10數(shù)據(jù)集上進(jìn)行測(cè)試.為了排除無關(guān)因素對(duì)實(shí)驗(yàn)結(jié)果的影響,客觀反映E-REGAN的性能,仿真實(shí)驗(yàn)的編譯軟件和計(jì)算機(jī)運(yùn)行環(huán)境設(shè)置如下:編譯軟件為MATLAB 8.2版本,計(jì)算機(jī)處理器為Intel(R)Core(TM)i7-4790,主頻為3.6GHz,RAM為8GB. MNIST數(shù)據(jù)集包含60000張訓(xùn)練數(shù)字圖像和10000張測(cè)試數(shù)字圖像,每一個(gè)數(shù)字均用多種手寫體顯示.每張圖像均是一個(gè)0~9的手寫數(shù)字,大小為28×28的像素規(guī)格.隨著模式識(shí)別和數(shù)據(jù)挖掘技術(shù)的不斷發(fā)展,很多理論方法應(yīng)用到該數(shù)據(jù)庫中.該數(shù)據(jù)庫被視為一種理想的、標(biāo)準(zhǔn)的測(cè)試新方法的經(jīng)典對(duì)象[25?26].取100張圖像數(shù)據(jù)和隨機(jī)噪音的組合作為訓(xùn)練樣本對(duì)生成模型進(jìn)行訓(xùn)練,首先對(duì)EREGAN的生成模型ADBN進(jìn)行訓(xùn)練,然后對(duì)判別模型ADAE進(jìn)行編碼解碼訓(xùn)練.其中ADBN結(jié)構(gòu)為781-80-80-781,ADAE結(jié)構(gòu)為781-80-80-80-80.E-REGAN生成模型ADBN的固有學(xué)習(xí)參數(shù)設(shè)置如表1所示. 表1 MNIST數(shù)據(jù)集測(cè)試中ADBN的固有參數(shù)Table 1 Fixed parameters of ADBN on MNIST dataset 圖4是生成模型ADBN最后一個(gè)階段的訓(xùn)練均方根誤差(Root mean square error,RMSE).從圖4可以看出,盡管上一階段ADBN的生成樣本依然被判別模型從真實(shí)樣本中識(shí)別出來,但是ADBN上一階段的訓(xùn)練RMSE已經(jīng)很小,收斂到0.005.最后一個(gè)階段訓(xùn)練RMSE收斂到0.000376,訓(xùn)練速度非常快,在前100次迭代中已接近收斂.圖5是判別模型的能量函數(shù)變化曲線.其中,SS-E-REGAN(Single sample E-REGAN)是指生成模型的輸入只有真實(shí)樣本x的E-REGAN,SN-E-REGAN(Single noise E-REGAN)是指生成模型的輸入只有噪音z的E-REGAN.從圖5可以看出,缺少噪音輸入的生成模型對(duì)應(yīng)的E-REGAN魯棒性差,缺少真實(shí)樣本輸入的生成模型對(duì)應(yīng)的E-REGAN精度不高;相比之下,同時(shí)將噪音和真實(shí)樣本作為生成模型輸入的E-REGAN具有較強(qiáng)的魯棒性,對(duì)抗學(xué)習(xí)性能優(yōu)越.同時(shí),ADAE中的自適應(yīng)學(xué)習(xí)率也加速了能量函數(shù)的收斂速度. 圖6是E-REGAN生成的手寫數(shù)字樣本,圖7是SS-E-REGAN生成的樣本圖像,圖8是SN-EREGAN生成樣本圖像,圖9是利用基于梯度校正信號(hào)且無能量函數(shù)模型的GAN(Gradient-GAN,g-GAN)的生成樣本圖像,圖10是Loss-sensitive GAN(LS-GAN)[27]的生成樣本圖像.可以看出,在經(jīng)過充分的對(duì)抗學(xué)習(xí)過程后,E-REGAN生成的樣本最清晰,與真實(shí)的手寫數(shù)字圖像幾乎完全一致,至少用肉眼無法辨別出真?zhèn)? 圖4 生成模型ADBN的訓(xùn)練RMSEFig.4 RMSE curve of generative model ADBN 圖5 E-REGAN的能量函數(shù)變化曲線Fig.5 Energy function curves of E-REGAN 圖6 E-REGAN生成的樣本圖像Fig.6 Sample images generated by E-REGAN 圖7 SS-E-REGAN生成的樣本圖像Fig.7 Sample images generated by SS-E-REGAN 圖8 SN-E-REGAN生成的樣本圖像Fig.8 Sample images generated by SN-E-REGAN 圖9 g-GAN生成的樣本圖像Fig.9 Sample images generated by g-GAN 圖10 LS-GAN生成的樣本圖像Fig.10 Sample images generated by LS-GAN 為了更客觀地反映E-REGAN優(yōu)越的學(xué)習(xí)性能和對(duì)抗生成能力,將E-REGAN與其他類似模型進(jìn)行比較,結(jié)果來自20次獨(dú)立實(shí)驗(yàn),如表2所示.其中,LS-GAN是Loss-sensitive GAN[27];LR-GAN是Layered-recursive GAN[28];Bayesian GAN[29]是一種基于貝葉斯準(zhǔn)則的GAN.在對(duì)比實(shí)驗(yàn)中,利用分類正確率作為衡量E-REGAN在MNIST數(shù)據(jù)集上生成樣本(100個(gè)圖像)的優(yōu)劣指標(biāo)(所有生成樣本圖像由同一個(gè)RBM分類器來分類). 表2 MNIST數(shù)據(jù)集實(shí)驗(yàn)結(jié)果對(duì)比Table 2 Result comparison on MNIST dataset 由表2可知,E-REGAN具有最好的對(duì)抗學(xué)習(xí)能力和樣本生成能力以及較好的魯棒性能,同時(shí)具有較快的網(wǎng)絡(luò)學(xué)習(xí)速度. CIFAR-10數(shù)據(jù)集包含10類60000個(gè)32×32的彩色圖像,其中有50000個(gè)訓(xùn)練圖像和10000個(gè)測(cè)試圖像.該數(shù)據(jù)集分為5個(gè)訓(xùn)練塊和1個(gè)測(cè)試塊,每個(gè)塊有10000個(gè)圖像.隨著深度學(xué)習(xí)技術(shù)的不斷發(fā)展,基于深度神經(jīng)網(wǎng)絡(luò)的識(shí)別方法不斷涌現(xiàn),CIFAR-10數(shù)據(jù)庫目前已成為最具說服力的測(cè)試新方法的數(shù)據(jù)集之一[30?34].取100張圖像數(shù)據(jù)和隨機(jī)噪音的組合作為訓(xùn)練樣本對(duì)生成模型進(jìn)行訓(xùn)練,首先對(duì)E-REGAN的生成模型ADBN進(jìn)行訓(xùn)練,然后對(duì)E-REGAN的判別模型ADAE進(jìn)行編碼解碼訓(xùn)練.其中ADBN結(jié)構(gòu):1024-100-100-100-1024,ADAE結(jié)構(gòu):1024-100-100-100-100-100.EREGAN生成模型ADBN的固有學(xué)習(xí)參數(shù)設(shè)置如表3所示. 表3 CIFAR-10數(shù)據(jù)集測(cè)試中ADBN的固有參數(shù)Table 3 Fixed parameters of ADBN on CIFAR-10 dataset 圖11是生成模型ADBN在最后一個(gè)訓(xùn)練階段的RMSE變化曲線.可以看出,盡管上一個(gè)對(duì)抗迭代過程中ADBN的生成樣本被判別模型從真實(shí)樣本中識(shí)別出來,但是ADBN的訓(xùn)練RMSE已經(jīng)很小,收斂到0.0052.最后一個(gè)對(duì)抗迭代過程訓(xùn)練RMSE收斂到0.00032,訓(xùn)練速度非常快,在前16次迭代中已接近收斂.圖12是判別模型的能量函數(shù)變化曲線,可以看出E-REGAN的能量函數(shù)值在前50迭代中已經(jīng)接近收斂,且滿足能量函數(shù)閾值要求,此時(shí)生成模型的性能達(dá)到相對(duì)理想的狀態(tài).圖13是E-REGAN生成的CIFAR-10數(shù)據(jù)樣本,圖14是Loss-sensitive GAN(LS-GAN)[27]生成的CIFAR-10數(shù)據(jù)樣本,圖15是Layered-recursive GAN(LR-GAN)[28]生成的CIFAR-10數(shù)據(jù)樣本,圖16是Bayesian GAN[29]生成的CIFAR-10數(shù)據(jù)樣本.可以看出,在經(jīng)過充分的對(duì)抗學(xué)習(xí)過程后,E-REGAN生成的樣本圖像與真實(shí)的CIFAR-10數(shù)據(jù)集中的圖像最接近,至少用肉眼無法辨別出真?zhèn)? 為了更為客觀地反映E-REGAN優(yōu)越的學(xué)習(xí)性能和對(duì)抗生成能力,將E-REGAN與其他類似模型同時(shí)在CIFAR-10數(shù)據(jù)集上進(jìn)行試驗(yàn)驗(yàn)證并作比較.相應(yīng)結(jié)果來自20次獨(dú)立實(shí)驗(yàn),如表4所示.在對(duì)比實(shí)驗(yàn)中,利用測(cè)試誤差(Test-error)作為衡量E-REGAN在CIFAR-10數(shù)據(jù)集上生成樣本的優(yōu)劣指標(biāo).測(cè)試誤差Test-error定義如下: 圖11 生成模型ADBN的訓(xùn)練RMSEFig.11 RMSE curve of generative model ADBN 圖12 E-REGAN的能量函數(shù)變化曲線Fig.12 Energy function curves of E-REGAN 圖13 E-REGAN生成的樣本圖像Fig.13 Sample images generated by E-REGAN 表4 CIFAR-10數(shù)據(jù)集實(shí)驗(yàn)結(jié)果對(duì)比Table 4 Result comparison on CIFAR-10 dataset 圖14 LS-GAN生成的樣本圖像Fig.14 Sample images generated by LS-GAN 其中,pi和i分別為真實(shí)圖像和生成圖像經(jīng)過向量化和歸一化后的元素,I為圖像向量化后的維數(shù). 從表4可以看出,E-REGAN具有較好的樣本生成能力和更強(qiáng)的魯棒性,同時(shí),具有最快的網(wǎng)絡(luò)學(xué)習(xí)速度. 圖15 LR-GAN生成的樣本圖像Fig.15 Sample images generated by LR-GAN 圖16 Bayesian GAN生成的樣本圖像Fig.16 Sample images generated by Bayesian GAN 針對(duì)現(xiàn)有生成式對(duì)抗網(wǎng)絡(luò)GAN生成模型學(xué)習(xí)效率低下和判別模型的學(xué)習(xí)過程易出現(xiàn)梯度消失的兩個(gè)缺點(diǎn),本文提出了一種能量函數(shù)意義下的生成式對(duì)抗網(wǎng)絡(luò)(E-REGAN).將自適應(yīng)深度信念網(wǎng)絡(luò)(ADBN)作為生成模型來加速生成式學(xué)習(xí),自適應(yīng)深度自編碼器(ADAE)作為判別模型來加速判別式學(xué)習(xí).噪音和真實(shí)樣本同時(shí)作為自適應(yīng)深度信念網(wǎng)絡(luò)的輸入信號(hào),判別模型采用無監(jiān)督學(xué)習(xí),自適應(yīng)深度自編碼器的重構(gòu)誤差作為能量函數(shù).能量函數(shù)意義下的判別基準(zhǔn)無需梯度校正信號(hào)使得生成模型和判別模型在對(duì)抗學(xué)習(xí)過程中實(shí)現(xiàn)快速精確的交替優(yōu)化.與其他幾種模型相比,基于能量函數(shù)的E-RAGAN能夠在快速的交替對(duì)抗優(yōu)化過程中生成大量無限接近于真實(shí)樣本的數(shù)據(jù),且網(wǎng)絡(luò)魯棒性較強(qiáng).本文仍有不足之處,由于深度自編碼器的引入,自適應(yīng)學(xué)習(xí)率在面對(duì)深層次的特征提取時(shí),加速效果已不再明顯.在今后的工作中,如何從網(wǎng)絡(luò)結(jié)構(gòu)的角度提高特征提取的效率將是優(yōu)先研究方向. 1 Goodfellow I J,Pouget-Abadie J,Mirza M,Xu B,Warde-Farley D,Ozair S,et al.Generative adversarial nets.In:Proceedings of the 27th International Conference on Neural Information Processing Systems.Montreal,Canada:MIT Press,2014.2672?2680 2 Makhzani A,Shlens J,Jaitly N,Goodfellow I,Frey B.Adversarial autoencoders.arXiv preprint arXiv:1511.05644,2015. 3 Mao X D,Li Q,Xie H R,Lau R Y K,Wang Z,Smolley S P.Least squares generative adversarial networks.arXiv preprint ArXiv:1611.04076,2016. 4 Durugkar I,Gemp I,Mahadevan S.Generative multiadversarial networks.arXiv preprint arXiv:1611.01673,2016. 5 Huang X,Li Y X,Poursaeed O,Hopcroft J,Belongie1 S.Stacked generative adversarial networks.arXiv preprint arXiv:1612.04357,2016. 6 Saito M,Matsumoto E,Saito S.Temporal generative adversarial nets with singular value clipping.In:Proceedings of the 2017 IEEE Conference on Computer Vision.Venice,Italy:ICCV,2017.2849?2858 7 Che T,Li Y R,Zhang R X,Hjelm R D,Li W J,Song Y Q,et al.Maximum-likelihood augmented discrete generative adversarial networks.arXiv preprint arXiv:1702.07983,2017. 8 Wang Kun-Feng,Gou Chao,Duan Yan-Jie,Lin Yi-Lun,Zheng Xin-Hu,Wang Fei-Yue.Generative adversarial networks:the state of the art and beyond.Acta Automatica Sinica,2017,43(3):321?332(王坤峰,茍超,段艷杰,林懿倫,鄭心湖,王飛躍.生成式對(duì)抗網(wǎng)絡(luò)GAN的研究進(jìn)展與展望.自動(dòng)化學(xué)報(bào),2017,43(3):321?332) 9 Arjovsky M,Chintala S,Bottou L.Wasserstein GAN.arXiv preprint arXiv:1701.07875,2017. 10 Donahue J,Kr?henbühl P,Darrell T.Adversarial feature learning.arXiv preprint arXiv:1605.09782,2016. 11 LeCun Y,Huang F.Loss functions for discriminative training of energy-based models.In:Proceedings of the 10th International Workshop on Arti ficial Intelligence and Statistics.Barbados:AIS,2005.206?213 12 Qiao Jun-Fei,Pan Guang-Yuan,Han Hong-Gui.Design and application of continuous deep belief network.Acta Automatica Sinica,2015,41(12):2138?2146(喬俊飛,潘廣源,韓紅桂.一種連續(xù)型深度信念網(wǎng)的設(shè)計(jì)與應(yīng)用.自動(dòng)化學(xué)報(bào),2015,41(12):2138?2146) 13 Qiao Jun-Fei,Wang Gong-Ming,Li Xiao-Li,Han Hong-Gui,Chai Wei.Design and application of deep belief network with adaptive learning rate.Acta Automatica Sinica,2017,43(8):1339?1349(喬俊飛,王功明,李曉理,韓紅桂,柴偉.基于自適應(yīng)學(xué)習(xí)率的深度信念網(wǎng)設(shè)計(jì)與應(yīng)用.自動(dòng)化學(xué)報(bào),2017,43(8):1339?1349) 14 Lopes N,Ribeiro B.Towards adaptive learning with improved convergence of deep belief networks on graphics processing units.Pattern Recognition,2014,47(1):114?127 15 Wang Gong-Ming,Li Wen-Jing,Qiao Jun-Fei.Prediction of effluent total phosphorus using PLSR-based adaptive deep belief network.CIESC Journal,2017,68(5):1987?1997(王功明,李文靜,喬俊飛.基于PLSR自適應(yīng)深度信念網(wǎng)絡(luò)的出水總磷預(yù)測(cè).化工學(xué)報(bào),2017,68(5):1987?1997) 16 Hinton G E.Training products of experts by minimizing contrastive divergence.Neural Computation,2002,14(8):1771?1800 17 Le Roux N,Bengio Y.Representational power of restricted boltzmann machines and deep belief networks.Neural Computation,2008,20(6):1631?1649 18 Hinton G E,Osindero S,Teh Y W.A fast learning algorithm for deep belief nets.Neural Computation,2006,18(7):1527?1554 19 Alain G,Bengio Y.What regularized auto-encoders learn from the data-generating distribution.The Journal of Machine Learning Research,2014,15(1):3563?3593 20 Chan P P K,Lin Z,Hu X,Tsang E C C,Yeung D S.Sensitivity based robust learning for stacked autoencoder against evasion attack.Neurocomputing,2017,267:572?580 21 Huang G B,Chen L,Siew C K.Universal approximation using incremental constructive feedforward networks with random hidden nodes.IEEE Transactions on Neural Networks,2006,17(4):879?892 22 Leung F H F,Lam H K,Ling S H,Tam P K S.Tuning of the structure and parameters of a neural network using an improved genetic algorithm.IEEE Transactions on Neural networks,2003,14(1):79?88 23 de la Rosa E,Yu W.Randomized algorithms for nonlinear system identi fication with deep learning modi fication.Information Sciences,2016,364?365:197?212 24 Zhao J B,Mathieu M,LeCun Y.Energy-based generative adversarial network.arXiv preprint arXiv:1609.03126,2016. 25 Larochelle H,Bengio Y,Louradour J,Lamblin P.Exploring strategies for training deep neural networks.The Journal of Machine Learning Research,2009,10:1?40 26 Wang Y,Wang X G,Liu W Y.Unsupervised local deep feature for image recognition.Information Sciences,2016,351:67?75 27 Qi G J.Loss-sensitive generative adversarial networks on lipschitz densities.arXiv preprint arXiv:1701.06264,2017. 28 Yang J W,Kannan A,Batra D,Parikh D.LR-GAN:layered recursive generative adversarial networks for image generation.arXiv preprint arXiv:1703.01560,2017. 29 Saatchi Y,Wilson A.Bayesian GAN.arXiv preprint arXiv:1705.09558,2017. 30 Hinton G E,Srivastava N,Krizhevsky A,Sutskever I,Salakhutdinov R R.Improving neural networks by preventing co-adaptation of feature detectors.arXiv preprint arXiv:1207.0580,2012. 31 Xu B,Wang N Y,Chen T Q,Li M.Empirical evaluation of recti fied activations in convolutional network.arXiv preprint arXiv:1505.00853,2015. 32 Goroshin R,Bruna J,Tompson J,Eigen D,LeCun Y.Unsupervised learning of spatiotemporally coherent metrics.In:Proceedings of the 2015 IEEE Conference on Computer Vision(ICCV).Santiago,Chile:IEEE,2015.4086?4093 33 Metz L,Poole B,Pfau D,Sohl-Dickstein J.Unrolled generative adversarial networks.arXiv preprint arXiv:1611.02163,2016. 34 Springenberg J T.Unsupervised and semi-supervised learning with categorical generative adversarial networks.arXiv preprint arXiv:1511.06390,2015.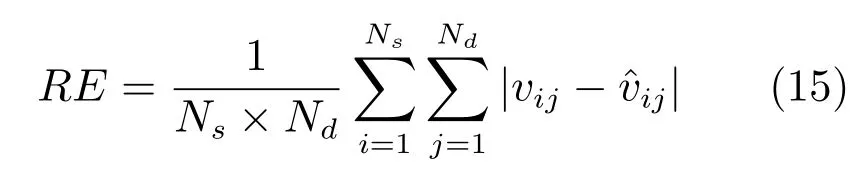
2.3 E-REGAN穩(wěn)定性分析
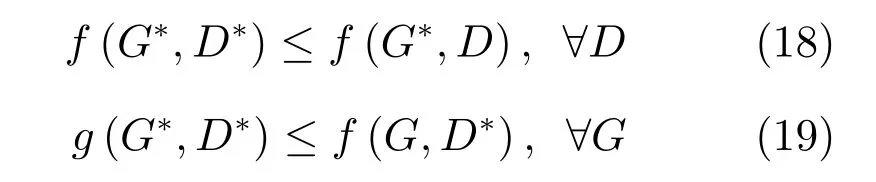
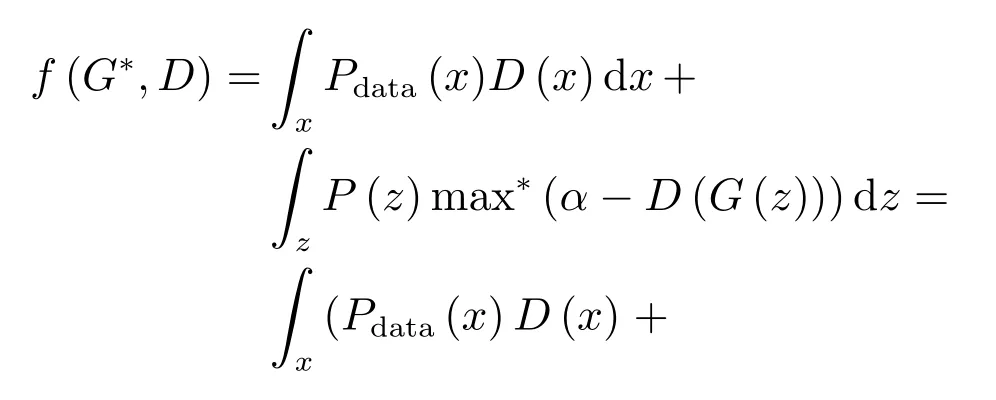
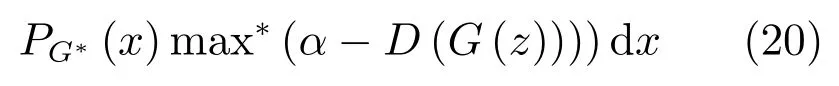
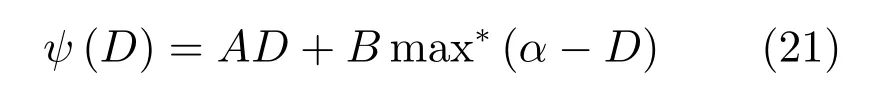

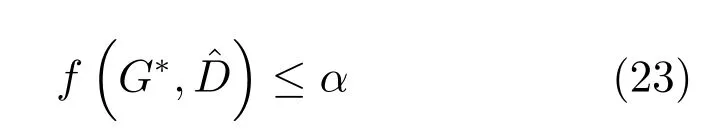
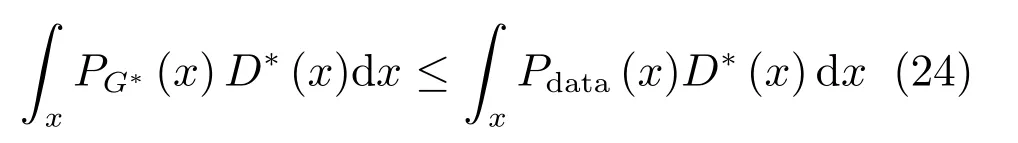
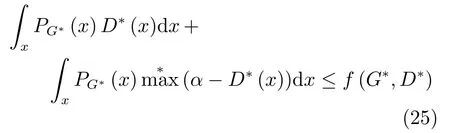
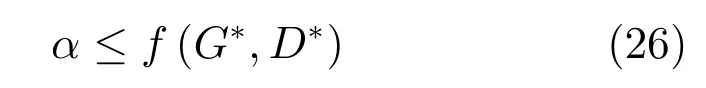
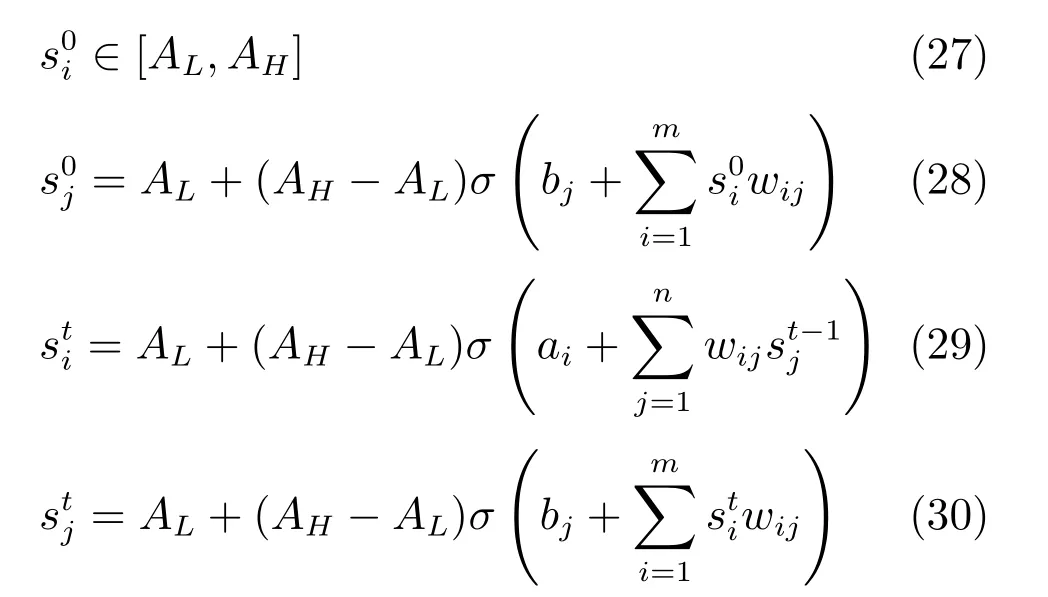

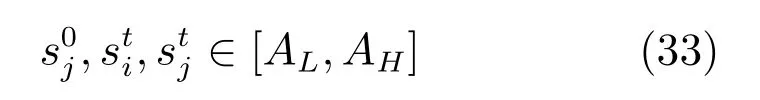
3 實(shí)驗(yàn)研究
3.1 MNIST數(shù)據(jù)集






3.2 CIFAR-10數(shù)據(jù)集




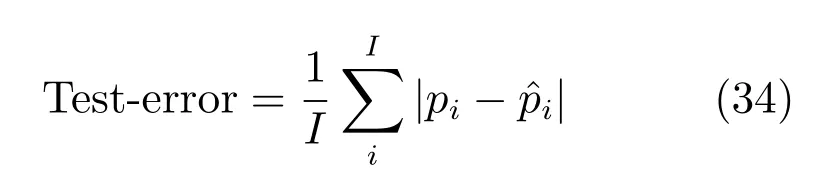
4 結(jié)束語

 猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年8期)2019-01-14 01:14:28藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年10期)2019-01-08 02:44:26藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年6期)2019-01-08 02:43:04藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年12期)2018-08-26 06:03:48光學(xué)精密工程(2016年6期)2016-11-07 09:07:19核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年8期)2019-01-14 01:14:28藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年10期)2019-01-08 02:44:26藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年6期)2019-01-08 02:43:04藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年12期)2018-08-26 06:03:48光學(xué)精密工程(2016年6期)2016-11-07 09:07:19核科學(xué)與工程(2015年4期)2015-09-26 11:59:03