基于生成對抗網絡的漫畫草稿圖簡化
2018-06-07 16:21:45盧倩雯陶青川趙婭琳劉蔓霄
自動化學報 2018年5期
關鍵詞:模型
盧倩雯 陶青川 趙婭琳 劉蔓霄
漫畫中的線條是構成整張圖的重要部分,如何合理的將草稿中凌亂的線條進行增減、組合,是計算機草圖簡化的關鍵.大多數漫畫家在繪制草稿時,主要目的是快速地在圖紙上確定畫面的整體結構、人物的大致形象和動作,這使得草稿圖上的線條更加凌亂與不確定.在草稿圖完成之后,漫畫家們需要在凌亂的草稿圖的基礎上,勾勒出線條準確、干凈的線稿圖.在這個過程中,隨著草稿圖的復雜度的增加,漫畫工作者的工作量也會成倍的提升,付出更多的時間和精力.因此,通過訓練好的神經網絡,自動合理地簡化潦草的線條,生成漫畫工作者們所需要的線稿圖,將大大提升漫畫繪制的工作效率,極大地減輕工作者的負擔.
在本文之前,已經出現了一些草稿簡化的算法以及基于深度學習的圖像處理算法[1?10].文獻[3?5]提出的草稿簡化算法,核心在于刪減掉畫面中多余的線條;文獻[6]提出的基于距離和拓撲理論合并線條的算法,文獻[7]提出的基于線條與線條間的多個幾何關系的約束的簡化算法,都是通過修改線條的形狀來達到草圖簡化的目的,文獻[8]利用訓練圖中的線條之間的幾何關系進行監(jiān)督線條聚類來獲得簡化圖;文獻[9]提出基于封閉感知的草圖簡化方法,通過語義分析線條之間產生的封閉區(qū)域,再對區(qū)域進行處理來達到簡化草圖的目的.草圖簡化最新的方法是Simo-Serra等[10]提出的基于卷積神經網絡的線稿圖生成方法,通過訓練卷積神經網絡內部的參數,學習標準草稿圖與線稿圖之間復雜的映射關系,模仿線稿圖的生成過程,使卷積神經網絡在輸入草圖后能生成對應的簡化圖,較以前的方法具有自主學習、輸入草圖大小不固定、簡化效果較以往方法更好的優(yōu)點,但要獲得較好的簡化效果,則需要人工調整輸入草圖的大小,并且對于線條過于凌亂的畫面,其簡化能力有限.Simo-Serra[10]的草圖簡化算法的實驗結果證實了卷積神經網絡能通過學習獲得較好的草圖簡化能力,在此基礎上,本文通過將生成對抗式的卷積神經網絡替換基本的卷積神經網絡,提升網絡模型的草圖簡化能力.在網絡搭建中,借鑒了Goodfellow在機器自主進行圖像生成學習的網絡構建上提出的一個新穎的理論—生成式對抗網絡(Generative adversarial networks,GAN)模型[11?12].該網絡由生成器和判別器組成,在迭代學習的過程中,生成器的目的是生成更加趨近于真實圖像的偽造圖,判別器的目的是正確區(qū)分生成器生成的偽造圖和真實圖像,二者在對抗中逐漸達到納什均衡,即判別器判斷偽造圖和真實圖,均有相等的可能性為真,且模型中的生成器已經具有優(yōu)秀的仿真能力.文獻[13?16]在原始GAN上進行改進的算法,其中,Mao等[16]在Goodfellow等[11]的基礎上,針對解決生成對抗網絡在迭代學習中的梯度消失等問題,提出了最小二乘生成式對抗網絡(Least squares generative adversarial networks,LSGAN).該方法通過改變生成器與判別器的誤差函數,使網絡整體更加穩(wěn)定,收斂更快速,具有更強大的無監(jiān)督圖像處理能力.
另一方面,條件隨機場(Conditional random field,CRF)作為無向圖模型,已經廣泛地被用于優(yōu)化圖像處理結果.文獻[17]引入分層的條件隨機場處理街景圖像的分割與物體分類問題,文獻[18]利用分層條件隨機場建立模型對人造圖和真實圖進行分類,文獻[19]使用全連接的條件隨機場優(yōu)化卷積網絡的語義分割結果.
本文將條件隨機場與最小二乘生成式對抗網絡理論相結合,提出了基于條件隨機場與最小二乘生成式對抗網絡的草圖簡化方法.網絡中的生成器和判別器均由卷積單元構成,因此,與卷積神經網絡相類似,生成器與判別器也能通過迭代學習,自動更新內部卷積核的參數,同時,在生成器的損失函數中,添加了條件隨機場的約束以提高生成模型的精度與網絡整體捕捉圖像細節(jié)的能力.本文網絡能通過學習數據集中草稿圖與線稿圖之間的映射以及線稿圖的特征,生成更加接近于真實線稿圖的簡化圖.本文的方法具有以下優(yōu)點:1)模型構建基于條件隨機場與最小二乘生成式對抗網絡,在損失函數中添加條件隨機場能夠增加偽造圖的生成約束,使網絡向生成理想的偽造圖的方向收斂更加迅速,且偽造圖中線條內和背景內像素的像素值相差更小,線條與背景交界處的像素點的像素值相差更大,有利于更快速的生成更加優(yōu)質的線稿圖,同時,能夠確保模型在通過學習后,能夠生成更加接近真實線稿圖的草稿簡化圖.2)訓練完成后,生成器可以獨立使用,本文模型對輸入的草稿圖的大小沒有要求,能夠自動生成與輸入圖相應圖片大小的優(yōu)秀簡化圖,不再需要判別器部分.3)本文首次將生成式對抗網絡與條件隨機場結合使用在草圖簡化工作上,將條件隨機場作為生成對抗網絡損失函數的一部分,加入了先驗知識,大大提升了網絡的收斂速度和簡化效果,具有一定的創(chuàng)新性.圖1是草圖和利用模型得到的對應簡化圖.
1 技術細節(jié)
1.1 網絡搭建

圖1 草稿圖和與之對應的模型結果圖Fig.1 Original sketches and output images of model
本文通過建立一個基于條件隨機場和最小二乘生成式對抗網絡的卷積網絡進行草圖的簡化學習.在學習的過程中,草圖經過生成器生成對應的偽造圖,再將生成的偽造圖和真實的線稿圖一起,輸入判別器進行分類.判別器的輸出代表對每張輸入圖片的真假判定,判定結果與標簽求誤差后,再根據梯度下降法對模型參數進行調整,達到模型自主學習的目的.模型的構建參考了Simo-Serra[10]搭建的卷積神經網絡和最小二乘生成式對抗網絡.其中,生成器模型內部包含了卷積層、平卷積層和上卷積層,分別具有不同的步長,在迭代學習中完成特征提取與圖像重構的工作.判別器模型包括卷積層和全連層,在迭代中學習準確地區(qū)分出標準線稿圖和生成器偽造圖.為了提高網絡整體的穩(wěn)定性,除了生成器的輸出卷積層和判別器的輸入卷積層,其他卷積層之后都添加歸一化處理層(Batch normalization)[20].為了加快模型的收斂速度,模型內使用卷積層代替了池化層.本文的草稿圖簡化模型如圖2所示,包括生成器模型和判別器模型.在訓練過程中,生成器模型學習生成與線稿圖像相似的偽造圖,判別器模型學習更準確地區(qū)分出偽造圖與標準線稿圖.模型將生成式對抗網絡與深度卷積網絡相結合,遵從文獻[15]提出的深度卷積生成式對抗網絡的構建約束:1)在判別網絡中使用步幅卷積層替代池化層,在生成網絡中使用微步幅卷積層;2)除了生成網絡的輸出卷積層和判別網絡的輸入卷積層,其他卷積層后都添加Batchnorm層;3)不使用任何全連接隱含層;4)生成網絡中,輸出層使用Tanh激活函數,其他層使用Relu激活函數;5)判別網絡中,所有層都使用Leakyrelu激活函數.
模型中的生成網絡在搭建中參考了Simo-Serra等[10]提出的卷積神經網絡.網絡內部包含了三種卷積層:步幅卷積層,平卷積層和微步幅卷積層.其中,步幅卷積層內卷積步幅為2,將輸出特征圖的大小減小為輸入特征圖大小的一半,確保生成網絡在學習中能夠獲得提取輸入草圖的從像素級特征到內容級特征的能力.同時,為了在一些特征級上提取更多特征圖,模型中加入了步幅為1的平卷積層.而為了使生成網絡的生成圖具有和輸入草圖相同的尺寸,模型中使用了步幅為1/2的微步幅卷積,使輸出圖片的大小為輸入圖片的兩倍.另外,為了增加生成網絡應對線條復雜程度更高的輸入圖,增加了模型中平卷積層的數量提高了對高層特征的提取能力.
草圖簡化模型的判別網絡,由卷積層與全連接層構成,具有提取輸入圖片特征以及根據提取特征圖對輸入圖像分類的能力.模型結構的細節(jié)如表1所示.1~25層為生成器內卷積層,26~36層為判別器內卷積層.除了生成器和判別器的輸出卷積單元和判別器的輸入卷積單元,每個卷積單元都添加了Batchnorm層和一個Relu層,在生成網絡的輸出層使用了Tanh激活函數.為了保持輸入圖片和輸出圖片的大小一致,每個卷積層都進行補零.在訓練完成后,生成器模型可以單獨使用,處理任何尺寸的圖片.
在模型中,Batch normalization在除了生成網絡的輸出卷積層和判別網絡的輸入卷積層之外的卷積層后使用,通過在每個Mini-batch中計算得到均值和方差后,將卷積層輸出信號進行規(guī)范化.Batch normalization的使用能夠增加模型的穩(wěn)定性,提高模型的收斂速度.

圖2 模型示意圖Fig.2 Schematic figure of model

表1 基于條件隨機場和最小二乘生成式對抗網絡的草圖簡化模型Table 1 Sketch simpli fication model based on the conditional random field and least squares generative adversarial networks
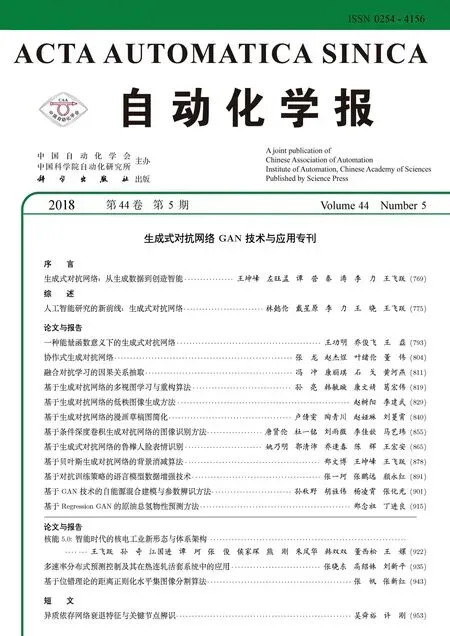
在生成網絡中,除了輸出卷積層,每個卷積單元都加入了Relu激活函數.
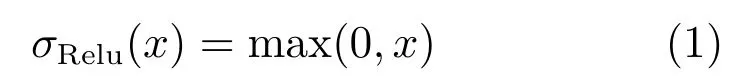
在判別網絡中,所有的卷積單元都加入了Leaky relu激活函數.
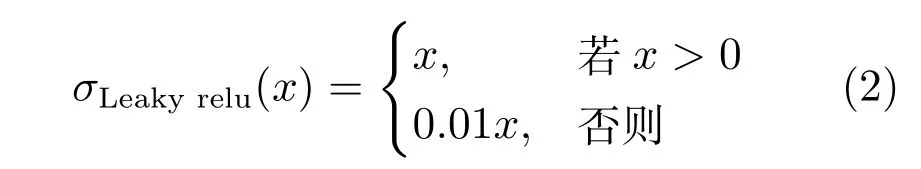
在生成器的輸出卷積層,添加了Tanh激活函數代替Relu激活函數,將生成器輸出歸一化至區(qū)間[?1,1].
1.2 網絡損失函數
在確定模型的損失時,引入Goodfellow等[11]提出的生成式對抗網絡的相關理論.為從標準數據x中學習生成器目標分布,生成式對抗網絡的輸入定義為pz(z),具有多層感知器功能的生成器定義為G(z;θg),其中θg為生成器內的參數,G(z)代表生成器輸出的偽造圖.具有分類功能的判別器定義為D(x;θd),其中,θd代表判別器內的參數.判別器的輸出D(x)代表對應的輸入被判定為真的比率.在訓練過程中,生成器學習更好的欺騙判別器的能力,使判別器對偽造圖的評分更高,即學習最小化log(D(x))+log(1?D(G(z))).同時,判別器通過學習,不斷提升區(qū)分偽造圖與真實圖的能力,使其對偽造圖的評分更低,真實圖的評分更高,即學習最大化log(D(x))+log(1?D(G(z))).生成器和判別器在博弈的過程如下所示:
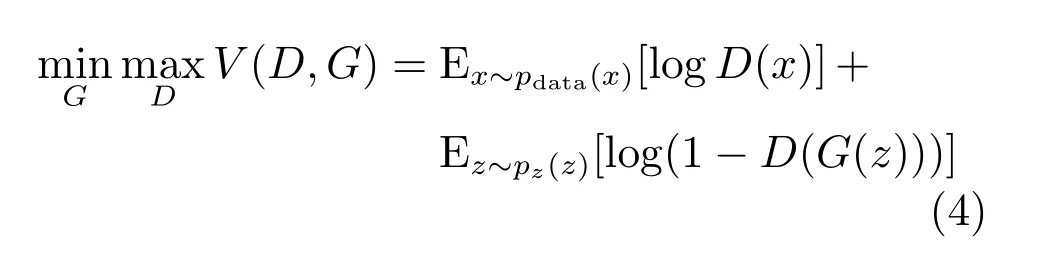
當生成器固定,V(D,G)形如函數y→alog(y)+blog(1?y),其中(a,b)∈R2{0,0},求導可得[0,1]區(qū)間上的最大值在點a/(a+b)處,即V(D,G)要獲得最大值必須滿足條件如下:
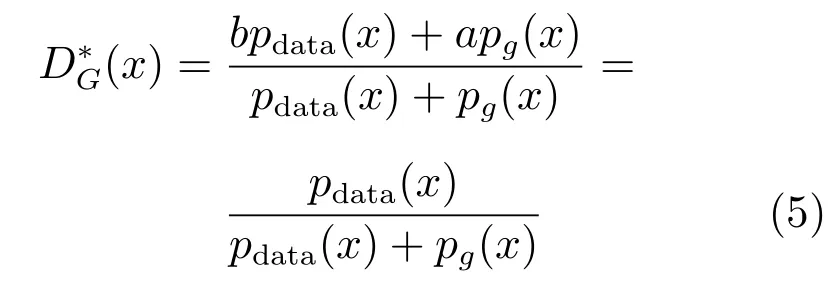
同時,為了使該網絡達到納什均衡,生成器需要在maxDV(G,D)取到最小值,函數表示如下:
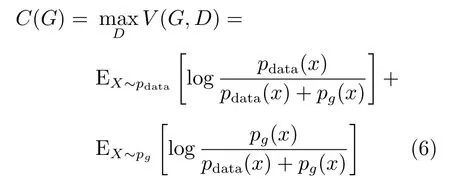
為了使pdata(x)=pg(x),此時C(G)取得最小值.
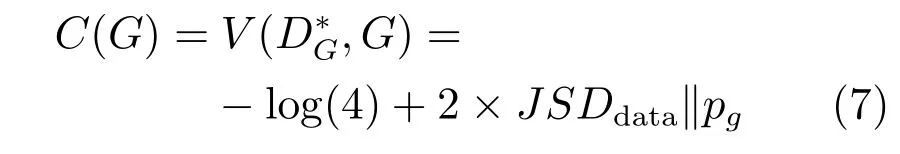
此時生成器生成的偽造圖與真實圖幾乎一致,香農散度為0,C(G)最終取得值為?log(4)的全局最小值.
需要注意,原始生成對抗網絡在訓練中,判別器的Sigmoid交叉熵損失只關注輸入的圖片是否被正確區(qū)分,對于偽造圖分類正確的情況不進行懲罰,使得該損失函數能提供的損失誤差較小,容易在學習時產生梯度消失的情況.文獻[16]在Goodfellow[11]的基礎上提出的最小二乘生成式對抗網絡,優(yōu)化了生成器和判別器的損失函數.
生成器損失函數如下:
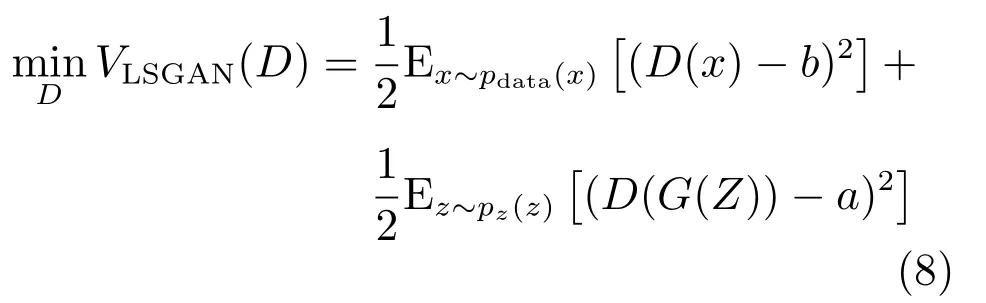
判別器損失函數如下:
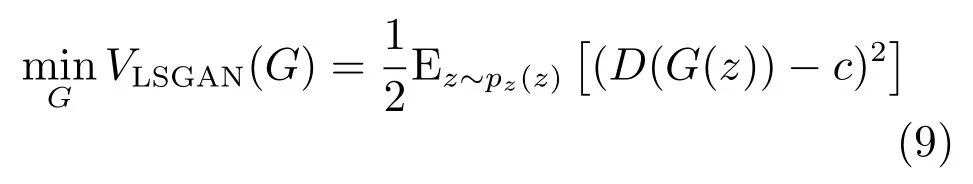
其中,設定a=0,b=c=1,且a,b,c分別代表偽造圖的標簽、真實圖的標簽和生成器期望判別器對偽造圖判定的標簽.與原始的生成式對抗網絡一致,在pdata(x)=pg(x)時,達到網絡內部的納什均衡.
為了進一步優(yōu)化對抗網絡的精度,本文在最小二乘生成式對抗網絡的損失函數的基礎上,在生成器模型中添加了條件隨機場的能量函數作為損失函數的一部分.通過生成器的仿造圖中像素點與其四鄰域點之間的關系約束,在迭代學習中不需要進行人為的干預,網絡整體能夠自主地向像素間能量更低、更穩(wěn)定的方向收斂,生成更加符合要求的仿造圖.
在本文的模型中,生成器和判別器分別具有不同的損失函數.生成器的損失函數主要包括內容損失、對抗損失和條件隨機場能量損失.內容損失計算生成器生成圖與對應標準線稿圖的逐像素均方誤差,在學習中保證生成圖與對應線稿圖的像素分布相似.對抗損失計算判別器對偽造圖判定的標簽與真實圖標簽的誤差,確保生成網絡在學習中增加欺騙判別網絡的能力.另外,圖像中的每個像素點的灰度值,都與其領域內的其他點存在相關關系.同為背景點,線條內部點之間像素值相差很小,線條邊緣點像素值則相差較大.因此,本文參考文獻[19]的算法,利用條件隨機場的能量損失對偽造圖像素點與其四鄰域像素點之間的關系進行約束,使簡化網絡在收斂的過程中,學習增加像素標簽不同的偽造圖像素點之間的灰度差,減小像素標簽相同的像素點之間的灰度差,使生成的偽造圖邊緣對比更加明顯、背景與線條的顏色更加穩(wěn)定.
生成網絡的總誤差定義如下:
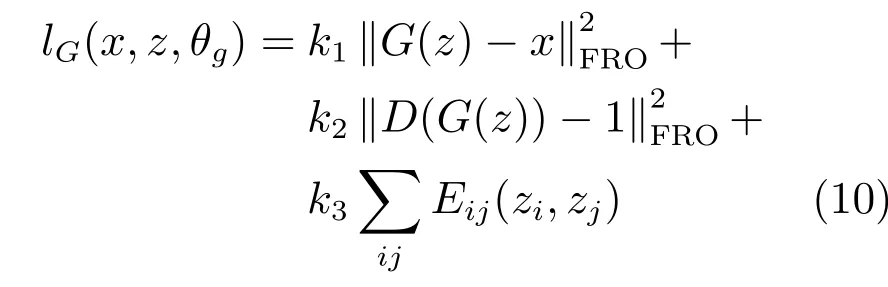
其中,代表Frobenius范數,系數計算如下:
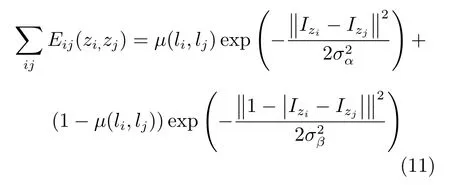
其中,zi,zj分別代表在生成器偽造圖內選取的像素點和像素點的四鄰域點,li,lj代表像素點和四鄰域點對應的像素標簽.像素的像素標簽由生成器偽造圖對應的標準線稿圖上對應的像素點的位置決定,本文規(guī)定標準圖內位于背景的像素點的像素標簽為1,位于線條的像素點的像素標簽為0,且當li=lj時,μ(li,lj)=0,否則μ(li,lj)=1.Izi,Izj分別代表zi,zj像素點的灰度值.經過驗證圖集驗證,參數σα和σβ通常取值為1.
判別網絡作為分類器,目的是學習正確地對生成器偽造圖與真實圖進行區(qū)分.判別器的損失函數由最小二乘生成式對抗網絡誤差函數定義如下:
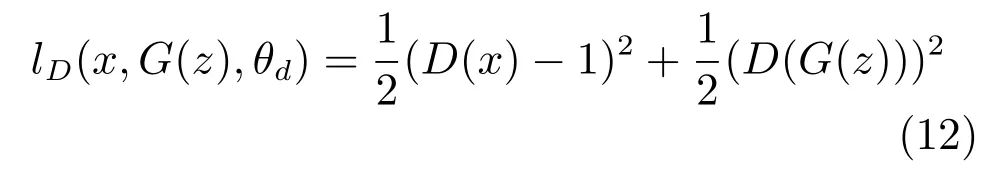
利用最小二乘的損失函數,使網絡的損失函數在判別器分類錯誤的情況下提供學習誤差,在判別器分類正確的情況下,仍然可以對遠離決策邊界的點進行懲罰,并將它們拉向決策邊界.使判別器具有更強的辨別能力,能夠對生成器學習提供更多貢獻,避免了模型崩潰情況的出現,大大提高了網絡的圖像處理精度.
本文網絡的損失函數中未添加文獻[10]中使用的Lossmap.添加Lossmap雖有利于加速網絡收斂速度,且使網絡在學習的過程中不因注重于較粗的線條而忽略較細的線條,但增加Lossmap進行訓練的網絡在訓練完成之后有個明顯的缺陷:在處理較粗的線條時,網絡的生成圖更傾向于將組線條分離成兩個獨立的線條,或出現線條消失的情況,如圖3所示.為避免上述情況出現,本文網絡使用CRF代替Lossmap加速網絡的收斂.
2 實驗結果及分析
2.1 數據集構成
本文構建了由240對在紙和手繪板上完成的草圖與線稿圖組成的原始大圖數據集.數據集中的原始大圖分辨率不一致,但所有圖片都大于500像素×500像素.在實驗中,為了使本文中構建的草圖簡化網絡具有更好的簡化能力,原始的圖片數據集被分成訓練圖集、驗證圖集和測試圖集三部分.
訓練圖集中的大圖在經過變換截取后獲得了1000張以上,大小均為128像素×128像素的成對的小圖,作為簡化模型在訓練時的輸入與標準圖.這些訓練圖中的小圖對是通過從原始大圖對數據集中抽取部分圖片后,經過旋轉隨機角度,隨機地選取坐標截取獲得,如圖4所示.同時,為了增加模型的穩(wěn)定性,針對紙質草圖在掃描后產生的畫面變臟、畫質更低、噪聲點更多等問題,本文將圖片對中的草稿圖使用Adobe photoshop隨機進行了4種變換:質感變化,圖像模糊,增加圖像噪聲,增加斑點.在圖5中列舉出了本文中一部分用于訓練簡化模型的數據集圖片,分類為動植物、建筑與場景、日漫風格漫畫形象和迪士尼風格漫畫形象,且一部分在實際訓練前進行了加噪處理.此外,在構建訓練圖集之前,由于紙質漫畫與電腦繪制的漫畫在線條上存在區(qū)別,如圖6所示,在兩幅圖中,由圖形板描繪的草圖更凌亂,且使用文獻[10]中提供的模型更難清理干凈.而由于越來越多的漫畫家和插圖師選擇使用手繪板作圖,在進行網絡訓練之前,本文收集了一些由手繪板在電腦上進行繪制的圖片對,加入到網絡訓練中,增強模型應對復雜情況時的草圖簡化能力.驗證圖集包含400對大小為128像素×128像素的圖片,主要用于在模型訓練時,通過驗證模型訓練圖對中的草稿圖的簡化效果確定模型的超參數.同時,本文構建了圖片對數量為400、大小為128像素×128像素的測試圖集,使用于測試已訓練好的模型的草圖簡化能力,通過與最新的草圖簡化算法的輸出結果對比,證明本文提供的草圖簡化模型確實具有更優(yōu)秀的簡化能力.需要注意的是,驗證圖集和測試圖集不參與模型內部的參數更新.
2.2 訓練過程

圖3 本文網絡輸出圖與使用了Lossmap的Simo-Serra[10]的結果圖對比Fig.3 The comparison of our model outputs and results from Simo-Serra algorithm[10]with the usage of lossmaps
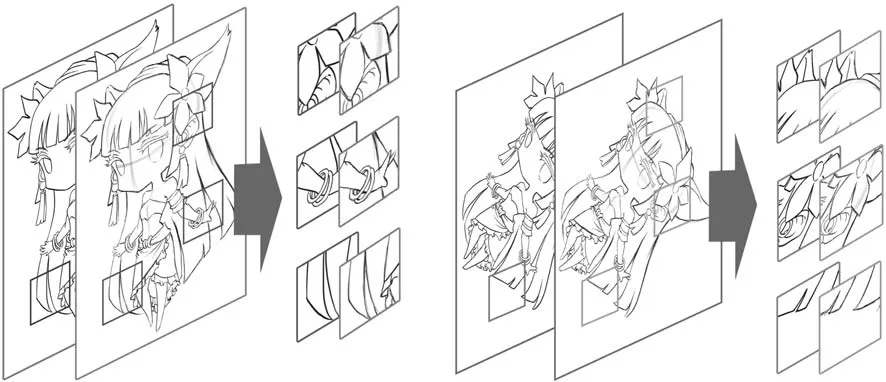
圖4 在大圖中截取用于訓練的小圖示意Fig.4 Extracting small images from the original images for training
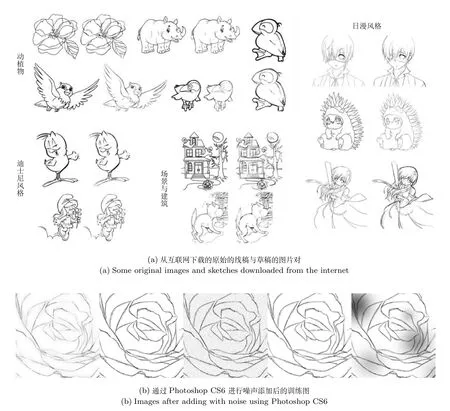
圖5 圖片集構成Fig.5 Images dataset construction
在實驗中,本文使用了卷積生成式對抗網絡[11]、最小二乘生成式對抗網絡和添加條件隨機場能量損失的最小二乘生成式對抗網絡[16]三種方法進行對比訓練.同時,還將本文算法和未添加條件隨機場能量函數的最小二乘生成式對抗網絡與全連接條件隨機場優(yōu)化相結合的算法進行了對比.
卷積生成式對抗網絡、最小二乘生成式對抗網絡和本文網絡的損失函數值隨迭代次數的變化如圖7所示.從圖7可以看出,本文提供的網絡具有最快的收斂速度,且最快達到較平穩(wěn)的狀態(tài).在訓練的過程中,卷積生成式對抗網絡無法經過訓練學習復雜的草圖簡化,由于判別器起初不具有正確分類的能力,并且當Sigmoid交叉熵作為損失函數時,只關注模型是否正確分類而不關心偏離正確分類的程度,使得判別模型對標準圖和偽造圖持續(xù)判為錯,Fake loss持續(xù)為0,失去一部分對生成器提供殘差的能力,最終訓練失敗.在最小二乘生成式對抗網絡與添加條件隨機場能量損失的最小二乘生成式對抗網絡的對比中,可以看到添加條件隨機場能量損失的最小二乘生成式對抗網絡中的生成器具有最快的收斂效果.網絡整體在迭代次數5000時,生成器與判別器誤差都已趨于穩(wěn)定,已經具有較好的生成偽造圖的能力,判別器也能夠持續(xù)為生成器提供穩(wěn)定的殘差,有助于判別器與生成器內部的參數微調.學習過程中,三個網絡的輸出圖片隨迭代次數變化的對比如圖8所示.從圖8可以看出,本文添加了條件隨機場能量函數的網絡明顯較未添加的網絡具有明顯的收斂速度更快、生成圖更清晰、更貼近標準線稿圖的優(yōu)勢,同時體現了條件隨機場能量函數對于提升簡化效果的重要性.
為了對比文獻[19]提出的先通過卷積神經網絡(Convolutional neural network,CNN)分類,再經過條件隨機場進行迭代優(yōu)化分類結果的方法,本文將相同迭代次數下未添加條件隨機場的最小二乘生成式對抗網絡生成圖再經過條件隨機場優(yōu)化的結果圖與添加了條件隨機場能量方程的最小二乘生成式對抗網絡的結果圖進行了對比實驗.由于未添加在模型內部的條件隨機場優(yōu)化不能使用網絡生成圖相應的標準線稿圖進行參數的訓練,因此不能使用與本文添加在網絡內部的條件隨機場能量方程一致的能量函數,本文利用與文獻[19]一致的全連接條件隨機場能量方程,如下:
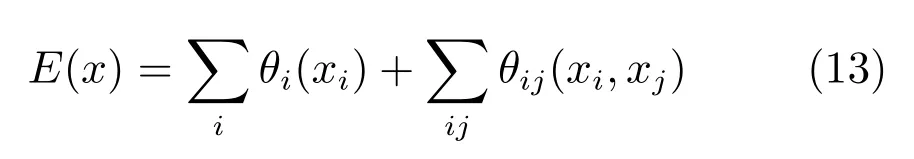
其中,x為輸入圖中的像素,P(xi)為CNN網絡輸出的標簽分類概率,當時,μ(xi,xj)=1,否則μ(xi,xj)=0.km代表基于像素點i與像素點j的特征f且權值為ωm的高斯核,其公式如下:


圖7 三網絡損失函數變化圖Fig.7 Curve of loss functions changing with iterations
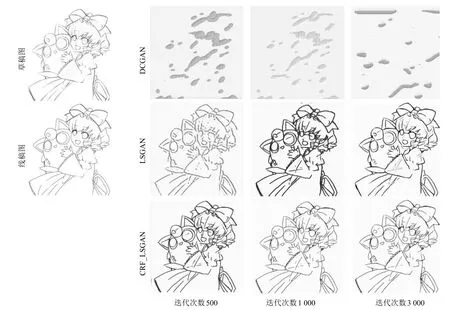
圖8 三個網絡的輸出圖隨迭代次數變化對比Fig.8 Outputs of three models changing with iterations
在實驗中,為了獲得較好的二分類效果,參數設置為ω1=10,ω2=0,σα=60,σβ=20,σγ=3.
本文分別選用了迭代了5000次的添加了條件隨機場的最小二乘生成式對抗網絡的生成圖和未添加條件隨機場的最小二乘生成式對抗網絡的生成圖,再經過全連接的條件隨機場迭代10次后的結果圖進行了對比,如圖9所示.需要注意,條件隨機場迭代10次以上,結果圖幾乎不再有改變.根據圖片顯示,由于缺少條件隨機場能量方程對內部的參數訓練提供的有力的幫助,未添加條件隨機場的網絡在同等迭代次數的情況下,學習效果遠不如添加了條件隨機場約束的網絡.并且,雖然通過全連接的條件隨機場迭代優(yōu)化,網絡的生成圖邊緣確實較之前分界明顯,但是遠不足以改善生成圖的整體情況,仍然存在大面積黑塊、細節(jié)缺失等情況,生成圖質量較差.另外,由于條件隨機場添加在外部,則即使在網絡訓練好后,每次輸入圖片都需要進行額外的迭代優(yōu)化的步驟,比本文網絡更加耗時,效率較低.

圖9 本文網絡輸出圖、最小二乘生成式對抗網絡輸出圖、最小二乘生成式對抗網絡與全連接條件隨機場優(yōu)化結合的輸出圖對比Fig.9 The comparison of outputs from our model,LSGAN model and the model combined with LSGAN and CRF
本文網絡在學習的過程中,生成網絡的參數θg更新,通過計算生成網絡誤差lG(x,z,θg)與θgt的一階導數實現,如下:
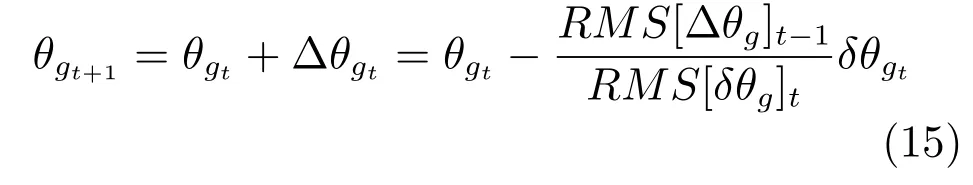
其中,?θgt為參數θg的更新量,δθgt代表參數在迭代t次時的梯度.
判別網絡也利用了梯度下降法更新網絡內參數θd,為了獲得誤差函數lD(x,G(z),θd)的最小值,參數的更新方法如下:
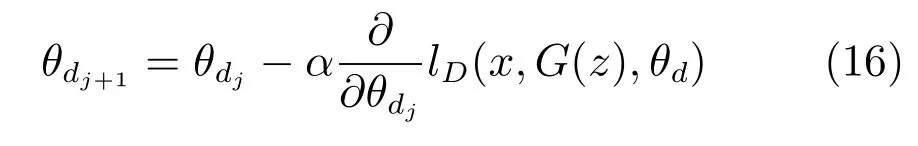
其中,α表示判別網絡的參數更新速率.
2.3 生成圖向量化
本文提供的網絡通過訓練事實上已經能夠生成逼真的草稿簡化圖,但由于圖像線條的邊緣在像素級別上仍然具有不夠圓滑、邊界對比不夠強烈的問題,這些問題雖不影響美觀,但對繪畫工作者后續(xù)的上色工作將產生一定的影響.因此,本文使用Potrace software[21]對網絡生成圖進行向量化,使用其默認值,并且在向量化過程中不需要人為干預.在圖10中展示了向量化的輸入與輸出結果.需要注意,文獻[10]已經證明直接對草稿圖進行向量化不能得到較好的簡化結果.
2.4 實驗結果
通過學習現有的簡化草圖方法并結合對LSGAN模型的分析,經過大量實驗,證明與目前最新的Simo-Serra等提出的方法[10]相比,本文提供的生成對抗網絡模型更適合于簡化草圖.實驗中,搭建模型使用Python3.5和Tensor flow 1.1.0,并在GPU為Nvidia gtx980ti的Windows平臺上訓練4周.需要注意,模型輸入不需要任何預處理,并且在訓練完成后,生成網絡可以輸入任意大小的草圖,如圖11所示,其中生成圖2均為以原始大小的左側草圖為輸入圖獲得的網絡生成圖,生成圖1為以擴展為原始長寬的2倍的草圖為輸入圖獲得的網絡生成圖,生成圖3為以縮減為原始長寬的1/2倍的草圖為輸入圖獲得的網絡生成圖.從圖11可以看出,當輸入圖尺寸較大時,結果圖獲得的細節(jié)相對較多,輸入圖尺寸較小時,結果圖相對簡化,但輸入草圖無論如何變化大小,本文提供的簡化算法都能得到相應優(yōu)秀的簡化圖,可直接被繪畫工作者使用.利用本文提供的測試圖集,基于條件隨機場與最小二乘生成式對抗網絡的草圖簡化模型的輸出圖和原始草稿圖的對比如圖12所示.從圖12可以看出,在各種內容、風格、繪制方式的草圖輸入下,本文網絡均能獲得較好的簡化結果.另外,在GPU為Nvidia gtx980ti的Windows平臺上,草圖簡化模型在訓練完成后,生成器網絡生成簡化圖所需時間如表2所示.

圖10 模型輸出與向量化結果圖對比Fig.10 Comparison between output of our model and image after vectorization

圖11 多尺寸草圖獲得的算法生成圖對比Fig.11 The comparison of output images obtained by different sizes of imput images
2.5 對比現有技術
本文在算法驗證階段使用了測試圖集,并且利用了宏查全率、宏查準率以及相應的宏F1的相關原理,對本文算法的簡化圖與Simo-Serra[10]提供的例子的簡化結果做了詳細的計算與對比分析,通過結果驗證,本文的簡化模型與最新的草圖簡化模型相比,確實具有更加優(yōu)秀的草圖簡化能力.

圖12 不同草圖與本文模型對應的生成圖Fig.12 Fake images generated by our generator using different sketches
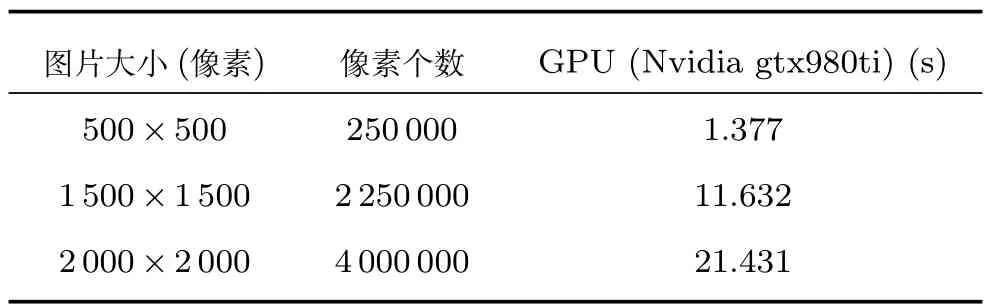
表2 生成器網絡生成簡化圖所需時間Table 2 Time needed for generating a simpli fied image by the generator
在二分類問題中,查全率與查準率常用來共同衡量一個模型的輸出結果.其中,可將樣本根據其真實的類別與分類器預測的類別的組合劃分成真正例(TP)、假正例(FP)、真反例(TN)、假反例(FN)四種情況.
查全率(P)和查準率(R)定義如下:
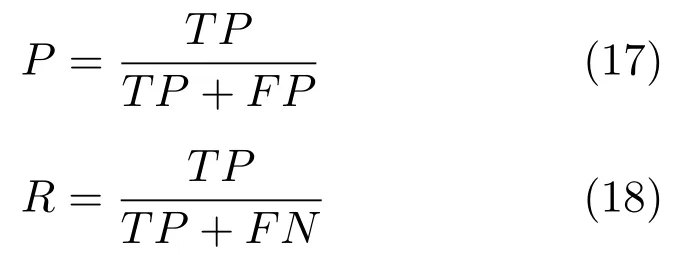
F1為查全率和查準率的加權調和平均.但在有多個混淆矩陣的情況下,常常使用宏查全率和宏查準率來計算得出相應的宏F1,以代替F1.宏查全率、宏查準率和宏F1的公式下:
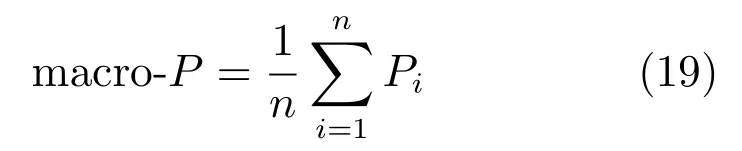

本文中的簡化模型也可以看成一個二分類的分類器,規(guī)定標測試集圖片對中的每張標準線稿圖的所有像素點分別為每次計算時的總樣本,其中線條部分的像素點是實際為“真”的樣本,背景的像素點則是實際為“假”的樣本.同時,在對應的輸出簡化圖中,規(guī)定線條部分的像素點是分類器預測為“真”的樣本,而背景部分的像素點則是分類器預測為“假”的樣本.同理,例子的結果也可以作為Simo-Serra[10]草圖簡化模型的分類結果.
測試的過程中,將測試圖集中的草稿圖輸入本文的簡化網絡,得到本文算法的結果圖,同時,將同樣的草稿圖輸入Simo-Serra[10]的例子中,獲得Simo-Serra[10]算法的結果圖.上述步驟完成之后,再利用測試圖集中的標準線稿圖和查全率和查準率的公式獲得對比測試結果,如表3.需要注意,由于經過卷積神經網絡后輸出圖中的線條會有些許像素位移,不能對標準圖和兩個對比圖進行像素間的一一對應判定,而應該對計算設置一定的范圍.為確定相對合理的范圍,本文對范圍的變化對測試的結果macro-F1與macro-F1s的影響進行了實驗,結果如圖13所示.本文算法結果圖的測試結果macro-F1與Simo-Serra[10]算法結果圖的測試結果macro-F1s在范圍增大時,均能獲得穩(wěn)定提升.另外,在范圍為3像素×3像素時,macro-F1與macro-F1s達到最大的差值,在小于該范圍時,由于網絡輸出的像素位移對二者均有顯著影響,二者結果下降的同時,差值也相對下降,而在大于該范圍時,二者由于容忍條件的放寬,測試結果的可信程度相對降低,雖然二者的結果均有提升且差異減小,但過大的范圍獲得的測試結果已經不具有實際意義.最后,本文選擇將范圍為5像素×5像素時的macro-F1與macro-F1s的數值作為對比測試的結果.需要注意,范圍變化的過程中,macro-F1始終大于macro-F1s,因此,測試證明了本文提供的基于條件隨機場與最小二乘生成式對抗網絡的草圖簡化模型確實優(yōu)于最新的、由Simo-Serra等[10]提出的基于卷積神經網絡的草圖簡化模型.另外,在輸入同一內容和大小的草稿圖的情況下,本文算法得到的結果圖與文獻[9?10]得到的結果圖對比如圖14所示.從圖14可以看出,本文提供的算法確實具有比最新的算法[9?10]更好的草圖簡化能力,輸入相同草圖得到的簡化結果圖細節(jié)更加的豐富,畫面中的線條雖有粗細的變化,但既體現了作者對線條的強調或忽略的作畫意圖,也保持了線條的粗細均勻,具有很強的實用性.

表3 利用測試集獲得的Simo-Serra[10]簡化模型輸出圖和本文簡化模型輸出圖的宏查全率、宏查準率和宏F1的測試結果Table 3 Test results of macro-R,macro-P and macro-F1 of output images of Simo-Serra[10]simpli fication model and output images of our model using test dataset
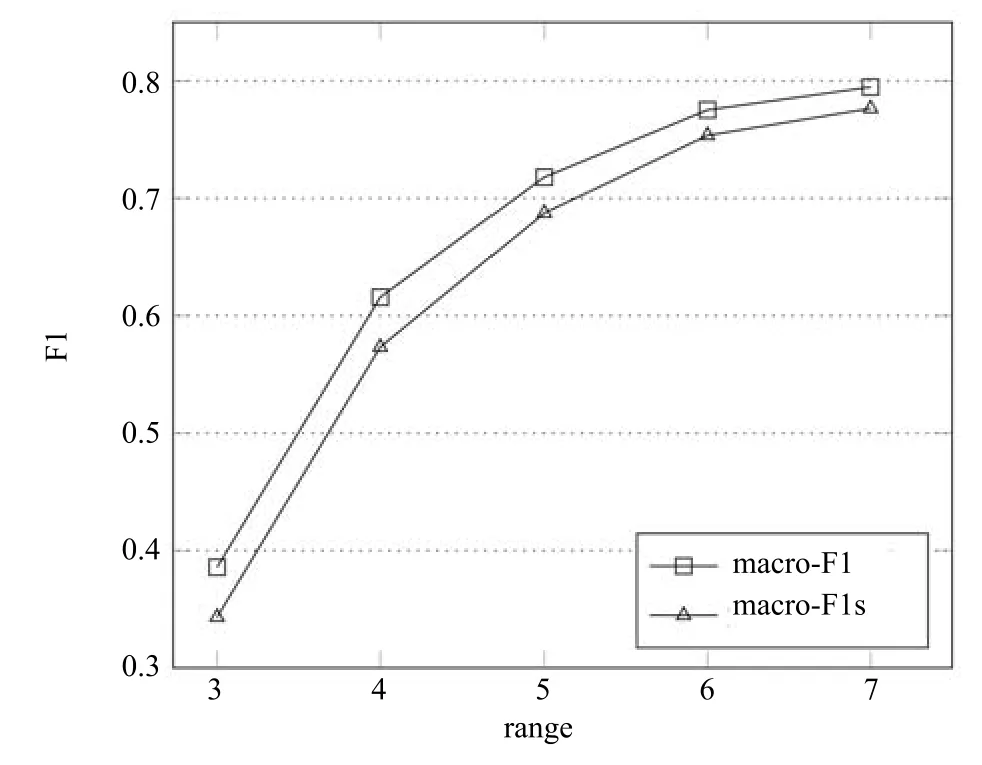
圖13 macro-F1與macro-F1s對比圖Fig.13 Experiment on the in fluence of range change on macro-F1 and macro-F1s

圖14 本文算法與其他算法的兩組對比圖Fig.14 Compared with outputs of the latest algorithms
2.6 局限性
本文中的基于條件隨機場與最小二乘生成式對抗網絡的草圖簡化模型由于包含生成網絡和判別網絡兩個部分,擁有更多的隱含層和更高的復雜度,導致訓練草圖簡化網絡的過程更耗時.此外,模型生成圖像的質量取決于訓練數據的質量和數量,這與由卷積層構建的其他模型相同,原因在于由于模型內部參數較多,不充足的訓練數據更容易使模型過擬合,得不到較好的實驗效果.但在提供更多的高質量的訓練圖像以及迭代次數充足的情況下,能夠盡量避免過擬合導致的訓練失敗,同時,基于條件隨機場與最小二乘生成式對抗網絡的草圖簡化模型能夠為圖形藝術家提供更優(yōu)秀的草稿簡化圖.
3 結論
本文提出了一種基于條件隨機場和最小二乘生成式對抗網絡(LSGAN)的新穎草圖簡化方法,并能獲得更高質量的草圖簡化圖.同時,構建了新的數據集,其中包含在真實紙張和數碼手繪板上繪制的草稿圖與其對應的干凈線稿圖.此外,草圖簡化模型使用GPU進行訓練,并且計劃收集更多的圖像對,使模型在后續(xù)的訓練中生成更好的簡化圖像.
1 Sun Xu,Li Xiao-Guang,Li Jia-Feng,Zhuo Li.Review on deep learning based image super-resolution restoration algorithms.Acta Automatica Sinica,2017,43(5):697?709(孫旭,李曉光,李嘉鋒,卓力.基于深度學習的圖像超分辨率復原研究進展.自動化學報,2017,43(5):697?709)
2 Zhang Hui,Wang Kun-Feng,Wang Fei-Yue.Advances and perspectives on applications of deep learning in visual object detectionActa Automatica Sinica,2017,43(8):1289?1305(張慧,王坤峰,王飛躍.深度學習在目標視覺檢測中的應用進展與展望.自動化學報,2017,43(8):1289?1305)
3 Wilson B,Ma K L.Rendering complexity in computergenerated pen-and-ink illustrations.In:Proceedings of the 3rd International Symposium on Non-Photorealistic Animation and Rendering.New York,NY,USA:ACM,2004.129?137
4 Grabli S,Durand F,Sillion F X.Density measure for linedrawing simpli fication.In:Proceedings of the 12th Paci fic Conference on Computer Graphics and Applications.Seoul,South Korea:IEEE,2004.309?318
5 Cole F,DeCarlo D,Finkelstein A,Kin K,Morley K,Santella A.Directing gaze in 3D models with stylized focus.In:Proceedings of the 17th Eurographics Conference on Rendering Techniques.Nicosia,Cyprus:ACM,2006.377?387
6 Grimm C,Joshi P.Just Drawit: a 3D sketching system.In:Proceedings of the 2012 International Symposium on Sketch-Based Interfaces and Modeling.Annecy,France:ACM,2012.121?130
7 Fi?er J,Asente P,Sykora D.ShipShape:a drawing beauti fication assistant.In:Proceedings of the 2015 Workshop on Sketch-Based Interfaces and Modeling.Istanbul,Turkey:ACM,2015.49?57
8 Orbay G,Kara L B.Beauti fication of design sketches using trainable stroke clustering and curve fitting.IEEE Transactions on Visualization and Computer Graphics,2011,17(5):694?708
9 Liu X T,Wong T T,Heng P A.Closure-aware sketch simpli fication.ACM Transactions on Graphics(TOG),2015,34(6):Article No.168
10 Simo-Serra E,Iizuka S,Sasaki K,Ishikawa H.Learning to simplify:fully convolutional networks for rough sketch cleanupACM Transactions on Graphics(TOG),2016,35(4):Article No.121
11 Goodfellow I J,Pouget-Abadie J,Mirza M,Xu B,Warde-Farley D,Ozair S,et al.Generative adversarial networks.In:Proceedings of the 2014 Advances in Neural Information Processing Systems(NIPS).Montreal,Canada:Curran Associates,Inc.,2014.2672?2680
12 Wang Kun-Feng,Gou Chao,Duan Yan-Jie,Lin Yi-Lun,Zheng Xin-Hu,Wang Fei-Yue.Generative adversarial networks:the state of the art and beyond.Acta Automatica Sinica,2017,43(3):321?332(王坤峰,茍超,段艷杰,林懿倫,鄭心湖,王飛躍.生成式對抗網絡GAN的研究進展與展望.自動化學報,2017,43(3):321?332)
13 Qi G J.Loss-sensitive generative adversarial networks on Lipschitz densities.ArXiv:1701.06264,2017.
14 Arjovsky M,Chintala S,Bottou L.Wasserstein GAN.ArXiv:1701.07875,2017.
15 Radford A,Metz L,Chintala S.Unsupervised representation learning with deep convolutional generative adversarial networks.In:Proceedings of the 2015 International Conference on Learning Representations(ICLR).San Diego,CA,USA:ICLR,2015.
16 Mao X D,Li Q,Xie H R,Lau R Y K,Wang Z,Smolley S P.Least squares generative adversarial networks.In:Proceedings of the 2017 IEEE International Conference on Computer Vision.Venice,Italy:IEEE,2017.2813?2821
17 Huang Q X,Han M,Wu B,Ioffe S.A hierarchical conditional random field model for labeling and segmenting images of street scenes.In:Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition.Colorado Springs,CO,USA:IEEE,2011.1953?1960
18 Yang M Y,F?rstner W.A hierarchical conditional random field model for labeling and classifying images of man-made scenes.In:Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops.Barcelona,Spain:IEEE,2011.196?203
19 Chen L C,Papandreou G,Kokkinos I,Murphy K,Yuille A L.DeepLab:semantic image segmentation with deep convolutional nets,atrous convolution,and fully connected CRFs.IEEE Transactions on Pattern Analysis and Machine Intelligence,2018,40(4):834?848
20 Ioffe S,Szegedy C.Batch normalization:accelerating deep network training by reducing internal covariate shift.In:Proceedings of the 32nd International Conference on Machine Learning.Lille,France:PMLR,2015.
21 Selinger P.Potrace:a polygon-based tracing algorithm[Online],available:http://potrace.sourceforge.net/potrace.pdf,May 10,2017
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19