大數據平臺下的電力負荷預測系統設計與實現
2018-06-12 02:53:26鄭凱文
自動化儀表 2018年6期
關鍵詞:模型
夏 博,楊 超,鄭凱文
(貴州大學電氣工程學院,貴州 貴陽 550025)
0 引言
隨著常規電力系統向智能電網的逐步發展,電力系統中使用了大量的傳感器和智能設備,使得需要處理的各類數據呈指數級增長。數據存儲規模將增長到TB級,甚至PB級[1]。而電力系統負荷預測的誤差大小直接影響發供電計劃的制定、電網的供需平衡以及電力市場的平穩運行[2-3]。現有的預測方法中,數據挖掘法[4]、小波分析法[5]、近似熵法[6]等都具有較好的預測精度,但是在處理海量數據方面還存在很大的不足。文獻[7]提出了調和分類-聚類的負荷預測模型,能夠較好地對大量數據進行分析處理并且提高預測的精度。文獻[8]提出了適用于智能電網大數據環境下的預測方法,能夠有效提高負荷預測的速度與精度。文獻[9]分析了電力大數據的相關特征,介紹了正在研發的智能電網大數據分析系統。
針對上述問題,本文提出了基于Gradient Boosting思想和Shrinkage思想的Xgboost算法負荷預測模型,并通過負荷預測試驗分析驗證了該算法的有效性。
1 極端梯度上升算法
Xgboost是基于梯度提升決策樹(gradient boosting decision tree,GBDT)提出的算法[10]。Xgboost可以使用CPU多線程進行并行計算,并對目標函數進行二階泰勒展開,在目標函數之外加入正則項整體求最優解。
對于一個給定預測模型,需要通過目標函數來尋找最優參數。一般的目標函數模型為:
Obj(θ)=L(θ)+Ω(θ)
(1)
式中:L(θ)為誤差函數,表示模型擬合數據的程度;Ω(θ)為正則化項,表示懲罰復雜的模型。
為了防止過擬合,Xgboost除了目標函數正則化項,還引入了用于GBDT的縮減和用于隨機森林(random forest,RF)的列抽樣,以防止過擬合。其中,縮減認為殘差仍然是其學習目標,而且各個樹的殘差是漸變的;而列抽樣則是對樣本的特征量進行隨機抽樣計算,從而減少了工作量。
分類回歸樹中的回歸樹是提升樹最基本的組成部分,但是單棵決策樹往往不能有效而精確地作出預測。而由多棵決策樹組成的決策樹森林模型是一個有效而精準的模型。決策樹森林模型公式為:
(2)
式中:F為所有回歸樹集合;f為一個在函數空間F里的一個函數;xi為數據i的特征向量。
目標函數需要遵循的主要原則為:
(3)

參數采用加和策略的方式來訓練,通常面對不是平方誤差的時候,可以使用泰勒展開來定義一個近似的目標函數,并對這一步計算進行簡化,即除去常數項,進而會發現目標函數僅僅取決于每個數據點在誤差函數上的一階導數和二階導數。簡化后目標函數為:
(4)
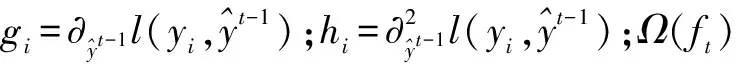
(5)

(6)

Xgboost單棵決策樹訓練流程如圖1所示。
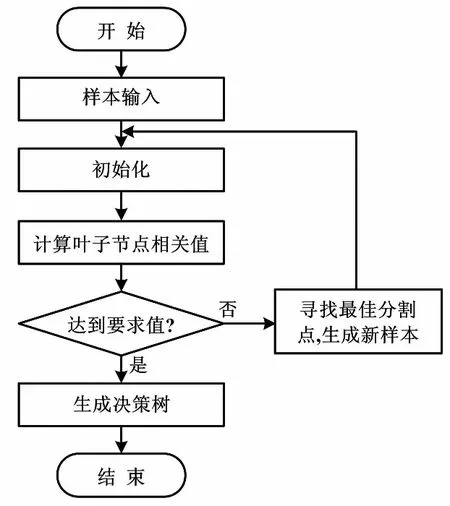
圖1 單棵決策樹訓練流程圖Fig.1 Training flowchart of single decision tree
整個Xgboost算法決策樹迭代流程如圖2所示。
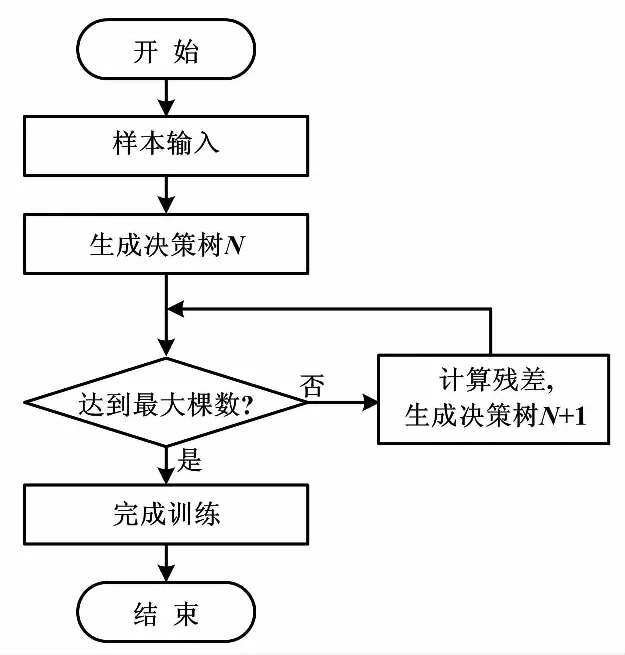
圖2 決策樹迭代流程圖Fig.2 Iterative flowchart of decision tree
2 大數據平臺實現
2.1 MapReduce
MapReduce是Hadoop的核心組件之一,是一種數據處理的編程框架。MapReduce采用“分而治之”的辦法。首先,各個節點處理其分得的數據集,再整合節點的處理結果得到最終結果。在分布式計算中,MapReduce框架負責處理并行編程中一些相對復雜問題,把處理過程高度抽象為map和reduce兩個函數。map可以對操作進行分解,reduce則是要綜合各個結果。
2.2 MapReduce架構
與Hadoop分布式文件系統(Hadoop distributed file system,HDFS)一樣,MapReduce采用了主從結構模型,主要由Client、JobTracker、TaskTracker和Task四個部分組成。
Client 客戶端:每一項任務都會將應用程序和所要配置的相關參數打包處理后再存儲到HDFS,并將路徑提交到JobTracker的master服務中,然后由master創建每一個Task(即MapTask和 ReduceTask),并將它們分發到各個TaskTracker 服務中去執行。在Hadoop中,依據自己的需求對調度器進行設計。
TaskTracker 定期將自己節點情況匯報給JobTracker,并且接受反饋的命令,然后執行相應的操作。TaskTracker使用“slot”等量劃分本節點上的資源量。“slot”代表計算資源(CPU、內存等)。調度器可以把每個TaskTracker上空閑的slot分配給Task使用。slot分為Map slot和Reduce slot兩種,分別供MapTask和ReduceTask使用。可配置參數又能夠對Task的并發度進行限定。
Task分為MapTask和ReduceTask 兩種,均由TaskTracker啟動。采用map函數對輸入的信息進行處理,并且把中間結果存儲到本地磁盤上,臨時數據會被分成若干個partition,每個partition對應一個ReduceTask。ReduceTask從節點上讀取MapTask中間結果;按照key對key/value進行排序;調用reduce函數,將結果保存到HDFS上。
2.3 Hadoop平臺搭建及Xgboost部署
本次試驗通過虛擬機虛擬3臺主機進行數據處理。其中1臺作為主節點Master,另外2臺作為分節點Node1、Node2。每臺主機配置為4核處理器,3G內存并安裝CentOS 6.5系統作為基礎環境。構建的Hadoop集群拓撲示意圖如圖3所示。
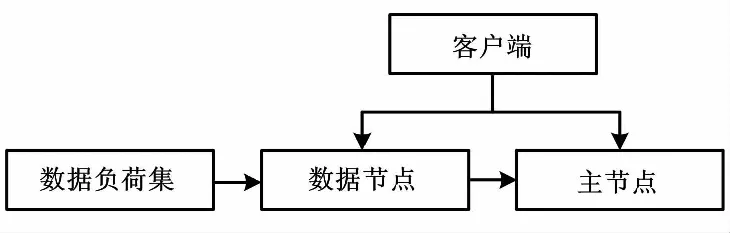
圖3 Hadoop集群拓撲示意圖Fig.3 Schematic diagram of Hadoop cluster topology
在CentOS 6.5系統中創建Hadoop賬戶,并賦予Hadoop賬戶管理員權限,通過修改hosts為主節點和從節點配置IP地址,然后配置ssh使各節點間實現密碼登錄,完成后各臺機器之間可以直接通過ssh+機器名進行訪問。
Spark安裝成功后,將Xgbooost克隆到本地并進行編譯。編譯成功后通過指令以yarn模式啟動spark-shell,并引用Xgboost包。將訓練數據及相應參數輸入Xgboost后運行,至此Xgboost算法基于Spark的分布式計算部署成功。
3 負荷預測試驗及結果分析
試驗采用平均絕對百分比誤差 (mean absolute percentage error,MAPE) 和均方根誤差(root mean squared error,RMSE),公式如下:
(7)
(8)
式中:Xi為實際負荷值;Yi為預測負荷值;n為負荷預測結果的個數。
在負荷預測中,MAPE越小,負荷預測結果就越準確。RMSE越小,則負荷預測結果的精度就越高。
本次預測的數據來源于某省M縣2013年1月1日至2016年9月30日:每5 min采集一次的負荷數據,共計368 640條數據;以及對應日期的天氣數據,如最高氣溫、平均氣溫等共計10 240條數據。短期負荷受天氣、時間、日期等因素的影響而出現波動。這些因素都為負荷特性分析提出了挑戰。分析這些因素與負荷之間的互相關系,有利于負荷預測模型特征的建立。
選擇2016年6月1日至2016年8月24日的日最大負荷值作為訓練數據,預測2016年8月25日至2016年8月31日的日最大負荷值。同時,選取上星期同日的日最大負荷值、上月同日的日最大負荷值、當日最高氣溫、當日平均氣溫、當日是否為工作日等數據,構成預測數據的特征。其中:上星期同日的日最大負荷值、上月同日的日最大負荷值、當日最高氣溫、當日平均氣溫的特征值均為具體真實的數值;當日是否為工作日用0、1表示,0表示當日為非工作日、1表示當日為工作日。訓練數據及特征如表1所示。

表1 訓練數據及特征Tab.1 Training data and features
分布式Xgboost算法成功運行后,將單機版Xgboost算法所采用的樣本重新輸入分布式Xgboost算法進行預測。夏季和冬季的分布式預測結果MAPE和RMSE對比如表2所示。
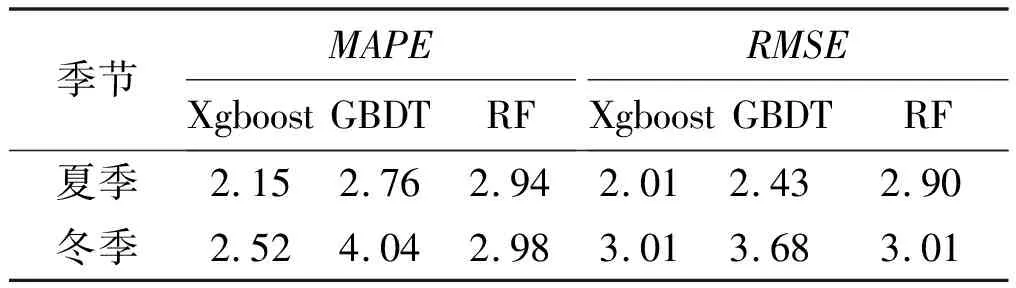
表2 MAPE和RMSE的對比Tab.2 Comparison between MAPE and RMSE
從表2可以看出,Xgboost算法預測精度略高于其他兩個算法。由于樣本量大,各算法訓練速度出現較大差異,考慮計算過程中相關因素對結果造成的影響,經過多次訓練求平均值,結果見表3。
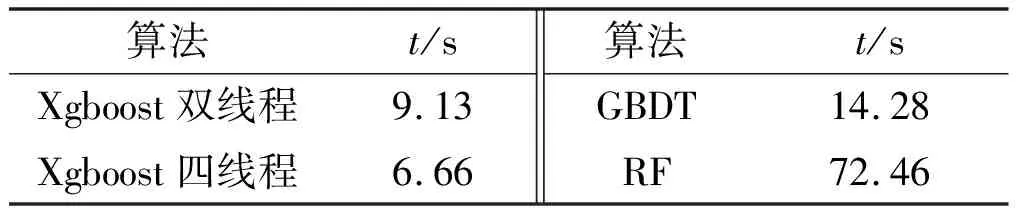
表3 算法訓練速度對比Tab.3 Comparison of the training speed
分布式Xgboost采用的是分布式加權值算法。在數據無法一次載入內存或在分布式情況下,該方法可以高效地生成候選的分割點。
從表3可以看出,RF訓練模型的時間比其他兩個算法訓練時間多,這是由于RF需要多次隨機抽取特征,導致訓練時間增加。Xgboost開啟多線程模式后,訓練速度相對于其他算法有較大的優勢。
平臺首先通過將負荷數據、氣象數據以及其他特征由客戶端輸入;然后,將對應的數據進行分塊,分給兩臺機器進行處理,并將各臺所處理得到的結果匯總到主機上得到整體的預測模型;最后,可以通過測試數據的輸入進行相關的負荷預測工作。
4 結束語
本文針對電力系統負荷預測所用的預測方法不能快速、有效地訓練大量數據樣本,也不能有效地利用歷史數據這些問題,提出了基于Gradient Boosting思想和Shrinkage思想的Xgboost算法負荷預測模型。通過對某省M縣實際負荷數據特性分析,構建了基于負荷的時間特性、溫度特性的訓練樣本,并分別進行了夏季、冬季情況下的負荷預測,同時與RF和GBDT兩種算法進行對比。預測試驗對比驗證了Xgboost算法具有準確性好、訓練速度快等特點,且在開啟多線程的情況下,Xgboost算法有更明顯的速度提升。
參考文獻:
[1] 李龍,魏靖, 黎燦兵, 等.基于人工神經網絡的負荷模型預測[J].電工技術學報, 2015, 30(8): 225-230.
[2] 楊甲甲,趙俊華,文福拴,等.電力零售核心業務架構與購售電決策[J].電力系統自動化,2017,41(14):10-18.
[3] 廖旎煥,胡智宏,馬瑩瑩,等.電力系統短期負荷預測方法綜述[J].電力系統保護與控制,2011,39(1):147-152.
[4] 李黎,楊升峰,邱金鵬,等.電力系統供電短期負荷預測方法仿真研究[J].計算機仿真,2017,34(1):104-108.
[5] 姚李孝,劉學琴.基于小波分析的月度負荷組合預測[J].電網技術,2007,31(19):65-68.
[6] 楊茂,董駿城,羅芫,等.基于近似熵的電力系統負荷預測誤差分析[J].電力系統保護與控制,2016,44(23):24-29.
[7] 竇全勝,史忠植,姜平,等.調和聚類-分類方法在電力負荷預測中的應用[J].計算機學報,2012,35(12):2645-2651.
[8] 于希寧,牛成林,李建強.基于決策樹和專家系統的短期電力負荷預測系統[J].華北電力大學學報,2005,32(5):57-61.
[9] 劉廣一,朱文東,陳金祥,等.智能電網大數據的特點、應用場景與分析平臺[J].南方電網技術,2016,10(5):102-110.
[10]CHEN T,GUESTRIN C.Xgboost:A scalable tree boosting system[C]//Proceedings of the 22Nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.ACM,2016:785-794.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
