網絡爬蟲技術原理
2018-06-14 11:52:06Kevin
計算機與網絡 2018年10期
■Kevin
爬蟲技術就是一個高效的下載系統,能夠將海量的網頁數據傳送到本地,在本地形成互聯網網頁的鏡像備份。本文從爬蟲技術的誕生開始,為你詳細解析爬蟲技術原理。
一、爬蟲系統的誕生
通用搜索引擎的處理對象是互聯網網頁,目前互聯網網頁的數量已達百億,所以搜索引擎首先面臨的問題是:如何能夠設計出高效的下載系統,以將如此海量的網頁數據傳送到本地,在本地形成互聯網網頁的鏡像備份。
網絡爬蟲能夠起到這樣的作用,完成此項艱巨的任務,它是搜索引擎系統中很關鍵也很基礎的構件。盡管爬蟲經過幾十年的發展,從整體框架上來看已經相對成熟,但隨著互聯網的不斷發展,也面臨著一些新的挑戰。

二、通用爬蟲技術框架
爬蟲系統首先從互聯網頁面中選擇一部分網頁,以這些網頁的鏈接地址作為種子URL,將這些種子放入待抓取URL隊列中,爬蟲從待抓取URL隊列依次讀取,并將URL通過DNS解析,把鏈接地址轉換為網站服務器對應的IP地址。
然后將其和網頁相對路徑名稱交給網頁下載器,網頁下載器負責頁面的下載。
對于下載到本地的網頁,一方面將其存儲到頁面庫中,等待建立索引等后續處理;另一方面將下載網頁的URL放入已抓取隊列中,這個隊列記錄了爬蟲系統已經下載過的網頁URL,以避免系統的重復抓取。
對于剛下載的網頁,從中抽取出包含的所有鏈接信息,并在已下載的URL隊列中進行檢查,如果發現鏈接還沒有被抓取過,則放到待抓取URL隊列的末尾。在之后的抓取調度中會下載這個URL對應的網頁。
如此這般,形成循環,直到待抓取URL隊列為空,這代表著爬蟲系統將能夠抓取的網頁已經悉數抓完,此時完成了一輪完整的抓取過程。
1.通用爬蟲架構
上述是一個通用爬蟲的整體流程,如果從更加宏觀的角度考慮,處于動態抓取過程中的爬蟲和互聯網所有網頁之間的關系,可以概括為以下5個部分:
(1)已下載網頁集合:爬蟲已經從互聯網下載到本地進行索引的網頁集合。
(2)已過期網頁集合:由于網頁數量龐大,爬蟲完整抓取一輪需要較長時間,在抓取過程中,很多已下載的網頁可能已經更新了,從而導致過期。之所以如此,是因為互聯網網頁處于不斷的動態變化過程中,所以易產生本地網頁內容和真實互聯網不一致的情況。
(3)待下載網頁集合:處于待抓取URL隊列中的網頁,這些網頁即將被爬蟲下載。
(4)可知網頁集合:這些網頁還沒有被爬蟲下載,也沒有出現在待抓取URL隊列中,通過已經抓取的網頁或者在待抓取URL隊列中的網頁,總是能夠通過鏈接關系發現它們,稍晚時候會被爬蟲抓取并索引。
(5)未知網頁集合:有些網頁對于爬蟲是無法抓取到的,這部分網頁構成了未知網頁結合。事實上,這部分網頁所占的比例很高。
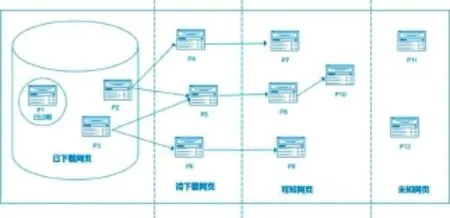
2.互聯網頁面劃分
從理解爬蟲的角度看,對互聯網網頁給出劃分有助于深入理解搜索引擎爬蟲所面臨的主要任務和挑戰。絕大多數爬蟲系統遵循上文的流程,但是并非所有的爬蟲系統都如此一致。根據具體應用的不同,爬蟲系統在許多方面存在差異,大體可以將爬蟲系統分為如下3種類型:
(1)批量型爬蟲:批量型爬蟲有比較明確的抓取范圍和目標,當爬蟲達到這個設定的目標后,即停止抓取過程。
至于具體目標可能各異,也許是設定抓取一定數量的網頁即可,也許是設定抓取的時間等。
(2)增量型爬蟲:增量型爬蟲與批量型爬蟲不同,會保持持續不斷的抓取,對于抓取到的網頁,要定期更新。
因為互聯網網頁處于不斷變化中,新增網頁、網頁被刪除或者網頁內容更改都很常見,而增量型爬蟲需要及時反映這種變化,所以處于持續不斷的抓取過程中,不是在抓取新網頁,就是在更新已有網頁。通用的商業搜索引擎爬蟲基本都屬此類。
(3)垂直型爬蟲:垂直型爬蟲關注特定主題內容或者屬于特定行業的網頁,比如對于健康網站來說,只需要從互聯網頁面里找到與健康相關的頁面內容即可,其他行業的內容不在考慮范圍。
垂直型爬蟲一個最大的特點和難點就是:如何識別網頁內容是否屬于指定行業或主題。
從節省系統資源的角度來講,不可能把所有互聯網頁面下載之后在進行篩選,這樣會造成資源過度浪費,往往需要爬蟲在抓取階段就能夠動態識別某個網址是否與主題相關,并盡量不去抓取無關頁面,以達到節省資源的目的。垂直搜索網站或者垂直行業網站往往需要此種類型的爬蟲。
三、優秀爬蟲的特性
優秀爬蟲的特性對于不同的應用來說,可能實現的方式各有差異,但是實用的爬蟲都應該具備以下特性:
(1)高性能
互聯網的網頁數量是海量的,所以爬蟲的性能至關重要。這里的性能主要是指爬蟲下載網頁的抓取速度,常見的評價方式是以爬蟲每秒能夠下載的網頁數量作為性能指標,單位時間能夠下載的網頁數量越多,爬蟲的性能越高。
要提高爬蟲的性能,在設計時程序訪問磁盤的操作方法及具體實現時數據結構的選擇很關鍵,比如對于待抓取URL隊列和已抓取URL隊列,因為URL數量非常大,不同實現方式性能表現迥異,所以高效的數據結構對爬蟲性能影響很大。
(2)可擴展性
即使單個爬蟲的性能很高,要將所有網頁都下載到本地,仍然需要相當長的時間周期,為了能夠盡可能縮短抓取周期,爬蟲系統應該有很好地可擴展性,即很容易通過增加抓取服務器和爬蟲數量來達到此目的。
目前實用的大型網絡爬蟲一定是分布式運行的,即多臺服務器專做抓取。每臺服務器部署多個爬蟲,每個爬蟲多線程運行,通過多種方式增加并發性。
對于巨型的搜索引擎服務商來說,可能還要在全球范圍、不同地域分別部署數據中心,爬蟲也被分配到不同的數據中心,這樣對于提高爬蟲系統的整體性能是很有幫助的。
(3)健壯性
爬蟲要訪問各種類型的網站服務器,可能會遇到很多種非正常情況:比如網頁HTML編碼不規范、被抓取服務器突然死機,甚至爬蟲陷阱等。爬蟲對各種異常情況能否正確處理非常重要,否則可能會不定期停止工作,這是無法忍受的。
從另外一個角度來講,假設爬蟲程序在抓取過程中死掉,或者爬蟲所在的服務器宕機,健壯的爬蟲應該可以做到:再次啟動爬蟲時,能夠恢復之前抓取的內容和數據結構,而不是每次都需要把所有工作完全從頭做起,這也是爬蟲健壯性的一種體現。
(4)友好性
爬蟲的友好性包含兩方面的含義:一是保護網站的部分私密性;另一是減少被抓取網站的網絡負載。爬蟲抓取的對象是各類型的網站,對于網站所有者來說,有些內容并不希望被所有人搜到,所以需要設定協議,來告知爬蟲哪些內容是不允許抓取的。目前有兩種主流的方法可達到此目的:爬蟲禁抓協議和網頁禁抓標記。
爬蟲禁抓協議指的是由網站所有者生成一個指定的文件robot.txt,并放在網站服務器的根目錄下,這個文件指明了網站中哪些目錄下的網頁是不允許爬蟲抓取的。具有友好性的爬蟲在抓取該網站的網頁前,首先要讀取robot.txt文件,對于禁止抓取的網頁不進行下載。
網頁禁抓標記一般在網頁的HTML代碼里加入meta name="robots"標記,content字段指出允許或者不允許爬蟲的哪些行為。可以分為兩種情形:一種是告知爬蟲不要索引該網頁內容,以noindex作為標記;另外一種情形是告知爬蟲不要抓取網頁所包含的鏈接,以nofollow作為標記。通過這種方式,可以達到對網頁內容的一種隱私保護。
遵循以上協議的爬蟲可以被認為是友好的,這是從保護私密性的角度來考慮的;另外一種友好性則是,希望爬蟲對某網站的訪問造成的網路負載較低。
爬蟲一般會根據網頁的鏈接連續獲取某網站的網頁,如果爬蟲訪問網站頻率過高,會給網站服務器造成很大的訪問壓力,有時候甚至會影響網站的正常訪問,造成類似DOS攻擊的效果。
為了減少網站的網絡負載,友好性的爬蟲應該在抓取策略部署時考慮每個被抓取網站的負載,在盡可能不影響爬蟲性能的情況下,減少對單一站點短期內的高頻訪問。
四、爬蟲質量的評價標準
如果從搜索引擎用戶體驗的角度考慮,對爬蟲的工作效果有不同的評價標準,其中最主要的3個標準是:抓取網頁的覆蓋率、時新性及重要性。如果這3方面做得好,則搜索引擎用戶體驗必定好。
對于現有的搜索引擎來說,還不存在哪個搜索引擎有能力將互聯網上出現的所有網頁都下載并建立索引,所有搜索引擎只能索引互聯網的一部分。而所謂的抓取覆蓋率指的是爬蟲抓取網頁的數量占互聯網所有網頁數量的比例,覆蓋率越高,等價于搜索引擎的召回率越高,用戶體驗越好。
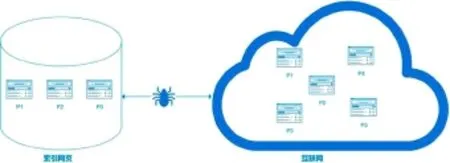
索引網頁和互聯網網頁對比
抓取到本地的網頁,很有可能已經發生變化,或者被刪除,或者內容被更改,因為爬蟲抓取完一輪需要較長的時間周期,所以抓取到的網頁當中必然會有一部分是過期的數據,即不能在網頁變化后第一時間反應到網頁庫中。所以網頁庫中過期的數據越少,則網頁的時效性越好,這對用戶體驗的改善大有裨益。
如果時效性不好,搜索到的都是過期數據,或者網頁被刪除,用戶的內心感受可想而知。
互聯網盡管網頁繁多,但是每個網頁的差異性都很大,比如來自騰訊、網易新聞的網頁和某個作弊網頁相比,其重要性猶如天壤之別。如果搜索引擎抓取到的網頁大部分是比較重要的網頁,則可以說明在抓取網頁重要性方面做得比較好。這方面做的越好,則越說明搜索引擎的搜索精度越高。
通過以上3個標準的說明,可以將爬蟲研發的目標簡單描述如下:在資源有限的情況下,既然搜索引擎只能抓取互聯網現存網頁的一部分,那么就盡可能選擇比較重要的那部分頁面來索引;對于已經抓取到的網頁,盡可能快的更新內容,使得索引網頁和互聯網對應頁面內容同步更新;在此基礎上,盡可能擴大抓取范圍,抓取到更多以前無法發現的網頁。
3個“盡可能”基本說清楚了爬蟲系統為增強用戶體驗而奮斗的目標。
大型商業搜索引擎為了滿足這3個質量標準,大都開發了多套針對性很強的爬蟲系統。以Google為例,至少包含兩套不同的爬蟲系統:一套被稱為Fresh Bot,主要考慮網頁的時新性,對于內容更新頻繁的網頁,目前可以達到以秒計的更新周期;另外一套被稱之為Deep Crawl Bot,主要針對更新不是那么頻繁的網頁抓取,以天為更新周期。
五、最后的總結
閱讀本文,通過了解爬蟲的技術架構、爬蟲的類型、優秀爬蟲的特性和爬蟲質量標準,相信你對爬蟲系統已經有了一個初步的系統性的認識,最后將主要知識點做一個簡短的綱領性總結:
爬蟲抓取網頁的工作流程:選擇待抓取網頁,按順序放入待抓取隊列;系統依次將網頁鏈接地址轉換為IP地址,下載到本地后,按順序進行存儲和標記,避免重復下載;繼續執行新一輪的抓取,周而復始。
爬蟲和互聯網所有網頁之間的關系:已下載網頁集合、已過期網頁集合、待下載網頁集合、可知網頁集合以及未知網頁集合。
爬蟲類型:批量型爬蟲、增量型爬蟲、垂直型爬蟲。
優秀爬蟲的特性:高性能、可擴展性、健壯性、友好性。
爬蟲質量的評價標準:抓取網頁的覆蓋率、抓取網頁時新性及抓取網頁重要性。
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
工業設計(2022年8期)2022-09-09 07:43:20
保健醫苑(2022年1期)2022-08-30 08:39:14
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
家庭影院技術(2017年9期)2017-09-26 03:41:45
中國衛生(2015年12期)2015-11-10 05:13:38
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
技術經濟與管理研究(2014年11期)2014-03-11 17:02:44
電腦愛好者(2011年11期)2011-06-22 08:20:18
