人工智能技術的企業文件智能監察系統的研發
2018-06-22 02:59:30肖招娣
微型電腦應用 2018年6期
肖招娣
(廣東電網有限責任公司 佛山供電局, 佛山 528000)
0 引言
對企業的審計,已經成為常態化工作,故企業內部常態化的審計和監察也成為必要。在企業的生產、經營、管理過程中,產生大量的非結構化文本。傳統的企業文件監察與審計通過人工完成,需要投入大量的人力、物力、財力,無法避免人的主觀因素的影響,面對海量的企業文件只能采用抽查的方式開展,難免留有死角和潛在的風險。本文提出基于NLP(Natural Language Processing,自然語言處理)的企業文件智能監察系統。其核心技術是使用NLP算法,把非結構化的文檔轉換為結構化的數據,存儲在數據庫中;將相關的企業的規章制度、管理辦法以及國家的法律法規拆分成一條條審計規則,存放在知識庫中;基于知識庫,使用專家系統及統計分析,對企業文件進行智能監察。
1 系統架構
該企業文件智能監察系統包括3個核心功能模塊:
非結構化數據結構化處理模塊,該模塊主要使用自然語言處理技術,借助R語言或者Python的函數,將文檔轉化為結構化數據存放在數據庫中,減少數據的體量,大幅度降低數據處理的技術難度。
文件監察規則管理模塊:該模塊主要運用知識庫管理系統,實現對監察規則的管理。這也是智能監察功能的基礎。
智能監察模塊:通過運用專家系統或者統計建模分析,實現對文件的智能監察。
如圖1所示。
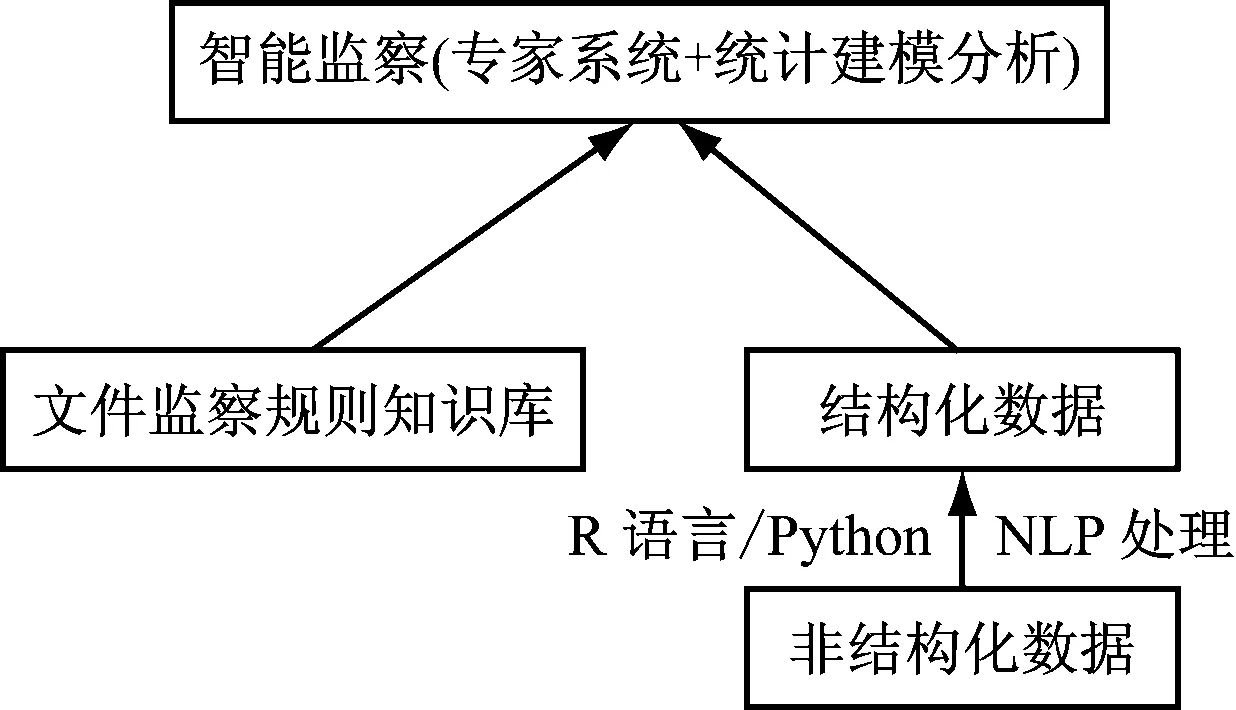
圖1 系統架構圖
2 系統功能及其實現
2.1 非結構化數據結構化處理
2.1.2 數據去重
從非結構化數據中結構化處理過程得到的數據最終將存儲在關系型數據庫中。為了避免數據冗余,為了避免重復對一個文件進行兩次或者兩次以上的結構化處理(該處理過程需要花費一定的時間和計算資源),需要進行必要的去重。文檔查重常用的算法有simHash和minHash算法,通常使用局部敏感散列LSH。其中simHash是Google提出并且使用查重的算法。
本文使用simHash算法查重,如圖2所示。
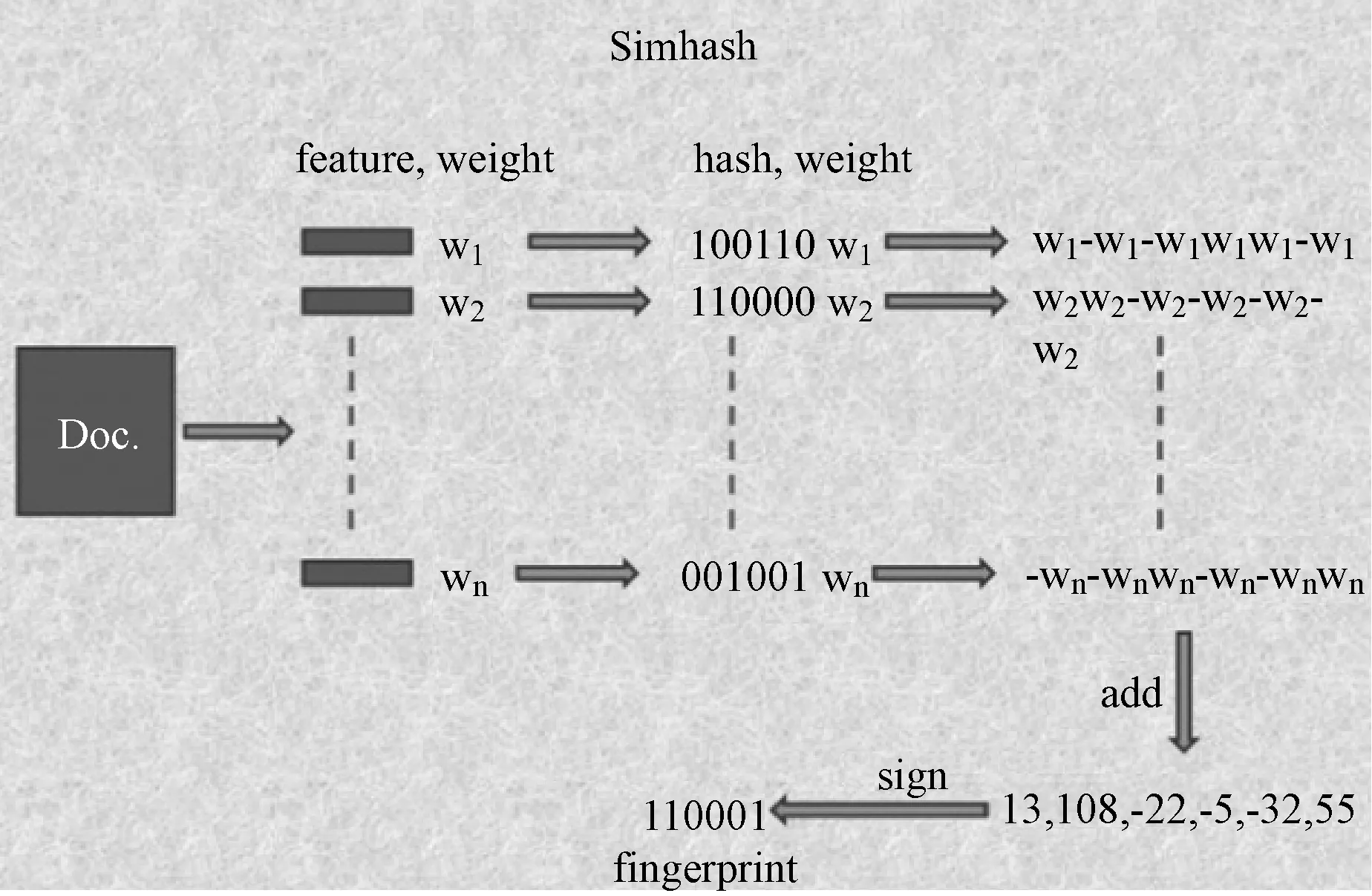
圖2 simHash原理圖
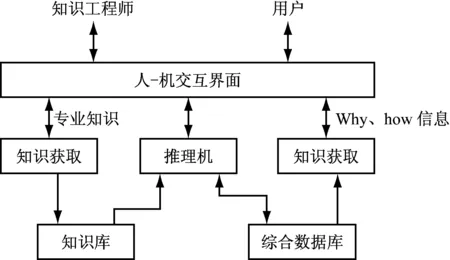
簡單說來,simHash的原理是:將一份文檔轉換為64字節的特征字,然后判斷重復只需要判斷他們的特征字的距離是不是 2.1.2 數據轉換 由于結構化數據的處理相對半結構化數據、非結構化數據的處理更為簡單,且有不少現成的工具和方法可用。為了降低非結構化文件的智能監察的技術難度,也為了減少數據的量體,本文首先對非結構化數據進行結構化處理。非結構化數據結構化處理的過程,其核心為正則表達式的使用,從海量的非結構化數據中提取出關鍵信息。R語言和Python均提供了一系列的方法幫助實現非結構化數據的結構化處理。 在R語言中,需要用到幾個重要的函數,包括gregexpr( )、substring( )、strsplit( )和grep( )函數。其中,gregexpr( )、strsplit( )和grep( )函數是正則表達式相關的函數。而substring( )函數為字符串函數,用于提取字符串子集。 在Python中,更是提供了強大的正則表達式功能,相關函數有match( )、search( )、split( )、group( )、compile( )、sub( )和subn( )等函數。同時,在處理海量文本時,由于單純使用正則表達式的效率較低,可以使用Python的開源庫FlashText提取關鍵字,提高效率。 對企業文件的審計和監察,無非是對海量的企業文件進行合規性和合法性的審查,及時發現存在審計風險的問題,第一時間提醒相干人在文檔修訂過程中完成整改,防患于未然。本文使用Wiki的知識庫管理系統進行審查規則的管理,包括添加、修改、刪除和查詢等功能。知識庫分主題進行規則管理,對于每一類文件的審查,均會將相應的法律法規、公司內部的規章制度和管理辦法拆分成一條條規則。 專家系統是一個智能計算機程序系統,基于其內部存放的大量的某個領域專家的經驗及知識,應用人工智能技術和計算機技術,模擬人類專家的決策過程,進行推理和判斷,能夠利用人類專家的知識和解決問題的方法來處理該領域問題。 本文應用的是基于規則的專家系統,如圖3所示。 圖3 專家系統架構圖 專家系統通常由人機交互界面、知識庫、綜合數據庫、推理機、解釋器、知識獲取等6個部分構成。在本系統中,知識數據庫有專門的功能模塊,其中包括了知識獲取的功能;綜合數據庫即用于存放非結構化數據結構化處理后得到的數據的數據庫。系統需要著重實現的功能是解釋器和推理機部分,為了簡化開發過程,本系統使用了開源的專家系統。 在智能審查方面,涉及兩類的主要的方法。大部分情況下,使用專家系統,結合知識庫固化的規則,即可完成智能審查。但是專家系統具有其優點的同時,也具有其缺點,具體說來包括: (1) 規則之間的關系不透明。在基于規則的系統中,由于基于規則的專家系統缺乏分層的知識表達,難以觀察單條規則如何對整個策略起作用。 (2) 低效的搜索策略。推理引擎在每個周期中搜索所有的規則。當規則很多時,系統速度會很慢。 (3) 沒有學習能力。修改和維護系統的任務仍然由知識工程師來做。 故而對于一些審計規則較為復雜的情形,本文使用統計建模進行分析,通過編程為特定的審計規則實現專用的功能,以此提高系統的效率。 發現問題最終是為了解決問題。智能監察模塊的存在,主要是為了及時發現企業文件編寫過程中存在的風險,將監察結果及時反饋到合同起草、項目文檔審查等過程中相關干 系人環節,提出問題及整改意見,避免錯誤成為定局,避免給企業和個人帶來不必要的風險,實現安全從業。 為了實現輔助整改的功能,該系統在開發的過程中,開發了一系列的API供各信息系統在流程中調用。同時,為了提高系統的實時計算的性能和效率,負責計算的應用服務器采用負載均衡的方式進行部署。 針對企業日常生產、經營、管理活動過程中產生了大量的文件,僅依靠法務工作者及監察審計人員肉眼審閱,已經無法滿足監管需求的現狀,本文研發了一套基于人工智能技術的企業文件智能監察系統。該系統首先利用自然語言處理技術對非結構化數據進行結構化處理;再結合知識庫對審計規則進行管理;最后使用專家系統及統計建模分析,完成對企業文件的智能審查。 通過該系統的研發與應用,使得對企業文件實現全面監察成為可能,解放了勞動力,保證了監察結果的客觀性,提升了工作效率,為企業員工的安全從業提供了技術保障。 [1] Rishi Nalin Kumar.從原始數據到數據科:使非結構化數據結構化,以推動產品開發[EB/OL].周元昊,譯.(2016-12-28). http://www.infoq.com/cn/articles/raw-data-to-data-science. [2] 文檔去重算法:SimHash和MinHash[EB/OL].[2017-01-01].http://m.blog.csdn.net/lafeedfh/article/details/51997814. [3] simhash算法原理及實現[EB/OL].(2014-01-30).https://yanyiwu.com/work/2014/01/30/simhash-shi-xian-xiang-jie.html. [4] 使用SimHash進行海量文本去重[EB/OL].[2016-05-30].https://www.cnblogs.com/maybe2030/p/5203186.html. [5] 基于規則的專家系統的優點和缺點[EB/OL].(2012-09-13).http://book.51cto.com/art/201209/356613.htm. [6] 丁世飛.人工智能(第二版)[M].北京:清華大學出版社,2015. [7] 蔡自興,(美)約翰·德爾金,龔濤.高級專家系統:原理設計及應用(第2版)[M].北京:科學出版社,2017. [8] 王眾托,吳江寧,郭崇慧.信息與知識管理(第2版)[M].北京:電子工業出版社,2014. [9] Steven Bird.Python自然語言處理[M].北京:人民郵電出版社.2014. [10] 章宗慶.統計自然語言處理(第2版)[M].北京:清華大學出版社,2013:73-104. [11] [印度] Deepti Chopra, Nisheeth Joshi, Iti.精通Python自然語言處理[M].北京:人民郵電出版社.2017. [12] [印度]Deepti Chopra, Nisheeth Joshi,Iti Mathur. Mastering Natural Language Processing with Python[M].Packt Publishing,2016:79-103. [13] 鄭捷.NLP漢語自然語言處理原理與實踐[M].北京:電子工業出版社,2017. [14] 張文宇,薛昱,蘇錦旗,等.知識發現與智能決策[M].北京:科學出版社有限責任公司,2017. [15] Yoshua Bengio.人工智能中的深度結構學習[M].北京:機械工業出版社,2017.2.2 審查規則管理
2.3 智能監察
2.4 輔助整改
3 總結
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
Coco薇(2017年11期)2018-01-03 20:59:57
