基于連續幀的在線實時人體行為檢測
2018-06-28 02:44:28周道洋關勝曉夏雨薇
網絡安全與數據管理 2018年6期
周道洋,關勝曉,夏雨薇
(中國科學技術大學 信息科學技術學院,安徽 合肥 230026)
0 引言
近年來隨著深度學習的快速發展,計算機視覺蓬勃發展,極大地推動了人體行為檢測的發展。人體行為檢測作為計算機視覺中一個極具挑戰性的課題,涉及圖像處理、模式識別、計算機視覺、人工智能等多個交叉學科,廣泛應用于視頻監控和安全、人機交互、醫療康復運動分析、環境控制和預測等領域[1]。當前人體行為檢測主要受攝像頭視角變化、光照變化、個體差異等的影響[2]。
深度學習方法在計算機視覺中的廣泛應用得益于卷積神經網絡(Convolutional Neural Network,CNN)的普遍使用。卷積神經網絡因其特殊的網絡結構使其特別適合處理計算機視覺任務,近年來被廣泛應用于圖像分類,物體檢測、分割,視頻理解等任務[3]。
目前基于卷積神經網絡的人體行為檢測方法主要是直接提取視頻的時空特征,然后基于時空特征進行分類和回歸以達到行為檢測的目的。例如SIMONYAN K等的雙流網絡[4],使用視頻幀提取空間信息,同時使用光流提取運動信息(時間流),然后結合時間流和空間流的輸出得到最終結果;Wang Limin等的TSN(Temporal Segment Networks)網絡進一步研究了時空流融合的方法[5];Zhao Yue等提出了時序動作提名算法TAG(Temporal Actionness Grouping)以及后面的分類、邊框回歸網絡SSN(Structured Segment Networks)用于行為檢測[6]。這類方法要求網絡能很好地處理視頻的時序信息,盡可能地提取時序信息,然后將時空信息融合在一起,受光流的影響,這種方法處理速度較慢。隨著對人體行為檢測實時性要求的提高,在線實時人體行為檢測算法被提出。首先使用物體檢測算法將每幀圖像里面的物體檢測出來,然后再使用貪心連接算法將離散的候選框連接起來,以此實現行為檢測。由于物體檢測方法運行很快,又是逐幀檢測,因此很自然地可以設計連接算法實現在線實時人體行為檢測。例如SINGH G等提出Real-time Online Action Detection(ROAD)[7],基于SSD實現物體檢測[8],然后使用貪心連接算法將候選框連接成行為實例,并進行分類,算法最快可以達到40幀每秒的速度。
本文基于SINGH G等提出的ROAD算法,設計了連續幀作為輸入來進一步提高實時在線系統的準確性,同時研究了時空流的融合方法讓網絡能更好地利用和提取時空信息。實驗結果表明改進的網絡結構在保證實時在線的同時提高了準確率。
1 在線實時人體行為檢測算法
SINGH G等提出的ROAD使用物體檢測算法SSD實現幀等級的物體檢測,然后使用貪心連接算法將檢測框連接起來并得到人體行為的分類和定位,當只使用視頻幀的RGB信息時,處理速度高達40幀每秒,同時還可以選擇使用快速光流作為補充,處理速度也達到了28幀每秒,滿足了在線實時系統的要求。
1.1 物體檢測算法SSD
物體檢測算法SSD的主要思想是在不同層次的特征圖上分別生成不同寬高比的邊界框,以此適應不同大小、不同寬高比的物體。由于沒有了候選框提取步驟,整個物體檢測完全在一個網絡結構里面完成,真正實現了端到端的訓練,因此SSD網絡更容易優化訓練,更容易將檢測結果融合進系統之中,最主要的是省去了耗時的候選框提取,SSD網絡運行的速度更快。這也使得SSD網絡更加適合作為在線實時人體行為檢測系統的基礎網絡。
SSD網絡主要由4部分組成:基礎網絡部分、附加的特征提取層、默認框生成部分和卷積預測部分。將不同尺寸大小的圖片變化成300×300后作為模型的輸入,然后經過基礎網絡和附加的特征提取層提取原始圖像的大量卷積特征。選擇一部分特征層作為目標預測的依據,分別送入默認框生成部分和卷積預測部分得到多種尺度的默認框和在每個位置處的默認框偏移及類別概率。最后默認框、預測結果與圖片的真實標記通過Loss層計算損失,并進行誤差的反向傳播訓練模型的參數。
1.2 貪心連接算法
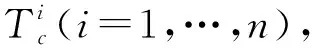
算法總結如下:
(1)對于每一個類別c,算法執行步驟(2)~(7)。
(2)對于已經存在的屬于類別c的行為管道按得分進行降序排序,行為管道的得分為管道里每個檢測框得分的平均值。
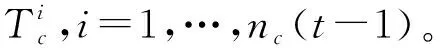
(6)結束循環。
(7)對于沒有匹配的檢測框,以它們為開始初始化新的行為管道。
1.3 在線實時人體行為檢測算法的不足
ROAD處理速度很快,但是準確率還有提升的空間,網絡結構還可以進一步優化,且這種方法是在單幀視頻上進行物體檢測,沒有有效利用視頻里面的時序信息。同時作者使用了快速光流作為補充,但光流與空間流也沒有很好地融合,而這種時序信息和光流與空間流的融合是人體行為檢測里至關重要的。基于此,本文提出一種基于連續幀的在線實時人體行為檢測算法,并考慮空間流和光流的融合進一步提高準確率。
2 基于連續幀的在線實時人體行為檢測算法
在SINGH G等提出的ROAD[7]基礎上,首先考慮時空流的融合,然后使用連續幀作為輸入改進網絡,最后通過對比實驗驗證網絡效果。
2.1 空間流與時間流的融合
現在視頻處理的經典算法一般都會使用雙流網絡提取特征:一個空間流,使用視頻幀的RGB通道作為輸入,通過網絡提取空間信息;一個光流,使用視頻連續幀之間的光流作為輸入,通過網絡提取運動時間信息。分別使用兩個網絡去訓練并做預測,然后將兩者的結果取平均,或是訓練一個SVM分類器,這種方法較單一的一個流準確率有明顯提高,但是這種融合只發生在最終的結果上,中間的特征并沒有進行融合。本文研究了在中間特定層進行特征融合然后基于融合的特征進行人體行為檢測。
總結FEICHTENHOFER C等關于人體行為識別中雙流網絡融合的研究[9],發現卷積融合是最好的融合方法,本文借鑒這種卷積融合方法。
考慮到光流對幀等級邊框檢測的不準確性,本文的融合只發生在分類任務上,對于邊框回歸任務,只使用空間流的特征,但是在訓練的時候邊框回歸的誤差同樣會傳播到光流,因為光流網絡也是使用了SSD,這樣能更好地訓練光流網絡。
本文的基礎網絡仍然使用SSD來進行物體檢測,在每一個要使用的特征層上先進行卷積融合,然后再執行卷積進行分類任務,即在最后的特征層上分別進行融合。時空流融合如圖1所示。
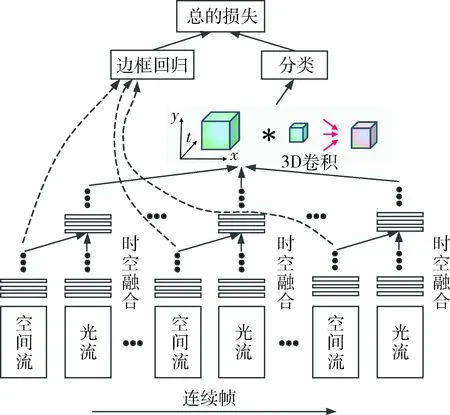
圖1 時空融合及多幀輸入
2.2 連續幀輸入
考慮到連續幀更能描述行為的具體類別,本文使用連續K幀代替單一幀作為輸入,使用相同的卷積網絡結構分別處理每一幀,這些網絡共享參數。
對于分類任務,在進行了時空流的卷積融合以后得到每一幀的時空特征,對于連續K幀,使用3D卷積和3D池化進一步提取時空信息。網絡結構如圖1所示。
連續K幀得到的行為立方體可以類比單幀得到的檢測框,后面經過相同的貪心連接算法,唯一不同的地方在于計算兩個行為立方體的重疊度,兩個行為立方體的重疊度定義為連續K幀重疊度的平均值。
由于使用了連續幀作為輸入,每一幀都會包含于多個行為立方體中。對于每一幀,使用多個關聯的行為立方體中對應幀檢測框的平均值作為當前幀的檢測框,這種處理能得到更加平滑的行為管道。由于本文的連續幀輸入已經得到了較準確的檢測框信息,因此通過算法的初始化和中間的處理已經能很好地檢測行為的開始和結束,1.2節中算法的第5步不需要執行。
KALOGEITON V等通過實驗論證了對于連續幀輸入當K=6時能更好地表示人體行為的特征[10],本文中,使用K=6幀作為輸入,而且使用重疊的輸入,即連續兩次的輸入有K-1幀是重疊的,這樣進一步使用時序信息。分類使用softmax損失,邊框回歸使用Smooth-L1損失。光流的邊框回歸損失不計入總損失,誤差反向傳播時將空間流的邊框回歸損失傳入光流網絡。
3 實驗結果對比分析
為了對本文提出的方法進行有效評估,在公共基準數據集J-HMDB-21和UCF101-24上進行對比實驗。UCF101-24是UCF101子集,包含24類行為,視頻未經修剪,每個視頻都有明確的時空標注。J-HMDB-21是J-HMDB的子集,包含21個行為類別,928段視頻,每一個視頻都只包含一個按行為發生時間修剪好的行為實例。
下面針對本文提出的方法在不同的數據集上分別進行試驗。評價指標為不同重疊度閾值(0.2,0.5,0.75,0.5:0.95)下視頻等級mAP的值,其中0.5:0.95表示此范圍內以0.05為等差計算出來的重疊度對應的視頻等級mAP的平均值。
3.1 關鍵幀檢測
本文算法使用連續6幀作為輸入,對于每一幀都進行邊框回歸,但是6幀作為一個整體進行分類,如圖2所示。從圖中可以看出,相對于單幀輸入使用連續幀能更好地提取視頻的時序信息,從而實現更精確的分類。同時隨著視頻幀的推移,人體的動作在變,檢測框的位置和形狀也能適應性地跟著變化,這都反映出本文算法在幀等級有很好的表現。

圖2 連續幀輸入
3.2 視頻等級mAP平均值對比
表1和表2分別列出不同重疊度閾值(0.2,0.5,0.75,0.5:0.95)下的視頻等級mAP,其中表1是在J-HMDB -21(all splits)數據集上本文算法與ROAD的視頻等級mAP值對比,表2是在UCF101-24(split 1)數據集上本文算法與ROAD的視頻等級mAP值對比。
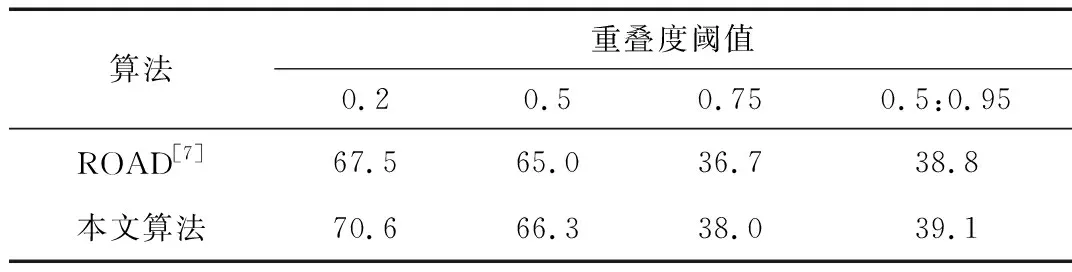
表1 J-HMDB-21視頻等級mAP結果對比
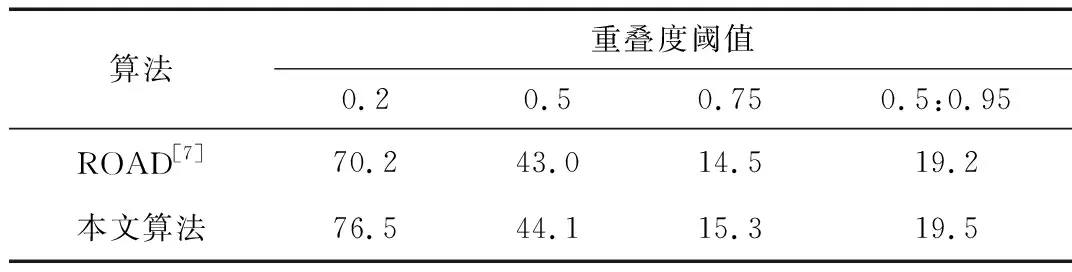
表2 UCF101-24視頻等級mAP結果對比
從表1和表2中可以看出本文算法相對于ROAD[7]在不同數據集上準確率都有明顯提升,特別是在重疊度閾值比較低的時候,準確度提升更明顯。這說明時空流的融合及連續幀輸入的確能更好地提取視頻的時序信息,從而更好地表示視頻,這也驗證了本文方法的有效性。
試驗均在Linux14.04操作系統、CPU(16核,3.0 GHz)、GPU GTX TITAN X(顯存12 GB)上使用caffe完成。連續幀輸入算法的運行速度達到25~30幀 每秒,滿足在線實時系統的要求。
4 結束語
本文基于SINGH G等提出的實時在線人體行為檢測算法,對網絡結構和輸入進行了改進。首先進行時空流的融合,充分利用視頻時序信息;其次使用連續幀作為輸入,進一步利用視頻的時序信息,同時在分類任務中對連續幀的特征使用3D卷積和3D池化融合時空信息。試驗表明,在保證在線實時的條件下,人體行為檢測準確率提升明顯。下一步將通過研究時空流更好的融合方法以縮小模型的大小,使其能運行在嵌入式設備中,讓在線實時人體行為檢測更有意義。
[1] 徐勤軍, 吳鎮揚. 視頻序列中的行為識別研究進展[J]. 電子測量與儀器學報, 2014, 28(4):343-351.
[2] 雷慶, 陳鍛生, 李紹滋. 復雜場景下的人體行為識別研究新進展 [J]. 計算機科學, 2014, 41(12):1-7.
[3] 李岳云, 許悅雷, 馬時平,等. 深度卷積神經網絡的顯著性檢測[J]. 中國圖象圖形學報, 2016, 21(1):53-59.
[4] SIMONYAN K, ZISSERMAN A. Two-stream convolutional networks for action recognition in videos[C]//Advances in Neural Information Processing Systems, 2014: 568-576.
[5] Wang Limin, Xiong Yuanjun, Wang Zhe, et al. Temporal segment networks: towards good practices for deep action recognition[C]//European Conference on Computer Vision, Springer International Publishing, 2016: 20-36.
[6] Zhao Yue, Xiong Yuanjun, Wang Limin, et al. Temporal action detection with structured segment networks[C]//The IEEE International Conference on Computer Vision (ICCV), 2017:2933-2942.
[7] SINGH G, SAHA S, SAPIENZA M, et al. Online real-time multiple spatiotemporal action localisation and prediction[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 3637-3646.
[8] LIU W, AAGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[C]//European Conference on Computer Vision, Springer, Cham, 2016: 21-37.
[9] FEICHTENHOFER C, PINZ A, ZISSERMAN A. Convolutional two-stream network fusion for video action recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 1933-1941.
[10] KALOGEITON V, WWINZAEPFEL P, FERRARI V, et al. Action tubelet detector for spatio-temporal action localization[C]//ICCV-IEEE International Conference on Computer Vision, 2017.
猜你喜歡
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
今日農業(2021年19期)2022-01-12 06:16:36
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
無線電工程(2020年11期)2020-10-29 01:25:46
