基于Spark的因子分析法對(duì)古代疫病數(shù)據(jù)的分析與研究
2018-07-09 09:00:28鄭曉梅黎鉦暉
無(wú)線互聯(lián)科技 2018年13期
關(guān)鍵詞:因素
劉 迪,鄭曉梅,黎鉦暉
(南京中醫(yī)藥大學(xué) 信息技術(shù)學(xué)院,江蘇 南京 210023)
古代疫病數(shù)據(jù)繁雜多怪,但是其中蘊(yùn)含了豐富的中醫(yī)疫病的知識(shí),分析數(shù)據(jù)中的潛在規(guī)律,可以為中醫(yī)臨床提供客觀有效的指導(dǎo)。目前對(duì)古代疫病數(shù)據(jù)的研究大多應(yīng)用數(shù)理統(tǒng)計(jì)方法對(duì)某個(gè)區(qū)域、某個(gè)時(shí)期來(lái)分析疫病的病因病機(jī)、治則治法、方藥配伍、臨床療效等。但實(shí)際上疫病的相關(guān)因素有很多,如天氣、季節(jié)、地域、朝代、用藥、人群等。在某種疫病的生命周期只有某幾種因素導(dǎo)致了疫病的健壯或衰亡。而其他因素則是一些基礎(chǔ)的,影響度較小的,拋開(kāi)這些影響因素不會(huì)對(duì)疫病的發(fā)展趨勢(shì)產(chǎn)生很大的變化。如果能夠量化某種因素對(duì)某種疫病的影響程度,就能找出眾多疫病之間的決定性因素的相似點(diǎn),從而發(fā)掘古代疫病數(shù)據(jù)中的潛在規(guī)律。
就當(dāng)前而言針對(duì)古代疫病的影響因素的分析,完全基于某種算法,但是無(wú)論哪一種算法都經(jīng)受不住高迭代度的復(fù)雜運(yùn)算,如文獻(xiàn)[1]中基于Apriori算法對(duì)古代疫病數(shù)據(jù)進(jìn)行數(shù)據(jù)挖掘,原因就在于目前計(jì)算機(jī)的硬件限制,大部分研究都是在用運(yùn)算時(shí)間去填補(bǔ)機(jī)器硬件的缺陷,然而,在數(shù)據(jù)量達(dá)到TB,PB級(jí)別時(shí),時(shí)間的彌補(bǔ)也無(wú)濟(jì)于事。但是當(dāng)今社會(huì),信息化時(shí)代,我們每個(gè)人每天都在產(chǎn)生大量的數(shù)據(jù),傳統(tǒng)的計(jì)算方法有很大缺陷,如何高效、迅速地發(fā)掘數(shù)據(jù)中的潛在價(jià)值,本文提出了基于Spark的因子分析法,即將大數(shù)據(jù)分布式存儲(chǔ)計(jì)算架構(gòu)與傳統(tǒng)的分析算法相結(jié)合,能夠解決數(shù)據(jù)量過(guò)大導(dǎo)致運(yùn)算時(shí)間過(guò)長(zhǎng)甚至無(wú)法進(jìn)行運(yùn)算的問(wèn)題[2]。
隨著云計(jì)算、移動(dòng)互聯(lián)網(wǎng)等新一代信息技術(shù)的創(chuàng)新和應(yīng)用普及,數(shù)據(jù)的計(jì)算方式開(kāi)啟了一次重大的轉(zhuǎn)型,由于古代疫病數(shù)據(jù)需要繁雜的分析工作,采用適合的計(jì)算分析方法必不可少,本文將古代疫病數(shù)據(jù)算作計(jì)算數(shù)據(jù),利用Spark與傳統(tǒng)的因子分析算法相結(jié)合,幫助找出疫病數(shù)據(jù)中的潛在規(guī)律,了解古代疫病的特點(diǎn),對(duì)現(xiàn)代中醫(yī)疫病的治療提供有效的臨床指導(dǎo)。
1 準(zhǔn)備工作
1.1 因子分析
本研究的目的在于尋找各種和疫病相關(guān)因素之間的潛在規(guī)律,為現(xiàn)代的臨床醫(yī)療提供參考指導(dǎo)。在我們從古書(shū)中抽取的古代疫病數(shù)據(jù)中,針對(duì)一種疫病有多重不同的影響因素,例如年代、病名、地域、季節(jié)、環(huán)境、病因等,維度復(fù)雜混亂沒(méi)有規(guī)律可循。
因子分析多元統(tǒng)計(jì)分析處理的是多變量問(wèn)題。由于變量較多,增加了分析問(wèn)題的復(fù)雜性。但在實(shí)際問(wèn)題中,變量之間可能存在一定的相關(guān)性,因此,多變量中可能存在信息的重疊。人們自然希望通過(guò)克服相關(guān)性、重疊性,用較少的變量來(lái)代替原來(lái)較多的變量,而這種代替可以反映原來(lái)多個(gè)變量的大部分信息,這實(shí)際上是一種“降維”的思想[3]。
1.2 Spark架構(gòu)
Spark是一個(gè)圍繞速度、易用性和復(fù)雜分析構(gòu)建的大數(shù)據(jù)處理框架。Spark運(yùn)行在現(xiàn)有的Hadoop分布式文件系統(tǒng)(Hadoop Distributed File System,HDFS)基礎(chǔ)之上提供額外的增強(qiáng)功能。它支持將Spark應(yīng)用部署到現(xiàn)存的Hadoop v1集群或Hadoop v2 YARN集群甚至是Mesos之中。Spark通過(guò)在數(shù)據(jù)處理過(guò)程中成本更低的洗牌(Shuffle)方式,將MapReduce提升到一個(gè)更高的層次。利用內(nèi)存數(shù)據(jù)存儲(chǔ)和接近實(shí)時(shí)的處理能力,Spark比其他的大數(shù)據(jù)處理技術(shù)的性能要快很多倍。Spark還支持大數(shù)據(jù)查詢(xún)的延遲計(jì)算,這可以幫助優(yōu)化大數(shù)據(jù)處理流程中的處理步驟。Spark還提供高級(jí)的API以提升開(kāi)發(fā)者的生產(chǎn)力,除此之外還為大數(shù)據(jù)解決方案提供一致的體系架構(gòu)模型[4]。Spark的結(jié)構(gòu)如圖1所示。
1.3 Spark與因子分析的結(jié)合
因子分析法是指從研究指標(biāo)相關(guān)矩陣內(nèi)部的依賴(lài)關(guān)系出發(fā),把一些信息重疊、具有錯(cuò)綜復(fù)雜關(guān)系的變量歸結(jié)為少數(shù)幾個(gè)相關(guān)的綜合因子的一種多元統(tǒng)計(jì)分析方法。基本思想是:根據(jù)相關(guān)性大小把變量分組,使得同組內(nèi)的變量之間相關(guān)性較高,但不同組的變量不相關(guān)或相關(guān)性較低,每組變量代表一個(gè)基本結(jié)構(gòu)—公共因子。
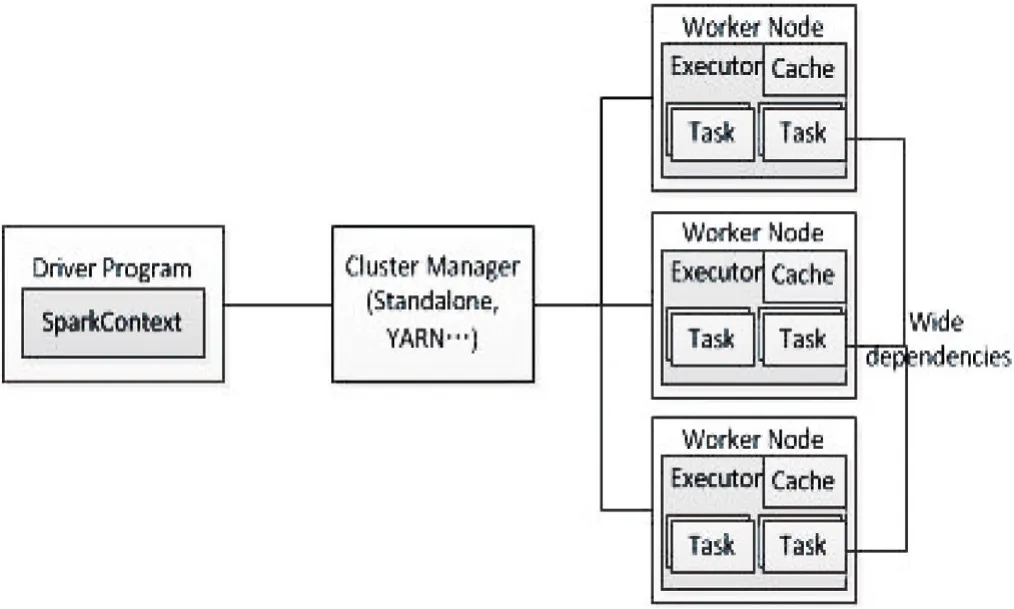
圖1 Spark結(jié)構(gòu)
但是在矩陣求解的過(guò)程中,大部分運(yùn)算都是建立在過(guò)長(zhǎng)的時(shí)耗上,不能進(jìn)行的運(yùn)算,但是如果降低求解時(shí)的迭代次數(shù),結(jié)果會(huì)發(fā)生偏移。所以引入Spark分布式計(jì)算架構(gòu),根據(jù)MapReduce的思想,將矩陣進(jìn)行分解計(jì)算,從而提高運(yùn)算的效率[5]。
2 基于Spark的因子分析法
古代疫病數(shù)據(jù)中含有大量的疫病相關(guān)因素,針對(duì)其影響因素較多的特點(diǎn),本文采用因子分析法進(jìn)行屬性的劃分,通過(guò)計(jì)算給出每種因素的權(quán)重,或是形成新的屬性定義,找到疫病相關(guān)的新的因素,能夠?qū)σ卟〉呐d衰提供詮釋。
2.1 數(shù)據(jù)采集,數(shù)據(jù)預(yù)處理
收集《蘭室秘藏》《簡(jiǎn)明醫(yī)彀》《古今醫(yī)鑒》《丹溪心法》等古代醫(yī)書(shū)籍中提取和疫病有關(guān)的部分,將其分組歸類(lèi),對(duì)描述的方式進(jìn)行歸一化、標(biāo)準(zhǔn)化,最終的數(shù)據(jù)庫(kù)中包含的年代、病名、地域、季節(jié)、環(huán)境、病因、病例數(shù)、年齡、體質(zhì)、性別、癥狀、證型、病機(jī)、治法、方劑、劑型、組成及劑量、用法、其他療法、療效。所有的字段都以古代疫病為基礎(chǔ),從醫(yī)書(shū)中找出相關(guān)影響因素(見(jiàn)表1)[6]。
2.2 Spark結(jié)合因子分析
Spark中的MapReduce將計(jì)算分解為map和Reduce兩個(gè)操作,我們引用mapreduce的計(jì)算思想將相關(guān)系數(shù)矩陣使用QR進(jìn)行分解,將每一塊提交到一個(gè)worknode中,各個(gè)worknode相互獨(dú)立并同時(shí)進(jìn)行運(yùn)算,再經(jīng)過(guò)Reduce將矩陣的求解結(jié)果取出進(jìn)行膠合。即將大矩陣劃分為小矩陣,在不減少迭代次數(shù)的情況下短時(shí)間對(duì)其進(jìn)行求解,提高運(yùn)算的準(zhǔn)確率和效率。
QR分解法是目前求一般矩陣全部特征值的最有效且最廣泛應(yīng)用的方法,一般矩陣先經(jīng)過(guò)正交相似變化成上Hessenberg矩陣,然后再應(yīng)用QR方法求特征值特征向量,由于因子分析處理的是相關(guān)系數(shù)矩陣,是對(duì)稱(chēng)矩陣,從而可以進(jìn)行分塊存儲(chǔ)、運(yùn)算,在不減少迭代次數(shù)的基礎(chǔ)上有效地減少運(yùn)行的時(shí)間,提高效率[7]。Spark和因子分析組合流程如圖2所示。
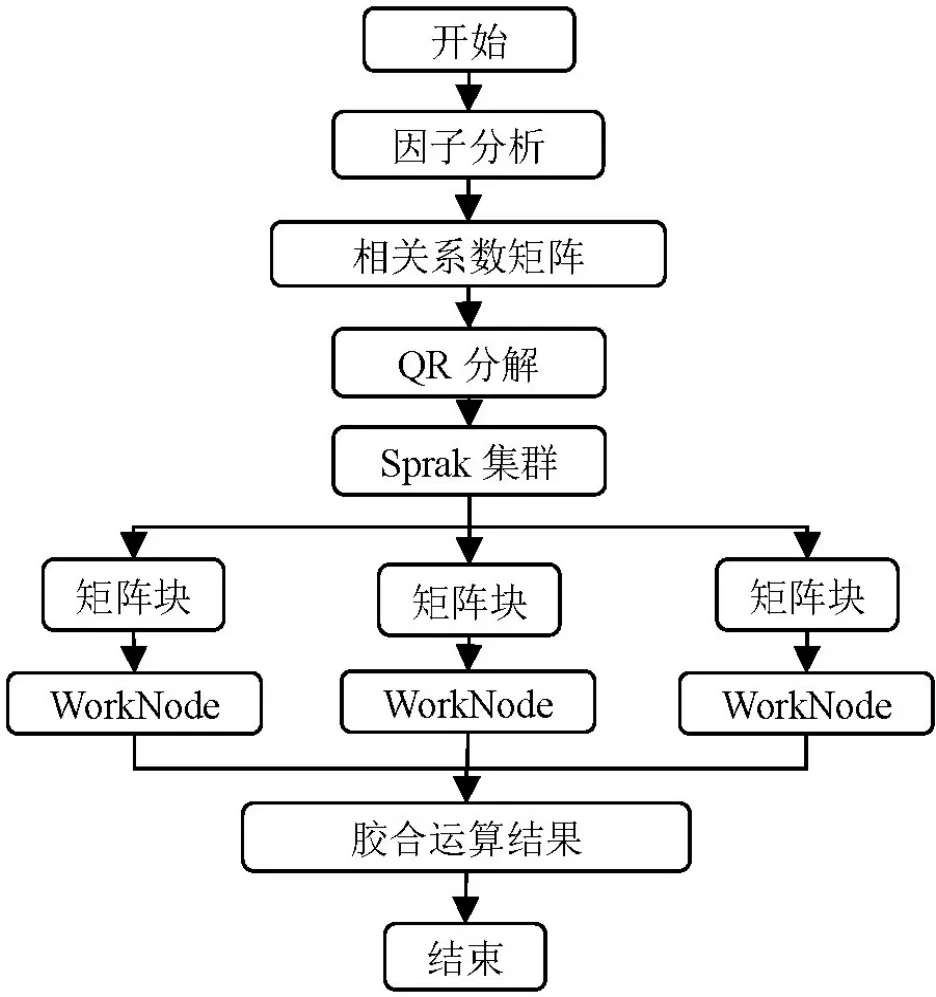
圖2 Spark和因子分析組合流程
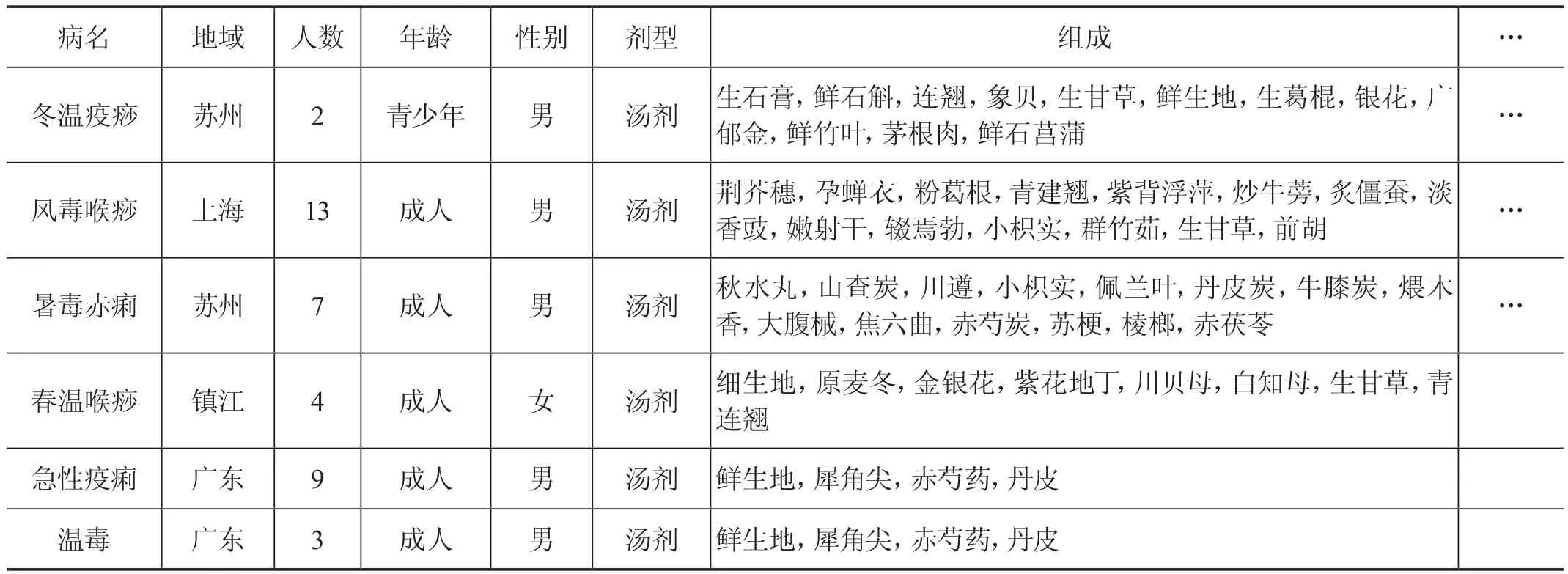
表1 古代疫病相關(guān)數(shù)據(jù)
2.3 因子載荷矩陣旋轉(zhuǎn)
我們得到的初始因子解各主因子的典型代表變量不是很突出,容易使得因子的意義含糊不清,不便于對(duì)實(shí)際問(wèn)題進(jìn)行分析,出于該種考慮,可以對(duì)初始公共因子進(jìn)行線性組合,即進(jìn)行因子旋轉(zhuǎn),以期找到意義更為明確、實(shí)際意義更明顯的因子[8-9]。
3 實(shí)驗(yàn)結(jié)果
實(shí)驗(yàn)設(shè)置了兩組比對(duì):第一組,在運(yùn)算模式都為單機(jī)串行的情況下,兩個(gè)矩陣和4個(gè)矩陣樣本個(gè)數(shù)相同、屬性個(gè)數(shù)不同的情況下運(yùn)算的時(shí)耗。第二組,在分塊的個(gè)數(shù)都為4的情況下,計(jì)算不同屬性個(gè)數(shù),單機(jī)串行將關(guān)系型矩陣分別分為兩個(gè)和4個(gè)矩陣的試驗(yàn)結(jié)果對(duì)比如表2所示。
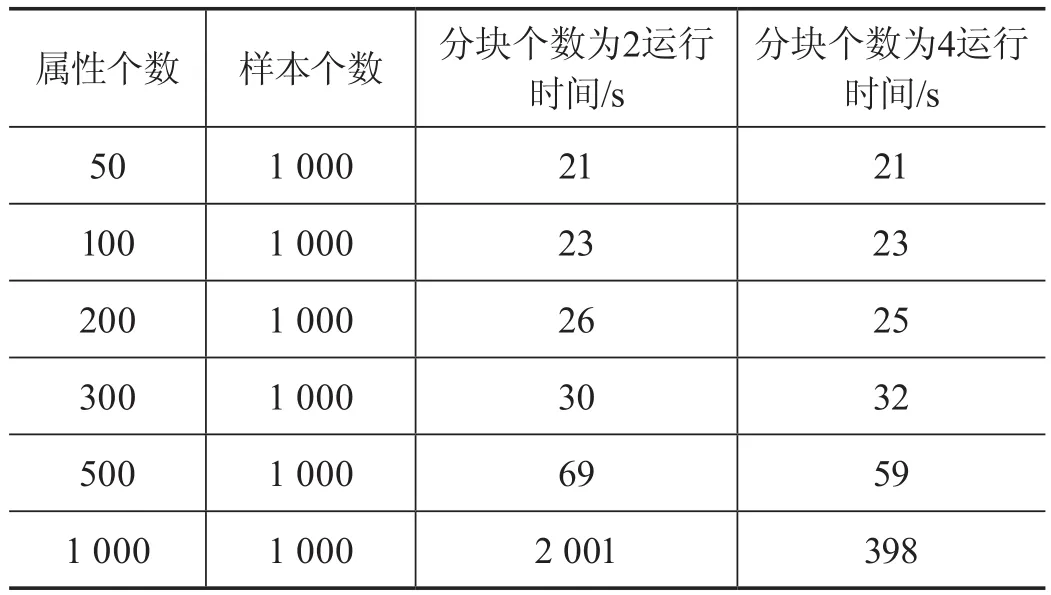
表2 分塊不同的運(yùn)行時(shí)間
單機(jī)代碼實(shí)現(xiàn)因子分析和基于Spark的因子分析的運(yùn)行時(shí)間對(duì)比結(jié)果如表3所示(分塊量為4)。
從表3可以看出,相對(duì)于單機(jī)計(jì)算,基于Spark的因子分析并行算法在速度上明顯更快,并行化的速度在屬性量少的情況下差異不大,但是在屬性的個(gè)數(shù)大幅度提升之后,并行化的運(yùn)行速度要遠(yuǎn)高于單機(jī)的運(yùn)行速度,在迭代次數(shù)不減少的情況下運(yùn)行的性能十分可觀,由此可見(jiàn)算法十分高效。
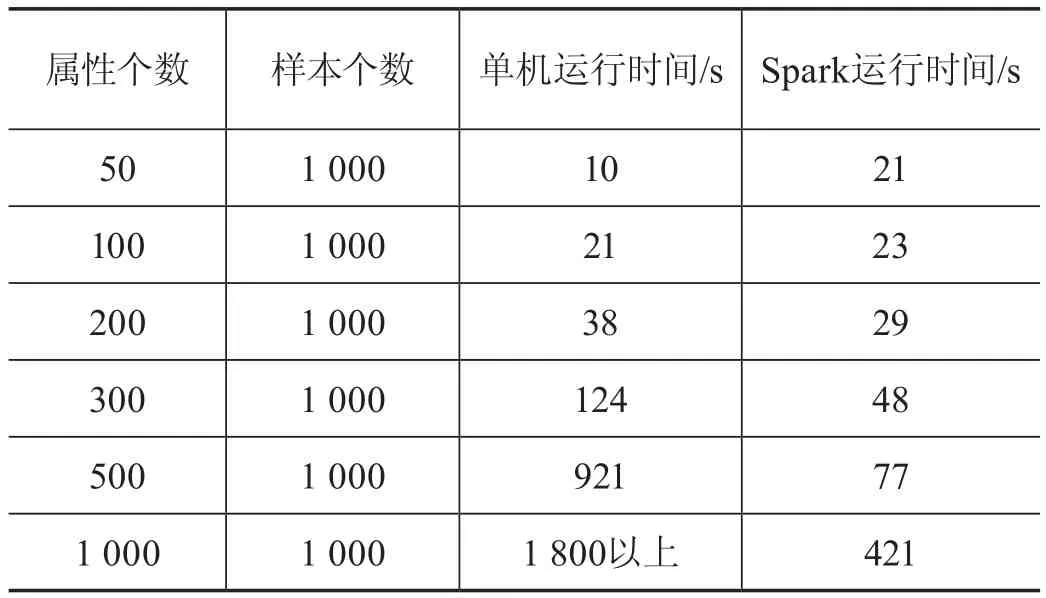
表3 單機(jī)和Spark運(yùn)行時(shí)間對(duì)比
4 結(jié)語(yǔ)
本研究利用QR分解法對(duì)因子分析法中的相關(guān)系數(shù)矩陣進(jìn)行分解,并使用Spark對(duì)分解的矩陣進(jìn)行分布式運(yùn)算,再將計(jì)算的結(jié)果進(jìn)行膠合,從而提高大樣本數(shù)據(jù)、高迭代次數(shù)下因子分析法的運(yùn)行效率。從實(shí)驗(yàn)結(jié)果可以看出,本文提出的基于Spark的因子分析算法對(duì)多因素的古代疫病數(shù)據(jù)具有良好的運(yùn)行性能,從分塊個(gè)數(shù)來(lái)看,隨著分塊的數(shù)量的增加,分塊的優(yōu)勢(shì)越來(lái)越明顯,相對(duì)于單機(jī)運(yùn)行超多屬性的因子分析算法而言,基于Spark的并行計(jì)算模型的運(yùn)行效率更高。
[1]蔡婉婷,李新霞,陳仁壽.基于Apriori算法的古現(xiàn)代疫病用藥比較與分析[J].時(shí)珍國(guó)醫(yī)國(guó)藥,2017(6):1510-1512.
[2]辛智科.中國(guó)古代疫病的流行及其防治[C].哈爾濱:國(guó)際中國(guó)科學(xué)史會(huì)議,2004.
[3]甄盡忠.近30年來(lái)中國(guó)古代疫病流行及社會(huì)應(yīng)對(duì)機(jī)制研究綜述[J].商丘師范學(xué)院學(xué)報(bào),2010(8):59-64.
[4]張稚鯤.疫病(急性傳染性疾病)古今用藥特點(diǎn)及配伍規(guī)律研究[D].南京:南京中醫(yī)藥大學(xué),2017.
[5]熊益亮.明清閩北疫情資料整理與研究[D].福州:福建中醫(yī)藥大學(xué),2014.
[6]單聯(lián)喆.明清山西疫病流行規(guī)律研究[D].北京:中國(guó)中醫(yī)科學(xué)院,2013.
[7]宿佩勇.福州古代疫病文獻(xiàn)資料研究[D].福州:福建中醫(yī)學(xué)院,2005.
[8]王瑤.基于Spark的主成分分析和因子分析并行化的研究與實(shí)現(xiàn)[D].北京:北京郵電大學(xué),2017.
[9]徐斌,呂梁.基于“i-Spark”模型的新員工創(chuàng)新素質(zhì)測(cè)評(píng)實(shí)證研究[J].中國(guó)人力資源開(kāi)發(fā),2016(6):55-62.
猜你喜歡
中老年保健(2022年5期)2022-08-24 02:36:04
今日農(nóng)業(yè)(2021年17期)2021-11-26 23:38:44
現(xiàn)代臨床醫(yī)學(xué)(2021年5期)2021-11-02 05:21:10
食品安全導(dǎo)刊(2021年21期)2021-08-30 08:21:30
中老年保健(2021年4期)2021-08-22 07:07:10
當(dāng)代陜西(2021年12期)2021-08-05 07:45:46
林業(yè)科技(2020年3期)2021-01-21 08:28:40
醫(yī)學(xué)新知(2019年4期)2020-01-02 11:04:04
醫(yī)學(xué)新知(2019年4期)2020-01-02 11:04:00
頌雅風(fēng)·藝術(shù)月刊(2019年11期)2019-03-15 09:22:10
