藏文期刊論文檢索系統研究
2018-07-10 09:49:46仁青東主安見才讓
電腦與電信 2018年4期
關鍵詞:用戶
仁青東主 安見才讓
(青海民族大學計算機學院,青海 西寧 810007)
1 引言
隨著國家教育事業的飛速發展,國內藏區教育教學水平也得到了全方位的提高,而期刊論文發表是其中一項非常重要的組成部分,其主要目的是分享科學研究成果,進行學術交流。為用戶提供一個在最短的時間內要找到自己需要的信息的平臺是現實迫切的需求。本系統目的就是將分散在各處雜志上的論文收集整理,并按照論文結構分類存儲到一個數據庫中,并提供統一的查詢接口,方便用戶在更大的范圍內查找所需內容,提高查詢效率,同時也增加了電子論文潛在的讀者。以上這些問題引出了本課題的研究內容:藏文期刊論文檢索系統的研究。
2 藏文期刊論文檢索系統相關技術分析
在自然語言處理中,詞是最小的、能獨立活動的、有意義的語句成分,而英文、漢文、藏文對字符、字、詞各有不同的含義。英文是以詞為單位的,詞與詞之間按照空格進行分割,劃分很明顯,即字與詞是合二為一的,而詞是由字符構成,界限很清楚;漢文是以字為單位,根據漢文組詞的語法規則構成詞語,詞與詞之間又沒有明顯的標記區分,即由字構成詞,而字與字符是合二為一的;藏文同漢文,也是以字為單位根據組詞規則由字構成詞,而字又由字符構成,即藏文中字符構成字、字構成詞,只是字與字之間由音節符隔開,以此可以區分字與字符。例如,英文句子“He is a teacher”,翻譯成漢文“他是一名老師”,翻譯成藏文計算機可通過空格識別“teacher”是一個單詞,但是無法識別也是一個單詞,所以需引入分詞技術。
2.1 最大概率法分詞技術
本研究使用了最大概率法分詞技術,其主要思路是:(1)一個待切分的藏文字符串可能包括多種分詞結果;(2)將其中概率最大的分詞結果作為該文本的分詞結果。我們用這個例子來進行說明,該字符串各種可能的分詞結果可以用一個有向圖1來顯示如下:
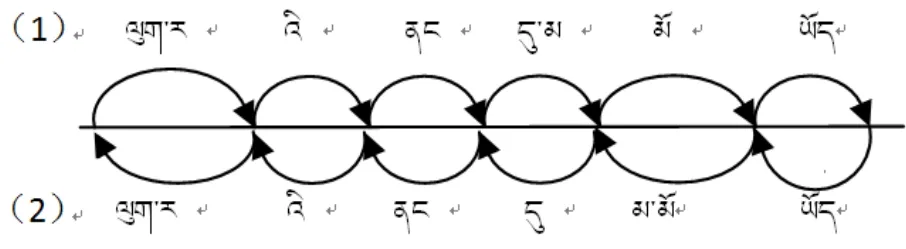
圖 1 “ ”正向與逆向切分結果的有向圖表示
其中(1)表示正向分詞結果,(2)表示逆向分詞結果,把這兩種分詞結果分別表示為W1和W2,則有如下兩種分詞結果:
W1如果采用最大匹配法進行分詞,W1是正向最大匹配的結果,W2是逆向最大匹配結果。對于這個例子來說,很顯然,W2是正確的分詞結果。如果用最大概率法來進行分詞,就是計算W1和W2的概率P(W1)和P(W2),從中挑選一個概率大的作為分詞結果輸出。P(W)的概率可以有不同的計算方法,其中最為簡便直接的一種是將W中的各個詞看作互不相干的獨立事件,以每個候選詞的概率乘積來求得整個詞串的概率。公式如下:
而P(Wi)可由詞語在一定規模的語料庫中的出現頻次來近似估計,即

詞語的概率信息可以按公式2事先計算好,存儲在詞典中。假設詞典中記錄有概率信息如下表1,則可以計算相應的概率值,并選擇最大的作為詞串輸出。

通過計算可以發現P(W2)>P(W1),從概率角度看,詞串W2比W1具有更大的可能性[4]。
2.2 基于排序法的索引創建技術
排序法在創建索引期間,始終占用固定的分配空間,以保存索引的中間結果和詞典信息,當分配空間被占滿時,將中間結果導入磁盤,內存空間就得到了釋放,為下一次保存索引中間結果做準備。可見,這種方法占用的內存空間是固定的,從而可對不同大小的文檔集合創建索引,詳見下圖2。
圖2為排序法創建索引的流程圖。在讀取文檔后,立即對文檔作編號處理,不僅使每個文檔都有專屬的ID,還完成了文檔內容解析。對于經常出現的單詞,可運用查詞典法將單詞轉換為相匹配的單詞ID,如果在詞典中未發現這個單詞,表明這是首次遇到這個單詞,同時將賦予ID并存儲至詞典。

表1 詞語概率信息表

圖2 排序法
3 論文檢索模塊設計
檢索模塊分為普通檢索和相關性檢索兩種方式。普通檢索時,先讓用戶選擇檢索方式,即論文的題目、作者、期刊、關鍵字等,輸入檢索內容之后可預覽論文基本信息。如果需要閱讀詳細內容,就要雙擊題目進行PDF格式閱覽。操作界面如圖3所示:

圖3 檢索結果預覽界面
為了進一步提高用戶的檢索體驗,當用戶輸入錯誤關鍵詞不知道如何檢索關鍵詞時,通過借鑒系統提供的相關檢索,從而可以提高檢索質量,能夠快速地找到自己所需的論文。首先要對論文進行分詞處理,然后要對分詞好的論文進行詞頻統計,根據詞頻計算逆文檔頻率,得到了逆文檔頻率就能得到相應的詞項權重值[1]。相似度計算模塊界面由兩個小模塊組成。第一個小模塊是相關檢索,相關檢索根據計算查詢詞條與論文之間的相似度,按照相似度的評分高低,對查詢結果列表進行排序。第二個模塊是根據用戶輸入的詞條檢索與此相關的詞條,對論文進行查詢,例如查詢詞條,意思為導師,跟導師相關的詞條有老師,通過建立相關詞詞典,能夠實現類似查詢[2]。
4 實驗—壓力測試
壓力測試是一個必不可少且有益的過程,它提供了對Web和移動應用程序在極端負載下的性能測試,可確定應用程序中的潛在漏洞,并在出現問題前對其進行更正[3]。Visual Studio 2017企業版自帶測試功能。為了確保網站的效能及容量可以滿足上線需求,首先需要預設負載測試時間、并發人數。本次實驗預設并發人數為200人,從初始10個用戶開始,每10秒增加30個用戶,直到200個用戶為止,測試時間為5分鐘。
在系統壓力測試中通過逐漸增加用戶訪問人數的方法,從初始的10個用戶到200個用戶同時訪問網頁的實驗中,我們可以發現隨著用戶數量的增多,響應時間最高達到1.81秒,最低響應時間是1.07秒,平均響應時間是1.52秒。實驗證明,該系統基本上能夠達到預期效果。
5 結論

圖4 相關性檢索模塊界面
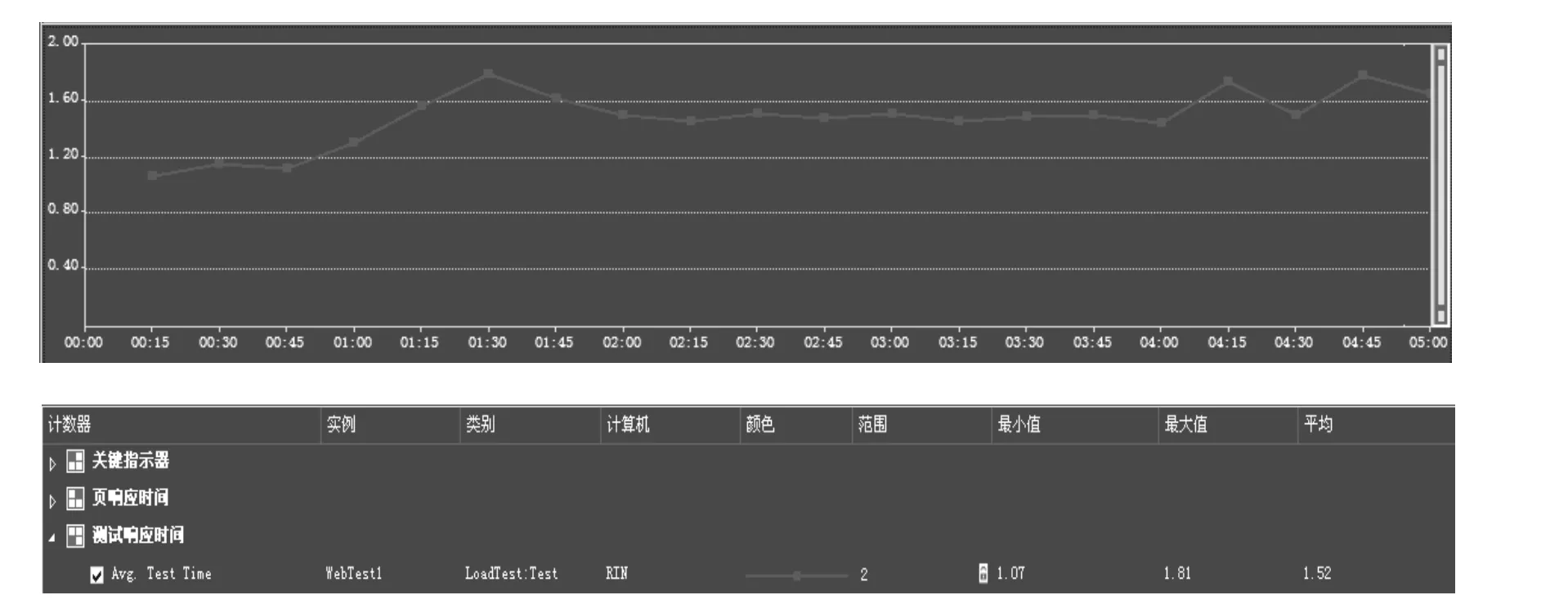
圖5 測試響應時間圖
本文實現了最基本的藏文期刊論文檢索功能,該系統基本上能夠達到預期效果,但仍存在不足之處,離實際的藏文期刊論文檢索系統的標準還有一定的差距,在下一步的研究工作中將繼續改善。比如,當兩個句子意義相似而使用了不同的詞性時,借助近義詞典進行替換,由于近義詞典的詞量相對較少,因此,該算法的計算結果與人的主觀判斷誤差較大。因此,需要更科學、適用的藏文近義詞典,盡可能減少相似度計算誤差。
[1]陳玉忠,李保利,俞士汶.藏文自動分詞系統的設計與實現[J].中文信息學報,2006,20(5):10-16.
[2]安見才讓.藏語句子相似度算法的研究[J].中文信息學報,2011(4):111-113.
[3]伊文斌,鄭劍.基于Load Runner的Web負載測試[J].江西理工大學學報,2008,29(04):13-15.
[4]王瑞雷,欒靜,潘曉花,等.一種改進的中文分詞正向最大匹配算法[J].計算機應用與軟件,2011,28(3):195-197.
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
