基于HBase的車聯網海量數據查詢
2018-07-11 03:30:10馮心欣胡淑英鄒其昊徐藝文
福州大學學報(自然科學版) 2018年4期
馮心欣, 胡淑英, 鄒其昊, 徐藝文
(福州大學物理與信息工程學院, 福建 福州 350116)
0 引言
車聯網(internet of vehicles, IoV)是物聯網(internet of things, IoT)在交通運輸領域的典型應用, 它是一種基于人、 車、 環境協同的開放融合網絡系統, 通過先進的信息通信與處理技術對網內各環節產生的大規模復雜靜態、 動態信息進行感知、 認知和計算, 解決泛在異構移動融合網絡環境中智能管理和信息服務的可計算性、 可擴展性和可持續性問題, 最終實現人、 車、 路、 環境的深度融合[1-3].
在人、 車、 路、 環境的交互過程中產生了海量數據, 一些實際項目的統計發現, 這一數據的規模將會突破10 TB級[4], 因此, 如何在龐大的數據中快速查詢到用戶需要的信息, 以進行車聯網交通信息的綜合分析, 成為車聯網研究的熱點.然而, 這些數據的海量特性、 異構性和眾多并發訪問, 給傳統基于單機數據庫的系統帶來了很大的挑戰.雖然有研究者提出了一些關系型數據庫集群的解決方案, 例如在MySQL集群[5]和Oracle集群[6]中采用分表分庫的方法來進行擴容, 但此擴容操作比較復雜, 需要聯合多個分表數據, 查詢繁瑣, 并增添了分表維護問題.近年來, 基于云計算的分布式存儲系統和新興的非關系型(NoSQL)數據庫技術為解決上述問題帶來契機.目前, 具備高容錯、 高可靠、 經濟等優勢的開源分布式大數據處理平臺的Hadoop和有高擴展性、 快速存儲等優勢的NoSQL數據庫代表HBase, 廣受各界青睞.已有實際案例利用Hadoop和HBase構建存儲倉庫以存儲來自地質氣象研究[7-8]、 環境檢測[9]、 太陽能光伏效應研究[10]、 醫療衛生大數據分析[11]和智慧交通[12-13]等各領域產生的大數據.
基于以上背景, 為解決海量交通數據中快速查詢用戶所需信息的問題, 本研究提出一種基于HBase的車聯網海量數據存儲查詢方案.考慮車聯網數據的時空相關性, 在HBase表設計中通過合理的列族設置和行鍵設計, 使海量數據分布有序, 提高查詢算法的效率, 滿足車聯網信息實時查詢的需求.最后通過實際數據的實驗測試, 驗證方案的可行性與合理性.
1 數據預處理
研究采用的實測車聯網數據是福州市出租車軌跡數據, 原始數據包對每輛車采集包含設備標識(mdtid)、 車輛地理位置經度(longitude)、 緯度(latitude)、 車輛定位時間(msgdatetime)等11項數據.對原始數據進行初步分析發現, 數據包內數據龐雜, 質量參差不齊.為了提高數據的合理利用率以及保證后期數據查詢分析的正確性, 在把數據導入HBase之前, 先進行數據預處理工作, 主要包含以下4個方面內容.
1) 剔除重復數據.由于設備重復發送數據, 導致在原始數據中出現連續多條相同記錄, 為保證數據的唯一性, 剔除整行重復數據.
2) 剔除異常狀態數據.原始數據中的異常數據主要指經緯度數值位數不滿足要求、 車速不合理以及方向信息數值錯誤的數據, 這類數據干擾后期的數據分析.在研究的先期工作中, 已討論了基于Epanechnikov核的修正邊界核建立, 及相應的數據集概率密度函數建立[14].本研究采用其中的核密度估計方法, 對經緯度、 車速和方向信息數據中出現概率較小的數據(即信任度不足的數據)予以剔除.
3) 剔除缺失數據.缺失數據是指在某些字段中存在空缺值的數據, 這樣的數據在后期數據分析時會因缺項而不起作用.缺失數據的數量較少, 預處理中也予以整行數據刪除.
4) 地理位置的路段匹配.雖然原始數據中已收集有車輛經緯度的定位信息, 但由于數據來源和地圖更新等問題, 將這一信息投射在地圖上時, 發現并不是所有數據點都能落在城市道路上, 這對后期道路車流量分析、 車輛路徑軌跡分析都存在影響.因此預處理工作對原始數據增加一步地圖匹配工作, 將車輛的經緯度定位信息與地圖上的道路位置進行匹配, 修正原始經緯度數據, 使得校正后的車輛經緯度位置可以較為精確地落在地圖道路上, 并得到一列新的數據“road”, 該字段表示該定位信息具體落在哪一段道路位置上, 信息格式為“0000-00”, 前4位為道路路段編號, 后兩位為該路段的路徑編號.然而實際工作發現, 并非所有的定位信息都能得到準確的道路匹配, 這是由于有些現實中新建設的道路沒有及時在地圖上更新.但這些數據不屬于上述提及的3種需要剔除的數據類型, 因此對這些少量的暫時無法得到精確道路匹配的數據采取在“road”字段保留“xxxx-xx”的形式.這樣, 既能保證最后的數據行不含缺項, 也能在地圖更新后修改對應的道路信息.
2 HBase表設計與查詢模式設計
HBase的物理模型是以列族為單位存儲數據, 磁盤上同一個列族下所有的單元格都存儲在一個存儲文件(StoreFile)中.因此, 相關的數據項應放置在同一個列族, 保證數據物理存儲的靠近以提高查詢效率[15-16].另一方面, 行鍵作為 HBase 表索引的主鍵, 決定了表數據處理的性能.因此, 為了使海量車聯網數據在云服務器集群能夠合理存儲并便于后期用戶訪問, 需要針對數據特點并結合實際應用對數據存儲表做表結構設計, 設計主要包含列族設置與行鍵設計.
2.1 列族設置
將經過預處理后的數據視作合理、 可用的車聯網數據, 對現有的12項信息進行分析發現: 車輛定位的經緯度信息、 道路位置信息、 車輛定位時間、 車速、 方向等信息都是車聯網綜合分析服務中常用到的查詢項目, 對分析交通運行情況、 司機駕駛習慣等實際應用場景都十分必要.考慮查詢的高效率, 在設計表時將上述提及的幾項常用信息放置在同一列族中; 而數據項中的“islocate-是否定位”、 “sourceflag-信息源”、 “indate-數據入庫日期”這3項信息較為不常用, 歸為同一列族.最終的列族設計如表1所示.

表1 車聯網數據的列族設置
2.2 行鍵設計
由于數據在HBase中以鍵值(key value)形式存儲, 行鍵(row key)是主鍵, 行鍵的設計對數據的存儲查詢性能起關鍵作用, 因此在設計時需充分考慮車聯網信息查詢的應用場景, 做綜合分析.在車聯網信息查詢應用中, 車牌號、 車輛定位信息、 定位時間是最關鍵的信息項.如, 對某一路段車流量的查詢, 希望根據車輛定位時間(msgdatetime)查詢到某路段上的所有車輛設備標識(mdtid)并統計其數量; 對某車運動軌跡的查詢, 希望根據車輛設備標識(mdtid)和定位時間(msgdatetime)查詢到車輛定位的經緯度(longitude & latitude).
因此將實測數據中采集的對應信息項 “mdtid-設備標識”、 “msgdatetime-車輛定位時間”和“road-道路信息”放入行鍵的位置并進行組合, 分析對比各復合行鍵設計方案后, 采用如表2所示的最終方案.

表2 行鍵最終方案
此行鍵設計方案的優點是:
1) 用此3個字段信息組合的復合行鍵保證了行鍵的唯一性和長度一致.
2) 規避數據以時間順序存放時, 因時間數據呈現單調遞增趨勢而引起集群內單一region過載, 而其他機器閑置的風險.
3) 根據HBase存儲特性, 以車輛設備標識為順序排列的存儲方案使同一輛車的數據能在物理存儲上同樣靠近, 在以車輛為檢索條件的查詢應用上體現出高效性.
2.3 查詢模式設計
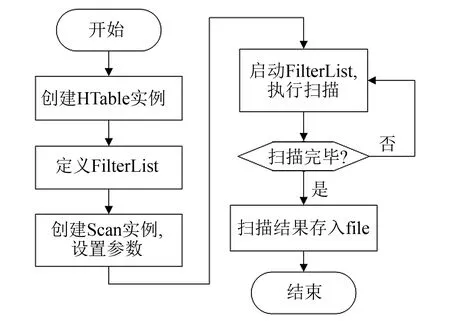
圖1 車輛軌跡查詢程序流程 Fig.1 Flowchart of vehicle trajectory query program
在上述行鍵設計的基礎上設計兩類車聯網信息查詢的模式.
模式一: 車輛駕駛情況查詢.該模式包含車輛在某個時間點的定位情況查詢和車輛在某個時間段內行駛軌跡查詢.根據用戶輸入車輛設備標識和查詢時間, 可定位車輛坐標位置并顯示車速、 方向等相關信息以分析特定車輛的行駛狀況.
模式二: 路段車流量查詢.該模式根據用戶輸入的路段信息和時間范圍, 顯示該時間段內經過該路段的所有車輛的設備標示并統計車輛總數.
下面分析各查詢模式的程序實現流程.
1) 模式一: 車輛軌跡查詢程序的流程, 如圖1所示, 具體步驟說明如下.
① 設置自定義過濾器集合(Filterlist), 集合包含一個前綴過濾器用來確定車輛, 兩個行過濾器(RowFilter)確定檢索的起始時間和結束時間, 3個過濾器全通可以鎖定Scan()的起始行和結束行, 過濾器參數為用戶輸入的車輛設備標識(mdtid), 查詢起始時間(start_time)、 查詢結束時間(end_time).
② 創建Scan實例, 用s.addColumn()方法限制返回數據列只有車輛定位經度(longitude)、 緯度(latitude)、 對應的路段-路徑編號(road)、 數據發送時間(msgdatetime).
③ 將返回至掃描器(scanner)的信息逐行輸出至名為“設備標識-時間時間-結束時間.txt”的文本中, 通過文本將車輛軌跡數據導入地圖模塊, 最終可在ArcGIS軟件中已經事先導入的城市地圖上顯示該車輛該時段的軌跡圖.
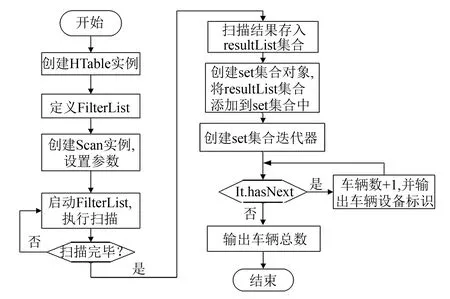
圖2 路段車流量查詢程序流程Fig.2 Flowchart of roadtraffic flow querying program
2)模式二: 路段車流量查詢的程序流程如圖2所示, 具體步驟說明如下.
① 設置自定義過濾器集合(Filterlist), 集合包含一個行過濾器用來確定路段, 兩個列值過濾器(SingleColumnValueFilter)確定檢索的起始時間和結束時間, 一個列限定符過濾器, 限定返回列項僅為“設備標識-mdtid”, 4個過濾器全通使Scan()操作結果滿足查詢要求.
② 創建Set集合, 通過addAll()循環將Scan()結果添加進集合, 此方法可以去掉重復值, 保證車輛數量統計的正確性.
③ 最后通過iterator()對象獲取Iterator()實例, 再通過遍歷迭代器來獲取集合對象, 即該時段經過該路段的車輛設備標識, 并統計車輛總數.
3 實驗與結果分析
為了驗證上述HBase表設計與查詢模式的性能, 通過實驗對其進行評測.實驗平臺采用3臺機器搭建HBase集群, 操作系統均為Ubuntu 14.04 LTS, 每臺機器的主機名、 IP地址、 角色分配如表3所示.

表3 集群配置
3.1 查詢模式的性能驗證
在所搭建的平臺上對上述查詢模式進行測試, 實驗數據使用福州市出租車2015年12月2日的GPS數據, 數據量10 506 479 條.
模式一: 車輛駕駛情況查詢.
1) 查詢車輛11823在2015年12月2日12:20:00的定位記錄, 結果如圖3(a)所示.查詢結果顯示該車在該時間點, 所在的經緯度位置為119.327 298 583°E, 26.068 719 103 4°N, 所在路段編號為0554-08, 車輛行駛方向為6(正西), 車速16 km·h-1.此查詢功能可以有效地對特定車輛的行駛情況進行分析, 如檢測車輛是否超速、 追蹤車輛的位置等.
2) 查詢車輛13702在2015年12月2日12:00—12:30的車輛軌跡信息, 得到結果如圖3(b)所示, 圖中分別用藍點和紅點標出該車輛在此時段行駛軌跡的起點和終點, 車輛的行駛方向則用箭頭標識.
模式二: 路段車流量查詢.
查詢2015年12月2日17:00—17:10經過道路0616-01的車流量, 部分結果如圖4所示.圖4(a)顯示了查詢的部分結果, 分別為該時間段經過該路段的各車輛設備標識和車輛總數; 圖4(b)顯示了該路段的地圖; 圖4(c)則是從查詢結果中任意選取的兩輛車在該時間段的軌跡圖, 從軌跡圖中可以看出這兩輛車在2015年12月2日17:00—17:10時段內確實經過路段0616-01, 從而驗證了查詢結果的正確性.
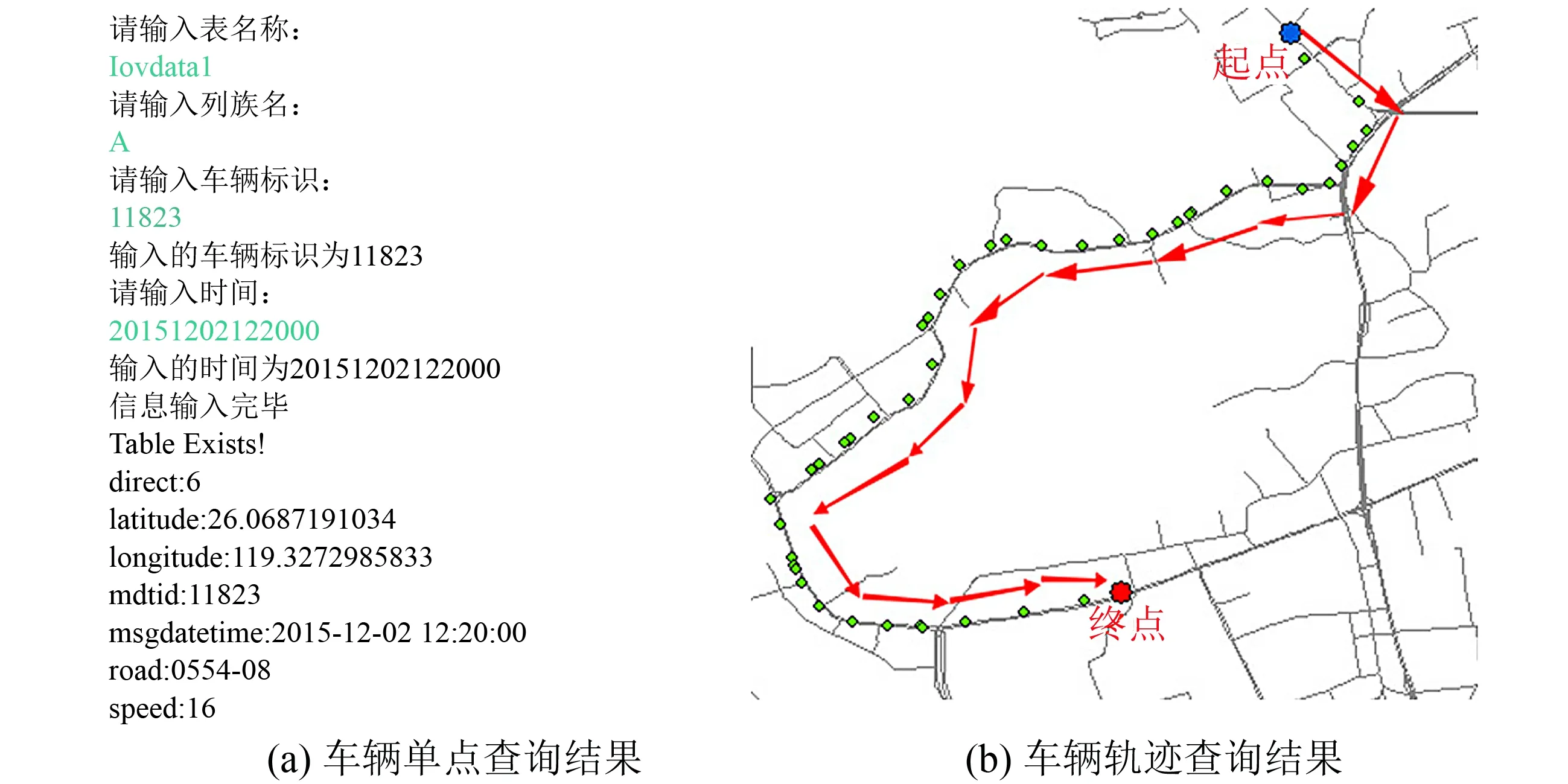
圖3 車輛駕駛情況查詢結果Fig.3 Querying the driving conditions of a certain vehicle

圖4 路段車流量查詢結果Fig.4 Result of traffic flow querying for a road
3.2 行鍵設計方案的性能驗證
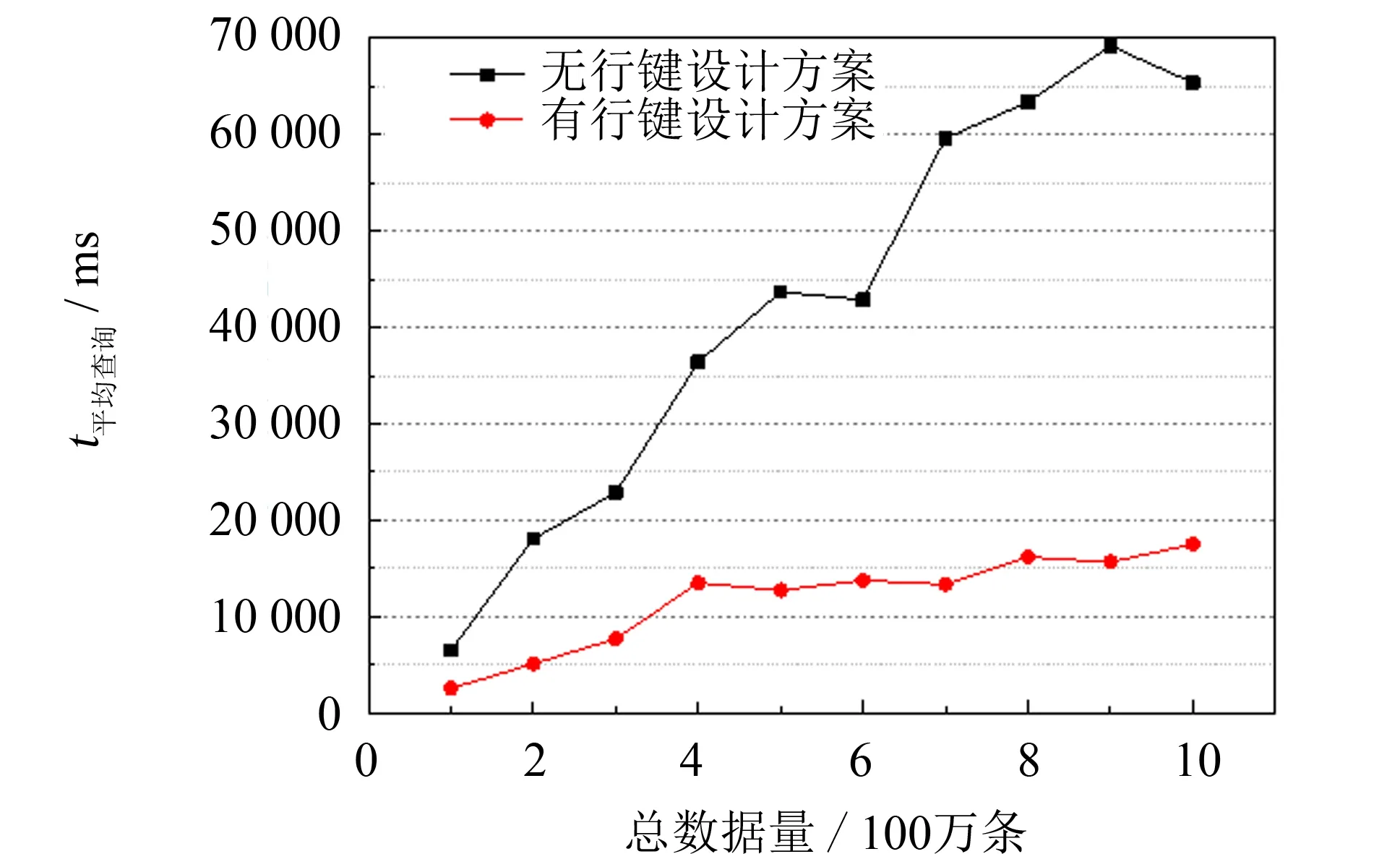
圖5 查詢耗時對比 Fig.5 Time consumption comparison
為了驗證HBase行鍵設計方案確實能有效提高數據查詢性能, 設計實驗通過查詢相同的數據以對比有無行鍵設計對實際查詢耗時的影響.具體方法為:
1) 設置每組實驗的數據總量從100萬條逐次遞增至1 000萬條, 每次增加100萬條數據, 總共做10組對比實驗;
2) 每組實驗隨機選取20輛車, 查詢指定1 h的軌跡數據;
3) 每組實驗重復3次, 取最終的查詢時間平均值.
按以上策略分別測試行鍵設計方案和無行鍵設計, 僅以列值做檢索這兩種方法的數據查詢用時, 通過對比兩者的差異來比較兩種方法的查詢性能優劣.實驗結果如圖5所示, 圖中橫軸為數據總量, 縱軸為平均查詢時間.
由圖5可知, 隨著數據總量的增大, 兩種方案的平均查詢時間都逐漸增長, 但是當數據總量達到400萬條時, 以行鍵為查詢索引的方案平均查詢時間的增速開始放緩, 而沒有行鍵設計的查詢方案直至數據總量達到900萬條時, 平均查詢時間的增速才開始下降.雖然曲線的轉折點不同, 但兩種查詢方案都呈現出在數據總量增至一定程度時, 查詢時間的增速將下降的趨勢, 這顯示了HBase對于海量數據查詢的適用性.同時, 圖5顯示出在不同的數據總量中查詢時, 有行鍵設計的方案平均查詢時間都明顯小于沒有行鍵設計的查詢方案.實驗說明, HBase表設計中, 是否針對查詢應用做合理的行鍵設計, 對數據查詢耗時影響較大.本研究采用的方案在數據特性分析的基礎上針對數據查詢應用功能做了對應的行鍵設計, 使查詢指定車輛某段時間軌跡數據的耗時降低, 從而顯著地提升了查詢性能, 對比實驗驗證了行鍵設計方案的高效性.
4 結語
車聯網對實現智能交通系統(intelligent transportation system, ITS)具有重要意義.研究針對車聯網采集到的海量數據, 提出一種基于HBase的存儲查詢方案.HBase是建立在Hadoop上的列式開源數據庫, 相比于傳統關系型數據庫在存儲海量數據時有突出優勢.研究提出一種合理的表結構設計, 實現在HBase中存儲龐大的車聯網數據, 并在數據導入HBase之前, 對數據進行了預處理工作, 特別是通過地圖匹配校正了原始數據中錯誤的車輛經緯度定位信息, 并增加了精確的道路信息以豐富交通情況的查詢分析功能.通過實驗測試了幾種查詢模式的合理性, 并通過對比實驗顯示了行鍵設計方案在查詢耗時上的優越性.
猜你喜歡
現代裝飾(2020年7期)2020-07-27 01:27:42
流行色(2020年1期)2020-04-28 11:16:38
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2017年5期)2017-06-05 08:53:16
中外會展(2014年4期)2014-11-27 07:46:46
舒適廣告(2008年9期)2008-09-22 10:02:48
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
