用于云存儲數(shù)據(jù)服務(wù)器的I/O請求調(diào)度算法
2018-07-12 11:29:32李宇
西南交通大學(xué)學(xué)報(bào) 2018年4期
李 宇
(北京交通大學(xué)軟件學(xué)院, 北京 100044)
在大數(shù)據(jù)時(shí)代,人們?nèi)粘a(chǎn)生大量的數(shù)據(jù)(如視頻、照片、個(gè)人狀態(tài)等),以Facebook為例,其每天存儲三億張用戶上傳的照片[1].為了吸引用戶,國內(nèi)外互聯(lián)網(wǎng)公司紛紛推出相應(yīng)的云存儲產(chǎn)品,如Dropbox[2]、百度云網(wǎng)盤[3]、騰訊微云[4]、360云盤[5]等.在云存儲應(yīng)用環(huán)境中,用戶的數(shù)據(jù)(如視頻、語音、圖片、文字等)集中存放在分布式文件系統(tǒng)(distributed file system, DFS)中,用戶通過瀏覽器/云存儲客戶端向應(yīng)用服務(wù)器發(fā)送數(shù)據(jù)請求,由應(yīng)用服務(wù)器連接DFS來獲取數(shù)據(jù)并返回給用戶在上述應(yīng)用環(huán)境中,用戶的數(shù)據(jù)請求具有以下特點(diǎn):一方面,云存儲的用戶量非常龐大,數(shù)據(jù)服務(wù)器會收到大量的并發(fā)I/O請求;另一方面,不同類型I/O請求的發(fā)送頻率和對響應(yīng)時(shí)間的要求也不盡相同(如在線播放視頻和瀏覽圖片時(shí),對端到端的延遲和數(shù)據(jù)傳輸帶寬的要求有很大差別).
目前,在云計(jì)算存儲環(huán)境下的I/O調(diào)度相關(guān)研究主要集中在虛擬機(jī)資源的合理調(diào)度上.同時(shí)考慮能耗和負(fù)載的虛機(jī)調(diào)度算法[6],允許虛機(jī)重新聲明CPU片段供使用.面向云存儲的I/O資源效用優(yōu)化調(diào)度算法[7]通過服務(wù)水平目標(biāo),采用最早截止時(shí)間優(yōu)先算法或者預(yù)計(jì)效益來提高總收益率.動態(tài)優(yōu)先級排序[8]基于多屬性決策理論,以離差最大化方法計(jì)算I/O任務(wù)的優(yōu)先級評估屬性權(quán)重并綜合評估,將虛擬域的差異體現(xiàn)在虛擬機(jī)的I/O調(diào)度上.
當(dāng)前常用DFS(如Ceph[9]、GlusterFS[10]、HDFS[11]等)的設(shè)計(jì)關(guān)注點(diǎn)均在如何高效地存儲和查詢元數(shù)據(jù)、如何把數(shù)據(jù)均勻地分散到不同的數(shù)據(jù)服務(wù)器,以及數(shù)據(jù)的可靠性等方面,對數(shù)據(jù)服務(wù)器守護(hù)進(jìn)程(data server daemon, DSD)的I/O請求調(diào)度并沒有進(jìn)行特別的設(shè)計(jì),采用的是先來先服務(wù)(first in first out, FIFO)策略,將所有并發(fā)請求同等對待,以盡力而為(best effort)的方式順序處理.這種調(diào)度策略側(cè)重于減小開銷和有效利用網(wǎng)絡(luò)帶寬,能夠提高系統(tǒng)整體的平均響應(yīng)時(shí)間.然而,它并未考慮不同類型I/O請求的時(shí)效性要求,使得需要實(shí)時(shí)響應(yīng)的I/O請求(如在線視頻播放)和普通I/O請求(如圖片瀏覽)一同排隊(duì)等待,前者可能會被阻塞相當(dāng)長的時(shí)間而無法得到及時(shí)處理,從而導(dǎo)致整個(gè)系統(tǒng)服務(wù)質(zhì)量降低.
針對上述問題,本文提出一種用于DSD基于優(yōu)先級的周期性調(diào)度算法(priority-based periodic scheduling algorithm, PPSA).PPSA首先對來自客戶端的I/O請求進(jìn)行分類,并賦予不同的優(yōu)先級;然后以合適的時(shí)長作為周期,以分時(shí)間片的方式對不同優(yōu)先級的I/O請求進(jìn)行周期性的調(diào)度.PPSA在保障實(shí)時(shí)請求響應(yīng)性能的同時(shí),也兼顧了其他優(yōu)先級請求的響應(yīng)性能.
1 算法概述
當(dāng)前主流的云存儲應(yīng)用環(huán)境中,用戶使用數(shù)據(jù)的方式基本都是“一次寫、多次讀”(write once, read everywhere)模式:用戶上傳的文件或者分享給別的用戶,或者是對已有數(shù)據(jù)的備份,只有很小部分文件在上傳之后會被修改[12].因此,本文主要研究DFS中數(shù)據(jù)服務(wù)器讀I/O請求的調(diào)度問題,寫I/O請求仍采用原來的調(diào)度方式.后文如無特別說明,所有出現(xiàn)的I/O請求均指讀I/O請求.
1.1 工作原理
PPSA的工作原理見圖1,它工作在DFS的DSD內(nèi).客戶端收到上層應(yīng)用發(fā)出的I/O請求后,通過網(wǎng)絡(luò)將其發(fā)送到存儲相應(yīng)數(shù)據(jù)的服務(wù)器DSD緩沖隊(duì)列中;之后,分類器根據(jù)分類配置文件對I/O請求進(jìn)行分類,并把分類后的I/O請求放入對應(yīng)優(yōu)先級的請求隊(duì)列;最后由調(diào)度器統(tǒng)一進(jìn)行調(diào)度.
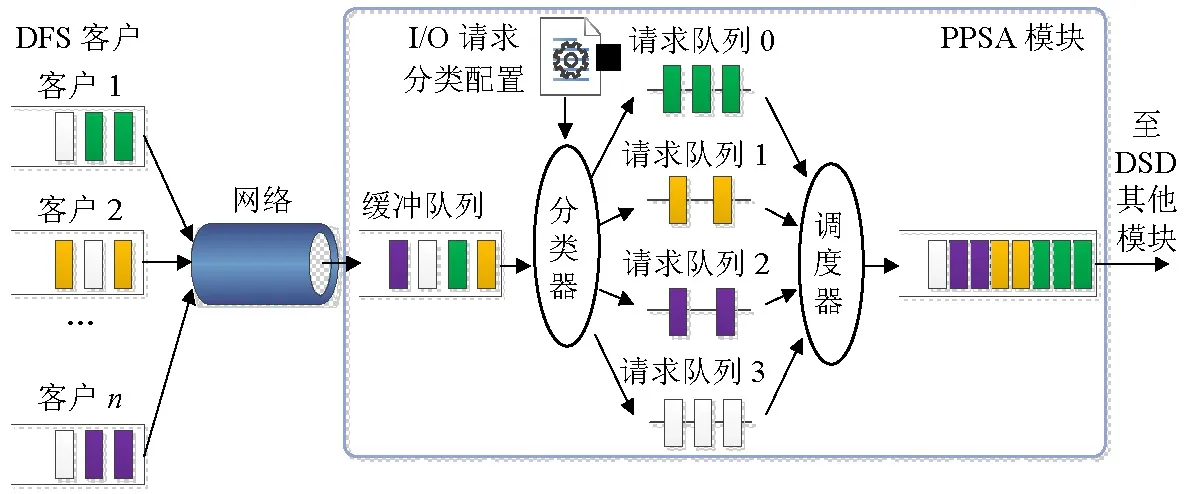
圖1 PPSA工作原理Fig.1 Working principle of PPSA
1.2 I/O請求分類
在云存儲應(yīng)用環(huán)境中,用戶的數(shù)據(jù)請求最終由應(yīng)用服務(wù)器進(jìn)行處理,而應(yīng)用服務(wù)器則通過訪問DFS中的數(shù)據(jù)服務(wù)器來獲取用戶需要的數(shù)據(jù),并將其傳回給用戶.根據(jù)當(dāng)前主流云存儲系統(tǒng)的業(yè)務(wù)類型,可以把應(yīng)用服務(wù)器發(fā)出的I/O請求分為如下4類:
(1) 實(shí)時(shí)I/O請求:通常為在線視頻/音頻播放類I/O請求.這類請求可對應(yīng)于實(shí)時(shí)可變比特率(real-time variable bit rate, rt-VBR)類[13],其生成和發(fā)送具有突發(fā)性和一定的連續(xù)性,要求最小的延遲和一定范圍內(nèi)的傳輸帶寬保證,用符號t0表示;
(2) 非實(shí)時(shí)I/O請求:通常為文件瀏覽類(如在線瀏覽圖片、文檔等)I/O請求.這類請求可對應(yīng)于非實(shí)時(shí)可變比特率(non-real-time variable bit rate, nrt-VBR)類,允許一定程度的數(shù)據(jù)響應(yīng)延遲,用符號t1表示;
(3) 下載I/O請求:通常為數(shù)據(jù)下載類I/O請求.這類請求可對應(yīng)于不指明比特率(unspecified bit rate, UBR)類,對傳輸帶寬和延遲沒有要求,可采用“盡力而為”的方式提供服務(wù),用符號t2表示;
(4) 預(yù)取I/O請求:為提高系統(tǒng)I/O性能,可通過對歷史訪問信息的分析,由DFS客戶端預(yù)測未來的I/O請求并進(jìn)行預(yù)取操作[14].這類請求對應(yīng)于可用比特率(available bit rate, ABR)類[15],對傳輸帶寬和延遲沒有要求,且不要求一定被處理.這類I/O請求可在系統(tǒng)空閑時(shí)進(jìn)行處理,若系統(tǒng)負(fù)載較重,在一定期限內(nèi)未得到處理,則可直接丟棄,用符號t3表示.
在云存儲應(yīng)用環(huán)境中,可采用專一功能的應(yīng)用服務(wù)器/集群來處理不同類型的用戶數(shù)據(jù)請求(如視頻播放服務(wù)器/集群、文件服務(wù)器/集群、下載服務(wù)器/集群).因此,可以通過分類配置文件來配置與應(yīng)用服務(wù)器/集群相對應(yīng)的I/O請求類別.此外,在該配置文件中還可以配置不同I/O請求類型的其他要求(如在線視頻播放時(shí)所要求的最小傳輸帶寬、最大傳輸延遲等),以便分類器對I/O請求進(jìn)行更加精確的分類.
對于預(yù)取請求,由DFS客戶端在發(fā)送請求時(shí)設(shè)置一個(gè)PREFETCH標(biāo)志,PPSA分類器可根據(jù)該標(biāo)志識別出這類I/O請求.
1.3 算法參數(shù)
在PPSA中,來自DFS客戶端的I/O請求經(jīng)分類器后進(jìn)入4個(gè)不同的請求隊(duì)列(隊(duì)列0~3).其中,隊(duì)列0中的I/O請求均為實(shí)時(shí)請求(t0類),隊(duì)列1中的I/O請求均為非實(shí)時(shí)請求(t1類),以此類推.這4個(gè)隊(duì)列的優(yōu)先級分別為Pri0、Pri1、Pri2和Pri3,則有Pri0>Pri1>Pri2>Pri3.
對I/O請求進(jìn)行基于優(yōu)先級的調(diào)度時(shí),高優(yōu)先級隊(duì)列中的請求應(yīng)當(dāng)優(yōu)先處理.但若嚴(yán)格按照優(yōu)先級的大小順序來進(jìn)行處理,在有大量突發(fā)高優(yōu)先級請求的情況下,低優(yōu)先級的I/O請求可能會長時(shí)間等待,甚至發(fā)生超時(shí).基于公平性的考慮,PPSA中的I/O請求處理采用一種周期性的調(diào)度策略——選取一個(gè)適當(dāng)長度的時(shí)間段T作為調(diào)度周期,并把每個(gè)周期分為4個(gè)時(shí)間段:實(shí)時(shí)請求處理階段、非實(shí)時(shí)請求處理階段、下載請求處理階段和預(yù)取請求處理階段,各時(shí)間段內(nèi)的時(shí)間片優(yōu)先用于處理對應(yīng)類型的I/O請求.在一個(gè)調(diào)度周期內(nèi),把實(shí)時(shí)請求、非實(shí)時(shí)請求、下載請求和預(yù)取請求對應(yīng)的時(shí)間段時(shí)長分別記為Trt、Tnrt、Tdld和Tpre,如圖2所示,其計(jì)算方法如式(1)~(4).
(1)
Tnrt=(T-Trt-Tpre)β,
(2)
Tdld=(T-Trt-Tpre)(1-β),
(3)
Tpre=Tσ,
(4)
式中:vi為調(diào)度周期T內(nèi)的實(shí)時(shí)請求對應(yīng)的DFS客戶端與DSD之間的一條I/O流所需的傳輸帶寬,則∑vi表示一個(gè)調(diào)度周期T內(nèi)所有實(shí)時(shí)I/O流所需的傳輸帶寬之和;V為DS的總網(wǎng)絡(luò)傳輸帶寬;α為調(diào)節(jié)因子,以確保預(yù)留的時(shí)間片能夠滿足所有實(shí)時(shí)請求的需求;β為調(diào)節(jié)因子,用于平衡非實(shí)時(shí)請求和下載請求的處理時(shí)長;σ為比例系數(shù),可由用戶自行設(shè)定.
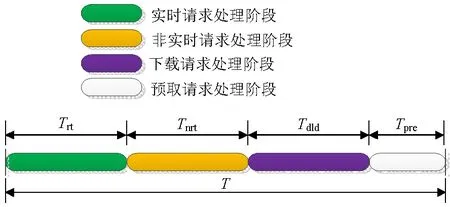
圖2 周期性調(diào)度示意Fig.2 Periodic scheduling process
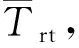
1.4 數(shù)據(jù)結(jié)構(gòu)
對PPSA來說,請求隊(duì)列中I/O請求的組織是影響算法性能的一個(gè)重要因素,因此,必須對這些請求進(jìn)行有效的組織和管理.由于所有I/O請求的目標(biāo)均是數(shù)據(jù)服務(wù)器(DS)上的文件,所以,可以I/O請求的目標(biāo)文件為依據(jù)來組織它們.
PPSA的每個(gè)請求隊(duì)列中I/O請求的組織方式如圖3所示.其中,哈希表存放的是DS上文件的全路徑與請求列表的映射,格式為:
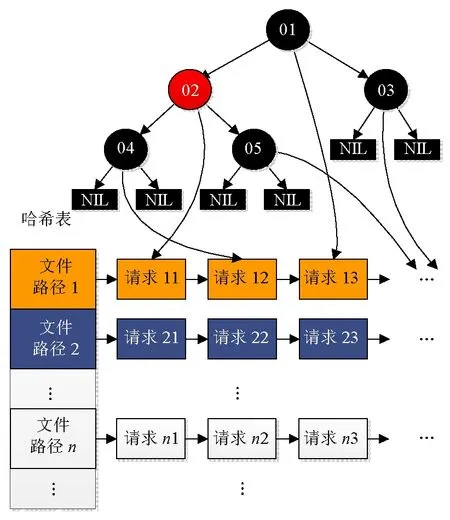
圖3 請求隊(duì)列數(shù)據(jù)結(jié)構(gòu)Fig.3 Data structure of a request queue
為了提高效率,PPSA還對哈希表中每個(gè)隊(duì)列內(nèi)的所有請求建立了一棵紅黑樹,并以每個(gè)請求數(shù)據(jù)在其目標(biāo)文件內(nèi)的偏移量作為關(guān)鍵字.由于紅黑樹中不同節(jié)點(diǎn)的關(guān)鍵字必須不同,所以,對于偏移量相同的I/O請求,在樹的相應(yīng)節(jié)點(diǎn)中使用不同的指針指向?qū)?yīng)的請求即可.
2 算法流程
PPSA在一個(gè)調(diào)度周期T內(nèi)為各類I/O請求分配時(shí)間片配額,配額內(nèi)的時(shí)間片優(yōu)先用于處理對應(yīng)類型的I/O請求.在同一時(shí)刻如果有多類請求滿足調(diào)度條件,則根據(jù)其優(yōu)先級的高低來依次處理實(shí)時(shí)請求、非實(shí)時(shí)請求和下載請求.在調(diào)度周期內(nèi)如果某類I/O請求的時(shí)間片配額有剩余,則剩余的時(shí)間片可被其他種類的I/O請求按優(yōu)先級從高到低的順序來使用.在前三類請求均處理完畢后,若仍有空閑時(shí)間片,則進(jìn)行預(yù)取請求的處理.
PPSA優(yōu)先考慮高優(yōu)先級請求的響應(yīng)性能,同時(shí),通過時(shí)間片資源的預(yù)分配,可有效保障其他種類I/O請求所需的數(shù)據(jù)傳輸帶寬.PPSA的處理流程如下:
Algorithm PPSA
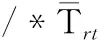
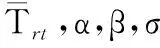
Output:時(shí)間片配額分配
Begin
loop
統(tǒng)計(jì)當(dāng)前所有I/O流的傳輸帶寬之和∑vi
步驟1基于時(shí)間片配額處理取請求
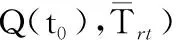
/*一個(gè)調(diào)度周期即為一個(gè)統(tǒng)計(jì)窗口*/
更新一個(gè)統(tǒng)計(jì)窗口內(nèi)隊(duì)列Q的相關(guān)統(tǒng)計(jì)數(shù)據(jù),包括:每條實(shí)時(shí)I/O請求流成功傳送給目標(biāo)DFS客戶端的數(shù)據(jù)總量Rrti
callhandle_Q(非實(shí)時(shí)請求隊(duì)列Q(t1),Tnrt)
更新一個(gè)統(tǒng)計(jì)窗口內(nèi)隊(duì)列Q的相關(guān)統(tǒng)計(jì)數(shù)據(jù),包括:隊(duì)列Q成功傳送給所有DFS客戶端的數(shù)據(jù)總量Rnrt
callhandle_Q(下載請求隊(duì)列Q(t2),Tdld)
更新一個(gè)統(tǒng)計(jì)窗口內(nèi)隊(duì)列Q的相關(guān)統(tǒng)計(jì)數(shù)據(jù),包括:隊(duì)列Q成功傳送給所有DFS客戶端的數(shù)據(jù)總量Rdld
步驟2基于優(yōu)先級處理請求
/*分別計(jì)算當(dāng)前調(diào)度周期內(nèi)剩余的時(shí)間片Trt、Tnrt和Tdld的長度.按優(yōu)先級從高到低進(jìn)行處理*/
for eachQin {Q(t0),Q(t1),Q(t2)}; do
callhandle_Q(Q,trest)
end for
步驟3處理預(yù)取請求
callhandle_Q(Q(t3),trest)
/*采用bestjofk策略(j=8,k=10)預(yù)測I/O請求的未來趨勢,并根據(jù)預(yù)測結(jié)果來調(diào)節(jié)算法參數(shù).之前對Tnrt、Tdld和Tpre的值進(jìn)行了修改*/
根據(jù)式(2)~(4)重新計(jì)算Tnrt、Tdld和Tpre
Unrt←Rnrt/(TnrtV)
/*對最近10個(gè)統(tǒng)計(jì)窗口的8個(gè),當(dāng)Unrt超過100%或小于90%時(shí),對參數(shù)β做正或負(fù)0.1的修正,對參數(shù)α做正或負(fù)0.05的修正*/
Udld←Rdld/(TdldV)
/*對最近10個(gè)統(tǒng)計(jì)窗口的8個(gè),當(dāng)Udld超過100%或者小于90%時(shí),對參數(shù)β做負(fù)或正0.1的修正,對參數(shù)α做負(fù)或正0.05的修正*/
/*設(shè)置參數(shù)邊界為0.10和0.90*/
/*設(shè)置參數(shù)邊界為0.05和0.30*/
end loop
End
Algorithmhandle_Q
Input:請求隊(duì)列Q,Q對應(yīng)的處理時(shí)長為Tq
Output:隊(duì)列Q相關(guān)的統(tǒng)計(jì)數(shù)據(jù)
Begin
if隊(duì)列Q非空 andTq>0 then
N←隊(duì)列Q哈希表的大小
for 隊(duì)列Q哈希表中的每文件file; do
/*時(shí)間片用完則返回,計(jì)算分配給每個(gè)目標(biāo)文件的處理時(shí)長*/
t←Tq/N
pre_offset←上一次訪問的file的offset
ifpre_offset<0 orpre_offset>file對應(yīng)的紅黑樹中的最大offsetthen
pre_offset←0
end if
whilet>0 do
req←file對應(yīng)的紅黑樹中offset≥pre_offset且offset最小的請求
ifreq為預(yù)取請求andreq的等待時(shí)間超過設(shè)定的閾值 then
丟棄請求req
else
處理請求req
t←t—處理req的時(shí)間
Tq←Tq—處理req的時(shí)間
pre_offsetreq的offset
end if
end while
記錄file的pre_offset屬性
end for
end if
End
3 實(shí)驗(yàn)及結(jié)果分析
為了檢驗(yàn)PPSA的性能,使用PFSsim[16]進(jìn)行了仿真實(shí)驗(yàn).PFSsim是一款基于OMNeT++[17]和DiskSim[18]的DFS仿真器,它是跟蹤驅(qū)動(trace-driven)的,主要用來測試和驗(yàn)證DFS的I/O管理策略和一些新的設(shè)計(jì)思想.
PFSsim模擬的DFS的配置為1個(gè)元數(shù)據(jù)服務(wù)器和4個(gè)數(shù)據(jù)服務(wù)器(DS).設(shè)置DS的內(nèi)存容量為8 GB,其本地文件系統(tǒng)(包括緩存)使用的內(nèi)存為6.4 GB,緩存策略為LRU (least recently used );根據(jù)Linux的默認(rèn)臟數(shù)據(jù)率(dirty_ratio,默認(rèn)為內(nèi)存大小的40%),設(shè)置最大臟數(shù)據(jù)大小為3.2 GB;頁面/塊大小均設(shè)置為4 KB;硬盤的訪問速度則根據(jù)真實(shí)的測量結(jié)果來設(shè)定(被測服務(wù)器配置8 GB內(nèi)存,8塊15 000轉(zhuǎn)SAS硬盤組成RAID5陣列).客戶端和數(shù)據(jù)/元數(shù)據(jù)服務(wù)器之間的網(wǎng)絡(luò)帶寬設(shè)置為1 Gbit/s,網(wǎng)絡(luò)延遲為0.2 ms.
實(shí)驗(yàn)中使用的工作負(fù)載特性為實(shí)時(shí)請求(t0類)和下載請求(t2類)的分布均為均勻分布,非實(shí)時(shí)請求(t1類)和預(yù)取請求(t3類)的分布均為泊松分布.
在實(shí)驗(yàn)中,每個(gè)請求流由PFSsim中的一個(gè)客戶端組件來處理,每個(gè)請求所需的數(shù)據(jù)大小均為128 KB.t1類請求的平均到達(dá)速率為每秒2個(gè)請求,t2/t3類請求的平均到達(dá)速率為每秒1個(gè)請求.所有I/O請求均為同步讀請求,DFS客戶端收到一個(gè)請求的響應(yīng)后,才會發(fā)送下一個(gè)請求.PPSA的調(diào)度周期為50 ms.
3.1 響應(yīng)時(shí)間
該實(shí)驗(yàn)用于測試在不同的系統(tǒng)負(fù)荷條件下,分別采用FIFO和PPSA方式進(jìn)行調(diào)度時(shí),系統(tǒng)對不同類型請求的響應(yīng)時(shí)間.實(shí)驗(yàn)設(shè)定了2種不同的負(fù)載環(huán)境,分別為
(1) 輕負(fù)載環(huán)境:每個(gè)DSD均接受20個(gè)t0類請求流(每個(gè)請求流要求的最小數(shù)據(jù)傳輸速度均為5 Mbit/s),50個(gè)t1類請求流,100個(gè)t2類請求流和50個(gè)t3類請求流.
(2) 重負(fù)載環(huán)境:每個(gè)DSD均接受20個(gè)t0類請求流(每個(gè)請求流要求的最小數(shù)據(jù)傳輸速度均為10 Mbit/s),200個(gè)t1類請求流,100個(gè)t2類請求流和50個(gè)t3類請求流.
實(shí)驗(yàn)記錄了進(jìn)入平穩(wěn)狀態(tài)后,分別采用FIFO調(diào)度策略和PPSA調(diào)度策略時(shí),DSD對不同類型I/O請求的響應(yīng)時(shí)間.
從圖4中可以看出,在輕負(fù)載環(huán)境下,采用PPSA調(diào)度方式時(shí),t0類請求和t1類請求的響應(yīng)速度比FIFO調(diào)度策略有提高(前者t0類請求和t1類請求的平均響應(yīng)時(shí)間分別為1 981 μs和2 000 μs,后者對應(yīng)類型請求的平均響應(yīng)時(shí)間分別為2 005 μs和2 008 μs),但差別不大.
在重負(fù)載環(huán)境下,采用PPSA調(diào)度方式時(shí),t0類請求的響應(yīng)時(shí)間相比FIFO調(diào)度方式有較大降低(前者平均值為2 045 μs,后者平均值為2 201 μs);而t1類請求的響應(yīng)時(shí)間相比FIFO調(diào)度方式有所降低,但差別不是很大(前者平均值為2 152 μs,后者平均值為2 196 μs)
由于系統(tǒng)對每個(gè)I/O請求的響應(yīng)時(shí)間包含了數(shù)據(jù)在網(wǎng)絡(luò)上的傳輸時(shí)間(約1 000 μs)和網(wǎng)絡(luò)延遲(400 μs),所以,采用PPSA調(diào)度方式,在重負(fù)載情況下DSD對實(shí)時(shí)請求的響應(yīng)速度提高了20%左右,而對非實(shí)時(shí)請求的響應(yīng)速度也有一定的提升.當(dāng)然,這種性能提升是以低優(yōu)先級請求響應(yīng)性能的降低為代價(jià)的,可以通過調(diào)節(jié)算法的參數(shù)來對不同優(yōu)先級的請求進(jìn)行平衡.
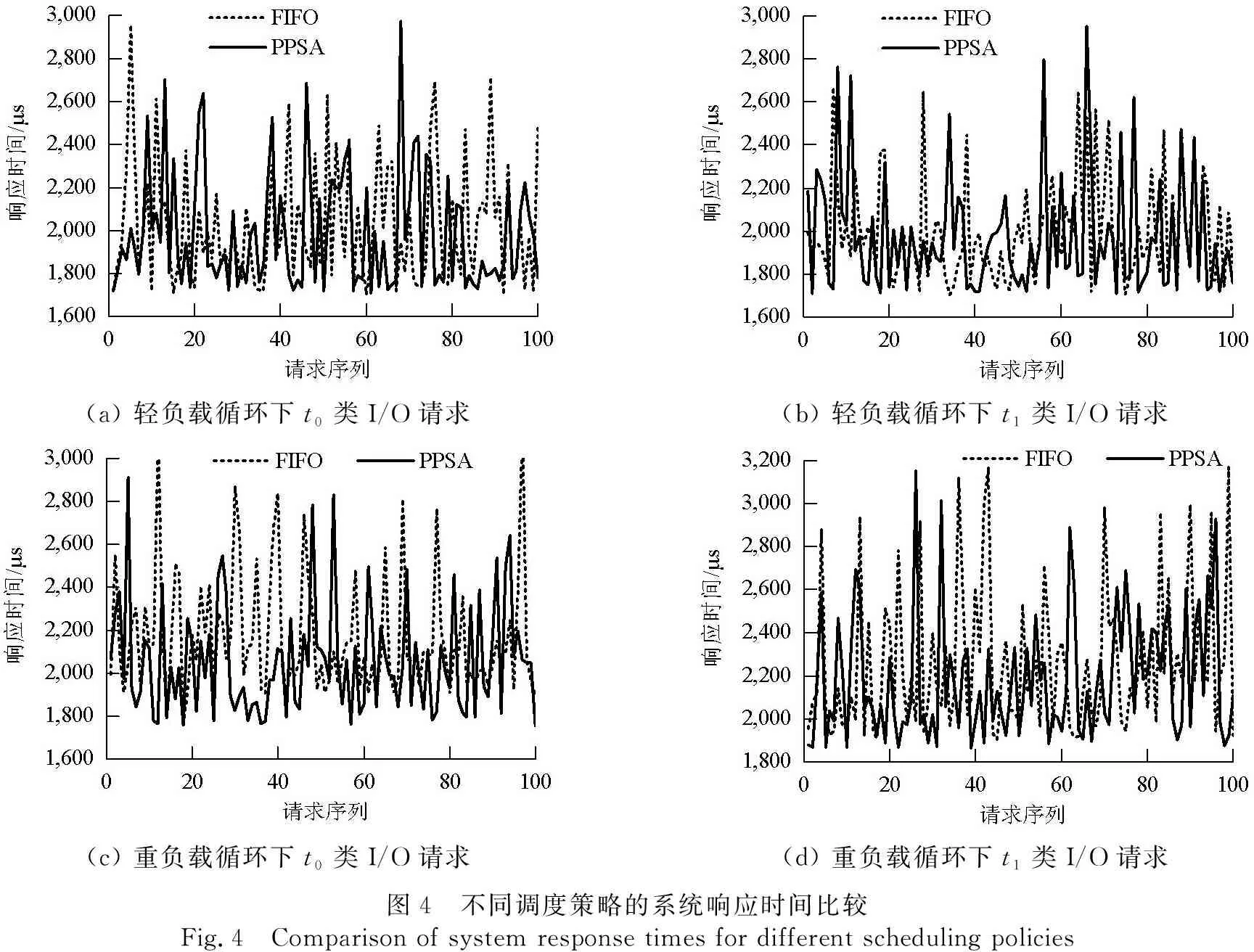
(a) 輕負(fù)載循環(huán)下t0類I/O請求(b) 輕負(fù)載循環(huán)下t1類I/O請求(c) 重負(fù)載循環(huán)下t0類I/O請求(d) 重負(fù)載循環(huán)下t1類I/O請求圖4 不同調(diào)度策略的系統(tǒng)響應(yīng)時(shí)間比較Fig.4 Comparison of system response times for different scheduling policies
3.2 平均等待隊(duì)列長度
該實(shí)驗(yàn)用于比較DSD采用不同的調(diào)度算法時(shí),系統(tǒng)在不同負(fù)荷下對各類請求的響應(yīng)情況.統(tǒng)計(jì)各類請求的平均等待隊(duì)列長度和最大等待隊(duì)列長度,并將統(tǒng)計(jì)結(jié)果與FIFO算法及多隊(duì)列優(yōu)先級調(diào)度算法相比較.實(shí)驗(yàn)中,t0類請求流要求的最小數(shù)據(jù)傳輸速度均為5 Mbit/s.
表1為其他類型請求負(fù)載一定的條件下,t0類請求流的數(shù)量對不同類型請求隊(duì)列的平均隊(duì)列長度的影響.實(shí)驗(yàn)中,t1類請求流的數(shù)量為200,t2類請求流的數(shù)量為300,t3類請求流的數(shù)量為100.從表1中可以看出,采用FIFO調(diào)度策略時(shí),所有類型請求的平均等待隊(duì)列長度基本相同;這是因?yàn)樵趯?shí)驗(yàn)中設(shè)置的條件使響應(yīng)數(shù)據(jù)所需的傳輸帶寬超過了網(wǎng)絡(luò)帶寬,因此,不管t0類請求流的數(shù)量如何增加,系統(tǒng)對所有類型請求的響應(yīng)性能都沒有變化.
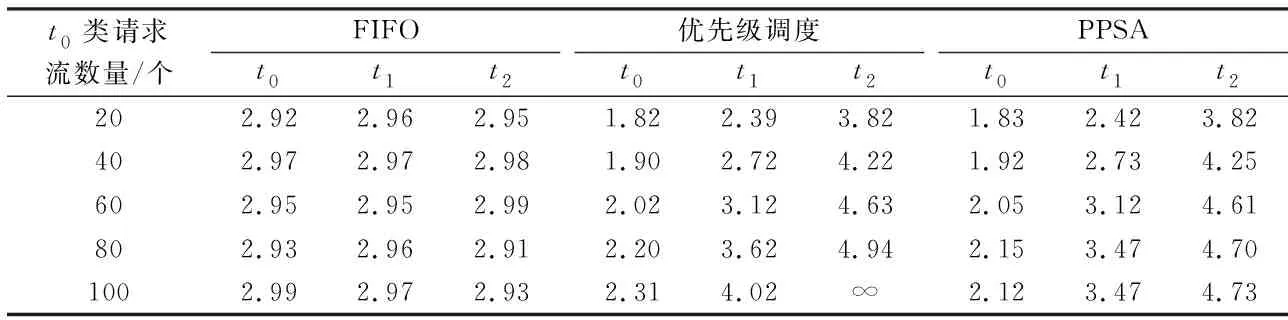
表1 t0類請求流數(shù)目對系統(tǒng)響應(yīng)性能的影響Tab.1 Effect of the number of class t0 request flows on the system response performance
采用優(yōu)先級調(diào)度策略時(shí),隨著t0類請求流數(shù)量的增加,系統(tǒng)優(yōu)先保證高優(yōu)先級請求的響應(yīng)性能,但是對低優(yōu)先級請求的性能不做保證;當(dāng)t0類請求流的數(shù)量增加到100時(shí),所有的t2類請求均無法得到響應(yīng).采用PPSA調(diào)度策略時(shí),在算法的設(shè)定參數(shù)范圍內(nèi),系統(tǒng)的響應(yīng)性能與優(yōu)先級調(diào)度策略相當(dāng);當(dāng)t0類請求流的數(shù)量增加到80時(shí),由于算法的調(diào)節(jié)作用,t0類、t1類和t2類請求的響應(yīng)性能均優(yōu)于優(yōu)先級調(diào)度策略;當(dāng)t0類請求流的數(shù)量增加到100時(shí),不僅t0類和t1類請求的響應(yīng)性能有較大提高,而且t2類請求也能夠獲得一定的處理機(jī)會.
表2為其他類型請求負(fù)載一定的條件下,t1類請求流的數(shù)量對系統(tǒng)響應(yīng)性能的影響.實(shí)驗(yàn)中,t0類請求流的數(shù)量為80,t2類請求流的數(shù)量為200,t3類請求流的數(shù)量為100.從表2中可以得出和表1基本相同的結(jié)論,采用FIFO調(diào)度策略時(shí),所有類型請求的響應(yīng)性能基本相同;采用優(yōu)先級調(diào)度策略時(shí),在帶寬資源不夠時(shí)會犧牲低優(yōu)先級請求的響應(yīng)性能;采用PPSA調(diào)度策略時(shí),雖然在帶寬資源不夠時(shí)會犧牲一些低優(yōu)先級請求的響應(yīng)性能,但算法保證這種性能犧牲不會超過一定的限度.
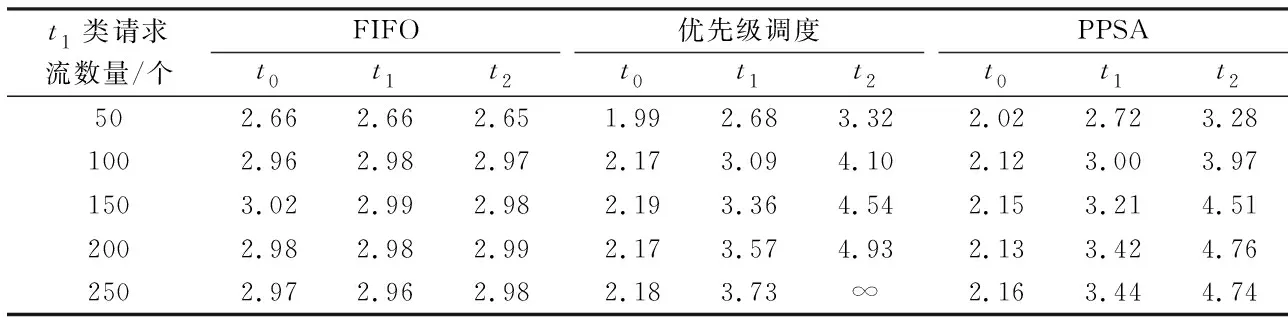
表2 t1類請求流數(shù)目對系統(tǒng)響應(yīng)性能的影響Tab.2Effect of the number of class t1 request flows on the system response performance
4 結(jié)束語
PPSA算法在兼顧公平調(diào)度和更短的響應(yīng)時(shí)間上,取得了更好的效果.在云存儲應(yīng)用環(huán)境中,用戶數(shù)據(jù)一般存儲在DFS中.為了更好地響應(yīng)不同種類的IO請求,在提高調(diào)度效率的同時(shí)兼顧不同類型請求調(diào)度的公平性,PPSA結(jié)合實(shí)際應(yīng)用場景對I/O請求進(jìn)行分類,并賦予不同的優(yōu)先級;然后以經(jīng)驗(yàn)值為周期,以分時(shí)間片的方式對不同優(yōu)先級的請求進(jìn)行周期性的調(diào)度.仿真實(shí)驗(yàn)結(jié)果顯示,PPSA在兼顧公平性的前提下,還能有效降低實(shí)時(shí)請求的響應(yīng)時(shí)間,可以為云存儲用戶提供更好的使用體驗(yàn).
猜你喜歡
教學(xué)考試(高考化學(xué))(2021年2期)2021-05-30 06:15:52
中學(xué)生數(shù)理化·高一版(2020年3期)2020-04-21 08:03:20
中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學(xué)生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數(shù)學(xué)大世界(2018年1期)2018-04-12 05:39:14
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:54:39
