基于CNN雙目特征點(diǎn)匹配目標(biāo)識(shí)別與定位研究
2018-07-16 11:54:06蔣強(qiáng)衛(wèi)甘興利李雅寧
無線電工程 2018年8期
蔣強(qiáng)衛(wèi),甘興利,李雅寧
(1.哈爾濱工程大學(xué) 信息與通信工程學(xué)院,黑龍江 哈爾濱 150000; 2.衛(wèi)星導(dǎo)航系統(tǒng)與裝備技術(shù)國家重點(diǎn)實(shí)驗(yàn)室,河北 石家莊 050081)
0 引言
物體識(shí)別和定位是機(jī)器人視覺導(dǎo)航、智能監(jiān)控、服務(wù)型機(jī)器人、工業(yè)自動(dòng)化和汽車安全駕駛等領(lǐng)域的非常關(guān)鍵的技術(shù),與之相關(guān)的技術(shù)也得到了前所未有的發(fā)展和重視。近幾年興起的深度學(xué)習(xí)是研究的熱點(diǎn)[1],在無人駕駛和機(jī)器人等方面應(yīng)用廣泛。卷積神經(jīng)網(wǎng)絡(luò)作為深度學(xué)習(xí)的重要分支,通過大量的樣本數(shù)據(jù)訓(xùn)練,學(xué)習(xí)到物體相應(yīng)特征,從而實(shí)現(xiàn)高效的物體識(shí)別。雙目立體視覺定位因其具有較大測量范圍、較高的測量精度和低成本,成為機(jī)器人視覺定位、無人駕駛等領(lǐng)域最常用的一種方法。
目前有許多方法用于檢測障礙物和測距(傳統(tǒng)的目標(biāo)測量方法,如激光雷達(dá)、紅外測距和超聲波測距等),但這些傳統(tǒng)測距技術(shù)所用的傳感器容易受到其他傳感器的影響和環(huán)境干擾,導(dǎo)致測距不準(zhǔn),存在的一個(gè)最大缺點(diǎn)是不能檢測與識(shí)別目標(biāo)物體[2]。
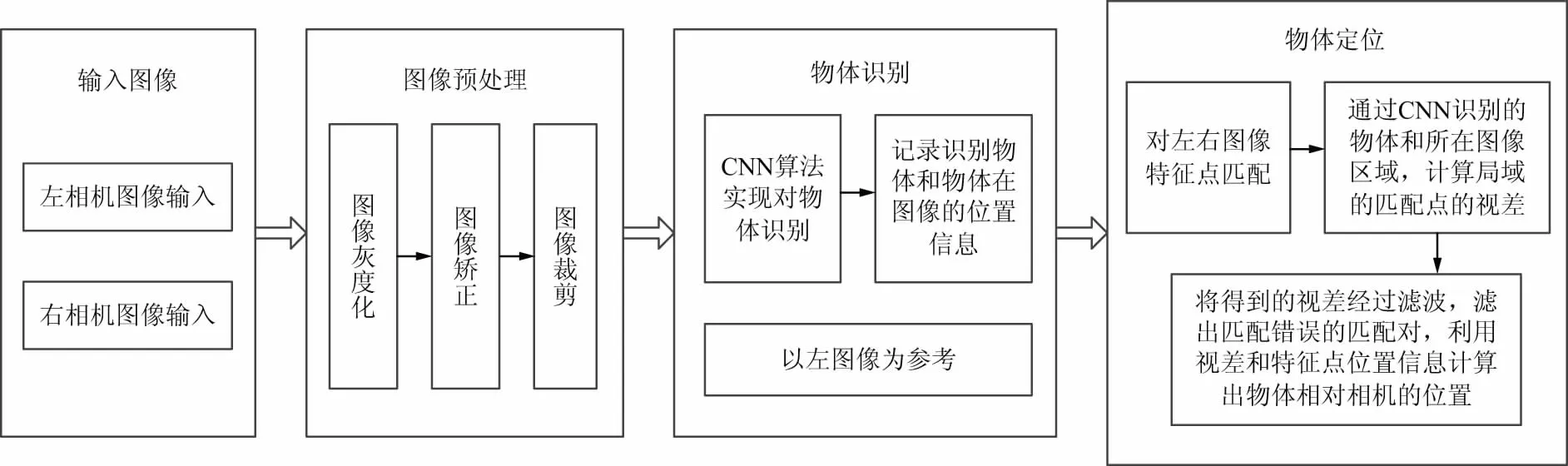
圖1 基于CNN雙目視覺物體識(shí)別和定位算法流程
據(jù)此,本文提出了基于CNN雙目視覺物體識(shí)別與定位的方法,其實(shí)現(xiàn)流程如圖1所示。在特征點(diǎn)匹配算法的研究中發(fā)現(xiàn),SURF算法[3]是一種有效的特征點(diǎn)提取和匹配的算法[4],相比于傳統(tǒng)的SIFT算法具有更高的效率和穩(wěn)定性[5]。在雙目三維重建中,重投影矩陣Q隨著目標(biāo)與攝像頭的距離變化也會(huì)發(fā)生相應(yīng)的變化[6],進(jìn)而影響到定位精度,通過采樣大量數(shù)據(jù),通過最小二乘法擬合位置和視差模型。實(shí)驗(yàn)結(jié)果表明,改進(jìn)后的三維重建模型有效提高了雙目視覺目標(biāo)定位的精度。
1 目標(biāo)識(shí)別
物體識(shí)別,有時(shí)又叫做目標(biāo)檢測[7],其任務(wù)有2個(gè):① 在給定的測試圖片的情況下,預(yù)測其中包含的物體實(shí)例的類別;② 預(yù)測給定測試圖像中物體的位置,用矩形框畫出來,效果如圖2所示。

圖2 物體識(shí)別實(shí)例
1.1 卷積神經(jīng)網(wǎng)絡(luò)模型
卷積神經(jīng)網(wǎng)絡(luò)是由Lencun在1989年提出的一種網(wǎng)絡(luò)結(jié)構(gòu),現(xiàn)已成為語言分析和圖像識(shí)別領(lǐng)域研究的熱點(diǎn)。它的權(quán)值共享網(wǎng)絡(luò)和生物神經(jīng)網(wǎng)絡(luò)類似,降低了網(wǎng)絡(luò)的復(fù)雜度,減少權(quán)值的數(shù)量。從結(jié)構(gòu)上看,CNN是一個(gè)多層的神經(jīng)網(wǎng)絡(luò),主要有輸入層、卷積層、池化層和全連接層組成。每層由多個(gè)二維平面組成,而每個(gè)平面是由多個(gè)獨(dú)立的神經(jīng)元組成,經(jīng)典的LeNet-5結(jié)構(gòu)如圖3所示。
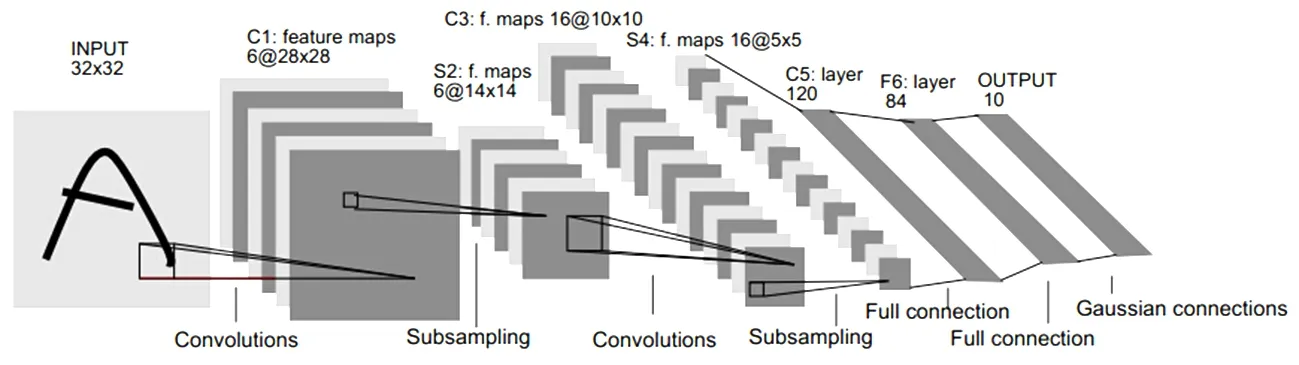
圖3 LeNet-5卷積神經(jīng)網(wǎng)絡(luò)模型結(jié)構(gòu)
輸入層:通常是輸入為二值圖像或RGB彩色圖像,在輸入之前對圖像濾波[8]、尺寸修改等預(yù)處理操作以提高網(wǎng)絡(luò)識(shí)別結(jié)果。
卷積層:使用卷積層的原因是通過卷積運(yùn)算,可以使原信號特征增強(qiáng),并且降低噪音[9]。
池化層:也叫降采樣層,根據(jù)圖像局部相關(guān)性原理,對圖像進(jìn)行子采樣,以減少計(jì)算量,同時(shí)保持圖像旋轉(zhuǎn)不變性[10],還可以混淆特征的具體位置。因?yàn)槟硞€(gè)特征找出來后,它的具體位置已經(jīng)不重要了,只需要這個(gè)特征與其他的相對位置。
全連接層:一般采用softmax全連接[11],得到的激活值即CNN提取到的圖片特征,在整個(gè)CNN中起到“分類器”的作用,即全連接層將學(xué)到的“分布式特征表示”映射到樣本標(biāo)記空間。
1.2 基于SSD模型的物體識(shí)別
采用由北卡羅來納大學(xué)教堂山分校的Weiliu博士提出的物體識(shí)別模型(Single Shot MultiBox Detector,SSD),它既保證了速度,又保證了精度,與現(xiàn)有的檢測模型一樣,將檢測過程整合成一個(gè)單一的深度神經(jīng)網(wǎng)絡(luò),便于訓(xùn)練和優(yōu)化,同時(shí)提高了精度。該網(wǎng)絡(luò)綜合了Faster R-CNN[12]的anchor box和YOLO[13]的單個(gè)神經(jīng)網(wǎng)絡(luò)檢測思路,既有Faster R-CNN的準(zhǔn)確度,又有YOLO的檢測速度,可以實(shí)現(xiàn)高準(zhǔn)確度的實(shí)時(shí)檢測。目標(biāo)檢測算法性能對比如表1所示。
表1目標(biāo)檢測算法性能對比
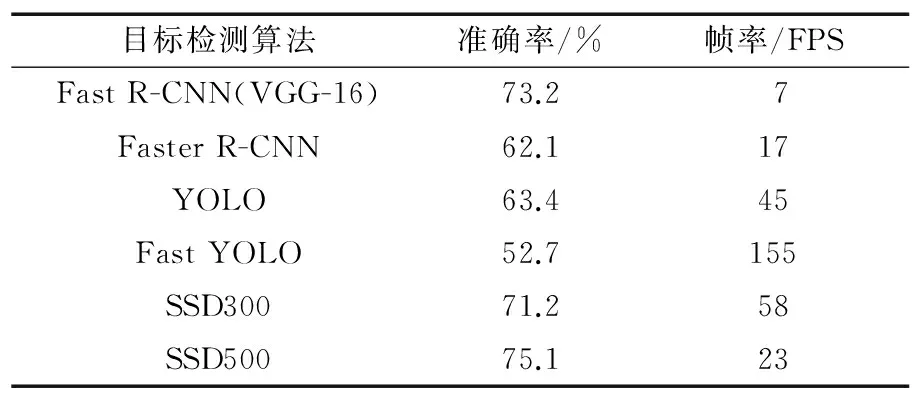
目標(biāo)檢測算法準(zhǔn)確率/%幀率/FPSFast R-CNN(VGG-16)73.27Faster R-CNN62.1 17YOLO63.4 45Fast YOLO52.7155SSD30071.2 58SSD50075.1 23
SSD是一種多尺度特征圖檢測模型,其檢測網(wǎng)絡(luò)模型如圖4所示。將輸入圖像resize到300*300,再將圖像輸入到VGG卷積神經(jīng)網(wǎng)絡(luò)中提取特征,然后添加額外的卷積層,這些卷積層的大小是逐層遞減的,可以在多尺度下進(jìn)行目標(biāo)檢測。模型選擇的特征圖包括:38*38(block4),19*19(block7),10*10(block8),5*5(block9),3*3(block10),1*1(block11)。每一個(gè)block中包含物體實(shí)例的可能性,進(jìn)行一個(gè)非極大值抑制(Non-maximum suppression)得到最終的置信度。本文采用PASCLA VOC數(shù)據(jù)集訓(xùn)練自己的網(wǎng)絡(luò),包括20類物體,加上背景一共21類。
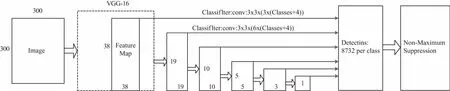
圖4 SSD多尺度特征檢測模型
2 SURF特征點(diǎn)匹配算法
SURF算法是對SIFT算法的改進(jìn)和優(yōu)化。SURF借鑒了SIFT中的簡化近似思想,將DoH中的高階二階微分模板進(jìn)行近似簡化,用積分圖像提高卷積的運(yùn)算速度,犧牲很小的精度為代價(jià),獲得更快的特征點(diǎn)匹配運(yùn)算速度。SURF特征點(diǎn)匹配主要包括3個(gè)步驟:
① 特征點(diǎn)提取。計(jì)算圖像的積分圖像,采用方框?yàn)V波近似代替二階高斯濾波[14],計(jì)算待候選點(diǎn)和周圍點(diǎn)的Hessian值[15],判斷候選點(diǎn)與周圍的值是否最大,如果是最大,則為特征點(diǎn)。
② 特征點(diǎn)描述。在檢測到的特征點(diǎn)周圍小區(qū)域上計(jì)算Haar小波[16],并計(jì)算其4種和以構(gòu)建特征描述。
③ 利用特征點(diǎn)描述向量的匹配。
2.1 特征點(diǎn)檢測
SURF算法對特征點(diǎn)檢測基于Hessian矩陣,給定積分圖像中的一點(diǎn)x(x,y)在點(diǎn)x處,尺度為σ的Hessian矩陣H(x,σ)定義如下:
(1)
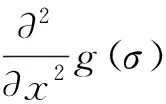
為了將模板與圖像的卷積轉(zhuǎn)化為盒子濾波(Box Filter)運(yùn)算,需要對高斯二階微分模板進(jìn)行簡化,簡化后的模板由幾個(gè)矩形區(qū)域組成,矩形區(qū)域內(nèi)填充同一值,如圖5所示,在簡化模板的白色區(qū)域的值為1,黑色區(qū)域的值為-1,灰色區(qū)域的值為0。對于σ=1.2的高斯二階微分濾波,設(shè)定模板的大小為9*9,并用它作為最小的尺度空間值對圖像進(jìn)行濾波和斑點(diǎn)檢測。使用Dxx、Dyy和Dxy表示模板與圖像進(jìn)行卷積的結(jié)果,這樣,便可將Hessian矩陣的行列式做如下簡化:
Det(Happrox)=DxxDyy-(0.9Dxy)2,
(2)
使用近似的Hessian矩陣行列式來表示圖中的某一點(diǎn)的斑點(diǎn)響應(yīng)值,遍歷圖像中所有的像素點(diǎn),使用不同的模板尺寸,便形成了尺度的斑點(diǎn)響應(yīng)的金字塔圖像,利用這一金字塔圖像,在三維(x,y,σ)空間中,每個(gè)3*3*3的區(qū)域進(jìn)行非極大值抑制,選取比相鄰的26個(gè)點(diǎn)響應(yīng)值都大的點(diǎn)作為斑點(diǎn)的特征點(diǎn),即可得到穩(wěn)定的SURF特征點(diǎn)的位置和尺度值。

(a) Lxx的簡化模型

(b) Lxy的簡化模型
2.2 特征點(diǎn)描述
通過上一步檢測出來的特征點(diǎn),對每一個(gè)特征點(diǎn)為圓心和6σ為半徑的圓形區(qū)域計(jì)算x和y方向的Haar小波響應(yīng)[17]。Haar小波響應(yīng)模型如圖6所示,以特征點(diǎn)為中心對這些響應(yīng)進(jìn)行高斯加權(quán)。采用張角為π/3的扇形區(qū)域的滑動(dòng)窗口,并對滑動(dòng)窗口內(nèi)圖像Haar小波x和y方向的響應(yīng)進(jìn)行累加,得到一個(gè)局部的方向向量,轉(zhuǎn)動(dòng)扇形遍歷整個(gè)圓,選擇最長的方向作為特征點(diǎn)的主方向。
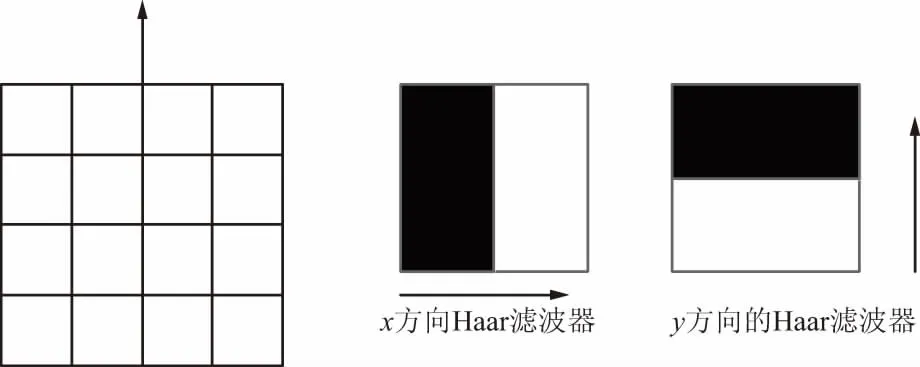
圖6 Haar濾波器模型
以特征點(diǎn)為中心,將坐標(biāo)軸旋轉(zhuǎn)到主方向,即
(3)
沿特征點(diǎn)的主方向?qū)?0*20的圖像劃分為4*4的子塊,每個(gè)子塊利用2 s的Haar小波模板進(jìn)行響應(yīng)值計(jì)算,然后對響應(yīng)值進(jìn)行統(tǒng)計(jì)(∑dx,∑dy,∑|dx|,∑|dy|)形成特征矢量。所有子區(qū)域的向量構(gòu)成該點(diǎn)的特征向量,得到長度4*4*4=64維的特征向量。
2.3 特征點(diǎn)匹配
得到左右2幅圖的特征點(diǎn)后,采用歐式距離來判斷匹配特征點(diǎn),為了剔除誤匹配的點(diǎn),以左圖為參考圖像,因?yàn)樽笥覉D像經(jīng)過矯正后幾乎是平行的,所以檢索的時(shí)候,只檢索右邊圖像[y-3,y+3]垂直范圍[18],提高了檢索效率和匹配精度。
3 三維重建
雙目立體視覺三維重建是基于視差原理,以左相機(jī)為參考,左圖像上的任意一點(diǎn)要能在右圖像上找到對應(yīng)的匹配點(diǎn),就可以確定出該點(diǎn)的三維信息,上面闡述了采用SURF特征點(diǎn)匹配算法,識(shí)別檢測圖像的特征點(diǎn)和匹配,通過神經(jīng)網(wǎng)絡(luò)到目標(biāo)的區(qū)域,計(jì)算區(qū)域內(nèi)的匹配點(diǎn)的視差,從而得到目標(biāo)的三維信息。工作原理如圖7所示。
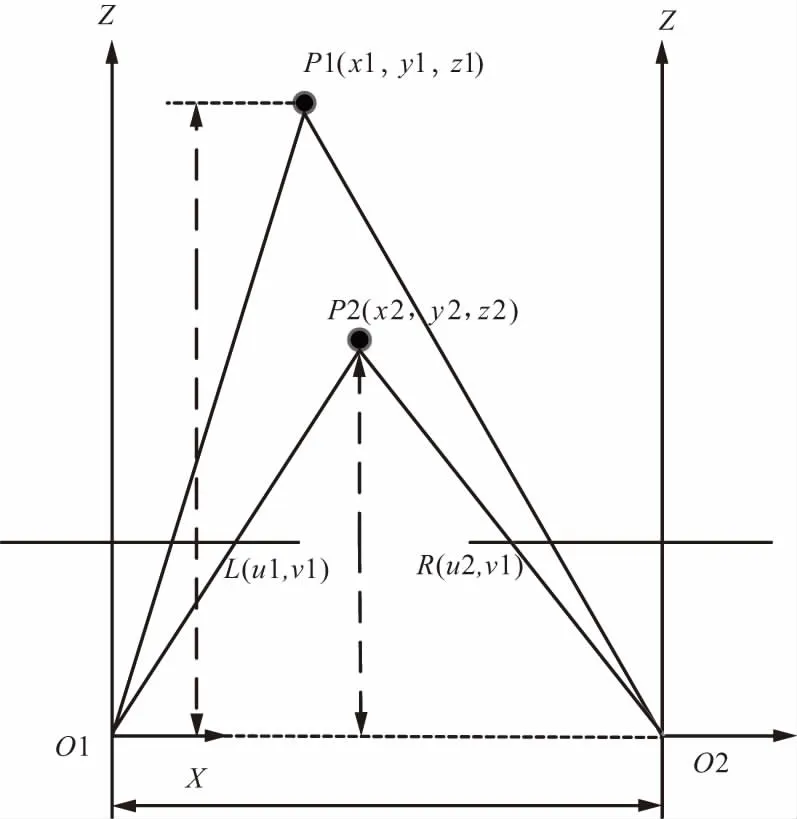
圖7 雙目定位場景模型
由三角測量原理,即由2臺(tái)攝像機(jī)的圖像平面和被測物體之間構(gòu)成一個(gè)三角形,如果已知2臺(tái)攝像機(jī)之間的位置關(guān)系,便可以通過三角幾何關(guān)系求解空間物體特征點(diǎn)的三維坐標(biāo)。以左攝像機(jī)的O1為原點(diǎn)坐標(biāo)系,通過相機(jī)標(biāo)定和矯正,得出重映射矩陣Q,得到世界坐標(biāo)系和相機(jī)坐標(biāo)系關(guān)系,進(jìn)而計(jì)算場景點(diǎn)P1(x1,y1,z1)的計(jì)算關(guān)系式如下:
tempx=Q[0][0]×x1+Q[0][3],
(4)
tempy=Q[1][1]×y1+Q[1][3],
(5)
temp=Q[2][3],
(6)
temp=Q[3][2]×(u1-u2)+Q[3][3],
(7)
(8)
實(shí)際實(shí)驗(yàn)過程中發(fā)現(xiàn),導(dǎo)致的誤差與相機(jī)標(biāo)定誤差和匹配點(diǎn)誤差有關(guān)[19],通過均值濾波,濾除一些異常匹配點(diǎn),計(jì)算均值作為目標(biāo)視差。距離和視差并非完全符合以上關(guān)系式,采用最小二乘曲線擬合,對距離和視差非線性優(yōu)化,提高定位精度。
4 實(shí)驗(yàn)結(jié)果及分析
下面開展物體識(shí)別、特征點(diǎn)匹配和物體定位的綜合實(shí)驗(yàn)。卷積神經(jīng)網(wǎng)絡(luò)算法是基于Caffe(Converlution Architecture for Fast Feature Embedding)框架編寫,特征點(diǎn)匹配和定位算法是C++編寫,通過Python腳本調(diào)用這2個(gè)功能模塊。開發(fā)環(huán)境采用Ubuntu系統(tǒng)。實(shí)驗(yàn)中采用2個(gè)Logitech C992攝像頭,DELL電腦(Intel i7、GTX960,內(nèi)存4G,顯存4G),組成平行雙目視覺系統(tǒng)。系統(tǒng)實(shí)物圖如圖8所示。

圖8 雙目視覺目標(biāo)識(shí)別與定位系統(tǒng)
目標(biāo)識(shí)別實(shí)驗(yàn):采用PASCLA VOC數(shù)據(jù)集訓(xùn)練自己的網(wǎng)絡(luò),一共包括20類物體。單一目標(biāo)識(shí)別實(shí)驗(yàn)如圖9所示,該系統(tǒng)識(shí)別到顯示器,置信度達(dá)到了0.997。目標(biāo)像素中心采樣結(jié)果如圖10所示。實(shí)驗(yàn)結(jié)果表明,目標(biāo)中心變動(dòng)范圍在(-2,2),識(shí)別目標(biāo)穩(wěn)定,保證后續(xù)目標(biāo)定位穩(wěn)定性。

圖9 目標(biāo)識(shí)別實(shí)驗(yàn)
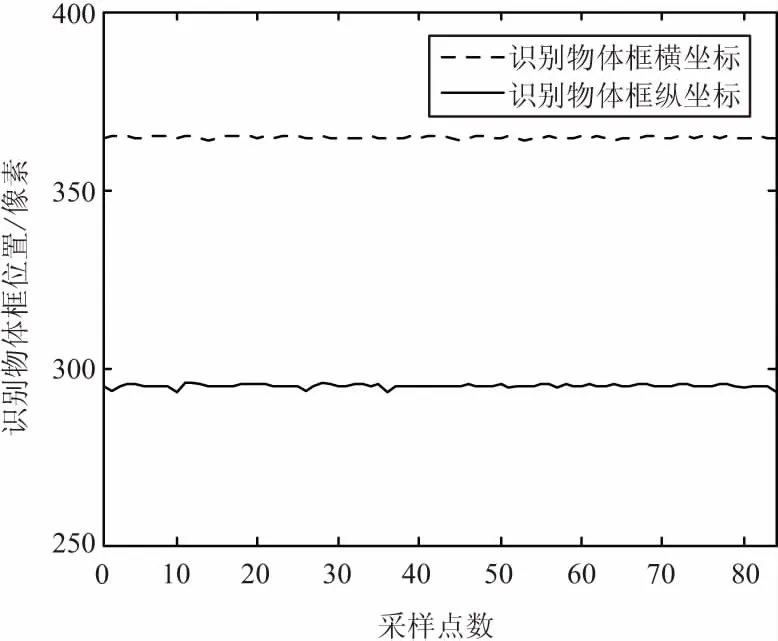
圖10 目標(biāo)像素中心采樣結(jié)果
特征點(diǎn)匹配實(shí)驗(yàn):通過SURF特征點(diǎn)匹配算法,得到目標(biāo)左右圖像的匹配點(diǎn),如圖11所示。

圖11 SURF特征點(diǎn)匹配結(jié)果
計(jì)算目標(biāo)區(qū)域類的視差值如圖12所示,通過中值濾波后的視差值,去除了異常點(diǎn)視差,穩(wěn)定在(68,74)范圍,可以提高后續(xù)的定位精度。
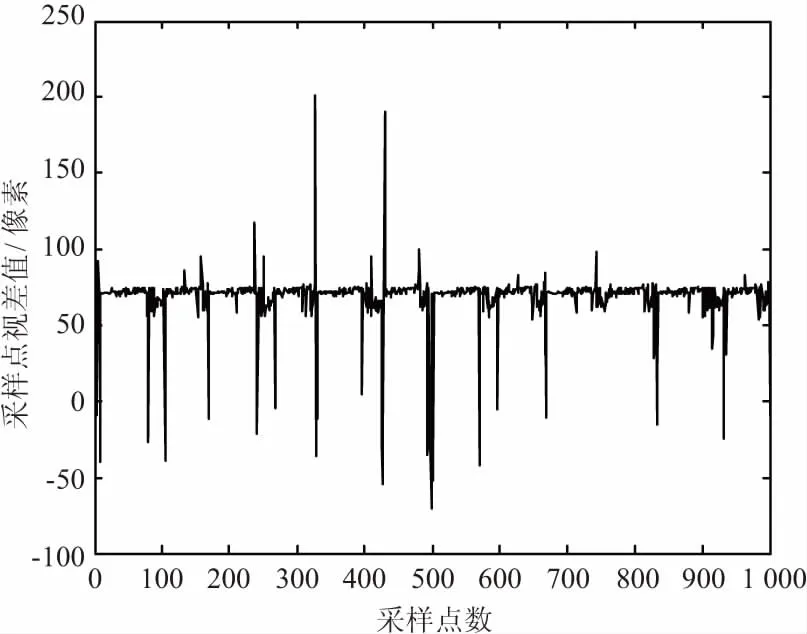
(a) 未濾波的視差
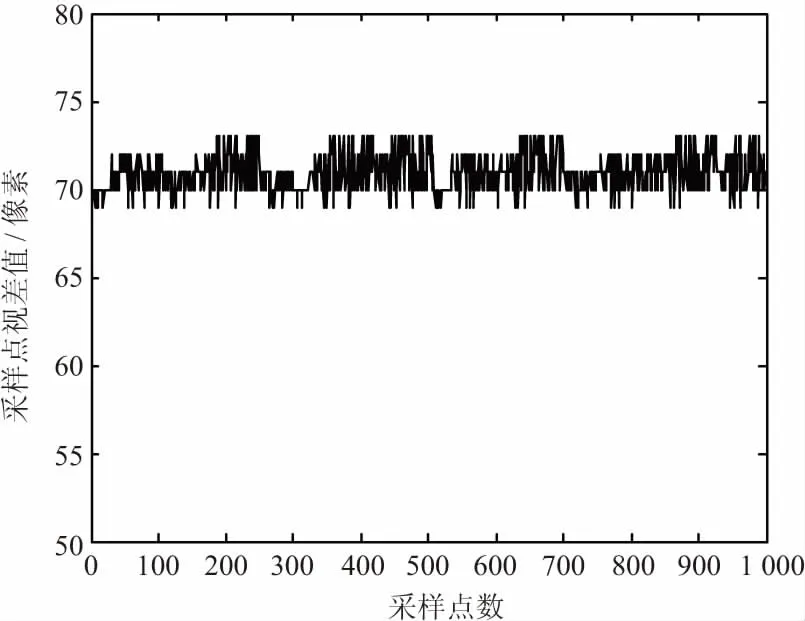
(b) 濾波后的視差值圖12 目標(biāo)范圍內(nèi)計(jì)算的視差值
目標(biāo)識(shí)別與定位實(shí)驗(yàn):選取單一的目標(biāo)進(jìn)行目標(biāo)識(shí)別與定位實(shí)驗(yàn)。視差和距離(z軸方向)的關(guān)系,如圖13所示。
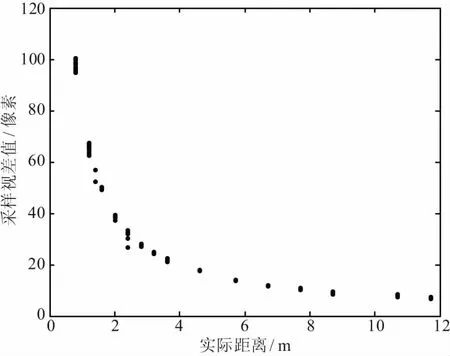
(a) 視差值/距離分布
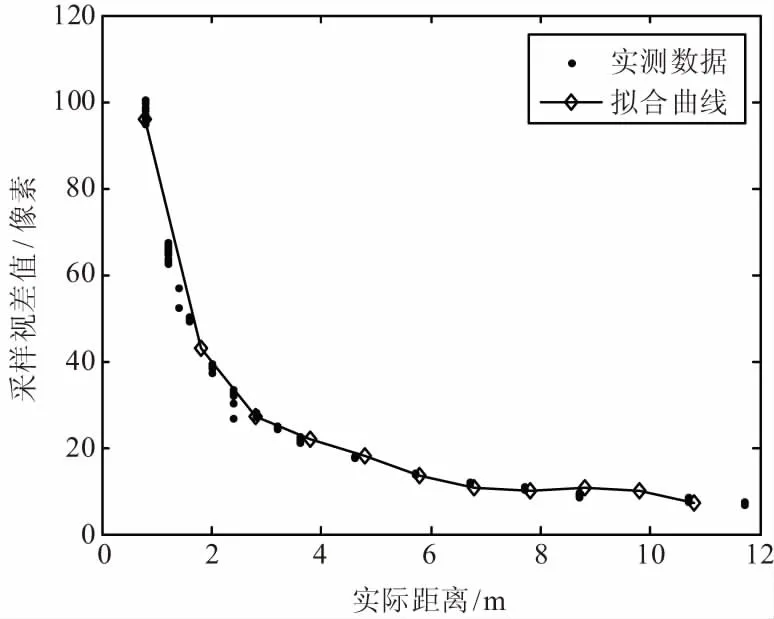
(b) 擬合視差值/距離曲線圖13 視差/距離分布
通過對比擬合和濾波后測距誤差明顯減少,從而提高定位精度和穩(wěn)定性,如圖14所示。
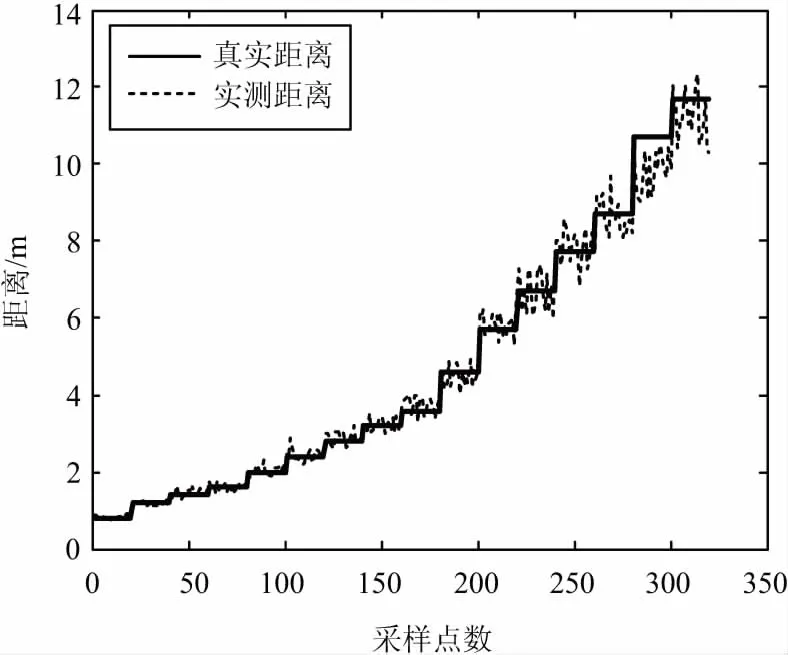
(a) 實(shí)測數(shù)據(jù)/真實(shí)數(shù)據(jù)對比
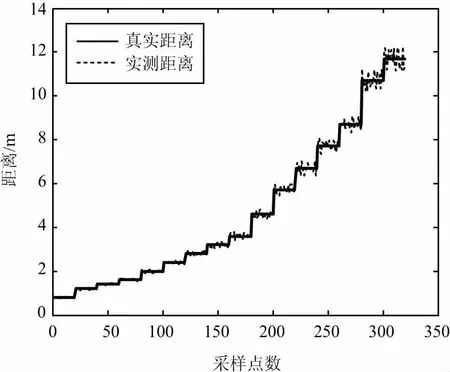
(b) 擬合、濾波后實(shí)測數(shù)據(jù)/真實(shí)數(shù)據(jù)對比圖14 測距誤差對比
該系統(tǒng)能夠精準(zhǔn)地實(shí)現(xiàn)目標(biāo)識(shí)別與定位,實(shí)測結(jié)果如圖15所示。

圖15 實(shí)測結(jié)果
實(shí)驗(yàn)結(jié)果表明,通過擬合后的雙目立體模型定位精度明顯提高,基于CNN雙目特征點(diǎn)匹配目標(biāo)檢測與定位系統(tǒng),能夠很好地實(shí)現(xiàn)目標(biāo)識(shí)別與定位。
5 結(jié)束語
針對傳統(tǒng)的物體識(shí)別算法識(shí)別物體類別單一、基于物體特定特征實(shí)現(xiàn)識(shí)別的精度不高等問題,本文采用CNN改進(jìn)雙目物體識(shí)別與定位系統(tǒng)實(shí)現(xiàn)物體識(shí)別類別多樣,識(shí)別精度也有所提高。針對雙目標(biāo)定誤差,對誤差進(jìn)行分析,對實(shí)驗(yàn)結(jié)果和標(biāo)定相機(jī)參數(shù)進(jìn)行擬合,濾除實(shí)驗(yàn)異常點(diǎn),提高物體定位精度。提出的CNN和雙目視覺原理結(jié)合以實(shí)現(xiàn)物體識(shí)別和定位,識(shí)別速度、精度和定位精度達(dá)到實(shí)用性要求,可以廣泛應(yīng)用于機(jī)器人視覺方面。在未來的工作中,通過GPU加速,提高匹配速度,實(shí)現(xiàn)在更高要求的實(shí)用場景中應(yīng)用。
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
