一種基于插值擬合的復雜刀具軌跡在線平滑壓縮算法
2018-07-17 09:51:10何改云王太勇董甲甲張永賓
中國機械工程 2018年13期
關鍵詞:方法
陶 浩 何改云 王太勇 董甲甲 張永賓
天津大學機械工程學院,天津,300072
0 引言
在復雜曲線曲面的數控加工中,傳統的刀具軌跡生成方法是通過CAM系統生成G01代碼,再將其輸入到數控系統中進行直線插補加工。該方法原理簡單,但相鄰線段的銜接處易出現速度和加速度的波動,從而顯著降低零件的加工質量。為了減小速度和加速度的波動,呂強等[1]提出了通過限制相鄰線段的銜接速度以實現速度平滑過渡的方法。近年來,隨著直接參數曲線插補方法的提出和發展,已有許多學者證明參數曲線插補方法能滿足目前數控加工行業高速高精的要求[2-5]。另外,相比G01代碼而言,參數曲線的數據量非常小,節省了數控系統的內存空間。對于復雜曲線曲面的加工路徑而言,現有的CAM系統仍以產生G01代碼為主,因此,人們利用參數曲線對G01代碼進行擬合[6-8],不但可壓縮數據量,還可從本質上平滑加工路徑。無論是參數曲線插補還是擬合,NURBS和B樣條曲線的應用最為廣泛。
數據點的擬合方法一般分為兩大類:插值擬合和逼近擬合。插值擬合精度較高,但不能縮減數據量;逼近擬合可大幅度縮減數據量,但為了在指定的精度內逼近給定的數據點,必須通過迭代的方法不斷增加控制點(一般以最少的控制點個數開始擬合),因此逼近擬合效率極低。且當控制點和節點的數量增加后,某些節點區間可能為空,會導致在逼近擬合求解時出現奇異方程組的情況,需進一步特殊處理。此外,關于NURBS曲線擬合時如何設定權值的研究很少,大多數情況下,簡單地將所有權值都取為1,即進行B樣條擬合(B樣條曲線實質上是控制點權因子均為1的NURBS曲線)。且實際上對逼近擬合來說,允許其選取任意的權因子可能會生成具有較少控制點的曲線;但對插值擬合來說,其控制點個數固定,沒有合適的理由選取任意的權因子[9]。
YAU等[10]利用最小二乘法,將數據點逼近擬合成NURBS曲線。為了減少擬合時的數據量,PARK等[11]提出了對主導點進行擬合的方法。ZHANG等[12]同樣提出了幾何特征點的自適應查尋方法。ZHAO等[13]提出了根據離散點曲率和弦高誤差等條件進行主導點選取的方法。TSAI等[14]提出了一種可實時具有C2連續性的局部Bezier曲線插值擬合方法,在逼近擬合時需計算數據點的擬合精度。傳統的牛頓迭代法雖精度較高,但效率較低。ZHU等[15]推導出了加工過程中實時計算輪廓跟隨誤差的Taylor二階展開算法,該算法可移植到數據點擬合時的精度校驗過程中,其計算速度較快且能達到合理的控制精度。
本文綜合主導點和局部Bezier快速插值擬合的方法,給出了主導點的確定方法,并在離線數據預處理階段,通過局部Bezier插值擬合和精度校驗不斷增加新的主導點,最后對主導點進行在線插值擬合以及誤差校驗,擬合后的曲線只需對非主導點進行1次誤差校驗循環,就能達到預期的擬合精度要求,從而加快了擬合速度。
1 主導點的種類與選擇
1.1 曲率極大值點和超過曲率閾值的點
很多文獻指出,曲線的曲率值是用來判斷曲線平滑性的一種有力工具[16]。但對于離散數據點而言,無法根據曲線的導數求取曲率的準確值。依據文獻[17]提供的方法,離散數據點的曲率估算公式如下:

式中,Qi-1、Qi和 Qi+1為三個連續的數據點;KQi為點 Qi處的曲率估算值;A(Qi-1,Qi,Qi+1)表示Qi-1、Q和Qi+1三點構成的三角形的面積。
文獻[18]提出了離散數據點曲率的另一種估算公式,通過推導發現,兩套計算公式的本質一致。但文獻[18]中的公式涉及反三角函數的求解,增加了計算的復雜性。
圖1所示為對半蝴蝶狀復雜曲線除去首末2點后的269個離散數據點的曲率估算結果。由圖1可以看出,將連續曲線離散后進行曲率的估值計算,不可避免地會引起計算值的波動,在曲率較大處的效果尤為明顯。為了更加準確地提取離散數據點的曲率極大值點,本文通過將當前曲率值點分別與前后5個連續相鄰的曲率值點相比較,進而篩選出曲率極大值點(部分)。對于前后比較點個數的確定并沒有嚴格的要求,但如果選取個數過少(前后至少各1個),則無法很好地排除數據波動點;而如果選取個數過多,可能會漏選一部分曲率極大值點(但在曲率值較大點處可通過曲率閾值點補選)。本文選定此數目為5,并將曲率極大值處的數據點標記為主導點。為了保證擬合曲線能夠較好地進行插值或逼近曲率值較大處的數據點,除了曲率極大值點外,本文還設定了1個曲率閾值Km,若離散數據點的曲率值大于設定的曲率閾值Km,則同樣將其標記為曲線擬合時的主導點。這也是本文不單純使用當前曲率值點與前后較少數量(如2個)曲率值點作比較的原因,因為單純應用曲率極大值點選取法且前后比較數量為2時,會漏選圖1中的P1和P2點。

圖1 半蝴蝶狀復雜曲線離散數據點的曲率估算值Fig.1 Curvature estimation of discrete points of semi-butterfly curve path
1.2 曲線的拐點或反曲點
在數學上,曲線的拐點或反曲點是定義曲線凹凸性發生變化的轉折點。對于3次Bezier曲線而言,其二階導函數為一條直線,依據曲線拐點的判斷原則,3次Bezier曲線內部最多只能有1個拐點,因此,在利用3次Bezier曲線對離散數據點進行逼近擬合時,離散數據點的拐點是決定曲線幾何形狀的重要主導點之一。
圖2中,設Ti為向量QiQi+1與QiQi+2的叉積,Ti+1為Qi+1Qi+2與Qi+1Qi+3的叉積,αT為向量 Ti和Ti+1的夾角。離散數據點拐點的計算方法滿足:


圖2 離散數據點的拐點計算Fig.2 The inflection point of discrete path points
對于平面數據點而言,若Qi+2為曲線的拐點,那么αT的值為π,反之,αT的值為0;如果是空間曲線,對于由CAM系統生成的連續復雜曲線的微小直線段路徑點而言,連續4點可近似看作位于同一平面內,所以,若Qi+2為曲線的拐點,則αT為一個較大的值(接近于π),反之,αT為一個較小的值(接近于0)。由此可設定一個正參考值αthre,(如αthre=2/3π),若αT≥ αthre成立,則將Qi+2作為曲線的拐點處理,并標記為主導點。
1.3 長度突變點
實驗驗證具有C2連續性的局部插值算法的要求之一是,相鄰微小直線段間的長度比值必須控制在一定范圍內,否則插值生成的曲線會出現扭曲或尖點(圖3),這是由算法本身連續性的限制條件造成的。為了解決此矛盾,需通過長度均分策略增加數據主導點,以保證相鄰主導點線段之間的長度比值變化較均勻。本文定義了長度突變系數λ=,以及長度突變閾值λ(本實驗選取limλlim=3)。在長度均分過程中會出現圖4中的兩種情況,當線段的長度突變系數λ大于設定閾值λlim時,需要對長線段進行均分處理。
由圖4a可以看出,第1段長度(第1個主導點與第2個主導點連線段長度)與第2段長度(第2個主導點與第3個主導點連線段長度)的比值大于λlim,預計將原始數據點下標為istart,new=(istart+imiddle)/2的點設置為新的主導點,并將istart,new的值賦給istart。由于選取數據點下標的中點并不能保證分割后的相鄰兩線段的長度接近相等,因此需對istart,new的值作進一步調整,以保證QistartQistart,new的長度和Qistart,newQiend的長度比值達到最合理。若istart,new=istart,則令 istart,new=imiddle。

圖3 長度不均勻造成的擬合尖角Fig.3 The sharp fitting angle caused by unevenness of the length between points

圖4 長度均分策略Fig.4 Length equalization strategy
由圖4b可以看出,第2段長度與第1段長度的比值大于λlim,預計將下標為iend,new=(imiddle+iend)/2的點設置為新的主導點,并將iend,new的值賦給iend,同樣可通過進一步調整,保證QimiddleQiend,new的長度與Qiend,newQiend的長度比值達到最合理。若iend,new=imiddle成立,則將 imiddle賦值給 istart,否則,istart值不變。
通過不斷地循環迭代,可實現主導點間的長度比值達到預設范圍之內的要求。由于迭代運算的原因,本文提出的查找主導點方法比較耗時,但是在離線數據預處理階段完成,并不會對在線擬合階段的效率造成影響。
2 C2連續的3次Bezier曲線局部插值算法
n次Bezier曲線C(u)的表達式如下:

式中,Pi為曲線控制點;Bi,n為Bernstein基函數。
n次Bezier曲線C(u)的一階求導公式為

根據式(6)可知,對于兩條相連的3次Bezier曲線,公共端點D處的一階導矢計算公式為

式中,D為相鄰兩條Bezier曲線C1(u)和C2(u)的連接點;為C1(u)的第3個控制點;為C2(u)的第2個控制點。
為了保證曲線C1(u)和C2(u)在連接點D處一階連續,聯立式(7)、式(8)可得

同理,兩條曲線在連接點D處的二階導矢計算公式為

同理,為了保證兩條曲線在連接點D處二階連續,聯立式(10)、式(11)可得


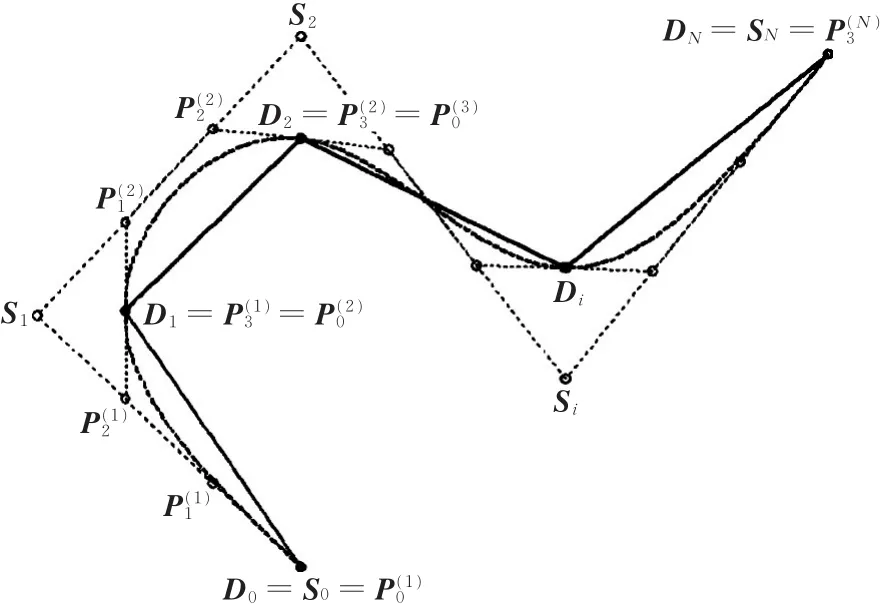
圖5 具有C2連續性的Bezier曲線局部插值過程Fig.5 Local Bezier curves interpolation fitting with C2 continuity
根據以上分析,為了保證所有分段Bezier曲線之間的C2連續,以下方程組必須成立:

通過進一步簡化,方程組(式(15))可改寫為

當i=0和i=N時,令Q0=S0,QN=SN,則式(16)為一線性方程組,可將其改寫為矩陣形式。通過矩陣求解得到所有Si后,將其代入式(15),進而可求出所有Bezier曲線段的控制點Pi1和Pi2,且有 P(i)0=Di-1及 P(i)3=Di。
從以上求解Bezier曲線段控制點的過程中可發現,此方法不涉及Bernstein基函數的求解,大大減少了運算量,很適合計算機的快速求解。除了具有控制點求解快速、方便的優點外,Bezier曲線還可同樣在不求解Bernstein基函數的情況下,快速計算曲線上對應的參數點。
3 Bezier曲線擬合后的非主導點誤差檢測與輪廓誤差跟隨法
3.1 de Castejau算法簡述
本文提出的在數據預處理階段對主導點進行具有C2連續性的插值擬合算法的另一個優點就是,在非主導點的誤差檢測過程中可充分利用de Castejau算法求解曲線及其導數曲線上的參數點,以提高非主導點誤差的計算速度。由于de Castejau算法是一種線性插值算法,在數值計算時受計算機浮點舍入誤差影響較小,因此也有利于提高計算精度。此外,由Bezier曲線的一階求導公式(式(6))可知,其導數曲線也是一條Bezier曲線,所以曲線及其導曲線上點的求取可利用同一套算法,從而精簡了程序的代碼量。
當n=3時,3次Bezier曲線上參數點的求解展開式如下:

由式(17)可知u=0.5時的de Castejau計算過程(圖6)。
3.2 Bezier曲線擬合后的非主導點誤差計算
點到參數曲線的誤差計算通常使用牛頓迭代法,且誤差定義如下:

牛頓迭代法的初始值u,可通過對Bezier曲線段內非主導數據點進行弦長參數化[9]求出。計算第i段Bezier曲線內所有非主導點到曲線的距離誤差,并將超過設定閾值的誤差最大點設為新的主導點(圖7);重新利用長度均分策略計算長度均分點,并再次將Bezier曲線擬合后計算出的非主導點中誤差超限且最大的點作為新的主導點,如此循環,直到所有非主導點的誤差達到預處理階段擬合誤差允許值的范圍內。

圖6 de Castejau算法線性插值過程Fig.6 de Castejau linear interpolation process

圖7 非主導點誤差計算與新增主導點Fig.7 Non-dominant points error calculation and new added dominant point
3.3 輪廓誤差跟隨法計算B樣條擬合誤差
對主導點進行插值擬合生成B樣條曲線后,需對非主導點的擬合誤差進行檢測。由于此過程需要在線完成,而傳統牛頓迭代法的誤差計算時間較長,算法效率較低,因此為提高算法的效率和減少誤差計算時間,本文利用文獻[15]中提出的輪廓誤差跟隨檢測方法,計算非主導點到擬合曲線的誤差。實驗結果表明:相比牛頓迭代法,輪廓誤差跟隨法對同樣數量點到復雜曲線的誤差檢測時間更短,且其計算所需的曲率值可提前算出,并用于后續B樣條曲線插補速度規劃預處理時速度突變點的檢測,從而提高了算法的效率。
圖8中,C(ui)為非主導點Qi在曲線上的估算投影點,C(ui+δ)為非主導點Qi在曲線上的實際投影點,δ為Qi對應的ui估算誤差,e(Qi)為非主導點到曲線的實際誤差。根據文獻[15],e(Qi)的二階泰勒展開表達式為


式中,K為B樣條曲線在C(ui)處的曲率;dt為矢量D在矢量T上的投影長度,o3(dt)表示截斷誤差;dc為矢量D在矢量C上的投影長度;T為曲線在C(ui)處的切向矢量;N為曲線在C(ui)處的單位主法矢量;C為D在C(ui)處主平面上的投影,且T、N、C均為單位向量。

圖8 誤差跟隨法計算B樣條擬合誤差Fig.8 B-spline fitting error calculation by error following method
由圖8可知,為了提高誤差跟隨法的誤差檢測精度,必須合理估算非主導點Qi對應的參數值ui。通常,對主導點進行B樣條插值擬合時,其節點向量是通過對主導點進行弦長參數化得到,而非主導點的參數值可通過再次對兩主導點間的數據進行弦長參數化得到。為了統一節點向量和數據點對應參數值的計算方法,本文采用原始數據,對主導點進行B樣條擬合時的節點向量進行合理規劃。設主導點Dj在原始數據點中的下標存儲在數組mark[N]中,其中N為原始數據點的個數,則進行B樣條擬合時,主導點處的參數值計算方法如下:

4 算法流程與仿真分析
4.1 算法流程
為了驗證本文所提方法及算法的正確性,以Visual Studio 2008為平臺,編寫了主導點(數據預處理)選取、主導點B樣條插值擬合及非主導點誤差計算的C++源程序,其算法流程見圖9。其中,數據預處理階段的誤差檢測容差e1設置較大,本文取e1=0.1 mm;實時處理階段的誤差結果一定小于e1,其檢測容差e2直接設置為最終的擬合誤差,本文取e2=0.03 mm,且在線處理時只需1次誤差檢測循環,并將超過誤差的非主導點增加為新的主導點,對更新后的主導點再次進行插值擬合生成B樣條曲線,此時的擬合誤差一定在e2范圍內。

圖9 算法流程圖Fig.9 Algorithm flowchart圖12 主導點B樣條插值擬合Fig.12 Dominant points and B-spline curve
4.2 仿真分析
本文的仿真案例為1條連續的半蝴蝶狀曲線,通過UG NX8.0軟件生成加工路徑,離散點內外公差絕對值均設置為0.02 mm。通過數據預處理后,篩選出138個主導點,原始數據點和主導點的分布見圖10。

圖10 主導點的組成部分Fig.10 Components of dominant points
主導點主要由離散數據點的曲率極大值點、曲率閾值點、曲線拐點、長度突變點以及誤差超限點組成。由圖10中的3處尖角放大圖可知,通過比較當前曲率值點與前后5個連續相鄰曲率值點確定曲率極大值點,能很好地消除數據波動造成的偽曲率極大值點,但會漏選曲率閾值點處的曲率極大值點(圖11),不過,這些點已通過曲率閾值點進行補選。對于除去特殊形狀標記覆蓋的叉形標記主導點,其生成方法是,對非主導點進行長度均分策略處理,將長度突變點記為主導點,以及將Bezier曲線擬合后的誤差超限點補選為主導點,此過程通過迭代計算完成,且每次迭代循環時都要重新進行長度均分處理及Bezier曲線擬合。

圖11 2點與5點比較法生成的曲率極大值點Fig.11 Local curvature max points with 2 and 5 points method
對主導點進行B樣條插值擬合后生成的曲線見圖12。

圖9 算法流程圖Fig.9 Algorithm flowchart圖12 主導點B樣條插值擬合Fig.12 Dominant points and B-spline curve
將主導點插值擬合成B樣條曲線后,需要對非主導點進行誤差檢測,本文采用誤差跟隨法計算擬合誤差,以保證此過程的快速和高效性,并將其結果與牛頓迭代法的計算值相比較。結果表明:兩種方法的方法誤差小于0.01 mm。圖13為兩種計算方法的誤差計算值對比圖。

圖13 兩種方法的誤差計算值對比圖Fig.13 Comparison of error calculation values of the two methods
測試結果表明:對133個非主導點進行誤差計算,通過牛頓迭代法(其距離檢測精度為0.001 mm)需要循環計算275次,共耗時8.6 ms;而誤差跟隨法只需要循環計算133次,共耗時5.537 ms,誤差跟隨法節省時間約35.6%。對138個主導點進行1次B樣條插值擬合的時間為647.435 ms。由于在線處理最多只需進行2次B樣條插值擬合,因此,相比傳統的插值擬合方法,在允許時間內,誤差跟隨法可一次性在線擬合更多的數據點,從而提高了擬合效率。
5 結論
(1)通過仿真實驗可知,本文提出的基于主導點的B樣條插值擬合方法可實現對復雜數控加工刀具軌跡(即G01代碼)的平滑壓縮,且利用輪廓跟隨誤差法的二階泰勒展開式計算擬合誤差,可在允許的誤差范圍內提高計算效率。
(2)由于所提方法的數據預處理過程可在離線階段完成,而在線處理階段只包含1次誤差檢測循環和最多2次B樣條插值擬合,因此根據數控系統的處理能力,若合理調整處理的數據量,此方法可實現刀具軌跡的在線甚至實時平滑壓縮計算。
(3)為了驗證理論的正確性,本文選取了形狀較復雜的半蝴蝶狀曲線作為仿真實例,實驗證明,將原始的271個離散數據點壓縮成以B樣條曲線控制點形式存儲的138個數據點,其壓縮效率可提高近2倍。若曲線形狀不復雜,可在數據預處理階段適當增大長度突變閾值,從而減少主導點數量,其壓縮效率將會進一步提高。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
