運用神經網絡獲取圖像的運動信息
2018-07-18 05:30:40董學強曾連蓀
現代計算機 2018年18期
關鍵詞:信息
董學強,曾連蓀
(上海海事大學信息工程學院,上海 201306)
0 引言
三維重建技術是現代技術發展的重要領域,在機器視覺視覺、計算機圖形學以及機器人的研究中都發揮著至關重要的作用。尤其在機器人的領域中一直是一個熱點與難點;機器人中的定位、導航,以及避障都需要運動信息的獲取,除此之外還能為給機器人提供感知外部環境的變化和辨別真實環境中物體變化的幾何特性。其理論框架主要包括如下幾部分:(1)圖像的預處理(2)稀疏點云重建(3)稠密點云重建(4)表面重建(5)紋理映射。本文主要研究稀疏點云的構建方法。
稀疏點云重建的基礎是運動的分析技術。由于圖像中包含大量的運動信息,所以獲取稀疏點云最直接的方法就是對圖像進行直接分析,其中主要包括傳統方法和現代方法。傳統的對于稀疏點云的構建是基于SFM(Structure From Motion)[1-2]。SFM的輸入主要是一段運動或者連續的圖片,然后根據2D圖之間的匹配可以推斷出相機的各個參數以及目標物體的運動參數。
特征點的匹配可以根據SIFT或者SUFT完成,特征點跟蹤是可以通過Optical Flow實現。現在對于圖像信息的分析我們可以通過CNN(Convolutional Neural Networks)處理,其輸入的主要的一幀圖像,通過卷積對于圖像信息的獲取,通過反卷積實現圖像信息的可視化,輸出的主要是圖像的深度圖,結合相機的校正矩陣可以實現稀疏點云的重構。
1 CNN算法
CNN由紐約大學的Yann LeCun于1998年提出,是多層感知機(MLP)的變種。由生物學家休博爾和維瑟爾在早期關于貓視覺皮層的研究發展而來。早期因為數據集獲取的困難和計算量限制未能得到廣泛的運用。現在由于科技的發展,很多成型的數據集我們可以輕松在網上獲取,計算機的計算量與計算速度實現了指數級的增長,才讓其應用成為了可能。從2012年中CNN在ImageNet數據集中表現出來的驚人的分類效果,讓其又重新進入了我們的視野,引起了我們的高度關注。CNN組成
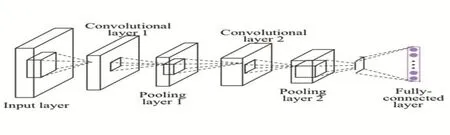
圖1 CNN的主要結構
卷積神經網絡一般由5部分組成:輸入層、卷積層、赤化層、全連接層、Softmax層。
(1)輸入層(input layer):是整個神經網絡的輸入,在一般的情況下它代表了一張圖片的像素矩陣,輸入層的長和寬代表了圖片的長和寬,其深度代表了圖片的深度1或者3,黑白圖片的深度就是1,彩色圖片具有RGB三種色彩通道一般深度就是3。
(2)卷積層:卷積層是神經網絡中最重要的一部分,卷積的主要目的就對輸入層的圖像信息的更加深入的獲取。通過不同的feature map分別對輸入圖像進行卷積實現對其特征的獲取,卷積層的長和寬取決于feature map的長和寬,其深度取決于不同的feature map的個數
(3)池化層(pooling layer):池化層可以有效地減少矩陣的尺寸(長和寬),從而可以減少最后全連接的參數的個數,參數的減少在一定程度上也可以防止過擬合的問題。一般具有兩種池化方法:最大池化和平均池化。
(4)全連接層(full layer):圖像經過幾輪的卷積層和池化層的處理,我們可以認為圖像的所有信息已經被抽象成了信息量更高的特征。我們需要將這些特征用全連接層進行處理。
(5)Softmax層:這層的主要作用就是讓輸出的結果變為一種概率值。假設原始輸出是y1,y2,…,yn,經過Softmax層以后輸出的結果是一般輸出的維度取決于圖像特征的個數。
2 CNN處理圖片的優勢
CNN在對于圖像的處理相對于其他的方法具有不可比擬的優勢,它有效地避免了對于圖像的前期處理過程(特征提取、特征匹配等),可以直接輸入原始的圖片。圖像處理中,我們需要將圖像看成是一個或者多個的二維向量。傳統的神經網絡是采用全連接的方式,即輸入層到隱藏層的神經元是全部連接的,這樣會導致一個很嚴重的問題就是參數會呈現爆炸式的增長,使得在訓練神經網絡的時候耗時導致難以訓練,CNN在處理這方面的問題的時候采用了局部連接和參數共享[3]的機制大大減少了參數的數量。該優點在網絡的輸入是多維圖像時表現地更為明顯,使圖像可以直接作為網絡的輸入,避免了傳統識別算法中復雜的特征提取和數據重建過程。在二維圖像處理上有眾多優勢,如網絡能自行抽取圖像特征包括顏色、紋理、形狀及圖像的幾何結構;在處理二維圖像問題上,特別是識別位移、縮放及其他形式扭曲不變性的應用上具有良好的魯棒性和運算效率等。
2.1 基于學習的運動估計
利用神經網絡學習每幀圖像的運動,這種神經網絡被地表實時信息所監督,用一些訓練實例來高效的學習一些缺乏紋理的的運動估計,這種方法取代了以前的依靠一些在運動場上加一些平滑限制,過去的一些優化方法就是采用此種方法[4]。從以前的直接優化未知的參數到現在直接優化神經網絡中的權重,在權重的優化過程中,我們并不需要可以獲取十分精確的圖片信息,只需要增加訓練實例的規模和次數就可以得到比較理想的權重參數。
2.2 反卷積網絡實現可視化
CNN的神奇的處理效果在大多數人眼里貌似還是一種“黑盒效應”,它為何表現地這么好,如何提高CNN的性能,這些還需要很強的理論知識支持。也許反卷積的使用可以讓我們多少了解一些其中的原理。反卷積在神經網絡中主要的作用是實現各個卷積層的可視化,具體來說就是探索各個網絡層學到了什么。反卷積又被稱之為Transposed Convolution,我們可以看出卷積層的前向傳播過程就是反卷積的反向傳播過程,卷積層的反向傳播過程就是反卷積層的前向傳播過程。反卷積主要包括三部分:反池化過程、反激活過程、反卷積過程[5]。
3 KITTI訓練數據集簡介
我們的實驗的訓練部分是采用KITTI數據集來實現的。KITTI數據集由德國卡爾斯魯厄理工學院和豐田美國技術研究院聯合創辦,是目前國際上最大的自動駕駛場景下的計算機視覺算法評測數據集。該數據集用于評測立體圖像(stereo),光流(optical flow),視覺測距(visual odometry),3D 物體檢測(object detection)和 3D跟蹤(tracking)等計算機視覺技術在車載環境下的性能。KITTI包含市區、鄉村和高速公路等場景采集的真實圖像數據,每張圖像中最多達15輛車和30個行人,還有各種程度的遮擋與截斷。整個數據集由389對立體圖像和光流圖,39.2 km視覺測距序列以及超過200k 3D標注物體的圖像組成[6],以10Hz的頻率采樣同步。總體上來看,我們將原始的數據集分為‘Road’,‘City’,‘Resident’,‘Campus’,和‘Person’。對于 3D 物體檢測,label可以細分為car,van,truck,pedestrian,pe?destrian(sitting),cyclist,tram以及misc組成。
4 神經網絡算法主框架
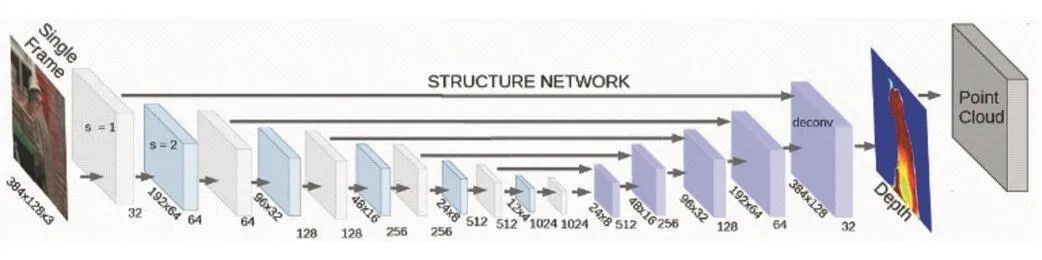
圖2 主要結構模型
我們用KITTI數據集作為訓練數據使用。通過訓練可以得到如上圖的主框架圖。神經網絡的主框架如上圖所示:我們將一幀圖像作為主要的輸入對象,圖像的大小是384×128×3即圖像具有RGB三種通道。輸出的是圖像的深度信息,我們結合相機的內參矩陣可以獲得其空間的三維點云。我們的結構一共有8層,卷積層和池化層和反卷積層和反池化層各有4層,每一個。我們的feature map的大小是2×2的而且每一步的的大小是2,所以我們才會看到每一幀圖像經過卷積層的時候會變為原來的1/4,經過反卷積的時候是原來的4倍。在神經網絡的訓練過程中為了避免一些問題例如:訓練過程太慢或者出現梯度爆炸的情況,采用了批量歸一化(Batch Normalization.BN)來解決這些問題。我們對每一層的輸出均采用批量歸一化處理。之所以采用這種方法歸根結底就是為了防止“梯度彌散”。訓練太慢也是由于“梯度彌散”造成的。運用BN這種小技巧一般還可以加速訓練速度,提高模型的訓練精度。在訓練過程中對于激活函數的選取需要考慮多方面的因素。在此我們選擇Relu激活函數。主要基于:深度值都是正值,Relu的變量的取值范圍也是正值符合我們的要求。Relu函數相對于其他激活函數具有兩大優點:梯度不飽和,因此在反向傳播過程中,減輕了梯度彌散的問題,神經網絡前幾層的參數也可以很快地更新;計算速度快。正向傳播過程中,Sigmoid和Tanh函數計算激活值時需要計算指數,而Relu函數僅需要設置閾值。如果 x<0,f(x)=0,如果 x>0,f(x)=x。加快了正向傳播的計算速度。在此我們將深度值的峰值設定在100,為了避免出現過大的梯度甚至梯度爆炸。
5 結果
采用本文算法的仿真結果如圖3所示:我們進行了簡單的比較。定性地比較了一個運用立體對(圖3中間部分)獲取的深度圖和在沒有相機運動信息的情況下運用幀序列獲取的深度圖(圖3最右圖)。在兩幀圖像的運動沒有發生劇烈變化的時候,運用立體對獲取的深度信息和運用幀序列獲取的幀序列獲取的深度圖,兩種深度圖基本一致。對于幀序列獲取的深度圖,在現實的訓練中也會出現一些失敗的例子如最后兩行。當兩幀圖像的空間位置發生極小變化的時候,其深度圖的精確度會降低。但是對于立體對的序列這種情況一般很少出現,因為在兩幀圖像之間會有一種補償來彌補這種微小變化帶來的損失。對于上述失敗的例子可以通過增加訓練數據的規模來避免的,因為一旦數據增加就相應的增加了帶有相關相機運動序列的場景出現的概率。

圖3 深度圖
6 結語
CNN的一個重要的優勢就是對圖像信息的分析和獲取。圖像中包括很多關于物體位姿的重要信息,物體之間的相對位置,物體在圖像的具體坐標等,這些信息我們都可以通過對圖像信息的提取獲得。通過增加數據集的數量,在一定程度上可以獲取更加精確的分析結果。現在我們可以輕松獲取不同規模大小的數據集,所以我們可以改變訓練的規模。獲取多樣化的結果,可以加深對運動信息的分析與比較。相對于傳統的參數的優化,運用CNN處理圖像可以降低獲取結果的時間成本,增加準確度。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創業(2009年10期)2009-10-08 04:52:00
數字社區&智能家居(2009年7期)2009-09-29 08:16:48
數字社區&智能家居(2009年11期)2009-06-25 04:30:34
數字社區&智能家居(2009年3期)2009-04-21 03:09:04
數字社區&智能家居(2009年2期)2009-03-27 04:33:44
數字社區&智能家居(2009年12期)2009-02-03 07:50:48
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
