融合批規范化編解碼網絡架構的道路分割
2018-07-18 05:30:40王亞蕊王嘯宇
現代計算機 2018年18期
關鍵詞:規范化
王亞蕊,王嘯宇
(1.上海海事大學電子信息系,上海 201306;2.合肥工業大學電子通信系,合肥 230009)
0 引言
道路分割是無人車視覺導航的基本功能之一,在無人汽車行駛過程中,其視覺導航中的攝像頭對車輛前方場景進行圖像采集,并根據采集的圖像信息,規劃路徑并控制車輛運動,在結構化或非結構化道路環境下完成行駛任務。無人汽車導航系統也可以自學習、自適應,從而使無人駕駛汽車能夠安全、可靠地在道路上行駛[1-2]。
近幾年來,基于深度學習的語義分割框架開始應用于道路分割中,在轉換的框架中,輸入圖像經過一次或者多次的卷積、池化、激活計算處理后,得到圖像的一系列高、中、低級別特征,接下來把得到的這些特征送入分類器,打上“道路”或者“非道路”的標簽[3-5]。傳統的基于卷積神經網絡的語義分割算法對圖像進行像素分類時,一般采用鄰近像素圖像塊作為卷積神經網絡層的輸入,學習像素到像素的映射,端到端的映射,從而對圖像進行訓練、預測[6-9]。然而,這種方式精確度小、細節敏感度低,2015年,Vijay等人提出了最大池化指數,并將其轉移到圖像解碼器中,改善了圖像語義分割的分辨率[10]。Fisher Yu等人使用了一種可用于密集預測的卷積層-空洞卷積,在圖像多尺度聚集的條件下使用空洞卷積的背景模塊[11-14]。在自動駕駛開始大熱的2016年,Liang-Chieh Chen等人在Vijay等人的研究基礎上,使用空間卷積和全連接條件隨機場,在空間維度上實現了金字塔形的空洞池化[15]。
然而,這些方式存儲開銷大、計算效率低、像素塊的大小限制了感知域的多少,而且在深層網絡中,就單層而言,每一層的輸入時前面所有層的輸出,這個輸出往往是不穩定的,它會隨著前一層參數迭代的更新而發生變化,因此,學習率的選擇和參數的初始化尤其重要,大量的改善問題還亟需解決[13,15-17]。
針對深層神經網絡訓練過程中,每一層都需要學習一個變化的數據分布,模型參數選取不穩定、調優難度大的問題,本文選取VGG16網絡和FCN32網絡模型分別組成道路分割的編解碼架構[18],在每層卷積計算后加入批規范化計算[19],學習一個比較穩定的參數數據分布。在KITTI數據集上的道路數據集實驗,結果表明本文設計的編解碼網絡架構對無人車駕駛領域的可行駛區域檢測、分割有著較高的魯棒性。
1 網絡模型的批規范化
批規范化和卷積神經網絡中的“白化”思想接近,在神經網絡的訓練過程中,深層神經網絡在做非線性變換前的激活輸入值會隨著網絡深度加深,它的數據分布會發生偏移、變動,數據的整體分布也會趨向于靠近非線性函數取值的上下限兩端,從而導致在深層神經網絡在后向傳播時低層神經網絡的梯度消失,這也是訓練深層神經網絡收斂越來越慢的本質原因[19,21-23]。
1.1 批規范化的基本流程
基于對數據分布的不同假設,通過人為對代價函數的設計,神經網絡對樣本數據的學習本質上就是一個優化過程,而在神經網絡模型中,低層網絡在訓練的時會時長自動更新參數,從而引起后面層輸入數據分布的變化,導致神經網絡訓練復雜、耗時、難以擬合。為了克服深度神經網絡難以訓練的弊病,Google于2015年提出批規范化的概念,通過mini-batch來規范化某些層的輸入,固定每層輸入信號的均值和方差來解決這種“梯度彌散”的問題[19]。

圖1 批規范化的基本流程
批規范化的基本流程如圖1所示,首先對輸入樣本的特征變量進行標準化處理得到x,降低特征變量間的差異性,減少錯分樣本對數據的干擾。標準化后的x經過W1的線性變換后得到s1,然后依次處理得到第二層結果s2,表達式如下:
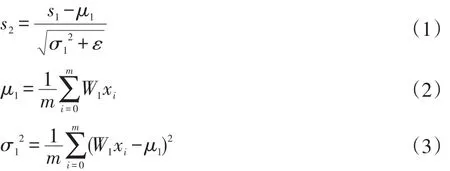

1.2 批規范化結果分析
圖2展示了批規范化操作前后每一層輸出值的數據分布結果,可以明顯看出,沒有采用批規范化操作的時候,每層的輸出值迅速全部變為0,也可以說,所有的神經元都已經“死亡”了,而對每一層的輸出采用批規范化后,每層的值都能有一個比較好的分布效果,大部分的神經元還活著。
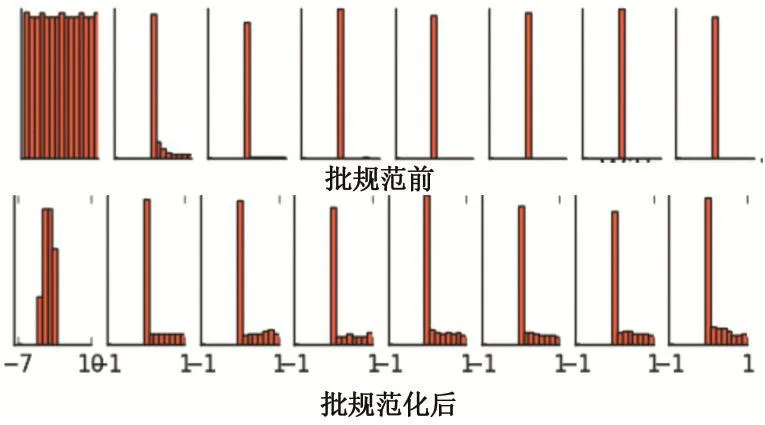
圖2 批規范化操作前后每一層輸出值的數據分布
2 融合批規范化編解碼結構的道路分割
K.Fukushima等人提出CNN的輸入是圖像,輸出的結果為一個概率值,早期的語義分割方法利用CNN的固有效率來實現隱式的滑動窗口[24]。而Jonalthan等人提出用于語義分割的FCN學習的是像素到像素的映射,其輸入為一張圖像,輸出也是一張圖像。它可采用端到端的方式訓練深度學習通道,來建模語義分割任務,與殘差網絡相結合的技術是目前最先進的技術[8]。
本文采用的道路分割基礎架構如圖3所示,編碼器部分由VGG16網絡的卷積層和池化層組成,采用13層卷積層輸出的結果,其中,每層卷積層的輸出部分都做批規范化處理,使每層神經網絡任意神經元輸入值的數據分布轉化為標準正態分布,從而使激活值落在非線性激活函數對輸入值比較敏感的區域,這樣激活的輸入值較小變化就會導致損失函數較大的變化,避免梯度消失問題產生,大大加快訓練速度,也增加了分類效果。
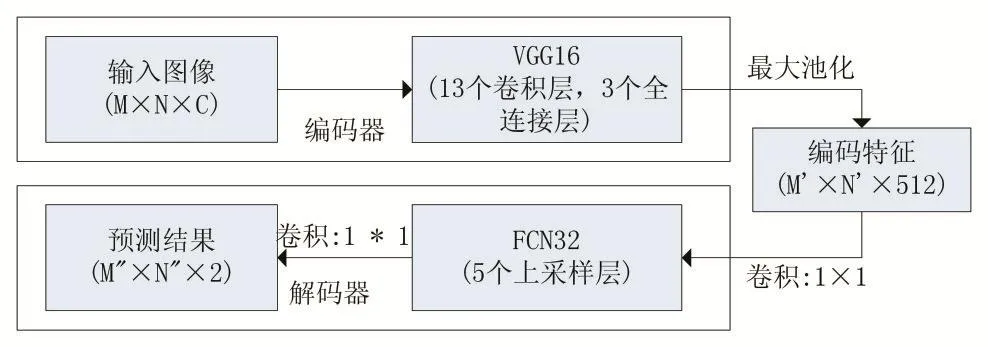
圖3 基于編解碼架構的自適應道路分割模型
解碼器部分采用全卷積網絡對圖像進行語義分割將VGG16解構的剩余3層全連接層轉化為1×1卷積層,產生尺寸較小的低分割分辨率圖像,其后采用3個反卷積層執行上采樣。然后加上一些較低層的高分辨率特征,這些特征經過1×1卷積層處理,然后加到部分上采樣結果中,從而得到我們最終的輸出結果。
3 實驗結果與分析
本文實驗驗證環境:Ubuntu16.04,內存8GB,Python版本2.7,TensorFlow版本1.3。
本文的實驗數據取自KITTI數據集上的道路場景數據[20],圖4顯示了融合批規范化編解碼網絡架構的道路分割結果,可以明顯看出融合批規范編后解碼網絡結構模型對陰影和大小尺度的車輛等障礙物有著更好的分割效果。
圖5為本文提出的網絡模型的實驗效果評估結果。表1為本文實驗結果與截止到目前KITTI分割結果最優的前五名的對比效果。
4 結語
本文采用基于編解碼架構模型的道路分割算法框架,并在每一層卷積計算加入批規范化計算,從而增強模型了訓練過程中參數調優的穩定性。與KITTI道路分割數據集評估對比效果印證了本文所提融合算法的優越性。

圖4 融合批規范化的編解碼網絡結構的道路分割結果圖
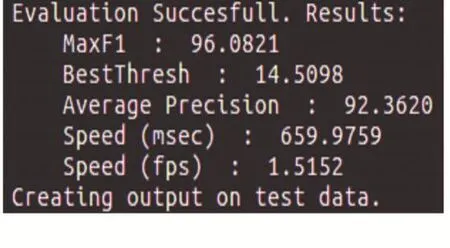
圖5 實驗效果評估結果
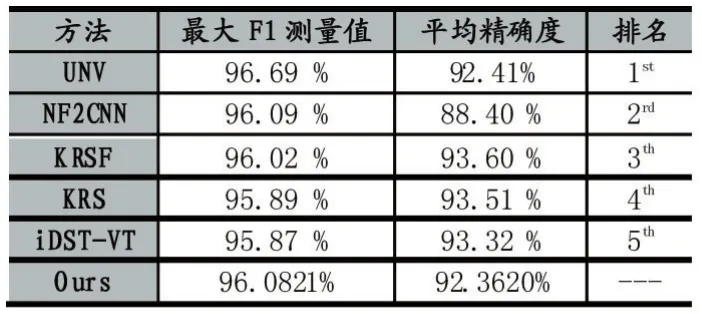
表1 KITTI Road分割結果部分對比
猜你喜歡
家庭影院技術(2018年4期)2018-05-09 07:07:29
商周刊(2017年23期)2017-11-24 03:24:09
蘭臺內外(2017年5期)2017-06-06 02:24:19
中外醫療(2016年15期)2016-12-01 04:25:46
時代農機(2016年6期)2016-12-01 04:07:29
中國老區建設(2016年9期)2016-02-28 09:34:05
行政事業資產與財務(2015年23期)2015-10-26 03:13:30
中國衛生產業(2015年10期)2015-03-11 18:58:41
中國當代醫藥(2015年9期)2015-03-01 02:02:15
中國衛生(2014年3期)2014-11-12 13:18:18
