用于軸承表面缺陷分類的特征選擇算法
2018-07-21 14:55:42宇文旋盧滿懷
軸承 2018年1期
宇文旋,盧滿懷
(1.電子科技大學 機械電子工程學院,成都 611731;2.電子科技大學中山學院 機電工程學院,廣東 中山 528400)
基于機器視覺的檢測方法是軸承表面缺陷檢測的重要手段,其高速、無損、自動化等特點吸引了大批研究人員。作為企業的管理人員,往往不僅希望將缺陷產品剔除,還希望得到缺陷的類別信息,以改進生產工藝及設備。
為完成軸承表面缺陷類型的準確識別,需要選擇高效的分類特征。文獻[1-3]對軸承表面缺陷的檢出方法進行了深入研究,為進一步的缺陷類型識別奠定了一定基礎。文獻[4]以軸承生產和裝配過程中產生的銹斑、劃痕、裂紋等缺陷為研究對象,采用缺陷區域的單一特征——圓度作為分類特征,可識別出差別明顯的缺陷類型。文獻[5]研究了鐵路貨車軸承常見的缺陷,以缺陷區域的面積、伸長度、厚實度、圓度、邊緣平滑度等作為分類特征,但由于未進行專門的特征選擇,分類正確率僅80%。文獻[6]在研究軸承使用過程中產生的外觀缺陷分類時,分析了表面缺陷二值圖像的幾何特征和形狀矩特征,進行了簡單的比較選擇,識別率提高到88%。文獻[7]提出的軸承表面缺陷識別算法考慮了定位、光照、放射不變性等因素,選擇缺陷的7個Hu矩值作為分類特征,識別率進一步提高到90%。文獻[8]在軸承鋼球生產過程缺陷分類的研究中,深入分析了缺陷的面積、長短徑比、歐拉數等特征,并用于點、凹坑、群點、劃傷、擦傷這5類缺陷的分類中,準確率高達96%。
綜上所述,隨著研究的不斷深入,缺陷的識別率不斷提高,但缺陷分類特征的選擇這一重要環節多依賴相關人員的經驗,未引入有效的特征選擇算法,導致所選特征易出現可分性差,特征之間相關性高等缺點,從而影響分類器的性能,有必要對特征選擇算法進行專門研究。因此,基于上述分析提出了一種用于軸承表面缺陷分類的特征選擇算法,并通過對比試驗進行分析驗證。
1 特征選擇算法流程
特征選擇算法整體流程如圖1所示,主要分為以下4個步驟:1)特征池的建立,搜集分類對象盡可能多的特征,組合成一個備選特征集合;2)數據獲取與處理,通過圖像采集、圖像處理、特征計算等步驟實現樣本由圖像到歸一化特征向量的轉化;3)降維目標確立,根據特征池所含特征維數、峰值現象和訓練樣本數量等因素綜合決定最終用于分類的特征個數;4)特征選擇,根據樣本數據和降維目標用所設計的特征選擇算法從特征池中選出分類性能較好的特征組合。
2 準備階段
準備階段雖然不屬于特征選擇的核心算法,但為算法提供了必需的備選特征、樣本數據和目標,是進行特征選擇的基礎條件。
2.1 特征池的建立
特征池是所研究分類對象的各種特征的集合,可用 X={xi},(i=1,2,…,d)表示。對于一個具體的特征池,其需具備有限性、可擴展性和一定的通用性。有限性指對于某一類研究對象,現階段可得到的特征數量是有限的;可擴展性是指隨著相關學科的發展,新的特征被提出后可隨時加入到特征池中;通用性是指某一領域的特征池一旦建立,相關的特征選擇工作就可以借鑒該特征池。特征池的建立為特征選擇提供了“原材料”,其所含特征維數決定了特征選擇維數的上限,其含分類信息的豐富程度決定了最終選取特征的分類能力。因此建立合理的特征池是進行特征選擇的重要內容。
機器視覺中一般采用圖像特征,其可分為基于區域的特征、基于灰度的特征和基于紋理的特征[9],每種類型都有數量不等的特征,通過收集和整理,初步建立了含有57個特征的特征池(表1)。

表1 圖像特征池Tab.1 Image feature pool
2.2 數據獲取與處理
數據獲取指通過圖像采集得到樣本的圖像,圖像采集過程受光照、拍攝角度等外部環境影響較大,為避免這種影響,工業系統的圖像采集裝置一般安放于相對穩定的環境。
數據處理則是指對所取得的圖像進行分割、特征計算和歸一化等一系列處理過程。其中歸一化的作用是對整個訓練集中所有訓練樣本的同一特征分量進行尺度變換,使在全部訓練集上變換后的數據處于[0,1]或 [-1,1]范圍內[9-10],以消除特征動態范圍的影響。
2.3 降維目標確立
降維目標不僅受特征池中特征數目的限制,還會受訓練樣本數量N的影響,一般而言,訓練樣本數量越多,所選分類特征亦可相應增加。而當訓練樣本數量N不變時,增加分類特征的數量d′可使分類器的性能得到初步的改進,但隨著特征數量的增加,分類器的錯誤率Pe會上升,這種現象稱為峰值現象[11],如圖2所示。通常Pe最小值發生在N/a處,其中a為經驗值,可取2~10之間的數。
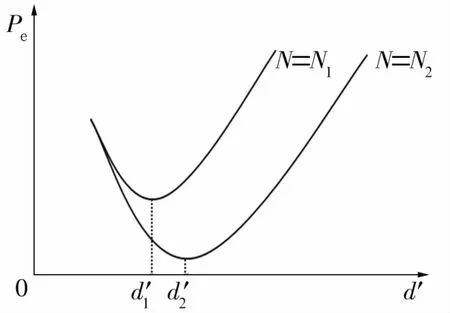
圖2 峰值現象Fig.2 Peak phenomenon
在確定分類特征數量前,可首先確定訓練樣本的個數,然后計算峰值處的特征數量,在目標維數小于峰值維數前提下,再根據分類問題的復雜程度等因素做出最終決定。
3 核心算法
經過上述準備階段,特征選擇就轉化為以樣本數據所提供的信息為基礎,從備選樣本中選出由降維目標確定特征作為最終分類特征的問題,其核心是設計有效的特征選擇算法,選出備選特征中的最優分類特征組合。
3.1 算法原理
常用的特征選擇算法有標量特征選擇和特征向量選擇。標量特征選擇是指分別計算每個特征的可分性判據值,并將特征以判據值降序排列,選擇前d′個特征作為分類特征的算法。其具有計算簡單、易于理解等優點,但沒有考慮特征之間的相關性,只有當特征之間相互獨立時才能保證解的最優性。特征向量選擇是指從原始的d維特征中任選d′個進行組合,然后計算每種組合的類可分性判據,從中選擇使判據最優的特征組合作為分類特征[12]。特征向量選擇法選出的特征具有更好的可分性,但當原始特征和所需的特征維數較大時,計算量會急劇增加,僅適用于維數較低的特征選擇。
為利用上述算法的優點,同時克服其缺點,在上述算法基礎上引入相關分析,提出了一種綜合運用相關分析、標量特征選擇和特征向量選擇的綜合算法。首先,根據可分性判據將所有特征按分類性能由好到差排序,實現特征池X到特征向量x(d)的轉化;其次,對各特征之間進行相關性分析,剔除相關性較強的特征,特征向量由x(d)降維到 x(d1);然后,對 x(d1)進行標量特征選擇,即只選擇x(d1)的前d2個特征組成新的特征向量x(d2),實現第 2次降維;最后,對 x(d2)進行特征向量選擇,選出x(d2)中d′個特征組合成的最佳分類組合,得到最終的分類特征向量x(d′)。
3.2 算法實現
根據上述算法原理,建立了一種以相關系數為相關性特征選擇判據,以Fisher判別率(Fisher Discrimination Ratio,FDR)為標量特征選擇判據,以J1為特征向量選擇判據的具體算法[13]。
假設已經按算法流程建立了特征池X,取得了標準化的訓練樣本集T,并確立了降維目標d′。其中,特征池中有d個特征,用X={xl},(l=1,2,…,d)表示;訓練樣本集 T有 c種類型(c≥3),分別為 ω1,ω2,…,ωc,每個類型 ωi有 Ni個樣本,共有N個訓練樣本;降維目標就是從特征池中的d個特征中,選擇d′個作為最終分類特征,其具體步驟如下:
(1)FDR特征排序
特征池中的特征以集合形式存在,為便于表示和計算,需要將所有特征以一定順序組合成一個特征向量,FDR用于表征單個特征的可分性,FDR值越大,特征可分性越好。
對于特征池中的任一特征xl,其FDR值為

對X中的所有特征進行上述計算,可得到所有特征的FDR值,根據FDR值由大到小將特征重新排序,得到特征向量 x=(x1,x2,…,xd)T。
(2)相關性特征選擇
相關性特征選擇指用特征之間的相關性做評價指標,去除相關性高的特征,保留相對較為獨立的特征。相關性的評價可用相關系數作指標。
將訓練樣本集T中所有樣本的特征xl按順序組成向量xl,因為每個樣本有d個特征,所以可生成d個這樣的向量,任意2個向量xi,xj之間的相關系數為


根據特征順序和相關系數對特征進行相關性特征選擇。首先,采用x1對與其相關系數大于設定閾值的特征進行剔除;然后,依次用未被剔除的特征剔除其后與其相關系數大于閾值的特征,直到最后一個特征為止。通過本次篩選,得到了各特征相關性較低的特征向量x(d1),實現第1次降維。
(3)FDR特征選擇
相關系數篩選后的特征既保留了原始特征的分類信息,又使各特征之間相關性大大降低,滿足了標量特征選擇的基本條件,且特征已經按FDR進行排序,因此直接取前d2個特征組成新的特征向量x(d2),實現第2次降維。
(4)向量特征選擇

4 試驗驗證
可分性判據只是對特征可分性的理論評價,實際應用中以此特征設計的分類器的識別率才是對特征進行評價的更好指標。為此,設計了一個實際的缺陷類型識別任務,然后用隨機選擇算法、標量特征選擇算法和文中算法分別進行特征選擇并完成分類任務,通過比較識別率的高低判斷算法的優劣。
試驗選取6204型軸承外圈機加工過程中常見的磨削過量、擦傷、磕碰傷3種表面缺陷作為識別對象,并收集了此型號外圈的900個缺陷樣本,每種缺陷300個。缺陷示例及其分割圖像如圖3所示。

圖3 缺陷圖像示例Fig.3 Images of defect examples
分別采用隨機選擇算法抽取3組特征,標量特征選擇算法和文中算法各抽取1組特征,共進行了5組試驗。隨機從每種缺陷中各取出100個并編號作為訓練樣本,剩余600個編號后作為檢測樣本;以表1中57個特征作為原始特征,降維目標定為從60個特征中選擇10個;采用線陣相機掃描方式采集圖像,動態閾值分割算法分割缺陷區域,分量白化算法進行歸一處理;以300個訓練樣本為基礎,分別用隨機抽取算法、標量特征選擇算法和文中算法進行特征選擇;根據輸入特征維數,輸出類別等確定了如圖4所示的神經網絡結構;分別用所選特征對多個相同結構的神經網絡進行訓練,并用訓練后的神經網絡對檢測樣本進行識別,得到每種方法的識別率,從而進行比較。

圖4 BP神經網絡Fig.4 BP neural network
試驗結果見表2,由表可知:3組隨機算法試驗的識別率均不高,且很不穩定,最高識別率可達82.2%,最差識別率則僅19.0%。以FDR準則進行的標量特征選擇試驗也未取得好的效果,識別率僅66.7%。進一步分析發現其分類錯誤主要是將所有200個磨削過量缺陷誤識別為擦傷,其余2類則完全正確識別。這種結果印證了算法本身的缺點,即所選單個特征具有較好的可分性,但特征之間可能存在強相關性,使特征組合總體分類能力下降,從而導致誤識別。而文中算法則取得了良好的效果,在600個檢測樣本中,有3個被錯誤識別,包括:402號擦傷被識別為磕碰傷;492號和600號擦傷被識別為磨削過量,如圖5所示。其余樣本均正確識別,識別率高達99.5%。其部分試驗數據見表3和表4,包括每種缺陷的5組數據以及被錯誤識別的樣本數據(灰色標出)。

表2 各特征選擇算法的識別率Tab.2 Recognition rates of each feature selection algorithm

圖5 錯誤分類樣本Fig.5 Misclassified samples
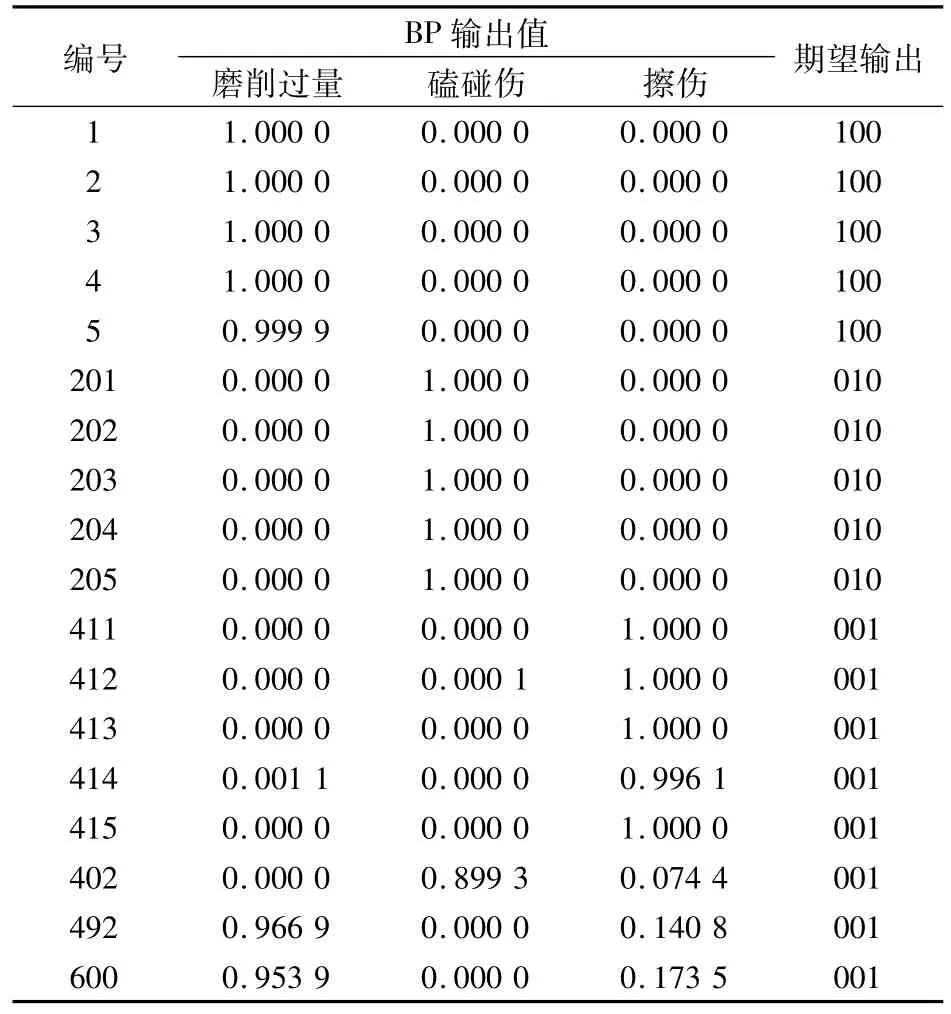
表4 部分檢測樣本的BP神經網絡輸出和期望輸出Tab.4 BP neural network output and expected output values of part of testing sample
由以上對比試驗可得:相較于不加選擇的隨機方法以及僅進行簡單比較的標量特征選擇,文中算法所選特征設計的分類器所選取的特征具有更好的可分性,且具有更高的識別率,可以嘗試用于更加復雜的實際應用中。
5 結束語
圍繞基于機器視覺的軸承表面缺陷分類特征的選擇做了以下工作:1)總結了特征選擇的完整流程,為算法應用提供了清晰的思路;2)初步建立了軸承缺陷圖像的特征池,為相關領域的特征選擇工作提供了便利;3)提出了一種特征選擇的綜合算法,通過相關性選擇、標量特征選擇和特征向量選擇3次篩選,實現了較好的特征選擇,且相對于單獨的特征向量選擇大大降低了計算量;4)通過對比分析驗證了特征選擇算法可以選出可分性高的特征及其可操作性。
應當指出,沒有絕對的最優特征,只有在一定條件下的最優,因此文中提供的是特征選擇的方法,而不是最終分類特征本身,所進行的實例驗證目的是驗證算法的有效性,而非給出一個普遍適用的分類特征。對于研究者來說,要想得到適合自己研究問題的分類特征,還需要參考文中算法進行相應的改進計算。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
