基于改進殘差網絡的人臉識別算法*
2018-08-03 03:14:22張紅英
傳感器與微系統 2018年8期
曹 川, 張紅英
(1.西南科技大學 信息工程學院,四川 綿陽 621010;2.特殊環境機器人技術四川省重點實驗室,四川 綿陽 621010)
0 引 言
隨著深度學習的快速發展,人臉識別技術也在日益提高,如文獻[1~5]提出的方法。但各文獻中的方法采用的數據集并沒有太大姿態差異,不適于實際應用。為此,有研究創建了包括極端姿態變化的數據集(如CASIA-WebFace數據庫)。2016年,楊瑞等人[6]提出了一種基于Gabor特征和深度信念網絡(deep belief network,DBN)的人臉識別方法,通過學習高層特征降低特征維數提高了分類器的分類精度,最終改善了人臉識別率。同年,張軍等人[7]提出了由多個卷積層和次采樣層構成的改進卷積神經網絡提高了對復雜特征的提取能力。同年,Masi I等人[8]通過提出姿態感知卷積神經網絡模型的方法,改進了包括大姿態變化的數據集的識別結果。實際中,需要對自然條件下含有較大姿態差異等復雜因素的人臉進行人臉特征提取。2015年,He K M等人[9]提出的新的神經網絡結構,其中包含的殘差單元有效的解決了網絡由于過深而出現的退化問題。該網絡結構在ILSVRC(ImageNet large scale visual recognition challenge)—2015[10]中獲得了第一名,具有非常高的特征提取能力,在人臉識別方面顯得更具潛力。
在已有的殘差神經網絡模型的基礎上,結合Zagoruyko S等人[11]提出的寬的神經網絡也可以有好的網絡模型性能的思想,本文提出了一種改進的殘差神經網絡模型,該模型共14層含有6個殘差單元,最大的特點是網絡比較寬而且相對較淺。 通過實驗,改進的網絡模型具有更加優異的網絡性能,對含有姿態等復雜因素的人臉圖像具有更強的特征提取能力。
1 改進的殘差網絡結構
受Zagoruyko S等人[11]提出的寬殘差神經網絡的啟發,發現隨著模型深度不斷加深,梯度在反向傳播過程中,并不能保證可以流經每一個殘差單元的權重,以致學習效果較差,在整個訓練過程中,只有比較少的幾個殘差單元可以學到有用的特征表達,因此,本文采用一種較淺的,但寬度更寬的模型,使得殘差單元更多的起到作用以更加有效地提升模型性能。該結構主要通過減少殘差單元的數量和增加殘差單元中卷積層的特征圖數量來實現,經過實驗證明了增加模型的寬度可以提升模型的性能,但不能完全認為寬度比深度更好。因此,采用基于ResNet-32的網絡模型,結合寬殘差神經網絡的思路,進行改進得到14層的寬殘差神經網絡模型(稱為W-ResNet-14),網絡結構如圖1所示。
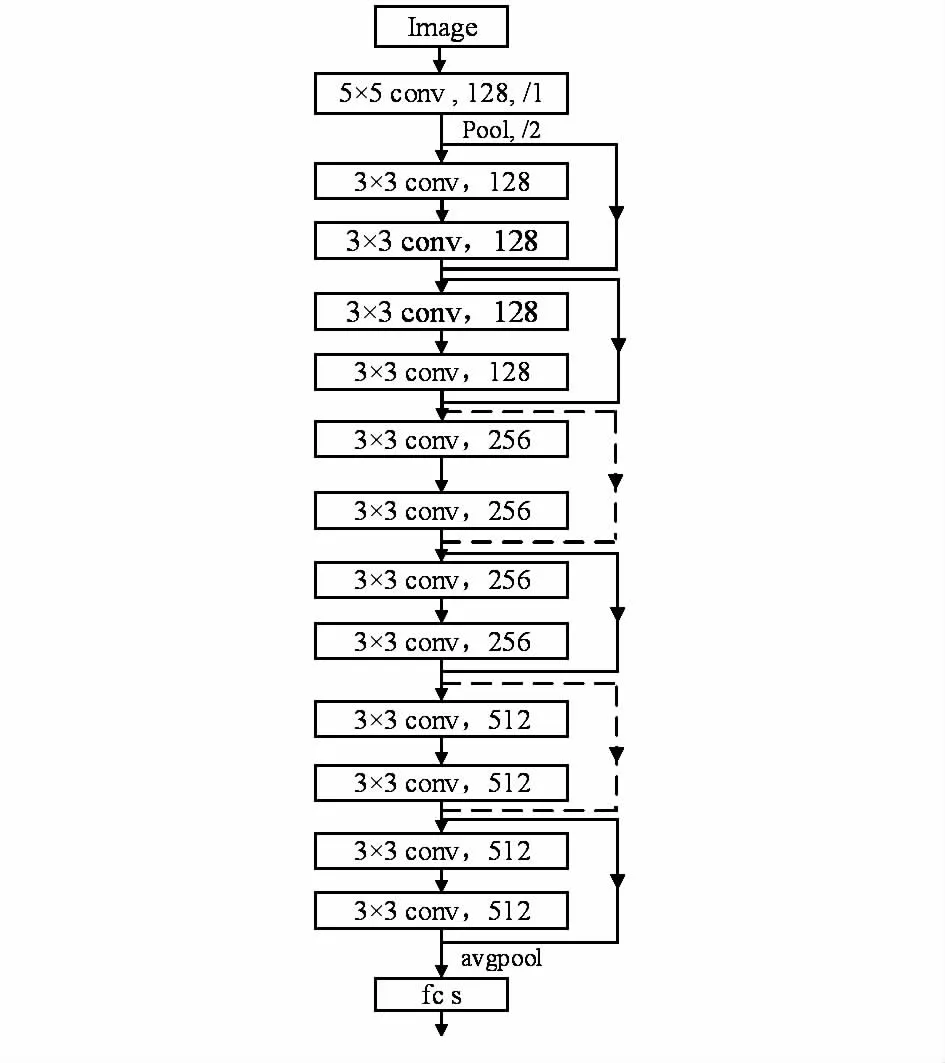
圖1 W-ResNet-14
首先第一層卷積使用5×5大小的卷積核,步長為1,Padding大小為1,使得卷積輸入與輸出具有相同的特征圖,然后再經過平均池化,濾波器的大小為2×2,步長為2,以減小特征圖大小,簡化網絡計算復雜度,然后輸入第一個殘差單元。
提出的網絡模型包括6個殘差單元,每個殘差單元使用如圖2所示的結構。其中每一個殘差單元的輸入Hi-1與輸出Hi的尺寸大小并不改變。首先使用批標準化(batch normalization,BN)[12]算法對每一次的輸出數據進行標準化,以達到以下效果:以有效參數穩定網絡收斂;適當設置較大的初始學習率以加快網絡收斂;有效防止網絡出現過擬合現象。將BN算法處理過的數據通過Relu激活函數激活,以增加神經網絡各層之間的非線性關系,完成需要神經網絡完成的提取復雜特征的任務;另外還可以保證網絡的稀疏性,較少參數間的相互依存關系,減少過擬合情況的發生。將激活后的數據輸入一個卷積層,本文選用大小為3×3的卷積核,步長為1,Padding設置為1,以保證輸入Hi-1與輸出Hi具有相同尺寸。通過BN算法和Relu激活函數輸入第二個卷積層,相關參數與第一個卷積層相同。最后將第二個卷積的輸出與殘差單元的輸入通過矩陣相加運算作為下一個殘差單元的輸入,最終實現了殘差思想中的將需要學習的特征映射轉換為F(x)+x。其中第一個殘差單元中在卷積層前不使用BN算法和Relu激活函數。

圖2 殘差單元結構
通過6個殘差單元后,連接一個均值下采樣層,最后網絡連接一個與人臉身份類別數相同的全連接層。相關層數的參數如表1所示,其中,Basis Block為He K M等人[9]提出用于cifar-10實驗的網絡, Improve Block為本文改進的網絡模型相關參數。因此使網絡最底層可以從原始像素學習濾波器,刻畫局部的邊緣和紋理特征;然后通過各種邊緣濾波器的組合,中層濾波器可以描述不同類型的人臉器官;最高層描述的是整個人臉的全局特征。以此完成對輸入人臉圖像的特征學習。

表1 網絡層參數
在人臉識別任務上訓練神經網絡,對32層的殘差網絡模型進行改進,主要利用Zagoruyko S等人[11]提出的寬殘差神經網絡的思想,通過增加原殘差模型中某些卷積輸出通道數,以加寬網絡模型,同時通過減少殘差單元數量使原來較深的殘差模型變得更淺,以此將網絡層數從32層減少到14層,即為本文提出的W-ResNet-14模型。
2 實驗結果與分析
2.1 數據集
為了說明所設計的殘差神經網絡結構的特征提取能力,選取了具挑戰性的CASIA-WebFace數據庫和自建數據庫OurFace作為實驗對象。
在實驗過程中于CASIA-WebFace數據庫上的數據集中隨機選取同種身份至少包含200張圖片的部分數據集組成訓練和測試的數據集。為了減少計算量,加速網絡訓練,將所有圖像的分辨率降低到了64×64大小,同時為了使每個身份的圖像數量相等和豐富數據集,使用了數據增強技術,包含了如旋轉、平移等方式。如圖3所示對圖像進行了翻轉和平移,最終得到了可以用于進行訓練和測試的數據集,然后將每個身份下的數據集隨機獨立的分為2個子集:訓練集和測試集,其中80 %作為訓練集訓練網絡參數,20 %用于評估網絡性能。

圖3 對圖像進行翻轉、平移等變換
同樣將OurFace數據庫中采集到圖像數據通過預處理后劃分為相同比例的訓練集和測試集。
2.2 實驗分析
實驗使用Google的開源深度學習框架TensorFlow,因其高度的靈活性和真正的可移植性等優點成為當下應用最廣的深度學習框架之一。首先通過批量處理將已經收集到的數據集調整為大小為64×64的人臉圖像,然后轉換為TensorFlow支持的用于神經網絡高效輸入的二進制數據格式TFRecord;再通過隨機讀取一定批次大小圖像數據。實驗平臺相關主要配置為:處理器為Intel Xeon E5—2680,運行內存為64 GB,顯卡為NVIDIA GeForce GTX 1080 8 GB。
使用該平臺用于加速訓練所提出的改進模型,采用梯度下降算法優化網絡。實驗中參數如表2所示。
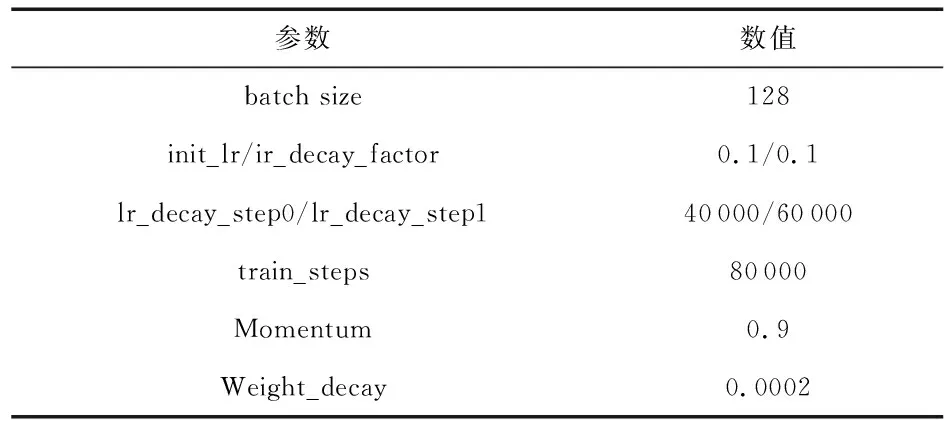
表2 網絡超參數
訓練過程中為了在現有硬件設備上得到盡量好的實驗結果,選取的訓練批次大小為128,同時使用隨步數衰減的學習率訓練網絡參數,初始學習率為0.1,在40 000步和60 000步分別衰減當前步數的0.1 倍,以盡可能地逼近最優解,提高準確率。在CASIA-WebFace數據OurFace數據集上分別進行訓練和測試,實驗中,沒有對原始數據集中的人臉進行對齊、裁剪等操作,最終得到的top—1準確率如表3所示。

表3 2種網絡結構下top—1 的準確率 %
可以看出,相較于原來的殘差神經網絡模型改進的殘差神經網絡W-ResNet-14在CASIA-WebFace和OurFace數據集上具有更好的性能。主要是因為改進的殘差模型可以提高模型中殘差單元的利用率,從而使得網絡性能高于原網絡模型,繼而提高對人臉特征的提取能力。
3 結 論
提出的W-ResNet-14神經網絡模型,在CASIA-WebFace和OurFace數據集上較原網絡在準確性上有2 %以上的提高,特別是在CASIA-WebFace數據上具有更好的性能,說明所提出的改進殘差神經網絡對于復雜特征的提取能力更強。但由于未對數據集進行更加優異的預處理,比如人臉對齊,裁去過多的背景信息等,或者可能提出的模型并不是網絡深度和寬度的最佳平衡點。因此本文模型通過優異數據集預處理和找到寬度和深度最好的平衡點,可能會發揮殘差神經網絡模型在人臉識別上更好的網絡性能,這是下一步研究的工作。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
