基于大樣本的隨機森林惡意代碼檢測與分類算法
2018-08-06 08:07:56李雪虎王發明
網絡安全與數據管理 2018年7期
李雪虎,王發明,戰 凱
(北京江民新科技術有限公司,北京 100097)
0 引言
隨著互聯網的快速發展,計算機安全問題已經提高到國家安全的戰略角度,但是在互聯網上傳播的惡意代碼的數量、種類等都在增加。根據江民病毒疫情監測預警中心提供的數據顯示[1]:2018年5月,新增病毒1 140種,感染計算機13 569臺。北京、上海、廣州是主要的被感染和受攻擊地區。雖然惡意代碼一直在持續的增長,但是大部分惡意代碼在編寫過程中都是關鍵模塊重利用,其特征行為具有高度的相似性[2]。
首先,惡意代碼為了偽裝自身,會對自身代碼結構進行修改,而修改自身代碼結構的方法則具有規律性;其次,惡意代碼為了實現獲取計算機相關權限、修改計算機重要文件等敏感操作,就需要調用系統相關的API函數來達到目的。所以本文根據以上惡意代碼的特點通過機器學習的方法實現對惡意代碼的辨別與分類。
1 惡意代碼分類算法相關研究
1.1 基于API調用的特征提取
應用程序編程接口(Application Programming Interface, API)是可以作為惡意代碼分類特征使用的,惡意程序通過調用一些API(主要是系統底層API),達到竊取用戶敏感信息或者獲取本計相操作權限等,而這些API在大部分的惡意代碼中均被大量使用,本文將這些API稱為敏感API。在文獻[3]中已經證實在同一種分類算法中,使用敏感API得到的分類結果準確度要優于不使用敏感API得到的分類結果準確度,故本文將敏感API作為惡意代碼分類的特征向量。
一般提取惡意代碼特征主要有兩種方法:靜態分析方法和動態分析方法。靜態分析主要使用IDA[4]、JEB等反匯編工具,主要特征有PE文件結構信息和敏感API調用等。動態分析方法主要是使用沙箱[5](例如布谷鳥)等程序模擬操作系統環境,監測其中未知程序的行為并與已知的惡意代碼行為進行匹配,如果匹配成功,則可判定未知程序為惡意程序。但是在具體的應用過程中發現,由于系統API層次較低,沙箱進行行為監控時,難以獲得行為的準確含義,并且沙箱分析出結果的速度緩慢,耗時較長。由于這些缺點的存在,故本文采用靜態特征分析的方法。
得到特征數據以后,就可以使用機器學習的相關模型進行惡意代碼的分類識別。分類算法有很多,常見的算法有K近鄰(K-Nearest Neighbor, KNN)[6]、支持向量機(Support Vector Machine, SVM)[7]、邏輯回歸(Logistic Regression)[8]、卷積神經網絡(Convolutional Neural Network, CNN)[9]等。本文主要是使用隨機森林進行惡意代碼分類。
1.2 隨機森林
隨機森林可以解釋為若干自變量(X1,X2,…,Xi,…,Xn) 對因變量Y的作用。如果因變量Y有m個觀測值,有n個自變量與之相關(并且大多數情況下,m是遠遠小于n的);在構建決策分類樹的時候,隨機森林會隨機地在原數據中重新選擇m個觀測值,其中有的觀測值可能被多次選擇,有的可能一次都沒有被選到。根據選擇的樣本進行決策樹建模,然后組合多棵決策樹的預測,通過投票得出最終的預測結果。
1.3 隨機森林算法實現
本文的隨機森林算法是在Spark下實現的,采用的是Python第三方庫Pyspark。實驗分為兩個,第一個實驗的輸入為樣本文件的文件特征,包括文件類型、文件大小、文件導入表、文件基地址、文件版本等50個特征作為輸入;第二個實驗的輸入為敏感API特征,其中調節的參數為:numTrees=150,maxDepth=30,labelCol=“indexed”,featuresCol='features',seed=42,其余參數保持不變。本文將總數據集的80 %用于訓練,20%用于測試。
2 實驗分析
2.1 實驗數據集
惡意代碼數據集是進行惡意代碼分析的基礎,機器學習算法只有結合相關的數據集對樣本進行訓練,才能更好地實現檢測功能。
本文采用的數據集是江民新科技術有限公司病毒庫中的數據集。本次采用的數據集總量為90萬,其中45萬白樣本,45萬病毒樣本。并且在45萬病毒樣本中,Downloader、Trojan、Backdoor三類樣本樣本量分別是15萬、15萬、15萬。
2.2 實驗環境
實驗環境:CPU:Intel(R) Xeon(R) CPU E5645 @ 2.40 GHz,操作系統CentOS Linux release 7.3.1611,內存32 GB。
Hadoop和Spark的版本為:Hadoop版本2.7.1,Spark版本2.2.1。
2.3 實驗評判標準
用查準率(Precision)、查全率(Recall)和F1度量評估本文算法,通常以關注的類為正類,其他類為負類,指標的取值為0~1。這些度量的計算公式如下:
(1)
(2)
(3)
其中,TP(True Positive)是指將正類預測為正類數,FP(False Positive)是指將負類預測為正類數,FN(False Negative)是指正類預測為負類數。
2.4 結果分析
在所選擇的數據集(江民新科技術有限公司病毒庫中的數據集)上將本文的隨機森林算法與支持向量機算法、邏輯回歸算法做比較。
首先進行黑白樣本分類的實驗,查看實驗的查準率、查全率和F1值,從實驗結果可以看出當樣本總量在10萬左右的時候,隨機森林在辨識黑白樣本的效果上與支持向量機算法、邏輯回歸算法相比較,結果并不理想。但是隨著樣本數量增大到90萬,隨機森林模型在辨識黑白樣本的查準率、查全率、F1值從原來的0.732、0.711、0.721提升到0.973、0.973、0.973,都達到了三種分類中的最好,其中在500 000到700 000樣本的時候,查準率、查全率和F1值出現了下降,是因為隨著病毒樣本的增加,其中部分白樣本經過編譯器編譯得到的PE結構信息與部分病毒樣本的結構信息相似,使得隨機森林算法出現了一定的誤差。但是隨著樣本量的繼續增大,這一小部分的樣本對于整體的分類影響逐漸變小。實驗結果如圖1、圖2、圖3所示。
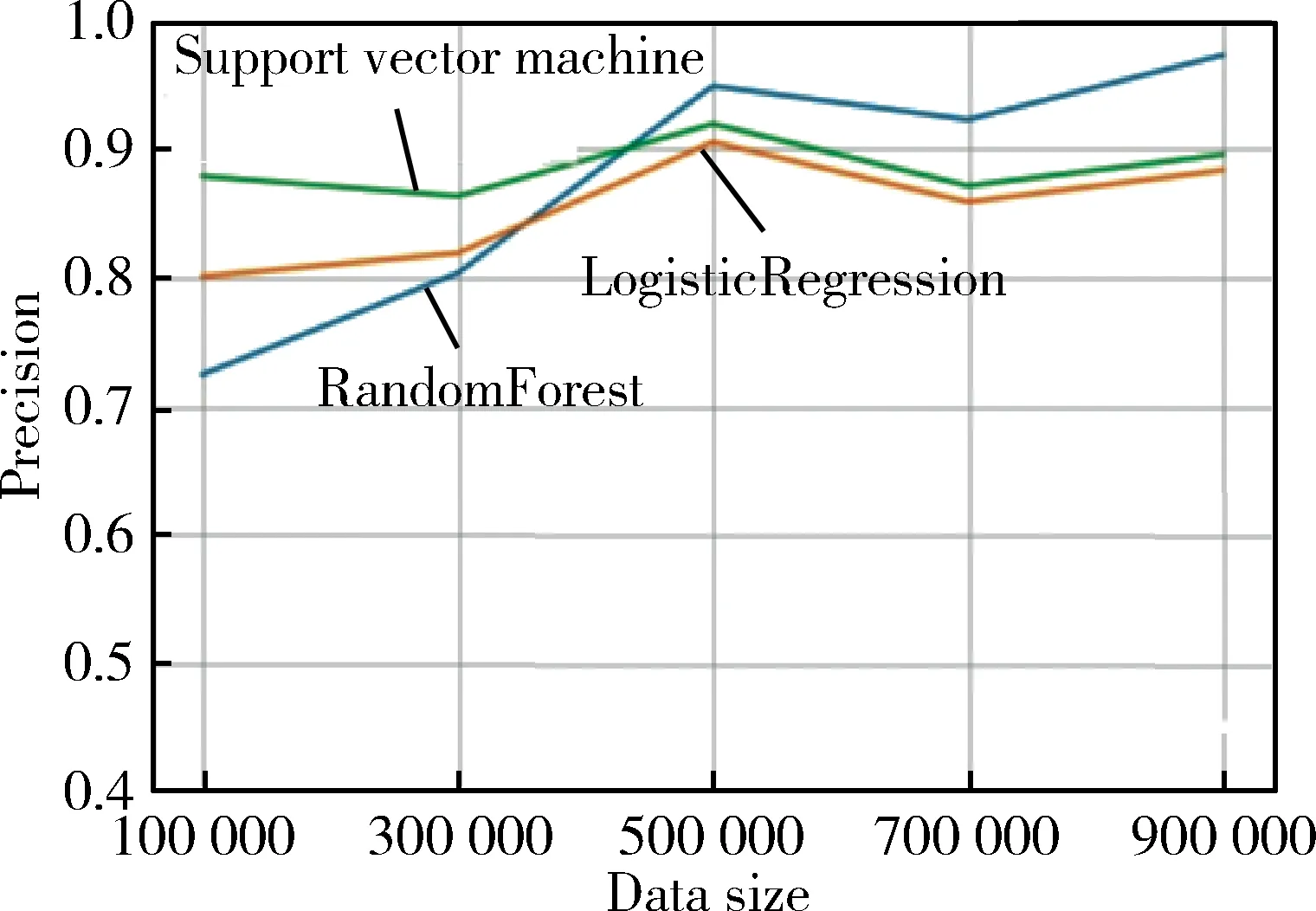
圖1 三種分類算法黑白分類查準率

圖2 三種分類算法黑白分類查全率
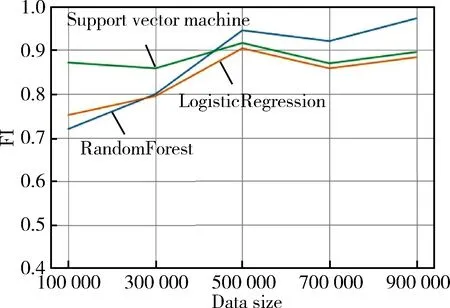
圖3 三種分類算法黑白分類F1值
其次,再進行基于Downloader、Trojan、Backdoor這三種病毒分類的實驗,本次實驗的惡意代碼數據是總數據集中的45萬病毒樣本。從實驗結果可以看出隨機森林在對Downloader、Trojan、Backdoor三種病毒分類時,與支持向量機分類算法和邏輯回歸分類算法相比較,實驗效果是比較好的。隨著惡意代碼的樣本量從9萬增長到45萬時,查準率、查全率、F1值從原來的0.924、0.918、0.921提升到0.935、0.932、0.934,評判標準都有提升。其實驗結果如圖4、圖5、圖6所示。

圖4 三種分類算法在病毒分類的查準率
從以上結果可知,隨機森林在分類的泛化能力上要優于SVM和邏輯回歸。
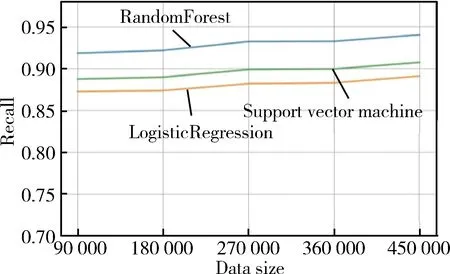
圖5 三種分類算法在病毒分類的查全率
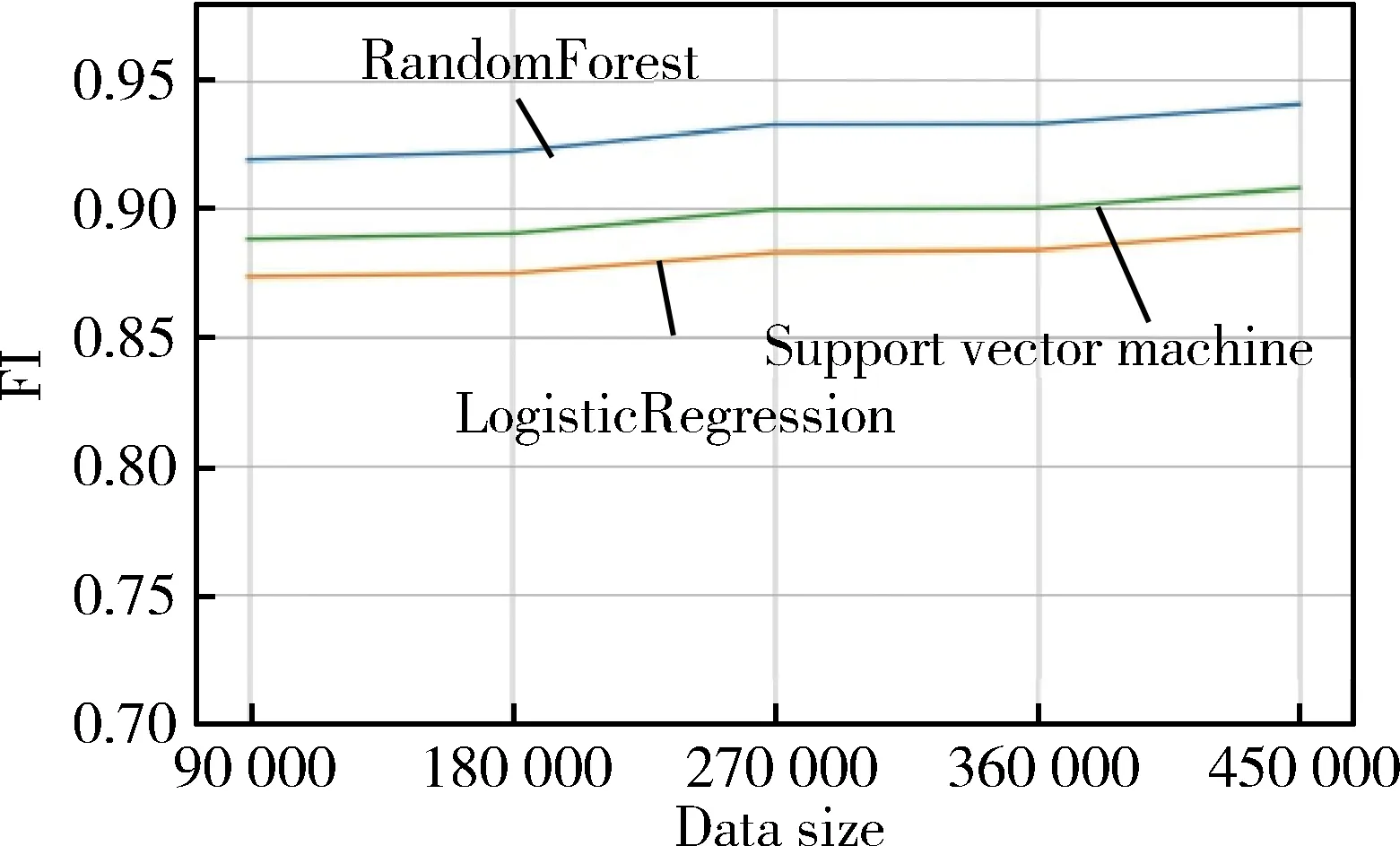
圖6 所示為三種分類算法在病毒分類的F1值
3 結束語
本文聚焦在大樣本下利用機器學習算法對惡意代碼進行識別和分類檢測,選擇PE文件結構和敏感API作為輸入,實驗數據表明隨機森林的評價效果比支持向量機、邏輯回歸模型的效果優秀。在進行三種病毒分類上,雖然隨機森林的效果最好,但是隨機森林對于某些白樣本使用和病毒樣本相同的編譯器時,容易將其劃分為病毒樣本。其次,準確率仍然不是很高,只有0.935左右,在基于大樣本的前提下,模型的分類效果仍然需要提升,以上兩個問題是本文今后工作的重點。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
