基于模糊理論的入侵檢測
2018-08-13 02:04:16汪濤
信息記錄材料 2018年9期
汪 濤
(國家新聞出版廣電總局724臺 陜西 岐山 722400)
1 引言
早在1965年,美國著名自動控制專家L.A.Zadeh教授,便在權威雜志上發表了模糊集的文章,自此開創了此領域的先河[1],模糊集憑借其前衛、先進的思想,已經融入到數學的整個體系架構當中,比如模糊圖論、模糊矩陣、模糊積分、模糊群、模糊概率、模糊系統等[2-11]。自此,模糊集理論在實際應用領域,取得了比較大的發展與進步[12-19]。而在其整個架構中,其應用最多的領域除了有模糊聚類分析、模糊綜合決策之外,還有模糊控制、模糊模式識別等。
伴隨計算機技術的不斷發展與完善,計算機在通信網絡方面所存在的安全問題日漸凸顯,針對以往的網絡安全措施而言(防火墻),已無法滿足當前需要。為了能夠更好的、更加全面的保護網絡安全,社會中出現了各種殺毒軟件,而且還專門開發出了各種有效的入侵檢測系統。針對現階段的入侵檢測技術而言,人們應景對此展開了深入、系統化研究,取得了不錯的研究成果,比如以特征檢測為基礎而設定的協議分析,以特征檢測為基礎而開展的行為異常檢測。除此之外,近年來,入侵檢測系統的智能化已經成為時下的研究重點與熱點。而對于模糊推理系統而言,從總體上來講,其與人的思維更為接近。2000年,Dicker—son便根據當時情況,指出了構建模糊入侵檢測系統相關理念,而且還專門為此進行了網絡數據檢測實驗,從中對其實用性及可行性進行了驗證。以模糊理論為基礎而開發的入侵檢測系統,截止到今天,已經有8年的時間,關于此領域的研究,涉及到了與模糊數學理論相關的多個方面,比如模糊數據挖掘等。從總體上來講,針對模糊理論而言,其應用于入侵檢測系統,相比于非模糊應用,盡管能夠為此方面帶來許多益處,但是,模糊入侵檢測系統所具有的模糊性特質,往往會使誤警率維持在高位,因而對其長久發展造成了嚴重影響與限制。基于此問題,本文運用了兩大現今技術,其一為協議分析,其二為模糊綜合評判。以網絡協議分析為基礎,對各種網絡服務所具有的優越性進行分析,能夠更好的通過模糊綜合評判,來達成或實現入侵檢測的目的。
2 方法原理
(1)協議分析
針對TCP/IP協議來講,其乃是整個計算機網絡的關鍵所在,針對此協議而言,其由一組屬于各個層次的協議構成。針對網絡協議而言,其所具有的層次特性,為協議分析的正常開展提供了穩定性與可靠性。首先,針對數據包而言,需對其中的協議類型進行判斷,然后,依據各協議所具有的不同特性,從中選擇合理特征。針對文中而言,所采用協議分析主要由層組成:
其一,協議類型(protocol type),即tep udp iemp.
其二,服務類型(server),即(tcp)private other http ftp smtp;(icmp)eco_i;
其三,等連接標識(flag),即SF REG SO SH等。
(2)模糊綜合評判原理
所謂模糊評判,實際即為結合所提供的實測值及評價標準,通過開展模糊變換,來評價事物的一種方法。而對于綜合評判而言,即對由各種因素所影響的事物展開評價,從本質上來講,就是以評判對象為對象,依據所提供的相關條件,分別對各對象賦予一個非負實數—評語結果,然后根據這種順序,從中進行優選。針對模糊綜合評判來講,其步驟為:
針對因素集來講,從本質上來講,就是將那些對評價對象造成影響的各種因素當作其元素,由此而構建起的一個普通集合。
②構建權重集:對于各因素而言,因其核心程序存在一定的差異性,對此,為了能將各因素所具有的重要程度給體現出來,需要基于各因素,分別賦予其一個權數ai,各個權數經過規律性組成,便構成了集合

即權重集。
③構建評價集:針對評價集來講,實際就是評價者根據實際情況,針對評判對象所作出的總評集合:

④將評判矩陣找出來:針對評判對象,依據因素集當中的第i個因素μi,開展系統化評判,除此之外,針對評價集當中的第j個元素vi,如果其隸屬程度是rij,那么對于第i個因素μi而言,其評判結果便可以運用模糊集合來表示

單因素評價集由Ri表示,其實為整個評價集V上當中的一個典型的模糊子集,即:,模糊評判矩陣為:
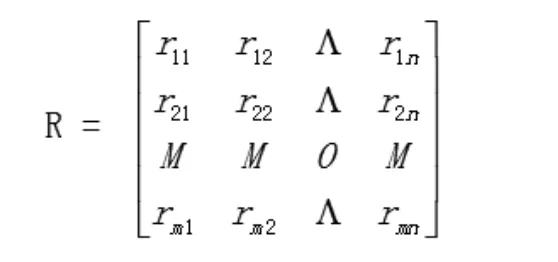
⑤綜合評判:針對單因素模糊評判而言,其僅僅能夠將一個因素對整個評判結果所具有的影響給反映出來。從總體上來講,其實遠遠不足的,最終目的即為開展綜合評判,從中獲取準確、詳細的評判結果。針對模糊綜合評判來講,可用公式進行表示,在此公式當中,“Ο”所表示的是模糊關系框架下所生成的合成算子,而對于bj而言,實際就是進行模糊綜合評判的一項重要指標。基于廣義模糊運算條件下,即M(Λ,V),在整個運算模型中,“n”所表示的是 “與”運算,而“V”所表示的是“或”的運算,由于運算不同,與之相對應的模型含義也會存在差異。
(3)入侵檢測算法
模糊入侵檢測的算法思路為:
①依據判決輸出方面所給出的具體要求,完成模糊集合的構建;
②將網絡數據包提取出來,基于TCP/IP協議,可將其劃分為三種類型,其一為tcp,其二為udp,其三為icmp;
③結合協議的相應服務類型,開展總體的分類工作,比如以udp為基礎進行分類,即private and others;
④結合②中所給出的分類,來對網絡傳輸標志flag實施劃分,比如SF;
⑤結合某類容易遭受攻擊的特征屬性所對應的數據集,并以上述分類為參照,來權重賦值與之相關的各種因素,從中便可以將權重分配向量A的出來,用于切實滿足各向量所對應的元素之和為1的基本條件,并且從中將其單因素確定下來,當作判決向量,最終,便能夠經過單因素,對矩陣R進行判決;
⑥通過開展系統化的合成運算,能夠從中獲得評判向量結果B,結合模糊識別所持有的最大隸屬原則,便能夠從中得到最終判決結果,也就是所說的模糊集。
3 入侵檢測算法的具體實現
(1)實現原理,圖l為算法的實現原理。
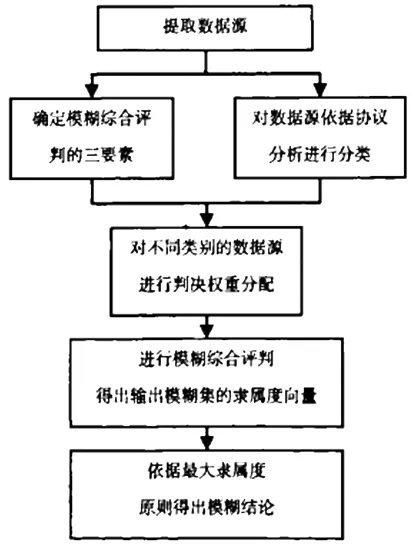
圖1 文中提出算法的實現原理
(2)確定模糊數據參數的具體方法
無論是模糊綜合評判的三要素,還是對因素權重進行評判的相關分配,均以諸多攻擊數據的系統化統計所得。針對KDD Cup 1999 Data數據庫來講,其無論是在數據挖掘領域中,還是在知識發現領域,均為具有較高權威性的數據集合。比如早在1999年,所組織的2大競賽,其一為分類器競賽,其二為知識發現競賽。針對分類器競賽來講,其基礎背景就是入侵檢測,通過此檢測的運用,較好的且系統化的提供了與入侵檢測相關的數據集,針對參賽者來講,其運用此該數據,開展集中訓練,另對各自所對應的分類器進行計算,從中將對分類器各項技術性能進行準確評估。首先,以KDD Cup 1999 Data數據庫為基礎,對其中的一些重要數據進行提取,比如kddcup.data-10-percent.gz,而在整個數據集當中,所記錄的全部是某類型的攻擊,然后,結合受攻擊的具體類別與對象屬性,完成統計圖的繪制工作,最后結合所得出的統計結果,對模糊數據參數進行劃分,并對界限加以明確,設定具體的參數賦值,完成上述步驟后,系統化修整這螳參數。
(3)實驗仿真
①實驗數據庫介紹
基于KDD Cup 1999 Data數據架構中,主要可劃分為5種數據類別:分別為R2L攻擊數據、DOS攻擊數據、正常數據,Probe攻擊數據、U2L攻擊數據。而針對KDD Cup 1999 Data數據來講,其一共有多大41個屬性,在這些屬性當中,數值型屬性占據其中的34個,而字符型屬性則占其中的7個。比如Probe攻擊類別當中的satan攻擊。針對Satan攻擊而言,從本質上來講,就是以某些探測程式為軸心,針對同一主機,開展關于網絡通信方面的掃描,以此種方式對主機當中的網絡服務進行查找,另外,還能查找其中的主要弱點。結合專家建議與經驗,對satan攻擊所持有的相應特征屬性向量加以明確。
②確定數據參數值
針對模糊綜合評判來講,其判決因素所對應的權重分配向量,以及與之相滿足的單因素評判向量為:
1)基于tcp連接情況下,在整個A=(0 0.1 0.1 0.1 0.3 0.4)中;其實為一種典型的服務類型(service),無論是其中的哪一種,與之呈對應關系的單因素,所持有的評判向量均為(0.4 0.4 0.2);而對于網絡傳輸而言,其核心標志為flag,如果是SF,那么與之呈對應關系的單因素,其評判向量就是(1 0 0),針對REJ而言,其評判向量是(0.1 0.4 0.5),除此之外的其它判斷向量,均認定為(0.1 0.50.4);而對于向對應的變量為count,如果在取值上>400,那么此時的單因素評判向量就是(0.1 0.1 0.8),如果<400,那么就是(0.3 0.3 0.4);針對變量rerror—rate來講,如果在實際取值時,其>0.7,那么經過單因素評判,其向量的取值區間為(0.1 0.1 0.8),如果是<0.7,那么其取值區間就是(0.8 0.1 0.1)。
2)udp連接下,A=(0 0.4 0 0.1 0 0.5);其具體的服務類型為(service),如果為prirate,那么與之相對應的單因素評判向量就是(O.1 0.2 0.7),另外的都設定為(0.4 0.4 0.2);flag為其網絡傳輸的核心標志,其在判決中沒有參與,因此,判決向量的取值范圍是(0 0 O);如果是>0,那么與之相對應的單因素,對應的評判向量就是(0 01)。
③數據舉例
1)數據記錄(0 tcp other RFJ00 00000000 0000 000 0 511 1 0.09 0.00 0.91 1.00 0.00 1.00 0.00 255 l 0.001.00 0.00 0.00 0.06 0.00 0.94 1.00 satan.),則
A=(0 0.1 0.1 0.1 0.3 0.4)。
B=A*R=(0.13 0.2 0.61)。
那么最終所得出的判決結果為satan攻擊。
2)數據記錄(0 tcp http SF 290 516 0 0 0 0 0 1 0 0 0 0 00 0 0 0 0 6 10 0.00 0.00 0.00 0.00 1.00 0.00 0.40 255 2551.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 normal.),那么
A=(0 0.1 0.1 0.1 0.3 0.4)。
B=A*R=(0.73 0.14 0.13)。
那么最終所得出的判決結果就是正常數據。
4 入侵檢測結果的評估
(1)入侵檢測結果評估方法
怎樣比較準確的對此模糊入侵算法的好壞進行評價,從本質上來講,就是可以將入侵攻擊所對應的檢測率當作其評價尺度,還可以將其誤報率當作具體的評價尺度。針對判決結果的輸出來講,其相比于實際結果,可以設定4個數值變量參數,分別時I,N,A與L,除此之外,初始值均可設置為0,見表l。

表1 入侵檢測評估參數的賦值
針對此實驗而言,其檢測率是L/(L+I),而A/(N+A)為其誤檢率。
(2)評估結果
將corrected.gz數據庫,當作開展實驗的主要數據來源。
以下便是實驗結果,如表2。

表2 論文提出的檢測算法的實驗結果
運用相同測試數據,并以模糊模式識別為基礎所得到的實驗結果,見表3。

表3 基于模糊模式識別的入侵檢測結果
(3)結果分析
通過對上述實驗結果進行比較,可得治,本文所探討的入侵檢測算法,能夠得到比較準確的檢測結果,即比較低的誤警率以及比較高的檢測率。相比于運用相同測試數據,并且以模糊模式識別為基礎的攻擊檢測而言,誤警率得到大幅降低。
5 結語
綜上,本文所提出的算法,能夠較好的實現有傳統的模糊化所造成的誤警率偏高問題的有效解決。因而可以盡早發現且最大程度減少虛報入侵情況。因此,入侵檢測技術在實際當中,有著良好的實用價值。但需指出的是,要想得到更加理想的結果,需結合攻擊類型的差異,從中選擇更為適宜、準確的攻擊特征屬性,并且結合協議分析結果,權重分配綜合評判當中的各種因素,并從中獲得所需要的統計信息。所以,將模糊綜合評判與協議分析有機融合在一起的入侵檢測算法,能夠使相關工作變得更加規范,從其所得出的檢測結果可以看出,其乃是值得的滲入研討的。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
石油瀝青(2021年4期)2021-10-14 08:50:44
世界科學技術-中醫藥現代化(2021年10期)2021-03-02 05:52:06
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
中國工程咨詢(2015年2期)2015-02-14 02:59:26
