文本線局部極值區域兩階段場景文本序列識別
2018-08-15 08:24:32董引娣趙曉祎
計算機與生活 2018年8期
董引娣,趙曉祎
1.重慶城市管理職業學院 信息工程學院,重慶 401331
2.中國人民解放軍后勤工程學院 訓練部,重慶 401331
1 引言
場景文字定位與識別是非常有價值的研究方向,可幫助視障人士進行語言翻譯和寫作,同時可用于大型圖像和視頻數據庫文本內容自動索引(例如谷歌街景、Flickr等)。不同于傳統印刷文檔的OCR(optical character recognition),現有場景文本識別方法在識別精度上無法滿足應用需要,最近的ICDAR 2015大賽獲獎算法也只能達到70%的識別精度,并且要求場景文本不存在透視變形或明顯噪聲[1]。
文本定位過程在算法中占有非常大的計算復雜度,因為對應于大小為N像素的圖像會產生2N個子集。現有算法一般采用兩種處理方式:
(1)借鑒其他對象的檢測問題,利用滑動窗口方法對個別字符或整個詞進行定位。這種方法已得到成功應用,例如文獻[2]提出基于樹結構模型的端到端場景文本識別;文獻[3]提出集成多個字符建議的魯棒場景文本提取方法;文獻[4]提出基于窗口特征識別的魯棒的自然場景圖像文本檢測方法等。這類方法的優點是對噪聲和模糊性具有很強的魯棒性,因為對于窗口興趣區域的特征進行了充分的開發利用[5]。主要缺點是需要評估的矩形數量迅速增長時,須找到具有不同規模、方向、旋轉和扭曲的文本,導致定位精度降低。
(2)使用圖像的局部屬性(如顏色、強度或筆劃寬度)將單個字符定位為連接組件的方法。這種方法逐漸得到流行,例如文獻[6]提出基于強度跟蹤的多方位場景文本檢測,設計了動態規劃檢測方法的統一框架;文獻[7]提出利用智能手機處理的自適應場景文本圖像二值化顏色檢測方法;文獻[8]提出基于筆劃寬度的實時無詞典場景文本定位與識別方法。這類方法的復雜性不依賴于所有字符尺度的文本參數,在OCR階段可檢測到字符分割的連通分量。最大缺點是依賴于字符是連接組件的假設,噪聲的單像素改變可能會導致連接組件的大小、形狀或其他屬性不發生變化,從而可能影響其分類。
本文提出了終端到終端的實時文本定位和識別方法,它不依賴于任何先驗知識即可實現文本檢測,這與詞匯為基礎的方法存在明顯的不同。本文方法屬于第二種算法類別,因為它首先檢測單個字符,然后建立更復雜的字符結構,例如字和文本線。最后,通過實驗仿真對算法性能進行了測試和分析。
2 算法框架描述
近期,大多數文本局部化方法都使用連接組件方法。這些方法在個體特征檢測方法上有所不同,它們可以基于邊緣檢測、特征能量計算或極值區域檢測。雖然這些方法都非常注重個性檢測,但最終分割的決策僅取決于局部特征。這種方法對噪聲和模糊圖像很敏感,因為它依賴于成功檢測到的邊緣,并且只為每個字符提供一個分割,這對OCR模塊來說可能不是最好的。現有大多數方法只注重文本識別,文字位置通過人工進行設定,只有少數的端到端文本定位和識別方法能夠處理嘈雜的數據,但它們的通用性受到詞匯字典的限制。本文提出文本線局部極值區域兩階段場景文本序列識別方法,所要解決的便是文本的自動定位和處理方法的通用性問題。
對于一組給定的訓練圖像S={(Ii,Bi)}ni=1,其中Ii為圖像,Bi是圖像Ii中用于指定字符的位置和范圍的一組邊界框。文本檢測算法應該能夠捕捉到字符的本質子結構,并且區別于局部背景,具有相互對立關系。由于S僅提供字符級注釋,需要對其字符原型進行自動識別[9-10]。
給定“發現”圖像集D和“自然詞語”圖像集N,算法目標是在D中發現歧視其他集群的有代表性補丁集群及圖像集N中可視詞語。該算法輸出是具有最高排名的補丁集群K和分類集C。每個集群Kj對應分類器Cj可檢測到在新圖像下與聚類Kj相似的補丁。本文提出端到端的實時文本定位和識別方法,不依賴于任何先驗檢測知識。該方法首先檢測單個字符,然后建立更復雜的結構模型。通過將字符檢測問題轉換成一組有效的順序極值區域(extremal regions,ER)選擇問題,實現實時的檢測能力,算法框架見圖1所示。
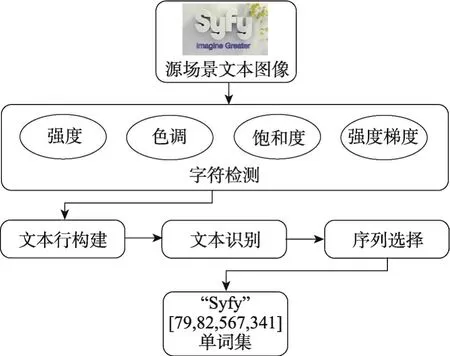
Fig.1 Algorithm framework圖1 算法框架
在第一階段,利用特征計算對每個ER字符概率進行計算,這部分算法計算復雜度較低,然后選取具有局部最大概率的特征用于第二階段,并采用復雜度更加昂貴的算法細化特征計算。利用高效聚類算法將ER處理成文本線,然后利用字符區域的標簽以及OCR分類器合成字體。最后,在上下文中的每個字符的文本線已知的情況下,可實現最有可能的字符序列的快速選取,實現算法效率提升。
3 特征檢測過程
3.1 極值區域
考慮圖像映射I:D?N2→V,對于彩色圖像,V為[0,255]3。圖像I的信道是映射C:D→S,其中S是完全有序集合,fc:V→S是一個完全有序集的像素值投影。令A表示鄰接區域A?D×D。本文考慮4像素情形,具有坐標(x±1,y)和(x,y±1)的像素是像素(x,y)的鄰接矩陣。圖像I的區域R是D的連續子集[11]:
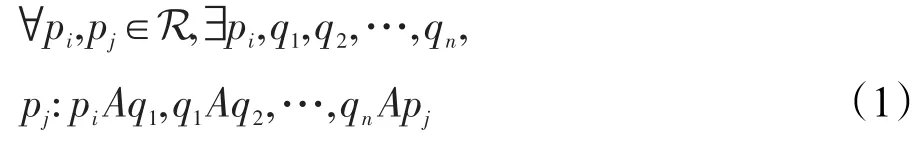
外邊界?R相鄰但不屬于R像素集:

極值區域是其外邊界像素具有嚴格高于該區域本身值的區域:
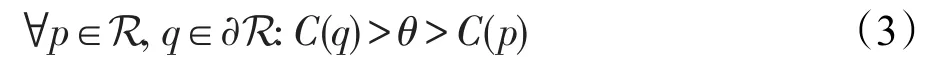
其中,θ表示極值區域的閾值。考慮RGB和HSI顏色空間和附加強度梯度通道(?),其中每個像素通過其鄰居之間的最大強度差近似進行“梯度”像素分配。
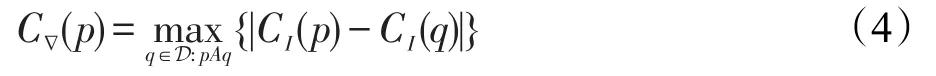
在圖像中,有些字符是由較小元素或多個聯合字符組成的單個元素構成的。采用高斯金字塔分解對圖像進行預處理,如果字符包含多個元素,這些元素融合在一起成為單一區域,則在每級金字塔只有具有一定間隔的字符筆劃寬度被放大。
3.2 描述符的增量計算
ER快速分類關鍵是分類器特征的區域描述符獲取[12]。在閾值θ上極值區域r可構成聯合區域,或在閾值θ-1上的更多極值區域。使用特殊描述符,并利用ER之間存在的包含關系,以增量計算方式進行描述。令Rθ-1表示閾值θ-1上極值區域集合,在閾值θ上極值區域r∈Rθ可利用閾值θ-1上區域像素及像素值θ聯合構成:
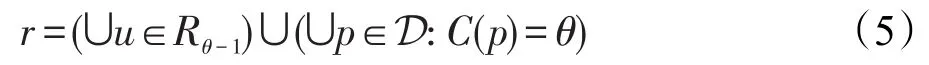
假設閾值u∈Rθ-1上所有極值區域描述符為?(u)。為計算區域r∈Rθ描述符?(r),需對區域u∈Rθ-1描述符和像素{p∈D:C(p)=θ}融合,形成區域r:

其中,符號⊕表示合并區域描述符;ψ(p)表示給定像素p描述符初始化函數。這樣的描述符ψ(p)和⊕存在增量計算過程,如圖2所示。
可通過簡單地依次增加閾值θ從0到255,實現對所有極值區域描述符的計算,在閾值θ中添加像素的計算描述符ψ,在閾值θ-1中重用區域?描述符。此外,假定單個像素ψ(p)描述符計算及組合操作⊕具有固定時間復雜度,由此產生的對于N個像素的圖像所有極值區域描述符的計算復雜度為O(N),每個像素只計算一次?(p),那么組合函數可在最多N次計算過程中完成評估,因為極值區域數目上限為圖像中的像素數。本文使用以下增量計算描述符:
(1)面積參數a,即像素數,其初始化函數是一個常數函數ψ(p)=1,組合運算⊕表示加法操作(+)。
(2)邊界框(xmin,ymin,xmax,ymax),表示區域右上角和左下角。坐標為(x,y)像素p的初始化函數為(x,y,x+1,y+1),組合操作⊕為(min,min,max,max)。該區域寬度ω和高度h可計算為xmax-xmin和ymax-ymin。
(3)周長參數p,區域邊界長度見圖2(a)。在像素p中當閾值添加時,初始函數ψ(p)確定周長的變化:
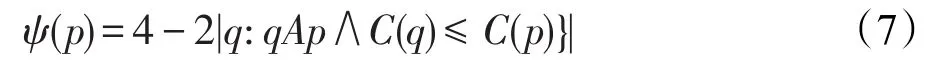
式中,ψ(p)的計算復雜度為O(1),因為每個像素最多有4個鄰居像素。

(4)歐拉數η。歐拉數是一個二元圖像的拓撲特征,其計算形式為:其中,C1、C2和C3分別表示圖像中二進制像素數。初始化函數值ψ(p)可通過對給定閾值C(p)像素p由0到1變化所確定:
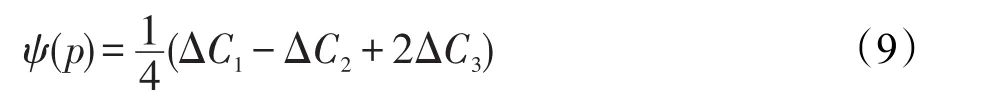
3.3 順序分類
在本文方法中,每個信道分別進行高斯金字塔處理,然后檢測ER。為減少高誤報率和高冗余的ER檢測器,順序分類只對獨特ER對應的字符進行選擇。
步驟1閾值從0逐漸增加到255,對極值區域r的描述符增量計算復雜度為O(1),這些描述符作為分類器的特征,用于對類的條件概率p(character|r)的計算,只選擇具有最大概率的極值區域進行第二步計算,如圖3所示。
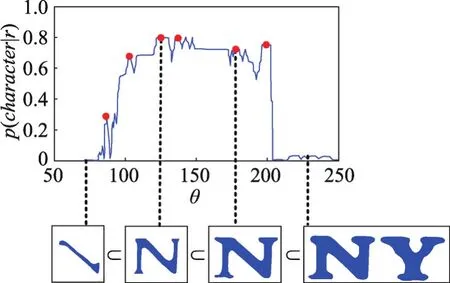
Fig.3 Conditional probability computation of a class圖3 類的條件概率計算
采用AdaBoost分類器順序分類,采用的字符特征有:縱橫比ω/h、緊性、孔數(1-η)、水平通道特征,作用是在水平投影中估計字符筆劃數。只對c的固定大小子集采樣,獲得固定復雜度計算過程。利用Logistic修正,對分類器輸出進行概率函數p(character|r)校準。通過實驗,設置參數pmin=0.2,Δmin=0.1。
步驟2通過步驟1篩選的極值區域進行字符和非字符類別劃分,但對這些特征進行操作的計算復雜度也很高。本文采用支持向量機(support vector machine,SVM)和RBF(radial basis function)核函數進行操作。該步驟中利用步驟1所有特征,并增加如下特征:開孔面積比ah/a,其中ah表示區域孔的像素數;凸殼比率ac/a,其中ac表示區域凸包的面積;外邊界拐點數κ,表示區域邊界周圍像素之間的凹凸角變化次數。
4 算法計算步驟
4.1 文本行構建
令R表示在前一階段中檢測到的所有通道和尺度區域(字符候選)集。搜索所有序列空間,及其對應的子字符序列。利用底線估計和附加的外形限制進行集群個體距離測量。基于窮舉算法進行初始文本線候選,如算法1所示。
算法1初始文本線候選
輸入:區域集R。
輸出:三元組集T。
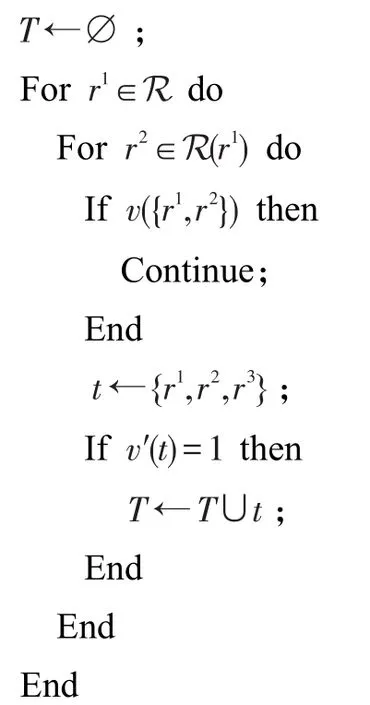
算法1中,對r1∈R進行窮舉操作,利用其鄰居r2∈N(r1)和r3∈N(r2)。r2∈N(r1)指相距K=5以內的r2與r1,該距離表示兩區域質心距離。通過限制集合r2∈N(r1)到區域r2方式,按照自左到右方向強制執行文本,其質心在r1質心右邊,即cx(r2)>cx(r1),其中cx(r)表示該區域r的質心x的坐標。
在窮舉搜索中,區域對(r1,r2)和(r2,r3)及(r1,r2,r3)可利用約束v進行修剪,目的是降低窮舉操作復雜度。在本文方法中,二進制約束v使用高度比和區域距離寬度歸一化值作為特征,而三元約束v′采用文本行高度和區域質心角度歸一化距離底線作為特征。實驗中,AdaBoost分類器事先利用ICDAR 2013訓練集進行訓練。
算法2構建文本行,每個三元組變成長度為3的文本行,利用最小二乘法估計初始基線方向b。橫框中包含所有的行文本區域計算,并保存坐標(左)、(右)和(高)。查找行l和l′的最小距離dist(l,l′)。兩部分區域合并,基于合并文本行區域集可實現對新底線方向和包圍盒坐標更新。最小相互距離dist(l,l′)定義如下:
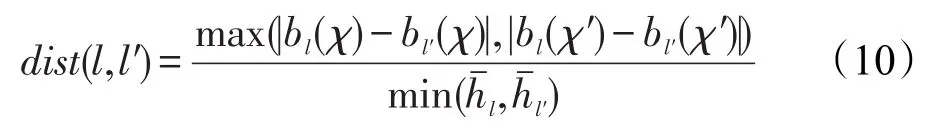
算法2文本線構建
輸入:三元組集T。
輸出:文本線集L。


4.2 基于序列選擇的字符識別
令表示所有文本行區域的集合,即:

每個候選區域r∈利用Unicode碼對最近鄰分類器進行標記。區域r標簽集r∈定義為:
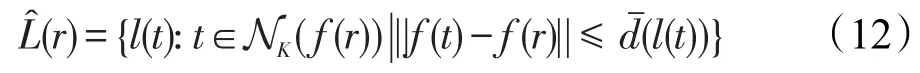
其中,l(t)表示訓練樣本t的標簽;NK(f(r))表示字符特征空間f中區域r的K近鄰;是標簽l的最大距離;A是支持Unicode字符集。
首先將區域歸一化到固定大小為35×35像素的矩陣,保留該區域的質心和縱橫比。訓練集由白色背景上的黑色字母圖像組成,共有5 580個訓練樣本。最近鄰分類器NK由近似最近鄰分類器實現,K設定為11。為計算每個類別估計的值,每個特征表示為訓練集的交叉驗證乘以β的公差因子,這里選取β=2.5。
考慮將字表示為字符序列,在文本線中給定區域r1和r2,如果r1和r2是相同文本行一部分,r1為r2前身,即字符序列中與r1相關聯的字符緊接在與r2相關聯字符之前。可引入有向連接圖G對其進行表達,從而使節點對應于標記區域:

其中,rl表示具有標簽l∈A的區域r。沒有由字符分類器分配任何標簽的區域不是文本行圖的一部分。每個節點rl和邊具有關聯的權值s(rl)和,計算形式分別為:
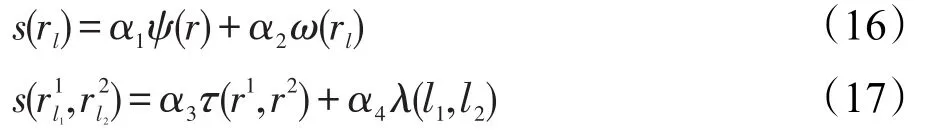
其中,權重α1、α2、α3、α4可由訓練階段確定。
字符識別置信度ω(rl)表示通過分類器區域r具有字符標簽l的概率。利用標簽為l的訓練集對K近鄰模板進行計算,獲得字符特征空間中的距離和,并利用最近模板的距離進行歸一化:
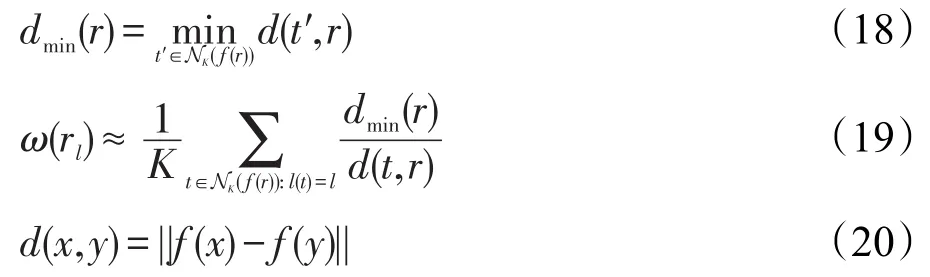
閾值重疊區間τ(r1,r2)是區域r1和r2間隔的交集;轉移概率λ(l1,l2)表示給定語言模型中,標簽l1跟隨l2的估計概率。本文算法最后一步,為每個節點和邊緣分配分數,實現有向圖構造。該過程中與每個文本行關聯的單詞序列作為算法的最終輸出。則本文算法計算復雜度為O(pN),其中p為所采用的通道數,N為圖像的像素數。
5 實驗分析
硬件設置:CPU-AMD 7650K 3.30 GHz,內存為8 GB ddr4-2400k,系統為Win10旗艦版。參數設置:極值區域的閾值θ∈[0,255]逐漸增加,pmin=0.2,Δmin=0.1,間距K=5,公差因子β=2.5,歸一化區域的固定大小35×35像素,其余參數b、、、在算法開始節點進行自動估計,見算法2。
對比算法選取文獻[13-16],其中文獻[13]是一種考慮紋理特征和圖像矩的自然場景文本識別算法;文獻[14]利用邊界聚類、筆劃分割和字符串片段分類實現對場景圖像中的文本局部化操作;文獻[15]是基于文本嵌入式分割的場景文本有效圖切割識別算法;文獻[16]也是一種局部化操作的場景文本識別算法。測試對象選取USTB-SV1K數據庫,其場景文本具有多方向特征,如圖4所示。
該數據庫是具有500幅圖像的多方向場景文本數據庫。圖片平均尺寸是1 600×1 200像素。場景圖像采集通過瀏覽器直接在亞馬遜網站上復制,并通過人工注釋,特定圖像與特定文本,例如企業標志和名稱只能處于水平方向。評價指標為:識別精度(precision)、召回率(recall)、F-score以及計算時間。前3項指標定義如下:


Fig.4 USTB-SV1K database multi-direction features(partial images)圖4 USTB-SV1K數據庫多方向特征(部分圖像)
式中,TP表示正確劃分為正例個數;FP表示錯誤劃分為正例個數;FN表示錯誤劃分為負例個數。實驗結果如表1所示。
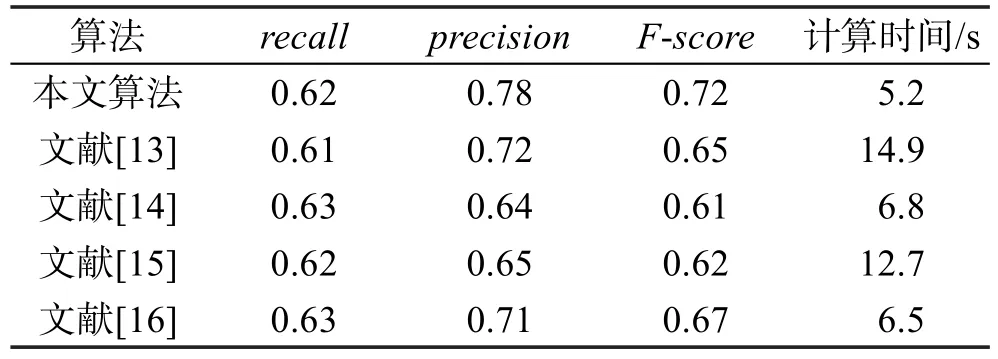
Table 1 Comparison of experimental data表1 實驗對比數據
根據表1數據,在recall指標上,幾種對比算法性能相差不大,均分布在0.61~0.63之間。在precision指標上,本文算法精度為0.72,相對于選取的幾種算法,具有較為明顯的優勢,對比算法識別精度分布在0.61~0.67之間。而在計算時間上,本文算法計算時間為5.2 s,在上述幾種算法中,計算時間是最少的。對比算法中,文獻[14]和文獻[16]也都采用了局部化操作方法,因此其計算時間也相對較少,分別為6.3s和6.5s。
圖5所示為文獻[13-16]以及本文算法的場景文本識別效果,實驗對象選自USTB-SV1K數據庫。從圖5結果可知,從分割效果上看,本文算法要明顯優于選取的文獻[13-16]對比算法。文獻[13]算法和文獻[14]算法在HOWARD字符識別上效果不理想,存在較大區域的黑化現象。文獻[16]算法在REDBACK、HOWARD和LITTER字符上的識別效果不好,存在白化現象。文獻[15]算法在上述實驗對象上的識別效果總體還可以,但是噪聲問題比較嚴重,識別圖像不夠清晰。上述實驗結果驗證了本文算法的性能優勢。

Fig.5 Image localization segmentation effect圖5 圖像局部化分割效果
6 結束語
本文提出了一種基于文本線局部極值區域兩階段場景文本序列識別方法,采用兩個階段進行場景文本的識別,將第一階段的最大概率的局部特征作為第二階段的輸入,然后利用文本線處理方式和順序分類算法實現場景文本的有效識別。實驗結果驗證了算法性能優勢。今后研究主要集中在以下三點:(1)采用更復雜和數量更大的數據庫對算法性能進行測試;(2)對應用系統開發進行研究,并考慮建立與真實字符系統的接口;(3)對算法性能進行優化,實現更佳的識別性能和更快速的計算。
猜你喜歡
今日農業(2021年9期)2021-11-26 07:41:24
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
電測與儀表(2015年5期)2015-04-09 11:30:52
