基于抽樣和兩級CBF的長流識別算法
2018-08-16 14:16:58翟金鳳孫立博林學(xué)勇秦文虎
中國測試 2018年7期
翟金鳳, 孫立博, 魯 凱, 林學(xué)勇, 秦文虎
(1. 東南大學(xué)儀器科學(xué)與工程學(xué)院,江蘇 南京 210096; 2. 南京市計量監(jiān)督檢測院,江蘇 南京 210049)
0 引 言
諸多研究表明,網(wǎng)絡(luò)流具有顯著的重尾分布特征,數(shù)量較少的長流占據(jù)了網(wǎng)絡(luò)流量的大部分[5]。因此掌握長流信息就可以對鏈路上經(jīng)過的所有網(wǎng)絡(luò)流有個整體的認(rèn)識,便于對網(wǎng)絡(luò)流量進(jìn)行管理和監(jiān)測分析,對網(wǎng)絡(luò)流量計費(fèi)、安全檢測、流量調(diào)控等工程應(yīng)用起著重大作用,并且對長流進(jìn)行識別可以有效縮減處理和存儲的數(shù)據(jù)量,提高系統(tǒng)處理效率和資源利用率。
目前長流識別算法主要使用抽樣技術(shù)、哈希技術(shù)以及Bloom Filter技術(shù)。單獨(dú)使用抽樣技術(shù)需要對流信息進(jìn)行維護(hù),同時會產(chǎn)生較大的計算開銷;而單獨(dú)使用哈希技術(shù)或Bloom Filter技術(shù)則會增大哈希沖突,影響測量精度[6]。因此可以將抽樣技術(shù)和哈希技術(shù)或者Bloom Filter技術(shù)相結(jié)合以實現(xiàn)更高效的長流識別。景泉等[7]提出了一種將分層隨機(jī)抽樣與哈希技術(shù)相結(jié)合的長流識別算法,能夠較準(zhǔn)確地識別出長流,但對流長度的測量存在一定誤差,且哈希技術(shù)仍需對流信息進(jìn)行維護(hù),浪費(fèi)存儲資源。吳燁等[8]提出利用雙重計數(shù)型布隆過濾器(counting bloom filter,CBF)對長流進(jìn)行識別的算法,并進(jìn)行了一定的理論分析,表示算法可以適應(yīng)于大規(guī)模網(wǎng)絡(luò)的流量監(jiān)測,但對每個報文進(jìn)行長流過濾并不能有效節(jié)約空間和時間資源。劉元珍[9]則先對報文進(jìn)行隨機(jī)抽樣,再通過多級CBF過濾出達(dá)到閾值的長流,一定程度上可以提高長流識別的準(zhǔn)確率,但同時也犧牲了一定的時間和存儲資源。
本文提出一種基于抽樣和兩級CBF的長流識別算法,將長流過濾和流長計數(shù)分開處理。首先對觀測時間內(nèi)鏈路上通過的報文進(jìn)行系統(tǒng)抽樣。繼而利用兩級CBF對被抽樣報文進(jìn)行處理,第一級CBF對長流進(jìn)行過濾,識別出報文數(shù)達(dá)到閾值的長流;第二級則對識別出的長流所含報文數(shù)進(jìn)行統(tǒng)計。最后利用第二級CBF對所有未被抽樣的報文進(jìn)行查詢,若屬于已識別出的長流,則對流長繼續(xù)計數(shù)。
1 抽樣技術(shù)和Bloom Filter技術(shù)介紹
1.1 報文抽樣技術(shù)
在網(wǎng)絡(luò)測量中,抽樣是指以某種方式從網(wǎng)絡(luò)中提取一定數(shù)目的報文或流數(shù)據(jù),通過樣本盡可能準(zhǔn)確描述總體數(shù)據(jù)的參數(shù),以節(jié)約系統(tǒng)空間和時間資源,因而被廣泛應(yīng)用于高速網(wǎng)絡(luò)流量測量領(lǐng)域。使用抽樣進(jìn)行網(wǎng)絡(luò)流量測量時,必須考慮如何從感興趣的數(shù)據(jù)總體中提取具有充分代表性的樣本對象,以確保所提取的樣本與總體特征相近[10]。
典型的報文抽樣技術(shù)主要包括系統(tǒng)抽樣、隨機(jī)抽樣和分層抽樣3種[11]。系統(tǒng)抽樣是在總體中按固定的間隔進(jìn)行樣本的選取,如圖1(a)所示[12]。其主要優(yōu)點是易于理解、簡便易行,適用于總體容量很大的情況;缺點則是易存在同步問題,引起測量失真。隨機(jī)抽樣即嚴(yán)格按照隨機(jī)原則從觀察對象總體中提取一定數(shù)量的樣本,如圖1(b)所示。該方法操作最為簡便迅速,樣本間相互獨(dú)立性高,但樣本分配較分散,代表性恐有不足。分層抽樣先根據(jù)額外信息將觀察對象總體分成不同的層,然后分別在各層中以獨(dú)立、隨機(jī)的方式進(jìn)行樣本對象的提取,如圖1(c)所示[13]。分層抽樣樣本和總體結(jié)構(gòu)相似度高,代表性強(qiáng),但層界的設(shè)定會增加樣本選擇的成本和復(fù)雜性,同時怎樣選取分層特征或規(guī)則也是個難點。
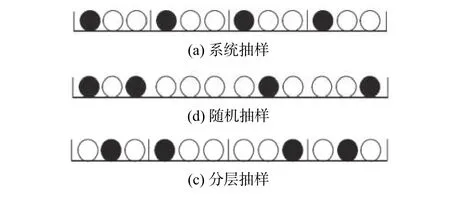
圖1 3種抽樣方法
本文綜合考慮樣本對總體的代表性以及計算和時間的復(fù)雜度后,選用系統(tǒng)抽樣作為長流識別過程中的抽樣方式。
1.2 Bloom Filter技術(shù)
Bloom Filter是一種基于哈希的二進(jìn)制向量數(shù)據(jù)結(jié)構(gòu)[14],其利用一個位向量簡潔地表示一個包含大量元素的集合,同時實現(xiàn)快速查詢某一元素,并檢測該元素是否屬于某一集合[15-16]。元素插入和查詢的時間都是常數(shù)級,可以顯著節(jié)約空間和時間資源,缺陷是存在一定的誤判率和不支持元素刪除操作。
初始化Bloom Filter時,將位向量的每一位均設(shè)置為0,選取k個相互獨(dú)立的哈希函數(shù)h1,h2,···,hk[17]。插入元素時,計算元素的k個哈希值,將元素映射到位向量中相應(yīng)的k個位置,設(shè)置這k個位置為1,其余位置不做改變。查詢元素時,若元素的k個哈希值映射到位向量中的位置均為1,則判定該元素屬于Bloom Filter所表示的集合。但由于映射過程中存在某一位被重復(fù)置1以及哈希沖突的可能性,進(jìn)而會導(dǎo)致某個不屬于集合的元素被判定為屬于集合,這樣的誤判概率定義為“誤判率”[18]。
當(dāng)級配碎石拌和完畢后應(yīng)及時采用大噸位自卸式卡車將其運(yùn)輸至施工現(xiàn)場,運(yùn)輸過程中車輛的行駛速度不宜過快,避免混合料出現(xiàn)較為嚴(yán)重的離析現(xiàn)象,另外,運(yùn)輸車的車廂上方宜覆蓋一層帆布,以減小級配碎石混合料的水分散失。
標(biāo)準(zhǔn)Bloom Filter不支持元素的刪除操作,CBF[19]作為Bloom Filter典型的改進(jìn)結(jié)構(gòu)之一,將Bloom Filter的每一位擴(kuò)展為一個counter計數(shù)器,增加元素刪除功能。如圖2所示,插入元素時,將對應(yīng)位置的k個計數(shù)器值加1;刪除元素時則將對應(yīng)的k個計數(shù)器值減1;查詢元素時,若元素映射到對應(yīng)位置的k個計數(shù)器值都不為0,則判定為屬于集合。與Bloom Filter一樣,CBF在判斷元素是否屬于集合時仍存在一定的誤判率。
2 長流識別算法
設(shè)觀測時間內(nèi)鏈路上通過的報文總數(shù)為N,若將占據(jù)報文總數(shù)m%以上的流定義為長流,則閾值設(shè)置為T=N·m%,長流即為觀測時間內(nèi)所含報文數(shù)超過閾值T的流。長流的定義是可調(diào)的,通過改變m的值進(jìn)而滿足各種測量應(yīng)用需求。
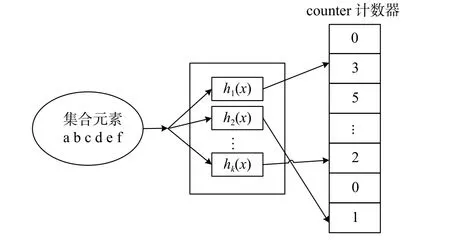
圖2 CBF原理圖
由網(wǎng)絡(luò)流顯著的重尾特性可見,如果對鏈路上通過的總報文按某種抽樣頻率進(jìn)行抽樣,那么長流中包含的大量報文被抽中的可能性要比短流中的少量報文大的多,因此可以先對總報文實施抽樣,再利用抽樣后的報文進(jìn)行長流識別。這樣既能大大縮減處理的數(shù)據(jù)量,有效節(jié)省時間資源,又能保證長流識別的準(zhǔn)確性。如圖3所示,基于抽樣和兩級CBF的長流識別算法的實現(xiàn)過程為:
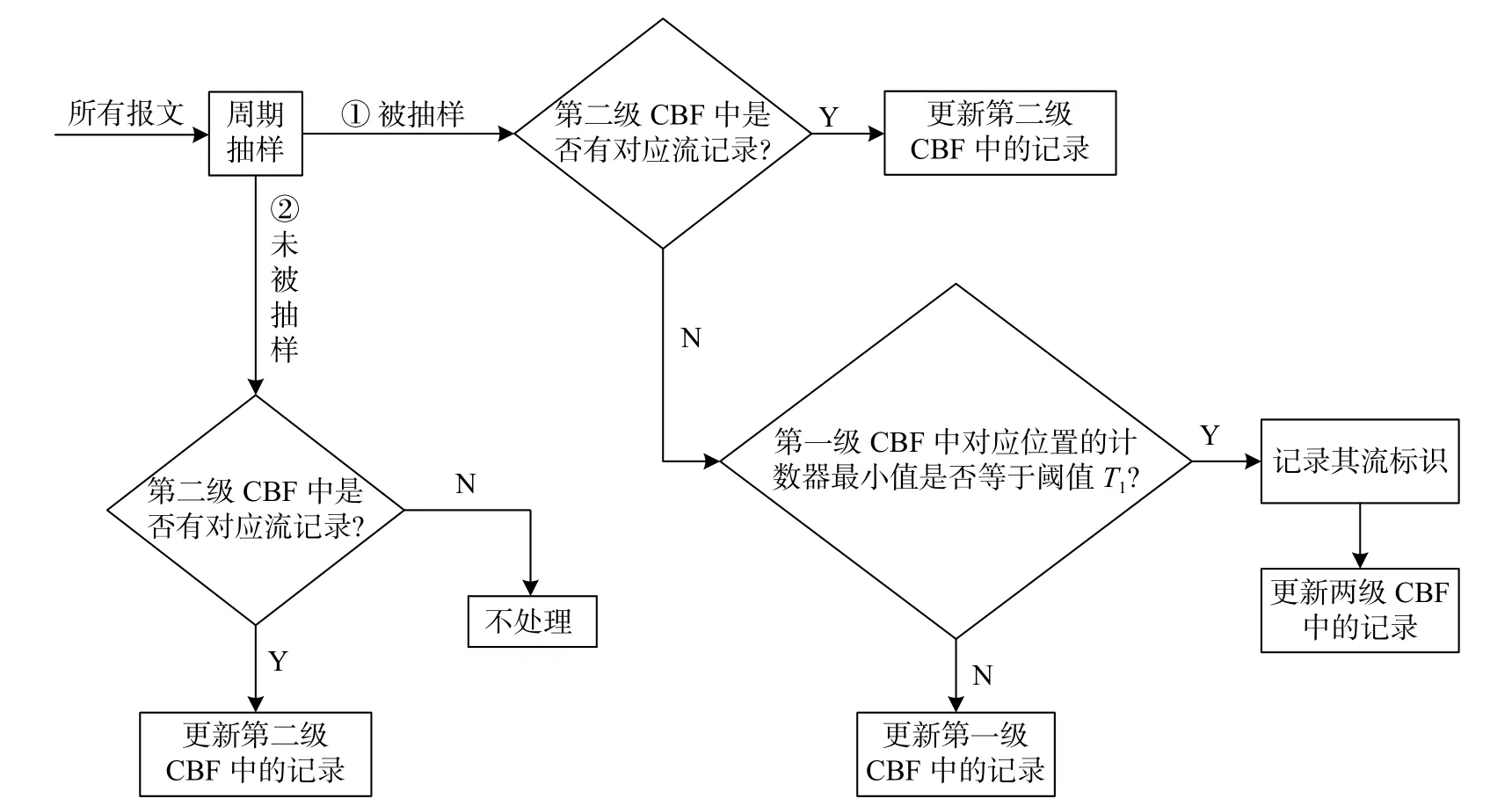
圖3 算法流程示意圖
2)設(shè)定長流識別的閾值T1,同時合理配置兩級CBF的結(jié)構(gòu)參數(shù)。由于報文的抽樣頻率為p=1/n,根據(jù)簡單線性關(guān)系,使用抽樣報文進(jìn)行長流識別的閾值應(yīng)設(shè)置為T1=T/n。兩級CBF選用相同的k個沖突小的哈希函數(shù)h(1),h(2),···,h(k);第一級CBF結(jié)構(gòu)中counter數(shù)組的長度m1設(shè)置為大于抽樣報文總數(shù)N/n的2的冪次方,每個counter分配的位數(shù)b1需滿足條件2b1>T1,且需適當(dāng)?shù)囟喾峙鋷孜灰员苊庥嫈?shù)器溢出;第二級CBF結(jié)構(gòu)中counter數(shù)組的長度m2設(shè)置為大于報文總數(shù)N的2的冪次方,每個counter分配的位數(shù)b2需滿足條件也需適當(dāng)?shù)囟喾峙鋷孜灰员苊庥嫈?shù)器溢出。
3)對于每個被抽樣的報文,先通過k個哈希函數(shù)將其映射到第二級CBF的相應(yīng)位置。若相應(yīng)位置的k個計數(shù)器值均不為0,則判定該報文屬于已識別出的長流,將其插入第二級CBF中,即將這k個計數(shù)器值分別加1。
4)若相應(yīng)位置的k個計數(shù)器值中有任意一個為0,則判定該報文不屬于已識別出的長流,再通過k個哈希函數(shù)將其映射到第一級CBF中,求取相應(yīng)位置的k個計數(shù)器的最小值;若這k個計數(shù)器的最小值等于閾值T1,則判定其所屬流為長流,記錄下該報文的流標(biāo)識,將這k個計數(shù)器值分別減去閾值T1,并將其映射到第二級CBF中,設(shè)置相應(yīng)位置的k個計數(shù)器值為T1+1。
5)若這k個計數(shù)器的最小值不等于閾值T1,則判定其所屬流不為長流,將其插入第一級CBF中,即將這k個計數(shù)器值分別加1。
6)重復(fù)步驟3)~5)完成對所有被抽樣報文的處理后,通過第二級CBF對所有未被抽樣的報文進(jìn)行查詢。若報文映射到第二級CBF的相應(yīng)位置的k個計數(shù)器值均不為0,則判定該報文屬于已識別出的長流,將其插入第二級CBF中,即將相應(yīng)位置的k個計數(shù)器值分別加1,否則不做任何處理。
由上述算法的具體實現(xiàn)過程可以看出,對所有報文處理完后,步驟4)中記錄的流標(biāo)識即為該算法識別出的長流的流標(biāo)識;將記錄的流標(biāo)識映射到第二級CBF中,相應(yīng)位置的計數(shù)器的最小值即為該算法測量出的長流的流長度。
3 實驗分析
實驗選取互聯(lián)網(wǎng)數(shù)據(jù)分析合作組織(CAIDA)公開提供的2016年3月17日在Chicago采集的實際Trace數(shù)據(jù)進(jìn)行仿真分析。實驗平臺為Visual Studio 2013,原始Trace中共有1 759 536 911個報文,本文截取前5 000 000個報文數(shù)據(jù)進(jìn)行實驗分析,閾值設(shè)置為21 000,報文數(shù)超過閾值的真實長流共有3個,具體長流信息如表1所示。實驗中的流是指具有相同的源和目的IP地址的報文集合,具體的流標(biāo)識的定義可以根據(jù)網(wǎng)絡(luò)實際應(yīng)用需求決定。
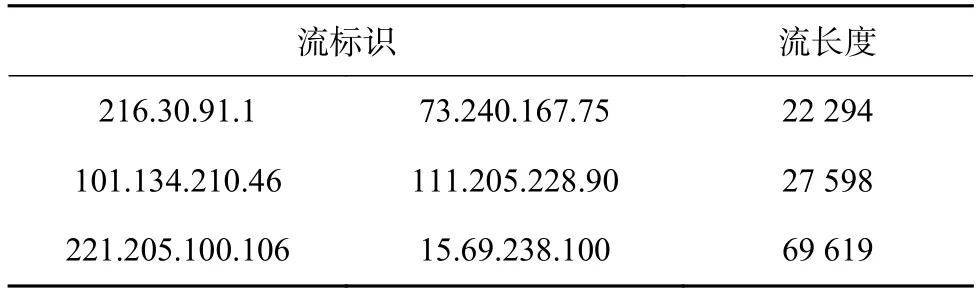
表1 真實長流信息
分別以1/10、1/50、1/100的抽樣頻率對總報文進(jìn)行系統(tǒng)抽樣,兩級CBF的哈希函數(shù)均選用SHA1算法。分別取哈希函數(shù)個數(shù)為1,2,3進(jìn)行長流識別,當(dāng)哈希函數(shù)個數(shù)大于1時,對報文信息進(jìn)行復(fù)制作為新的SHA1輸入以生成新的哈希值。當(dāng)抽樣頻率設(shè)為1/100,哈希函數(shù)個數(shù)設(shè)為1時,算法仿真結(jié)果如表2所示,可以看出由本算法識別出的長流信息與真實的長流信息完全相同。
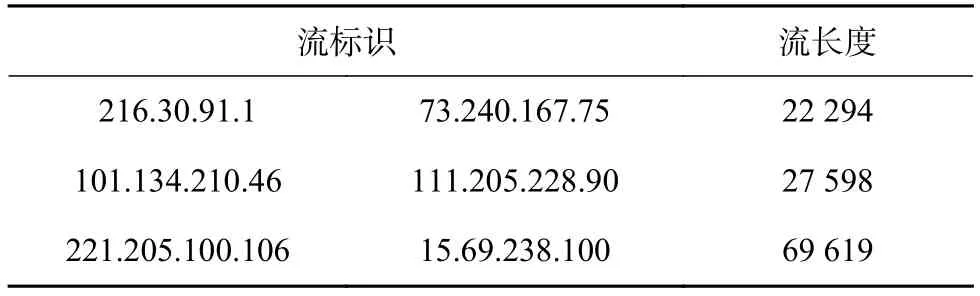
表2 算法識別出的長流及流長度
使用不同的抽樣頻率和哈希函數(shù)個數(shù)進(jìn)行仿真實驗后發(fā)現(xiàn):
2)當(dāng)系統(tǒng)抽樣的抽樣頻率分別取1/10、1/50、1/100時,該算法均可以零誤差地識別出各長流及其流長度。由此可以看出,長流識別中利用系統(tǒng)抽樣可以提取出具有充分代表性的報文樣本,且操作簡單,時間復(fù)雜度低。同時,抽樣頻率越小,算法用時越短,識別速度越快,因此在報文總數(shù)較大時,可以適當(dāng)降低抽樣頻率以提高算法的處理速度。
4 結(jié)束語
本文提出一種基于抽樣和兩級CBF的長流識別算法,對3種典型的報文抽樣技術(shù)進(jìn)行性能比較分析后,選取系統(tǒng)抽樣對總報文進(jìn)行抽樣;繼而利用兩級CBF對被抽樣報文分別進(jìn)行長流過濾和流長計數(shù)處理,最后再利用第二級CBF對所有未被抽樣的報文進(jìn)行查詢,統(tǒng)計出長流所含的總報文數(shù)。通過仿真實驗驗證本文算法能在有效節(jié)約空間和時間資源的基礎(chǔ)上,既實現(xiàn)對長流的準(zhǔn)確識別,又實現(xiàn)對原始流長度的零誤差的高精度測量。同時,算法還具有可擴(kuò)展性,一定誤差范圍內(nèi)可以選用相對簡單的哈希算法,或者使用硬件實現(xiàn),以進(jìn)一步提高算法的處理效率,滿足當(dāng)前高速網(wǎng)絡(luò)發(fā)展對網(wǎng)絡(luò)流量監(jiān)測的需求。
