面向Docker容器的動態負載集群伸縮研究?
2018-08-28 02:50:24楊忠
艦船電子工程 2018年8期
關鍵詞:資源
楊 忠
(成都理工大學工程技術學院 樂山 614000)
1 引言
隨著互聯網的迅猛發展,傳統計算機架構已不能滿足爆炸式增長的數據處理需求,云計算的出現為這一問題提供了新的解決思路,然而在實際使用時,服務器通常會面臨多種不同種類的工作負載[1],企業需要根據這些負載的變化動態地調整服務器的數量以保證服務的穩定性[2]。在某些特定的互聯網應用場景中,服務器時常會出現不可預知的負載請求,在這些額外負載出現時,企業需要及時增加服務器的數量,從而保證服務的穩定性,在這些額外負載消退時,企業也需要即使終止部分服務器,節省運維和管理費用。目前已有很多基于動態負載的集群伸縮方法研究,文獻[3]提出了一種基于工作流模型的虛擬機動態分配以及回收的方法,該方法通過對作業指定截止時間的方式來進行作業的調度分配,從而節省計算資源,但是該方法并不能對未來的工作負載進行預測。文獻[4]提出了一種面向混合負載的集群資源彈性調度方法,該方法允許作業基于自身負載特征提出多維度的資源申請,從而實現同一集群內各業務的統一部署與管理。文獻[5]提出了一種基于用戶負載預測的虛擬資源動態調度管理框架,該框架可以對用戶的高負載進行預測并快速做出響應,保證服務的可用性。在以上關于動態負載的集群伸縮研究中,集群的底層都是基于傳統的虛擬機技術,然而虛擬機需要額外的虛擬化控制層來實現硬件的虛擬化,因此給云平臺帶來了性能上的額外損失,并且虛擬機的啟動速度也比較慢。
為了解決以上問題,本文通過引入Docker容器技術,提出了一種基于混合負載的容器集群動態伸縮方案,這一方案能夠根據不同的工作負載進行相應的容器集群伸縮,從而有效地應對網絡峰值,提升服務質量。
2 Docker容器技術
2.1 Docker概述
Docker是一款輕量級的容器管理引擎,其最初實現主要是基于Linux的容器技術(LXC),它使用Go語言進行系統開發,屬于操作系統層面的虛擬化技術[6]。Docker在容器的基礎上進行了進一步的封裝,包括文件系統、網絡通信和進程隔離等,因此能夠給用戶提供一個更加易于使用的接口,極大地簡化了容器的創建和管理操作。
Docker容器從本質上來說是宿主機中的一個進程,它的底層核心技術主要包括Linux上的命名空間(Namespaces)、控制組(Control groups)和聯合文件系統(Union file systems),其中Namespaces主要用來解決容器間的資源隔離問題,cgroups主要用來實現容器的資源限制功能,而UFS則實現了容器內高效的文件操作。
1)Docker資源隔離
Docker使用Namespaces技術來實現底層的資源隔離,Namespaces是Linux內核中的一個強大特性,在同一個Namespace下的進程能夠相互感知彼此的存在,但是對外界的其他進程卻一無所知,由于這一特性,不同容器中的進程雖然都共用同一個內核和某些運行時環境(如系統命令和系統庫),但是彼此都看不到,都以為系統中只有當前容器存在,這樣便達到了獨立和隔離的目的,實現了操作系統層的輕量虛擬化服務。
2)Docker資源控制
Docker使用cgroups技術來實現對底層資源的控制功能,cgroups是Linux內核提供的一種機制,它能夠根據用戶的需求對共享資源(CPU、內存和I/O等)進行隔離和限制,因此可以解決多個容器同時運行時的資源競爭問題。cgroups能夠提供以下四種功能[7]:資源限制、優先級分配、資源統計和任務控制。
資源限制:cgroups能夠限制同一個進程組中能夠使用的資源總量。
優先級分配:cgroups能夠通過控制對一個進程組分配的CPU時間片的數量或磁盤I/O帶寬的大小從而控制進程組的優先級。
資源統計:cgroups能夠統計一個進程組中的資源使用總量。
任務控制:cgroups能夠對進程執行掛起和恢復等操作,從而控制任務的執行狀態。
3)Docker文件系統
Docker使用的聯合文件系統(UFS)是一種高性能的分層文件系統,它支持將文件系統中的修改進行提交和層層疊加,這一特性使得Docker鏡像能夠通過分層來實現繼承,在實際使用時,通常會基于基礎鏡像來制作各種不同的應用鏡像,這些應用鏡像都是共享的同一個基礎鏡像,因此能夠提高存儲效率。
若開發者需要將Docker鏡像升級到新版本,則在改動原始Docker鏡像時,系統會自動創建一個新的鏡像層,因此開發者無需重新構建應用鏡像,只需要在老版本的鏡像上添加新的層即可。在開發者分發鏡像時,也只需要分發這些被改動過的新層內容,這使得Docker的鏡像管理變得更加方便和快捷。
Docker使用UFS作為其文件系統主要有以下幾點優勢[8]:首先由于多個容器能夠共享同一個基礎鏡像存儲,因此能夠有效地節省存儲空間;其次是能夠實現不同應用的快速部署,并且節省內存,這是因為當多個容器共享基礎鏡像時,容器中的進程命中緩存內容的幾率也會大大增加;最后就是應用的升級也會更加方便,開發者可以通過更新基礎鏡像從而一次性更新所有基于此基礎鏡像的容器。
2.2 Docker的優勢
在實際的使用中,Docker通常被用來與傳統的虛擬機技術進行比較,圖1分別列出了Docker和傳統的虛擬機技術的體系結構。傳統的虛擬機技術主要是通過虛擬出一套硬件系統后,在虛擬的硬件上運行一個完整的操作系統,所有的應用程序都運行于這個系統上。而容器中的應用進程則是直接運行于宿主機的操作系統內核上,它不需要進行虛擬硬件的操作,也沒有自己的操作系統,因此會比傳統的虛擬機技術更加輕便快捷[9]。
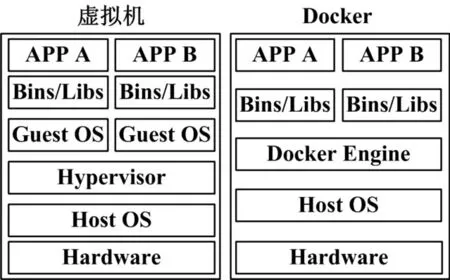
圖1 Docker與虛擬機的比較
3 動態伸縮技術
集群的動態伸縮指的是集群能夠根據工作負載的大小自動調整集群的規模,從而調整其對外服務的能力。借助于動態伸縮技術,企業能夠在網絡峰值到來時自動地擴展資源從而處理額外的工作負載,并且在峰值過后可以自動減少資源從而降低管理和運維成本。動態伸縮技術按照其實現方式可以劃分為響應型伸縮和預測型伸縮。
3.1 響應型伸縮
基于閾值的響應型伸縮算法是一種比較簡單的算法[10],因此被廣泛應用于云平臺的自動擴展中。具體來說,基于閾值的響應型伸縮算法通過對系統資源(如CPU、內存、網絡流量和磁盤I/O等)的使用情況進行實時監控,一旦出現某些指標的實際值超過設定的閾值時,就會發出擴展或收縮命令。在基于閾值的響應型伸縮算法中,最重要的就是響應規則和閾值的制定,通常只有在系統的負載變化很明確的情況下才能很好地制定響應規則,并設置閾值,因此它的優點主要是實現較為簡單,通用性強,但是在一些負載變化不明確的場景中無法很好地使用,系統的伸縮調整往往會晚于工作負載的變化,因此導致用戶的體驗變差。
3.2 預測型伸縮
在基于閾值的響應型伸縮算法中,算法只會對系統資源的實時情況進行響應,因此具有滯后性的特點,而在預測型伸縮算法[11]中,系統會對過去一段時間內的數據進行分析、建模并完成對未來時刻的預測,其中使用到的分析方法主要有時間序列分析、隊列理論和增強型學習等。通常在使用預測型伸縮算法時也會使用到基于閾值的響應型伸縮算法,在預測型伸縮算法計算出預測結果時,再通過響應規則和閾值來決定是否需要進行容器集群的擴展或收縮。預測型伸縮算法能夠很好地彌補基于閾值的響應型伸縮算法的缺點,它能夠在系統的工作負載變化之前就發出擴展或收縮命令,因此能夠保證系統的穩定性和連續性,缺點就是預測算法的選擇非常重要,當預測算法過于復雜時會使得預測建模過程過于緩慢,若預測造成較大偏差又會給容器集群帶來很大的資源浪費。
現有的預測算法主要包括兩大類:機器學習[12]和時間序列分析[13],前者通常需要在學習過程上花費大量的時間,因此不太適用于容器集群的快速伸縮中,而時間序列分析則相對簡單且無明顯的學習過程,計算速度較快。時間序列分析的常見預測算法有簡單移動平均法、指數平滑法和自回歸模型等。
4 容器集群動態伸縮方案
4.1 方案總體架構設計
基于混合負載的容器集群動態伸縮方案的整體架構如圖2所示,整個方案主要由底層容器集群、負載均衡和伸縮控制系統這三部分組成。

圖2 方案總體架構圖
伸縮控制系統是整個方案架構的核心部分,它包括資源監控模塊、伸縮決策模塊和資源調度模塊。其中資源監控模塊負責統計物理主機和Dock?er容器的資源使用情況并報告給伸縮決策模塊,伸縮決策模塊會分析統計數據從而決定是否需要進行擴展或收縮,資源調度模塊負責對底層的容器資源進行調度,負責容器的創建和銷毀工作。
4.2 資源監控模塊
4.2.1 資源監控類型
對容器集群的資源監控可以劃分為對物理主機的資源監控和對Docker容器的資源監控。
1)基于物理主機的資源監控
相對于Docker容器來說,物理主機的生命周期更長,因此更應該進行資源優化,當多個Docker容器運行于同一臺物理主機時,需要很好地考慮資源分配問題,因此需要對物理主機的相關指標進行監控。物理主機的相關監控指標包括主機CPU使用情況、主機內存使用情況、主機網絡帶寬和主機上運行的容器數量等。
2)基于容器的資源監控
主機資源的共享需要對容器進行合理的調配,在容器集群的彈性伸縮中,需要根據容器資源的使用情況來確定是否需要進行擴容或縮容。Docker主要通過cgroups來實現容器的資源限制,限制的對象包括容器的CPU占用率、內存使用量、磁盤I/O,網絡流量也是需要監控的因素之一。
4.2.2 資源監控架構設計
資源監控模塊主要對主機和Docker容器運行時的各項指標數據進行收集并進行存儲,其架構如圖3所示,主要分為數據采集(Collector)、數據處理(Processor)、數據存儲(Storage)和數據展示(Dash?boards)這四個模塊。其中Collector運行在主機上,它會將所有指標數據上傳到Processor,Processor在獲取到監控數據后會通過Storage定時進行數據的存儲,用戶能夠通過Dashboards獲取到監控數據并進行展示。

圖3 資源監控架構圖
4.3 伸縮決策模塊
伸縮決策模塊主要負責根據資源監控模塊的數據判斷是否需要進行容器集群的擴展或收縮,然后向資源調度模塊發出對應的指令,其架構圖如圖4所示。伸縮決策模塊主要由兩個部分組成:Mod?eler模塊和Controller模塊,其中Modeler模塊負責對監控歷史數據進行建模,從而預測未來時刻的數據,而Controller模塊則負責對所有的輸入數據進行判斷,并在滿足伸縮條件時對資源調度模塊發出伸縮調整命令。

圖4 伸縮決策模塊系統架構圖
在實際的互聯網應用場景中,通常可以將服務劃分為計算密集型服務和網絡密集型服務,計算密集型服務主要依賴于CPU,在這種服務場景下,CPU的使用率會在很短的時間內提升到一個較高的值,并且變化很快,因此很難對其進行預測,而網絡密集型服務則主要依賴于網絡帶寬,在這種服務場景下,網絡流量的變化更為平緩,連續性也較強,因此對于網絡流量使用預測算法通常能夠得到一個比較合理的預測值。綜合考慮CPU和網絡流量的變化特征,本文中對計算密集型服務采用基于閾值的響應型伸縮算法,而對網絡密集型服務則采用預測型伸縮算法。
4.3.1 Modeler模塊
Modeler模塊主要負責預測型伸縮算法的實現,它會讀取數據庫中的網絡流量歷史數據,并對其進行建模,然后預測下一時刻的網絡流量值,最后將這一預測值發送給Controller模塊。綜合考慮時序序列分析的各種預測算法,本文選用了二次指數平滑法來對網絡流量值進行預測,二次指數平滑法的計算公式為
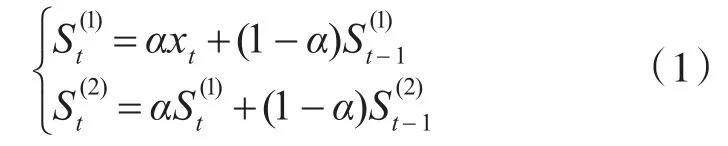
二次指數平滑法的預測模型為

其中,Ft+T為第t+T次的預測值,T為未來預測的期數,at和bt分別為模型參數,其計算公式為
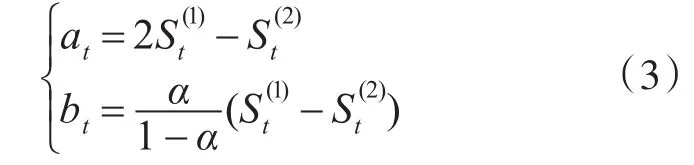
Modeler模塊的工作流程圖如圖5所示。

圖5 Modeler模塊流程圖
4.3.2 Controller模塊
Controller模塊主要負責基于閾值的響應型伸縮算法的實現,它會對Modeler模塊提供的網絡流量預測值和CPU的實時使用數據進行判斷,若有任意一種資源的使用情況超過給定的閾值,則會立即計算需要擴充的容器數量,并向資源調度模塊發送對應的伸縮命令,完成容器集群的伸縮。這一模塊主要包含兩個過程:伸縮條件判斷和容器數量計算。
1)判斷伸縮條件
Controller模塊會根據容器的實際資源使用情況對各種硬件資源(主要是CPU使用率和網絡流量大小)設定一個閾值T0,當容器資源的實際使用值Ut第一次超過這個閾值的時候,會進入伸縮評估階段,算法會維護一個長度為L的數組A,當后續的資源使用值Ut大于閾值T0時,會將Ut加入數組A,若在后續的L個資源使用值中有一個小于閾值T0,則會將數組清零,重新等待下一次的評估。若在L長度的時間內,資源的實際使用值一直都大于閾值T0,則認為需要進行對應服務的擴容,并且在這之后Controller模塊會進入一段時間的冷卻階段,這期間不會進行伸縮評估,避免容器集群的頻繁伸縮給系統服務帶來劇烈抖動[14]。
2)計算容器數量
當伸縮條件判斷過程給出了服務擴容的信號,則系統會進行擴充容器數量的計算。擴充容器數量的計算主要通過網絡流量進行估算,若設定單個容器的服務能力為C0,額外網絡流量對應的服務需求為C,則系統所需要擴充的容器數量為

整個Controller模塊的流程圖如圖6所示。
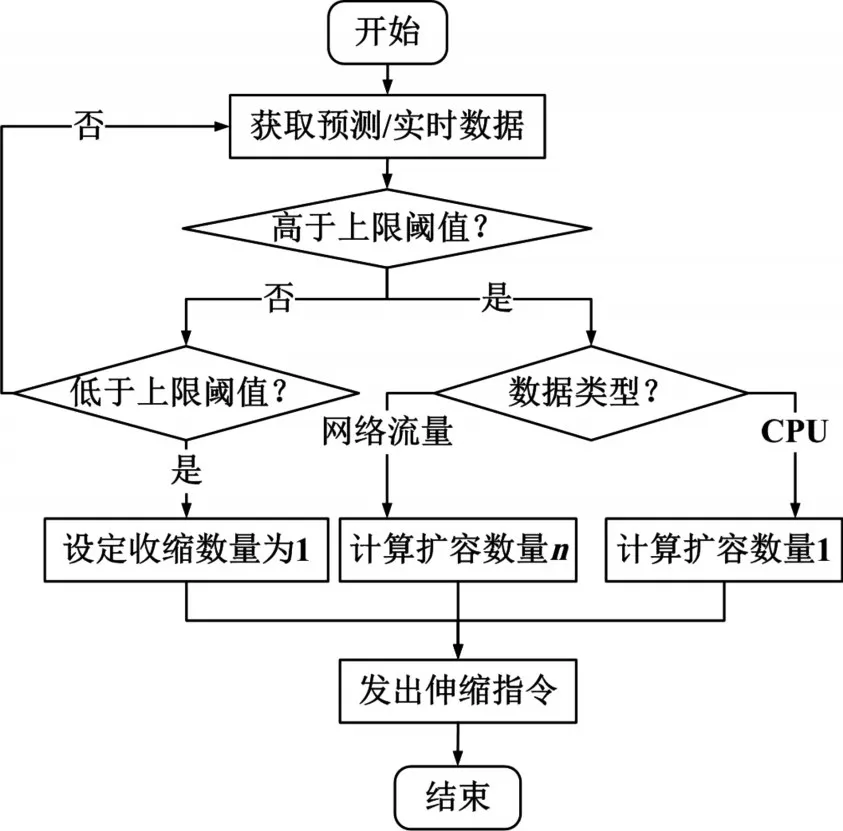
圖6 Controller模塊流程圖
在容器集群擴展時,綜合考慮CPU和網絡流量的實際情況,在CPU突破閾值的場景下,系統只會進行第一步,也就是只會判定是否滿足擴展條件,在滿足擴展條件時,Controller模塊會向資源調度模塊發出擴展命令,并且指定擴展數量為1,而在網絡流量突破閾值的場景下,系統會首先進行擴展條件的判斷,然后再計算需要擴充的容器數量n,此時Controller模塊也會向資源調度模塊發出擴展命令,指定擴展數量為n。
在容器集群收縮時,考慮到業務容器數量的突然變小會給負載均衡模塊帶來較大的影響,因此在這種情況下,系統也只會進行第一步,即判斷是否滿足收縮條件,若滿足指定的收縮條件,則Control?ler模塊會向資源調度模塊發出收縮指令,并指定收縮數量為1。
4.4 資源調度模塊
資源調度模塊主要負責對容器集群的底層資源進行分配和調度,當集群需要進行擴展或收縮時,資源調度模塊會確定在哪臺宿主機上進行容器的創建或銷毀[15]。資源調度模塊主要分為兩個部分:Manager模塊和Scheduler模塊,其架構圖如圖7所示。
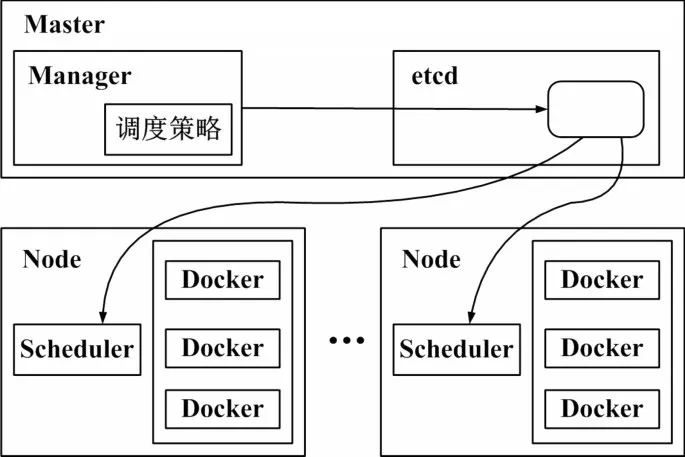
圖7 資源調度模塊系統架構圖
4.4.1 Manager模塊
Manager主要負責根據給定的調度策略確定待創建或銷毀的容器對應的宿主機節點,其調度策略主要包含兩個步驟:節點篩選和節點打分。
在節點篩選過程中,主要考慮的篩選條件包括端口占用和資源占用,端口占用主要是查看待調度容器指定的端口是否已經在宿主機上被占用,若端口已被占用則舍棄此節點,資源占用主要是查看宿主機上的可用資源是否能夠滿足待調度容器的資源使用需求,若不滿足則同樣舍棄此節點。
在經過了篩選過程后,會得到一個備選主機節點列表,然后便進入打分過程,打分過程中的分值主要用于體現宿主機上的資源消耗情況,資源消耗越小,則其對應的分值越高,這一策略使得集群中的宿主機資源使用情況能夠盡量平衡。其具體計算過程為:首先計算出待調度容器和宿主機上所有容器的CPU占用總量totalCpu、內存占用總量to?talMem和網絡帶寬占用總量totalNet,然后對其打分,打分規則為

其中,CpuCap為宿主機的CPU計算能力,Memory?Cap為宿主機的內存總容量,NetCap為宿主機的網絡帶寬大小,int()為取整函數。
在經過篩選和打分兩個階段后,對于待調度的容器會確定其對應的宿主機,系統會將這一配對信息寫入到etcd中,供各個主機上的Scheduler模塊使用。
4.4.2 Scheduler模塊
Scheduler主要負責對Manager生成的調度信息進行監聽,在獲取到本節點的調度信息后,自動從本地倉庫下載容器鏡像,并啟動容器。其調度過程如下:
1)Scheduler根據etcd中的容器信息確定其對應的Docker鏡像和資源限制情況;
2)若當前節點上不存在對應的Docker鏡像,則向本地倉庫進行鏡像的拉取;
3)創建容器對應的工作目錄并生成容器必要的環境變量和參數;
4)構造Docker run container命令行所需的參數并調用Docker REST API來進行容器的創建。
5 方案驗證
5.1 基于CPU負載的容器集群動態伸縮
為了測試基于CPU負載的容器集群動態伸縮功能,在本地部署了一套基于Docker容器的Web服務,Web服務的后端通過Python實現,其主要功能是在收到Web請求的時候進行一系列的數值運算,提高CPU的運行頻率,從而模擬某些場景下的計算密集型服務。用戶的請求模擬主要通過一個Python腳本實現,并通過Apache JMeter工具來實現并發從而提升容器集群的CPU負載。最終得到的CPU負載變化和對應容器數量變化如圖8所示。

圖8 CPU負載及容器數量變化圖
從圖8可以看出,容器集群的確能夠隨著CPU負載的變化而動態伸縮,但是具有一定的滯后性,容器集群在CPU負載升高后的第20s左右才會開始進行擴展,由于每次只擴充1個容器,因此容器集群的擴展速度也比較慢,與此同時,容器集群的收縮也是在CPU負載降低后的第20s左右才會開始進行。
5.2 基于網絡流量的容器集群動態伸縮
為了測試基于網絡流量的容器集群動態伸縮功能,在Web服務的基礎上編寫了一個Python腳本來實現文件的傳輸,然后在使用Apache JMeter工具進行并發測試時,同時往對應的容器發送一個文件,從而模擬某些場景下的網絡密集型服務,最后得到的網絡流量變化和對應的容器數量變化如圖9所示。
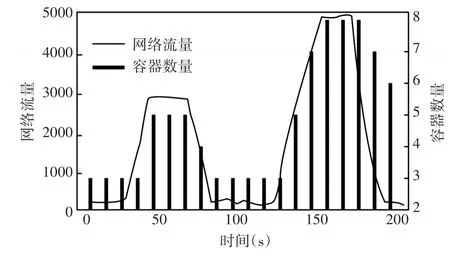
圖9 網絡流量及容器數量變化圖
從圖9可以看出,容器集群的確能夠根據網絡流量的變化而進行相應的動態伸縮,并且基于網絡流量的伸縮策略是預測型伸縮算法,因此會比基于閾值的響應型伸縮算法的滯后時長短一些,容器集群在擴展時的滯后時長大約為10s,同時預測型伸縮算法能夠確定即將到來的額外網絡流量,因此可以及時確定容器集群的擴展數量,從而擴展速度也比較快。
6 結語
Docker作為一種新興的虛擬化技術正在打破傳統的以虛擬機為基礎的云平臺部署方式,本文正是通過使用Docker容器技術作為集群的底層虛擬化技術,針對互聯網應用場景中的不可預知負載,提出了一種基于混合負載的容器集群動態伸縮方案,這一方案通過對不同的工作負載采用不同的容器集群伸縮策略從而實現業務的動態伸縮,保證服務的穩定性,文末通過設計兩種不同的工作負載場景對容器集群的伸縮功能進行了測試,驗證了這一方案的可行性。但是本方案也存在一定的不足之處,文中使用的二次指數平滑法在遇到網絡流量的突然大規模變化時預測結果會不太準確,對于這種情況,后續可以使用如線性自回歸模型、機器學習等方法來進行預測,提升預測的準確率。
猜你喜歡
江蘇安全生產(2023年1期)2023-02-08 05:58:38
資源節約與環保(2022年8期)2022-09-20 02:25:22
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
藝術品鑒(2020年7期)2020-09-11 08:04:44
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
當代貴州(2018年28期)2018-09-19 06:39:04
資源再生(2017年3期)2017-06-01 12:20:59
決策(2015年9期)2015-09-10 07:22:44
