基于進化算法的船舶避碰軌跡建模
2018-09-04 11:11:30劉超
西安文理學院學報(自然科學版) 2018年4期
劉 超
(安徽交通職業技術學院 航海系,合肥 230001)
目前,許多國內外研究學者對船舶自動舵與自動避碰算法展開了深入的研究.文獻[1]將航跡遵循、航向調控和船舶避碰定義為航行自動控制領域內的3個重要組成部分.航跡遵循和航向調控的難題已基本得到解決.船舶避碰一直是船舶航行領域研究的熱點,因為船舶發生意外碰撞導致船毀的事件頻頻發生.文獻[2]將遺傳算法應用到船舶航路規劃以實現安全避碰,但對航海《規則》和船員的技術水平沒有考慮周全,造成在設計最優航海路線時經常會違反避碰規則和航海最基本的規定條文;文獻[3]將群體智能理論的算法引入到船舶避碰中,此算法具有運算簡單、依賴參數小、易于操作等優點,但該算法比較容易受局部極值點的影響、避碰精度較差;文獻[4]提出了一種模糊神經網絡推理方法,在對船舶避碰最佳路徑運算時,可迅速規劃出一條最佳路徑,但在外界干擾的不利情況下,精確度將會下降.
本文提出了一種基于進化算法的船舶避碰軌跡建模方法,對船舶避碰軌跡模型進行深入分析,通過引入進化算法,將本船和干擾船的航向、航速、位置信息等主要輸入參數,規劃出避碰路徑,完成了該目標下的船舶避碰算法設計.
1 船舶軌跡數據的重要進化算法
1.1 進化算法
本算法主要使用了Map/Reduce編程算法進行的,船舶的停留時間和情況聯系很密切,船舶一般在晚上停留,在白天行駛.為了獲得數據,需要給船舶提供重要的時間范圍[begin,end],這種算法Map和Reduce的函數程序如下:

map(key,value)value主要是指船舶號、船舶ID和行駛時間3個字段的字符串1.從value中可以得到phoneID,baseID,timeStamp這3個屬性;2.{if(timeStamp>=begin‖timeStamp<=end){3.output(phoneID,

reduce(key,values)‖key為船舶號,ualues為船舶的所有夜間行駛記錄1.regionList=null;2.values記錄要通過時間開展記錄和排序工作,然后要給定范圍的軌跡數據進行分析;3.每個軌跡和船舶之間進行聯系,調用獲得一種新的模塊,即狀態序列;4.開展對深層的狀態模塊進行調用,獲得正確的調用效果;5.做好軌跡數據的處理工作,對相關的狀態根據區域進行分組.;6.分析各個區域,如果區域g的狀態數高于閥值freq則此區域處于重要的位置;7.要對regionList調用相關的聚類模塊,找到船舶的重要位置以及有效時間.
Map函數的主要功能:第一步是讓船舶可以將軌跡點輸送給Reduce函數;第二步是記錄船舶的軌跡;第三步是要對調用狀態的算法進行計算;第四步主要是對調用狀態的模塊要刪除數據的狀態;第五步是要對停留次數很少的區域,由于這些位置的船舶形成的狀態時間不短,但是因為時間不夠長和頻率不夠高,所以需要刪除位置的對應狀態;第六步是要對找到的區域使用聚類算法,然后從獲得的結果中得出有效時間和位置.
1.2 聚類分析模塊
聚類分析模塊通過對出現的區域要進行搜索,找到重要的區域位置.由于船舶的位置不同,本文通過聚類方法DBSCAN對聚類結果進行分析,找出重要位置和有效的時間.
聚類分析算法:
輸入:狀態列表regionList;
輸出:重要位置和有效的位置時間.
1)讓regionList區域中心點作為輸入情況,通過DBSCAN算法做好點的聚類;
2)聚類之后可以得到很多簇,而且簇和簇之間的對應狀態可能會出現重合,如果出現重合,則需要慢慢地刪除船舶的行駛次數比較少的簇;
3)要不斷地分析每個簇,然后才能找到船舶的重要位置;
4)要對位置的有效范圍進行分析.
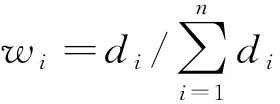
1.3 夜間行駛船舶的位置修正策略
前述算法能夠較準確地獲得船舶的重要位置,但是會出現夜間行駛而白天休息的船舶,所以本文通過對船舶行駛的日志進行分析,這種船舶工作時候的船舶頻率比一般的船舶頻率要高,而且在船舶停留的時候,船舶的頻率很低,如果能夠分析船舶的行駛頻率就可以推斷船舶的時間段,然后得出船舶的行駛時間段.
使用如下模型來分析時間因素對船舶所處狀態的影響:
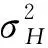
當前船舶的位置意味著船舶處于“工作”狀態并且表示船舶的狀態.“時間”處的位置,通過文中描述的算法計算的船舶與工作位置之間的距離以及和工作場所平均值之間的距離的協方差矩陣相同,最終使用以下形式來確定船舶在某個時間點的狀態:
在l(x)≥1時,證明船舶在該時間點處于“在家”狀態;否則,船舶處于“工作”狀態.
2 實驗結果及分析
2.1 實驗數據集
本文獲得的數據來源主要是上海航海局提供的船舶數據,這個數據源有1 342艘船舶,包括了2014年8月15日到2015年3月11日的期間船舶上網的船舶記錄數據以及位置信息,數據空間的總量為1.6 TB,而且隨機的對98艘船舶的數據進行了算法的準確性分析,表1中對船舶的使用年數分布情況進行了分析,表2分析了工作分布狀況,8.1%的船舶是報廢的船舶.

表1 船舶使用年數分布

表2 船舶的航行地點數目分布
2.2 算法的準確性和精度評估
算法的準確性評估主要是使用準確率(Precision)、召回率(Recall)、值(value)進行分析,精度使用平均誤差(mean_error),如果算法獲得的與未知船舶距離小于2 000 m,則知船舶的分布密度不平衡,而且信號會出現跳變的情況,2 000 m的值是比較合理的,我們認為獲得了一個重要的信息位置,而找到的重要位置個數是P,實際的重要位置個數為R,找到正確的位置個數是Q,于是有Precision=Q/P,Recall=Q/R,F1-measure=2×PR(P+R).假設實際重要位置為l,算法找出的位置為f,則
其中,ed一般是l與f兩個位置之間的歐式距離.
表3對FQM和AXM算法優化之后的性能進行了分析與介紹,一般算法網格長度以及船舶的半徑為500 m,在工作地和夜間工作的船舶變換位置后,將這兩種算法對其軌跡進行修正,可找出船舶的重要位置(P)數量在不斷的縮小而且找到的正確位置數量(Q)也在增加,實際的位置數量不會發生改變,準確率和召回率也在不斷提升,最后會導致F1不斷增加,由于船舶的位置在相鄰的住宅中得到了修改,所以位置一般可以反映出實際狀況,而且誤差也在不斷下降.通過表3可以知道AXM算法一般精確度要高于FQM算法.
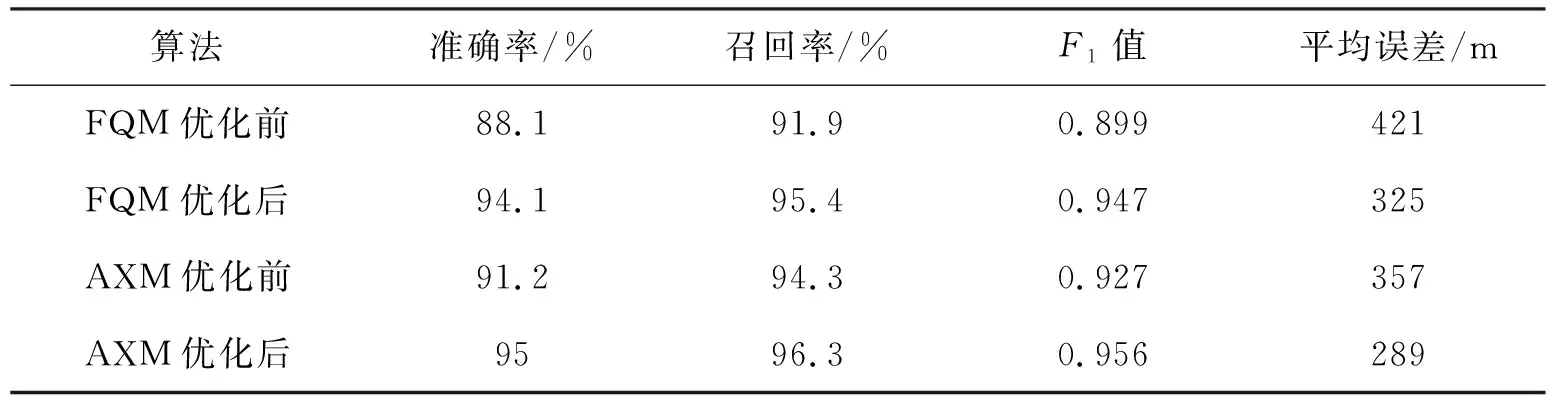
表3 優化措施的影響
表4是前述的兩種算法以及文獻[7]的算法在數據中的準確情況,船舶的覆蓋范圍一般在500 m.通過表4可知FQM與AXM兩種算法在修正之后得到的實驗結果一般比文獻[5]與文獻[6]要高,文獻[7]算法和文中的算法性能差距不大,而且精度也不會超過本文算法,文獻[6]的算法性能不好,主要是因為算法需要進行船舶的聚類操作,深刻地影響船舶的重要位置.
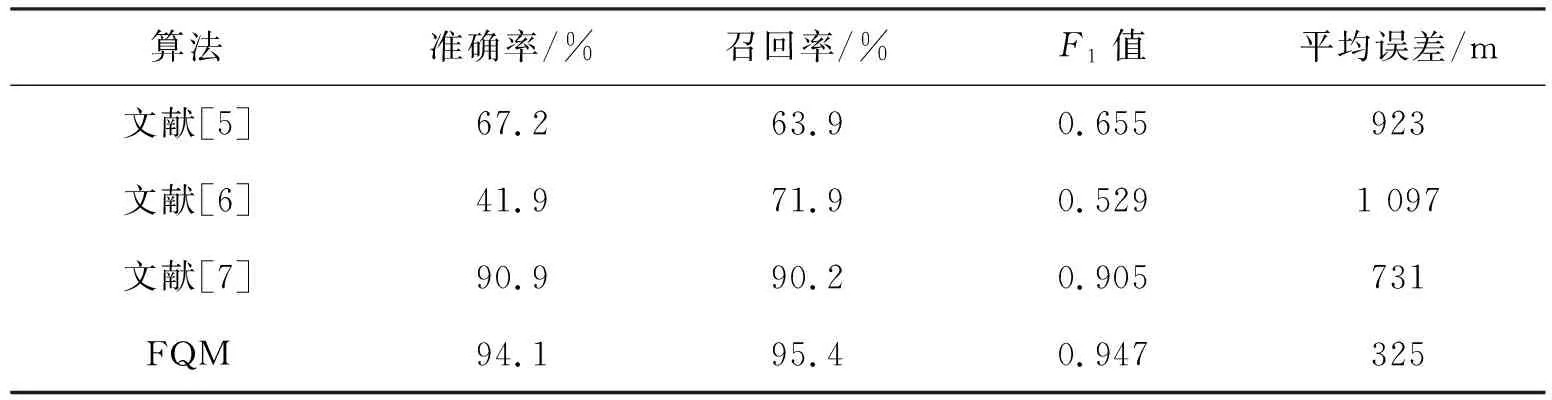
表4 算法性能比較
2.3 算法運行性能評估
為了更好地測量網格尺寸對FQM時間性能的重要作用,對許多數據開展了不同的計算機性能測試,獲得結果如圖1所示.根據圖1可知,網格數據越小,則算法的使用時間將會延長,而且FQM算法的線性加速性也更好,在不同船舶的覆蓋也會有不同的算法時間性.根據圖2可知算法的半徑越小那么效率就會增強,這和FQM算法獲得的結果是不一樣的.一般船舶的覆蓋面積增加,那么船舶的數量也會增加,出現的狀態也會增加,導致了聚類的輸入數量也不斷地增加,也會增加算法運行的時間,而FQM算法的網格邊長如果增加,網格的數量也會不斷減少,運行的時間也會不斷地縮短.
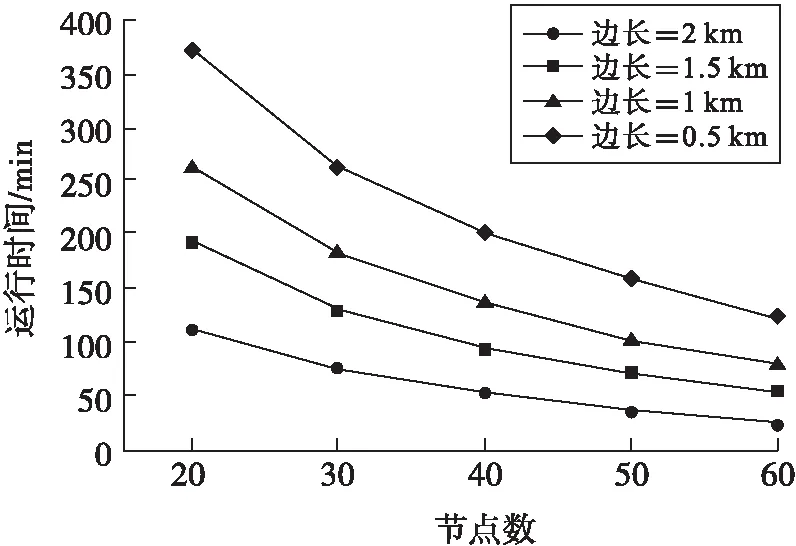
圖1 不同網格粒度下的時間性能
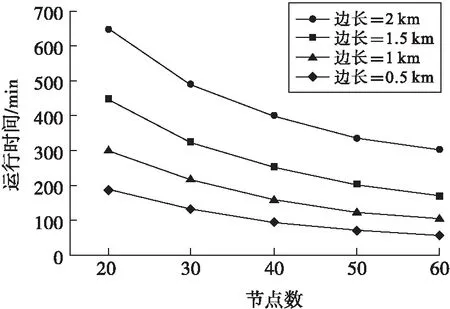
圖2 不同半徑下的時間性能
3 結語
本文提出了一種基于進化算法的船舶避碰軌跡建模方法.通過船舶的活動記錄找到重要的區域,然后對區域開展聚類分析,通過聚類獲得的結果對船舶的具體位置進行定位.選取安全避讓、路徑最短及準備復航為目標,采用進化算法對船舶避碰軌跡問題的系統運動方程進行求解,最終規劃出避碰路徑.通過實驗結果可知:該算法可以有效避開其他船舶的干擾,且航跡最佳,對船舶自動避碰的研究提供了一定的理論基礎.
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:07:40
艦船科學技術(2022年2期)2022-03-29 01:12:44
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
小哥白尼(趣味科學)(2019年10期)2020-01-18 09:16:22
船舶標準化工程師(2019年4期)2019-07-24 07:21:12
電子制作(2018年18期)2018-11-14 01:48:24
中國船檢(2017年3期)2017-05-18 11:33:09
山東工業技術(2016年15期)2016-12-01 05:31:22
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
終身教育研究(2014年5期)2014-02-28 01:23:06
