基于用戶分類的余額寶資金流預測研究
2018-09-08 05:47:06王媛
中國鄉鎮企業會計 2018年8期
王 媛
一、引言
以余額寶為代表的互聯網金融作為一種創新的金融服務模式對傳統金融行業產生了巨大的沖擊。余額寶最大的創新之處在于用戶把資金從外部轉入余額寶的同時能夠完成對貨幣基金的購買,而在客戶需要資金時可以在自己的已申購金額內隨時轉出自己需要的金額,用于在線消費、移動支付或者轉到銀行卡等,極大地簡化了操作流程,實現了“T+0”的高流動性資金轉移。
資金流動情況管理和預測是是保障企業正常運營的重要的一個基礎環節。現金流是動態變化的,一旦流入現金流少于流出現金流,就會遭受現金流危機。對余額寶這種用戶資金流動性非常高的平臺,對資金的流入和流出進行預測是非常重要的。
時間序列分析方法是對金融領域進行定量研究預測的一種有效有段。本文研究基于時間序列分析的余額寶資金流入流出金額的預測模型,在資金流入流出的預測中考慮了客戶分類對和申購和贖回的影響,對不同類別的用戶分別建立時間序列模型進行分析,提高了預測分析的準確性。
二、相關研究
由于資金流對企業而言極其重要,已經有不少對資金流預測的研究。模型分析法建立價格指數的模型,依據模型進行股價預測。基本分析法從宏觀經濟、行業和公司三個層面進行分析,理論上能夠對整體價格走勢進行分析,但實際應用中的表現總是顯得差強人意。在20世紀,時間序列分析方法逐漸發展壯大,成為經濟發展的重要推動力量。Yule率先使用自回歸模型預測市場的變化規律。Bollerslev等提出了GARCH模型。互聯網理財平臺會涉及到大量的資金,并且資金的流動性比傳統金融行業中更強。目前已經有學者探索分析方法之間的融合,將時間序列分析與干預分析、人工智能等方法結合起來進行數據的分析和挖掘,在更好地把握時間序列的變化規律的同時發掘出更多有價值的信息。
三、基于用戶分類的資金流預測模型
不同類別的用戶在申購和贖回過程中會有不同的規律。本文中使用K-均值聚類方法對用戶進行分類,將用戶分為“大額用戶”和“普通用戶”兩類。所以本文在分析過程中,對兩類用戶的數據分別進行預測,在進行匯總,從而提高預測的準確度。在進行時間序列分析時,選擇總申購金額,消費金額和轉出金額這三個變量分別回歸預測。構建時間序列模型,在分析之后,對預測結果進行匯總,從而評價整體的預測準確度。
1.用戶分類
資金的流動性風險和用戶的聯系尤為密切,不同類別的用戶在申購和贖回過程中產生的數據集會具有不同的規律和趨勢。在本文中,通過聚類的方法將用戶依據各自的數據特點聚集成不同的簇,從而實現對用戶進行分類。首先挑選出符合要求的變量,然后確定合適的聚類數,最后利用K-均值聚類方法按照選定的變量和確定的分類數進行聚類。
在進行用戶聚類之前,通過Pearson相關系數對變量之間的相關性進行分析,挑選出合適的變量用于聚類分析。通過分析選取今日余額、今日申購金額、今日轉出總量、今日消費金額和今日轉出到余額寶余額總量等沒有明顯相關關系的5個變量。
2.預測模型
本文分別對余額寶的用戶的申購和贖回進行預測。在用戶的申購行為上,通過支付寶轉入或者通過銀行卡轉入資金購買都是對余額寶的認可,區別不大。用戶贖回對余額寶而言意味著現金流出,如果用戶將資產從余額寶中贖回轉入到支付寶或銀行卡中,可能暗示了用戶對余額寶不信任或者興趣度降低等現象發生。如果用戶用于消費則表示用戶對資金的需求,所以對用戶贖回這一行為分析的時候分為消費和轉出。所以選擇當日申購金額、消費金額、轉出金額這三個維度作為變量進行分析,其中用戶的贖回金額為消費金額和轉出金額之和,用戶的申購金額作為一個整體進行分析。
首先根據用戶分類中對余額寶用戶的劃分,將大額用戶(key account)記為Uk,將普通用戶normal記為Un,分別采用ARIMA模型對其進行時間序列建模。ARIMA(p,d,q)的全稱是差分自回歸移動平均模型,它是由三個部分組成的,其中“AR”代表的是自回歸模型,p為自回歸項,是AR模型的最高階數;“MA”代表的是移動平均模型,q為移動平均項數,是MA模型的最高階數;“I”代表的是差分,對原始時間序列做d次差分后得到的數列能夠滿足進行時間序列分析所要求的平穩性。ARIMA模型本質上是對差分穩定序列擬合自回歸移動平均模型。
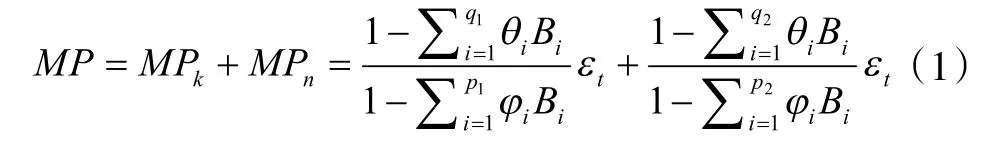
把兩類用戶贖回金額之和記為Mr使用表示大額用戶消費金額,用表示大額用戶轉出金額,用表示普通用戶消費金額,用表示普通用戶轉出金額。贖回的預測模型如下:
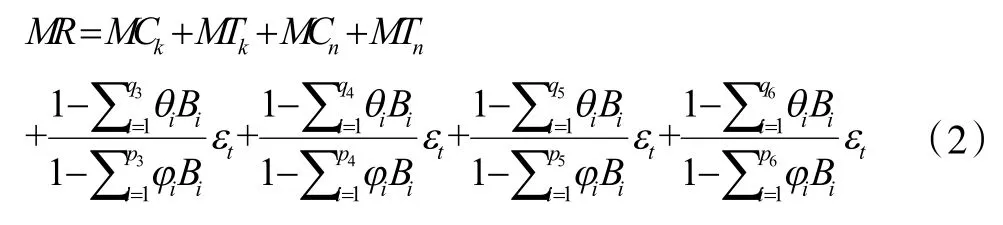
其中,Pi分別為六組時間序列的ARIMA模型中AR(p)模型的參數p,qi分別為六組時間序列的ARIMA模型中的MA(q)模型中的參數q,B為延遲算子,εt為零均值白噪聲序列。建模預測在未來一個月內,余額寶每天的資金總流出金額以及總流入金額。依據預測的目的,對之前建立的六個時間序列模型進行組合,從而構建出最終需要的預測模型--基于客戶分類的時間序列預測模型。
四、實證分析
文中所使用到的數據由螞蟻金服官方提供,可以從網址https://tianchi.aliyun.com得到本文中所使用的數據,對模型進行實證分析。選取在2014年3月1日至2014年7月31日之間,共有1614551條訓練集數據。據作為訓練集,用于模型的構建。使用構建的模型對2014年8月份每天申購和贖回金額總量數據進行預測,并用真實的數據對預測結果的準確性進行驗證,檢測模型的可信度。首先對用戶進行聚類,通過實驗發現可以很好地把用戶分為兩類。
對于大額用戶,首先要進行數據的平穩性檢測,為了增強數據的穩定性,對數據進行一階差分處理。因此,在構建相應的ARIMA(p,d,q)模型時,參數d的值為1。接下來需要確定參數p和參數q的取值。為此,做一階差分序列的自相關圖和偏自相關圖,得到參數p和參數q的大致取值范圍。首先通過自相關圖和偏自相關圖判斷出參數取值的大致范圍,再進一步由BIC熱度圖具體判斷出參數的最佳取值。
普通用戶的數據在構建模型時,同樣分為三個模型進行構建:普通用戶申購金額模型,普通用戶消費金額模型以及普通用戶轉出金額模型。與大額用戶相同,下文將對這三個模型的構建過程進行詳細的描述。首先進行平穩性分析,決定是否要進行差分處理。普通用戶消費金額時間序列本身就是平穩的,沒有做差分處理,所以ARIMA模型中參數d的值為0。對參數p和參數q的值進行判斷即可。首先依據自相關圖和偏自相關圖進行初步判斷,然后根據BIC熱度圖具體判斷出參數的最佳取值。
本次的預測目標是對余額寶未來31個交易日的流入資金金額和流出資金金額進行預測。按照前文中構造的基于用戶的時間序列模型對目標數據進行預測。我們分別得到用戶申購和贖回金額預測值和真實值折線圖,從實驗數據分析,本文提出的基于用戶分類模型的預測效果可以較好的擬合出資金流入和資金流出的變化趨勢。文中的模型對趨勢變化的預測準確度也較高。
五、結論與進一步的工作
本文從余額寶資金流動性入手,實現用戶的分類、變量的選擇以及預測模型的構建和實現。利用螞蟻金服提供的貨幣市場基金真實數據進行分析和論證,對其未來一個月的資金流入和流出情況進行預測,以可視化的方式呈現預測結果,評估所構建的時間序列模型的有效性。
本文的工作重點是用戶分類和變量選擇與構建時間序列模型,對影響資金流因素這方面仍然后很多工作可以做,本文中構建的基于用戶分類的時間序列模型仍有很大的改進空間。日后更進一步的研究工作主要從以下幾個方面進行:(1)加強單點預測。中國節假日很大一部分都是按農歷計算的,因此,假日的具體日期是不確定的,這一現象增加了對節假日消費情況預測的難度。(2)考慮宏觀經濟環境。隨著各項經濟政策的出臺以及對余額寶監管力度的增強,在余額寶收益率出現下降的情況,因此余額寶對用戶的吸引力可能會出現變化。大額客戶和工薪階級的考慮的地方不同,因而做出的反應也不同。(3)考慮個性化數據的影響。在余額寶所提供的數據中,有許多個性化的數據。例如:星座,城市,性別等等。對用戶個性化的數據開展更為細致的分析工作,能夠更好地進行人群畫像。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2018年18期)2018-11-14 01:48:24
商用汽車(2016年11期)2016-12-19 01:20:16
山東工業技術(2016年15期)2016-12-01 05:31:22
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
