一種針對類別不平衡的代價敏感集成算法
2018-09-17 10:13:00田愛奎吳志勇
山東理工大學學報(自然科學版) 2018年6期
關鍵詞:分類
譚 浩,田愛奎,吳志勇
(山東理工大學 計算機科學與技術學院,山東 淄博 255049)
由于現代社會信息爆炸式發展,如何從海量的信息中提取有用的知識越來越受到重視.其中分類是一種重要方法.分類已經被廣泛運用到各領域,而大多數的分類方法都要求各種類型的數據具有較為均勻的分布,但是有一些特殊的事件比較罕見.針對罕見事件的分類是許多領域中常見的問題,如欺詐交易、網絡入侵檢測和醫學診斷等.而分類中伴隨著分類成本不同的問題[1],如將病人誤診為健康人的代價比將健康人誤診為病人的大得多,后者只是增加成本,而前者會導致失去生命.針對包含罕見事件的不平衡數據集的研究方法主要分為兩個方面:數據層方法和算法層方法[2].數據層方法是先對數據進行預處理,然后用于學習.主要的方法可分為過抽樣和欠抽樣兩種.過抽樣是通過增加數據集中少數類實例的數量以提高少數類分類精度,本文所用的SMOTE算法就是一種過抽樣算法;欠抽樣就是減少數據集中多數類實例的數量來平衡數據集的類別分布,如文獻[3]為此提出了一種基于樣本權重的欠抽樣方法,該方法引入了樣本權重來反映樣本所處的區域,通過多次聚類修改樣本權重,然后根據樣本權重進行抽樣.過抽樣與欠抽樣都可以達到平衡數據集的目的,但一般欠抽樣算法優于過抽樣算法[4].算法層方法就是通過修改分類算法本身,來提高少數類的分類精度,當不同類被錯分的代價不等時, 便引出了代價敏感(Cost-sensitive) 分類,較為著名的有 MetaCost方法[5],但它不能估計后驗概率;FU[6]提出一種多標簽代價敏感分類集成學習算法,算法的流程類似于自適應提升,可以自動學習多個弱分類器來組合成強分類器;文獻[7]提出了一種局部代價敏感算法.代價敏感學習要求設計的分類器滿足錯分代價最小而非分類錯誤率最小,從而提高錯分代價高的樣本分辨率.本文將兩者結合,通過在AdaCost算法每次迭代前插入合成的少數類以提高分類器在分布不平衡的數據集上的表現,實驗驗證了算法的有效性.
1 評價標準和相關算法
1.1 不平衡數據集分類的評價標準
表1所示的混淆矩陣通常被用于評估機器學習算法的性能.在分類問題中,假設C類為少數類,在代價敏感分類算法中也被稱為正類,而NC作為所有其他類的結合,在代價敏感分類算法中也被稱為負類,在檢測C類時有四種可能的結果.通過表1,精確率(Precision),召回率(Recall),F-measure有如下定義:
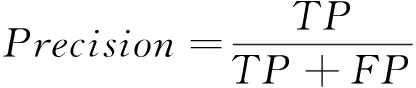
式中:β表示Recall和Precision的相對重要性,在本文中β=1.只有Recall和Precision都比較大時,F-measure才會相應比較大.因此,F-measure可以合理評價分類器對于少數類(正類)的分類性能.
表1 分類混淆矩陣
Tab.1 Confusion matrix defines
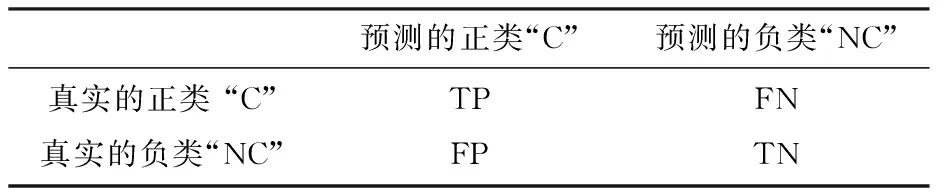
預測的正類“C”預測的負類“NC”真實的正類 “C”真實的負類“NC”TPFPFNTN
1.2 相關算法
1.2.1 SMOTE算法
SMOTE (Synthetic Minority Oversampling Technique)算法[8]是為減小數據集中少數類影響而提出的人工合成抽樣技術.算法在“特征空間”中操作,而不是在“數據空間”中合成少數類實例,算法偽代碼如圖1所示.

圖1 偽代碼Fig.1 Pseudocode
對于連續性特征:
(1)取少數類樣本的特征向量和它K近鄰中任意一個少數類樣本的特征向量之間的差.
(2)用0到1之間的隨機數乘以這個差.
(3)將第(2)步計算結果添加到原始特征向量的特征值中,從而創建一個新的特征向量.
對于標稱特性:
(1)少數類樣本的特征向量和它K近鄰中少數類樣本的特征向量進行投票選擇.在平局的情況下,隨機選擇.
(2)將該值分配給新合成的少數類樣本.
使用這種技術,可以在連接少數類樣本及其最近鄰的線段上創建一個新的少數類樣本.通過合成少數類實例可以拓寬決策樹(如C4.5)、規則學習算法(如RIPPER算法)的決策區域[9].
1.2.2 AdaCost算法
AdaCost算法是AdaBoost算法[10]的一個變種.AdaCost算法[11]保持了AdaBoost算法核心理論.而在AdaCost算法中,權值更新規則給予被錯誤分類的錯分代價高的樣本更高的權重,而被正確分類的錯分代價高的樣本較為保守的權重.這是通過在權重更新公式中引入誤分類代價調整函數來實現的.在這種更新規則下,錯分代價高的樣本權重較高,而錯分代價低的樣本權重相對較低.這樣,每輪迭代產生的弱分類器都更加關注錯分代價高的樣本,最終投票產生的強分類器也將正確地識別錯分代價更高的樣本.
2 Cost-SMOTEBoost算法
AdaCost通過錯分代價來更新每輪迭代中訓練樣本的權重,給予少數類(正類)更大的權重,算法更關注那些少數類樣本.通過SMOTE合成實例可以改善樣本的類別分布.本文將兩者結合,提出了Cost-SMOTEBoost算法,在每輪迭代的開始向數據集中插入合成的少數類實例,改善少數類的分布,同時分類結果向更被人們關注的錯分代價更高的少數類(正類)傾斜,通過關注分類困難的少數類(正類)樣本來提高整體的精度.利用SMOTE人工合成實例也可以增加集合中分類器之間的多樣性,因為在每次迭代中,產生了不同的合成訓練集.
Cost-SMOTEBoost算法流程為:
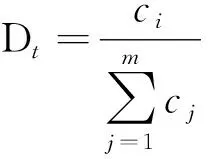
(2)在每一輪迭代中都會調用一個弱分類器h(xi)進行訓練,并運用SMOTE算法合成少數類(正類)實例加入訓練集中,改善訓練集中類別的分布.
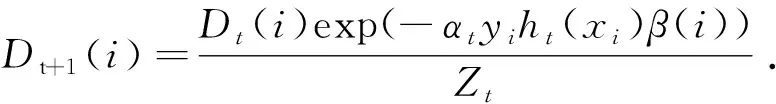
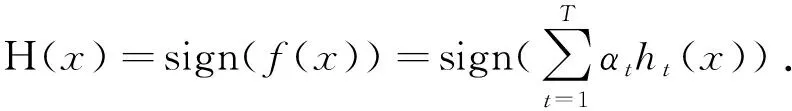
3 實驗與分析
3.1 數據集
實驗是在表2中3個數據集上進行的.這些數據來源于UCI公開數據集[12-13]. Credit-g是來自德國的信用卡數據,由一組屬性描述一個人的行為,評估每個人信用風險的高低;Seismic-bumps是采礦地震預測數據,采礦活動經常發生采礦威脅,這種威脅的一個特例就是在許多地下礦井經常發生地震危險,由于地震過程中低能和高能現象的地震事件數量之間不相稱的復雜性,導致統計技術不足以預測地震災害.因此,有必要利用機器學習方法尋找更好的危險預測方法;Thoraric Surgery是在弗羅茨瓦夫胸外科中心回顧性地收集2007—2011年期間接受肺癌切除術患者的數據,該中心與波蘭的弗羅茨瓦夫醫科大學和下西里西亞肺病研究中心的胸外科有關,研究數據庫是國立肺癌登記處的一部分.
表2 實驗數據集
Tab.2 Dataset
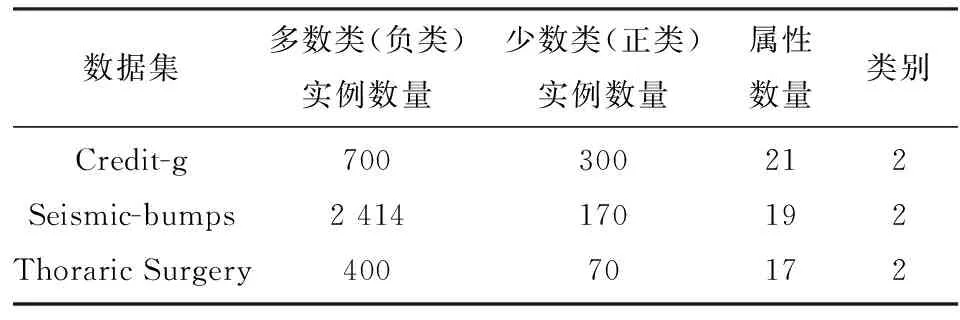
數據集多數類(負類)實例數量少數類(正類)實例數量屬性數量類別Credit-gSeismic-bumpsThoraric Surgery7002 41440030017070211917222
3.2 實驗結果與分析
圖2顯示了Cost-SMOTEBoost算法和AdaCost算法在Credit-g數據集上的對比.隨著迭代次數的增加兩個算法的精確率和召回率都有不同程度的增加,兩個算法有著接近的精確率,但是Cost-SMOTEBoost算法明顯提高了召回率,得到了更高的F-measure值.
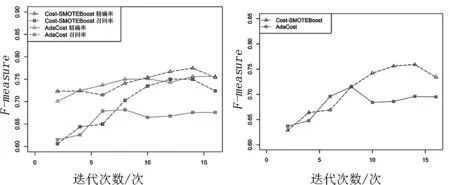
圖2 在數據集Credit-g上的對比Fig.2 The contrast on the Credit-g dataset
圖3顯示了Cost-SMOTEBoost算法和Adacost算法在Seismic-bumps數據集上的對比.兩個算法在經過5次迭代后精確率和召回率都趨于平穩,同樣兩者的精確率比較接近,Cost-SMOTEBoost算法在召回率上有更好的表現從而得到了更高的F-measure.
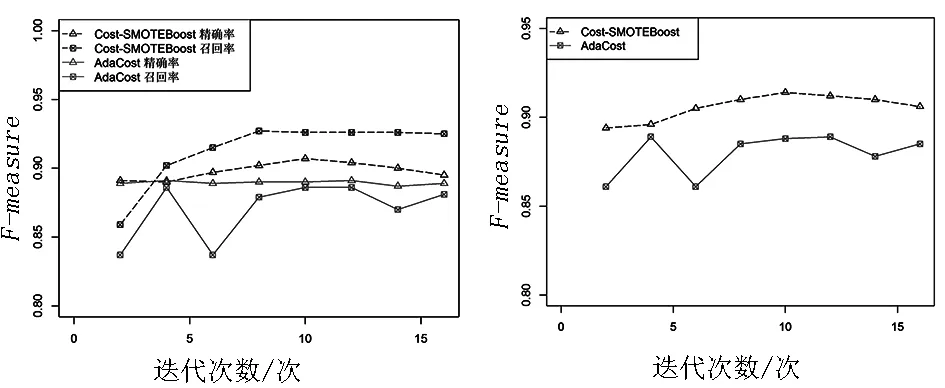
圖3 在數據集Seismic-bumps上的對比Fig.3 The contrast on the dataset Seismic-bumps
圖4顯示了Cost-SMOTEBoost算法和Adacost算法在Thoraric Surgery數據集上的對比.在迭代初期兩算法的表現比較接近,隨著迭代次數的增加Cost-SMOTEBoost算法的精確率和召回率都超過了AdaCost算法.
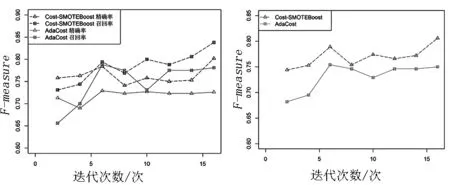
圖4 在數據集Thoraric Surgery上的對比Fig.4 The contrast on the dataset Thoraric Surgery
由圖2、圖3和圖4可知,Cost-SMOTEBoost算法在3個數據集上有更高的召回率,它在不降低精確率的情況下,提高了召回率從而得到了更高的F-measure.
4 結束語
本文提出了一種基于AdaCost的集成算法——Cost-SMOTEBoost算法,該算法通過在每輪迭代前加入由SMOTE算法合成的人工實例以改變數據的分布,同時利用成本敏感函數使分類結果向更被人們關注、錯分代價更高的正類傾斜.在實驗中使用的數據集包含不同程度的不平衡和不同的規模,從而提供了一個多樣化的測試,以精確率(Precision),召回率(Recall)和F-measure為度量指
標對算法進行評價,并與AdaCost算法進行比較.實驗結果表明,Cost-SMOTEBoost算法平衡了精確率和召回率,在不降低整體精確率的同時提高了針對少數類(正類)的表現.
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
