基于統計和詞典方法相結合的韓漢雙語語料庫名詞短語對齊
2018-09-18 09:33:40凌天斌畢玉德
中文信息學報 2018年8期
關鍵詞:方法
凌天斌,畢玉德
(解放軍戰略支援部隊信息工程大學,河南 洛陽 471003)
0 引言
在基于實例的機器翻譯系統中,翻譯實例獲取根據粒度區分,可以分為篇章級、句子級、短語級和詞語級等,其中詞語對齊是基礎,而短語對齊在很大一部分程度上依賴于詞語對齊。本文討論的是利用較大規模韓漢雙語平行語料庫,在統計和詞典相結合的詞對齊方法基礎上,實現基于雙語語料庫的短語對齊。由于短語對齊比句子對齊提供了更細程度的對譯信息,因此對于它的研究具有重要意義。
在短語對齊方法方面,短語級別上的對齊可以歸結為雙語平行語料庫上的多詞單元的對應。許多學者在多詞單元對齊和自動構建雙語翻譯詞典方面做了進一步的研究,基本方法有n-gram、有限狀態機、近似字符匹配、雙語語法分析樹等。其中Marcu[1]說明了單個詞作為翻譯基本單元的不足,并說明了在翻譯中加入短語翻譯對的原因,并且證明了加入短語翻譯對可以提高系統性能。Zhang[2]等人為雙語句對建立一個互信息矩陣,并將矩陣中抽取的互信息值相似的區域視為短語對。Zhang和Stephan Vogel[3]提出了將短語對齊視為句子分割問題的方法,在源短語固定的情況下,尋找目標短語的最優左邊界和右邊界。常寶寶[4]等人提出了基于詞語關聯度進行詞語組合方法,并利用假設—檢驗的方法,在漢英雙語語料庫中抽取翻譯等價單位。程潔[5]等人采用結合閾值和關聯度提取的方法獲取多詞單元翻譯詞典。屈剛[6]等人針對漢英句子候選句法分析樹集中存在大量的翻譯異常現象,使得源語言句法樹和目標語言句法樹往往不存在簡單的對應關系這一問題,提出了“有效句型”概念和“翻譯中相對不變準則”的短語對齊模型。
本文在現有資源的基礎上,首先從韓國語名詞短語結構特點出發,在統計和詞典相結合的詞對齊方法基礎上,提出了基于詞對齊位置信息的韓漢雙語語料庫名詞短語對齊方法。該方法在較大規模語料庫情況下,取得了較好的短語對齊結果。
1 韓國語名詞短語結構特點
在韓國語研究方面,早期的研究都是以句子為單位,組塊識別和短語結構分析是近年來關注的焦點。韓國語名詞組塊的研究則以基本名詞短語的相關研究為主[7]。安帥飛[8]等人提出了采用左右邊界判定進行名詞短語獲取的方法,并在此基礎上總結歸納出了八類名詞短語類型:
(1) 名詞|代詞+?+名詞|名詞疊加;
(2) 兩個或兩個以上名詞(代詞)混合疊加;
(3) 名詞|代詞+接續助詞|特殊的副詞+名詞|代詞;
(4) 冠形詞+名詞|代詞;
(5) 數字|數詞+名詞;
(6) 名詞|名詞疊加+?+名詞;
(7) 名詞+名詞派生接尾詞+肯定指示詞+冠形轉成詞尾+名詞;
(8) 名詞|代詞+數詞+(依存名詞)。
其中,語料庫中韓國語采用“世宗計劃”語料庫的分詞標注體系進行分詞標注。根據八類名詞短語形式,通過定義正則表達式的方法實現語料庫中名詞短語的抽取。
該方法的主要原理是: 根據名詞短語左右相鄰詞出現規律,確定名詞短語左右邊界,實現名詞短語的獲取。
2 詞對齊方法
2.1 詞典模糊匹配詞對齊方法
雙語詞典具有豐富的詞匯對譯信息,是可以充分利用的優秀資源,基于詞典的詞語對齊方法是利用雙語電子詞典來進行雙語詞語對齊的算法。由于真實翻譯中上下文的多樣性和翻譯的靈活性,為了提高詞典譯文的覆蓋率,我們引入了詞典的模糊匹配。
詞典的模糊匹配采用詞語相似度計算的方法實現,通常用Dice系數進行兩個字符串之間相似度的計算,詞語相似度如式(1)所示。
(1)
式(1)中,comm(t1,t2)是t1和t2中相同字符的個數,len(t1)是字符串t1的長度,len(t2)是字符串t2的長度,Dice(t1,t2)取值在0到1之間。
在獲得同一種語言中詞語相似度Dice(t1,t2)的基礎上,則源語言詞語s與目標語言詞語t的相似度為,如式(2)所示。
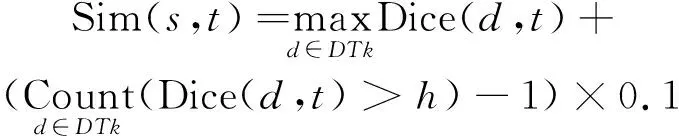
(2)
式(2)中,DTk為源語言詞語s的所有譯文。h為定義好的相似度的閾值,Count為次數統計函數,d為源語言詞語s譯文中的一個。若源語言詞語s存在多個譯文,在計算詞語相似度時,將所有譯文與目標語言詞語t分別兩兩計算,取最大值作為兩個詞語的相似度值。
基于詞典的詞語對齊方法可以得到比較可靠的非空匹配,但由于雙語詞典的覆蓋面是有限的,在未登錄詞、上下文關系方面存在一定的局限性,使得該方法達到的正確率和召回率都十分有限。
2.2 基于語義相似度的詞對齊方法
在真實翻譯過程中,譯文往往具有很強的靈活性,常常會存在同義詞替代翻譯詞的現象。中國科學院計算技術研究所的王斌[9]等人于1999年引入了語義作為基于詞典的詞語對齊方法的補充。
《同義詞詞林》是現代漢語中比較常用的一部義類詞典,哈爾濱工業大學信息檢索實驗室在此基礎上完成了《哈工大信息檢索研究室同義詞詞林擴展版》,它收錄了了各類詞語7萬余條,按照樹狀的層次結構把所有收錄的詞條組織到一起,把詞匯分成大、中、小三類,大類有12個,中類有97個,小類有1 400個。小類根據詞義的遠近和相關性原則分成若干個詞群。每個詞群中的詞語進一步分成若干行,同一行的詞語在詞義方面相同或具有很強的相關性。通過詞義代碼可以看出、這種分類方法具有層次性。通過抽象可以將該分類體系用一個樹形圖表示,則根節點的子節點就是所有大類,所有大類的子節點就是所有中類,中類的所有子節點就是所有小類。
通過《同義詞詞林(擴展版)》的樹形結構,田久樂[10]等人提出了義項相似度算法,該算法主要思想是: 利用同義詞詞林獲得詞語義項的代碼,通過義項之間的語義距離計算出義項相似度。該算法基于義項代碼所在分支的區別進行判斷,義項代碼從哪一層開始不同,就使用該層對應的系數與調節參數和控制參數相乘,得出兩個義項的相似度。如式(3)所示。
若兩個義項不在同一顆樹上,則
Sim(S1,S2)=f
(3)
若兩個義項在同一顆樹上,則
(4)
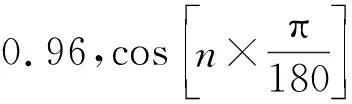
由式(4)可知,兩詞義S1與S2之間的語義距離可以定義為語義樹中節點S1到節點S2的最短路徑的長度,通過比較兩個詞的語義編碼可計算出它們的語義距離。兩個詞語的距離越大,其相似度越低;反之,兩個詞語的距離越小,其相似度越高。
在義項相似度定義的基礎上,定義兩個漢語詞c1、c2的語義相似度公式,如式(5)所示。
(5)
式(5)中,Senseof(c1)和Senseof(c2)函數分別返回詞語c1和c2的詞義代碼集合。若詞語c1、c2存在多個義項,在計算詞語相似度時,將義項分別兩兩計算,通過式(5)取最大值作為兩個詞語的相似度值。
基于語義相似度的詞語對齊方法,可以彌補基于詞典的詞語對齊方法在覆蓋面方面的不足,兩者結合使用可以提高對齊的召回率。
2.3 基于統計的詞對齊方法
在基于統計的詞對齊方法方面,本文中使用了目前比較典型的工具GIZA++。GIZA++是GIZA的一個擴展,是Och[11]等人在GIZA軟件包基礎上進一步優化得到的統計機器翻譯工具。GIZA++在實現了IBM model 1-5和HMM(隱馬爾科夫模型)基礎上,對IBM-1、IBM-2和HMM模型的概率計算算法進行了改進。
運行GIZA++相關命令,將普通文本轉化為 GIZA++ 格式,生成~.A3.final對齊文件,包含對齊概率、目標句子、源語言句子和對齊位置信息。例如,
# Sentence pair (3128) source length 14 target length 10 alignmentscore: 1.55964e-17
但是1在2投資3領域4不5可能6一直7靠8運氣9。10
2.4 統計與詞典相融合的詞對齊方法
通過基于詞典和基于統計的詞對齊實驗,可以看出完全基于詞典的對齊可以獲得可靠的非空對齊。但是由于雙語詞典的覆蓋面有限,得到的對齊的召回率并不理想。基于統計的方法可以彌補純詞典方法的不足,獲得更多對齊,因此可以將統計的方法作為初始對齊的方法,在此基礎上,使用基于詞典和基于語義相似度的方法進行詞對齊校正。其主要步驟為:
(1) 通過GIZA++工具,獲取詞對齊文件;
(2) 通過韓漢機讀辭典,獲取某一韓國語詞語的譯文;
(3) 將該譯文與漢語句子中每個漢語詞語進行詞語相似度計算,取相似度值大于閾值結果中的最大值,將其對應漢語詞語位置加入詞對齊文件;
(4) 若不存在相似度值大于閾值的結果,對韓國語所對應漢語譯文與漢語句子中所有詞語進行語義相似度計算,取語義相似度值大于閾值結果中的最大值,將其對應漢語詞語位置加入詞對齊文件。
上例中經過統計方法得到的詞對齊結果再通過基于詞典和基于語義相似度的方法進行詞對齊校正,得到校正后的對齊文件如下所示:
# Sentence pair (3128) source length 14 target length 10 alignmentscore: 1.55964e-17
但是1在2投資3領域4不5可能6一直7靠8運氣9。10
通過例句可以看出,在現有資源和語料規模的情況下,綜合使用基于詞典和基于統計的方法可以得到更好的對齊結果。
3 名詞短語對齊方法
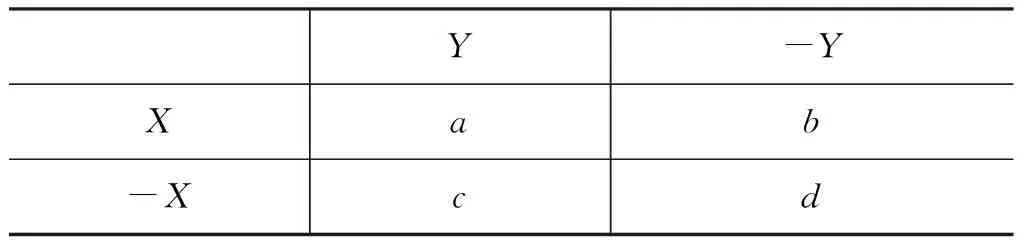
表1 X與Y的聯列表
表格中a、b、c、d的含義為:
a: 雙語語料所有句對中,短語X和Y同時出現的次數;
b: 雙語語料所有句對中,短語X出現但短語Y不出現的次數;
c: 雙語語料所有句對中,短語X不出現但短語Y出現的次數;
d: 雙語語料所有句對中,短語X和Y均不出現的次數;
(6)
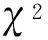
名詞短語對齊方法主要利用詞對齊時所獲得的對齊位置信息實現名詞短語對齊,其主要步驟如下:
(1) 從韓國語標注語料中通過正則表達式抽取出韓國語名詞短語;
(2) 根據抽取出的名詞短語,獲取詞對齊文件中每個韓國語詞語對應的漢語位置;
(3) 將獲得的漢語位置序列,按照從小到大的順序進行排序,按照排序順序抽取出對應的漢語詞語,獲得候選名詞短語翻譯對;
4 實驗結果及分析
基于上述方法,本文初步實現了一個原型系統,并針對基于詞典和語義相似度的詞對齊方法、基于統計的詞對齊方法和基于統計和詞典相融合的方法,初步進行了一些試驗,測試不同詞對齊方法對本文提出的基于詞對齊位置信息的名詞短語對齊結果的影響。
實驗中使用的韓漢雙語詞典包含詞條50 357條。語義詞典使用《同義詞詞林》。經過句子對齊并用于統計訓練的雙語句對112 475對,來自韓國《朝鮮日報》、《中央日報》和《東亞日報》發布的各類新聞,內容涵蓋韓國語的政治、經濟、文化、科技等方面。該語料庫在內容真實的基礎上,具備韓國語新聞語料最普遍的語言特點,根據這些語料進行相應研究,得出的結論也能體現出韓國語新聞語料的一般性特征,因此選用新聞語料,可使研究結果更加客觀真實。其中的漢語句子經過分詞處理,韓國語句子經過分詞和詞性標注處理。從訓練語料中隨機抽取300句對中的名詞短語并做人工校對,作為標準測試語料。
在實驗結果的評價方面,目前最常用的兩個指標分別是準確率和召回率[12],其中,準確率和召回率的定義如式(7)、式(8)所示。
表2給出了基于詞典的詞對齊方法、基于統計的詞對齊方法和融合的詞對齊方法下的名詞短語對齊結果。
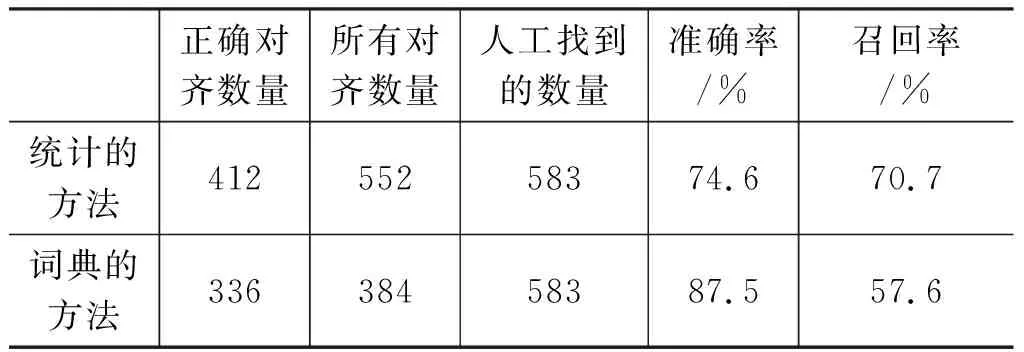
表2 名詞短語對齊結果
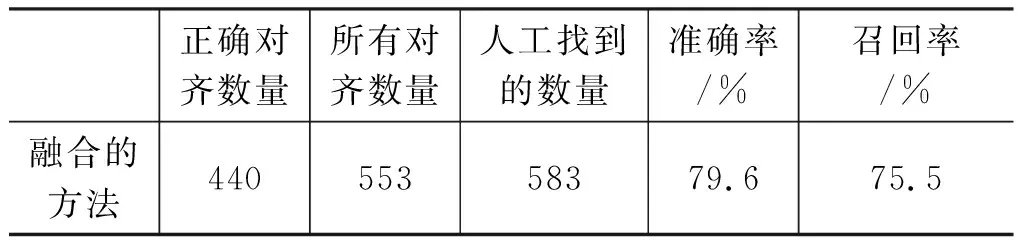
續表
從表2可以看出,基于詞典的方法中,對齊具有較高的準確率,但由于詞典的覆蓋能力有限,因此召回率較低。而基于統計的方法,可以提高召回率,但準確率較低。在基于統計和詞典相融合的方法中,在基于統計的方法基礎上,利用基于詞典的方法,結合了基于統計的方法和基于詞典的方法的優點,既彌補了基于統計方法中準確性的不足,使得正確的對齊數增加,保證非空對齊的正確率,又可以克服基于詞典的方法中詞典覆蓋能力有限的問題,使得對齊的召回率有了進一步的提高,在此方法下召回率和準確率也都達到了三個實驗中較為均衡的值。
分析對齊中產生的錯誤,一部分原因是由于資源不足引起的(詞典譯文缺乏、統計數據不足等)。其他錯誤大部分是由于漢語和韓國語之間存在固有的表達差異造成的,如韓國語中的成語、慣用搭配等在相應的漢語中通常采用意譯。本文提到詞對齊方法尚不能解決好這類錯誤,對于這些錯誤,有待進一步增加句法分析和語言學知識加以解決。
5 結論
本文通過對基于三種不同詞對齊方法的名詞短語對齊結果進行實驗分析,可以得到以下結論:
(1) 語言學信息在雙語語料庫詞對齊中有著重要作用。雙語詞典可以提供可靠的非空對齊。基于詞典和語義相似度的方法可以提高對齊的正確率。
(2) 當語料庫規模較大時,基于統計的方法對提高對齊的召回率具有重要作用。
(3) 在資源和語料不足的情況下,基于詞典和基于統計相結合的方法是進行詞對齊的有效方法。
盡管本文使用了多種對齊方法,但對齊的準確率與召回率仍然不能令人滿意。一個主要原因是由于韓漢雙語間的語言差異,使得很多對齊問題需要在句法層面上才能得以解決。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
