類比社交網絡的進程故障檢測方法研究
2018-09-18 09:19:26程自強
中文信息學報 2018年8期
程自強,黃 榮,楊 洋
(1. 浙江大學 計算機學院,浙江 杭州 310058;2. 上海海高通信股份有限公司,上海 201612)
0 引言
對于一般的信息或社交網絡,我們已經得到很多它們的性質和建模方法。例如,六度分離理論(six degrees of separation)[1],弱連接(weak ties)[2],無標度(scale-free)[3-4],以及Small World[5],Kronecker Graph[6]等。利用這些知識,結合真實社交網絡的結構,我們可以對一個社交網絡進行社區(Community)[7-8]劃分,對網絡中的邊進行預測[9]以及對節點對之間的影響進行建模和量化分析[10]等。而對于一個缺少先驗背景知識的網絡,以往并沒有明確的分析方法。
本文將從社交網絡的角度,運用社交網絡的相關性質和分析方法,去理解服務器集群上的進程網絡,并對該網絡上的節點即某個進程的狀態進行預測。
我們首先對這樣一個電信CSB業務系統服務器集群上的進程網絡進行建模:
該進程網絡可看作圖G(V,E,T)。其中節點v∈V為單個進程,T為當前網絡的時間戳,e∈E表示進程間的聯系,即e(i,j)意味著進程i和j在時刻T存在通信(如socket通信),邊e的權重w為當前時刻兩個進程之間的通信次數(多端口通信)。
和社交網絡不同的是,我們缺乏對該進程網絡上節點的了解。例如,一個進程何時會與周圍的進程產生通信,為什么會產生通信,及我們的預測目標: 一個進程是否會發生崩潰。因為進程間的通信通常依賴于某個進程的具體功能和實際服務的使用情況。
即使如此,我們還是可以類比社交網絡中節點的相關性質,對該進程網絡中的節點做出如下假設:
1) 對應于社交網絡中個人的性別、年齡等信息,我們可以將某個進程的占用CPU、內存情況看作進程節點的“固有屬性”;
2) 對應于社交網絡中個人的社交關系,進程之間的通信可以看作進程網絡中的邊;那么,節點在網絡中的中心度[11-12]可以衡量節點的活躍程度以及與外界聯系的緊密程度;
3) 對應于社交網絡中的個人行為如轉發推文等,我們將進程的某一特定狀態視作該進程做出的一個行為;具體地,我們把進程崩潰視作一個進程的行為,那么進程網絡中進程崩潰這一現象可以類比為社交網絡中消息的擴散[13]。
在社交網絡中,我們傾向于認為“朋友的朋友更有可能成為自己的朋友”[14];對應地,在進程網絡中,我們可以傾向于認為,一個進程的行為(狀態)不僅會影響和它直接有通信的進程,還有可能影響它的“鄰居的鄰居”。
基于以上假設,我們把一個進程發生崩潰的現象定義為進程網絡中一個節點的狀態;在給定的時間戳下,網絡中的節點可以被分為兩類: 發生崩潰的節點和沒有發生崩潰的節點;因此,預測進程網絡中進程的崩潰問題可以轉化為針對網絡節點的二分類問題[15]。我們仔細地選取節點的相關屬性作為節點分類的特征,用SVM(Support Vector Machine)分類器[16]對該模型進行分類,并得到了較為可信的結果。
1 問題定義
我們對電信CSB業務系統服務器集群上的進程網絡以及該網絡中的節點、邊和節點狀態做出如下定義:
1.1 進程標識符:
我們用一個進程的如下信息作為其標識符: 本地IP,本地主機名,本地進程組,進程描述以及進程號。換言之,上述五個字段可以確定一個唯一的進程。
如果兩條日志記錄中進程的標識符完全一致,我們認為這是同一進程的記錄。
1.2 常駐進程:
我們把存在時長超過某一閾值ΔT的進程定義為常駐進程。一方面我們關心那些運行時間較長的主要進程的狀態;另一方面服務器集群上存在臨時啟動的進程,它們的進程號不斷變化,狀態表現得極不穩定,干擾我們對進程狀態的判斷。
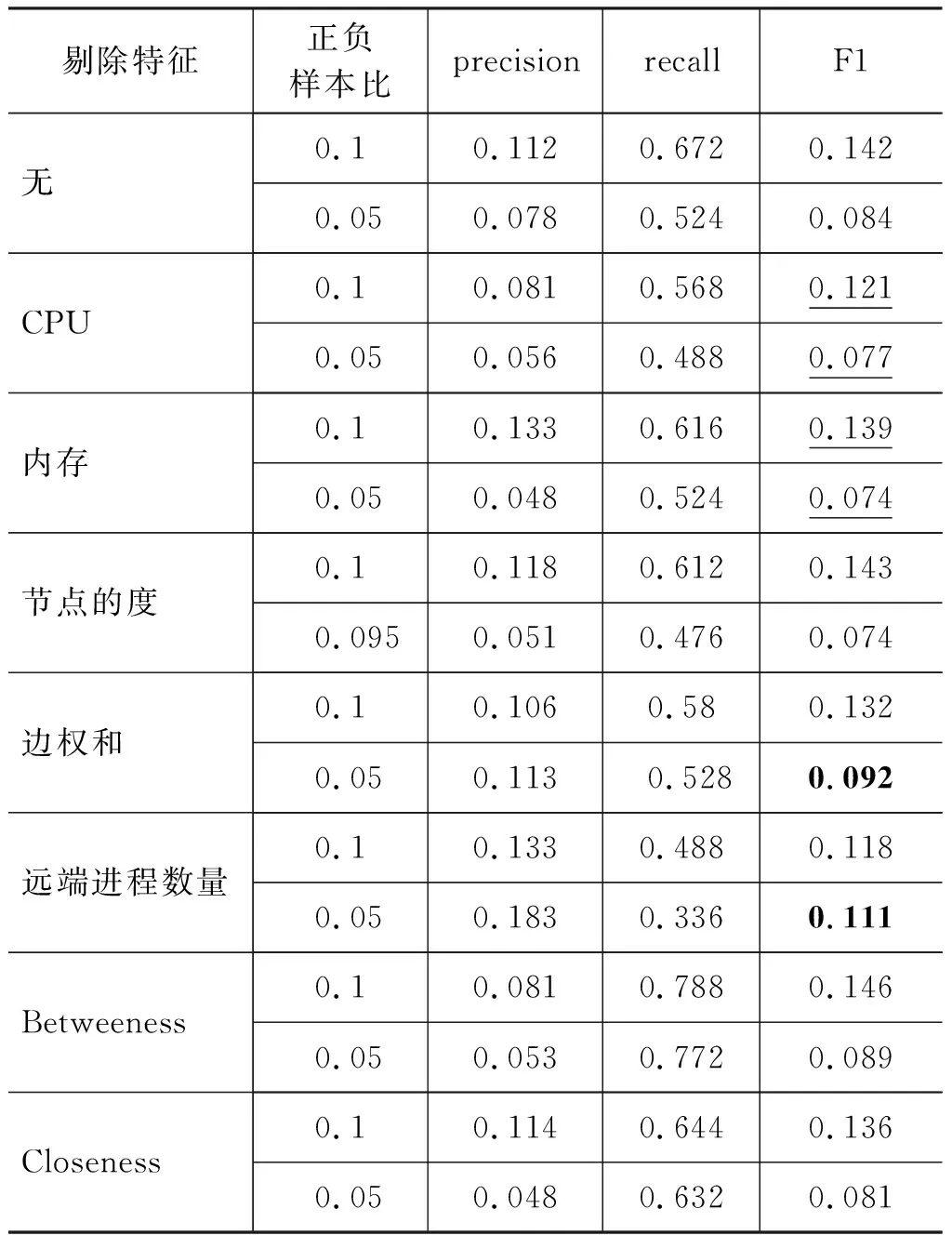
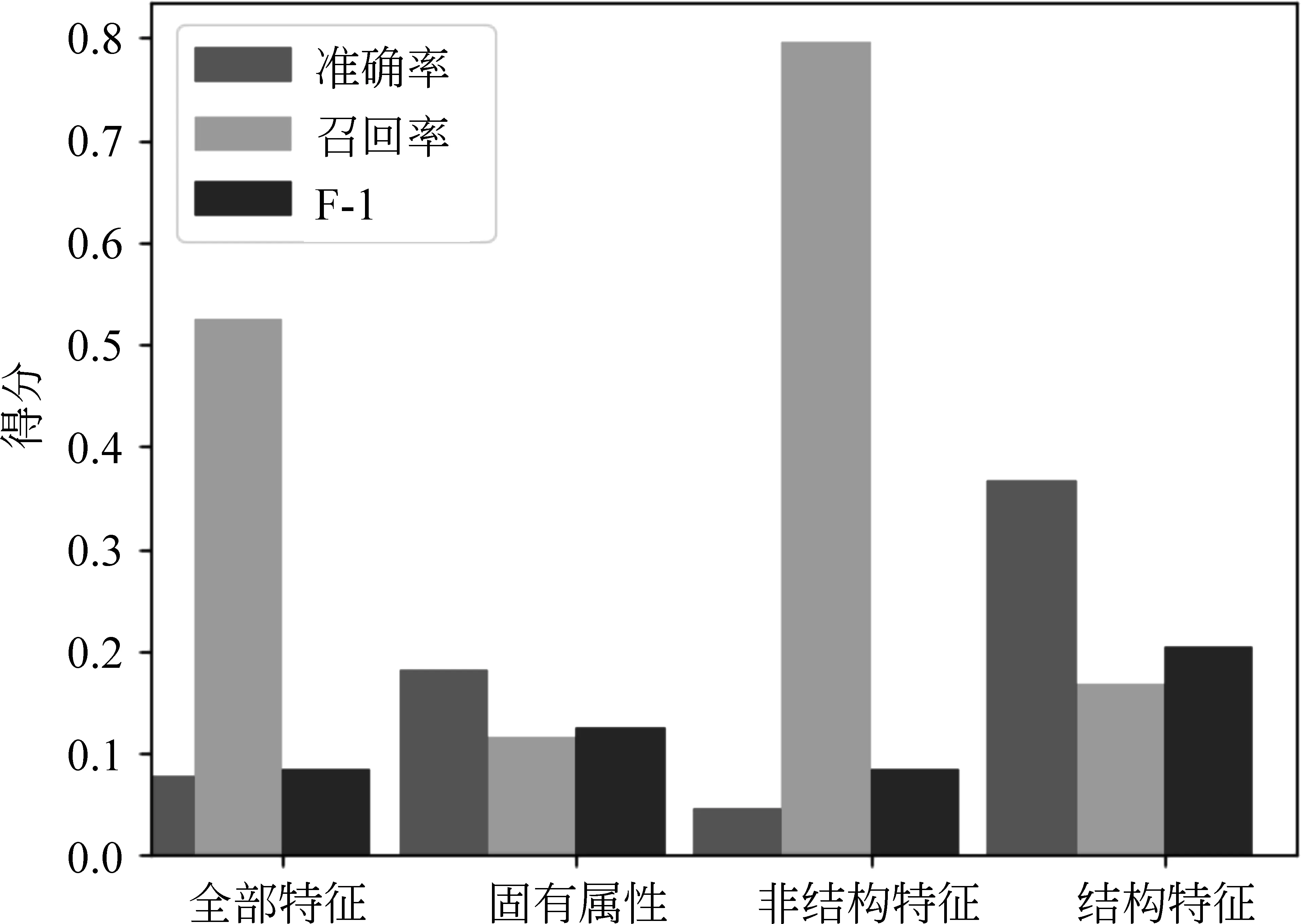
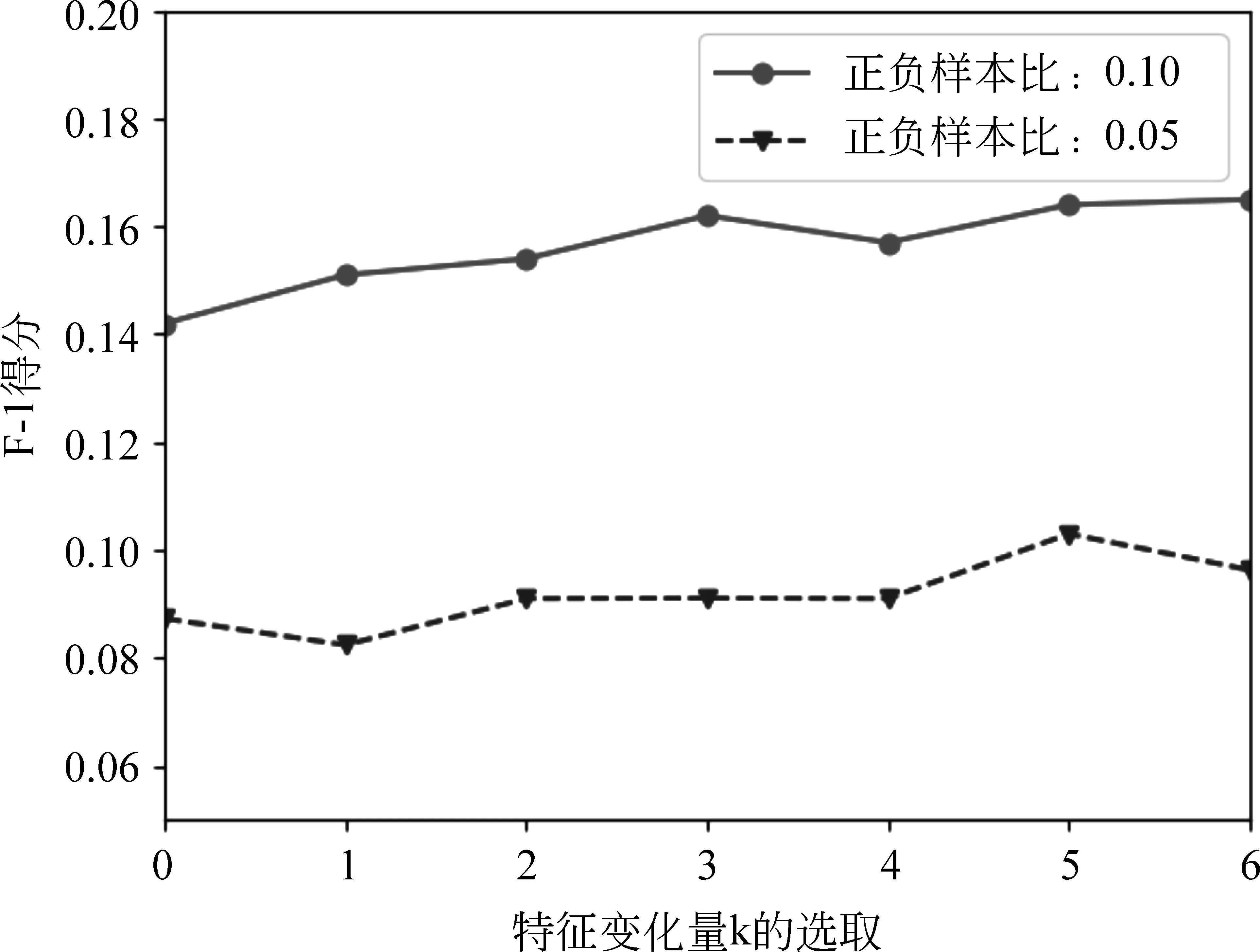
常駐進程i體現在日志記錄中的形式為: 存在進程i的兩條記錄,時間戳分別為T1,T2(T1 該進程網絡可以用圖G(V,E,T)來表示,其中節點v∈V為某一具體進程,用1.1中的五個字段來描述,T為當前網絡的時間戳,e∈E表示進程間的聯系,即e(i,j)意味著進程i和j在時刻t存在通信,邊e的權重w為通信次數。 假設常駐進程i在進程日志中連續出現的時間戳分別為T1,T2(T1 我們把常駐進程i在時刻T2為崩潰狀態定義為: 與T1時刻相比,除進程號外,進程i的其余四個標識符均未發生變化,即e1≠e2。 換言之,一個常駐進程在時刻T為崩潰狀態意味著該進程此刻的進程號與其上一次在日志中出現的進程號不一致。 我們把在日志記錄中本地IP或本地主機名為空的進程定義為遠端進程。由于日志記錄是由本地probe探針對正在運行的進程進行遍歷得到的,因此日志記錄中本地IP或主機名為空可以視作該進程不在這個服務器集群上,我們稱這類進程為遠端進程。 在對進程狀態進行預測前,我們先從整體上對數據做一些基本的分析。 本數據集(服務器集群的進程日志)由電信CSB業務系統服務器CSB節點上的probe探針定時探測得到,我們選取了2016年8月30日14時至18時共2 858 063條日志記錄進行分析。其中,該時間段內的常駐進程共973個,進程崩潰次數為25次。在后面的二分類問題中,我們把在時刻T發生崩潰的進程定義為正樣本,沒有發生崩潰的進程定義為負樣本。在此數據集上,正負樣本比為0.16‰,是極為稀疏的。 對常駐進程i在時刻T,我們定義以下特征: 1) CPU占用率; 2) 內存使用量; 3) 與之存在通信的進程數量(即進程網絡中節點的度); 4) 與其他進程的通信總量(即進程網絡中節點的邊權之和); 5) 存在通信的遠端進程數量; 6)i在進程網絡G(,,T)中的中心度,包括betweenness[17]和closeness[18]。 因此,可以得到正負樣本的特征整體分布: 圖1 CPU占用率的整體分布 其中橫坐標為進程CPU占比(百分比),縱坐標為累積分布概率;圓形點線為正樣本分布曲線,三角形點線為負樣本分布曲線。 圖2 內存占用量的整體分布 其中橫坐標為進程內存使用量(100MB),縱坐標為累積分布概率;圓形點線為正樣本分布曲線,三角形點線為負樣本分布曲線。 從圖1~圖2來看,正負樣本在CPU和內存這兩個“固有屬性”上存在一定的差異: 對于負樣本即沒有發生崩潰的進程,它們的CPU使用率集中在20%以下和100%以上,內存使用量的分布較為分散;而正樣本的CPU使用率分布較為分散,內存使用量卻集中在0和10GB以上這兩個區間。根據經驗,這種分布是可以理解的。因為,一個較大的進程發生崩潰后剛剛啟動時往往需要重新加載,內存使用量自然比較多;而對于正在運行的進程,如果是計算密集型的,CPU使用量會較高。否則,一般不會占用太多的CPU資源。 圖3 存在通信的進程數量的整體分布 其中橫坐標為存在通信的進程數量(即進程節點在進程網絡中的度),縱坐標為累積分布概率;圓形點線為正樣本分布曲線,三角形點線為負樣本分布曲線。 圖4 與其他進程的通信總量的整體分布 其中橫坐標為通信總量的值(即進程節點在進程網絡中的邊的權重之和),縱坐標為累積分布概率;圓形點線為正樣本分布曲線,三角形點線為負樣本分布曲線。 圖3~圖5為其他非結構特征的整體分布。從各圖中可以看到,存在通信的進程數量這一特征在正負樣本之間沒有顯著區別,即進程網絡中節點的度大多為1;與其他進程的通信總量也不具有太大的參考價值。盡管從分布來看,正樣本的通信總量分布更為平均(即節點的邊權之和范圍較大),但由于正樣本過于稀疏, 實際上在負樣本中邊權之和落在40至80之間的進程數量相對于正樣本總量仍是十分巨大的;而存在通信的遠端進程數量這一特征同樣很難對正負樣本做出區分。也就是說,正負樣本在這三個非結構特征上沒有明顯差異。 圖5 與遠端進程通信的整體分布 其中橫坐標為存在通信的遠端進程數量,縱坐標為累積分布概率;圓形點線為正樣本分布曲線,三角形點線為負樣本分布曲線。 我們再對該進程網絡中的結構特征的分布情況進行考察。再次回到我們的目標,即我們希望能對進程狀態做出判斷: 對于給定的進程,其是否為崩潰狀態。對于較大規模的服務器集群,其上運行著大量進程。我們不難想象,如果一個進程關聯越多的其他進程,那么該進程就越重要,其對服務器的負載就越重,崩潰的可能性就越大。 因此,我們選擇進程網絡圖上的結構特征來衡量一個進程的重要性或者核心程度,我們希望通過進程節點的中心度[11-12]來幫助我們對進程狀態做出分析。圖6~7給出了進程節點的中心度的分布情況。 圖6 betweeness的整體分布 其中橫坐標為betweenness的十進對數(log10),縱坐標為累積分布概率;圓形點線為正樣本分布曲線,三角形點線為負樣本分布曲線。 圖7 closeness的整體分布 其中橫坐標為closeness的值(log10),縱坐標為分布概率;縱坐標為累積分布概率;圓形點線為正樣本分布曲線,三角形點線為負樣本分布曲線。 遺憾的是,正負樣本的中心度并沒有顯著的區別: 正負樣本的betweenness的整體分布幾乎一致。而對于closeness,盡管正樣本看似在30至40上的某個區間有異常的分布,但注意到負樣本中也有近百分之二的進程的closeness大于50。我們更傾向于認為這些都是closeness較大的進程,至于closeness的值究竟是30還是50,這是不重要的。 事實上,這并不與“中心度高的重要進程更容易崩潰”這一假設矛盾。往往一個中心進程崩潰會導致與其存在通信的其他進程或者該進程的子進程產生異常,而日志記錄是在某個特定的時間點通過probe探針生成。因此,很有可能在生成日志記錄時,以該中心進程為核心的進程組都進行了重啟,故而正樣本的中心度分布和樣本的整體分布沒有較大區別。 值得注意的是,betweeness和closeness具有一定的相關性。盡管正負樣本關于中心度特征的分布相似,但二者作為特征訓練分類器的效果也許會有意想不到的效果,在實驗中我們也將看到這一點。 我們對進程的靜態特征做了整體分析,但是我們還應當注意到,進程的崩潰是一個過程,時間維度上的特征也許會較好地反映進程的狀態。 我們考慮進程從正常狀態到崩潰狀態的時間間隔,體現在日志記錄中即為同一進程的進程號不同的兩條連續日志記錄的時間戳的差。如果進程一直保持著正常狀態(沒有崩潰),我們傾向于認為其在日志記錄中出現的時間戳應當是比較穩定的,即不會突然在一段時間內沒有日志記錄。而對于發生崩潰的進程,由于其重啟等因素,可能會有較長時間間隔沒有日志記錄的現象。 具體地,我們定義進程i的一個時間間隔ΔT=T2-T1,其中T1,T2為i的連續兩條日志記錄的時間戳(T2>T1);定義ΔT=T2-T1為正樣本的時間間隔,如果恰好在T2時刻進程號發生變化。 圖8為正負樣本的時間間隔的整體分布。再則,我們發現在時間間隔這一特征上沒有顯著區別。由于probe探針每三分鐘采樣一次,因此時間戳的差集中在3、6或9等數值上。 圖8 時間間隔的整體分布 其中橫坐標為時間間隔(分鐘),縱坐標為累積分布概率;圓形點線為正樣本分布曲線,三角形點線為負樣本分布曲線。 除了時間間隔外,對于進程i的兩條日志記錄T1,T2,我們在分類問題中還會考慮T1,T2上的特征差,即進程的特征隨時間的變化量。后面將看到,這一考慮是十分有效的。 我們將用分類問題的思路判斷給定進程的狀態。由于進程狀態只有正常和崩潰兩種,因此目標簡化為二分類[15]問題。 問題: 給定一個進程的相關描述,輸出該進程所處的狀態(崩潰與否)。 我們人工提取2.2中提及的關于進程的非結構化和結構化特征作為輸入,通過訓練集得到一個SVM分類器,對測試集中的每個進程輸出判斷結果。 其中,由于正負樣本比過小(正樣本過少),我們采用過采樣(over-sampling)[19]的方法生成訓練集,用交叉驗證[20-21]的方式對分類器進行訓練,然后對正樣本極少的原始數據集進行測試。 我們按照1.4給出的方式,人工從原始數據集中提取進程標簽(正負樣本)。即首先過濾日志得到常駐進程,對每個常駐進程,判斷其上一條時間戳的日志記錄的進程號是否與當前時間戳的進程號一致;若不一致,則認為在當前時間戳進程發生崩潰,采集為正樣本,否則為負樣本。 我們將2.2中提及的非結構化和結構化特征組合起來作為一個進程的基本特征向量。除此之外,我們還增加考慮特征隨時間的變化量。 給定進程i,時間戳T0和其截至T0時刻所出現的日志記錄的時間戳序列Ti,i≥0,滿足 Tk+1 我們定義進程i在T0時刻的k階特征變化量 Δfk=g{f(T0)-f(Tk),T0-Tk}, 其中f(T)為T時刻進程i的基本特征向量,g(v,t) 為time_decay[22]函數,定義為: g(v,t)=v*t*e1-t, 即對向量v乘時間間隔系數t*e1-t。 我們將上述k階特征變化量(k為參數)和基本特征向量拼接起來,得到一個進程的完整特征,作為樣本數據的輸入。 本數據集(電信CSB業務系統服務器集群的進程日志)時間跨度為2016年8月30日14時至18時,共2 858 063條日志記錄進行分析。其中,常駐進程973個,進程崩潰次數為25次,正負樣本比為0.16‰。 進程狀態的判斷是一個二分類問題,因此選取precision, recall和F1得分作為評價標準。由于正負樣本比過低,實驗過程中,首先對負樣本進行隨機采樣,使得正負樣本比分別為0.1和0.05。然后采用過采樣和交叉驗證的方式進行訓練,每次訓練和測試過程重復10次,結果取平均值。 首先考慮具體的某個基本特征對分類效果的影響: 表1給出了不同特征對分類結果的影響的比較。可以看到,正負樣本比對實驗結果的影響是明顯的: 正負樣本比越低,訓練得到的分類器進行崩潰檢測的效果越差;此外,橫向地與沒有剔除任何特征的分類器相比,我們可以發現,CPU和內存這兩個特征對區分正負樣本的作用是顯著的,剔除其中任何一個都會使得F1-score的值有明顯的下降。這個結果和特征的分布具有一致性,因為正負樣本的CPU占用率和內存使用量的分布有著明顯的區別;而對于剔除節點的度、邊權和以及圖的結構化特征betweeness和closeness,我們可以發現隨著正負樣本比的降低,F1-score反而在增加。 表1 單個特征對分類結果的影響 為了考慮不同特征之間的相關性的影響,我們把上述的特征分為三類: 1)進程的運行信息,即CPU和內存使用情況;2)進程的通信情況,體現為進程網絡中節點的度(或帶權重的邊權和)以及存在通信的遠端進程數量;3)進程網絡中節點的結構特征,即betweenness和closeness。 圖9、圖10展示了不同特征對分類結果的影響。可以看到,第二類特征極大地提高了分類器的recall值,但precision值很低。這是因為有大量的負樣本在第二類特征上和正樣本具有相同的值,在只有第二類特征的條件下,分類器傾向于認為大部分樣本都是正樣本。因而崩潰預測在沒有第二類特征的分類器上達到了最好的效果。 而第一類和第三類特征都可以在一定程度上反映進程的狀態。這正如我們在特征分布中看到的那樣,正負樣本的CPU和內存使用情況的分布不同。而第三類特征即進程節點的中心度盡管分布相似,但二者具有緊密的相關性,結合在一起考慮便可以作為崩潰檢測的指標之一。 圖9 不同特征對分類的影響(1)其中橫坐標表示選取哪些特征。 圖10 不同特征對分類的影響(2)其中橫坐標表示選取哪些特征。 圖11 不同特征變化量的F1-score 其中橫坐標為考慮特征變化量的階(0表示沒有考慮特征變化量),縱坐標為F-1得分。 圖11給出了特征變化量對分類結果的影響的比較,其中k=i表示我們將1,2,…,i階特征變化量均拼接加入進程的特征中。我們可以明顯地看到,特征變化量對分類結果有正相關的影響,即考慮特征變化量越充分(k越大),分類結果越好。 這說明進程的崩潰不是突然的,一個進程在發生崩潰的前后,其CPU、內存使用情況以及和其他進程的通信等屬性往往會有突出的變化: 比如在PC上,往往一個進程占用內存過大會出現崩潰,崩潰前內存使用量增加的趨勢則反映了其崩潰的可能性。 從社交網絡的角度來看,進程網絡也是在不斷變化的,網絡節點也就是某個進程在時間這一維度的變化帶有著豐富的信息。實驗結果也表明,我們將時間信息加入進程的特征進行訓練,得到了效果更好的分類器以對進程的崩潰進行檢測。 本文從社交網絡的角度去分析由進程節點構成的網絡,并選取節點的特征進行訓練以對節點故障(崩潰)進行預測。 通過選取不同的特征(如進程運行信息、通信情況、進程節點的結構化特征以及時間維度的特征等)對進程崩潰進行預測,我們可以得到如下結論: 1) 由于數據集上正樣本的稀疏性,訓練數據的正負樣本比對訓練結果有顯著的影響。 2) 相比于進程的通信情況,進程節點的結構特征以及進程運行信息(如CPU占用率,內存使用量等)對于判斷一個進程是否會崩潰更具參考價值。 3) 從時間的維度看,進程的運行和通信信息的變化量更能反映該進程的狀態。 針對電信CSB業務系統進程故障檢測這一問題,我們還可以從以下兩方面著手考慮: 1) 類比社交網絡中的信息擴散[12],我們可以把進程崩潰看作進程的一種行為。通過對進程節點之間的影響力進行建模,可以預測進程的崩潰情況。 2) 除了人工地選取進程特征進行訓練,我們還可以運用graph embedding[23]的方法對進程網絡進行建模,用embedding的結果作為進程特征訓練分類器。1.3 進程網絡
1.4 進程崩潰
1.5 遠端進程
2 數據觀察
2.1 數據量
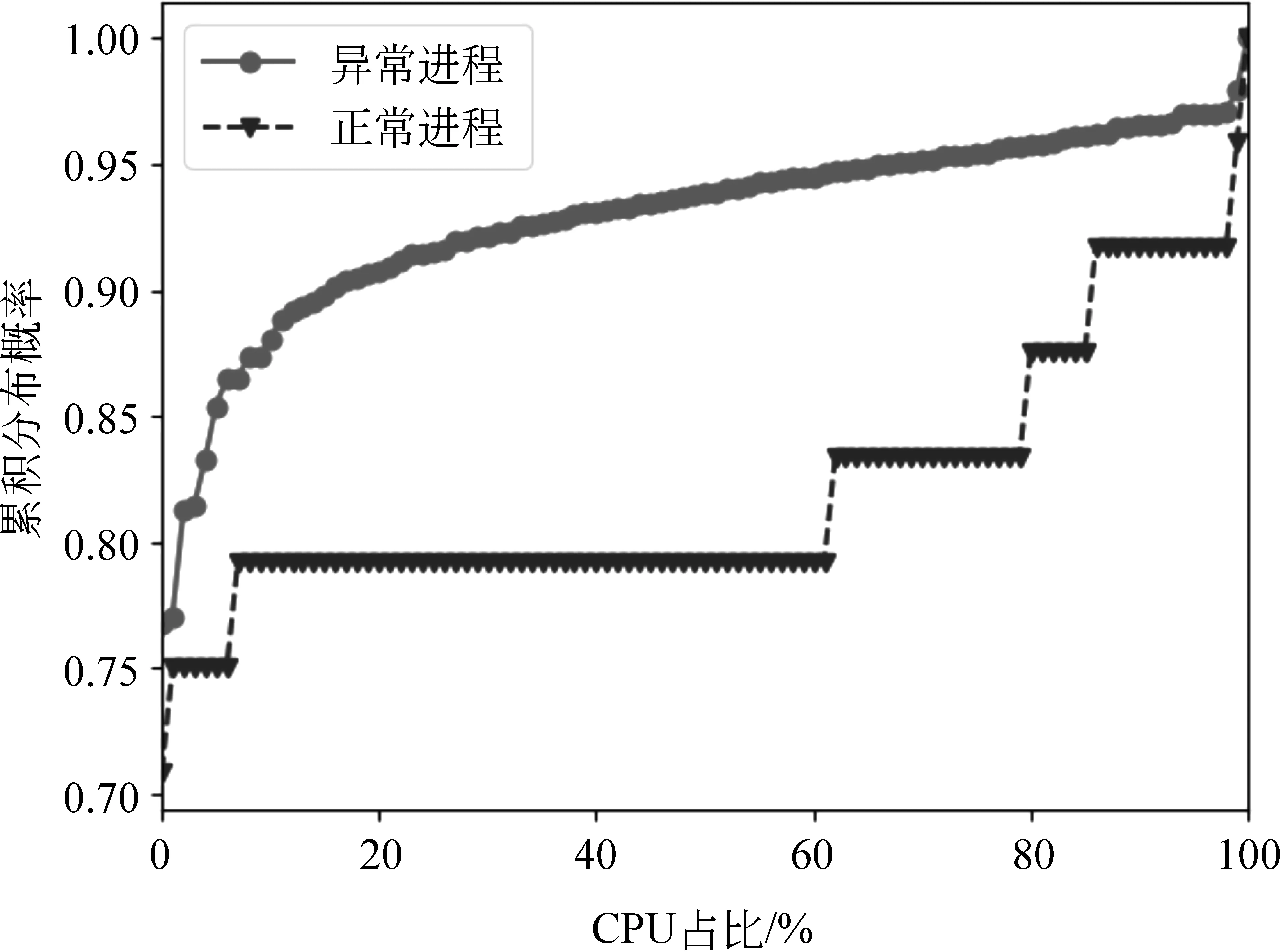
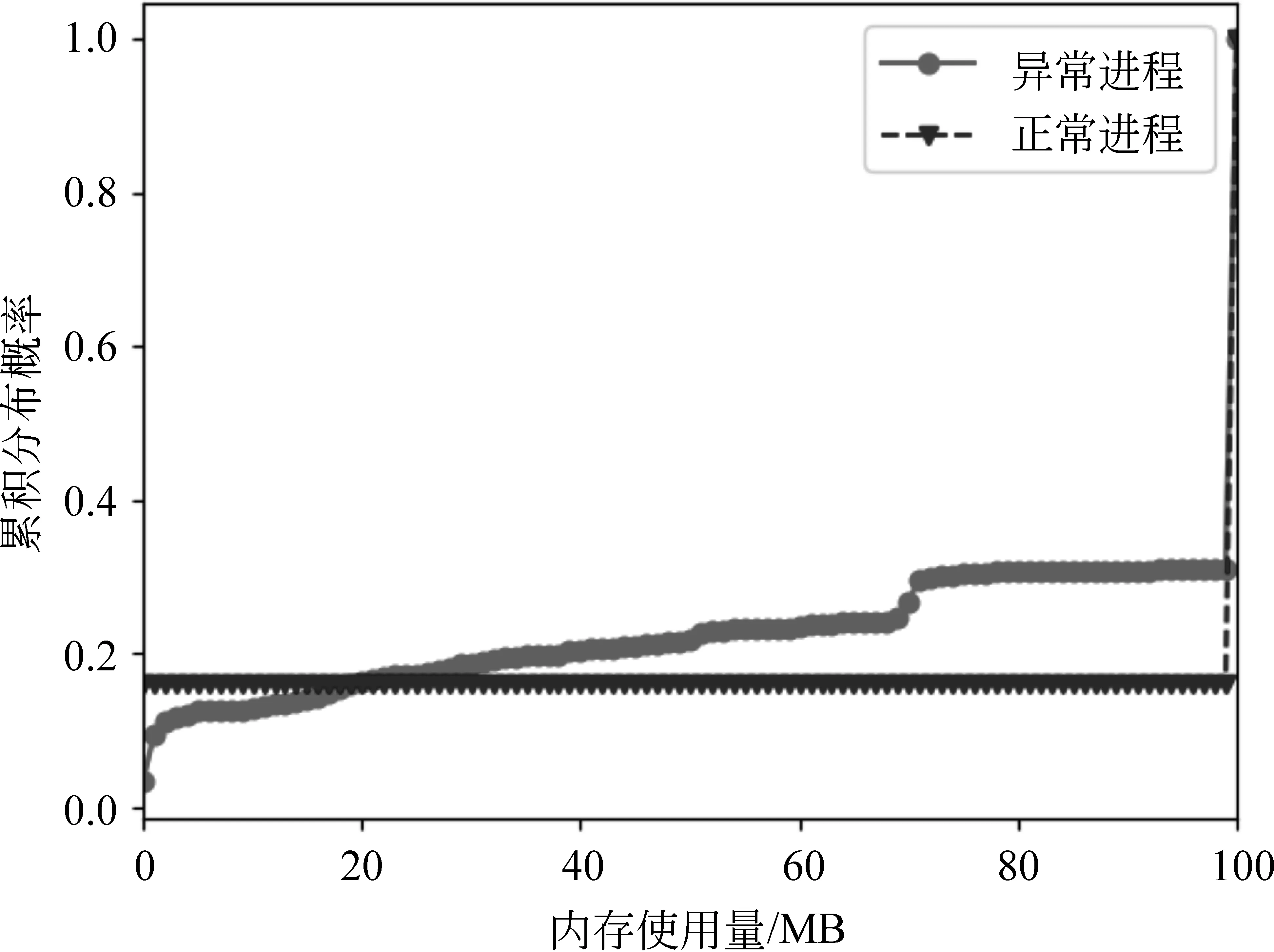
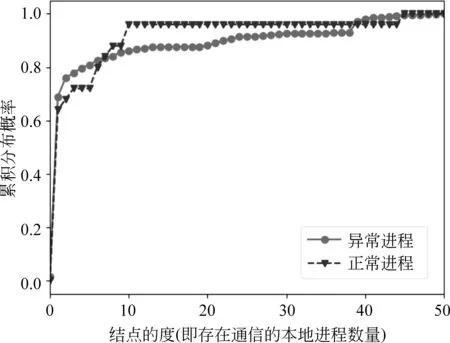
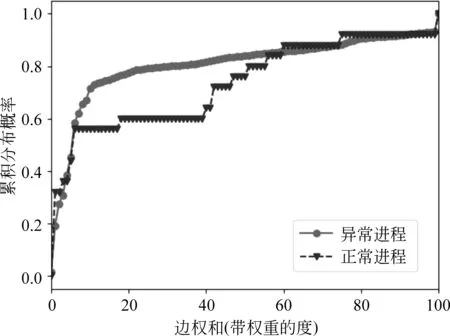
2.2 特征分布
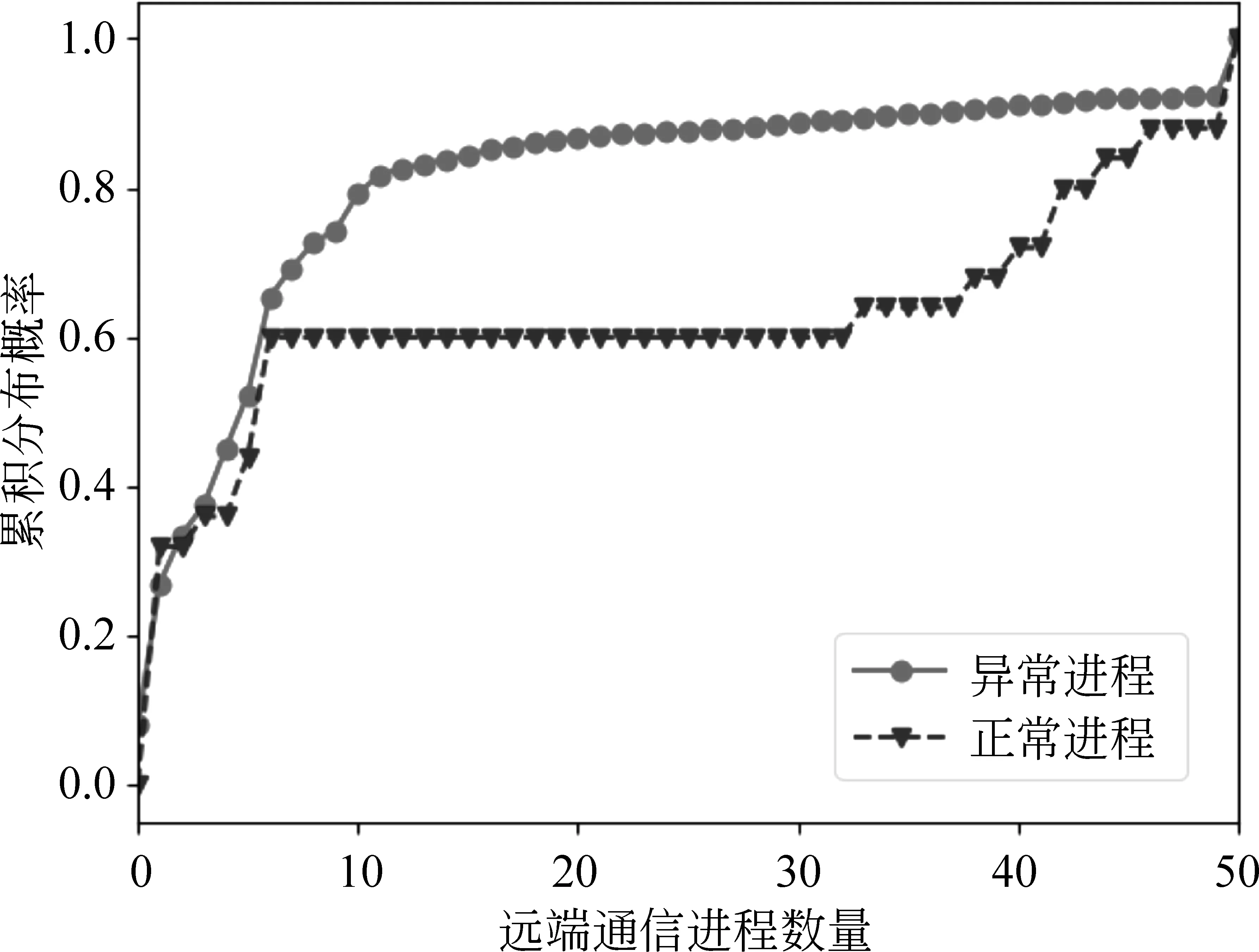
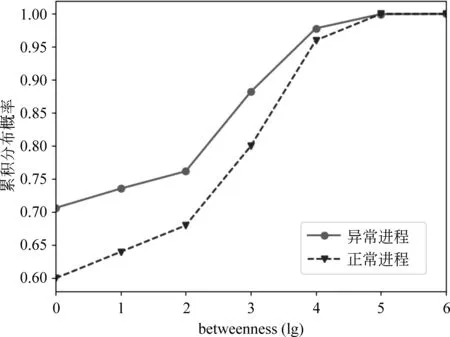
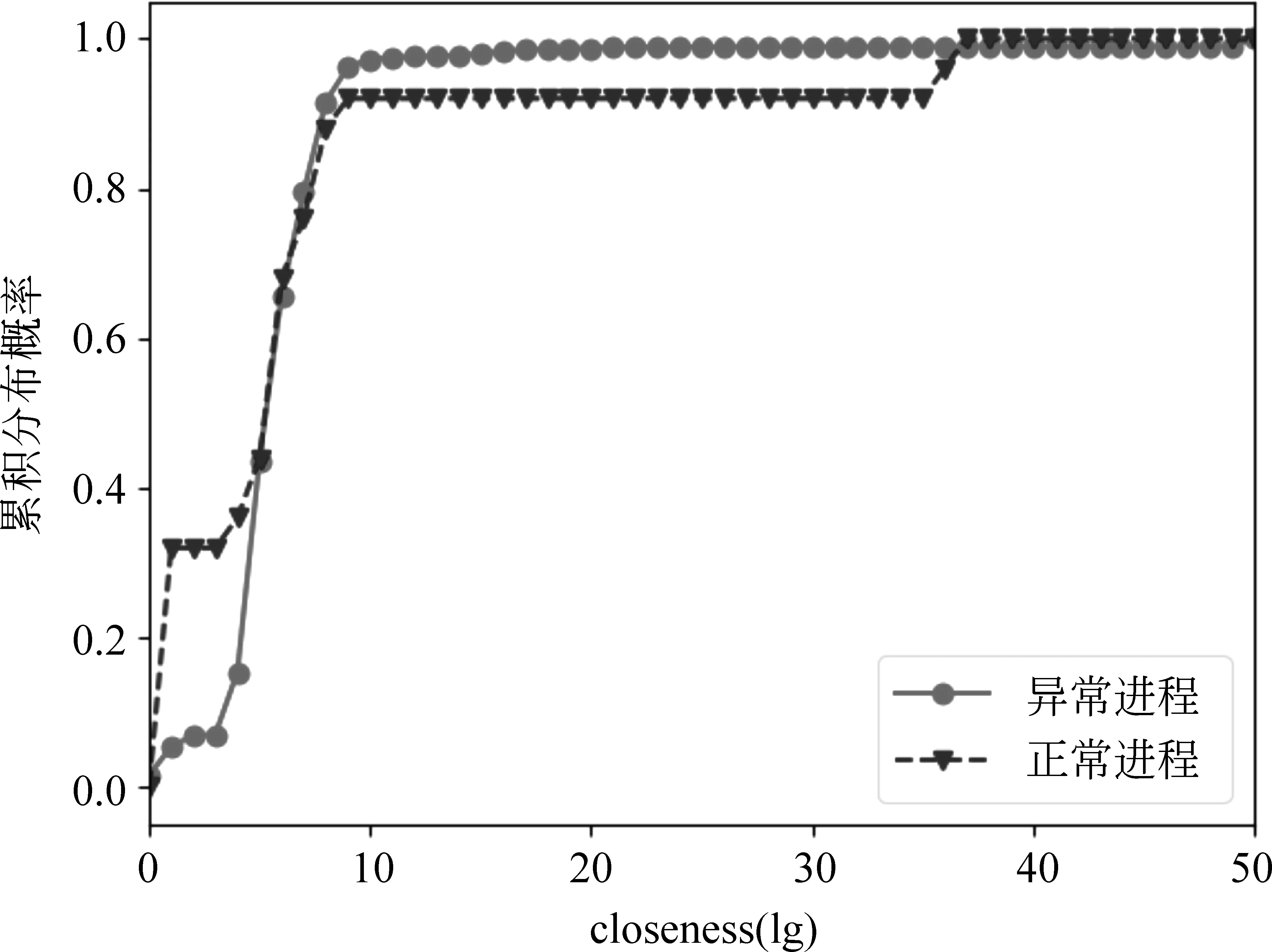
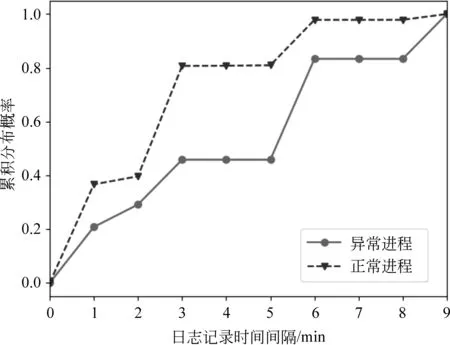
2.3 時間間隔分布
3 實驗方法
3.1 訓練方法
3.2 標簽的提取
3.3 特征選取
4 實驗結果
4.1 實驗設置
4.2 實驗結果

5 總結
6 未來的工作
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28中國外匯(2019年20期)2019-11-25 09:54:58當代陜西(2019年10期)2019-06-03 10:12:04數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54河南科技(2014年23期)2014-02-27 14:19:15教育與職業(2014年7期)2014-01-21 02:35:04計算機與網絡(2013年1期)2013-06-05 05:31:50中華女子學院學報(2012年6期)2012-03-25 13:52:27
