基于Bi-tagged特征的維吾爾文情感分類方法研究
2018-09-18 09:19:16熱西旦木吐爾洪太吾守爾斯拉木
中文信息學(xué)報 2018年8期
熱西旦木·吐爾洪太,吾守爾·斯拉木
(1. 新疆大學(xué) 信息科學(xué)與工程學(xué)院,新疆 烏魯木齊 830046; 2. 伊犁師范學(xué)院 電子與信息工程學(xué)院,新疆 伊寧 835000)
0 引言
近年來,由于國家在政策、資金等方面對新疆通信事業(yè)的大力支持,維吾爾文網(wǎng)站及通信平臺蓬勃發(fā)展,由此產(chǎn)生了規(guī)模龐大的具有情感傾向的維吾爾文文本數(shù)據(jù)。面對海量數(shù)據(jù),人工方式已然難以進(jìn)行全面、有效的情感分析,因此運用計算機技術(shù)實現(xiàn)對維吾爾文文本的情感分析成為必然選擇。
文本情感分類是對帶有情感色彩的文本按其情感傾向進(jìn)行區(qū)分的一種處理方式,是文本情感分析中的一項核心任務(wù)。目前常用的文本情感分類方法包括基于情感詞典的情感分類方法[1-2]和基于機器學(xué)習(xí)的情感分類方法。其中基于機器學(xué)習(xí)的方法經(jīng)歷了淺層學(xué)習(xí)(傳統(tǒng)學(xué)習(xí))[3-4]和深度學(xué)習(xí)[5-6]兩次發(fā)展浪潮。
對傳統(tǒng)機器學(xué)習(xí)方法的研究已經(jīng)取得了較為豐碩的成果,該方法的分類效率很大程度上依賴于對情感特征的描述。在基于傳統(tǒng)機器學(xué)習(xí)的情感分類實踐中,基于詞袋(BOW)模型的特征表示方法比較常用。雖然BOW模型簡單有效,但卻偏重詞語之間的獨立性,導(dǎo)致忽略詞語之間的語義關(guān)系和順序關(guān)系。因此,有必要開發(fā)更具代表性并能更好體現(xiàn)詞語之間語義關(guān)系的特征提取方法,從而提高文本情感分類效率和質(zhì)量。為此,研究者們在情感分類任務(wù)中紛紛嘗試不同類型的詞依賴特征,如基于詞性的特征[1,7],更高序列的n-grams特征[2,8],依賴關(guān)系特征[8-9]等。
深度學(xué)習(xí)(deep learning)是相對于淺層機器學(xué)習(xí)而言的。隨著近年硬件設(shè)備的發(fā)展以及大數(shù)據(jù)時代的到來,情感分類領(lǐng)域掀起了研究“深度學(xué)習(xí)”的熱潮。深度學(xué)習(xí)模型將從大量無標(biāo)注語料中自動學(xué)習(xí)詞向量并將其作為基本特征,從而克服傳統(tǒng)方法人工設(shè)計特征的不足,降低人力和時間成本的消耗。
但在將深度學(xué)習(xí)模型中訓(xùn)練出的詞向量作為情感分類過程的輸入特征時,存在一個不容忽視的問題: 根據(jù)詞匯上下文構(gòu)建詞向量時,由于未考慮情感信息,可能產(chǎn)生基于上下文相似而情感極性相反的詞匯訓(xùn)練出相似詞向量的現(xiàn)象,這就會降低文本情感分類的效率和質(zhì)量。為解決該問題,研究者們將情感詞向量與傳統(tǒng)人工設(shè)計特征相結(jié)合[10-11],以此提高深度學(xué)習(xí)模型的性能。
在情感分類領(lǐng)域,情感詞匯(如“好”“高興”等)可以作為表達(dá)句子情感傾向的重要線索。但有時孤立地分析單字、單詞并不能確定句子所蘊含的真實情感。同一字詞與不同的上下文相結(jié)合,完全可以表達(dá)不同的情感傾向。如若單獨提取情感特征“好”,并不能將“很好”“不好”等詞匯特征所表達(dá)的相異的語義區(qū)別開,從而無法正確判斷句子的情感傾向。因而,在對關(guān)鍵詞匯進(jìn)行情感傾向分析的基礎(chǔ)上,兼顧由該詞匯及其上下文組成的短語,將有助于準(zhǔn)確判別整個句子的情感傾向。
在維吾爾文中由兩個或兩個以上單詞組成的短語十分常見,這些短語能夠表達(dá)豐富多樣的情感信息。但由于維吾爾文文本情感分類研究起步略晚,句法分析、語義分析等基礎(chǔ)自然語言處理工具相對缺乏等原因,在維吾爾文文本情感分類相關(guān)研究中,關(guān)于短語特征對情感分類效果的影響研究明顯不足。
針對該問題,本文借鑒文獻(xiàn)[2-3,7]中的研究思路,通過將語言學(xué)和統(tǒng)計方法相結(jié)合,從已經(jīng)標(biāo)注情感傾向的維吾爾文文本中總結(jié)出若干詞性規(guī)則,并據(jù)以從文本中提取具有先后順序的兩個單詞所構(gòu)成的Bi-tagged特征。為了進(jìn)一步提高分類效率,對Bi-tagged特征和unigram特征進(jìn)行組合,運用基于文檔頻率(DF)的特征選擇方法和SVM分類器對維吾爾文文本進(jìn)行正、負(fù)二元情感分類。
本文提出的Bi-tagged特征詞性組合規(guī)則,既包含了在英文情感分類任務(wù)中發(fā)揮積極作用的幾項詞性組合[2,7],又包含了在文獻(xiàn)[12]中提出的幾條維吾爾語情感短語構(gòu)詞規(guī)律,并通過對比實驗驗證了每一種組合對維吾爾文文本情感分類結(jié)果的影響。實驗證明: Bi-tagged特征能提取大部分具有豐富情感信息的維吾爾文情感短語,以及短語中所包含的否定信息。因此,該特征能夠在維吾爾文文本情感分類任務(wù)中發(fā)揮積極作用。
本文結(jié)構(gòu)組織如下: 第二部分介紹國內(nèi)外相關(guān)工作;第三部分介紹維吾爾文情感語料庫;第四部分介紹情感特征抽取工作;第五部分為實驗結(jié)果及分析;最后進(jìn)行總結(jié)并展望。
1 相關(guān)研究
大多數(shù)關(guān)于文本情感分類的研究主要基于傳統(tǒng)機器學(xué)習(xí)方法。該方法依賴良好的、具有代表性的特征來實現(xiàn)其較佳的性能。在基于機器學(xué)習(xí)的分類過程中,為了得到準(zhǔn)確的預(yù)測結(jié)果,就必須做好特征選擇。在英文和中文文本情感分類研究領(lǐng)域已有大量文獻(xiàn)比較系統(tǒng)地介紹了不同特征對情感傾向的影響,如unigram、bigram等常用的詞袋特征[3]、語法特征[7]、語義特征[4]、組合特征[7]及否定特征[13]。
近年來,深度學(xué)習(xí)方法在情感分類研究領(lǐng)域也取得了相當(dāng)進(jìn)展。國外Kim等人采用卷積神經(jīng)網(wǎng)絡(luò)(CNN)實現(xiàn)了情感分析和問題分類等任務(wù),得到了較好效果[5]。國內(nèi)朱少杰通過引入遞歸自編碼模型(RAE)對微博文本進(jìn)行了情感分類[6]。
經(jīng)過多年研究,研究者們提出了應(yīng)對情感分類任務(wù)的不同粒度的特征提取方法。基于詞性組合規(guī)則提取短語特征,進(jìn)而確定句子情感傾向的方法在英文和中文文本情感分類領(lǐng)域已得到了相當(dāng)深入的研究,其有效性亦得到證明。
Turney[2]在對電影評論語料進(jìn)行詞性標(biāo)注的基礎(chǔ)上,根據(jù)一些預(yù)先定義的模板抽取每條評論中由副詞和形容詞構(gòu)成的兩詞短語,進(jìn)而借助PMI-IR算法計算其情感傾向,最后通過每條評論中所有兩詞短語的平均情感傾向來計算評論的傾向值。Agarwal[3]擴充了Turney的規(guī)則,加入動詞的搭配規(guī)則,提取了更多情感豐富的短語,在電影評論語料的情感分類任務(wù)中取得了更佳的分類效果。考慮到Turney 和Agarwal的工作是通過手工方式對詞性組合規(guī)則進(jìn)行總結(jié),需要語言學(xué)領(lǐng)域知識的支撐,Mukras[7]通過IG、CHI、DF等特征選擇方法對語料中所有的詞性組合規(guī)律進(jìn)行篩選,并從中選取排在前列的、能夠表達(dá)豐富情感傾向的若干詞性組合規(guī)則,進(jìn)而提取符合規(guī)則的兩詞短語。
在維吾爾文情感分類研究中,田生偉等人使用unigram、bigram、trigram 等特征,通過文檔頻率、卡方檢驗、信息增益等特征選擇方法,以及樸素貝葉斯、支持向量機、最大熵等分類算法對維吾爾文文本情感分類進(jìn)行了研究,發(fā)現(xiàn)unigram特征在5 000個特征上使用支持向量機算法時的性能最佳[14]。熱依萊木·帕爾哈提等人從自己構(gòu)建的小規(guī)模語料庫中提取了區(qū)分性單詞作為特征,并對語料進(jìn)行了兩類分類[15]。阿不都薩拉木·達(dá)吾提等人把這些區(qū)分性單詞與情感詞典結(jié)合起來進(jìn)一步改善了分類效果[16]。李敏等人利用棧式自編碼神經(jīng)網(wǎng)絡(luò)對維吾爾文情感分類進(jìn)行了研究,得到了比傳統(tǒng)機器學(xué)習(xí)算法更高的準(zhǔn)確率[17]。李冬白等人先通過Word2Vec得到每個單詞的向量表示,再將詞向量與詞性特征線性組合起來,利用棧式自編碼算法實現(xiàn)了從大規(guī)模無標(biāo)注隱式情感文本中自動學(xué)習(xí)特征的方法,并通過softmax分類器完成了對維吾爾文文本中隱式情感的自動分類[18]。王樹恒等結(jié)合維吾爾語言特征及其詞語間的情感特征,實現(xiàn)了基于word embedding 和雙向LSTM深度學(xué)習(xí)的維吾爾文情感分類模型,其實驗結(jié)果好于RNN、CNN和SVM等分類器的分類結(jié)果[19]。
2 維吾爾文情感語料庫
目前在維吾爾文情感分類研究領(lǐng)域尚不存在通用的情感語料庫和情感詞典。研究者們通常利用自行構(gòu)建的小型語料庫和詞典進(jìn)行實驗。本文從天山網(wǎng)(維文版)[注]http://uy.ts.cn/上下載新聞文本并進(jìn)行了標(biāo)注。由于本文實驗只考慮正、負(fù)兩種分類情況,因此從語料庫中選擇了6 250條正面語料和6 250條負(fù)面語料進(jìn)行分類實驗。在特征提取之前對其進(jìn)行了分句、分詞、詞干提取、詞性標(biāo)注、停用詞[注]由本文作者構(gòu)建,包含1 241個維吾爾文停用詞表。過濾等預(yù)處理。分句則根據(jù)標(biāo)點符號來完成,由于在維吾爾文中一般按空格分詞,因此不需要使用特殊的分詞方法。本文采用“維文詞法分析器[注]由新疆大學(xué)多語種重點實驗室提供,是一個集詞干提取、詞性標(biāo)注功能為一體的工具。”對情感語料進(jìn)行了詞干提取和詞性標(biāo)注,以下為通過“維文詞法分析器”對一條維吾爾文句子進(jìn)行處理后的結(jié)果:
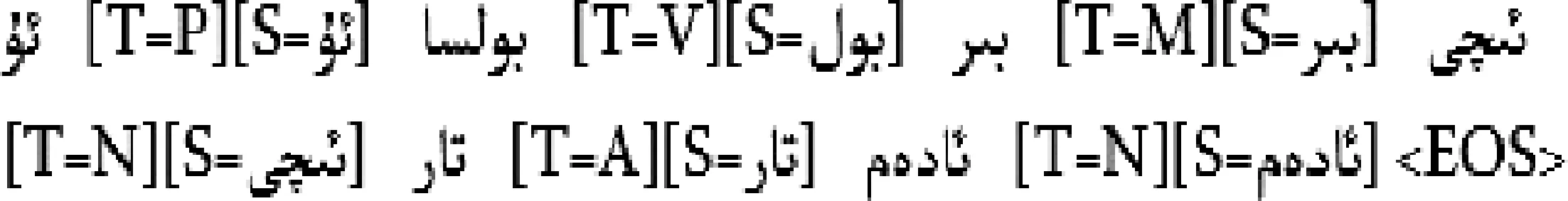
(他是一個小心眼的人)
其中“T=”表示詞性;P表示代詞;V表示動詞;M表示數(shù)詞;N表示名詞;A表示形容詞;D表示副詞;E表示嘆詞。方括號外面的是單詞原型,“S=”表示單詞的詞根。
3 本文情感特征的提取
3.1 Bi-tagged特征
通常,傳統(tǒng)的基于n-gram(n≥2)的特征提取方法會產(chǎn)生高維度的特征向量,高維數(shù)據(jù)不但增大分類難度,而且會延長分類時間。本文參考文獻(xiàn)[2-3]中的方法,通過對維吾爾文情感標(biāo)注語料庫進(jìn)行深入分析,總結(jié)了若干詞性組合規(guī)則,從文本中提取了符合規(guī)則的、具有先后順序的兩個單詞所構(gòu)成的短語,并將其命名為Bi-tagged特征,其有兩種形式: 由原詞匯構(gòu)成的原詞Bi-tagged特征(Fbi-tag)和由經(jīng)過詞干提取后的單詞構(gòu)成的詞干Bi-tagged特征(Fsbi-tag)。
與文獻(xiàn)[2-3]所使用的方法的差異包括以下兩點: ①本文所提取的Bi-tagged特征將名詞、動詞、形容詞、副詞、嘆詞等可能表達(dá)情感信息的所有詞性都考慮在內(nèi); ②提取Bi-tagged特征時,本文首先對以上詞性在本文數(shù)據(jù)集中所有可能出現(xiàn)的組合進(jìn)行統(tǒng)計,并按每種組合在文檔中出現(xiàn)的次數(shù),按從高到低的順序進(jìn)行排列,排列結(jié)果如表1所示。
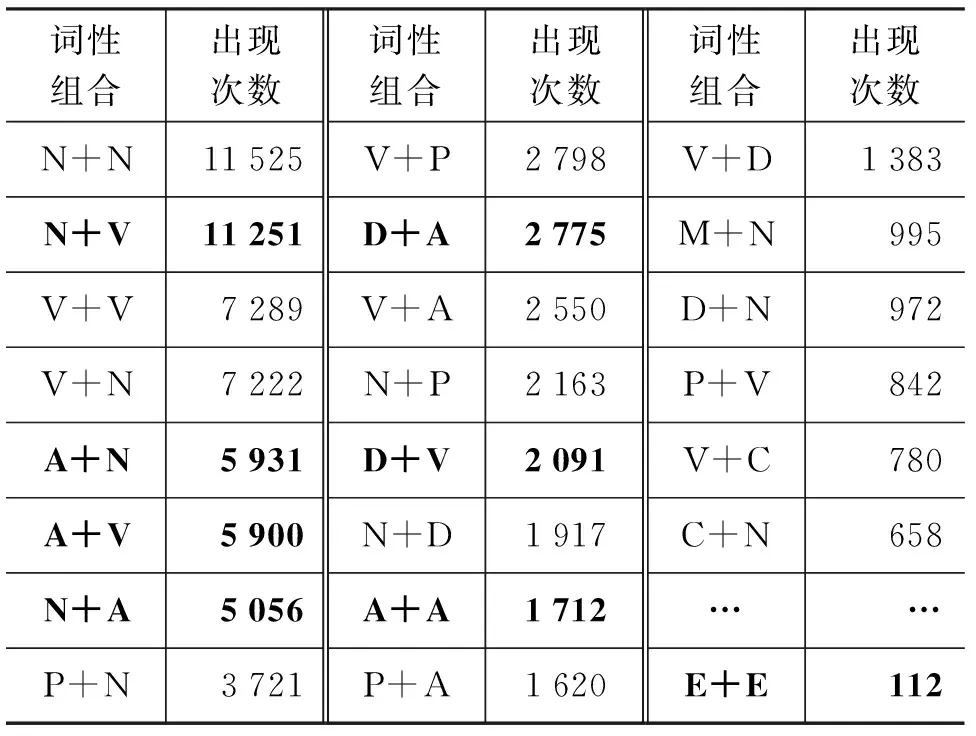
表1 不同詞性組合在本文語料上的出現(xiàn)次數(shù)

表2 Bi-tagged特征詞性組合規(guī)則
然后對表1中那些表達(dá)情感的可能性較低的組合(例如,N+N、V+V等)和不符合維吾爾文詞性搭配規(guī)則的組合(V+D、V+C等)予以排除,將剩余部分(加粗表示)作為Bi-tagged特征詞性組合規(guī)律,結(jié)果如表2所示。
3.2 Bi-tagged和unigram特征的組合
雖然unigram特征簡單有效,但卻忽略了詞匯之間的語義相關(guān)性。另一方面,雖然bigram、Bi-tagged等詞組特征能提高語義含量,但卻降低了特征向量的統(tǒng)計質(zhì)量,讓特征變得更加稀疏,使機器學(xué)習(xí)算法難以從中提取用于分類的統(tǒng)計特性。由于上述缺點的影響,采用這些特征獲得的情感分類結(jié)果不如采用unigram特征的理想[20-21]。針對該問題,本文根據(jù)Agarwal 等人的研究路線[20],對unigram特征和Bi-tagged特征進(jìn)行組合。
與以往工作[20]不同的是,本文對特征進(jìn)行組合時,設(shè)計了一個組合比例控制參數(shù)α。α=[0.1,0.2,0.3,0.4,…,0.9],而后按照不同的組合比例對兩種特征進(jìn)行組合,從而確定每一種特征在組合特征中的重要程度。其中α是指Bi-tagged特征在組合特征總體中所占的比例。例如,組合特征總數(shù)為N時,Bi-tagged特征數(shù)Nbi-tag=N×α ,unigram特征數(shù)Nuni=N-Nbi-tag,即用Nuni個unigram特征和Nbi-tag個Bi-tagged特征進(jìn)行組合。圖1展示了unigram特征(Fsuni)和Bi-tagged特征(Fsbi-tag)的組合特征Fsuni-bi-tag的形成過程。
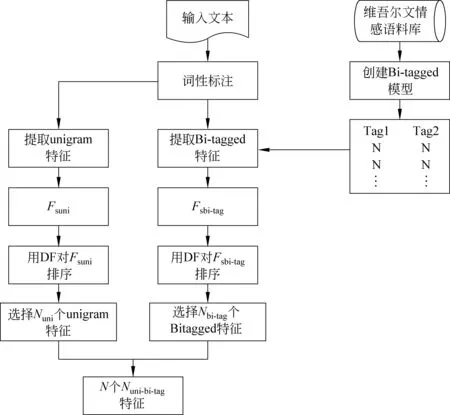
圖1 組合特征的形成過程
3.3 Bi-tagged特征中的否定信息
現(xiàn)代維吾爾語的否定范疇由單純否定詞(yaq, yoq, emes)、派生否定詞(bi, na, siz, bed)和否定構(gòu)型語素(ma, me, mi)構(gòu)成[22]。與英文和中文不同的是,在維吾爾文語句中否定詞的出現(xiàn)并不總是逆轉(zhuǎn)其原有的情感傾向,還可以是對原有情感的一種加強或者減弱。例如:
Men Hoshalliklirimni eytip tügütalmayman.
(我說不完自己的喜悅。)
該句子中否定詞的出現(xiàn)增強了負(fù)面情感。通過對維吾爾文情感標(biāo)注語料庫中包含否定詞的大量句子進(jìn)行詳細(xì)分析,作者發(fā)現(xiàn),只有結(jié)合上下文考慮否定詞,才能正確判斷其對情感傾向的影響。
本文所提出的Bi-tagged特征詞性組合規(guī)則中,包括以下兩種可以提取包含否定詞的上下文的規(guī)則。
(1) 形容詞 + emes (A+V)
Bügün keypiyatim peqet yaxshi(A)emes(V)
(今天心情不太好)
形容詞 + 動詞的否定 (A+V)
Bügün imtihanni yaxshi(A)bёrelmidim(V)
(今天的考試我考得不好)
(2) 名詞 + emes (N+V)
B? biz oylighan netije(N)emes(V)
(這不是我們想要的成績)
4 實驗及結(jié)果分析
4.1 實驗工具及評價標(biāo)準(zhǔn)
本文選擇SVM作為分類器(采用線性核函數(shù)及默認(rèn)參數(shù)設(shè)置)。采用DF特征選擇方法和TF-IDF特征權(quán)重方法進(jìn)行了維吾爾文文本的正、負(fù)情感分類。為了得到更加真實的結(jié)果,實驗中采用了五折交叉驗證方法,即把數(shù)據(jù)集分成五個子集(每個子集包含1 250個句子),每一輪將其中一個子集作為測試集,其余子集作為訓(xùn)練集,總共執(zhí)行五輪,將得到的結(jié)果取平均值作為最后結(jié)果。
文本情感分析的性能指標(biāo)與文本分類的性能指標(biāo)相同。主要有正確率(precision)、召回率(recall)、F1值和準(zhǔn)確率(accuracy)等。表3為計算評價指標(biāo)所用的混淆矩陣。
表3中,TP表示將正面文檔正確地分類為正面的文檔數(shù),F(xiàn)N表示將正面文檔錯誤地分類為負(fù)面的文檔數(shù),F(xiàn)P表示將負(fù)面文檔錯誤地分類為正面的文檔數(shù),TN表示將負(fù)面文檔正確地分類為負(fù)面的文檔數(shù)。總文檔數(shù)目為=TP+FP+TN+FN。
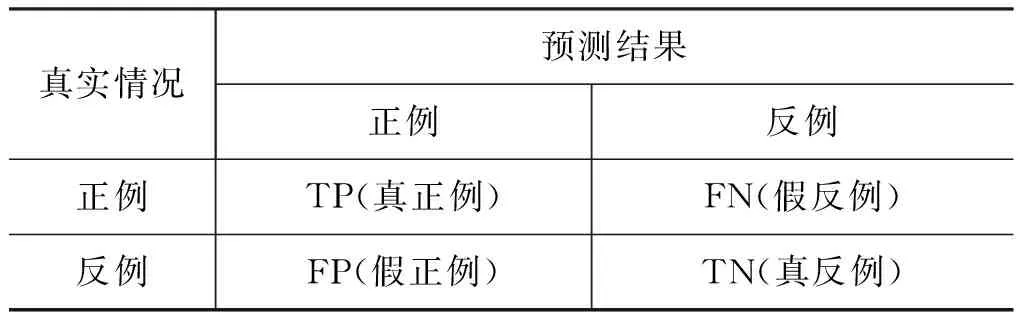
表3 分類結(jié)果混淆矩陣
正確率(Precision)是指被分類器判別為某個類別的文本中實際屬于該類別的文本所占的比例,其計算公式如式(1)。
召回率(Recall)是指實際屬于某個類別的文本中被分類器判別為該類別的文本所占的比例,其計算公式如式(2)。
正確率和召回率往往是負(fù)相關(guān)的關(guān)系,衡量意義不大。因此通常需要引入一個綜合評價指標(biāo)——F1值來對P和R進(jìn)行調(diào)和。F1值的計算公式如(3)。
由于F1是對某一個單一類別C的評價指標(biāo),為了得到正面和負(fù)面語料分類的綜合指標(biāo),本實驗選取了F1值的宏觀平均值,其計算公式如式(4)。
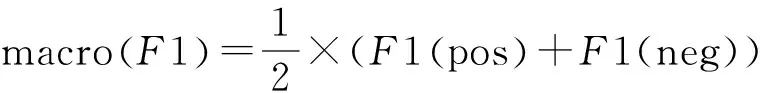
其中,F(xiàn)1(pos)是正面語料的F1值,F(xiàn)1(neg)是負(fù)面語料的F1值。
還有一個常用的評價指標(biāo)——精確率(準(zhǔn)確率,accuracy),可針對所有類別中的所有樣本,表示所有測試樣本中被正確分類的比例,對應(yīng)的計算公式如式(5)。
Acc=(TP+TN)/(TP+TN+FP+FN)
(5)
4.2 Bi-tagged特征中不同詞性組合對分類結(jié)果的影響分析
為了驗證Bi-tagged特征中每一種詞性組合規(guī)則的有效性,本文分別設(shè)計以下幾組Bi-tagged特征對語料進(jìn)行了情感分類。特征FAD只包含形容詞和副詞的組合規(guī)則;FV在FAD的基礎(chǔ)上增加動詞的組合規(guī)則;FN在FV的基礎(chǔ)上增加名詞的組合規(guī)則。FE在FN的基礎(chǔ)上增加嘆詞的組合規(guī)則。
在實驗過程中,首先通過DF特征選擇方法對提取特征進(jìn)行排序(文檔頻率值從大到小),之后從經(jīng)過排序的特征中依次選取10%~100%的特征,在不同規(guī)模的特征上進(jìn)行分類實驗。圖2為基于四種特征的分類MacroF1值,圖3為分類準(zhǔn)確率。
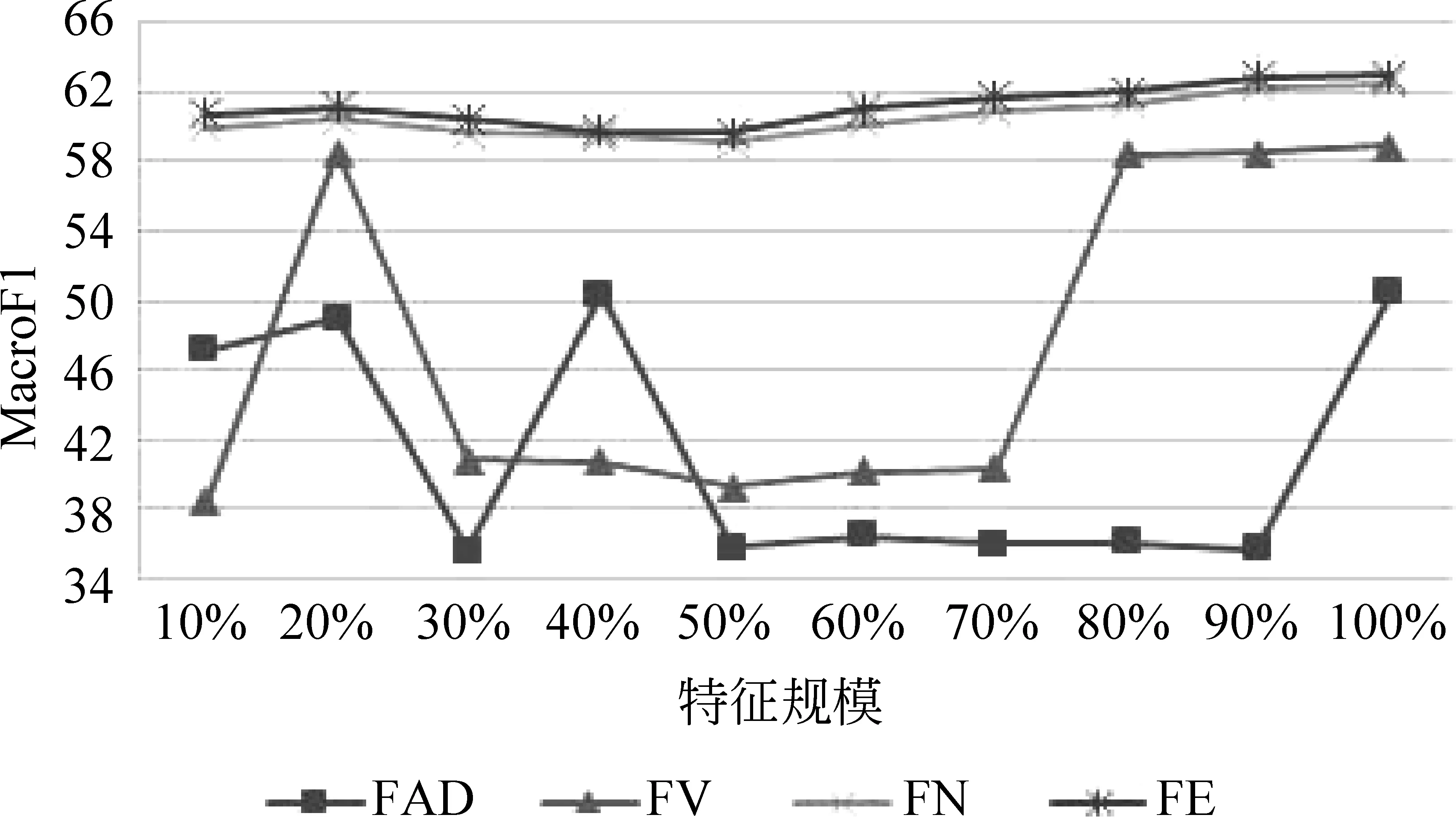
圖2 不同Bi-tagged特征下的MacroF1值
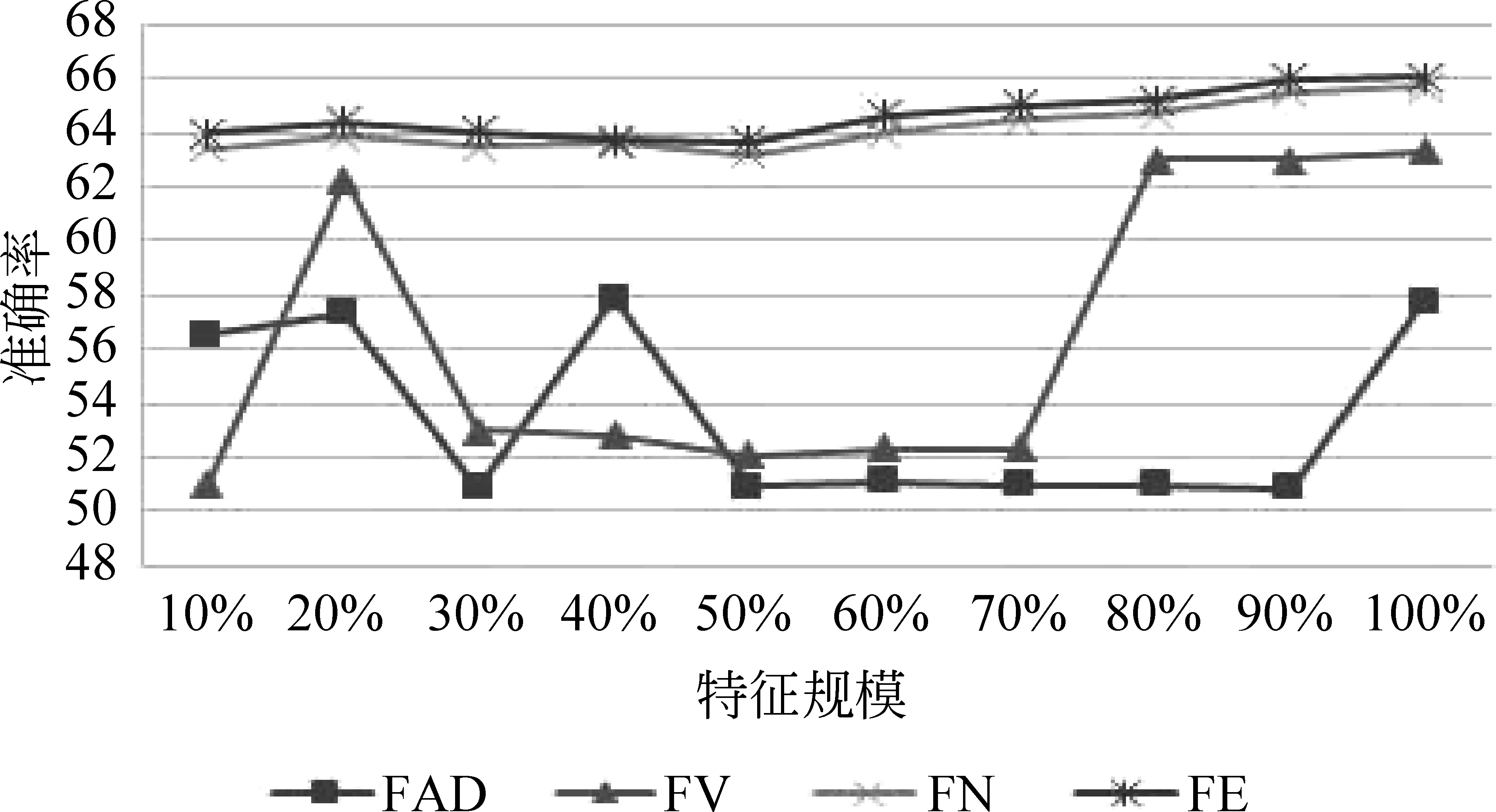
圖3 不同Bi-tagged特征下的準(zhǔn)確率
圖2和圖3中的結(jié)果顯示,這四組特征中FAD表現(xiàn)最差,最高M(jìn)acroF1值和準(zhǔn)確率分別為50.481%和57.743%。在此基礎(chǔ)上加入動詞的組合規(guī)則后,對應(yīng)值分別有了8.445%和5.562%的提高。在FV的基礎(chǔ)上加入名詞的組合規(guī)則后分類結(jié)果又有了3.562%(MacroF1)和2.401%(Acc)的提高。圖中,F(xiàn)E的分類結(jié)果略優(yōu)于FN的結(jié)果,MacroF1值和準(zhǔn)確率比FN分別提高了0.516%和0.36%。FE特征比FN特征只多出22個特征,在如此少的特征數(shù)上所得到的提高率可以納入考量。
以上實驗結(jié)果證明,本文所提取的Bi-tagged特征中,每一種詞性組合規(guī)則都對分類任務(wù)有積極貢獻(xiàn)。
4.3 Bi-tagged特征頻率對分類結(jié)果的影響分析
為了驗證Bi-tagged特征在文本中出現(xiàn)的頻率對情感傾向性的影響,本文根據(jù)Bi-tagged特征在文檔中出現(xiàn)的頻率對其進(jìn)行過濾。用FN1表示頻率大于等于1的Bi-tagged特征,F(xiàn)N2表示頻率大于等于2的Bi-tagged特征,以此類推。基于不同頻率的Bi-tagged特征的分類MacroF1值如圖4所示,準(zhǔn)確率如圖5所示。
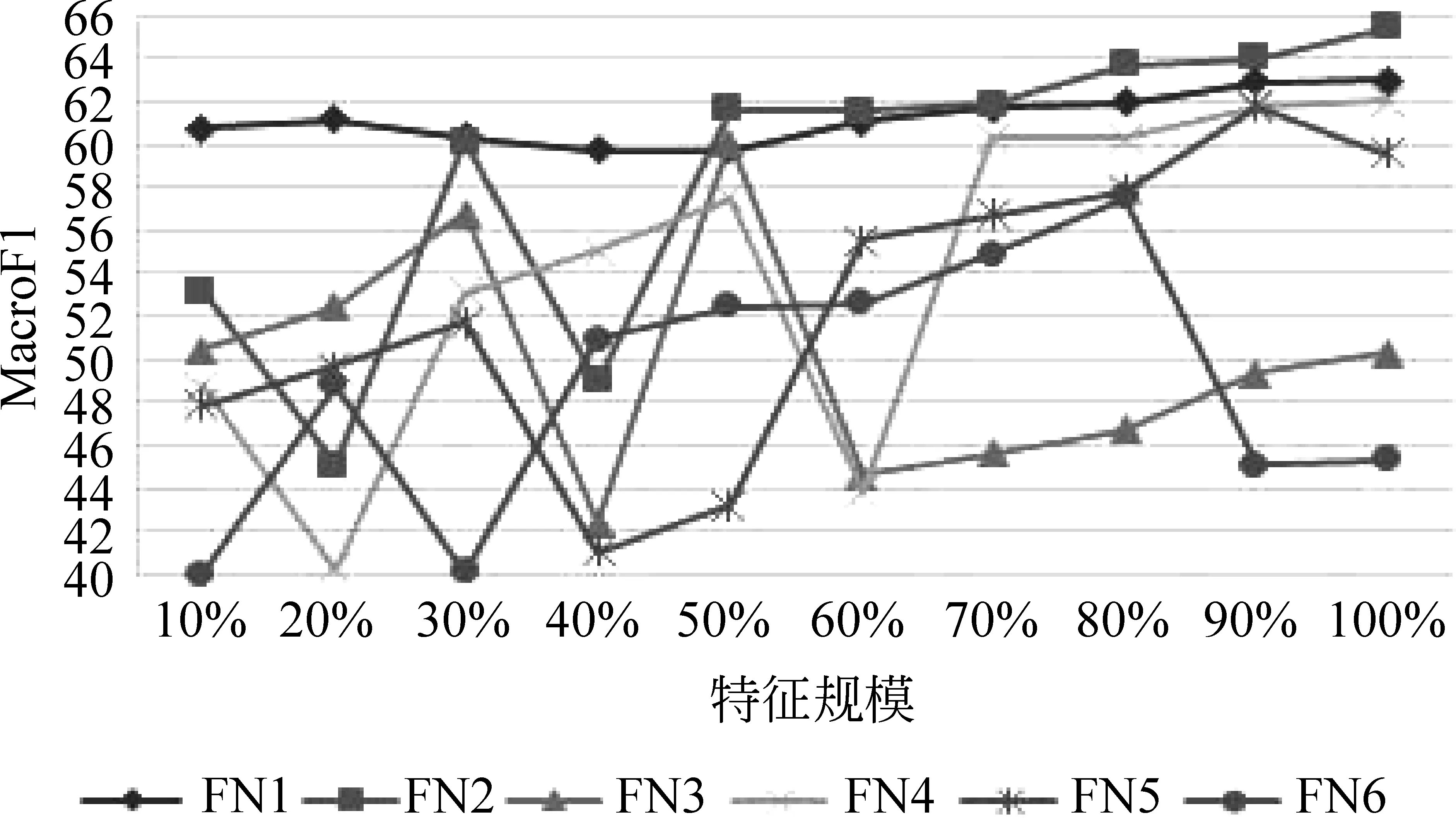
圖4 不同頻率的Bi-tagged特征分類MacroF1值

圖5 不同頻率的Bi-tagged特征分類準(zhǔn)確率
從圖4和圖5可知,F(xiàn)N3到FN6特征的分類結(jié)果非常不穩(wěn)定,主要原因是頻率越大特征數(shù)越少,數(shù)據(jù)稀疏問題較為嚴(yán)重,導(dǎo)致分類質(zhì)量的下降和效果的不穩(wěn)定。而FN1和FN2特征較其他特征穩(wěn)定,并取得了較好的分類效果。當(dāng)特征數(shù)達(dá)到總特征的50%后,F(xiàn)N2的結(jié)果優(yōu)于FN1,這種優(yōu)勢隨特征數(shù)的增加而愈益顯著。例如,當(dāng)FN2取所有特征時(3 101個特征)可以得到最高的MacroF1值65.433%和準(zhǔn)確率67.947%,分別比FN1(20 847個特征)的分類結(jié)果提高了2.429%(MacroF1)和1.881%(Acc)。因此在語料規(guī)模較大的情況下,取頻率大于等于2的Bi-tagged特征可以進(jìn)一步提高分類效率。
4.4 Bi-tagged特征對否定信息的處理功能
為了驗證在Bi-tagged特征下“A+V”“N+V”兩種規(guī)則能否提取否定信息,本文對上述兩種詞性組合規(guī)則在本文情感語料中所提取的Bi-tagged特征規(guī)模與其中包含的否定信息覆蓋率進(jìn)行統(tǒng)計,統(tǒng)計結(jié)果如圖6所示。

圖6 語料中提取的Bi-tagged特征及其中包含的否定短語
圖6顯示,在本文情感語料庫上按“A+V”“N+V”兩種詞性規(guī)則所提取的Bi-tagged特征中,否定特征占總特征的21%。若用絕對數(shù)表示,則為: 從該語料中總共提取了14 235個符合以上兩種規(guī)則的Bi-tagged特征,其中2 989個特征包含否定信息。
為了進(jìn)一步驗證基于上述兩種規(guī)則所提取的Bi-tagged特征對維吾爾文情感分類任務(wù)的影響,本文設(shè)計了兩組特征: 包含所有規(guī)則的Bi-tagged特征FSbi-tag和其中去除以上兩種規(guī)則后的Bi-tagged特征FNo。
從本文情感語料庫中選擇所有包含否定詞的句子構(gòu)成否定詞情感語料集,其中正面語料748個,負(fù)面語料1 277個。在該語料集上提取兩種特征進(jìn)行分類實驗。圖7為分類MacroF1值和準(zhǔn)確率。
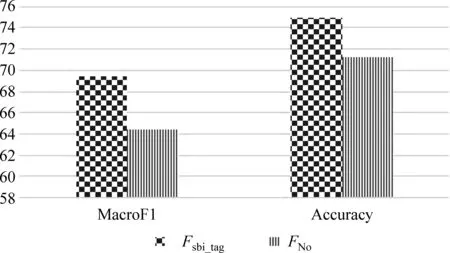
圖7 Bi-tagged特征對否定信息的處理分析
在分類過程中使用FNo特征時,分類MacroF1值為64.371、分類準(zhǔn)確率為71.287,比FSbi-tag特征的對應(yīng)值分別下降了5.015%和3.713%。實驗結(jié)果證明: 本文所提取的Bi-tagged特征,不僅能提取上下文中的豐富情感信息,而且還可以提取否定信息。
4.5 Bi-tagged特征與傳統(tǒng)詞袋特征的分類結(jié)果比較
為了對比本文提取的Bi-tagged特征與傳統(tǒng)n-gram特征的分類效率,本文從預(yù)處理后的維吾爾文情感語料中讀取每一個單詞的原形、詞干和詞性信息,得到unigram、bigram和Bi-tagged特征的集合{Funi,F(xiàn)suni,F(xiàn)bi,F(xiàn)sbi,F(xiàn)bi-tag,F(xiàn)sbi-tag}(為了得到最佳的分類效率,對每一種特征的原詞和詞干進(jìn)行分類)。采用DF特征選擇方法從其中選擇前10 000個特征,特征數(shù)從1 000開始,每次遞增1 000個特征(Fsbi-tag取所有特征)。實驗結(jié)果如表4所示,表中給出了正面和負(fù)面語料上的最高F1值、MacroF1值、準(zhǔn)確率和取得最高成績的特征數(shù)。
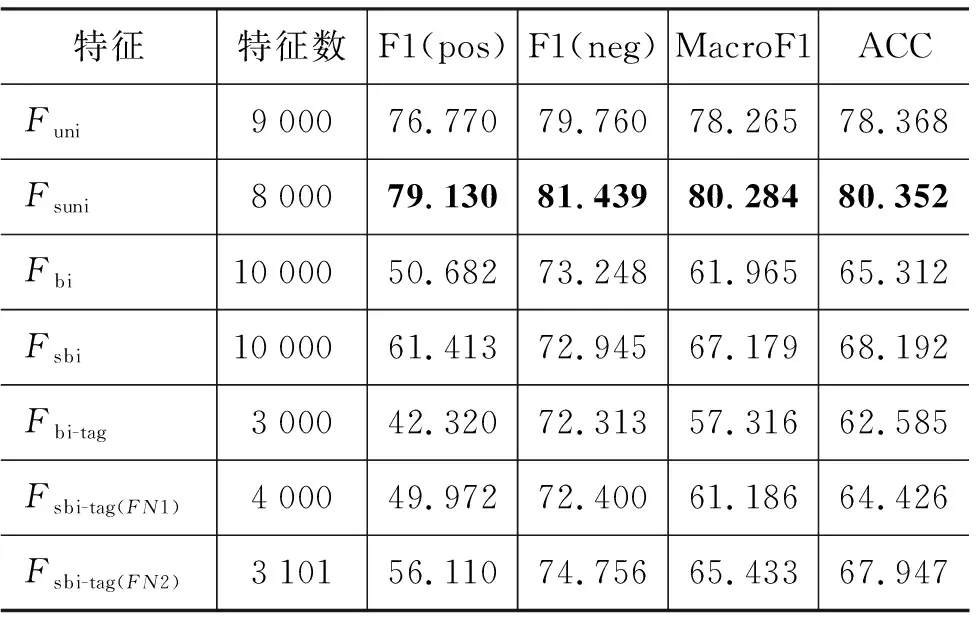
表4 SVM在不同特征上的分類結(jié)果
從實驗結(jié)果可知,所有特征詞干提取后的分類效率都比原詞特征的分類效率高。在維吾爾文情感分類任務(wù)中詞干提取對特征分類結(jié)果有積極的貢獻(xiàn): 詞干提取可以縮小特征空間的維度。本實驗所提取的幾種特征在詞干提取前后的數(shù)量對比如表5所示。
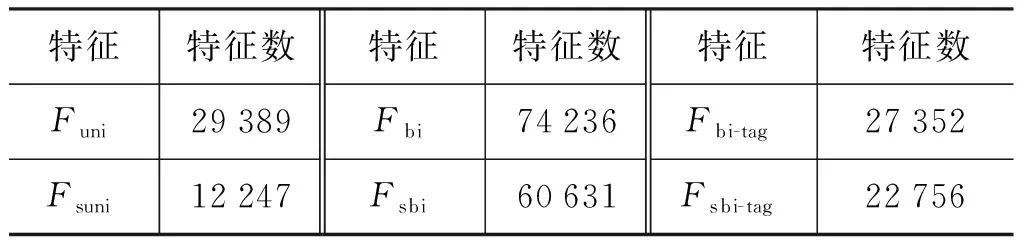
表5 詞干提取前后的特征數(shù)對比
從表5可知,詞干提取后的特征數(shù)與原詞特征數(shù)相比有了大幅度的減小。因此,詞干提取可以有效地解決維吾爾文文本情感分類過程中的維數(shù)災(zāi)難問題。
詞干提取可以提高分類準(zhǔn)確率,圖8展示了表4中的三種特征在詞干提取前后的分類準(zhǔn)確率對比。豎線條柱狀圖表達(dá)原詞特征(origin)上的分類準(zhǔn)確率;橫條柱狀圖表達(dá)詞干提取后的特征(stem)上的分類準(zhǔn)確率。
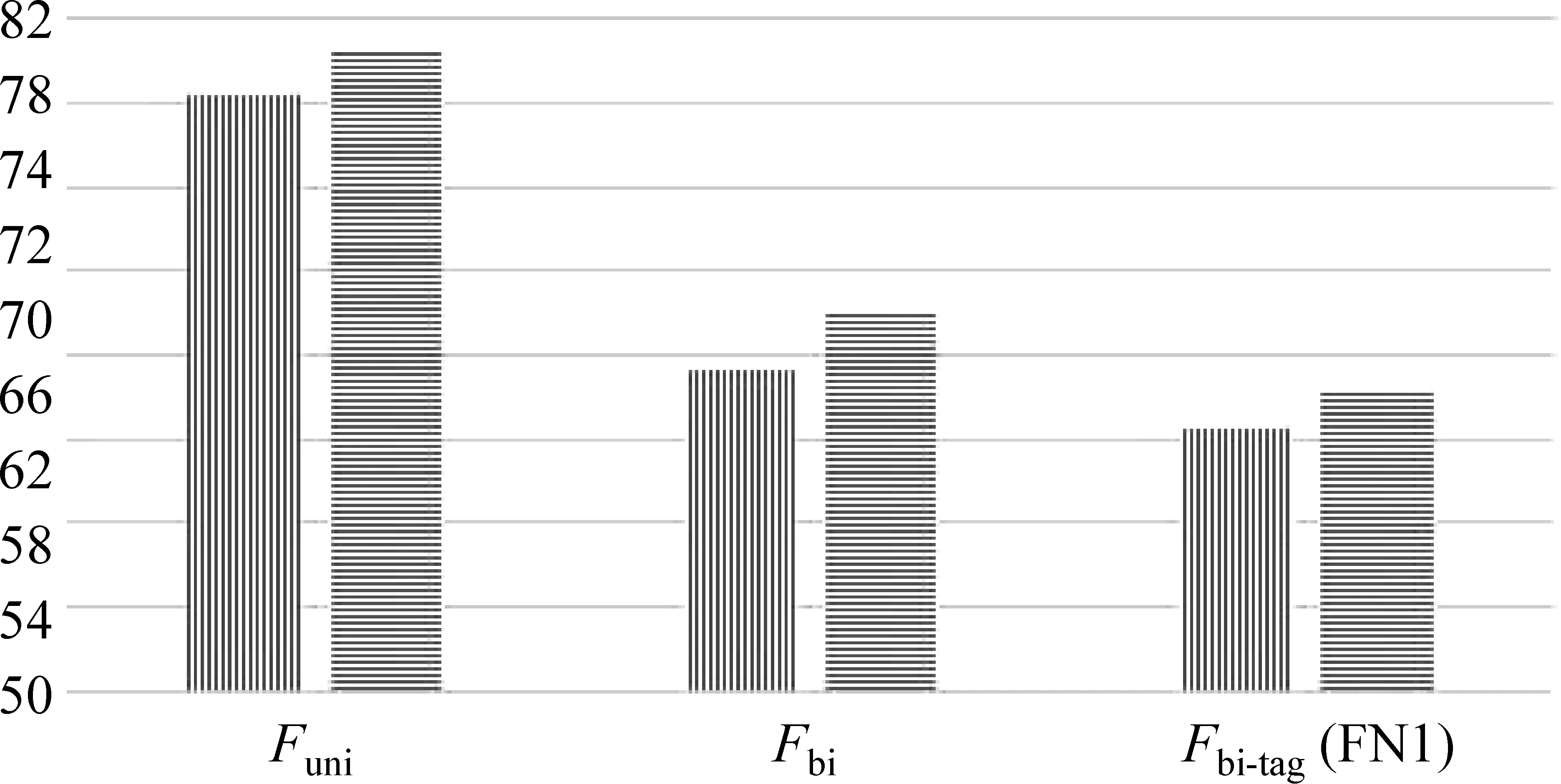
圖8 不同特征在詞干提取前后的結(jié)果對比
從圖8可知,對每一種特征,提取詞干后得到的分類效果優(yōu)于在原詞特征上的分類效果,數(shù)值提高幅度約為1%至3%。
從表4、圖8可以看出,在三種特征上的分類結(jié)果中,unigram特征上的分類效果最佳,所取得的最高分類準(zhǔn)確率為80.352%。本文所提取的Bi-tagged特征(頻率大于等于2)能夠在相對較少的特征維數(shù)上取得與bigram特征相當(dāng)接近的分類準(zhǔn)確率。例如,詞干提取后的bigram特征在10 000個特
征上所得到的分類準(zhǔn)確率為68.192%,而Bi-tagged特征在3 101個特征(約占bigram特征的31%)上所得到的分類準(zhǔn)確率為67.947%,與bigram的分類準(zhǔn)確率只相差0.245%。
4.6 Unigram與Bi-tagged的組合特征的分類結(jié)果分析
為了驗證組合特征對維吾爾文文本情感分類性能的影響,本文分別對Fsuni和Fsbi-tag(FN1)進(jìn)行組合,形成了Fsuni-bi-tag-1組合特征,對Fsuni和Fsbi-tag(FN2)進(jìn)行組合,形成了Fsuni-bi-tag-2組合特征(由于詞干提取后的特征性能優(yōu)于原詞特征性能,因此對詞干提取后的特征進(jìn)行組合)。而后基于兩種組合特征進(jìn)行了維吾爾文情感語料的正、負(fù)二元情感分類。為了更為客觀地評價本文組合特征的效率,本文以同樣方法對Fsuni和Fsbi進(jìn)行組合,形成了Fsuni-bi組合特征,進(jìn)而將其分類結(jié)果與本文所提出的兩種組合特征的結(jié)果進(jìn)行比較。在基于組合特征的實驗中,特征總數(shù)從1 000增加到10 000,α從10%增加到50%。基于組合特征的分類準(zhǔn)確率如圖9~圖11 所示。
為了便于對比,本文將unigram特征Funi的分類準(zhǔn)確率78.368%作為實驗的Baseline值。
在基于組合特征Fsuni-bi的實驗中(見圖9),當(dāng)特征數(shù)為10 000、bigram占20%時,SVM達(dá)到最高的分類準(zhǔn)確率80.634%,比Baseline提高了2.266%。
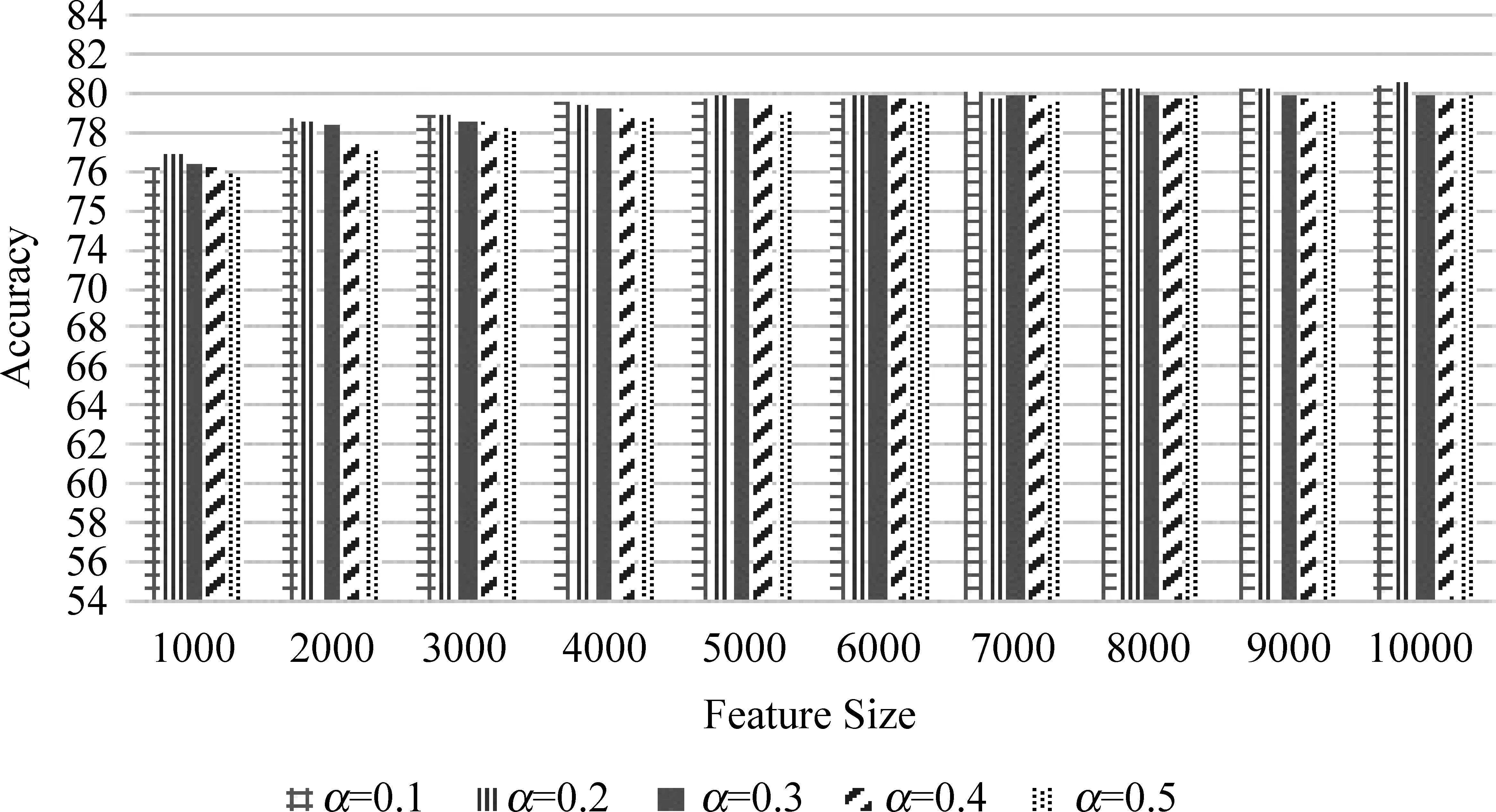
圖9 基于組合特征Fsuni-bi的分類準(zhǔn)確率

圖10 基于組合特征Fsuni-bi-tag-1的分類Accuracy
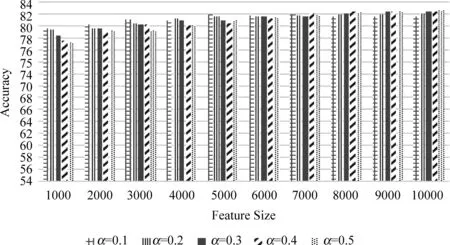
圖11 基于組合特征Fsuni-bi-tag-2的分類Accuracy
在基于組合特征Fsuni-bi-tag-1的實驗中(圖10),當(dāng)特征數(shù)為5000、Bi-tagged占10%時,分類器取得最高的準(zhǔn)確率81.993%,比Baseline提高了3.625%,比Fsuni-bi的最高準(zhǔn)確率提高了1.359%。在該組合特征中,當(dāng)特征總數(shù)超過2 000后,無論Bi-tagged特征的比例如何,分類準(zhǔn)確率均高于Baseline值。
在基于組合特征Fsuni-bi-tag-2的實驗中(圖11),分類準(zhǔn)確率值隨著特征數(shù)的增加而提高,當(dāng)特征總數(shù)為10 000、Bi-tagged特征占50%時,準(zhǔn)確率達(dá)到最高值82.593%,比Baseline提高了4.225%,比Fsuni-bi和Fsuni-bi-tag-1分別提高了1.959%和0.6%。當(dāng)特征總數(shù)超過8 000后,Bi-tagged特征的作用更加明顯。隨著Bi-tagged特征占比的增加,分類準(zhǔn)確率值也隨之提高。
本文組合特征上的實驗結(jié)果證明,對unigram特征與包含上下文語義信息的詞組特征進(jìn)行組合,可以有效地克服這些特征各自存在的不足之處,并能得到比單獨使用其中某個特征更佳的分類結(jié)果。組合特征的作用是: 當(dāng)unigram特征呈現(xiàn)數(shù)據(jù)稀疏的時候,詞組特征能夠提取一些情感豐富的上下文信息,對unigram特征起到補充作用。本文分類實驗中,F(xiàn)uni-bi-tag組合特征的分類效果優(yōu)于Funi-bi組合特征的分類效果。這主要是因為Bi-tagged特征可以刪除bigram特征中的很多噪聲特征。
表6中列出了采用DF特征選擇方法從本文情感語料集中提取的前10個bigram特征以及Bi-tagged特征。
表6中,提取的bigram特征包含“Bol ?”“Qil ?”“Ket ?”等不表達(dá)任何語義信息的兩詞短語。前10
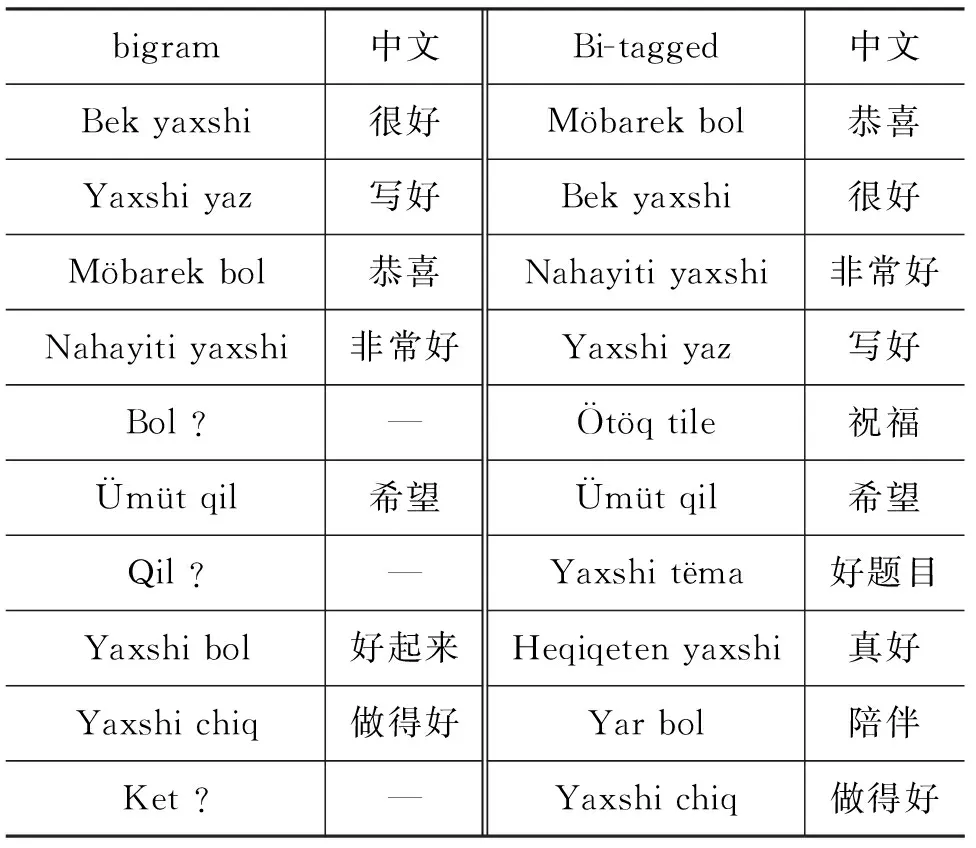
表6 前10個bigram特征和Bi-tagged特征
個特征中的三個不表達(dá)任何語義信息。而Bi-tagged特征能夠提取文本中語義完整的兩詞短語,表中展示的前10個Bi-tagged特征不僅表達(dá)完整的語義信息,而且?guī)в忻鞔_的情感傾向。可見,Bi-tagged特征能夠刪除bigram特征中的很多無用特征,并且能夠提取結(jié)構(gòu)穩(wěn)定、語義完整的上下文信息。因此,對unigram特征與Bi-tagged特征進(jìn)行組合,可以得到比unigram與bigram的組合特征更佳的分類效果。
5 總結(jié)與展望
通過對維吾爾文情感語料的深入分析,本文提出了Bi-tagged特征詞性組合規(guī)則,并通過對比實驗證明: 本文所提出的Bi-tagged特征詞性組合規(guī)則是有效的;采用Bi-tagged特征中頻率大于等于2的特征,可以進(jìn)一步提高基于該特征的維吾爾文情感分類效果;Bi-tagged特征不僅能夠用于提取包含豐富情感信息的兩詞短語,而且還可以用于提取包含否定信息的兩詞短語;對unigram特征與Bi-tagged特征進(jìn)行組合,可以進(jìn)一步提高維吾爾文文本情感分類效率。
本文所涉及的Bi-tagged特征是基于詞性搭配規(guī)則提取具有先后順序和相鄰關(guān)系的兩個詞所組成的特征,目前無法實現(xiàn)以包含兩個以上單詞的語句為單元進(jìn)行情感分類,并且無法解決長距離的情感問題。今后的工作將著重研究如何通過拓展詞組特征長度及利用長距離詞匯之間的依賴關(guān)系提高情感分類效率。同時把本文所提取的Bi-tagged特征與深度學(xué)習(xí)模型的詞向量特征進(jìn)行融合,并將融合特征作為輸入特征去評價其在完成基于深度學(xué)習(xí)模型的維吾爾文文本情感分類任務(wù)中的性能。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
Coco薇(2017年11期)2018-01-03 20:59:57
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
