基于PAD模型的級聯分類情感語音識別
2018-09-21 11:39:18張雪英
太原理工大學學報 2018年5期
張雪英,張 婷,孫 穎,張 衛
(太原理工大學 信息與計算機學院,山西 晉中 030600)
語音作為人類日常交流的主要方式,其中所攜帶的情感信息越來越受到研究者的重視。情感語音識別在人機交互、模式識別和人工智能等領域具有廣泛應用前景,開展情感語音識別研究對于人類社會的進步與發展具有重要意義[1]。在語音情感識別研究中,提高識別率主要有兩個研究方向[2]。一是改進情感語音特征的提取方式或者選取方式;在情感語音識別中,常用的聲學特征一般包括有聲學參數的統計特征、時序特征等[3]。二是改進分類方法或者選取更適合的分類方法;在情感識別方法的研究上,多種模式識別的分類方法均可用于情感識別[4]:如人工神經網絡ANN(artificial neural network)[5]、隱馬爾科夫模型HMM(hidden markov models)、高斯混合模型GMM(gaussian mixture models)、支持向量機SVM(support vector machines)等。相較于其他模式識別算法,SVM是在結構風險最小化原則上建立起來的,而且可以克服小樣本數據和非線性問題,具有良好的情感分類能力。近年來,SVM 被廣泛應用于語音情感識別中,是一種有效的語音情感識別分類器[6]。
本文在TYUT2.0情感語音數據庫的基礎上,提出了聲學特征與情感語音PAD數據相結合的級聯分類方法。首先根據前期PAD標注實驗的數據結果[7],將4類情感中混淆度高的情感按照愉悅度值高低劃分為2類,其次在此基礎上使用SVM識別網絡分別識別高低愉悅度的情感,然后在已區分高低愉悅度的基礎上再次使用SVM識別網絡,最終實現對4種情感的分類,情感分類識別率較傳統僅使用聲學特征的分類識別率提高了15.4%.
1 情感語音數據庫及三維情感模型
1.1 情感語音數據庫
本文采用的太原理工大學數字音視頻技術研究中心前期建立的TYUT2.0情感語音數據庫。該數據庫首先采用截取廣播劇的方式,包含“高興、憤怒、悲傷、驚奇”4種情感類別共237句的摘引型離散情感語音數據庫。后期在原有的離散情感語音數據庫的基礎上,根據PAD三維情感模型,通過心理學實驗的方法對情感語音進行標注,建立了維度情感語音數據庫。該數據庫中每句語音都有對應的PAD值,為后續的識別實驗奠定了數據基礎[7]。
1.2 PAD三維情感模型
情感可以用連續變化的維度表示,情感維度理論通常將不同的情感映射到一個多維空間中的一個點,該點的空間坐標對應標識某一種情感。其中PAD三維情感模型被廣泛認可[8]。該模型由UCLA大學的MEHRABIAN開發,采用語義差異評價方法將情感分為三個維度,它們分別是:反應說話者情感狀態的正負特征的愉悅度P(Pleasure-displeasure);反應說話者神經生理的激活程度是主動的還是被動的激活度A(Arousal-nonarousal);反應說話者對情境和他人的控制欲望強弱的優勢度D(Dominance-submissiveness)。三維情感模型是對情感空間的理論描述,建立了情感空間中不同情緒范疇的定位和關系,使不同的情感可以映射到三維空間中。根據文獻[7]標注實驗得出的PAD數據,將悲傷、憤怒、高興、驚奇4種情感分布在三維情感空間,如圖1所示。
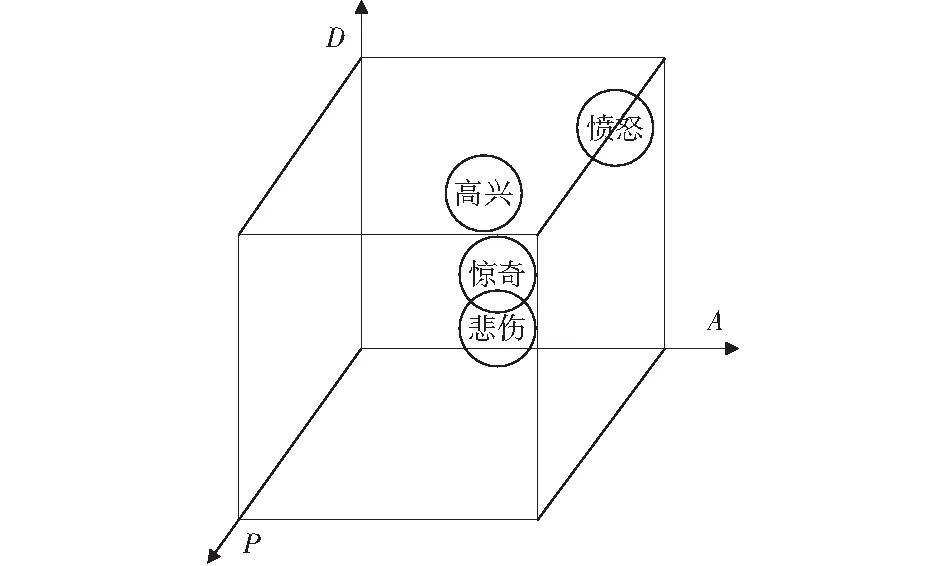
圖1 4種情感狀態在PAD三維情感空間上的分布Fig.1 Distribution of four emotional states in PAD three-dimensional emotional space
2 情感語音特征
采用何種有效的語音特征參數用于情感識別對于語音情感識別研究至關重要,情感語音特征參數的優劣直接決定情感最終識別結果的好壞。目前用于情感語音識別的聲學特征大致可歸納為韻律學特征、基于譜的相關特征和音質特征這3種類型[9]。韻律學特征在情感語音識別領域已經得到研究者的廣泛認可[10]。文獻[11]研究了Mel頻率倒譜系數(mel-frequency cepstrum coefficient,MFCC)和基頻、能量、發音持續時間與三維情感空間之間的關系,結果表明MFCC參數與三維情感空間的相關性最高。所以本文主要提取情感語音的韻律特征和MFCC特征用于情感語音識別。
2.1 韻律特征
韻律特征可以分為3個主要方面:音高、強度以及時間特性。通過測量相應提取輪廓的統計值來獲得特征。 其中平均值、中值、最小值、最大值和方差是最常用的統計值。本文從語音信號中提取了38維韻律特征。對應的韻律特征及統計參數如表1所示。

表1 韻律特征及統計參數Table 1 Prosodic features and statistical parameters
2.2 MFCC特征
MFCC特征是基于人耳聽覺特性提出來的,符合人類的聽覺特性,不僅能很好地度量語音頻譜的能量包絡,同時倒譜運算具有良好的解卷性能,因此MFCC特征廣泛地應用于情感語音識別、說話人識別、音頻和音樂分類方面。基于以上特性,本文提取了MFCC前12階的偏度、峰度、均值、方差、中值共60維特征用于識別實驗。
3 識別實驗
在本節的識別實驗中,首先通過3組對比實驗,分別比較了僅使用韻律特征的分類識別率、僅使用MFCC特征的分類識別率及將2種特征組合的分類識別率。數據庫使用TYUT2.0情感語音數據庫,對“悲傷”、“憤怒”、“高興”、“驚奇”4種情感語音進行分類識別。利用支持向量機SVM[12]識別情感語音采用十折交叉驗證(10-fold cross validation)的測試方法。所有語句被平均分為10份,識別實驗也相應地進行10次,輪流將其中9份作為訓練集,1份作為測試集。取10次實驗結果的正確率的平均值作為識別結果。采用交叉驗證測試方法能夠有效地降低隨機因素的影響 ,提高識別結果的可信度。
3.1 韻律特征分類
單獨運用韻律特征對情感語音進行分類識別,混淆矩陣如表2所示。
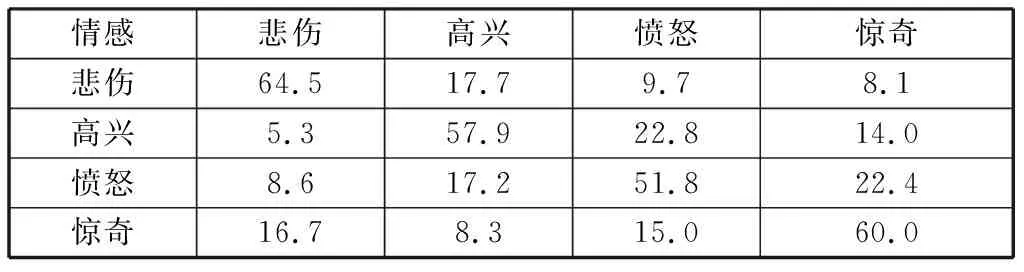
表2 單獨使用韻律特征的情感識別混淆矩陣Table 2 Emotion recognition confusion matrix using prosodic features alone %
整體平均識別率是58.6%,其中“憤怒”的識別率最低,僅達到51.8%.此外,單獨運用韻律特征時,“憤怒—高興”的混淆率、“憤怒—驚奇”的混淆率較高。實驗數據顯示,“悲傷”的識別率最佳達到64.5%;這是由于在TYUT2.0數據庫中,“悲傷”情感語音的發音較為緩慢,并且停頓時間較長,因此語速特征能夠較好的識別“悲傷”情感。
3.2 MFCC特征分類
單獨運用MFCC特征對情感語音進行分類識別,混淆矩陣如表3所示。
整體平均識別率是62.3%.通過實驗可以看到單獨運用MFCC特征,“憤怒”和“驚奇”的識別率得到了明顯提高,“憤怒”識別率提高了10.3%,“驚奇”識別率提高了10%.由此提出假設,MFCC特征中是否包含著一些韻律特征所不包含的特征信息,如果將這2種特征組合是否能提高分類識別率。
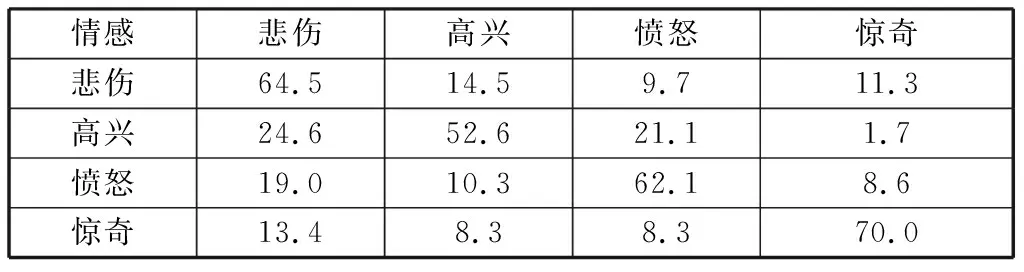
表3 單獨使用MFCC特征的情感識別混淆矩陣Table 3 Emotion recognition confusion matrix using MFCC features alone %
3.3 MFCC和韻律特征組合特征集分類
將MFCC和韻律特征組合進行分類識別,混淆矩陣如表4所示。整體平均識別率達到67.5%.相較于單獨運用韻律特征和MFCC特征,識別率有一定程度的提高。
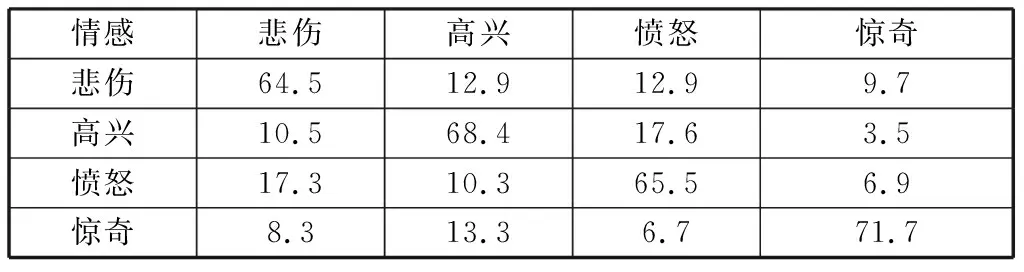
表4 運用韻律特征和MFCC特征組合的情感識別混淆矩陣Table 4 Using prosodic feature and MFCC feature combinationof emotion recognition confusion matrix %
由以上3組實驗可以看出由韻律特征和MFCC特征組合的分類識別率相比之下最好,分析原因是兩種特征的組合減弱了由于單一特征無法全面描述情感信息而導致的識別率低的缺點,在情感識別應用中具有互補性,因此可以在一定程度上提升分類識別結果。韻律特征和MFCC特征的組合特征是后續級聯分類實驗的特征基礎。
3.4 級聯分類
之前的分類識別方法僅僅是將聲學特征簡單地組合在一起,并沒有考慮到哪種類型特征能更好的對情感進行分類識別,文獻[7]中標注實驗得出的4類情感語音的PAD數據如表5所示,可以看出在P(愉悅度)上分數呈現明顯的高低差異,且在此維度上能夠很好的區分“憤怒—高興”和“憤怒—驚奇”這兩組混淆率較高的情感。據此將“悲傷”和“憤怒”2
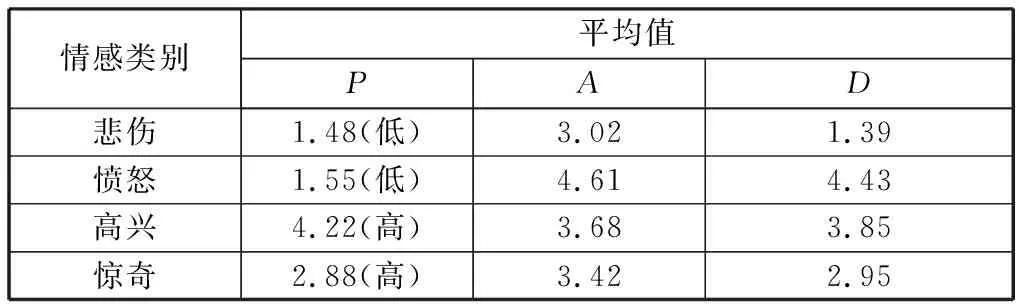
表5 4種情感的PAD值Table 5 PAD value of four types emotion
種情感標記成“低”,“高興”和“驚奇”2種情感標記成“高”。
圖2是級聯分類流程圖,將分類過程分為2個步驟。在第一階段中將“悲傷”、“憤怒”、“高興”、“驚奇”4種情感按照表5的高低分數標注分為兩類:一類為“悲傷”、“憤怒”,這2種情感具有較低的愉悅度;另一類為“高興”、“驚奇”,這兩種情感具有較高的愉悅度。將聲學特征組合與愉悅度情感維度的高低分類相結合,利用SVM分類器Ⅰ來區分高愉悅度情感和低愉悅度情感,如表6混淆矩陣所示,分類識別率達到了97.5%.
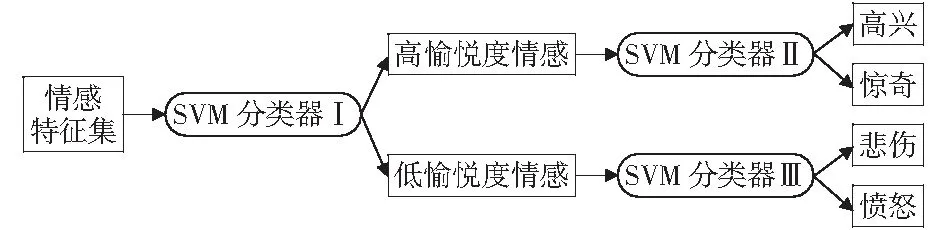
圖2 級聯分類流程圖Fig.2 Cascading classification flowchart
第二階段是在第一階段的基礎上,對于已經分類的高低不同的愉悅度的情感語音進一步分類識別。同樣運用SVM分類器Ⅱ來區分高愉悅度情感中的“高興”、“驚奇”,而SVM分類器Ⅲ來區分低愉悅度情感中的“悲傷”、“憤怒”。每一步的分類器都使用一個二進制SVM分類。表7和表8分別顯示了第二步的分類識別結果。

表6 高低愉悅度情感分類識別結果混淆矩陣Table 6 High and low pleasure emotion classification recognition result confusion matrix %

表7 低愉悅度情感分類識別結果混淆矩陣Table 7 Low pleasure emotion classification recognition result confusion matrix %

表8 高愉悅度情感分類識別結果混淆矩陣Table 8 High pleasure emotion classification recognition result confusion matrix %
通過將圖2兩個步驟組合起來,得到總體分類識別率的混淆矩陣如表9所示,平均分類識別率達到82.9%.可以看出本文提出的級聯分類方法無論在4種情感的識別率還是平均識別率都有很大程度的提高,尤其是在情感“高興”、“憤怒”中的表現尤為突出,級聯分類識別率相較于運用韻律特征和MFCC特征組合的分類識別率得到了明顯提高,識別率提高了15.4%.
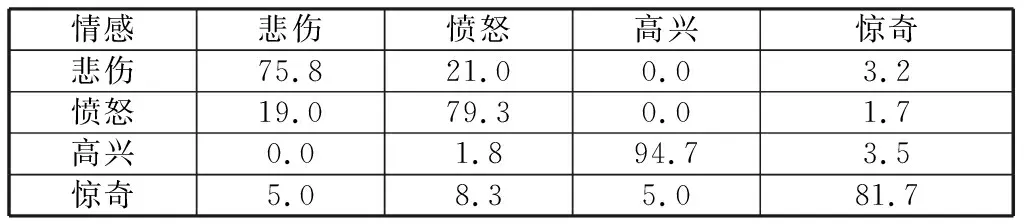
表9 級聯分類識別結果混淆矩陣Table 9 Cascading classification recognition results confusion matrix %
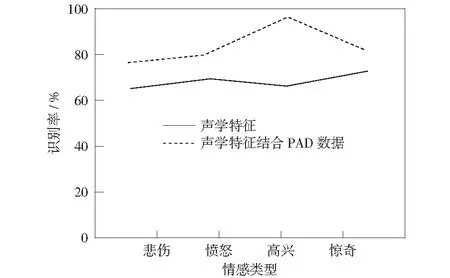
圖3 識別結果對比圖Fig.3 Recognition result contrast diagram
圖3直觀地展示了僅用傳統的聲學特征和本文提出的將聲學特征與情感語音PAD數據相結合的級聯分類方法識別率對比結果。由圖3可以明顯看出,通過將聲學特征與情感語音PAD數據相結合的級聯分類方法,各類情感的識別率均有提高,尤其對于“高興”情感來說,識別率提高了26.3%.
4 結論
針對運用聲學特征(韻律特征和MFCC特征)對情感語音的分類識別性能不理想的問題,提出了將聲學特征與情感語音PAD數據相結合的級聯分類方法。從三維空間情感模型出發,將聲學特征和PAD三維情感模型中對情感區分度最強的愉悅度相結合,通過SVM分類識別網絡,在每一步的識別中逐漸減少樣本數目,使得后一個分類器總比前一個分類器有更精確的分類。整體識別率提高了15.4%;尤其對于“高興”情感來說,識別率提高了26.3%,可達94.7%;其他情感的識別率也大幅提高。以上分析結果表明,本文提出的級聯分類的方法與傳統的情感語音識別方法相比有明顯的優勢,為語音情感識別提供了一種可靠可行的方法。但通過實驗結果可以看出,最終結果中的一些情感的混淆率仍然很大。因此在今后的研究工作中,需要進一步探究語音的情感特征與PAD三個維度的相關性,提取相關性高的情感特征,更有針對性地減少混淆率,從而有效提高情感識別率。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
