一種高效的RFID系統冗余閱讀器消除算法
2018-09-21 09:06:36郭穩濤何怡剛
東北師大學報(自然科學版) 2018年3期
郭穩濤,鄭 劍,2,李 兵,,何怡剛
(1.湖南機電職業技術學院,湖南 長沙 410151;2.湖南大學電氣與信息工程學院,湖南 長沙 410082;3.合肥工業大學電氣與自動化工程學院,安徽 合肥 230009)
0 引言
射頻識別技術(Radio Frequency Identification,RFID)作為物聯網代表性核心技術,已經廣泛應用于物流、交通運輸、醫療、定位導航等各領域.[1]一個完整的RFID系統通常包含標簽、閱讀器、中間件[2]和后臺應用系統.為保證區域標簽能夠完全被識別,RFID系統往往會部署過多的閱讀器,這可能帶來相鄰閱讀器的射頻信號重疊產生相互干擾,同時,同一標簽會多次被不同的閱讀器讀取,產生大量冗余數據.如何消除冗余閱讀器是RFID系統領域中數據清洗重大研究問題.冗余閱讀器的消除問題已被證明是NP(Non-deterministic Polynomial)問題[3].
冗余閱讀器消除問題一直是國內外研究學者關注的熱點.具有代表性的研究工作包括RRE(Redundant Reader Elimination)算法[4]、LEO(Layered Elimination Optimization)算法[5]和MRRE (Middleware-Base Redundant Reader Elimination)算法[6].RRE 算法使用閱讀器內可讀取標簽數量為權重,保證權重大的閱讀器對標簽具有更大地寫入鎖定優先級,迭代直至所有標簽被鎖定,未鎖定標簽的閱讀器即為冗余閱讀器.LEO算法思想是RRE算法針對某些系統拓撲結構失效而進行的進一步改進,保證標簽首次被閱讀器讀取時即被寫入鎖定,未鎖定標簽的閱讀器即判為冗余閱讀器.這兩個算法需要標簽具有寫鎖定存儲功能,同時要求閱讀器對標簽寫距離與讀距離相等,頻繁寫操作浪費時間,增加系統的負擔,影響系統性能.MRRE算法在RFID中間件建立閱讀器和標簽二維數組,對該數組進行迭代計算.根據閱讀器之間重疊標簽的數量判斷是否為冗余閱讀器,該算法避免了對標簽的寫鎖定操作,從全局上建立閱讀器與標簽間的對應關系.在系統的冗余檢測率、系統標簽信息量和覆蓋率等方面具有一定的優勢,但是該算法需要建立全局的閱讀器與標簽對應數組和在該數組的迭代操作,尤其迭代終止條件(需要迭代矩陣的元素全為0)極為苛刻,對系統中部署大量的閱讀器和標簽時,需要較大的存儲容量,使算法的復雜性急劇上升,算法的可擴展性差.[7-8]
由于完成消除冗余閱讀器是一個NP問題,因此,如何在冗余閱讀器的消除率和算法額外開銷取得較好的平衡是判斷一個冗余閱讀器消除算法優劣的重要指標.本文提出了友鄰閱讀器競爭冗余消除算法NRCEA (Neighbor-Reader Competitive Elimination Algorithm).該算法主要思想是比較相鄰閱讀器的共同標簽數,用來量化閱讀器間的信息匯聚度,匯聚度越高的閱讀器表明能夠識別的標簽越多,在網絡中發揮作用越大;匯聚度低的閱讀器表明可能分布在系統的邊緣地帶(可讀標簽數為0的閱讀器除外).這兩種閱讀器在消除算法中最應該保留,這樣分別從信息匯聚度低和高的兩種情況出發,消除網絡中重疊標簽,直至最后閱讀器可讀標簽集不再變化為止,可讀標簽集為空的閱讀器即為冗余閱讀器.為了驗證所提出算法的性能,將NRCEA消除算法與典型的RRE算法和LEO算法進行比較,NRCEA消除算法具有閱讀器檢測率高和系統部署更合理的優點,同時,與MRRE算法相比具有更低的復雜性.[9-10]
1 冗余閱讀器消除算法
冗余閱讀器收集標簽的功能可以被周圍其他閱讀器替代,不影響RFID系統的功能,因此,判斷系統中標簽的歸屬是去除冗余閱讀器的有效途徑.閱讀器讀取標簽受信號強弱的限制,具有一定地域性,只能讀取周圍一定范圍的標簽,本文提出的冗余閱讀器消除算法基于該思想,比較相鄰閱讀器的可讀標簽,與其他算法相比,可以極大地降低算法的搜索空間.[11-12]
1.1 閱讀器信息匯聚度
RFID系統中部署大量的標簽T和閱讀器R,且存在大量的冗余閱讀器,這些閱讀器射頻信號強弱相同,讀取標簽的范圍相同,讀取的范圍記為d.RFID中間件可接受并存儲閱讀器發送的標簽信息,并且可以得到閱讀器i在系統部署區域的坐標,記為〈xi,yi〉.
(1)
在中間件中,通過距離判別函數得到系統中每個閱讀器的相鄰閱讀器集,使用一個二元組〈TS,RS〉來表示閱讀器的信息,其中TS表示閱讀器可讀標簽集,RS來表示相鄰閱讀器節點集.根據相鄰閱讀器節點集RS可以將可讀標簽集TS中的標簽進行分類,共享標簽集TS1和孤立標簽集TS2,對閱讀器i使用的描述公式為:
?j∈RSi∧?r∈TSj∧?r∈TSi→r∈TSi1;
TSi2=TSi-TSi1.
(2)
為了精確刻畫相鄰閱讀器相似程度,對有多個閱讀器共享的同一標簽,需要重復計算多次,加入到共享標簽集TS1中.孤立標簽集TS2如果不為空,則表示該閱讀器需要獨自讀取某些標簽,標記為非冗余閱讀器.使用max來標記系統中的所有標簽數,定義相鄰閱讀器相似度用來刻畫閱讀器在系統中間可讀標簽的相似程度.[13-14]
定義1閱讀器相鄰相似度.閱讀器i的相鄰相似度可以表示為
α=|TS1|/max.
(3)
|TS1|表示共享標簽集的數目,α∈[0,1].
定義2閱讀器信息匯聚度.閱讀器i的信息匯聚度可以表示為
IAi=w*α(1-w)*|TS|/max.
(4)
其中:w∈[0,1],w取不同值,表示相鄰相似度和可讀標簽數間的比重.閱讀器信息匯聚度刻畫了當TS2≠?時,閱讀器在系統中承擔讀取共享標簽和總標簽的比重,w值越大,表示閱讀器承擔讀取共享標簽的功能越大,在閱讀器信息匯聚度的量化指標中占據的比重越大.圖1為一個簡單的RFID冗余閱讀器拓撲.
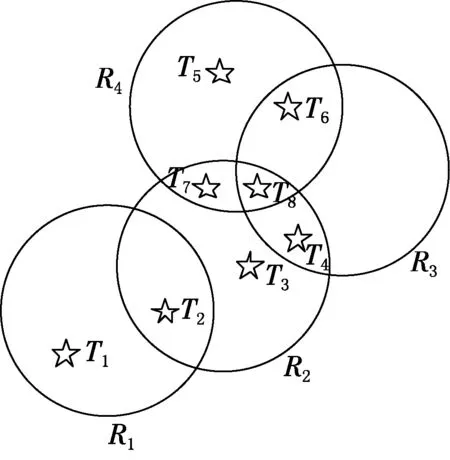
圖1 RFID冗余閱讀器舉例
根據上述概念的定義,可以分別得到可讀標簽集、共享標簽集和孤立標簽集:
TSR1={T1,T2},TSR11={T2},TSR12={T1};
TSR2={T2,T3,T4,T7,T8},
TSR21={T2,T4,T7,T8,T8},TSR22={T3};
TSR3={T4,T6,T8},
TSR31={T4,T6,T8,T8},TSR32=?;
TSR4={T5,T6,T7,T8};
TSR41={T6,T7,T8,T8},TSR41={T5}.
這里,max=9,假設取w=0.7,可以得到信息匯聚度:
首先,TSR32=?可以看出閱讀器R3的可讀孤立標簽集為空,則該閱讀器可能為空,從閱讀器的信息匯聚度值相對大小可知,閱讀器R2在系統中承擔讀取標簽任務的比重較大,從該閱讀器開始進行消減標簽,直至閱讀器可讀標簽為零為止.
1.2 算法描述
友鄰閱讀器競爭冗余消除算法NRCEA的基本思想:首先,RFID系統中各閱讀器發送讀取標簽廣播,收集可讀范圍內所有標簽標志,構成可讀標簽集TS.然后,各閱讀器將自身位置坐標〈xi,yi〉和可讀標簽集TS發送給系統中間件,根據中間件公式(1)計算各閱讀器的相鄰閱讀器集RS,并根據公式(2)將可讀標簽集TS分成共享標簽集TS1和孤立標簽集TS2.最后,按照以下步驟判別冗余閱讀器[15]:
步驟1中間件根據公式(3)和(4)計算閱讀器相鄰相似度和信息匯聚度,剔除那些孤立標簽集TS2不為空的閱讀器,判別為非冗余閱讀器,放入非冗余閱讀器集NRR.
步驟2從閱讀器集中任意選擇一個閱讀器Ri,與相鄰閱讀器集TS的閱讀器Rj進行比較,如果存在共同標簽:
(1) 如果閱讀器Ri∈NRR,則從閱讀器Rj的可讀標簽集RS中刪除該標簽;
(2) 如果閱讀器Rj∈NRR,則從閱讀器Ri的可讀標簽集RS中刪除該標簽;
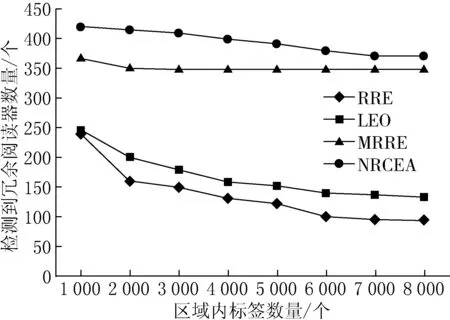
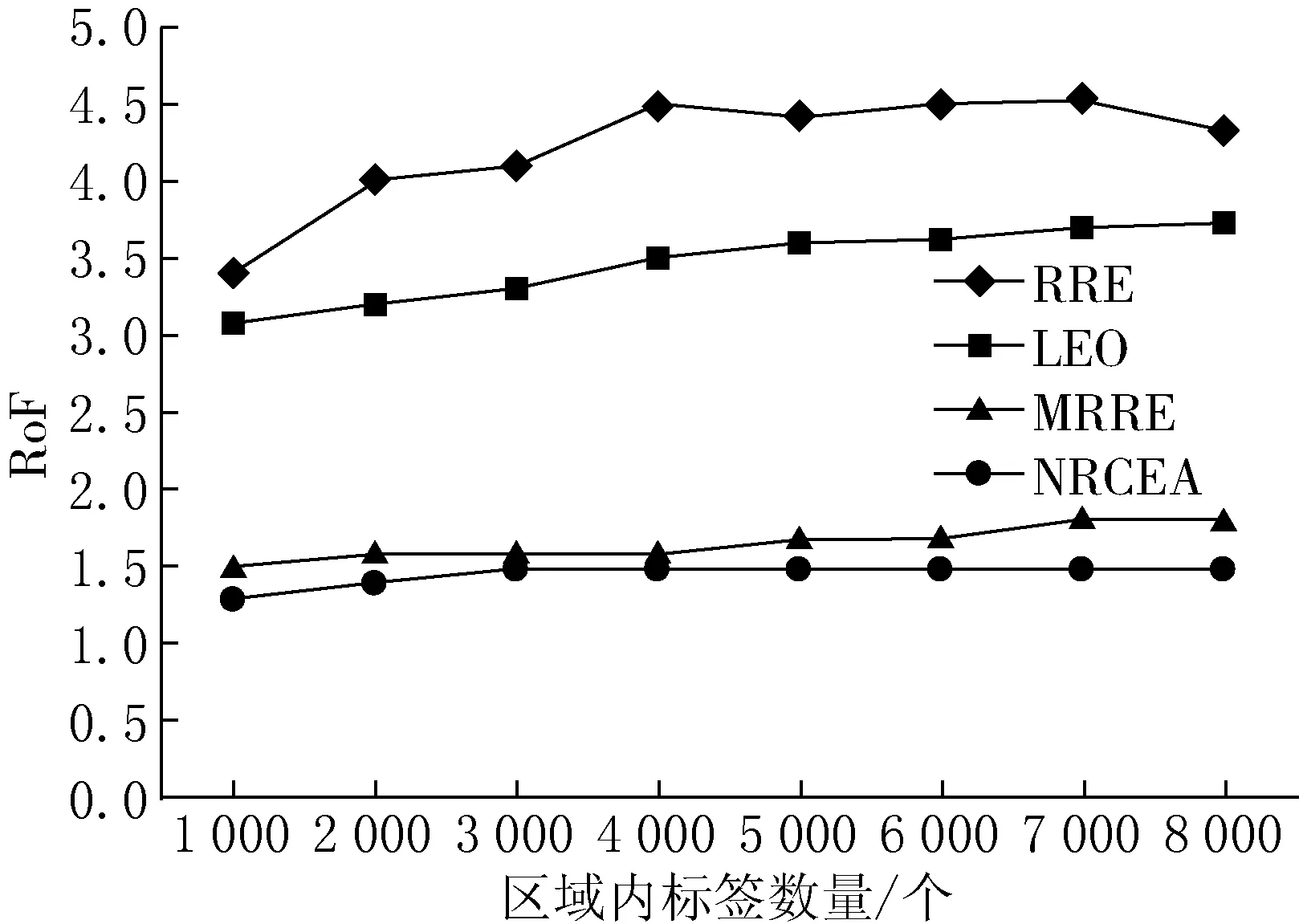
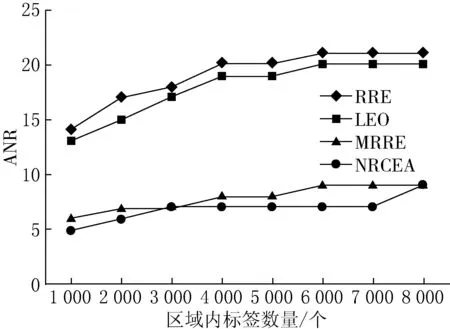
(3) 如果IAi (4) 如果IAi≥IAj,則從閱讀器Rj的可讀標簽集RS中刪除該標簽. 步驟3不斷迭代遍歷步驟2,直至閱讀器集中所有元素遍歷為止. 步驟4計算判別冗余閱讀器,如果可讀標簽集不為空,則為冗余閱讀器,放入非冗余閱讀器集NRR. 1.2.1 算法偽代碼 第1步:初始化,得到所有閱讀器可讀標簽集和相鄰閱讀器集. Set NRCEA(Set Rds,Set tags,flaot d;float w,float Thresd){ Set NRR=?,RR=?; for each(reader rd1 in Rds){ rd1.TS.put(rd.readtargers()); for each(reader rd2 in Rds $$ rd2!=rd1){ if(rd2.RS.contain(rd1)) rd1.RS.put(rd2); elseif(!abs(rd1.x-rd2.x)>2*d&& !abs(rd1.y-rd2.y)>2*d) rd1.RS.put(rd2); } }. 第2步:得到共享標簽集TS1和孤立標簽集TS2. for each(reader rd1 in Rds){ for each (reader rd2 in rd1.RS) for each (tag t in rd1.RS) if(t in rd2.TS) rd1.TS1.put(t); rd1.TS2=rd1.TS-rd1.TS1; }. 第3步:計算每個閱讀器的信息匯聚度. for each(reader rd1 in Rds) rd1.ia=w*rd1.TS1.num()/tags.num()+(1-w)*rd1.TS.num/tags.num(). 第4步:迭代遍歷閱讀器集,計算非冗余標簽集和冗余標簽集. for each(reader rd1 in Rds) for each (reader rd2 in rd1.RS) for each (tag t in rd1.RS) if(rd2.TS.contain(t)){ if(NRR.contain(rd1)){ rd2.TS.delete(t); break; } if(NRR.contain(rd2)){ rd1.TS.delete(t); break; } if(!rd1.TS2.empty()){ NRR.put(rd1); rd2.TS.delete(t); break; } if(!rd2.TS2.empty()){ NRR.put(rd2); rd1.TS.delete(t); break; } if (rd1.ia rd1.TS.delete(t); break; } rd2.TS.delete(t); }. 第5步:判斷冗余閱讀器. for each(reader rd1 in Rds) if(!NRR.contain(rd1)&&!rd1.TS.empty()){ NRR.put(rd1); RR=Rds-NRR; return RR; }. 1.2.2 算法流程 在迭代過程中,相鄰閱讀器間具有共同標簽的閱讀器,根據其信息匯聚度值競爭性刪除相同的標簽,能夠保留可讀標簽數量和相同標簽數大的閱讀器,該算法流程如圖2所示. 圖2冗余閱讀器消除算法流程 設系統中存在n個閱讀器,每個閱讀器可讀標簽平均數量為r,相鄰閱讀器平均數量為m.系統中標簽數為n*r. 首先,RRE算法和LEO+RRE算法在消除冗余閱讀器時,需要保存每個標簽的鎖定的閱讀器信息,因此,空間復雜度為系統中標簽的數量,即O(n*r);MRRE算法需要保存一個所有閱讀器與所有標簽一一映射的矩陣,其所有空間復雜度為O(n*n*r).而NRCEA算法消除過程中為每個標簽保存一張可讀標簽集合和相鄰閱讀器集合,其空間復雜度為O(n*(w+r)).因此,空間代價要比MRRE算法小得多. 其次,RRE算法和LEO+RRE算法需要對每個標簽執行寫鎖定操作,其寫操作復雜度為O(n*r),因寫操作時間要遠遠大于讀操作時間,因此,該算法的額外寫操作時間開銷比較大.MRRE算法和NRCEA算法不要寫操作,需要遍歷所有的閱讀器和標簽,其最差時間復雜性均為O((n*n*r)2). 因此,NRCEA算法空間復雜度要低于MRRE算法,時間復雜度要優于RRE算法和LEO+RRE算法,能夠在時間和空間上均具有明顯的優勢.同時,NRCEA算法設置2種閱讀器保留策略:一種是保留讀取孤立標簽集的閱讀器;另一種是通過計算閱讀器信息匯聚度作為相鄰閱讀器競爭讀取標簽的權重,保留信息匯聚度大的閱讀器,從而使算法在系統標簽信息量和覆蓋率、系統部署更合理性. 實驗環境基于Matlab 7.0,參數同文獻[4-6],實驗區域為1 000×1 000單位長度,隨機分布500個閱讀器和若干標簽,實驗標簽的數量范圍為[1 000,8 000],設定閱讀器讀距離d=50,閱讀器對標簽寫距離與讀距離比例為0.7[7].各種實驗分別進行10次,對實驗數據取平均值. 由于LEO算法和RRE算法需要對標簽進行寫鎖定操作,因此代價比較大,性能相對較低.MRRE算法和NRCEA算法在中間件上進行,受RFID工作特性影響較少,其性能較優. 各算法可擴展性性能可以使用系統標簽數量變化進行描述.4種算法隨標簽數量變化的冗余消除結果如圖3所示,由圖3可以看出,本文提出的NRCEA算法和MRRE算法明顯優于LEO和RRE算法,同時,NRCEA算法的冗余閱讀器檢測率比MRRE算法提高了6%~14%.因為NRCEA算法優先考慮處于邊界和孤立閱讀器,其他閱讀器共享標簽消除時依據閱讀器信息匯聚度,能夠保存讀取更多標簽的閱讀器,將閱讀信息量少的閱讀器盡可能地消除掉. 圖3 各算法去冗余消除結果 系統標簽信息量可以使用標簽總量溢出率(rate of overflow,RoF)來量化,定義為 (5) 其中:NRR表示系統冗余閱讀器消除后非冗余閱讀器集合;TS(Ri)表示閱讀器Ri可讀取的標簽集合;NoT表示系統標簽總數;Rr表示NRR對標簽的平均讀取率. 各算法隨標簽數量變化的RoF性能變化如圖4所示.NRCEA算法和MRRE算法的RoF值接近1,遠遠小于RRE算法和LEO算法,表明冗余閱讀器消除后閱讀器間共享的標簽數量特別少. 圖4 各算法RoF性能比較 系統部署合理性是指系統應盡量減少RFID對標簽讀寫沖突發生的概率.通過減少各標簽周圍覆蓋的閱讀器的數量,降低閱讀器間沖突的發生概率.因此,使用閱讀器的平均相鄰閱讀器數量(average quantity of neighbor readers,ANR)來衡量各算法的系統部署合理性,定義為: RNS(Ri)={Rj|Rj∈RS(Ri)∧Rj∈NRR}; (6) 圖5 各算法ANR性能比較 其中:RNS(Ri)表示閱讀器Ri在冗余消除后相鄰閱讀器集;|·|表示對應集合內元素數量. 各算法隨標簽數量變化的ANR指標曲線如圖5所示.由圖5可以看出,NRCEA算法明顯優于RRE算法和LEO算法,取得與MRRE算法相同的效果,但是算法的復雜度明顯低于MRRE算法. 為了解決RFID系統中冗余閱讀器的多讀問題,本文提出了一種基于閱讀器信息匯聚度的高效RFID系統冗余閱讀器消除算法NRCEA.與現有的典型RRE算法和LEO算法相比,該算法不需要對標簽寫鎖定操作,不受RFID工作特性的影響.與MRRE算法相比,該算法在存儲空間上具有更低的復雜度.仿真實驗結果表明,NRCEA算法在算法性能、系統標簽信息量和部署更合理性,具有更高的冗余閱讀器檢測率.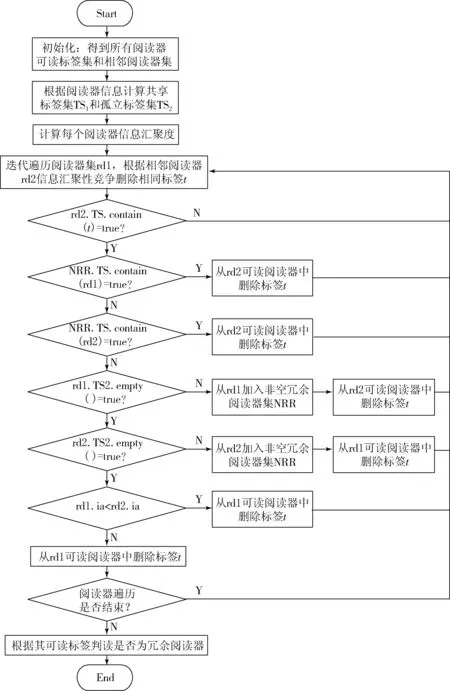
1.3 算法分析
2 算法實驗與結果分析
2.1 算法性能分析
2.2 系統標簽信息量分析
2.3 系統部署合理性分析
3 結束語
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30北京測繪(2020年12期)2020-12-29 01:33:58裝備制造技術(2019年12期)2019-12-25 03:06:46中國洗滌用品工業(2019年4期)2019-05-11 09:27:34家庭影院技術(2017年9期)2017-09-26 03:41:45中華手工(2017年2期)2017-06-06 23:00:31中外會展(2014年4期)2014-11-27 07:46:46建筑創作(2001年3期)2001-08-22 18:48:14祝您健康(1987年3期)1987-12-30 09:52:32
