深度學習大數據分析計算平臺
2018-10-13 07:58:04郭泉
現代計算機 2018年23期
郭泉
(四川大學計算機學院,成都 610065)
0 引言
近年來,大數據所隱含的巨大價值越來越受到各行各業的重視。大數據通常是指在可容忍的時間內用傳統信息技術和軟硬件工具難以對其進行獲取、管理、處理和分析的數據集合,具有體量浩大(Volume)、多源異構(Variety)、生成快速(Velocity)、價值巨大但密度很低(Value)的4V特征。大數據分析是將大數據轉換為價值的重要一環[1]。大數據計算,則主要是面向大數據分析進行計算。深度學習已經在大數據分析的各個領域取得突破性進展[1,2]。其需要大量計算,得益于GPU等計算資源高效的計算方式。然而如何管理好這些計算資源?本文提出利用Linux操作系統容器技術,通過對系統資源的分割和映射,管理其系統資源,尤其是計算資源,形成基于操作系統容器的深度學習大數據分析計算平臺。
1 研究現狀
深度神經網絡模型成為國際上大數據分析領域中的研究熱點。Google、微軟等公司利用GPU加速建立的深度學習網絡已經在圖像識別[3]、語音識別[4]等領域取得重大突破。然而大規模深度學習平臺的搭建仍處于摸索階段,尚缺乏統一的深度學習大數據分析計算的范式和可擴展的計算平臺搭建方法。除了傳統的CPU、GPU等通用處理器計算方式,還涌現了如FPGA、ASIC等專用處理器設計。中科院計算所陳云霽研究員等人在專用芯片設計上取得突破。基于深度學習的大數據分析計算初露頭角,百花齊放,目前的挑戰是,如何建立一個深度學習并行計算平臺,更好地利用GPU和其他協處理器的計算特性。
2 基于容器技術的計算平臺
Linux操作系統容器(Linux Container,LXC),可以看做是實現了一種輕量級的虛擬化,為每個計算節點提供虛擬化運行環境,幾乎無額外性能開銷,同時便于管理和應用獨立性。Docker是一個LXC應用容器引擎,可通過Docker進行系統資源的管理和分配,尤其是GPU等計算資源。
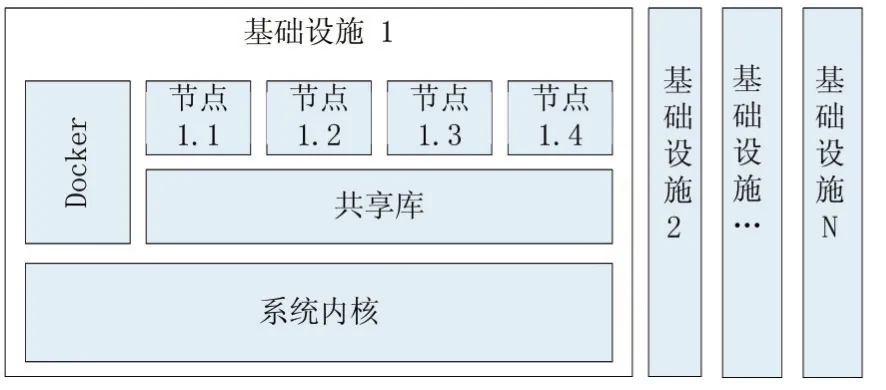
圖1 系統架構圖
我們在操作系統鏡像的基礎上,特定映射一個用戶工作目錄,用于管理該容器的工作范圍。其次映射GPU資源,包括設備文件、驅動文件和CUDA庫。最后為了方便操作,我們映射一個網絡端口方便在容器中通過網絡服務進行交互,例如通過Jupyter在瀏覽器上進行開發和維護工作等。
3 計算性能實驗
為了驗證本文提出的基于操作系統容器的深度學習大數據分析計算平臺的計算性能,我們進行以下幾組實驗。深度學習中的計算主要是矩陣乘法計算,對于m×k的矩陣A和k×n的矩陣B,其矩陣乘積為m×n的矩陣C,其中元素Cij為A中第i行元素與B中第j列元素對位相乘結果之和。矩陣乘法計算,在無特殊性質無優化的計算方式下,其計算代數操作數為m×k×n,其時間復雜度為O(n3)。我們設計一個大型計算圖,包括每個GPU上進行一個大型矩陣乘法,再匯聚到一個GPU上匯總求和。這符合深度學習中通常遇到的計算模式。這里我們令A為5120×10240的隨機矩陣,B為10240×7680的隨機矩陣,我們讓每個GPU計算C=AB,并對全部的C求和。注意,生成隨機矩陣也涉及GPU的代數操作,記入其代數計算次數,這也是深度學習訓練過程中常涉及到的操作過程。
接下來在提出的基于操作系統容器的深度學習大數據分析計算平臺,使用不同數量的GPU進行上述矩陣乘法實驗。
使用1塊GPU計算,任務包含代數計算805568512000次。重復進行10次實驗。

表1 使用1塊GPU計算的計算性能
以上實驗可以看出,10次實驗平均用時0.165秒,標準差0.107,平均計算吞吐量為6.150TFlops,標準差2.135。值得注意的是,第一次實驗的時間顯著高于其他9次,對應的,計算吞吐量也較后者低。這是因為系統中的計算卡的初始激活和分配被記入了時間統計過程。因此可以認為第一次實驗的結果為離群點,在統計中可以將其去除。去除離群點后實驗室平均用時0.131秒,標準差 0.042,平均計算吞吐量為6.640TFlops,標準差1.632。后面的實驗中我們也將以相同的原則去除離群點,并匯報兩種統計結果。
使用2塊GPU計算,該任務含有代數計算1611176345600次。重復進行10次實驗。

表2 使用2塊GPU計算的計算性能
以上實驗中,十次實驗平均用時0.227秒,標準差0.161,平均計算吞吐量為9.129TFlops,標準差3.255。去除離群點后實驗室平均用時0.177秒,標準差0.054,平均計算吞吐量為9.882TFlops,標準差2.470。
使用4塊GPU計算,該任務包含代數計算3222392012800次。重復進行10次實驗。

表3 使用4塊GPU計算的計算性能
可以發現,十次實驗平均用時0.302秒,標準差0.288,平均計算吞吐量為 14.499TFlops,標準差4.183。去除離群點后實驗室平均用時0.206秒,標準差 0.027,平均計算吞吐量為 15.802TFlops,標準差1.568。
以上四個實驗中的代數計算次數基與使用的GPU數量正相關,即每個卡上的平均計算量是一致的,因此我們可以認為這些任務中其卡均計算量是一定的,我們可以橫向比較這些吞吐量來觀察不同GPU數量下平臺計算性能變化情況。
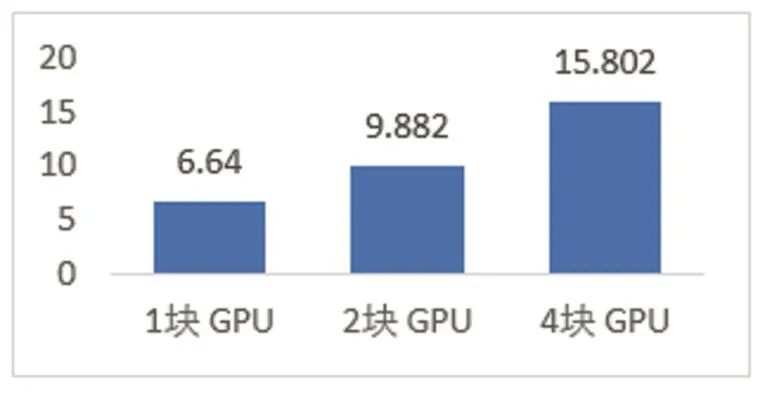
圖2 相同卡均計算量下使用不同數量GPU卡的計算性能
這里采用去除離群點的吞吐量平均值反映計算能力。可以看出,在同樣的卡均計算量任務的情況下,隨著使用GPU數量增加,平臺的吞吐量增加顯著。這是由于平臺利用了計算任務之間的并行特性,通過并行提高了總體計算能力。
4 結語
操作系統容器可以看做是一種輕量級的虛擬化,在劃分系統資源的同時,能夠較高效地映射系統資源形成一個小的完整操作系統,與當代深度學習相結合,通過映射和管理系統的存儲、計算資源,形成一個有效管理的平臺,即基于操作系統容器的深度學習大數據分析平臺。實驗證明,本文提出的平臺能夠很好地利用GPU進行深度學習計算,對于大規模的矩陣乘法、加法、隨機采樣復合代數操作計算圖,計算性能卓越,隨著使用的GPU數量增加,在卡均任務不變的情況下總體計算性能增加。未來可以向多機計算資源管理進行進一步工作。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
