多信息融合技術在船舶柴油機故障診斷中的應用
2018-10-16 04:55:12尚前明王瑞涵唐新飛
中國航海 2018年3期
尚前明, 王瑞涵, 陳 輝, 唐新飛
(武漢理工大學 能源與動力工程學院, 武漢 430063)
柴油機的性能直接影響著船舶航行的安全和效率。柴油機工作環境惡劣,故障發生率極高。并且,柴油機的構造復雜,出現故障時,維修難度較大,維修時間較長,一旦維修失誤,將極有可能引發嚴重事故,造成海洋污染和貨物的經濟損失,甚至危及海員的生命。因此,對柴油機故障和潛在危險的預測至關重要[1]。但隨著柴油機技術的不斷發展,傳統的故障診斷方法已無法滿足現實需求。基于融合的綜合診斷技術已經成為現代船舶故障診斷領域的一個新的研究方向,并隨著現代信息技術的發展,船舶行業也有了足夠的數據積累,對柴油機的故障實施智能診斷已具有可行性[2]。
目前國內外柴油機的智能診斷技術還不夠成熟,大多數采用監督學習,即神經網絡。文獻[3]通過對故障實例和診斷經驗的學習,實現對故障的識別。而神經網絡的學習時間較長,在初始數據較復雜時,容易陷入局部極小值,影響診斷結果,這在工程實踐中往往難以實現。還有一些文獻采用無監督學習,即分類算法,將同一工況下的數據進行分類,如文獻[4]和文獻[5],但柴油機故障復雜多樣,大多數分類方法僅局限于二分類,在樣本數據量不平衡時,預測偏差較大。文獻[6]采用多種技術融合的方法診斷柴油機故障,取得可喜的成績。本文采用無監督學習和監督學習融合的方法進行柴油機故障診斷。利用k均值聚類分析(k-means)和BP神經網絡對柴油機運行狀態進行診斷,并在此基礎上進行優化,利用主層次分析法(Principal Component Analysis,PCA)對數據進行特征值提取,對樣本參數進行有效的降維,結合k-means聚類分析和BP神經網絡來建立柴油機故障診斷模型,使得故障系統對獲得的信息進行處理,實現柴油機故障的智能診斷。
1 基于數據挖掘技術的故障診斷
故障診斷領域的方法大致可劃分為基于分析模型的方法,基于定性經驗知識的方法和基于數據挖掘的方法等3類。
1) 基于分析模型的方法適用于信息充足且可以建模的系統,數學建模的建立必須了解整個過程的機理且建模必須精準。
2) 基于定性經驗知識的方法適用于不能或不易建立機理模型、信息不充分的系統。基于分析模型的方法不可能獲得復雜機理模型的每一個細節,而基于定性經驗知識需要復雜高深的專業知識和長期積累的經驗,這超出了普通工程師所掌握的范圍,從而變得難以實現[7]。
3) 基于數據挖掘的方法是在以上兩類方法基礎之上的一種自動化診斷方法,汲取以上兩類方法的經驗和方法,設計出合理的診斷過程。
2 數據挖掘技術的故障診斷原理
采用數據挖掘技術對設備進行一系列的故障診斷,其原理就是根據設備傳感器的記錄數據,從這些數據信息中提取其中隱藏的有潛在價值的信息,找出其內在規律。對大量數據進行抽取和分析,最后進行模型化處理,預測其運行的趨勢,并對其可能存在的運行狀態分類。具體體現形式就是數據的分類,而數據挖掘分為監督學習和非監督學習兩大類[8]。
本文基于數據挖掘的原理,提出一種基于無監督和監督學習的柴油機故障診斷方法,無監督學習采用k-means聚類分析,監督學習采用BP神經網絡,并采用統計學原理對算法做進一步優化。對一組數據分別用這2種算法進行處理,分析試驗結果,用統計學優化后的算法診斷準確度和效率更好。該算法的診斷過程見圖1。
2.1 無監督學習
無監督學習是事先沒有訓練樣本的,直接對數據進行建模分類。聚類算法就是一種典型的無監督學習[9]。
本文聚類算法選擇簡單高效的k-means算法。以往的算法像回歸、樸素貝葉斯及SVM都必須有具體的類別,而k-means算法是基于距離的聚類算法,關鍵在于找到類別,通過均值對數據點進行聚類,將同一類別的特征放在一起。預先設定每個類別的初始質心,對相似的數據點進行劃分,最終通過劃分后的均值迭代獲得最優的聚類結果。 其算法步驟為
1) 隨機選取n個聚類點,為k1,k2,…,kn∈Rn。
2) 重復下面的過程直到收斂。
對于每一個樣例i,計算其應該屬于的類:
(1)
式(1)中:ci為i樣例與n個類中距離最近的那個類,其值是1到n個類中的一個。
對于每一個類j,重新計算該類的質心為
(2)
3) 定義一個畸變函數,來描述計算的收斂性為
(3)
J函數表示每個樣本點到其質心的距離平方和,由于J函數是一個非凸函數,有可能會陷入局部優化,不能保證取得的最小值就是全局最小值。為解決該問題,本文采用EM思想。EM思想是E步來確定隱含類別變量c,M步更新參數k使得J函數最小化。通過開始指定一個ci,為使得J函數最小,不斷調整kj的值,使J減少,此時發現若有更好的ci(使得質心與樣例xi距離最小的類別)指定給xi,ci可得到重新調整,上述過程重復,直到沒有更好的ci指定。
2.2 監督學習
監督學習是通過訓練樣本構建數學模型,對未知數據進行分類。BP神經網絡便是一種典型的監督學習[10],并廣泛應用于信息處理中。
BP神經網絡的訓練算法是反向傳播算法,即將均方誤差(MSE)作為全部權值和全部偏置值的函數。全部輸出向量和目標輸出向量之間的距離(差的模)越小,均方誤差越小。均方誤差的值越小,則神經網絡的行為與想要的行為越接近[11]。
2.3 算法優化
在對柴油機進行故障診斷時,經常會有多個故障征兆表示一個故障的情況。征兆變量數目較多會明顯增加分析問題的復雜性。因為有些信息是多余的,所以可采用主層次分析法。主層次分析法是一種統計方法,是多元統計學中一種常用的降維方法[12]。主層次分析法采取的是一種數學降維的方法,將原來眾多具有一定相關性的征兆變量,經過數學方法重新組合為一組新的相互無關的綜合變量來代替原來變量,將多個變量綜合為少數幾個代表性的變量,使這些變量既能代表原始變量的絕大多數信息,又不互相相關,減少數據量,從而減少工作量。主層次分析法的步驟為
1) 對原始數據進行標準化處理。
(4)
2) 計算相關系數矩陣。
(5)
3) 求出相關矩陣的特征值(λ1,λ2,…,λp)和特征向量。
ai=(ai1,ai2,…,aip),i=1,2,…,p
(6)
4) 根據相關矩陣的特征值,根據式(7)選擇重要的主成分(特征值越大的主成分所占的貢獻率越大)。

(7)
5) 按照式(8)計算求出主成分,依據主成分得分的數據,進一步對問題進行后續的分析和建模。
Fij=aj1xi1+…+ajpxip(i=1,…,n;j=1,…,k)
(8)
式(8)中:aj1,aj2,…,ajp為式(6)中的特征向量,xi1,xi2,…,xip為式(4)中標準化處理后的數據。
先將同一征兆下的數據進行聚類處理,簡化參數,并呈現一定的規律性。
1) 第1種算法是將聚類處理后的數據作為神經網絡的輸入量,進行柴油機工況的識別,對試驗進行分析。
2) 第2種算法是在聚類之前,先將數據通過PCA法對數據降維,使得原數據的多個征兆極大簡化。
將經過PCA處理后的數據進行聚類處理,2種算法處理后的數據最終作為神經網絡的輸入,對柴油機工況進行識別。最后比較2種方法的準確度和效率。
3 故障診斷實例
本文以MAN B&W 10L90MC型船用柴油機為研究對象。柴油機在90%負荷下,在5種常見工況(正常、噴油器噴嘴結碳、排氣閥漏氣、高壓油泵磨損及活塞環損壞)下所測得的數據,每種工況共6組數據。其中{S1,S2,S3,S4,S5,S6,S7,S8}為征兆,分別為平均有效壓力、排氣總管溫度、排氣壓力、掃氣壓力、壓縮壓力、最大爆發壓力、轉速及耗油率。
3.1 數據預處理
樣本數據的預處理采用k-means算法來實施聚類,其中k值的選擇,根據J函數的計算來選擇。聚類方法能使得原始樣本數據簡化,且呈現一定的規律性。分類結果及中心見表1。
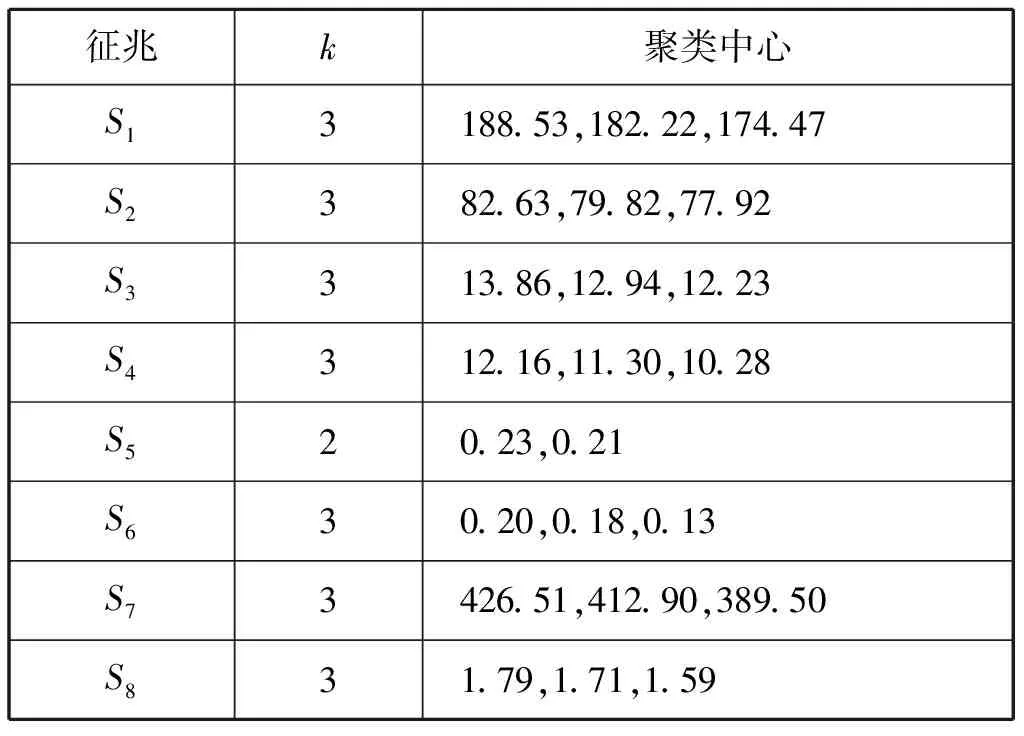
表1 分類結果及中心
限于篇幅,僅列出每種工況經過k-means算法聚類后的兩個樣本數據見表2。表2中:Ⅰ為正常工況;Ⅱ為噴油器噴嘴結碳;Ⅲ為排氣閥漏氣;Ⅳ為高壓油泵磨損;Ⅴ為活塞環損壞。
3.2 神經網絡診斷故障
選取經k-means處理后的樣本數據,采用MATLAB軟件使用神經網絡,以8種聚類分析后的征兆作為輸入量,工況模式輸出矩陣作為目標向量,經過不斷測試,網絡層數及結構最終確定為8-9-5。
輸出分別為矩陣:[1,0,0,0,0]表示正常工況;

表2 部分樣本數據聚類結果
[0,1,0,0,0]表示高壓油泵磨損;[0,0,1,0,0]表示噴油器噴嘴結碳;[0,0,0,1,0]表示活塞環損壞;[0,0,0,0,1]表示排氣閥漏氣。 每種工況的5組數據采用“訓練-測試”的方法進行多組試驗。選取訓練最好的網絡,網絡訓練誤差曲線見圖2。
由圖2可知,當計算達到第8步時,訓練誤差達到了目標誤差的要求。將每工況最后的一組數據作為檢驗樣本來檢驗訓練好的網絡,檢驗結果見表3。

表3 柴油機故障預測結果
表3中在正常工況和高壓油泵磨損排氣閥漏氣的3種工況,此神經網絡診斷精度都很高。在噴油器噴嘴結碳和活塞環損壞的工況下,雖然隸屬度分別為0.581 4和0.792 7明顯大于其他故障類型的隸屬度,但是隸屬度相對較小,診斷精度需進一步提高。
3.3 算法優化處理
由多個征兆來表現一個工況,這大大的增加神經網絡的訓練時間,且顯著增加分析問題的復雜性,所以在某些情況下會減弱神經網絡的監測精度。
其實在多個征兆之間存在一定的相關性,所以可采用PCA方法,對原始數據進行降維,將具有一定相關性的原始征兆數據,重新組合為一組新的相互無關的綜合變量。對數據進行PCA降維處理。雖然非線性相關的數據降維后會使原始數據的部分信息丟失,但由于柴油機各征兆之間存在一定的相關性,可計算各成分的貢獻率,貢獻率越大,包含原始數據的信息量就越多。通過累計貢獻率的計算,選擇較少維數的參數來表示原始數據大多數的信息,可降低學習算法的復雜性。
對數據進行標準化處理后,求數據的特征值和成分貢獻率,得到的特征值從大到下排列見表4。
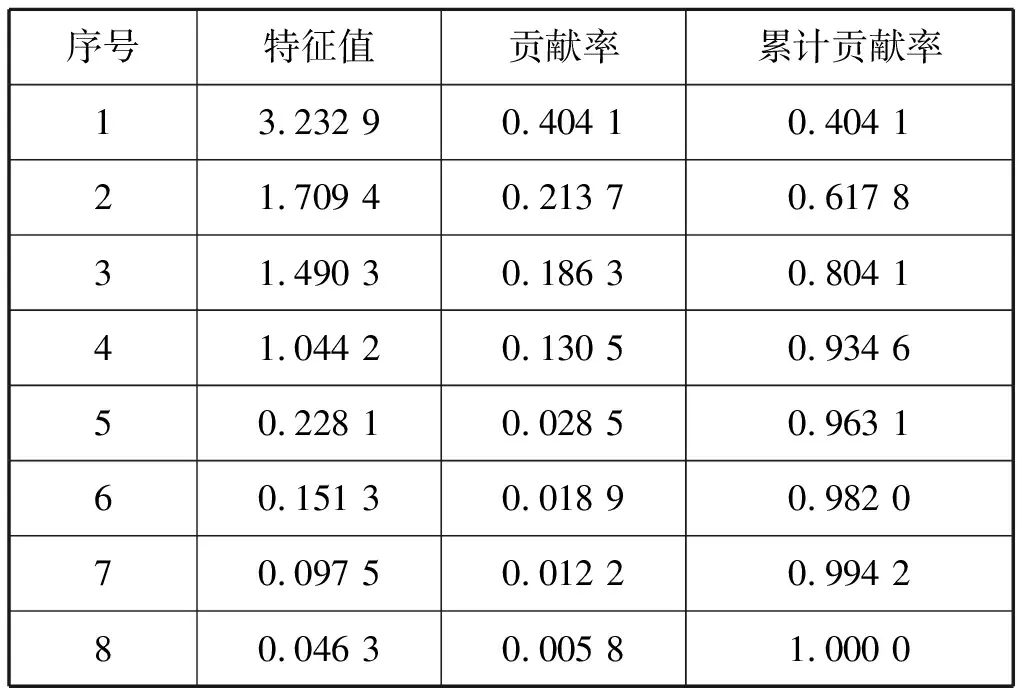
表4 主成分的貢獻率及累計貢獻率
主成分個數的選取根據主成分的累計貢獻率來決定,貢獻率根據特征值在所有特征值中的比重來決定,一般要求累計貢獻率大于85%,能保證計算后的變量能包括原始變量的絕大多數信息。根據表4和累計貢獻率,前4個特征值的貢獻率便已超過85%,達到93%,即經計算得到的前4個綜合變量就可包括原始數據8個變量中93%的信息量,然后計算出第1、第2、第3、第4的主成分值。
根據標準化的原始數據,按照各個樣品,分別帶入式(5),可得到前4個主成分下的各個樣品的新數據,即為主成分得分見表5。

表5 主成分計算后的樣本數據
對使用主成分分析法計算后的樣本數據進行k-means分類,將復雜的數據換成簡單的數字。根據數據不同的k值聚類分析進行具體的分類。采用EM思想,根據類之間有明顯的區分和類別的數量越多的要求來確定k值。分類結果及中心見表6。

表6 主成分聚類結果
根據表6的聚類中心,將各個主成分的數值進行分類,得到各個主成分的分類結果見表7。

表7 主成分分類結果
經過PCA和k-means兩種算法簡化原始數據,將得到的新數據用神經網絡采用相同的方法進行試驗,網絡結構為4-7-5。多次試驗,選取訓練最好的網絡,網絡訓練誤差曲線見圖3。
由圖3可知,當計算達到第7步時,訓練誤差達到了目標誤差的要求。將每工況最后的一組數據作為檢驗樣本來檢驗訓練好的網絡,檢驗結果見表8。
對表8的結果進行分析,得到經過PCA和k-means處理后的數據,神經網絡診斷工況的精度都很高,且這種優化后的算法能很好也識別在噴油器噴嘴結碳和活塞環損壞的2種故障。

表8 柴油機故障預測結果
3.4 分析試驗結果
2次的試驗結果對比見表9。由表9可知,所用經PCA優化聚類分析的神經網絡算法,不僅能保持較高的診斷率,同時也大大減少神經網絡的輸入節點數和隱含層數,簡化了網絡結構,且減少了平均誤差平方和迭代數,提高診斷速度。

表9 兩種診斷算法的試驗結果對比
4 結束語
本文根據對數據挖掘的理解,提出一種基于無監督學習和監督學習相結合的柴油機故障診斷算法,并用統計方法對原始數據降維,進而對算法進行優化。試驗分析證明,這種優化算法可靠并且有效,采用這種算法可大大提高柴油機故障診斷的效率,不僅可識別柴油機故障類型,且能較多在最大程度上簡化監測數據,為診斷故障節約了較多的時間。
猜你喜歡
人大建設(2020年4期)2020-09-21 03:39:12
汽車維修與保養(2019年7期)2020-01-06 03:30:42
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
汽車維護與修理(2016年10期)2016-07-10 08:17:41
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
浙江人大(2014年4期)2014-03-20 16:20:16
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
