數據中心中面向光互聯的流量識別與調度研究
2018-10-18 11:20:14郭秉禮趙寧朱志文寧帆黃善國
通信學報 2018年9期
郭秉禮,趙寧,朱志文,寧帆,黃善國
?
數據中心中面向光互聯的流量識別與調度研究
郭秉禮1,趙寧2,朱志文1,寧帆2,黃善國1
(1. 北京郵電大學信息光子學與光通信研究院,北京 100876;2. 北京郵電大學信息與通信學院,北京 100876)
為了解決數據中心鏈路擁塞問題,依據流量分布與類型的特點,提出了基于光互聯架構的流量識別和調度方案,即HCFD(host-controller flow detection),旨在識別出對網絡性能影響較大的大象流。利用SDN控制器下發轉發策略,對網絡中的流量進行合理調度。 HCFD首先在主機端利用Linux內核協議的Netfilter框架實現將超過閾值的數據流進行標記,然后在控制器端利用決策樹分類模型再對標記流進行分類,最后利用光電混合網絡的優勢,實現深度融合的流量適配和切換機制。HCFD方案整合了已有方法的優勢進行大象流識別,同時保證了識別的實時性、準確性以及流信息的全面性。實驗與仿真結果顯示,在此方案場景下,能有效緩解網絡擁塞情況,充分利用網絡帶寬,減少數據端到端時延,降低分組丟失率。
光互聯架構;流量識別;軟件定義網絡;Linux內核
1 引言
數據中心(DC, data center)作為云計算提供服務的主要基礎設施,集中了大量的數據、存儲資源及提高數據運行效率的計算資源,其通過網絡設備(高速鏈路、路由器等)進行互連,為各種基礎服務提供支持。數據中心在未來的互聯網服務領域扮演著舉足輕重的作用。近年來,在大量涌現的云應用的推動下,如實時視頻、搜索引擎、Map-Reduce計算和虛擬機遷移等,使數據中心流量呈飛速增長態勢。思科2018年2月發布的年度云產業調研報告中預測[1],到2021 年全球云數據中心流量將達到每年20.6 ZB,比2016年的每年6.8 ZB增長3倍。海量的數據以及復雜多變的業務對數據中心網絡流量管理提出了巨大的挑戰。現有數據中心網絡(DCN, data center network)流量工程機制已經無法快速應對突發多變的流量形式,已有的研究成果[2]表明,86%的數據中心的鏈路因為突發的高帶寬的數據流易而出現短暫的擁塞。網絡的擁塞直接導致大量數據分組丟失、網絡吞吐量下降、搜索時延變長、QoS質量無法保證等問題。為了解決數據中心的流量問題,首先,對網絡管控層來說,需要為數據中心的流量制定合理的流量調度策略。研究表明,數據中心雖然會產生巨大數目的流量,但是整體的網絡狀況是由少數的持續時間長的大流,也被稱為大象流[2-3](此處定義突發的高帶寬的流量為大象流)所影響。從高效管理網絡的角度考慮,控制器沒有必要處理所有數據流的調度,只集中于對網絡性能有重要影響的流操作。因此流量識別,尤其是對大象流的識別,就變得十分重要,通過轉移少數突發的高帶寬流量到空閑的通信鏈路上,能夠有效緩解網絡擁塞情況,充分利用網絡帶寬,減少時延。同時,近年來,許多基于光電路交換、光分組、光突發交換的數據中心內網絡結構被提出。如混合光電交換網絡架構通過集中式控制器對光鏈路的調整進行流量調度,一些大容量、持續時間長的大流(即大象流)會被引流到光網絡上進行傳輸,而一些小數據量,對時延要求高的小流(老鼠流)仍采用電交換設備進行轉發。基于光交換的混合光電網絡一方面可以提供快速通路shortcut 進行橫向流量優化,另一方面光交換機的可重配能力也給整個網絡架構帶來了靈活性;不僅能有效利用光網絡的大帶寬、低時延、低功耗等優勢,也保持了電域交換的靈活性。這能有效應對數據中心突發流量。總之,本文擬通過研究對數據中心流量進行識別和標記的方法,結合光電網絡各自的優勢,同時研究深度融合的流量適配與切換機制,可以實現數據流量到光電網絡的高效適配,緩解網絡擁塞情況,充分利用網絡帶寬,減少數據端到端時延。因此,本文實現了主機端的識別模塊和控制端的分類模塊,即在主機端能夠標記超過閾值的大流功能以及控制器上實現了將標記流轉移到光交換路徑上,小流實現默認路由電轉發的調度策略,最終達到網絡流量的負載均衡以及優化。
2 相關的工作
目前的流量識別技術主要有如下2種,一種是基于交換機,在數據流傳輸過程中基于數據量或特征進行識別,如流采樣技術,即在交換機上部署統計模塊或使用第三方代理工具sflow/Netflow,交換機周期性地采集網絡流的數據分組,控制器則分析采樣結果統計得到樣本特征,基于樣本特征推導出網絡整體流量的特征,并制定流表規則,下發到交換機,交換機再依據所制定的流表規則進行數據分組轉發,這些技術或多或少存在著交換機/控制器開銷大,準確度低,實時性差等問題。而另一種是基于主機端進行流識別,如Curtis 等[4]通過設計虛擬機的應用程序(mahout)來收集流信息,Yun等[5]則是通過監控TCP發送隊列的數據量來判斷大象流。2種方法都認定流緩存值超過指定閾值的網絡流為大象流,第二種流量識別技術因為是在主機端識別,而且有閾值設定機制,所以相較于第一種提高了大象流識別的準確性,也加快了識別的速度,減少了交換機/控制器的系統開銷。但是,值得注意的是,有些特定的大象流雖然數據量大,但是帶寬占用并不高且傳輸速率低,因此此類流存在著被Mahout方法誤檢為大象流的風險,而且無法修正判斷結果。而Yun的方法,雖然能通過控制器修正結果,但方法本身存在耗時長的問題,因為忽略了在主機端阻塞TCP隊列帶來的排隊時間。另外,利用機器學習進行流量識別也是一個研究熱點[6-7]。Chao等[6]提出了FlowSeer,一種能夠進行快速、低開銷的流量識別系統,僅通過分析流的前5個數據分組信息,使用預先訓練好的分類模型,就能準確識別出該流的速率和持續時間。該方法的實現較復雜且SDN控制器/交換機的處理開銷較大,因為需要在控制器和交換機上都部署模型,不符合SDN的數據面和控制面的分離思想。如表1所示[8],列舉了目前研究下對大象流的各種識別方法以及性能評估。整合現有研究方法的優勢,本文提出一種新的流量識別方案。
3 HCFD模型
3.1 流量識別方案
為了解決現有研究的不足,在目前光電混合的數據中心架構下,提出一種結合主機終端和控制器端的流量識別方案HCFD(host-controller flow detection)。方案旨在吸取已有研究的優點,高效、實時、快速地識別出大象流。并有效地利用光電網絡的優勢,實現深度融合的流量適配和切換機制。光電混合架構的流量識別方案如圖1所示。
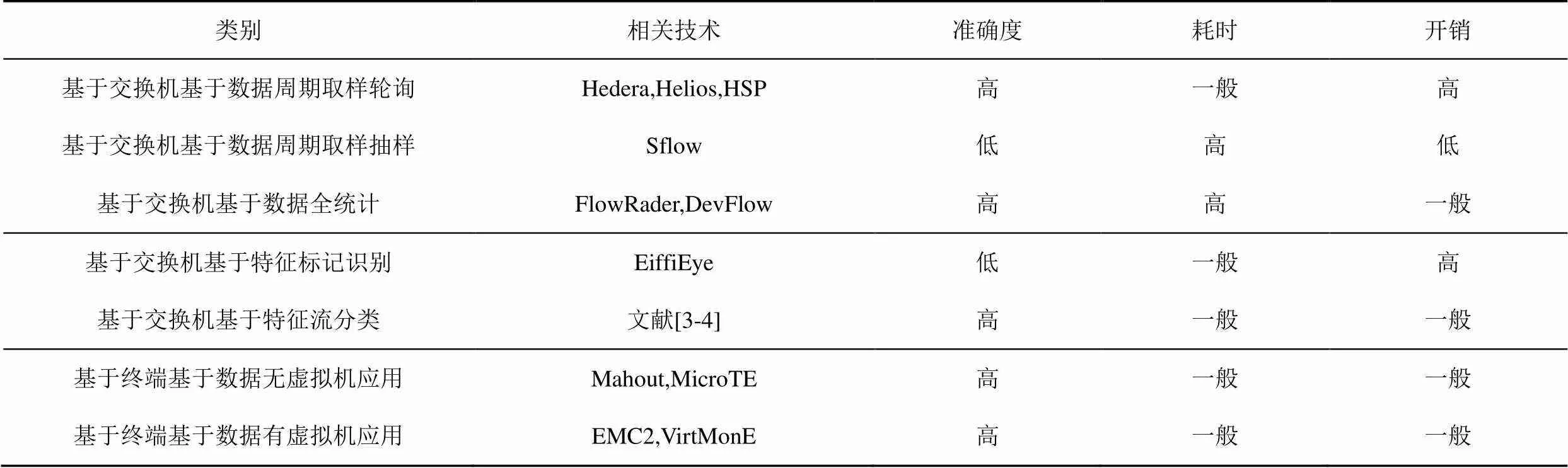
表1 不同的大象流識別方法性能比較
方案由主機端模塊和控制器端模塊組成。通過在主機端配置監控模塊起到流量預判斷的作用,標記出數據量超過閾值的流,即可能成為大象流的數據流,這一步能夠過濾掉大多數的小流,減小交換機的識別開銷。因為交換機只需要專門處理被標記過的流。在控制器端的分類模塊,能夠分類得到標記流的帶寬范圍,然后制定轉發策略,將大流轉移到光網絡傳輸,而小流默認在電網絡中傳輸,這樣就能滿足大流的帶寬需求,也能滿足小流的時延需求,同時避免了鏈路擁塞[9]。
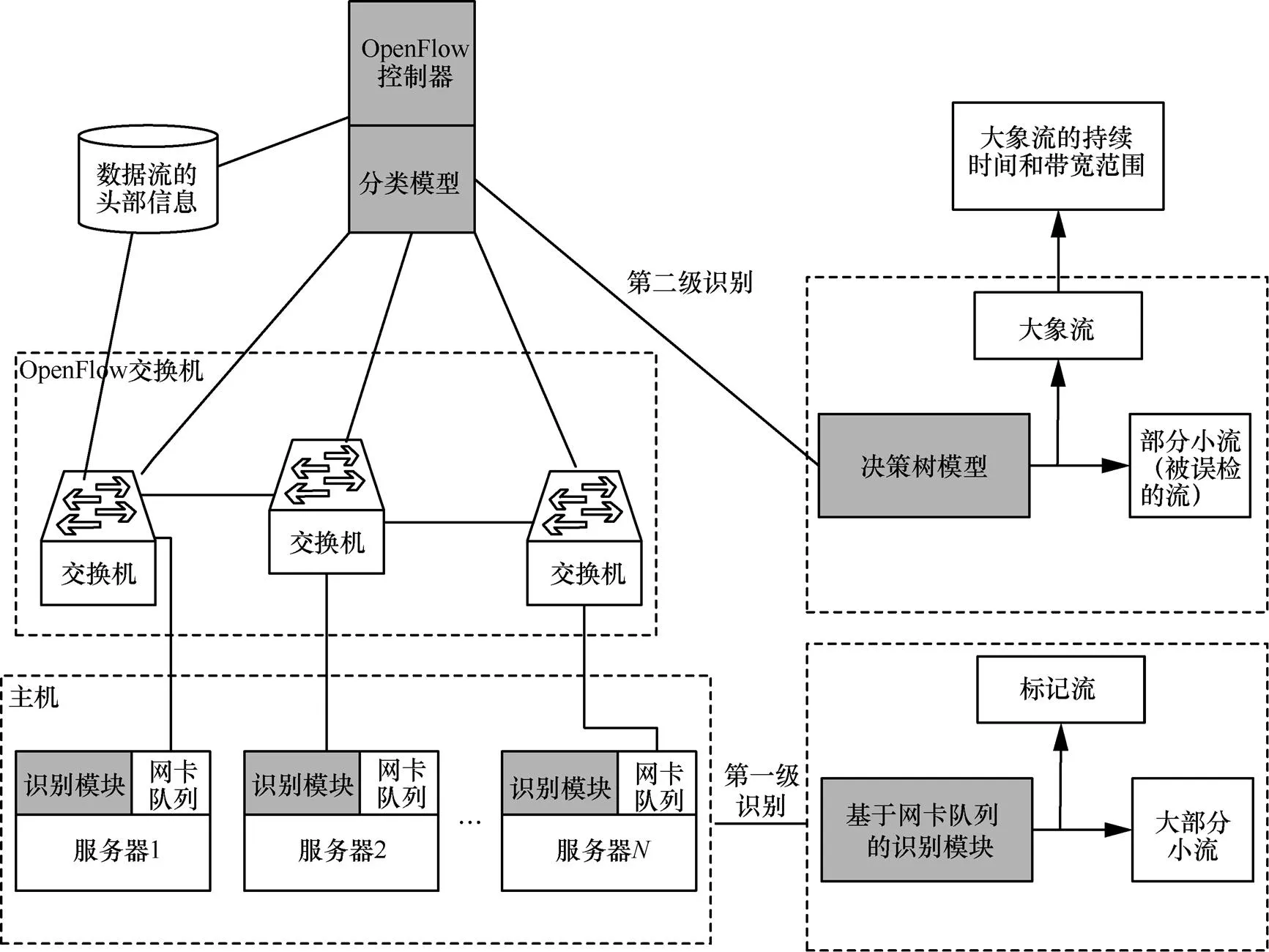
圖1 光電混合架構的流量識別方案
3.2 主機端模塊
Linux內核協議棧為網絡開發者提供了大量的系統調用和函數庫,如其中的libnetfilte_queue庫。應用層可以通過NFNETLINK與內核進行交互,直接性地截獲內核每個數據分組,并在應用層對數據分組進行邏輯處理,然后將裁決結果返回給內核。主機端模塊如圖2所示。
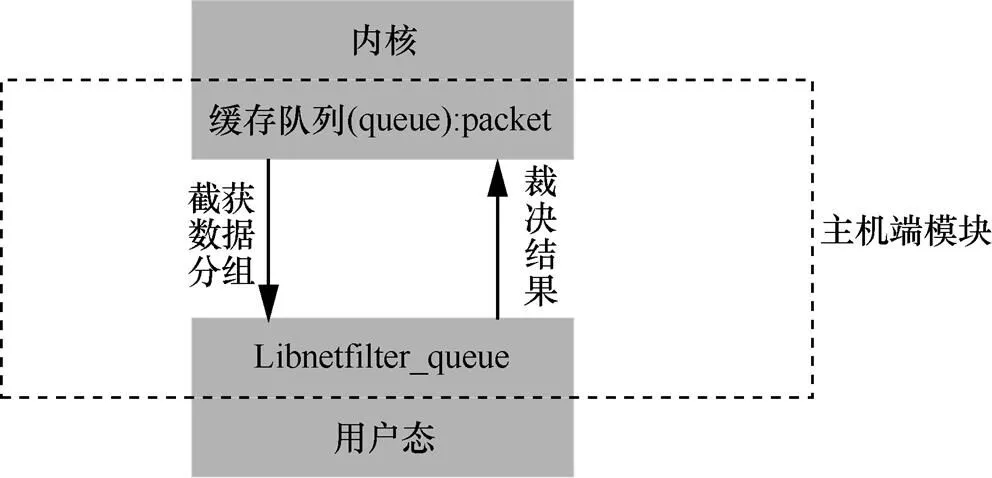
圖2 主機端模塊
具體實現上,用戶態進程thread()利用libnetfilter_queue庫從內核緩存的隊列中截獲的數據分組,將數據分組的IP頭部信息,通過散列函數映射成值,將作為一條流的唯一標識,然后將數據分組的數據負載部分作為[10]。最后將<,>保存在散列表內(鏈表數組)。如果新來的數據分組所在的流已經在散列表中,則將新來的數據分組的值放入舊流中進行更新(原值加上新來的數據分組的值),反之,則新建一條流表項。在用戶態進程持續處理每個數據分組的過程中,如果當某條流的數據量超過設定閾值,就對該流的ToS字段標記,視為標記流。如圖3所示,在代碼實現階段利用libnetfilter_queue庫提供的各種函數,第一步初始化,生成handler,接著綁定AF_INET協議簇,指定數據分組緩存隊列,并調用nfd_handle_packet()取得每個數據分組,實現邏輯部分,再利用回調函數通知內核,內核依據裁決結果,選擇對數據分組繼續轉發,然后退出程序。

圖3 Libnetfilter_queue處理數據分組流程
3.3 控制器端模塊
利用OpenFlow控制器端做二級識別。在數據分組傳輸過程中,被標記過的標記流一旦經過交換機,交換機會直接將該流數據分組的IP頭部信息上交給控制器進行處理,而未被標記過的數據流將按照ECMP等價多路徑算法計算出轉發規則而不必通過控制器制定流表項。控制器將拿到的IP頭部信息輸入事先訓練好的分類模型(model),如圖4所示,預測該流的帶寬范圍和持續時間范圍,這里的分類模型采用的是決策樹如圖4所示,是用數據中心內該節點的歷史流量數據進行訓練所得。控制器根據鏈路帶寬情況制定對該流調度策略,并通知給交換機,交換機將按照下發的流表規則轉發后來的被標記的數據流。
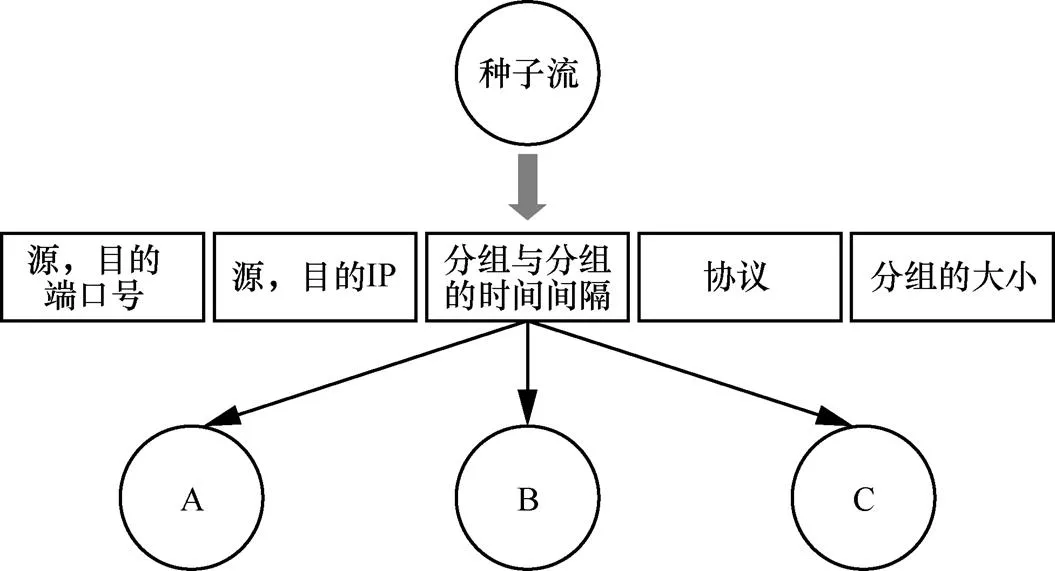
圖4 控制器端分類模型
基于決策樹模型的控制器模塊能夠通過歷史數據預測出標記流的帶寬范圍,比如1~10 MB,10~100 MB以及100 MB以上。對于控制器來說,針對不同帶寬可以制定不同的路由策略,充分利用空閑鏈路,進行數據傳輸。目前研究表明,快速光交換模塊已經被引入數據中心內,安裝在棧頂交換機負責連接各個服務器,傳輸鏈路中的大象流。所以,控制器模塊可以結合快速光交換模塊實現光電路切換。
4 性能測試與分析
針對本文提出的HCFD方案,設計仿真實驗測試其性能。
首先驗證方案中主機端模塊的標記功能。模擬實際網絡環境中的流量分布,利用Iperf在配置好模塊的主機生成1~100 KB大小的文件100個,100 KB~ 1 MB大小的文件10個,1~100 MB的文件5個。默認情況下,閾值設定為1 MB,研究表明[7],數據中心內超過80%流的數據量都不超過1MB。然后將數據源發送給接收端的主機(IP:10.108.48.14),發送端的主機(IP:10.108.49.201)會對超過閾值(1 MB)流的IP數據分組頭ToS字段進行標記,默認標記值為192。然后在接收端服務器利用wireshark進行抓包分析,發現大流的數據分組的ToS字段都被標記成0011xxxx,而小流的數據分組的ToS字段仍然是0000xxxx,如圖5和圖6所示。
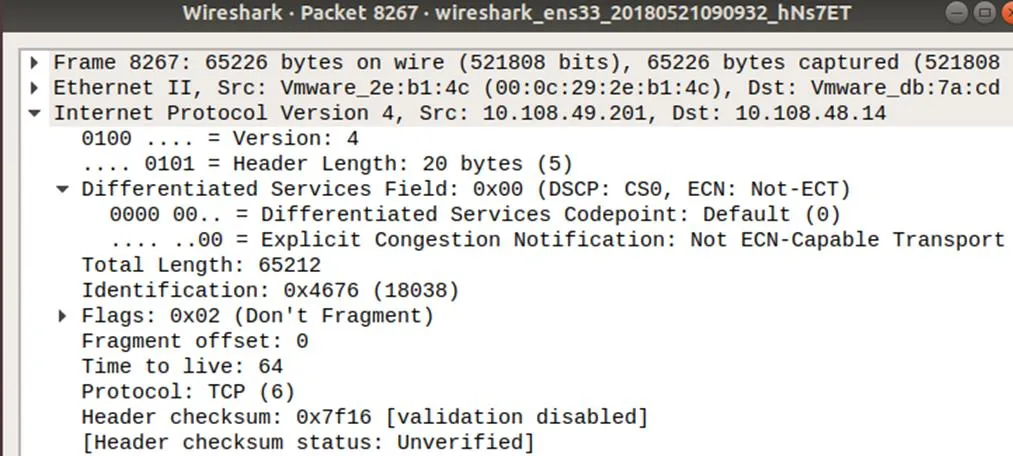
圖5 未被標記的數據分組
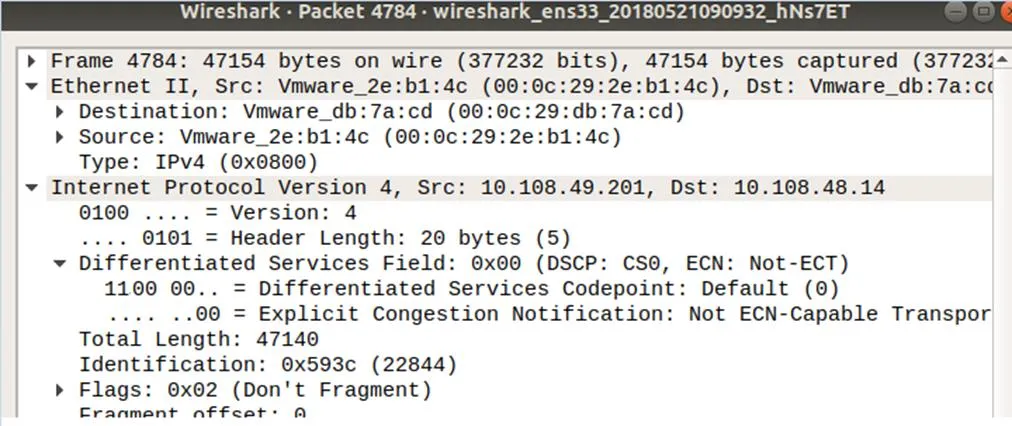
圖6 成功被標記的數據分組
由此可以驗證主機端模塊能夠實現對超過閾值的數據流進行標記的功能。接下來,設計實驗,驗證HCFD方案,在網絡分組丟失率以及端到端傳輸時間的性能表現。
Fat-tree是實際數據中心場景中常見的拓撲結構,這種拓撲結構對于每個源、目的主機間都有多條鏈路可到達,如圖7所示。
按照Fat-tree拓撲結構[11],用Mininet配置如下模擬環境。
所有的主機均部署主機端識別模塊,且與交換機相連。利用Iperf生成符合實際網絡流量分布的數據源。實驗在主機A生成了100條10~100 KB流以及10條1~10 MB的大流(大流會被主機端模塊標記),分組間隔設為1ms,分組的長度設為1 KB,持續時間為10 s[12]。然后將該數據源發送給主機B。這里有2條路徑可以選擇(A—電交換機—B;A—電交換機—光交換機—B),路徑的選擇由控制器決定。

表2 模擬環境配置
實驗分別驗證使用HCFD模型以及未使用HCFD模型2種場景下的端到端時延和分組丟失率情況。在未使用HCFD模型的場景中,數據流將默認按照A—電交換—B路徑傳輸。當在HCFD模型的場景下時,數據量大的流在發出網卡之前,會被主機端模塊將ToS字段標記成192,變成標記流,然后才會發出網卡。
默認情況下,當網絡數據分組途徑交換機時,如果是未標記的數據分組,則將直接被轉發到B主機,如果數據分組IP頭部ToS字段匹配到交換機設定的流表項,交換機便會將標記流的信息通過OpenFlow協議上傳到控制器,控制器經過決策會下發轉發規則到交換機,此處默認下發的規則是將標記流切換到光交換機上,然后再轉發到主機B。
通過實驗數據,可以得到采用HCFD模塊比未采用模塊,數據流的平均端到端時延會減少大約70%和45%。如圖9所示。
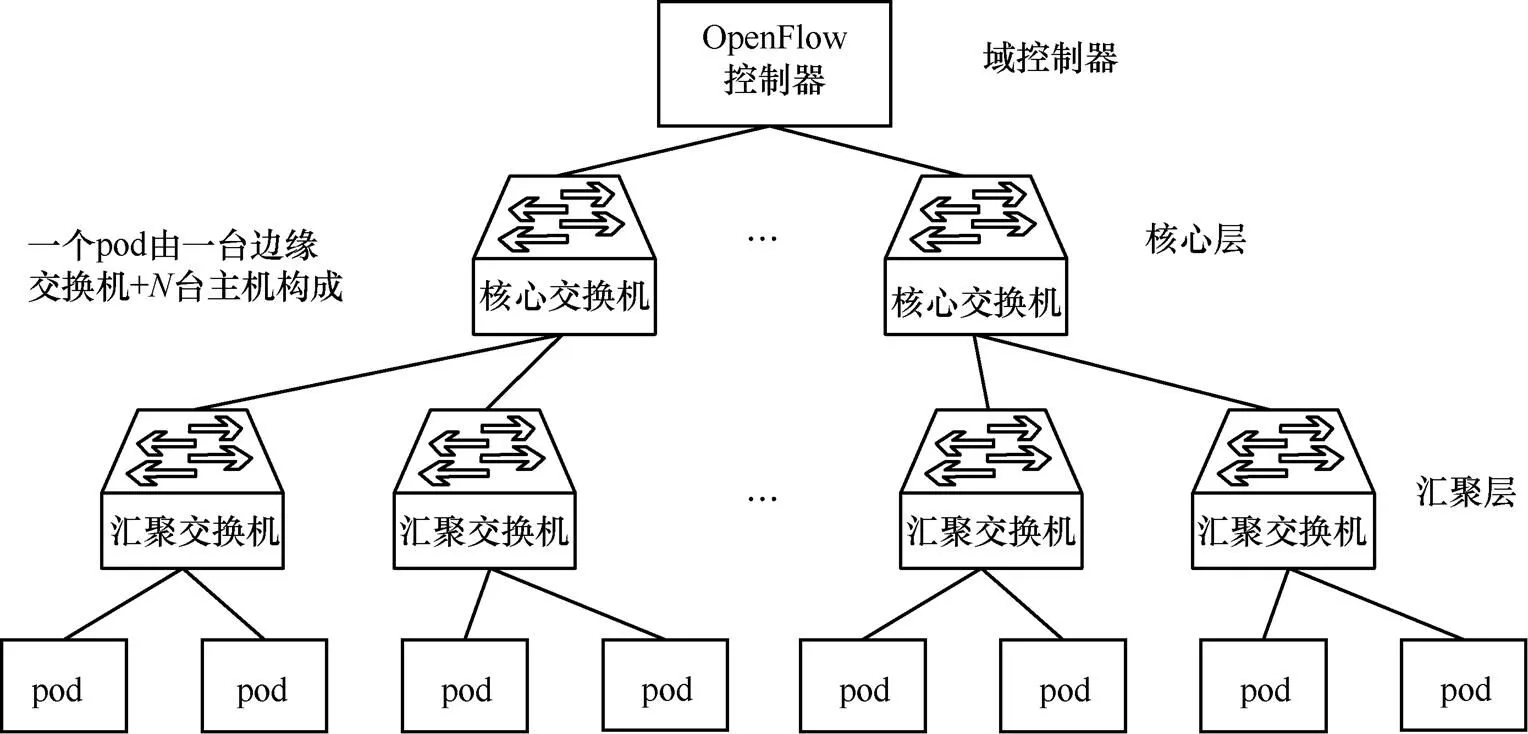
圖7 數據中心Fat-tree拓撲結構
圖8 流91CF調度模型
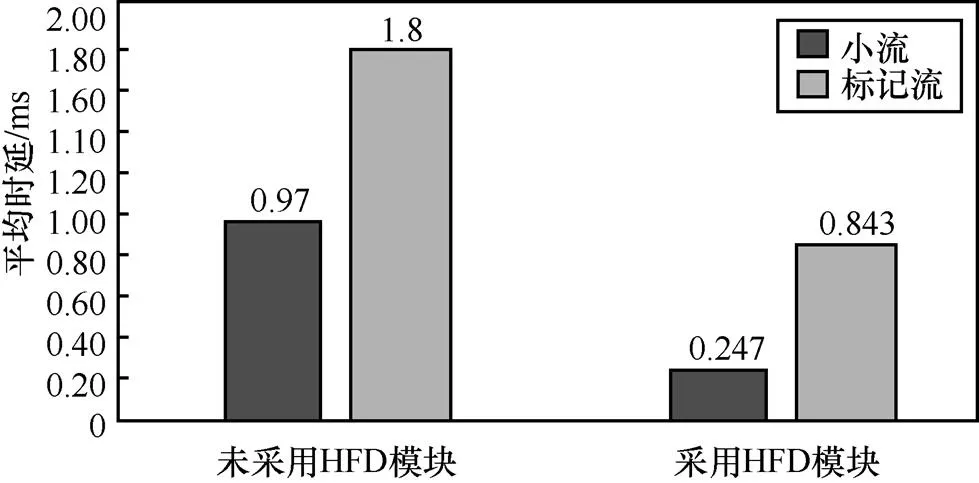
圖9 數據分組的端到端時延情況
而在分組丟失率上,小流和標記流分組發送數目分別是9 093和8 845,在2種場景下進行驗證,時延參數限制為5 ms,發現在未采用HCFD模型的場景下,兩者的分組丟失率分別達到62%和51.8%,而采用HCFD模型的場景下,分組丟失率降低到5%和17%。這說明HCFD模型能夠有效降低網絡分組丟失率。如圖10所示。
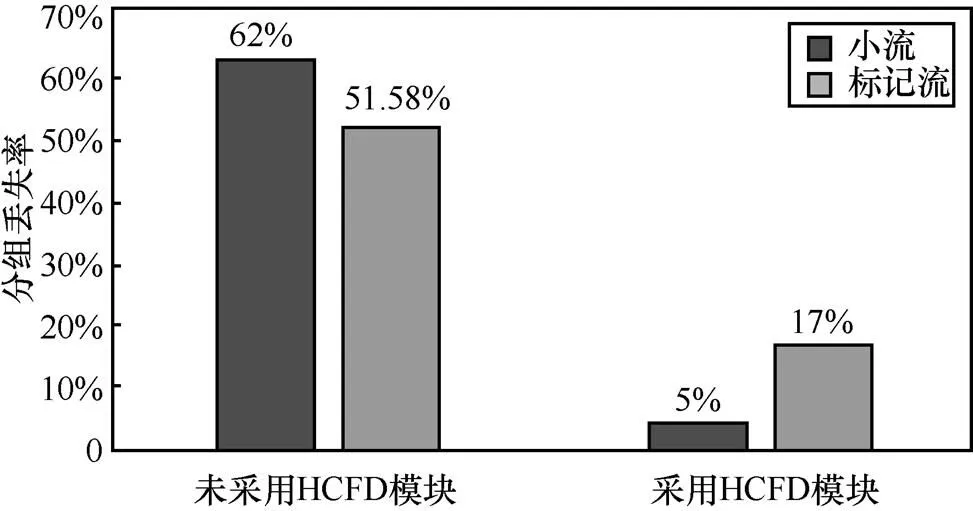
圖10 數據流的分組丟失率
通過控制大流的分組發送速率即分組發送時間間隔,單位為ms,來驗證大流和小流在接收端的時延變化。如圖11和圖12所示,當設置一組分組發送間隔,使大流的發送速率逐漸增加,可以看出有無模塊下數據流的時延變化情況,加載模塊的場景整個平均時延上都低于未加載模塊的場景,且小流的平均時延也大幅度地降低并保持穩定(0.247 s)(此處設置了一定的網卡緩存隊列長度,當數據分組過多就會導致大量分組丟失,時延也會有較大幅度上升。

圖11 未采用模塊的數據流時延情況

圖12 采用模塊的數據流時延情況
這種方案相較于Curtis等[4]提出的Mahout主機端識別技術,不需要過高的大象流閾值(Mahout:10 MB)設定,這樣便使處理的數據量更小,速度也更快,而且整體主機端開發難度會更簡單,從代碼實現上,不需要過多修改內核協議。同時,相比Chao等[6]的FlowSee和Huang等[7]的Application-Round的方案,他們需要在交換機上部署比如C4.5決策樹模型進行預識別,然而本方案不需要交換機參與做分類識別,交換機只需負責基本的數據轉發功能,更滿足SDN邏輯面與數據面解耦合的思想。而且,HCFD方案本身的準確度和速度預期也能達到目前高速網絡流的要求
5 結束語
本文設計了一個快速、低開銷大象流識別以及調度模塊,能夠在主機端標記大象流,并且讓控制器在識別出鏈路中的標記流之后進行分類,基于全局的流量分布情況,合理地選擇路徑,采取光電切換的流量調度策略對大流進行處理,將大流重路由到其他的路徑,以避免網絡擁塞和提高網絡鏈路利用率。
[1] CISCO. Cisco global cloud index: forecast and methodology, 2015-2020[R]. SanJose: Cisco Public, 2016.
[2] SRIKANTH K, SUDIPTA S, ALBERT G, et al. The nature of data center traffic: measurements & analysis[C]//The 9th ACM SIGCOMM Conference on Internet Measurement (IMC '09). 2009: 202-208.
[3] GREENBERG A, HAMILTON J R, JAIN N, et al. VL2: a scalable and flexible data center network[J]. Communications of the ACM, 2009, 54(4): 95-104.
[4] CURTIS A R, KIM W, YALAGANDULA P. Mahout: low-overhead datacenter traffic management using end-host-based elephant detection[C]// IEEE INFOCOM. 2011:1629-1637.
[5] 嚴軍榮,葉景暢,潘鵬.一種大象流兩級識別方法[J].電信科學,2017,33(03):36-43. YAN J R,YE J C, PAN P. A two-level method for elephant flow identification[J]. Telecommunications Science,2017, 33(3):36-43.
[6] CHAO S C, LIN K C J, CHEN M S. Flow classification for software-defined data centers using stream mining[C]//IEEE Transactions on Services Computing.
[7] HUANG Y H, SHIH W Y, HUANG J L. A classification-based elephant flow detection method using application round on SDN environments[C]//2017 19th Asia-Pacific Network Operations and Management Symposium (APNOMS).2017:231-234.
[8] WANG B, SU J. A survey of elephant flow detection in SDN[C]// International Symposium on Digital Forensic and Security. 2018:1-6.
[9] 蔡岳平,樊欣唯,王昌平.光電混合數據中心網絡負載均衡流量調度機制[J].計算機應用與軟件,2017,34(08):145-150+166. CAI Y P, FAN X W, WANG C P. Load balance traffic scheduling mechanism in an optical-electrical hybrid data center network[J]. Computer Applications and Software, 2017,34(8):145-150+166.
[10] RAN B B, EINZIGER G, FRIEDMAN R, et al. Optimal elephant flow detection[J]. IEEE INFOCOM .2017: 1-9.
[11] 羅軍舟, 金嘉暉, 宋愛波, 等. 云計算: 體系架構與關鍵技術[J]. 通信學報, 2011, 32(7): 3-21.LUO J Z, JIN J H, SONG A B, et al. Cloud computing: architecture and key technologies[J]. Journal on Communications, 2011, 32(7): 3-21.
[12] GANG D, ZHENG H G, HONG W. Characteristics research on modern data center network [[J]. Journal of Computer Research and Development, 2014, 51(2): 395-407.
Research on traffic identification and scheduling based on optical interconnection architecture in data center
GUO Bingli1, ZHAO Ning2, ZHU Zhiwen1,NING Fan2, HUANG Shanguo1
1. Institute of Information Photonics and Optical Communication, Beijing University of Posts and Telecommunications, Beijing 100876, China 2. School of Information and Communication Engineering, Beijing University of Posts and Telecommunications, Beijing 100876, China
In order to solve the data center link congestion problem, based on the characteristics of the flow distribution and flow types, a flow identification and scheduling scheme based on optical interconnect structure, named HCFD (host-controller flow detection), was proposed to identify the elephant flow which has a large impact on the network performance, and use the SDN controller to make forward strategy, and schedule the network traffic reasonably. The implementation of the scheme was to use the Netfilter framework in Linux kernel protocol on the host side to mark the flow that exceeds the threshold amount. Then, the classification model was used in the controller side to classify the marked flow. Finally, the appropriate forwarding strategy was developed based on the above results. With the advantage of the photoelectric network, mechanisms of flow depth fusion and switching could be realized. The scheme which integrates the advantage of the existing research results, was expected to identify elephant flow more accurately and comprehensively. It can effectively alleviate the network congestion, make full use of network bandwidth, reduce end-to-end delay and packet loss rate.
optical interconnection architecture, traffic identification, software define network, Linux kernel
TP393
A
10.11959/j.issn.1000?436x.2018161
郭秉禮(1982-),男,山西忻州人,北京郵電大學講師,主要研究方向為網絡存儲、并行與分布式系統等。

趙寧(1995-),女,四川南充人,北京郵電大學碩士生,主要研究方向為SDN、流量工程。
朱志文(1994-),男,安徽合肥人,北京郵電大學碩士生,主要研究方向為SDN、數據中心網絡。

寧帆(1962-),女,吉林長春人,北京郵電大學教授,主要研究方向為通信系統與網絡的理論與應用、教學模式等方面。
黃善國(1978-),男,山東濟南人,博士,北京郵電大學教授,主要研究方向為數據布局、并行與分布式系統。
2018?05?24;
2018?08?27
