面向網(wǎng)站圖像數(shù)據(jù)的安全分析系統(tǒng)①
2018-10-24 11:06:18王賽賽
計算機系統(tǒng)應(yīng)用 2018年10期
王賽賽, 張 磊, 李 健
1(中國科學院 計算機網(wǎng)絡(luò)信息中心, 北京 100190)
2(中國科學院大學 計算機與控制學院, 北京 100049)
隨著微博、知乎等網(wǎng)絡(luò)大眾媒體的出現(xiàn)與流行,互聯(lián)網(wǎng)用戶規(guī)模不斷擴大.截至2017年6月, 中國網(wǎng)民規(guī)模已達7.51億, 互聯(lián)網(wǎng)普及率約為54.3%.人們分享信息的方式開始從文字、音頻向圖像、視頻轉(zhuǎn)換,網(wǎng)絡(luò)信息結(jié)構(gòu)呈復雜化趨勢.互聯(lián)網(wǎng)普及率的不斷提高, 雖然使得人民生活更加便利, 但也帶來諸多網(wǎng)絡(luò)安全問題.網(wǎng)絡(luò)信息中出現(xiàn)很多涉及暴恐、色情和危害國家及公共安全的違規(guī)內(nèi)容, 嚴重影響用戶體驗, 并且對社會風氣和人民生活產(chǎn)生惡劣影響.違規(guī)文字較易檢測, 目前已有成熟的應(yīng)用軟件工具.與文字相比, 圖像內(nèi)容的檢測更為復雜.不法分子試圖將違規(guī)內(nèi)容添加在圖像中以逃脫網(wǎng)絡(luò)過濾系統(tǒng)的審核.網(wǎng)站運營人員很早就認識到網(wǎng)站圖像數(shù)據(jù)安全問題的重要性, 通常投入大量人力物力對圖像數(shù)據(jù)進行審核管理, 這在一定程度上保證了圖像數(shù)據(jù)的合法性, 但不法分子非法攻擊網(wǎng)站、篡改圖像數(shù)據(jù)時, 網(wǎng)站運營人員通常無法做出及時的處理.
因此, 為了能快速審查新上傳至網(wǎng)站的圖像數(shù)據(jù)是否合法并且監(jiān)測網(wǎng)站上已存在的圖像數(shù)據(jù)的合法性,本文提出了一種面向網(wǎng)站圖像數(shù)據(jù)的安全分析系統(tǒng),首先采用基于深度學習的圖像內(nèi)容檢測算法對新上傳的圖像內(nèi)容進行檢測以保證數(shù)據(jù)的合法性;其次利用基于文件監(jiān)測程序的事件觸發(fā)技術(shù)和外掛輪詢技術(shù)實現(xiàn)周期性監(jiān)測圖像數(shù)據(jù)是否被篡改.
1 研究現(xiàn)狀
雖然目前針對違規(guī)圖像還沒有成熟、高效和系統(tǒng)的解決方案, 但是很多研究者針對違規(guī)文本圖像、色情圖像和暴恐圖像的檢測做了大量研究, 積累了很多經(jīng)驗.
針對違規(guī)文本圖像, 其難點在于準確地識別圖像內(nèi)所含文本信息.惠普公司針對圖像中的文本識別, 研發(fā)了Tesseract -OCR算法[1], 之后谷歌對該算法進行了改進, 算法對英文識別效果較好.但識別包含漢字的圖像時, 即使引入中文字庫包chi_sim.traineddata, 中文的識別率依然較低.針對色情圖像, Jones MJ 等研究了基于統(tǒng)計直方圖的貝葉斯分類算法[2], 采用直方圖統(tǒng)計膚色像素點的像素值, 進而建立膚色區(qū)域, 并利用膚色建模, 將膚色區(qū)域及人體形狀性質(zhì)作為參數(shù), 采用貝葉斯分類器對其分類.該方法簡單易行, 運算效率高, 但是具有相近像素值的像素點可能會被誤判為膚色區(qū)域,因此可能產(chǎn)生誤差, 造成分類錯誤.針對暴恐圖像,Paul等開發(fā)了基于Haar-like特征的Adaboost分類器算法[3], 該算法最初應(yīng)用于人臉識別領(lǐng)域.利用積分圖像方法和Adaboost分類器的特征篩選特性來提取圖像特征, 再保留最有效特征, 這樣可以減少運算復雜度,同時也可提高圖像檢測準確率.由于暴恐圖像特征不如人臉特征明顯, 所以提取的圖像特征并不理想, 導致檢測準確率不高.中央民族大學研究了基于視覺語義概念的暴恐視頻檢測的算法[4], 其關(guān)鍵技術(shù)是利用視覺語義概念構(gòu)建暴恐圖像詞頻特征, 并構(gòu)建視覺語義概念直方圖, 然后采用SVM分類器進行分類檢測, 根據(jù)輸出結(jié)果判定是否為暴恐圖像.該算法提出根據(jù)視覺語義概念把特征分為八種類型, 若圖像中包括任何一種類型的特征即判定為暴恐圖像, 從而增大分類結(jié)果準確率.
以上均為針對特定單一違規(guī)圖像內(nèi)容的研究, 很多學者也研究了同時審查違規(guī)文本圖像、色情圖像和暴恐圖像的檢測系統(tǒng).其中, 比較有代表性的系統(tǒng)有:華南理工大學學者研究了基于歷史IP過濾的防御實驗系統(tǒng)[5], 每次將截獲到的IP地址更新到IP地址庫中以增強系統(tǒng)的防御能力.該方法操作簡便、高效, 但缺乏實時性.東北大學學者研究了基于語義的智能防火墻系統(tǒng)[6], 利用Daubechies小波與正則中心矩相結(jié)合的方法進行特征提取, 然后利用基于語義的特征向量匹配技術(shù)判別圖像內(nèi)容是否違規(guī).該方法具有一定的通用性, 但不具備信息反饋功能, 缺乏自適應(yīng)性.在基于語義特征的基礎(chǔ)上, 將動態(tài)知識庫和規(guī)則庫一起作為特征向量匹配的參考因素, 西南交通大學學者提出了基于知識的智能網(wǎng)絡(luò)安全監(jiān)測系統(tǒng)[7], 該方法具有信息反饋和知識導航功能, 但采用小波分析和特征不變量的方法進行特征提取, 得到的特征維度較低, 不能很好地表達特征.
以上三種系統(tǒng)均采用傳統(tǒng)機器學習方法提取特征,而傳統(tǒng)機器學習模型均為淺層結(jié)構(gòu), 并且大多依賴先驗知識, 擅長分析維度較低的數(shù)據(jù).面對高維的圖像數(shù)據(jù), 運用具有深層結(jié)構(gòu)的深度學習模型, 自動學習提取高維特征向量, 更有效率, 同時表達能力也更強.因此,本文采用基于深度學習的圖像內(nèi)容檢測引擎來完成新圖像數(shù)據(jù)的審核工作.
網(wǎng)頁防篡改技術(shù)[8]是保障網(wǎng)頁內(nèi)容安全的一種技術(shù), 目前應(yīng)用較多的技術(shù)有:1)外掛輪詢技術(shù):基于文件檢測程序, 以輪詢方式將被監(jiān)控文件與相對應(yīng)的文件比較, 然后判定文件是否被篡改.2)事件觸發(fā)技術(shù):利用操作系統(tǒng)的文件系統(tǒng)或驅(qū)動程序接口, 在網(wǎng)頁文件被修改時進行合法性檢查.外掛輪詢技術(shù)實現(xiàn)簡單,不需要有管理員權(quán)限且具有自我防護能力, 但輪詢時間周期設(shè)定過長, 則缺乏時效性;若輪詢周期設(shè)定過短,頻繁調(diào)度則降低服務(wù)器性能.事件觸發(fā)技術(shù)具有很強的自我防護能力, 能夠防范連續(xù)篡改攻擊, 能夠?qū)崟r檢測事件是否發(fā)生, 服務(wù)器負載低, 因而對網(wǎng)站訪問性能影響較小, 但需要對所監(jiān)測網(wǎng)站的文件系統(tǒng)有一定的訪問控制權(quán)限.本系統(tǒng)嘗試將上述兩種網(wǎng)頁防篡改技術(shù)應(yīng)用到網(wǎng)站圖像數(shù)據(jù)防篡改上.
2 系統(tǒng)總體架構(gòu)
系統(tǒng)采用功能模塊化設(shè)計結(jié)構(gòu), 降低系統(tǒng)復雜度,使系統(tǒng)設(shè)計、調(diào)試和維護等操作簡單化, 具有更多靈活性, 便于后續(xù)根據(jù)實際需求進行調(diào)整或擴展.本系統(tǒng)中, 圖像內(nèi)容檢測引擎針對特定違規(guī)圖像內(nèi)容分別運用不同的算法進行檢測, 力求達到最高的運算效率和識別精度, 并且加入圖像防篡改模塊保證網(wǎng)站圖像數(shù)據(jù)的合法性.系統(tǒng)總體架構(gòu)如圖1所示.
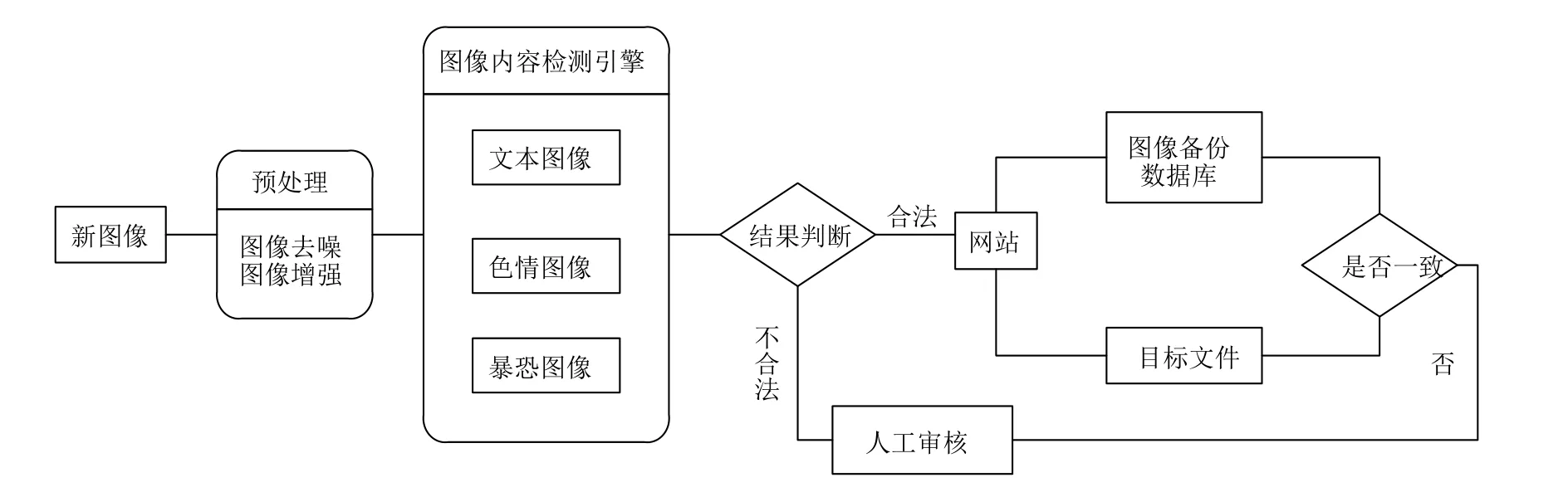
圖1 面向網(wǎng)站圖像數(shù)據(jù)的安全分析系統(tǒng)總體架構(gòu)
圖像預(yù)處理模塊:對新圖像進行圖像去噪、圖像邊緣增強等操作, 去除圖像中無關(guān)信息、增強邊緣信息以便增加圖像特征信息的可檢測性.
圖像內(nèi)容檢測引擎模塊:運用深度學習算法對新圖像數(shù)據(jù)進行圖像內(nèi)容檢測, 審查是否存在違規(guī)內(nèi)容.若圖像數(shù)據(jù)合法, 則提取其MD5編碼到圖像備份數(shù)據(jù)庫;否則將圖像數(shù)據(jù)提交給人工審核.該模塊的功能是保證新上傳至網(wǎng)站的圖像數(shù)據(jù)的合法性.
圖像防篡改模塊:利用事件觸發(fā)技術(shù)和外掛輪詢技術(shù)對網(wǎng)站中所有圖像數(shù)據(jù)進行監(jiān)測, 若檢測到圖像數(shù)據(jù)異常, 則移交人工審核.該模塊的功能是監(jiān)測網(wǎng)站中已存在的圖像數(shù)據(jù)合法性.
圖像內(nèi)容檢測引擎模塊和圖像防篡改模塊實現(xiàn)了本系統(tǒng)的核心功能, 下面將對兩個模塊中所用到的關(guān)鍵技術(shù)做具體分析和介紹.
3 關(guān)鍵技術(shù)分析
圖像內(nèi)容檢測引擎包括違規(guī)文本圖像檢測、色情圖像檢測及暴恐圖像檢測三個子模塊.經(jīng)檢測后的圖像數(shù)據(jù), 若結(jié)果判斷為合法, 則將其上傳至正常運營的網(wǎng)站后, 采用網(wǎng)站圖像數(shù)據(jù)防篡改策略對該圖像數(shù)據(jù)進行監(jiān)測, 檢測其是否處于安全狀態(tài).
3.1 違規(guī)文本圖像檢測
文本圖像檢測類似于目標檢測, 先檢測到目標區(qū)域, 然后進行特征提取、特征匹配及結(jié)果輸出.但不同之處在于特征匹配.對于文本檢測, 同一個文本線的多個字符組成一個序列, 線上不同字符可以互相利用上下文信息.本系統(tǒng)采用卷積神經(jīng)網(wǎng)絡(luò)(CNN)對違規(guī)文本圖像進行特征提取, 然后將同一文本線的字符特征輸入到長短時記憶網(wǎng)絡(luò)(LSTM)中進行分析與綜合,最后將分類得到的目標區(qū)域合成文本線并將最終文字作為結(jié)果輸出.這種把CNN和LSTM[9]無縫結(jié)合的方法提高了檢測精度和效率.
違規(guī)文本內(nèi)容檢測模塊可以根據(jù)上述思路自行編碼實現(xiàn), 也可以利用現(xiàn)有開源代碼及開放接口進行定制開發(fā), 本系統(tǒng)采用第二種方式, 具體流程如圖2.首先, 待檢測圖像利用百度AI[10]開放的basicGeneral接口識別出圖像中所含文字.然后, 采用基于TextRank算法的jieba.analyse.textrank接口[11]對其提取關(guān)鍵詞信息.最后, 將提取的關(guān)鍵詞同敏感詞匯庫做匹配.若匹配成功, 則該圖像屬于非法圖像, 返回人工審核;否則繼續(xù)進行色情圖像檢測.其中, 關(guān)鍵詞匹配采用模板匹配[12]與正則表達式相結(jié)合的方法.
3.2 色情圖像檢測
該模塊采用何凱明等人提出的深度殘差網(wǎng)絡(luò)[13]來解決圖像二分類問題, 將訓練圖像數(shù)據(jù)輸入到ResNet網(wǎng)絡(luò)中進行訓練, 最終根據(jù)模型將待檢測圖像數(shù)據(jù)分為合法圖像和非法圖像.考慮到色情圖像數(shù)據(jù)集性質(zhì)問題, 本系統(tǒng)采用雅虎公司開源項目open_nsfw[14]中已訓練完成的resnet_50_1by2_nsfw.caffemodel模型.該模型采用 ImageNet+NSFW(Not Suitable For Work)數(shù)據(jù)集, 首先在 ImageNet 1000 類數(shù)據(jù)集上進行預(yù)訓練, 然后根據(jù)NSFW數(shù)據(jù)集對權(quán)重進行調(diào)整.該方法采用的是pynetbuilder工具生成的resnet50_1by2作為預(yù)訓練網(wǎng)絡(luò).雖然更深層的網(wǎng)絡(luò)或者采用更多濾波器的網(wǎng)絡(luò)可能會提高準確率, 但綜合考慮準確率、訓練時間及參數(shù)問題, 最終選擇resnet50_1by2網(wǎng)絡(luò)作為系統(tǒng)預(yù)訓練網(wǎng)絡(luò), 最后一層為softmax層, 可以輸出圖像在合法、非法兩類中各自的概率值.模型以SFW值(合法圖像類)為判定依據(jù):當SFW值的概率大于0.8 時, 判定該圖像是合法圖像;SFW 值低于 0.2 時, 判定為違法圖像;SFW值處于0.2–0.8之間時, 圖像合法性隨著SFW值減小而降低, 判為不確定圖像.
系統(tǒng)將SFW值大于0.8的合法圖像送入暴恐圖像檢測模塊繼續(xù)檢測, 對于SFW值小于0.8的違法圖像及不確定圖像, 則移交給人工審核.

圖2 違規(guī)文本內(nèi)容檢測模塊流程
3.3 暴恐圖像檢測
根據(jù)視覺語義概念, 可以將暴恐圖像數(shù)據(jù)集分為以下九類:正常圖像、爆炸火災(zāi)圖像、暴亂圖像、血腥圖像、軍事武器圖像、殺人圖像、尸體圖像、暴恐人物圖像以及警察部隊圖像.鑒于傳統(tǒng)機器學習方法擅長分析維度較低的數(shù)據(jù), 而深度學習算法擅長分析高維度的數(shù)據(jù), 本系統(tǒng)采用卷積神經(jīng)網(wǎng)絡(luò)對數(shù)據(jù)集進行特征提取和模型訓練, 判別待檢測圖像分別屬于九類圖像的各自概率值, 最后綜合每類概率得出圖像總概率值, 根據(jù)概率值判定待檢測圖像是否為暴恐圖像.鑒于數(shù)據(jù)集收集比較耗費人力和時間, 最終本系統(tǒng)采用百度AI[11]開放的antiTerror接口對暴恐圖像進行圖像內(nèi)容檢測, 結(jié)果輸出為各項概率值.其中, 合法圖像數(shù)據(jù)的綜合概率值均在0.9以上.
3.4 網(wǎng)站圖像數(shù)據(jù)防篡改策略
圖像防篡改模塊采用事件觸發(fā)技術(shù)[15]或外掛輪詢技術(shù)予以實現(xiàn), 具體技術(shù)原理如圖3所示.當合法圖像上傳到網(wǎng)站時, 自動提取圖像的MD5編碼[16], 并且存儲于圖像備份數(shù)據(jù)庫.隨后可以根據(jù)是否擁有對網(wǎng)站文件系統(tǒng)具有訪問控制權(quán)限而采取不同方式:
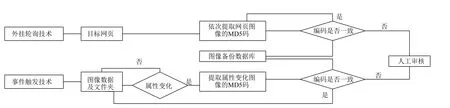
圖3 圖像防篡改模塊流程圖
1) 若有文件系統(tǒng)訪問控制權(quán)限, 可以利用事件觸發(fā)方式對圖像數(shù)據(jù)及文件夾進行實時監(jiān)控, 若圖像文件屬性發(fā)生變化, 則將提取該圖像數(shù)據(jù)的MD5編碼,然后與圖像備份數(shù)據(jù)庫中對應(yīng)圖像的MD5編碼比對,檢測已上傳的圖像數(shù)據(jù)是否被惡意篡改.若MD5編碼不同, 則表示圖像數(shù)據(jù)異常, 應(yīng)將圖像信息反饋給人工審核.本策略同樣適用于非圖像類文件的防篡改.
2) 若無文件系統(tǒng)訪問控制權(quán)限, 則采用外掛輪詢技術(shù)周期性地從外部逐個訪問目標網(wǎng)頁中的圖像數(shù)據(jù),提取圖像數(shù)據(jù)的MD5編碼與真實的圖像數(shù)據(jù)的MD5編碼相比較, 若發(fā)現(xiàn)異常, 則移交人工審核.
4 實驗分析
本次實驗程序主要采用Python語言編寫, 運行在帶有16G顯存容量的Ubuntu 16.04系統(tǒng)的服務(wù)器.新圖像進入圖像內(nèi)容檢測引擎模塊后, 首先進行以下預(yù)處理操作:
1) 利用小波域高斯混合模型[17]對圖像去噪處理.
2) 將圖像統(tǒng)一轉(zhuǎn)換為RGB圖像.
3) 對圖像進行邊緣增強處理.
通過完成圖像去噪、圖像增強等操作以達到去除圖像中無關(guān)信息, 并增強邊緣信息、突出圖像特征的目的.以下為違規(guī)文本圖像和色情圖像檢測的實驗結(jié)果.
4.1 違規(guī)文本圖像內(nèi)容檢測
本次實驗所用圖像均來自合法公開的圖像發(fā)布平臺, 所有圖像總共包括漢字2066個, 英文字母2522個.

表1 Tesseract-OCR 和 basicGeneral方法識別正確率 (%)
從實驗中可以得到結(jié)論:兩種方法對英文識別率均比較高, 其中, basicGeneral方法效果略好于Tesseract-OCR方法.對于漢字的識別, 整體準確率不如英文識別率高, 但basicGeneral方法的準確率明顯高于Tesseract-OCR方法, 本系統(tǒng)中采用basisGeneral方法.
4.2 色情圖像內(nèi)容檢測
實驗所用圖像來自于公開的圖像數(shù)據(jù)集ImageNet[18].圖4(b)是用利用直方圖提取的膚色特征, 根據(jù)貝葉斯分類算法, 判定為非法圖像, 而該圖像顯然為合法圖像,故分類錯誤.而在本系統(tǒng)中, 根據(jù)NSFW算法可計算得到該圖像的SFW值為0.99806279.該值大于0.8, 根據(jù)3.2部分的判別規(guī)則, 算法判別為合法圖像, 分類正確.因此, NSFW算法更適合色情圖像內(nèi)容檢測.
本次實驗從ImageNet數(shù)據(jù)集中隨機選取1165張圖像數(shù)據(jù)作為色情圖像檢測和暴恐圖像檢測的測試圖像數(shù)據(jù)集.其中, NSFW算法將19張合法圖像誤判為非合法圖像, 誤判率為1.63%;暴恐圖像檢測算法將26張合法圖像誤判為非合法圖像, 誤判率為2.23%.綜上, 誤判率均在系統(tǒng)誤差可接受范圍.
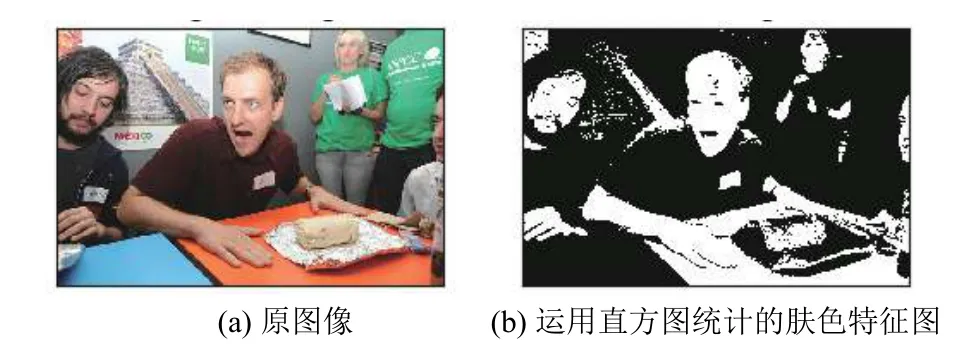
圖4 色情圖像檢測結(jié)果
5 結(jié)束語
本文提出的網(wǎng)站圖像數(shù)據(jù)安全分析系統(tǒng), 不僅可以對圖像內(nèi)容進行檢測, 及時檢測出違規(guī)文本圖像、色情圖像和暴恐圖像等, 而且可以對圖像數(shù)據(jù)進行周期性或者事件觸發(fā)式的監(jiān)測以防止非法篡改, 因此主要包括圖像內(nèi)容檢測引擎模塊和圖像防篡改模塊.圖像內(nèi)容檢測引擎模塊針對三類違規(guī)圖像內(nèi)容分別采用開源的 basicGeneral 接口、NSFW算法以及antiTerror接口進行定制開發(fā), 綜合了各個算法對不同圖像的識別優(yōu)勢, 得到了較好的集成效果, 違法圖像識別準確率較高, 可以檢出大部分非法圖像, 同時輔以對不確定圖像的人工審核, 兼顧了檢測的時效性和準確性, 使該系統(tǒng)具備了較高的實用性.圖像防篡改模塊可以監(jiān)測圖像數(shù)據(jù)是否安全, 即使發(fā)生黑客入侵網(wǎng)站并篡改圖像內(nèi)容, 也可以及時發(fā)現(xiàn)并妥善處理.
猜你喜歡
科學大眾(2022年11期)2022-06-21 09:20:52
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
臺聲(2016年2期)2016-09-16 01:06:53
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2014年1期)2014-02-28 21:59:13
