基于通用背景?聯合估計(UB-JE)的說話人識別方法
2018-11-01 08:02:18汪海彬郭劍毅毛存禮余正濤
自動化學報 2018年10期
汪海彬 郭劍毅 毛存禮 余正濤
語音是人們用來交流和溝通的最自然、最直接的方式之一,因此,語音是一種重要的生物特征.作為一種重要的身份鑒定技術,目前說話人識別[1?2]已廣泛運用于國家安全、司法鑒定、電話銀行及門禁安全等領域.與此同時,說話人識別仍有許多問題需要解決,例如信道多樣化的識別、噪聲對識別性能的影響等,這就涉及到對說話人識別算法的研究.
2000年左右,Reynolds等[3]提出的高斯混合模型–通用背景模型 (Gaussian mixture modeluniversal background model,GMM-UBM),以其特有的良好性能和靈活的模型結構,降低了說話人模型對訓練集的依賴,迅速成為當時說話人識別領域的主流方法之一,推動了整個領域的發展[4?5].由GMM-UBM 的思想可知,在高斯混合函數的均值超向量(Gaussian mixture model supervector,GSV)中包含有說話人語句的所有信息.根據該思想,Kenny等[6?7]提出了聯合因子分析方法(Joint factor analysis,JFA),認為說話人語句中包含說話人信息和信道信息兩部分,因此,GSV又可被分解為說話人和信道兩部分.Dehak[8]研究發現,在對JFA進行信道補償時,信道空間存在掩蓋和重疊問題,信道空間中不可避免地包含了一部分說話人的信息,即不能準確地對說話人與信道分別建模.在此基礎上,Dehak等[9?11]提出了i-vector方法,該方法認為對GSV進行處理時不應該區分說話人和信道,而應該把它們看成一個整體,即總變化空間.但是,在總變化空間中存在信道失配問題,Dehak等[9]又提出了一些信道補償技術:線性鑒別分析(Linear discriminant analysis,LDA)和類內協方差規整(Within class covariance normalization,WCCN)等.近幾年來,基于i-vector方法的說話人識別模型(圖1)明顯提升了說話人識別系統的性能,是目前說話人識別領域中最熱門的建模方法之一[12?13].在美國國家標準技術局組織的說話人評測(The National Institute of Standards and Technology speaker recognition evaluation,NIST SRE)中,該方法的性能明顯優于GMM-UBM[3]和GSV-SVM(Gaussian mixture model supervectorsupport vector machine)[14?15]等方法,是處于國際研究前沿的一種說話人識別方法.
i-vector是一種有效的因子分析方法,其中總變化因子空間的估計是基礎和關鍵.為了得到性能更好的i-vector方法,本文結合常規的因子分析方法提出了一種新的總變化因子空間估計算法,即通用背景–聯合估計(Universal background-joint estimation algorithm,UB-JE)算法.首先,針對說話人識別任務中正負樣本分布不平衡問題,本文借鑒GMM-UBM 的思想,結合i-vector方法,通過大量的非訓練數據來訓練形成一個包含大量說話人的通用背景初始總變化空間,從而提出了總變化矩陣通用背景(Universal background,UB)算法;其次,在i-vector模型中由于均值不能很好地與更新后的總變化因子空間耦合,我們根據因子分析理論結合文獻[16?17]提出了一種總變化矩陣聯合估計(Joint estimation,JE)算法;最后,將兩種算法相結合得到通用背景–聯合估計(UB-JE)算法.
本文結構如下:第1節介紹了因子分析方法的理論,主要是高斯混合模型超向量、聯合因子分析方法和總變化因子分析方法;第2節提出通用背景–聯合估計總變化矩陣估計算法,包含兩種總變化因子空間估計算法,即通用背景算法和聯合估計算法;第3節是針對提出的三種總變化因子空間估計算法的實驗與結果分析;第4節是結論.
1 因子分析方法理論
1.1 高斯混合模型超向量
由于GMM-UBM[3]是先用一些無關數據訓練一個通用背景模型(Universal background model,UBM),然后利用訓練數據對該UBM 進行數據更新,得到代表單個說話人的高斯混合模型(Gaussian mixture model,GMM).按照GMM-UBM 模型的原理,說話人所有的語音信息都包含在由說話人GSV[14?15]中(GSV形成過程見圖2).一般情況下,在說話人識別領域里常用的超向量是均值超向量,因此,下文中的超向量如果沒有特別指明,均默認為均值超向量.
1.2 聯合因子分析方法
隨著科技的發展,語音可以通過多種渠道獲取,在說話人識別任務中相應地產生了信道失配問題.Kenny等[6?7]認為一段語音信號中應包含說話人信息和信道信息兩部分,因此對說話人進行識別時,GSV應該被分解為說話人和信道兩部分,分別對它們建立模型,然后去除無關信息(信道模型),留下有用信息(說話人模型),然后再進行估計,這就是JFA的思想.
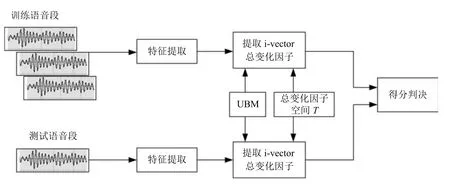
圖1 i-vector說話人識別系統Fig.1 i-vector speaker recognition system
根據Kenny提出的JFA思路,假設有一個混合度為C的GMM-UBM 模型,訓練時的語音特征參數為F維,則形成一個FC維的均值超向量,則該超向量可表示為

圖2 GMM均值超向量的形成過程Fig.2 The formation process of GMM mean super vector
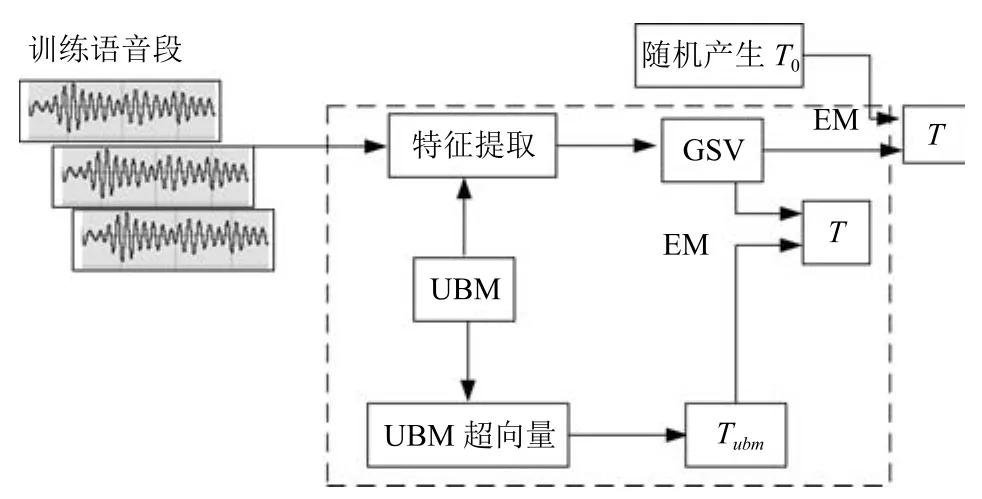
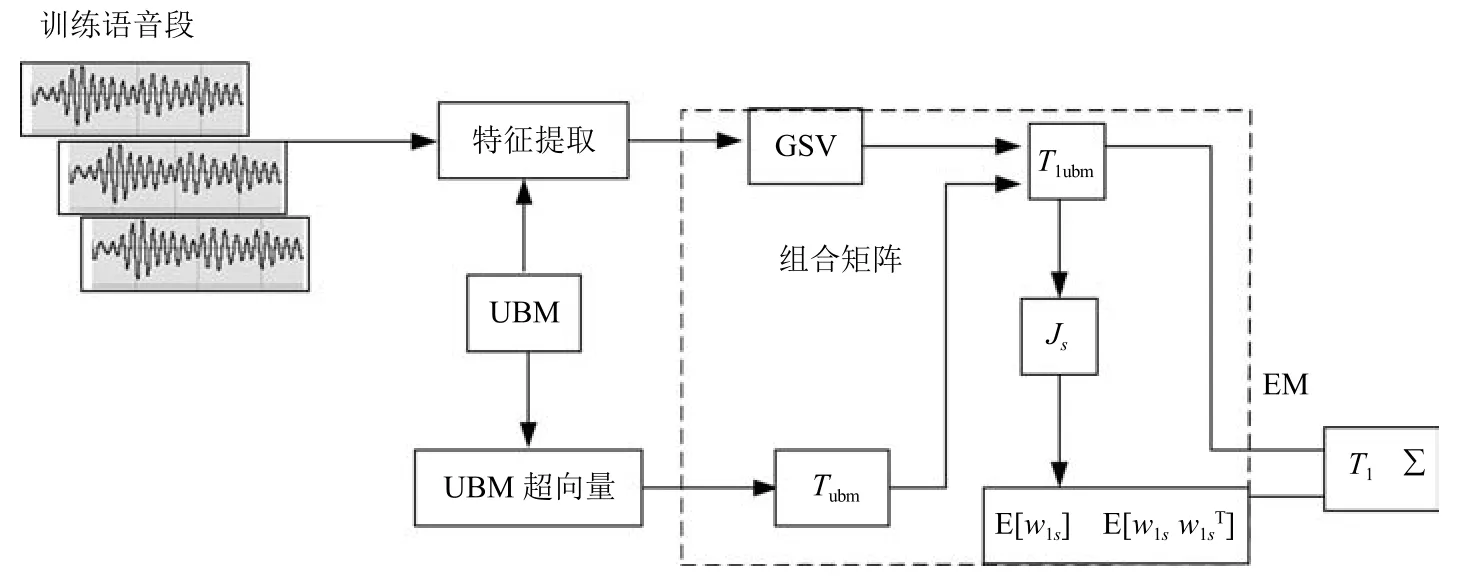
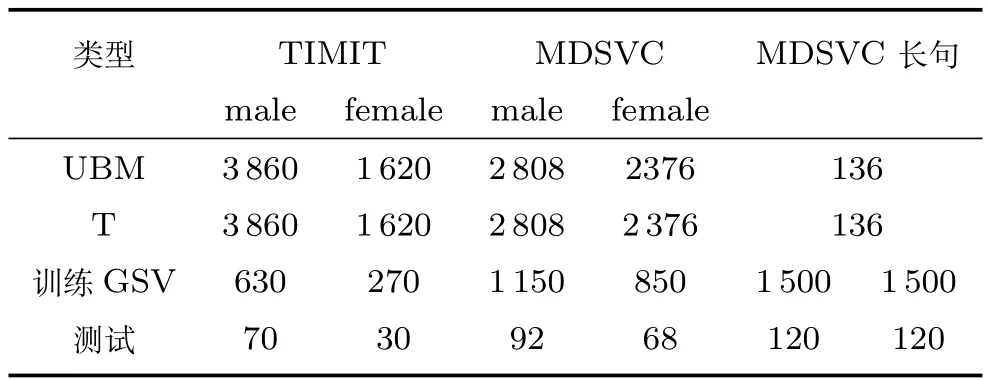
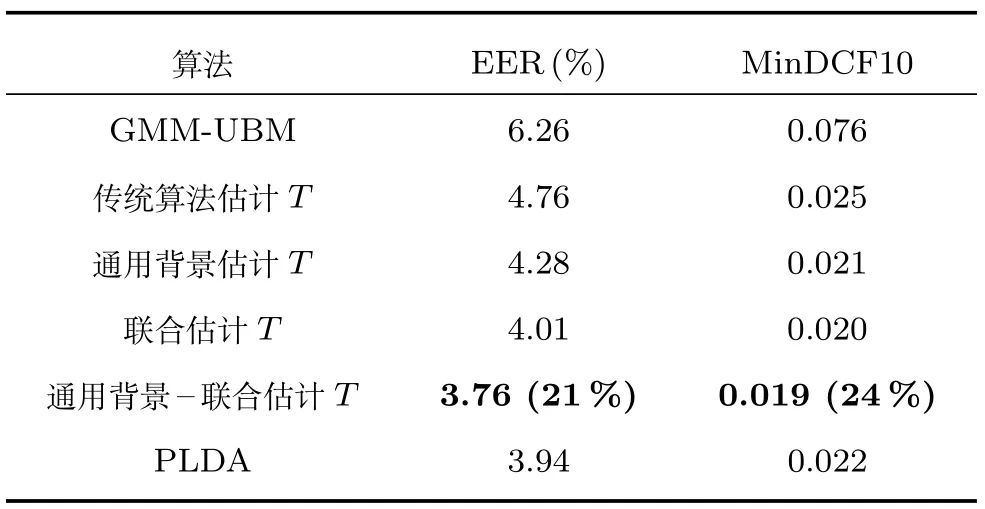
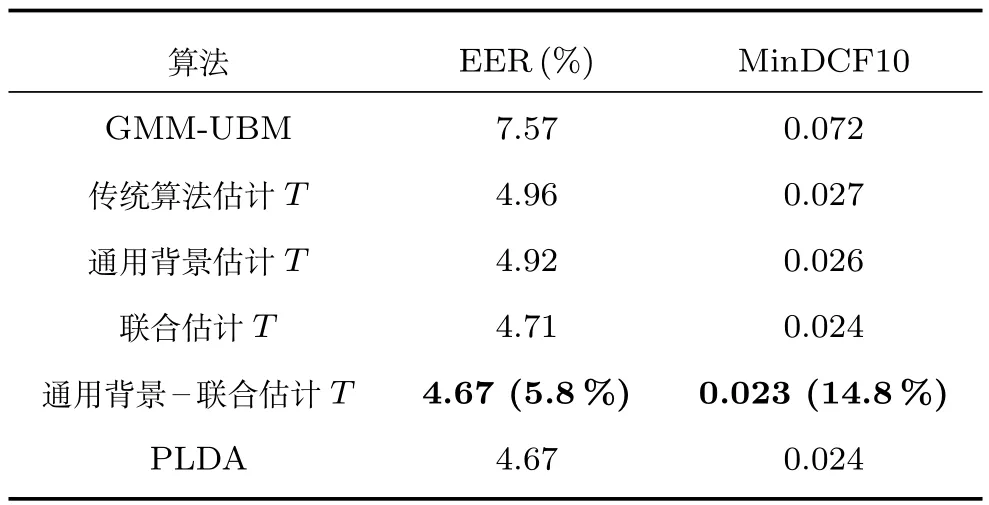
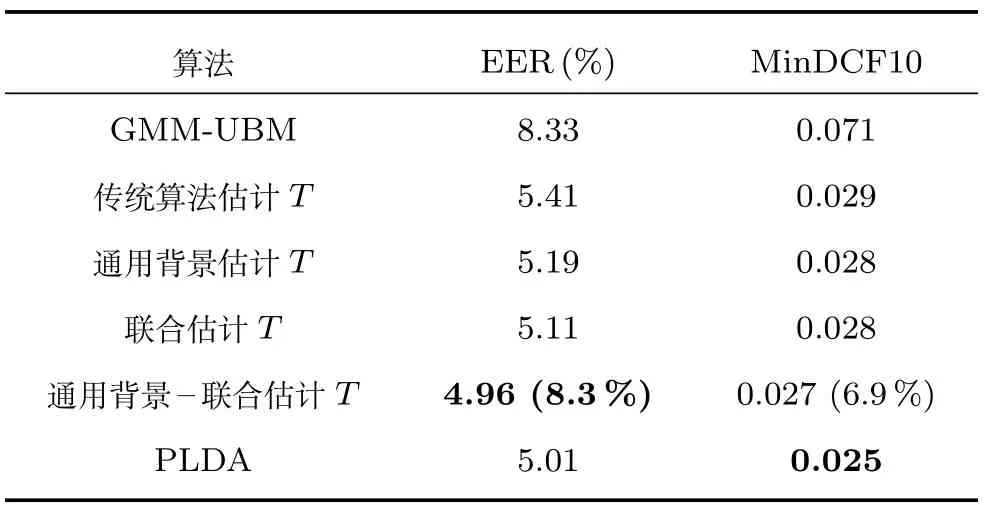
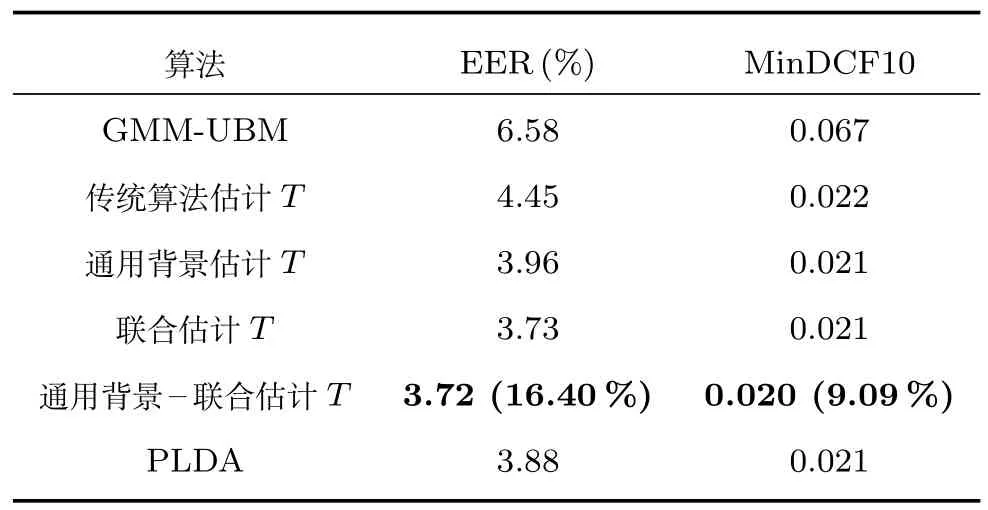
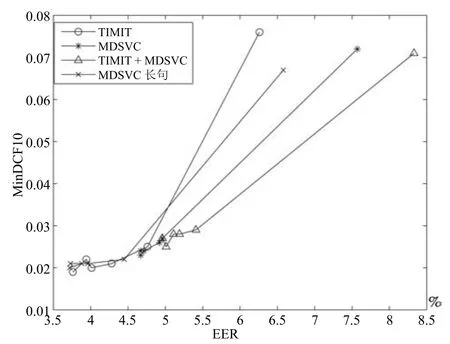
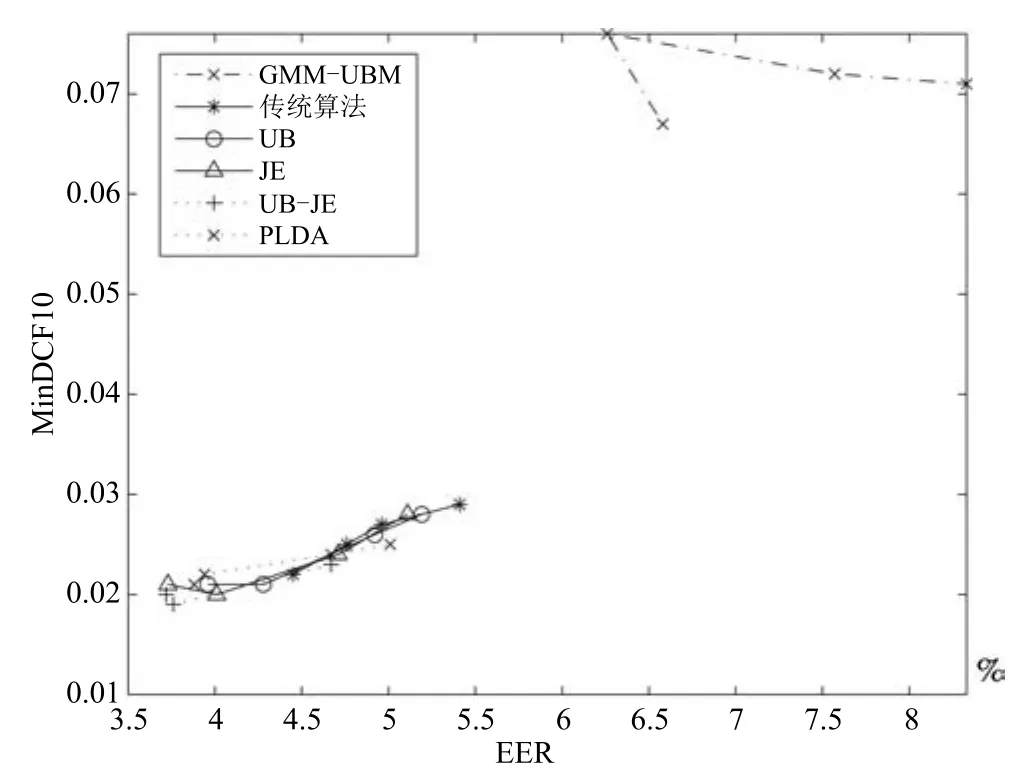
其中,ms,h為特定說話人s的第h段語音所形成的FC×1維的GSV,mu是FC×1維的UBM超矢量,U表示信道空間,是一FC×Ru維矩陣,其中Ru為信道因子數,V表示說話人空間,是一FC×Rv維矩陣,Rv是說話人因子數,D是殘差空間,是一個FC×FC維的對角矩陣,xs,h表示信道因子,ys表示說話人s的因子,zs是殘差因子.一般來說,10 由式(1)可知,在JFA中需要對mu,U,V以及D進行預先估計,由于mu已預先得到,因此只需要估計其他三個矩陣,即λ=(U,V,D).關于這三個矩陣的估計參見文獻[16]. 由于JFA存在空間掩蓋和空間重疊問題[8],不能很好地區分說話人和信道.Dehak等提出了ivector[9?10],i-vector把說話人和信道看成一個整體,根據JFA可把i-vector表示為 其中,s為特定說話人GSV,m為UBM超矢量,T表示總變化因子空間,迭代更新時,先隨機初始化,w為總變化因子,即i-vector,ε為殘差. 其中,Σ為對角協方差矩陣,可用UBM 協方差代替. 由式(2)可知,i-vector的建模可簡化為對模型參數λ=(s,m,T,Σ)的估計,由上述理論可知,訓練數據的s,m很容易得到,因此,可簡化為對λ=(T,Σ)的估計.其中最關鍵的是對總變化因子空間T的估計,T的估計類似于JFA中說話人空間估計,可以采用最大期望(EM)算法得到,參見文獻[9].步驟如下: 步驟1.估計統計量.一段語音特征參數為xs,t,UBM 超矢量為m,則 其中,Nc,s為零階統計量,Fc,s為一階統計量,Sc,s為二階統計量,mc為m中的第c個分量,γc,s,t為第c個高斯密度函數后驗概率. 步驟2.(E步)計算總變化因子w的一階統計量和二階統計量. 其中,Ls為臨時中間變量,為w的一階統計量(需要的結果)和二階統計量,Ns為Nc,s的對角拼接FC×FC維矩陣,Fs為Fc,s拼接的FC維矢量,Σ為UBM協方差. 步驟3.(M步)更新T和Σ. T更新: Σ更新: 其中,Ss為Sc,s拼接的FC×FC維矩陣,N=為所有說話人零階統計量之和.(當反復迭代幾次后,就可得到收斂的T和Σ). 在i-vector中T的估計是關鍵和基礎,由上一節可知,T是通過隨機初始化然后通過迭代產生的,但并沒有考慮到通用背景的情況.本文根據GMMUBM的思想,先通過背景無關數據產生一個初始化的Tubm,然后再進行迭代更新,提出了一種總變化因子空間通用背景算法.在常規的i-vector算法中,用均值最大化算法(Expectation maximum,EM)對數據更新時,僅僅考慮到T和Σ,而沒有對m進行更新.為了使得i-vector能夠有更好的結合性,本文又提出了一種同時更新m和T的聯合估計算法.在本節最后,我們把上述兩種算法相結合,提出通用背景–聯合估計算法. 首先,利用大量的無關數據訓練一個UBM 超向量,并根據i-vector中T估計方法估計一通用背景變化空間Tubm.然后,將Tubm作為EM 算法中對T估計的初始矩陣,進行自適應計算(如圖3所示).具體如下: 圖3 總變化因子的常規估計算法和UB算法(虛線框)比較Fig.3 Comparison of conventional estimation algorithm of total variation factor with UB(dashed frame) 步驟1.通過前端處理將大量的無關數據訓練成一個UBM超向量,并結合第1.3節中T的估計算法,生成一個通用背景下的總變化空間,記為Tubm. 步驟2.將Tubm代入式(7),生成Ls. 步驟3.將Ls代入式(8)和式(9)生成E[ws]和E[wswTs]. 步驟4.結合Tubm,E[ws]以及E[wswTs],根據第1.3節中的EM算法,依次對T和Σ進行更新. 步驟5.觀察T和Σ是否收斂或者達到迭代次數.如果沒有,則返回步驟2繼續;否則退出. 由第1.3節可知,i-vector的建模可轉化為對λ=(s,m,T,Σ)的估計.其中,s與m已預先估計好了,即GSV和UBM超矢量,因此,只更新λ=(T,Σ).事實上,在更新T和的Σ的同時,也應該更新m,即λ=(m,T,Σ),只有這樣,不斷更新的參數模型才會更加耦合. 本文提出一種m,T聯合估計算法,即 把T和m看成一個整體,在更新T的同時,也更新m.此時,i-vector模型表示為λ1=(T1,Σ),根據式(2)可寫為 其中,s為GSV,w1=[wT1]T,稱為聯合變化因子,T稱為聯合變化空間,ε為殘差. 根據第1.3節中i-vector中的EM更新算法可得: 步驟1.(E步) 步驟2.(M步) 對T1更新: 對Σ更新: 對T1的更新就是對T和m同時更新. 基于上述兩種算法,本文將它們相結合形成互補,提出了一種新的算法,即UB-JE(如圖4所示).具體如下: 步驟1.通過大量無關數據得到UBM超向量,集合JE算法中T1的估計算法,得到通用背景–聯合總變化空間T1ubm. 步驟2.將T1ubm代入式(15),生成Js. 步驟3.將Js代入式 (16)和式(17),生成E[w1s]和E[w1sw1Ts]. 步驟4.結合T1ubm,E[w1s]以及E[w1sw1Ts],根據JE算法中的EM算法,依次對T1和Σ進行更新. 步驟5.觀察T1和Σ是否收斂或者達到迭代次數.如果沒有,則返回步驟2繼續;否則退出. 圖4 通用背景–聯合估計算法(虛線框)Fig.4 Diagram of universal background-joint estimation algorithm(dashed frame) 實驗的測試數據采用TIMIT語音庫[18]、MDSVC語音庫[19]以及一組由MDSVC語音庫組成的長時語音數據.實驗在預處理階段包括:有效語音端點檢測(短時能量與平均過零率相結合的方法)、預加重(因子為0.95)、分幀(幀長25ms,幀移12.5ms)和加窗.實驗采用39維美爾倒譜系數(Mel frequency cepstral coefficients,MFCC)特征參數(基本特征包括1維能量和12維倒譜、13維一階差分特征以及13維二階差分特征).實驗中,UBM混合數為512,密度函數方差采用對角矩陣.在i-vector訓練中,總變化因子空間維數設置為400,訓練時迭代次數取6次. 運用5300句TIMIT語音(女性1620句語音,男性3680句語音)、MDSVC中Enroll_Session1+Enrol_Session2以及用HTK工具[20]對MDSVC語音數據組合長句(48Enroll_Session1+48Enroll_Session2+40Imposter共136長句)分別訓練UBM模型和T.實驗訓練數據為100人(30個女性,70個男性,每人9句語音)TIMIT語音、MDSVC中Imposter(23個文件的男性和17個文件的女性中各50句)以及MDSVC中部分數據(30個文件的男性和30個文件的女性中各50句);測試數據為TIMIT中100人(30個女性,70個男性,每人1句語音)、MDSVC Imposter(23個文件的男性和17個文件的女性中的剩余4句)以及MDSVC中部分數據(30個文件的男性和30個文件的女性中各4句)(詳見表1).本文設置了一個基線實驗(GMM-UBM)[3]來驗證因子分析方法(i-vector)的有效性. 表1 實驗所用語音庫Table 1 The corpus used in the experiment 本文采用等錯誤率(Equal error rate,EER)和2010年的NIST SRE中的最小檢測代價函數(Minimum detection cost function 2010,Min-DCF10)[21]作為性能評測指標.MinDCF10與EER越小說明系統的性能越好. 檢測代價函數計算公式為 表2 MinDCF10參數設定Table 2 MinDCF10 parameter setting 為了驗證所提算法的有效性,本文基于兩種不同的語音庫設置了四個實驗:實驗1基于TIMIT語音庫;實驗2基于MDSVC語音庫;實驗3是在兩者綜合的語音庫中完成的;實驗4基于MDSVC語音庫組成的長時語音數據.每一個實驗做6次比較試驗,即基線實驗(GMM-UBM)[3]、本文提出的三個新算法、總變化矩陣傳統算法以及文獻[22]中i-vector矢量規整PLDA技術.由于不同語音庫的錄音條件、方式等不同,四個實驗分別代表了四種不同的實驗環境.表3~6分別給出在不同語音庫上各算法訓練T后的系統性能比較.表中括號里的是性能提升值. 表3 GMM-UBM、傳統算法估計T、本文所提出算法估計T以及PLDA在TIMIT語音庫上的性能對比Table 3 Performance comparison of GMM-UBM,the traditional algorithm to estimateT,the proposed algorithms to estimateT,and the PLDA on TIMIT corpora 表4 GMM-UBM、傳統算法估計T、本文所提出算法估計T以及PLDA在MDSVC語音庫上的性能對比Table 4 Performance comparison of GMM-UBM,the traditional algorithm to estimateT,the proposed algorithms to estimateT,and the PLDA on MDSVC corpora 表5 GMM-UBM、傳統算法估計T、本文所提出算法估計T以及PLDA在TIMIT+MDSVC語音庫上的性能對比Table 5 Performance comparison of GMM-UBM,the traditional algorithm to estimateT,the proposed algorithms to estimateT,and the PLDA on TIMIT mixed MDSVC corpora 表6 GMM-UBM、傳統算法估計T、本文所提出算法估計T以及PLDA在MDSVC長句語音庫上的性能對比Table 6 Performance comparison of GMM-UBM,the traditional algorithm to estimateT,the proposed algorithms to estimateT,and the PLDA on MDSVC long sentence corpora 為了更加直觀地觀察實驗結果,本文分別作了圖5和圖6.圖5是在不同語音庫中各個算法的性能比較(表3~6的內容),圖6是不同算法在四種語音庫中的性能比較(包含表7). 表7 通用背景–聯合估計算法在不同語音庫中的性能對比Table 7 Performance comparison of universal background-joint estimation algorithm on different speech corpus 從以上圖表可以看出,在TIMIT數據集、MDSVC數據集、TIMIT+MDSVC綜合集或MDSVC長句集上,1)因子分析方法相較于基線系統(GMM-UBM)性能都有顯著提升.2)新提出算法的性能都有一定提升,特別是通用背景–聯合估計算法的性能在TIMIT中提升了較為明顯,EER和MinDCF10分別提升21%和24%.同時,在實驗環境更加復雜的綜合集TIMIT+MDSVC上性能也有一定提升,EER和MinDCF10分別提升了8.3%和6.9%.通過每單個實驗的對比發現,聯合估計算法的性能要一致性的優于通用背景算法,兩者結合的算法(通用背景–聯合估計)可以得到更優的系統.3)相比于文獻[22]中i-vector矢量規整PLDA技術,本文提出的算法(UB-JE)在不同語音數據庫中,性能有一定的提升. 但是對比表3~6的數據可知,表6中算法的性能最好,其次是表3,然后是表4,最后才到表5(從表7和圖6可以看出),這是由于長時語音相對短時語音更能準確地代表說話人信息以及隨著語音數據復雜程度的提高,系統的性能受到一定的影響.現階段說話人識別領域一個熱門方向就是針對語音數據復雜程度展開的,即多信道下的說話人識別,這是說話人識別發展的一個趨勢. 圖5 不同語音庫中各算法性能對比Fig.5 Performance comparison of algorithms on different speech corpus 圖6 不同算法在四種語音庫中的性能對比Fig.6 Performance comparison of different algorithms on four speech corpus 本文主要研究了說話人識別算法i-vector中總變化因子空間T的估計,提出了四種T估計算法.實驗結果顯示,在三種語音庫中,新提出的三種算法對系統的性能都有一定的提升(如圖5),且不同語音庫對每一種算法的性能都有一定的影響(如圖6).實驗結果證明有效估計T對整個i-vector模型起著至關重要的作用,驗證了前面i-vector理論分析,T的估計引領著整個模型.語音庫的選擇對整個系統的性能有一定影響,下一步將在更加復雜的語音庫(如NIST SRE語音庫)上進行評測實驗.1.3 總變化因子分析方法

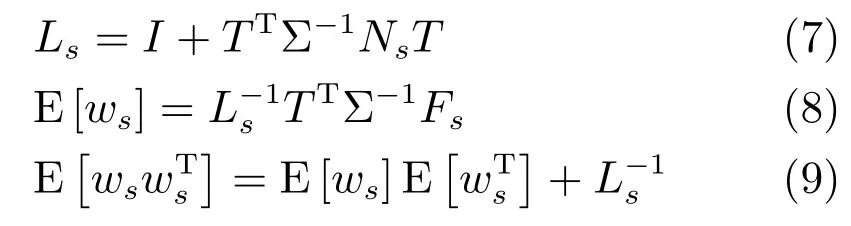
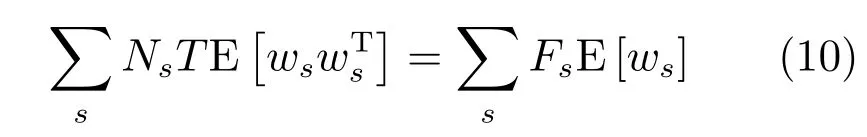
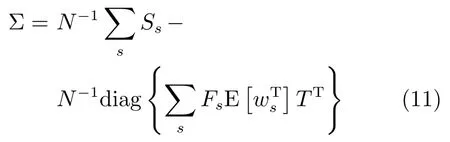
2 總變化因子空間通用背景?聯合估計算法
2.1 通用背景算法(UB)
2.2 聯合估計算法(JE)

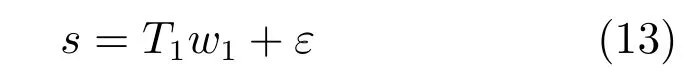
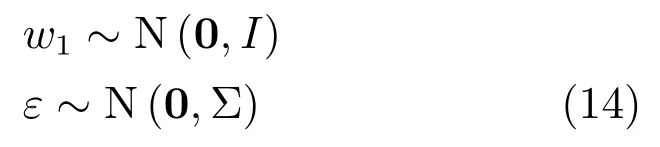
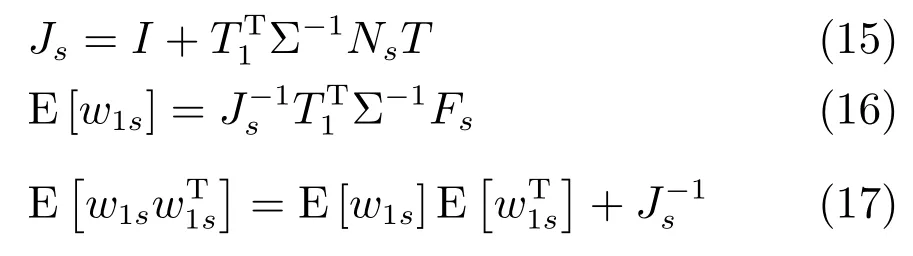
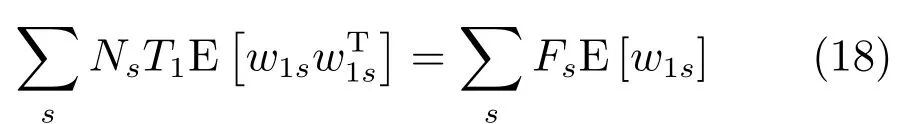
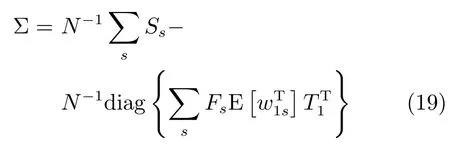
2.3 通用背景?聯合估計算法(UB-JE)
3 實驗與分析
3.1 實驗設置
3.2 評價指標


3.3 實驗設計與結果分析

4 結論
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
汽車工程師(2021年12期)2022-01-17 02:29:54
當代陜西(2020年14期)2021-01-08 09:30:42
奧秘(創新大賽)(2020年7期)2020-07-27 08:26:32
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
貴州師范學院學報(2016年4期)2016-12-01 03:54:07
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
紡織服裝流行趨勢展望(2016年1期)2016-05-04 03:45:20
