協(xié)同過濾算法的優(yōu)化研究
2018-11-09 08:33:58熊波元陳軍華
上海師范大學(xué)學(xué)報·自然科學(xué)版 2018年5期
熊波元, 陳軍華
(上海師范大學(xué) 信息與機電工程學(xué)院,上海 200234)
1992年,xerox公司郵件系統(tǒng)通過協(xié)同過濾技術(shù),對所有咨詢的郵件進行分析,提取有價值的郵件,推薦給公司優(yōu)先處理,這是對協(xié)同過濾算法最早的應(yīng)用[1].1994年,GroupLens研究小組創(chuàng)建了MovieLens系統(tǒng),對協(xié)同過濾算法的研究影響很大[2].
基于用戶的協(xié)同過濾算法雖然應(yīng)用廣泛,但是用戶相似性是通過用戶的評分來計算的,評分與購買商品沒有必然聯(lián)系,因此通過這種方式計算得到的用戶相似性,體現(xiàn)的是評分行為上的相似度,并不能直接代表用戶在興趣偏好上的相似度.對此,本文作者提出了改進方案,在原有用戶相似性計算中加入用戶興趣偏差度因素,以期達到較為準(zhǔn)確的相似度計算結(jié)果.
1 基于用戶的協(xié)同過濾算法的優(yōu)化
1.1 獲取用戶項目屬性評分矩陣

1.2 計算用戶興趣度指數(shù)
統(tǒng)計數(shù)據(jù)中瀏覽行為的總次數(shù)與其用相同方法對應(yīng)的有效購買總次數(shù),然后將有效購買總次數(shù)除以瀏覽總次數(shù)得到瀏覽行為的有效購買占比w1,用相同方法計算出關(guān)注行為的有效購買占比w2和購買行為的有效購買占比w3.
將用戶對某個品牌的某種行為操作次數(shù)乘以對應(yīng)行為的有效購買占比,然后累加,得到用戶興趣度指數(shù).
1.3 計算品牌偏好
品牌偏好計算公式如下:
(1)
其中,Iua是用戶u對品牌a的興趣指數(shù).
根據(jù)品牌偏好,可以得到用戶品牌偏好矩陣,每行中的數(shù)據(jù)是用戶對各個品牌的偏愛度,以此計算用戶間興趣偏差度:
(2)
其中,n是品牌的數(shù)量,Lua是用戶u對品牌a的偏好值,Lva是用戶v對品牌a的偏好值.
1.4 計算用戶相似性
矩陣Q中的每行數(shù)據(jù)代表一個用戶向量,通過余弦相似性、修正的余弦相似性及Pearson相關(guān)相似性,計算得到用戶評分相似度,再乘以用戶興趣偏差度,最終得到用戶相似性.
1.5 最近鄰居集合
采用Top-N的方式尋找目標(biāo)用戶的最近鄰居集合,即計算出每個用戶與目標(biāo)用戶之間的相似性,取相似性值最大的前k個用戶組成集合,即最近鄰居集合.
2 算法驗證與分析
2.1 數(shù)據(jù)集
實驗數(shù)據(jù)采用京東算法競賽提供的真實數(shù)據(jù),其中包括用戶信息、商品信息、商品屬性信息、用戶評分信息、用戶操作日志等數(shù)據(jù).實驗的數(shù)據(jù)中總共有983個用戶、2398件商品和146198條評分記錄,還有幾十萬條用戶操作數(shù)據(jù).
2.2 實驗標(biāo)準(zhǔn)
選擇平均絕對誤差(MAE)作為驗證標(biāo)準(zhǔn).MAE是計算用戶對項目的預(yù)測評分與用戶的實際評分之間的偏差,計算公式如下:
(3)
其中,n為商品數(shù)量,Suk為用戶u對商品k的預(yù)測評分,Quk為用戶u對商品k的實際評分.M越小,說明推薦準(zhǔn)確度越高.
2.3 實驗結(jié)果分析
將實驗的數(shù)據(jù)集隨機分為5等份,將其中4份作為訓(xùn)練數(shù)據(jù)集,剩下的一份作為測試數(shù)據(jù)集,總共實驗5次,每次實驗都取不同的訓(xùn)練數(shù)據(jù)集和測試數(shù)據(jù)集進行實驗,得到的5個結(jié)果再取平均值作為最后的實驗數(shù)據(jù),以此提高實驗的準(zhǔn)確性.
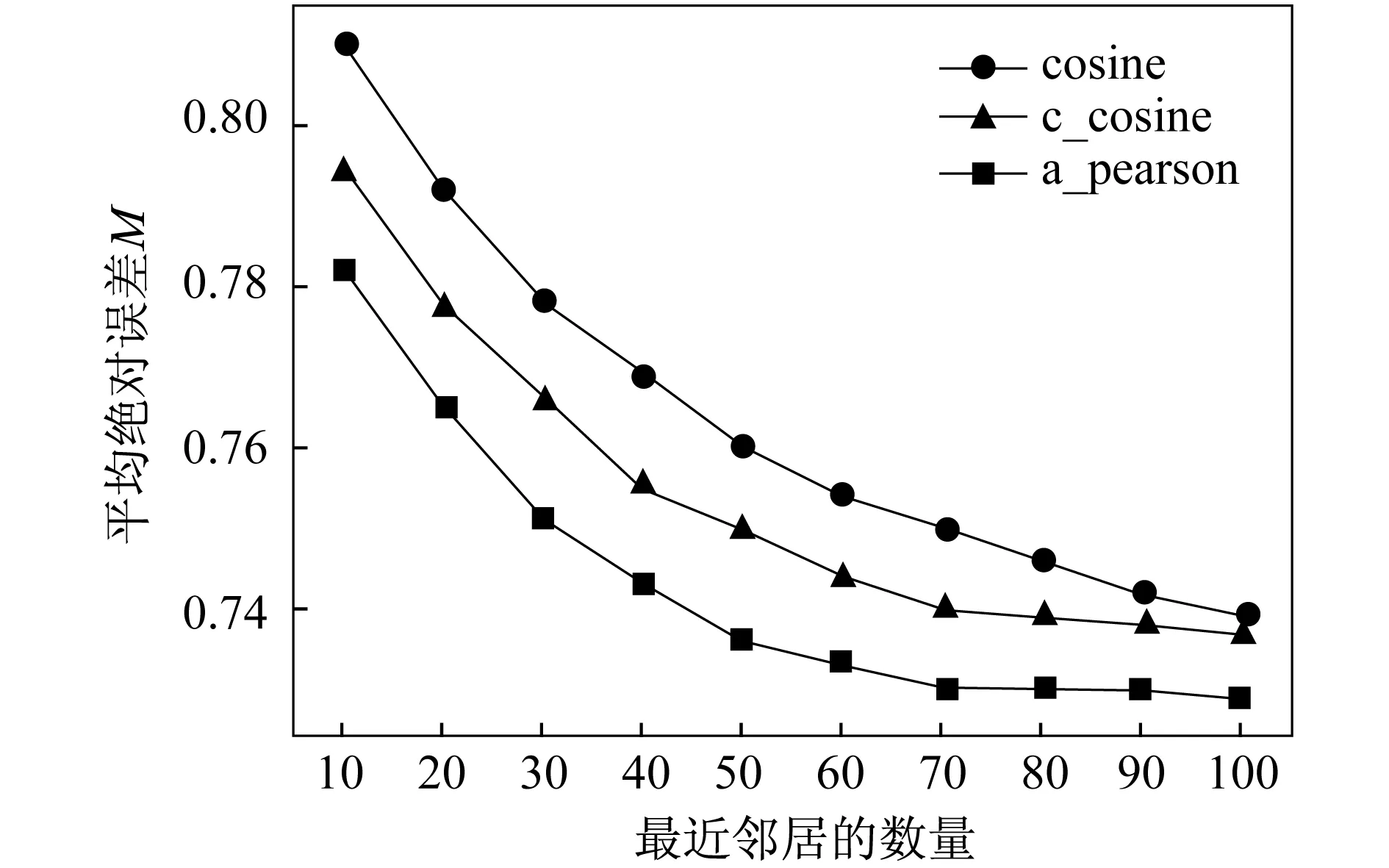
圖1 相似性度量方法的比較
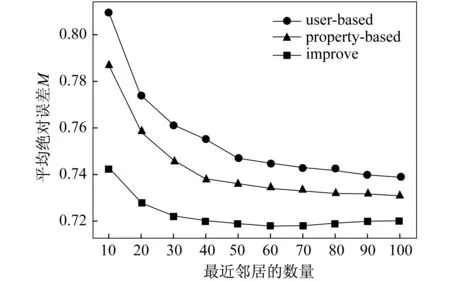
圖2 不同算法用戶評分預(yù)測的M值對比
對比了余弦相似性、修正的余弦相似性及Pearson相關(guān)相似性三種度量方法對算法M值的影響(圖1).從圖1中可以看出,隨著最近鄰居的數(shù)量的增加,三種度量方法對應(yīng)的M值都在減小,推薦準(zhǔn)確度在提高.相對而言,使用Pearson相關(guān)相似性公式計算用戶相似性更為準(zhǔn)確.因此,在后續(xù)比較算法的實驗中,采用Pearson相關(guān)相似性公式計算用戶相似性.
比較了不同算法下用戶評分預(yù)測的M值(圖2).從圖2可知,隨著最近鄰居的增加,M值均先減小后趨于穩(wěn)定,傳統(tǒng)的基于用戶的協(xié)同過濾算法和基于項目屬性的協(xié)同過濾算法在最近鄰居數(shù)為80后,才接近穩(wěn)定,而改進算法在最近鄰居數(shù)為60時,已趨于穩(wěn)定.相對來說,改進后的算法收斂速度較快,其對應(yīng)的M值整體相對于前兩種算法較低,表示改進后的算法推薦準(zhǔn)確度更高.從圖2中還可以看出,改進后的算法在最近鄰居數(shù)量為60時,推薦效果最好,推薦系統(tǒng)的準(zhǔn)確性和復(fù)雜度達到最佳平衡.綜上所述,改進后的算法的性能優(yōu)于傳統(tǒng)的基于用戶的協(xié)同過濾算法和基于項目屬性的協(xié)同過濾算法.
3 結(jié) 論
提出了一套協(xié)同過濾改進算法,對用戶相似性計算方面進行優(yōu)化,通過實驗驗證,相較于傳統(tǒng)算法,改進算法能提高推薦系統(tǒng)的準(zhǔn)確率.但本研究依然存在較多不足,如未能考慮實時性、多樣性的平衡及智能化等問題,有待下一步研究工作加以解決.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學(xué)生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
商用汽車(2016年11期)2016-12-19 01:20:16
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:54:39
