BP神經網絡在水下地形高程擬合的應用
2018-11-15 09:06:54彭中波
重慶交通大學學報(自然科學版) 2018年11期
彭中波, 高 陽
重慶交通大學 航運與船舶工程學院,重慶 400041)
0 引 言
人工神經網絡是模仿人類大腦的結構和功能的一種信息處理系統[1-2],由于具有并行結構和并行處理能力、知識能夠分布式存儲、良好的容錯性以及自適應學習能力等特點,在信號處理、模式識別、智能檢測以及人工智能等領域得到廣泛應用。具有3層或3層以上結構的無反饋、層內無互聯結構的前向神經網絡,即為BP神經網絡。它采用有指導的學習方式進行訓練和學習,即在一給出的BP神經網絡中,輸入神經元的激活值從輸入層經過各個隱含層傳遞到輸出層,在輸出層的各個神經元得到神經網絡的實際輸出。對神經網絡的實際輸出與期望輸出值進行比較,得到輸出值的誤差,再逐層修正各個從輸出層至隱含層的連接權值,最后返回到輸入層并不斷重復該過程,使誤差值減小到能夠接受的范圍。
隨著市政工程的不斷發展完善,高程測量[3-5]工作顯得尤為重要,測量值的準確性將直接影響到工程的質量。在市政工程中高程的主要測量方式有GPS技術測量、水準測量、三角高程測量和氣壓高程測量[6-9],其中以GPS技術測量、水準測量兩種方式所測數據最為精密,但是整個測量過程中對設備及設備的安裝位置有特定的要求,測量步驟也較為復雜,都需要嚴格按照相關測量規范進行。針對烏江河口至白馬河段水下地形圖高程測量問題,利用MATLAB提供的神經網絡函數編程實現GPS正常高的神經網絡數據擬合[10-12]。
1 BP神經網絡模型與理論基礎
BP(Back Propagation)神經網絡是一種典型的多層前向型網絡,可以實現從輸入到輸出的任意非線性映射。網絡中通常含有一個或多個隱含層,各個神經元接受前級輸入并輸出到后級,最終網絡的輸出是由輸入與其對應的權值求取加權和后通過傳遞函數得出。BP網絡的輸出可以通過選擇最后一層的傳遞函數確定。傳遞函數為S型時,輸出量為0~1的連續量;傳遞函數是線性傳遞函數時,網絡輸出量可以取任意值。其中隱含層神經元采用S型傳遞函數,輸出層神經元采用線性傳遞函數。BP神經元模型如圖1。

圖1 BP神經元模型Fig. 1 BP neuron model
圖1是具有R個輸入的神經網絡模型。每一個輸入信號的連接強度都用一權值表示,權值的刺激或者抑制作用通過對權值取正負值表示。給輸入信號相應突觸加權之和添加一個閾值,根據閾值的正負值去增加或減少激活函數的輸入。激活函數主要作用是限制神經元的輸出振幅,將輸入信號限制在允許范圍之內。一般的輸出的幅度范圍有[0,1]和[-1,+1]兩種。
BP神經網絡輸入輸出之間的線性或非線性關系都可以由隱含層的非線性傳遞函數神經元學習擬合獲得,輸出層采用線性傳遞函數是為了拓寬網絡輸出。圖2為一典型BP網絡結構,含有一個神經元數目為s的隱含層,隱層神經元傳遞函數tansig,輸出層神經元傳遞函數purelin[13]。

圖2 BP網絡結構Fig. 2 BP network structure
2 BP神經網絡設計
2.1 神經網絡問題簡述
將以獲取點的坐標值(xi,yi)和相對應的高程值zi作為新建神經網絡的數據樣本:
P={P1,P2,P3,…,Pn}
(1)
式中:Pi=(xi,yi,zi),i=1,2,3,…,n。
對數據樣本進行學習,建立映射關系:
z=f(x,y)
(2)
式中:x,y為平面坐標;z為高程值。
2.2 神經網絡設計
2.2.1 樣本數據的處理
從工程河段實測水下地形圖中提取坐標點(x,y)及高程值z,其中坐標點作為神經網絡的輸入層,坐標組成向量為二維,因此輸入層有兩個神經元;高程值組成向量Z作為神經網絡的輸出層,即輸出層有一個神經元。從實測圖中提取的數據顯示所測坐標點及高程值之間的差值較大,為了方便后面的數據處理與加快MATLAB中神經網絡程序的運行及網絡收斂速度,需要對樣本數據進行歸一化處理,歸一化后的數據將分布在區間[0,1],網絡訓練結束后可以將數據反歸一化到原始數據的范圍[14]。使用的歸一化函數:
(3)
式中:P為輸入輸出向量P(x,y,z);min(P)、max(P)分別為向量P(x,y,z)的最小值和最大值。
2.2.2 隱層神經元數選取
BP神經網絡的神經元個數選擇是關鍵。根據BP神經網絡任意逼近定理,對于有界區域中的任意連續函數在足夠多的神經元數時,都能用3層前向神經網絡以任意精度逼近[15-16]。但是神經元數目較多時,神經網絡訓練學習的時間較長,網絡復雜度增加,容錯性差以及過擬合現象出現;神經元數目較少時,網絡對樣本數據的訓練能力和預測能力不夠,不能識別之前沒看到過的數據,導致神經網絡訓練的結果達不到應用的要求。確定神經元數目的研究結果較多,筆者參考以下3個公式:
(4)
m=log2n
(5)
(6)
式中:m為隱含層神經元數;n為輸入層神經元數;l為輸出層神經元數;α為1~10之間的常數。
2.2.3 權值和閾值訓練過程
BP神經網絡的訓練就是輸入樣本訓練數據刺激網絡的連接權值動態調整[17],判斷網絡輸出和期望輸出相符精度是否符合要求,不滿足的誤差將反向傳輸進行動態修正連接權值,根據誤差值對權值的偏導數的正負判斷實際輸出與期望輸出的大小,確定權值的調整方向,使得實際與期望的誤差值收斂。權值和閾值初始化即是給各連接權值賦(-1,1)區間的任一隨機數,其初始化函數調用格式為:net=init(net)。網絡中各連接權值和閾值矩陣根據輸入層、隱層及輸出層節點數確定。BP網絡訓練完成,權值和閾值讀取函數分別為net.iw{1,1}、net.lw{2,1}、net.b{1}、net.b{2}。為了方便訓練好后的網絡使用,需要save net(保存網絡),在使用時只需要load net(保存網絡)就能進行高程點預測。
2.2.4 傳遞函數及訓練函數選取
1)傳遞函數選取
傳遞函數是BP網絡的重要組成部分。BP網絡的傳遞函數有多種,常用的有S型的對數或正切函數和線性函數。logsig函數也叫S型的對數函數,可取任意值為輸入值,輸出值為0~1之間的數;tansig函數又叫雙曲正切S型傳遞函數,輸入值可取任意數,輸出值在[-1,+1]之間;線性傳遞函數purelin的輸入值與輸出值都可取任意數[18]。在實際訓練中,可根據樣本數據的訓練誤差大小選取隱層和輸出層傳遞函數。
2)訓練函數選取
在BP網絡訓練時,采用不同的訓練函數對網絡的性能影響不同[19]。BP網絡主要的訓練函數有Newton算法的trainbfg函數、trainoss函數;共軛梯度算法的traincfg函數、trainscg函數以及trainrp函數、trainlm函數。這些函數在計算速度、收斂速度、內存要求及誤差范圍等方面有各自的優缺點。因樣本數據較多,需要的訓練精度較高,綜合各種條件選取trainlm訓練函數。
3 MATLAB實現神經網絡高程擬合
3.1 烏江河口至白馬河段航道建設工程圖

圖3 工程河段航標配布及高程Fig. 3 Standard layout and elevation map of river reach

圖4 局部高程點位概略分布Fig. 4 Local elevation general distribution map
3.2 烏江河口至白馬河段高程值預測
該河段工程測量點較多,所獲取的訓練樣本數據較充足。取3 000組數據作為樣本數據,其中前2 000組數據作為訓練數據(training data),剩下400組作為驗證數據(validation data),600組作為測試數據(testing data)。在實驗中,BP網絡創建函數為newff,其函數選用及訓練參數確定如表1、表2。

表1 BP網絡函數選用Table 1 Selection of BP network function
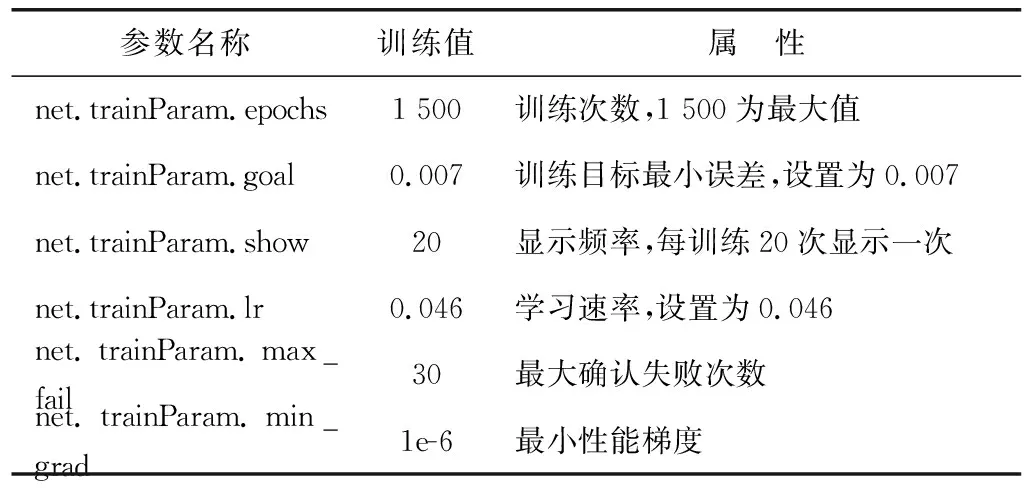
表2 BP網絡訓練參數Table 2 Training parameters of BP network
表1的函數選取都是針對研究河段獲取的樣本數據特點進行分析選取。表2中參數都是經過多次訓練得出,通過以上參數訓練獲得的BP網絡有較好的預測效果,其預測結果如圖5。

圖5 河口至白馬河段高程預測Fig. 5 Elevation forecast map between estuary and White Horse River reach
神經網絡性能的主要參數是均方差(Mean Squared Error),表現數據的變化程度,差值越小,擬合精度越高。擬合過程中最優的性能參數(Best Validation Performance)經過801次迭代運算得出為0.007 23,說明該預測模型擬合數據具有較高精確度。訓練樣本(train sample)、驗證樣本(validation sample)及測試樣本(test sample)的均方差擬合曲線如圖6。

圖6 訓練樣本、驗證樣本、測試樣本均方差曲線Fig. 6 Mean square errer curves of train semple, validation sampleand test sample
樣本數據集擬合曲線一般有線性和指數兩種形式。筆者將樣本數據歸一化處理,采用線性擬合描述訓練樣本(train sample)、驗證樣本(validation sample)、測試樣本(test sample)及整體樣本分析。擬合系數R是說明神經網絡訓練情況,越接近1訓練程度越好,更適合工程中高程預測應用。訓練樣本、驗證樣本、測試樣本及整體樣本擬合系數R分別為0.970 03,0.955 83,0.959 68,0.967 91,均大于0.95,其中訓練樣本R=0.970 03,如圖7,說明該網絡訓練較為成功,可用于數據預測。

圖7 訓練樣本、驗證樣本、測試樣本線性擬合Fig. 7 Linear fitting of train sample, validation sample and test sample
3.2 預測結果分析
將BP神經網絡擬合出的結果與工程實測高程對比分析,得出測試集擬合最大誤差為4.75 m。根據統計學中的置信水平(95%)對600組擬合結果進行區間估計,最大誤差為2.32 m,與對應高程點的占比為0.745%,擬合效果較好,符合地形測量的工程應用要求。擬合誤差及擬合精度的點位分布如圖8,高程誤差都在0~2.32 m之間,在1 m范圍內的誤差值占總數據的70.17%,誤差精度都在0.745%以內,屬于較高精度等級要求。

圖8 擬合誤差及擬合精度點位分布Fig. 8 Fitting error and fitting precision point distribution map
4 總 結
主要對重慶地區河口至白馬河段坐標數據進行分析,并對樣本數據建立BP神經網絡,通過訓練好的BP網絡對該河段更多區域高程值進行預測,并對該網絡進行推廣到該類河段高程預測應用,以此節省傳統高程測量方式需要耗費的人力和財力資源。
研究結果主要體現在兩個方面:一是針對工程河段水下地形圖高程的數據特征,建立BP神經網絡。神經網絡的創建工作包括:①分析不同網絡函數的適用范圍,選取合適的函數;②網絡層數及神經元個數的確定;③結構參數的選取。二是對神經網絡擬合的高程值與實際測量高程值進行對比分析,通過繪制工程圖的點位分布圖、神經網絡樣本數據集的擬合誤差曲線、擬合回歸曲線及擬合誤差和擬合誤差精度的點位分布圖等可知該網絡訓練預測值與實測值之間的誤差為0.745%以內,屬于工程應用的誤差范圍,對該河段其它未通過人為測量的高程值有預測作用。得出的BP網絡還可以在更多地方得以推廣應用。
