基于轉(zhuǎn)置卷積操作改進的單階段多邊框目標檢測方法
2018-11-23 00:57:58郭川磊
計算機應(yīng)用 2018年10期
郭川磊,何 嘉
(成都信息工程大學(xué) 計算機學(xué)院,成都 610225)(*通信作者電子郵箱hejia@cuit.edu.cn)
0 引言
在現(xiàn)實世界的應(yīng)用中,以高精度分類和定位目標是服務(wù)質(zhì)量的關(guān)鍵。例如,在高端的駕駛輔助系統(tǒng)中,精確地定位車輛和行人與實現(xiàn)安全的自動駕駛緊密相關(guān)。
近幾年在目標檢測領(lǐng)域取得的進展體現(xiàn)了深度卷積神經(jīng)網(wǎng)絡(luò)在自動駕駛技術(shù)發(fā)展中發(fā)揮的關(guān)鍵作用。目前基于卷積神經(jīng)網(wǎng)絡(luò)的不同方法可以大致被分為兩類:第一類是類似基于區(qū)域卷積神經(jīng)網(wǎng)絡(luò)(Regions with Convolutional Neural Network, R-CNN)[1]的雙階段方法。該類方法的第一階段產(chǎn)生高質(zhì)量的候選區(qū)域,第二階段對候選區(qū)域進行分類和定位結(jié)果優(yōu)化。另外一類方法取消了生成候選區(qū)域階段,構(gòu)建了一個單階段的端到端模型。單階段模型通常更加容易訓(xùn)練,能夠在生產(chǎn)環(huán)境中達到更高的計算效率[2]。然而,當單階段模型需要以更高的交并比(Intersection over Union,IoU)來評估平均目標檢測精度時,運算速度的優(yōu)勢通常會被較低的檢測精度抵消,而雙階段的目標檢測方法能夠取得更高的檢測精度。造成單階段方法在高IoU條件下檢測精度降低的主要原因是:在復(fù)雜的場景中,模型很難生成高質(zhì)量的邊界框。
通過實驗可以看出,大部分低質(zhì)量的邊界框是由于定位小目標和重疊目標失敗而產(chǎn)生的。在這種情況下,邊界框的回歸過程變得非常不可靠,因為邊界框的正確生成必須依賴于圖像的上下文信息(例如目標的尺寸信息或被遮擋目標周圍的環(huán)境特征)。消除這類錯誤的關(guān)鍵在于使用能充分利用圖像中上下文信息的優(yōu)化過程。更快速的基于區(qū)域的卷積神經(jīng)網(wǎng)絡(luò)(Faster Regions with Convolutional Neural Network, Faster R-CNN)[3]的感興趣區(qū)域池化(Region Of Interest Pooling,ROI Pooling)階段可以被認為是一個簡單利用上下文信息在特征圖上重新采樣的過程;但是 Faster R-CNN 在分類階段仍然需要進行大量的運算來處理候選區(qū)域,這使得模型很難進行端到端的訓(xùn)練以提升整體性能。
本文為單階段模型引入了利用圖像上下文信息的優(yōu)化方法。以轉(zhuǎn)置卷積操作為基礎(chǔ),構(gòu)建了循環(huán)特征聚合結(jié)構(gòu)。利用循環(huán)特征聚合結(jié)構(gòu),上下文信息可以被逐漸地、有選擇地被應(yīng)用到對目標的分類和定位過程中。圖像上下文信息的生成過程是完全由數(shù)據(jù)驅(qū)動的,并且可以進行端到端訓(xùn)練。實驗使用KITTI數(shù)據(jù)集,在IoU為0.7的條件下評估了模型的平均檢測精度(mean Average Precision, mAP)。本文實驗中,循環(huán)特征聚合模型與對比模型均使用經(jīng)過預(yù)訓(xùn)練的殘差網(wǎng)絡(luò)(Residual convolutional Network, ResNet)101作為特征提取網(wǎng)絡(luò),這證明了在使用相同特征圖的情況下,循環(huán)特征聚合模型能夠達到更高的平均檢測精度。
1 相關(guān)工作
使用卷積神經(jīng)網(wǎng)絡(luò)在目標檢測領(lǐng)域取得開創(chuàng)性進展的工作是R-CNN[1]。R-CNN使用選擇性搜索算法[4]來生成目標候選區(qū)域,然后使用卷積神經(jīng)網(wǎng)絡(luò)提取特征并輸出到分類器。空間金字塔形池化網(wǎng)絡(luò)(Spatial Pyramid Pooling Network,SPP-NET)、Fast R-CNN和Faster R-CNN先后三次對R-CNN作出了改進。SPP-NET[5]在特征提取網(wǎng)絡(luò)生成的特征圖上運行選擇性搜索算法來提升運算速度和候選區(qū)域的生成質(zhì)量。Fast R-CNN[6]利用了ROI池化來為目標候選區(qū)域高效地生成特征編碼。Faster R-CNN[3]使用卷積神經(jīng)網(wǎng)絡(luò)替換了選擇性搜索算法來生成候選區(qū)域。后續(xù)的許多工作都采用了Faster R-CNN的模式,發(fā)表了一系列變種,它們能被運用在以高IoU評估平均檢測精度的場景中。例如,基于區(qū)域的全連接卷積神經(jīng)網(wǎng)絡(luò)(Region-based Fully Convolutional neural Network, R-FCN)[7]利用全連接的卷積神經(jīng)網(wǎng)絡(luò),降低了第二階段的計算復(fù)雜度。然而,R-FCN的檢測精度重度依賴于更大、更深的特征提取網(wǎng)絡(luò)。多尺寸卷積神經(jīng)網(wǎng)絡(luò)(Multi-Scale Convolutional Neural Network,MS-CNN)[8]首先將轉(zhuǎn)置卷積操作應(yīng)用到了雙階段目標檢測模型中,先利用轉(zhuǎn)置卷積提升特征圖的分辨率,然后再學(xué)習(xí)候選區(qū)域生成過程。
單階段模型取消了R-CNN的候選區(qū)域生成階段,提升了檢測速度。單階段多邊框目標檢測(Single Shot multibox Detector, SSD)模型[2]是一個典型的單階段模型,模型在前向傳播過程中生成了不同分辨率和語義抽象層次的特征圖,這些特征圖被直接用來檢測尺寸在一定范圍內(nèi)的目標。SSD節(jié)省了巨大的計算量,所以運行速度比Faster R-CNN快很多。SSD以IoU為0.5評估檢測精度的任務(wù)中取得了接近Faster R-CNN的檢測精度。然而,如本文實驗中展示的,當IoU被提高時,模型的準確率會明顯下降。YOLO(You Only Look Once)[9]是另一個快速的單階段模型,但是它的檢測精度低于SSD。DSSD(Deconvolutional SSD)[10]以轉(zhuǎn)置卷積操作為基礎(chǔ),構(gòu)建了編碼-解碼的對稱結(jié)構(gòu),充分利用了圖像的全局上下文信息,但是DSSD的訓(xùn)練難度較大,失去了端到端訓(xùn)練的優(yōu)勢。RetinaNet(Retina Convolutional Neural Network)[11]的特征聚合的方式和特征聚合模型類似,但是該方法中上下文信息的生成過程是不可學(xué)習(xí)的。
循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network,RNN)被廣泛地應(yīng)用到了自然語言處理領(lǐng)域,如圖像描述生成,但是使用序列模型來提升目標檢測精度的想法只被很少的文章討論過。文獻[12]中將檢測問題作為了邊界框的生成問題,并利用了長短期記憶網(wǎng)絡(luò)(Long Short-Term Memory, LSTM)在深度的特征圖上學(xué)習(xí)邊界框的生成過程。然而,因為僅僅利用了特征提取網(wǎng)絡(luò)的最后一層特征圖,當?shù)谝粋€特征圖中的目標存在模糊、遮蓋等問題時,目標檢測的難度就會提升,而這種情況在實際應(yīng)用中非常常見。與文獻[12]不同,本文提出的循環(huán)特征聚合結(jié)構(gòu)能有效地檢測任意目標,因為它充分利用了上下文信息,并且在以高IoU評估的場景中得到了精確的檢測結(jié)果。
2 方法分析
2.1 已有方法分析
一個健壯的目標檢測系統(tǒng)必須能夠同時檢測尺寸和分辨率變化很大的目標。在Faster R-CNN[3]中,特征提取網(wǎng)絡(luò)的最后一個卷積層中的每個的卷積核都有很大的感受野,它們可以幫助模型檢測不同尺寸的目標。因為使用了多個池化層,最后一層特征圖的尺寸要遠小于輸入圖片的尺寸。這可能使檢測小尺寸目標變得困難,因為在低分辨率的特征圖中,表示小目標的特征可能很難被利用。OverFeat(Over Feature neural network)[13]將模型在不同尺寸的輸入圖片上訓(xùn)練可以緩解這個問題,但是運算的效率較低。
在SSD[2]中,作者觀察到在大多數(shù)用于目標檢測的模型中,由于池化操作的存在,不同卷積層輸出的特征圖已經(jīng)具有了不同的尺寸。所以,利用高分辨率、低語義抽象的特征圖來檢測尺寸相對較小的目標,而利用低分辨率、高語義抽象的特征圖來檢測尺寸相對較大的目標的方法是非常合理的。這種方法的優(yōu)勢在于,通過將目標的分類、邊界框的回歸過程轉(zhuǎn)移到了具有高分率的特征圖上,模型能夠更精確地檢測尺寸較小的目標;SSD作為一個單階段模型,它的運算速度要比雙階段模型快很多倍。運算速度快的原因在于這種方法并行處理多種尺寸特征圖,并且不會為特征提取網(wǎng)絡(luò)增加額外的運算量。
但是,SSD的檢測精度低于雙階段模型。當使用更高的IoU評估檢測精度時,SSD與雙階段模型之間的精度差距會擴大[14]。SSD利用多尺寸特征圖的運算過程可以寫作:
Φn=fn(Φn)=fn(fn-1(…f1(I)))
(1)
D=E(τn(Φn),τn-1(Φn-1),…,τn-k(Φn-k));n>k
(2)
其中:Φn代表第n層特征圖;fn(·)是作用在第n-1層特征圖上的非線性運算,通常是卷積層、池化層、線性修正單元(Rectified Linear Unit, ReLU)層等的組合;f1(I)是將輸入圖像I轉(zhuǎn)換為第一層特征圖的非線性運算;τn(·)是根據(jù)第n層特征圖運算得到目標檢測結(jié)果的函數(shù),該函數(shù)僅負責檢測尺寸在一定范圍內(nèi)的目標;E集成所有中間檢測結(jié)果并生成最終目標檢測結(jié)果D。
根據(jù)式(2),可以發(fā)現(xiàn)SSD模型實現(xiàn)高精度檢測依賴于一個假設(shè)。為了使模型中每一層的特征圖能實現(xiàn)對某個尺寸范圍內(nèi)目標的檢測,網(wǎng)絡(luò)中的每個特征圖都需要具備足夠的表示能力,能夠支持精確的目標分類和定位。所以,特征圖需要能夠表示目標的細節(jié);特征圖應(yīng)該有足夠高的抽象程度,具備高層語義信息;特征圖應(yīng)該包含待檢測目標的上下文信息,基于這些上下文信息,重疊、殘缺、模糊或尺寸較小的目標也能夠被可靠地檢測和定位[2-3,12]。通過式(1)~(2)可看出:當k很大時,Φn的深度大于Φn-k,所以Φn-k的抽象程度可能不足以實現(xiàn)對目標的檢測。這就使得用于將第n-k層的特征圖轉(zhuǎn)化為檢測結(jié)果的函數(shù)τn-k(·)比τn(·)更難于訓(xùn)練。
Faster R-CNN沒有這個深度問題,因為它的候選區(qū)域是利用特征提取網(wǎng)絡(luò)的最后一層特征圖得到的。但是特征提取網(wǎng)絡(luò)的最后一層特征圖的分辨率較低。所以,本文認為在單階段目標檢測模型中,輸出函數(shù)應(yīng)該被定義為:


H={Φn,Φn-1,…,Φn-k},n>k>0
(3)
2.2 使用轉(zhuǎn)置卷積操作實現(xiàn)特征聚合

(4)

2.2.1 循環(huán)特征聚合模型的細節(jié)
循環(huán)特征聚合模型的網(wǎng)絡(luò)結(jié)構(gòu)如圖1所示。圖1展示了一次特征聚合迭代過程。第一列的實線框代表由特征提取網(wǎng)絡(luò)ResNet101的res3b3_relu、res5c_relu、res5c_relu/conv1_2、res5c_relu/conv2_2、res5c_relu/conv3_2卷積層輸出的特征圖。在第一階段指向虛線框的箭頭代表特征聚合過程,生成的特征圖用虛線框表示。兩個階段之間的1×1卷積操作用于減少特征圖的維度,使特征圖可以被用于下次特征聚合。特征聚合與減少維度操作的權(quán)重在不同階段之間共享。本文使用去除了分類器的ResNet101[15]作為特征提取網(wǎng)絡(luò),然后將特征聚合結(jié)構(gòu)應(yīng)用于ResNet101所提取的特征圖。輸入圖像的尺寸為1 272×375,有3個顏色通道,所以ResNet101中卷積層res3b3_relu和res5c_relu輸出的特征圖的尺寸分別為 512×159×47和1 024×80×24,512和1 024是通道數(shù)。和原始SSD模型一樣,本文為檢測不同尺寸的目標而添加了卷積層res5c_relu/conv1_2、res5c_relu/conv2_2和res5c_relu/conv3_2。
本文使用一個轉(zhuǎn)置卷積層來聚合深層的特征。例如,卷積層res5c_relu/conv1_2生成的特征圖在經(jīng)過一個ReLU運算和一個轉(zhuǎn)置卷積運算后生成了新的特征圖,與在卷積層res5c_relu特征圖上使用3×3卷積生成新的特征圖拼接。類似地,圖中的每一組向右的1×1卷積和轉(zhuǎn)置卷積都表示了同樣的特征聚合操作。當?shù)谝淮翁卣骶酆辖Y(jié)束后,在每層產(chǎn)生的特征圖上分別做1×1卷積操作來將通道數(shù)減少到最初的設(shè)置。在減少通道數(shù)操作之后,第一個特征聚合過程就完成了。該減少通道數(shù)的操作保證了在兩次特征聚合迭代之間,特征圖的尺寸是一致的,這也使得循環(huán)特征聚合成為可能。訓(xùn)練時,不同迭代之間所有卷積和轉(zhuǎn)置卷積操作所對應(yīng)的卷積核的參數(shù)都是共享的。本文將該迭代的過程稱為循環(huán)特征聚合。
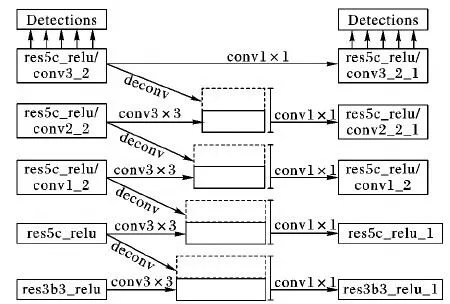
圖1 循環(huán)特征聚合網(wǎng)絡(luò)結(jié)構(gòu)Fig. 1 Architecture of recurrent feature aggregation network
文獻[16]中提出的生成包含上下文信息的網(wǎng)絡(luò)結(jié)構(gòu)與本文相似,區(qū)別在于本文去掉了顯式聚合前驅(qū)特征圖的過程,因為模型的前向傳輸過程中的卷積操作生成的特征圖已經(jīng)包含了前驅(qū)特征圖的相關(guān)信息;根據(jù)文獻[5,11],本文對特征圖進行了一次3×3卷積操作用于保證特征聚合的穩(wěn)定性。
2.2.2 利用循環(huán)神經(jīng)網(wǎng)絡(luò)實現(xiàn)目標檢測

循環(huán)特征聚合是個循環(huán)的過程,該過程中的每次迭代提取并聚合生成目標檢測所需的特征。如之前討論,這些重新生成的特征包含了對于檢測困難目標非常關(guān)鍵的上下文信息。在每次特征聚合迭代中,都有一組單獨的損失函數(shù)來指導(dǎo)模型對參數(shù)的學(xué)習(xí)。這保證了相關(guān)的特征將在訓(xùn)練過程中被逐步引入,并不斷取得進展。與文獻[12]不同,因為循環(huán)特征聚合不會特別處理某種尺寸的邊界框,所以上下文信息可以被利用來檢測場景中的任意目標。

圖2 循環(huán)特征聚合過程Fig. 2 Process of recurrent feature aggregation
在訓(xùn)練過程中,每次特征聚合迭代過程都有單獨的損失函數(shù)。和SSD一樣, Smooth L1損失被用來指導(dǎo)邊界框回歸。本文使用損失函數(shù)Focal Loss[11]指導(dǎo)目標分類。
實驗中,網(wǎng)絡(luò)中某一層輸出的特征圖,例如res3b3_relu負責實現(xiàn)對尺寸在某個特定區(qū)間的目標實現(xiàn)邊界框回歸。因為邊界框回歸在本質(zhì)上是一個線性過程,所以如果這個尺寸區(qū)間過大或者特征圖太過復(fù)雜,那么邊界框回歸過程的可靠性就會被嚴重地影響。因為循環(huán)特征聚合為特征圖引入了更多的上下文信息,這不可避免地使特征圖變得復(fù)雜,所以利用特征圖對原來尺寸范圍的目標進行邊界框回歸也就變得困難。為了使邊界框的回歸過程更加可靠,本文為所有特征圖都加入了多個邊界框回歸函數(shù),使邊界框回歸任務(wù)的尺寸區(qū)間離散化。這樣,每個邊界框回歸函數(shù)需要處理的任務(wù)比原來更簡單。
3 實驗
本文使用了KITTI數(shù)據(jù)集[17]進行模型評估。該數(shù)據(jù)集中不僅包含檢測難度較大的目標,例如小尺寸并且被嚴重遮擋的汽車和行人,而且在評估對車輛的檢測效果時,要求檢測結(jié)果與標注信息之間的IoU大于0.7。KITTI數(shù)據(jù)集包含7 481張圖像用于模型的訓(xùn)練和驗證,另外的7 518張圖像用來測試。
本文進行了三個實驗:第一個實驗考察了每次特征聚合后,模型損失函數(shù)值的變化情況;第二個實驗在一個較小的驗證集上評估了模型的性能;最后一個實驗對比了模型和其他已發(fā)表的單階段與雙階段模型的性能。
三個實驗使用了相同的設(shè)置來初始化模型。在網(wǎng)絡(luò)結(jié)構(gòu)方面,本文在訓(xùn)練過程進行了5次特征聚合迭代,為每一組特征圖設(shè)置了5個邊界框回歸器,用于實現(xiàn)邊界框回歸。因為特征聚合由1×1的卷積以及轉(zhuǎn)置卷積實現(xiàn),所以實驗得到的模型是非常高效的。在數(shù)據(jù)增廣方面,除了使用SSD[2]中所提到的所有數(shù)據(jù)增廣方法外,實驗在色相—飽和度—曝光度(Hue-Saturation-Value, HSV)顏色空間中隨機將部分圖像的飽和度和曝光度擴大至1.3倍。隨機調(diào)整了圖像的曝光度和飽和度。模型還刪除了SSD中的全局池化層。在訓(xùn)練過程中,本文使用了隨機梯度下降法,動量設(shè)置為0.9,權(quán)重衰減設(shè)置為0.000 5,學(xué)習(xí)率為0.001。學(xué)習(xí)率在每15 epoch后縮小為當前值的1/10。為了使訓(xùn)練集與驗證集的差別盡可能大,本文采用了歸一化顏色直方圖來衡量圖像的相似度,并根據(jù)相似度來分割訓(xùn)練集和驗證集。最終的驗證集包含了2 741張圖像。
3.1 每次特征聚合后的模型的損失值對比
因為循環(huán)特征聚合在測試中進行了5次特征聚合迭代,所以在實驗中可以得到6組目標檢測損失值,或者說模型連續(xù)做了6次檢測。這次實驗的目的是驗證每次特征聚合后,模型的目標檢測效果是否都有提升。
為了得到結(jié)果,在訓(xùn)練和驗證集上分別運行了循環(huán)特征聚合模型,并分別計算了平均損失值。損失值見表1。
第1次迭代的損失值在未進行任何特征聚合時得到,第2次到第6次迭代的損失值由在前一次得到的特征圖上進行特征聚合后得到。可以看到驗證集的損失值要比訓(xùn)練集上的損失值大,這表示模型都一定程度地過擬合。出現(xiàn)這種情況的原因是,實驗從訓(xùn)練集中抽取了很大一部分圖像來作為驗證集。從表1中可以歸納損失值基本的變化情況:第2次迭代的損失值,也就是進行一次特征聚合后,要比第1次迭代減小0.041。當進行四次特征聚合后,可以得到最小的損失值;然而,從第5次迭代特征聚合開始,損失函數(shù)不再減小。

表1 不同特征聚合迭代后的平均損失Tab. 1 Average loss of different iterations of feature aggregation
表1中的數(shù)據(jù)顯示循環(huán)特征聚合模型能夠在幾次連續(xù)的特征聚合迭代過程中持續(xù)提升檢測效果,但是之后提升停止。這種現(xiàn)象可以從兩個方面理解:一方面,循環(huán)特征聚合是有效的;另一方面,模型的模型效果最終下降的原因在于模型缺乏有效的記憶機制,記憶機制可提升對長序列的建模效果。盡管記憶機制對于提升模型的檢測效果可能很有幫助,但是這會為模型引入額外的運算量和內(nèi)存占用。這個實驗結(jié)果指導(dǎo)了如何集成最終的目標檢測結(jié)果。在之后兩個實驗中,本文通過在第3次、第4次和第5次迭代輸出值上運行非極大值抑制算法來得到模型最終的檢測結(jié)果。
3.2 在驗證集上模型性能評估
本實驗測量了循環(huán)特征聚合模型在目標檢測任務(wù)中帶來的提升。實驗在從數(shù)據(jù)集中抽取的包含汽車的圖像上完成。
在評估過程中,平均檢測精度(mAP)在不同的IoU條件下分別計算得到。實驗訓(xùn)練了一個用于檢測汽車的SSD模型來作為實驗精度的基準線。然后,本文使用同樣的初始化方法和模型配置訓(xùn)練了的循環(huán)特征聚合(Recurrent Feature Aggregation, RFA)模型。循環(huán)特征聚合模型的檢測結(jié)果在第3到5組輸出值上運行非極大值抑制算法而得到。通過表2可以看到,循環(huán)特征聚合模型的檢測精度比原本的SSD更高。因為SSD和循環(huán)特征聚合模型都使用ResNet101作為特征提取網(wǎng)絡(luò),所以檢測結(jié)果的提升是由于添加了循環(huán)特征聚合結(jié)構(gòu)。
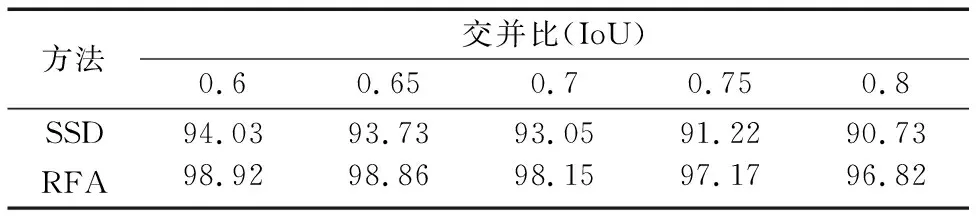
表2 在驗證集上使用不同的IoU評估檢測精度 %Tab. 2 mAP results on validation set for different IoU thresholds %
觀察到在不同IoU條件下,特征聚合模型的精度總是要比SSD高。這可以進一步確認本文在實驗一中得到的結(jié)論。當將評估模型的IoU提升到0.8時,循環(huán)特征聚合模型的檢測精度要比原始的SSD高6.09個百分點。這個結(jié)果說明循環(huán)特征聚合結(jié)構(gòu)可以有效地生成高質(zhì)量的邊界框。事實上,實驗中指出的SSD生成邊界框質(zhì)量差的問題普遍存在于單階段模型中,這也是限制單階段模型達到更好檢測精度的瓶頸。循環(huán)特征聚合模型在一定程度上解決了這個問題。
3.3 對比訓(xùn)練過程中模型檢測精度及運算速度對比
本實驗使用循環(huán)特征聚合模型與目前目標檢測領(lǐng)域內(nèi)典型的單階段和雙階段目標檢測模型的檢測精度及運算速度作了對比,包括目前檢測精度最高的雙階段模型Faster R-CNN[3]與R-FCN[7],以及單階段模型YOLOv2[18]與SSD[2],循環(huán)目標檢測模型則用RFA表示。對比模型的源代碼從相應(yīng)引用文獻中獲取,利用KITTI數(shù)據(jù)集重新訓(xùn)練,并記錄了模型在每輪全樣本訓(xùn)練后的檢測精度。模型的檢測精度使用IoU為0.7進行了評估。

圖3 不同模型檢測精度在訓(xùn)練過程中的變化對比Fig. 3 mAP comparison of multiple detectors during training process

表3 模型運算速度對比Tab. 3 Processing speed comparison of multiple detectors
由對比結(jié)果圖3可以看出,循環(huán)特征聚合模型的精度不僅比原始的SSD模型高5.1個百分點,并且比代表著最高檢測精度的Faster R-CNN高2個百分點。從表3可以看出,由于循環(huán)特征聚合模型RFA在原始的SSD模型上添加了額外的特征聚合過程,所以造成了一定的性能下降,但是運算速度依然明顯高于單階段模型 Faster R-CNN 和 R-FCN。實驗的結(jié)果確認了循環(huán)特征聚合結(jié)構(gòu)的有效性,也對未來設(shè)計更精確的單階段目標檢測模型具有指導(dǎo)意義。
4 結(jié)語
本文提出了一種基于SSD模型,利用轉(zhuǎn)置卷積操作改進的循環(huán)特征聚合結(jié)構(gòu),該結(jié)構(gòu)可以有效地提升單階段目標檢測方法的檢測精度。循環(huán)特征聚合能夠持續(xù)地聚合特征圖中的相關(guān)上下文信息,從而生成精確的檢測結(jié)果。循環(huán)特征聚合結(jié)構(gòu)在利用KITTI數(shù)據(jù)集的評估中達到了比雙階段目標檢測模型更高的檢測精度。
在未來的工作中,將研究將記憶機制引入循環(huán)特征聚合結(jié)構(gòu)中,并且量化記憶機制對目標檢測性能的影響。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
