一種有效的LDPC碼偽碼字搜索算法
2018-12-07 09:12:28郭軍軍白碩棟慕建君
西安電子科技大學學報 2018年6期
關鍵詞:規則
郭軍軍,白碩棟,慕建君,荊 心,肖 鋒
(1. 西安工業大學 計算機學院, 陜西 西安 710021;2. 西安電子科技大學 計算機學院,陜西 西安 710071)
低密度奇偶校驗(Low-Density Parity-Check, LDPC)碼是文獻[1]在1962年提出的一種現代糾錯編碼技術.因具有簡單的編譯碼方法和可逼近香農容量限的譯碼性能,LDPC碼已經成為當今工業界和學術界的研究熱點之一.但是,當采用消息傳遞迭代譯碼算法時,LDPC碼在高信噪比區域存在錯誤平臺現象.而低重量偽碼字(Pseudo-codeword)是造成LDPC碼譯碼錯誤平臺問題的主要原因之一.因此,研究LDPC碼低重量偽碼字的有效搜索方法是評估和改進其譯碼性能的關鍵.
搜索LDPC碼的偽碼字是一個非確定多項式(Non-deterministic Polynomial,NP)難問題[2].國內外目前關于這方面的研究方法可概括為兩大類:Tanner子圖枚舉法.根據Tanner圖結構來搜索停止集(Stopping Set)和陷阱集(Trapping Set)等有害子圖,從而確定LDPC碼的偽碼字.由于規則LDPC碼的陷阱集是由短環以及與短環相連的路徑組成的[3],文獻[4]中提出了基于短環的路徑擴展法可以有效地找出陷阱集,再通過偏置陷阱集噪聲來搜索規則LDPC碼線性規劃譯碼的偽碼字. 文獻[5]提出了非規則LDPC碼陷阱集的一種窮舉搜索方法. 該方法的基本思路是首先從Tanner圖中找出一個短環或度數較小的變量節點作為基礎,然后通過單邊、路徑或棒棒糖(lollipop)子圖方式進行擴展來找到非規則LDPC碼消息傳遞譯碼的陷阱集,從而確定對應的偽碼字[5].但是,這類偽碼字搜索算法屬于一種窮舉算法,隨著碼長和陷阱集尺寸增大,其效率變得越來越差.隨機噪聲輸入驗證法.該類方法首先產生隨機噪聲輸入向量,然后經多輪迭代促使譯碼器譯碼失敗而產生偽碼字. 文獻[6]提出的基于快平直方圖(Fast Flat Histogram,FFH)的搜索方法可以有效地找到加性高斯白噪聲(Additive White Gaussian Noise,AWGN)信道下置信傳播(Belief Propagation,BP)譯碼時LDPC碼的偽碼字[6].通過構造隨機信道噪聲,文獻[7-8]中提出的瞬子搜索算法(Instanton Search Algorithm,ISA)可在有限次迭代后找到LDPC碼線性規劃偽碼字.然而,譯碼器輸入的隨機性導致這類偽碼字搜索方法的效率較低.
針對上述方法的不足,筆者提出了針對二元對稱信道(Binary Symmetric Channel, BSC)下LDPC碼的一種線性規劃譯碼的偽碼字搜索算法.仿真實驗結果表明,與現有偽碼字搜索算法相比,所提算法能夠更準確地找到中短碼長規則和非規則LDPC碼的低重量偽碼字.
1 相關術語及定義
令G=(V∪C,E)是LDPC碼Θ的Tanner圖.Tanner圖G是一種特殊的二部圖,其頂點是由變量節點和校驗節點組成的,變量節點集V= {v1,v2,…,vn},校驗節點集C= {c1,c2,…,cm},n和m分別表示變量節點數和校驗節點數,E是校驗節點與變量節點之間相連的邊集,即E= {v,c:v∈V,c∈C}.與變量節點v相連的校驗節點集記作N(v)= {c:c∈C,v,c∈E},相應地,與校驗節點c相連的鄰居變量集記為N(c)= {v:v∈V,v,c∈E}.由于LDPC碼的校驗矩陣具有稀疏性特點,故圖G的邊數較少.若碼Θ的Tanner圖中所有變量節點和校驗節點的度分布相同,則稱該碼為規則LDPC碼;否則,稱之為非規則LDPC碼.
定義1 實數集上的向量u的支持集fsupp(u)定義為u的非零分量的位置下標集合[7],即fsupp(u)= {i:ui∈u}.
定義2 二元LDPC碼校驗多胞體(Check Polytope)定義為所有長度為d的校驗行組合向量構成的凸包,并且每個行向量x中有偶數個1,即Pd=fconv({x∈ {0,1}d|x中含有偶數個1})[9].
定義3 設一個LDPC碼Θ的校驗矩陣為H,則線性規劃譯碼時Θ的偽碼字p定義為H所對應的松弛校驗多胞體上的非整數頂點.

(1)
在式(1)中,其增廣拉格朗日函數為
(2)
其中,yj為拉格朗日乘子;υ>0,為懲罰參數.在ADMM迭代處理中,x、z和y的更新規則為
其中,函數ΠPdj(v)表示向量v在校驗多胞體Pdj上的歐幾里德投影.

(6)

2 偽碼字搜索算法
2.1 算法的提出
在二元對稱信道下,LDPC碼線性規劃譯碼失敗時輸出為非整數偽碼字.而低重量偽碼字是造成錯誤平臺現象的最直接原因之一.通過大量觀察分析可知,有害的Tanner子圖中變量節點的位置恰好與偽碼字向量中非整數位置重合.對于規則LDPC碼,這些偽碼字僅僅與Tanner圖中短環結構有關,而對于非規則LDPC碼,偽碼字還與Tanner子圖中含有度數較低的變量節點有關.特別地,非規則LDPC碼的偽碼字與變量節點度數為2的Tanner子圖結構密切相關.度數為2的節點可以抑制短環的出現,同時使得碼的漢明距離變小,這就降低了譯碼性能.因此,在搜索非規則LDPC碼的低重量偽碼字時,應考慮短環和與度數為2的變量節點相關的有害Tanner子圖結構.典型的有害Tanner子圖主要包括線性、樹狀和環形結構三大類,如圖1所示.

圖1 典型的有害Tanner子圖結構(○表示變量節點,□表示校驗節點)
受到基于Tanner圖搜索陷阱集和瞬子搜索算法的啟發,文中提出了一個以Tanner子圖為基礎的低重量偽碼字搜索(Low-Weight Pseudo-Codewords Search, LW-PCS)算法.該算法的基本思想是首先枚舉有害的Tanner子圖結構;其次選擇全零碼字作為譯碼器的輸入,并疊加隨機產生的足夠大的信道噪聲而導致譯碼器輸出偽碼字,確保有害Tanner子圖中變量節點對應位置的輸入碼字存在噪聲;最后借助ISA搜索算法,找到該噪聲結構對應的所有低重量偽碼字.
2.2 算法的描述
設一個LDPC碼的有害Tanner子圖集為S,相應的偽碼字集為P,二元對稱信道下LDPC碼ADMM線性規劃譯碼時的LW-PCS低重量偽碼字搜索算法如下:
(1) 初始化,令P←{?}.
(2) 從S中取出一個Tanner子圖s,并構造s中變量節點集合V.
(3) 對于全零向量r,隨機產生不少于|V|個擾動噪聲來翻轉r中對應位置的比特信息,并確保r中對應集合V的所有分量的比特值為1,從而得到向量r′.
(4) 令k←1,并對輸入向量r′進行ADMM線性規劃譯碼得到輸出偽碼字pk.
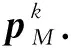


(8) 對于任意it∈fsupp(M(pk))(1≤t≤|fsupp(M(pk))|),令rit是一個具有fsupp(M(pk))it支持集的向量,pit為不同的rit進行ADMM線性規劃譯碼后得到的偽碼字向量.

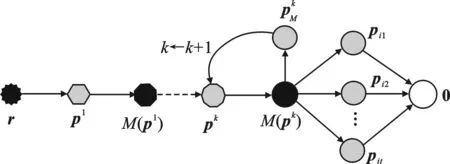
圖2 輸入向量r的ADMM線性規劃譯碼偽碼字收斂過程
LW-PCS算法中符號|V|表示集合V的分量的個數.在步驟(2)中,構造包含度為2的變量節點Tanner子圖時節點的數量應不少于分數距離的一半; 步驟(3)中增加過多擾動隨機噪聲會影響譯碼算法的收斂速度,因此,擾動噪聲的數目通常不超過碼長的 1/2.

3 仿真實驗及分析
為驗證文中所提出偽碼字搜索算法的準確性,選擇了一個典型的規則Tanner碼[11]和一個非規則的PEG碼進行數值仿真.
例1 (155,64)Tanner碼.Tanner碼是一個碼長為155的規則LDPC碼.該碼的校驗行數為93,分數距離為 8.349 8.Tanner碼的偽碼字最低重量wmin≈ 16.404.首先,采用文獻[12]方法找出長度為8、12、14和16的所有短環,然后利用文中提出的算法搜索偽碼字時,僅經過 3 700 次的嘗試即可得到155個低重量偽碼字.然而,利用現有的ISA搜索算法必須進行 112 320 次搜索嘗試才能夠找到這155個低重量偽碼字(如表1所示).

表1 兩種偽碼字搜索算法偽碼字搜索次數比較
例2 PEG構造的非規則LDPC碼.本實驗中選擇了一個PEG算法構造的碼長為504的PEGirReg 252× 504碼.該碼中變量節點度為2的節點約占全部變量節點的32%.由于PEGirReg252×504碼是非規則LDPC碼,因此筆者在構造LW-PCS算法的輸入集時,充分考慮了含有短環的Tanner子圖以及度為2的變量節點所構成的子圖結構對偽碼字搜索算法的影響.采用LW-PCS算法需要 598 289 次搜索即可找到該碼的291個低重量偽碼字.但是,采用現有的ISA搜索算法必須進行106次嘗試才僅僅能夠找到232個低重量偽碼字,如表1所示.
由此可見,與傳統的ISA搜索算法相比較,文中提出的LW-PCS搜索算法能夠通過較少的嘗試次數即可快速準確地找到LDPC碼的主要低重量偽碼字.
4 結 束 語
筆者針對二元對稱信道下LDPC碼線性規劃譯碼,提出了一種基于Tanner子圖知識的低重量偽碼字搜索算法.仿真結果表明,與現有偽碼字搜索算法相比,所提出的LW-PCS搜索算法能夠準確地找出中短長度的規則和非規則LDPC碼的偽碼字.雖然筆者提出的搜索算法可以找到許多低重量偽碼字,但并不能保證該算法能夠找到全部低重量偽碼字.因此,如何設計更加高效的偽碼字搜索算法有待于進一步研究.
猜你喜歡
作文周刊·小學一年級版(2022年28期)2022-05-30 10:48:04
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
法律方法(2019年3期)2019-09-11 06:26:16
中國外匯(2019年7期)2019-07-13 05:44:52
幸福(2018年33期)2018-12-05 05:22:42
環球飛行(2018年7期)2018-06-27 07:26:14
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
運動(2016年6期)2016-12-01 06:33:42
