基于深度學習的圖像超分辨率重建技術的研究
2018-12-18 10:16:34劉永信段添添
科技與創新 2018年23期
劉永信,段添添
?
基于深度學習的圖像超分辨率重建技術的研究
劉永信,段添添*
(內蒙古大學,內蒙古 呼和浩特 010021)
圖像的超分辨率重建技術指的是將給定的低分辨率圖像通過特定的算法恢復成相應的高分辨率圖像。隨著人工智能的不斷發展,超分辨率重建技術在視頻圖像壓縮傳輸、醫學成像、遙感成像、視頻感知與監控等領域得到了廣泛的應用。簡要介紹了圖像超分辨率技術的研究背景與意義,同時,概述了其基本原理及評估指標,著重介紹了基于深度學習的超分辨率重建技術的處理流程及幾種具有代表性的超分辨率深度學習模型。
人工智能;深度學習;超分辨率;制造工藝
1 超分辨率重建技術的研究背景與意義
圖像分辨率是一組用于評估圖像中蘊含細節信息豐富程度的性能參數,包括時間分辨率、空間分辨率及色階分辨率等,體現了成像系統實際所能反映物體細節信息的能力。相比于低分辨率圖像,高分辨率圖像通常包含更大的像素密度、更豐富的紋理細節及更高的可信賴度。但在實際中,受采集設備與環境、網絡傳輸介質與帶寬、圖像退化模型本身等諸多因素的約束,我們通常并不能直接得到具有邊緣銳化、無成塊模糊的理想高分辨率圖像。提升圖像分辨率的最直接的做法是改進采集系統中的光學硬件,但這種做法受制造工藝難以大幅改進、制造成本十分高昂等約束,所以,從軟件和算法的角度著手,實現圖像超分辨率重建的技術成為了圖像處理和計算機視覺等多個領域的熱點研究課題。
1955年,Toraldo di Francia在光學成像領域首次明確定義了超分辨率這一概念,主要是指利用光學相關的知識,恢復出衍射極限以外的數據信息的過程;1964年,Harris和Goodman首次提出了圖像超分辨率這一概念,主要是指利用外推頻譜的方法合成出細節信息更豐富的單幀圖像的過程;1984年,在前人的基礎上,Tsai和Huang等人首次提出使用多幀低分辨率圖像重建出高分辨率圖像的方法后,超分辨率重建技術開始受到了學術界和工業界廣泛的關注和研究。 具體而言,圖像超分辨率重建技術指的是利用數字圖像處理、計算機視覺等領域的相關知識,借由特定的算法和處理流程,從給定的低分辨率圖像中復原出高分辨率圖像的過程。其旨在克服或補償由于圖像采集系統或采集環境本身的限制,導致的成像圖像模糊、質量低下、感興趣區域不明顯等問題。 圖像超分辨率重建技術在多個領域都有著廣泛的應用和研究意義,主要包括以下幾個領域。
1.1 圖像壓縮領域
在視頻會議等實時性要求較高的場合,可以在傳輸前預先對圖片進行壓縮,等待傳輸完畢,再由接收端解碼后通過超分辨率重建技術復原出原始圖像序列,極大減少存儲所需的空間及傳輸所需的帶寬。
1.2 醫學成像領域
對醫學圖像進行超分辨率重建,可以在不增加高分辨率成像技術成本的基礎上,降低對成像環境的要求,通過復原出的清晰醫學影像實現對病變細胞的精準探測,有助于醫生對患者病情作出更好的診斷。
1.3 遙感成像領域
高分辨率遙感衛星的研制具有耗時長、價格高、流程復雜等特點,由此研究者將圖像超分辨率重建技術引入了該領域,試圖解決高分辨率的遙感成像難以獲取這一問題,從而在不改變探測系統本身的前提下提高觀測圖像的分辨率。
1.4 公共安防領域
公共場合的監控設備采集到的視頻往往受到天氣、距離等因素的影響,存在圖像模糊、分辨率低等問題。通過對采集到的視頻進行超分辨率重建,可以為辦案人員恢復出車牌號碼、清晰人臉等重要信息,為案件偵破提供必要線索。
1.5 視頻感知領域
通過圖像超分辨率重建技術,可以起到增強視頻畫質、改善視頻質量、提升用戶視覺體驗的作用。
2 圖像超分辨率重建技術概述
2.1 降質退化模型
低分辨率圖像在成像過程中受到很多退化因素的影響,運動變換、成像模糊和降采樣是其中最主要的3個因素。如圖1所示,整個過程可以通過使圖示的線性變換模型來表征。
上述退化模型可以由以下線性變換表示:
=+. (1)
式(1)中:為觀測圖像;為降采樣矩陣,通常由成像系統的分辨率決定;為模糊作用矩陣,通常由環境或成像系統本身引起;為運動變換矩陣,通常由運動、平移等因素造成;為輸入的高分辨率圖像;為加性噪聲,通常來自于成像環境或成像過程。
圖像降質退化模型描述了自然界中的高分辨率圖像轉換成人眼觀測到的低分辨率圖像的整個過程,即高分辨率圖像成像逆過程,為圖像超分辨率技術提供了堅實的理論基礎。
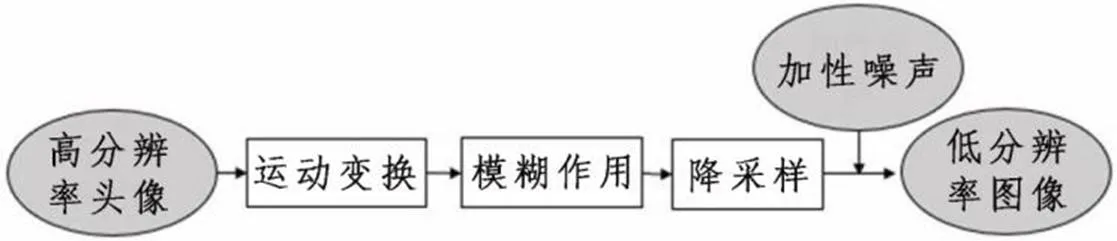
圖1 圖像的降質退化模型
2.2 重建圖像的評估
為了衡量重建算法優劣,需要引入一種評估指標來對重建后的圖像進行評估。重建圖像的評價方式一般分為兩大類,即主觀評價和客觀評價。
主觀評價以人為評價主體,對重建后圖像的視覺效果進行主觀和定性的評估。為了保證圖像的主觀評價具有一定的統計意義,此種評估方法需要選擇足夠多的評價主體,并保證評價主體中未受訓練的普通人和受過訓練的專業人員數量大致均衡。
客觀評價中,峰值信噪比(Peak signal-to-noise ratio,PSNR)和結構相似性(Structural Similarity,SSIM)是最常用的2種圖像質量評估指標。其中,PSRN通過比較兩幅圖像對應像素點的灰度值差異來評估圖像的質量,SSIM則從亮度、對比度和結構這3個方面來評估兩幅圖像的相似性。具體計算公式如下:
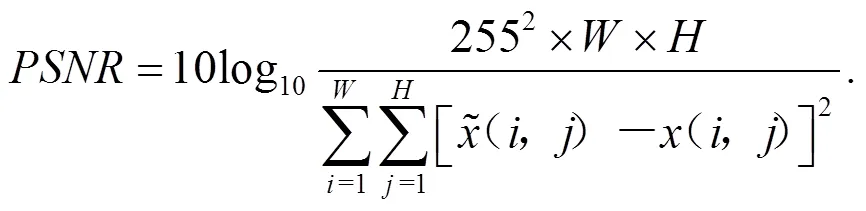
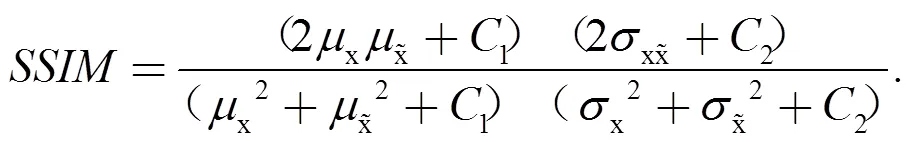
2.3 圖像分辨率重建技術分類
根據分類準則的不同,可以將圖像超分辨率重建技術劃分為不同的類別。從輸入的低分辨率圖像數量角度來看,可以分為單幀圖像的超分辨率重建和多幀圖像(視頻)的超分辨率重建;從變換空間角度來看,可以分為頻域超分辨率重建、時域超分辨率重建、色階超分辨率重建等;從重建算法角度來看,可以分為基于插值的重建、基于重構的重建和基于學習的超分辨率重建。本節主要從算法內容出發,介紹幾類常見的超分辨率重建技術。
2.3.1 基于插值的超分辨率重建
基于插值的方法將每一張圖像都看做是圖像平面上的一個點,則對超分辨率圖像的估計可以視為是利用已知的像素信息為平面上未知的像素信息進行擬合的過程,這通常由一個預定義的變換函數或者插值核來完成。基于插值的方法計算簡單、易于理解,但是也存在著一些明顯的缺陷:它假設像素灰度值的變化是一個連續、平滑的過程,但實際上這種假設并不完全成立;在重建過程中,僅根據一個事先定義的轉換函數來計算超分辨率圖像,不考慮圖像的降質退化模型,往往會導致復原出的圖像出現模糊、鋸齒等現象。常見的基于插值的方法包括最近鄰插值法、雙線性插值法和雙立方插值法等。
2.3.2 基于重構的超分辨率重建
基于重構的方法則是從圖像的降質退化模型出發,假定高分辨率圖像是經過了適當的運動變換、模糊及噪聲才得到低分辨率圖像。這種方法通過提取低分辨率圖像中的關鍵信息,并結合對未知的超分辨率圖像的先驗知識來約束超分辨率圖像的生成。常見的基于重構的方法包括迭代反投影法、凸集投影法和最大后驗概率法等。
2.3.3 基于學習的超分辨率重建
基于學習的方法則是利用大量的訓練數據,從中學習低分辨率圖像與高分辨率圖像之間某種對應關系,然后根據學習到的映射關系來預測低分辨率圖像所對應的高分辨率圖像,從而實現圖像的超分辨率重建過程。常見的基于學習的方法包括流形學習、稀疏編碼和深度學習方法。
3 基于深度學習的圖像超分辨率重建技術
機器學習是人工智能的一個重要分支,而深度學習則是機器學習中最主要的一個算法,其旨在通過多層非線性變換,提取數據的高層抽象特征,學習數據潛在的分布規律,從而獲取對新數據做出合理的判斷或者預測的能力。
隨著人工智能和計算機硬件的不斷發展,Hinton等人在2006年提出了深度學習這一概念,其旨在利用多層非線性變換提取數據的高層抽象特征。憑借著強大的擬合能力,深度學習開始在各個領域嶄露頭角,特別是在圖像與視覺領域,卷積神經網絡大放異彩,這也使得越來越多的研究者開始嘗試將深度學習引入到超分辨率重建領域。2014年,Dong等人首次將深度學習應用到圖像超分辨率重建領域,他們使用一個三層的卷積神經網絡學習低分辨率圖像與高分辨率圖像之間映射關系,自此,在超分辨率重建率領域掀起了深度學習的浪潮。
基于深度學習的圖像超分辨率技術的重建流程主要包括以下幾個步驟:①特征提取。對輸入的低分辨率圖像進行去噪、上采樣等預處理,然后將處理后的圖像送入神經網絡,擬合圖像中的非線性特征,提取代表圖像細節的高頻信息。②設計網絡結構及損失函數。組合卷積神經網絡及多個殘差塊,搭建網絡模型,并根據先驗知識設計損失函數。③訓練模型。確定優化器及學習參數,使用反向傳播算法更新網絡參數,通過最小化損失函數提升模型的學習能力。④驗證模型。根據訓練后的模型在驗證集上的表現,對現有網絡模型進行評估,并據此對模型進行相應調整。以下是幾種常見的基于深度學習的超分辨率重建技術及其對比。
3.1 SRCNN
SRCNN(Super-Resolution Convolutional Neural Network)是首次在超分辨率重建領域應用卷積神經網絡的深度學習模型。對于輸入的一張低分辨率圖像,SRCNN首先使用雙立方插值將其放大至目標尺寸,然后利用一個三層的卷積神經網絡去擬合低分辨率圖像與高分辨率圖像之間的非線性映射,最后將網絡輸出的結果作為重建后的高分辨率圖像。SRCNN的網絡結構如圖2所示。
3.2 ESPCN
與SRCNN不同,ESPCN(Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network)在將低分辨率圖像送入神經網絡之前,無需對給定的低分辨率圖像進行一個上采樣過程,得到與目標高分辨率圖像相同大小的低分辨率圖像。如圖3所示,ESPCN中引入一個亞像素卷積層(Sub-pixel convolution layer),來間接實現圖像的放大過程。這種做法極大地降低了SRCNN的計算量,提高了重建效率。

圖2 SRCNN的網絡結構

圖3 ESPCN的網絡結構
3.3 SRGAN
與上述兩種方法類似,大部分基于深度學習的圖像超分辨率重建技術使用均方誤差作為其網絡訓練過程中使用的損失函數,但是由于均方差本身的性質,往往會導致復原出的圖像出現高頻信息丟失的問題。而生成對抗網絡(Generative Adversarial Networks,GAN)則通過其中的鑒別器網絡很好地解決了這個問題,GAN的優勢就是生成符合視覺習慣的逼真圖像,所以,SRGAN(Photo-Realistic Single Image SuperResolution Using a Generative Adversarial Network)的作者就將GAN引入了圖像超分辨率重建領域。如圖4所示,SRGAN也是由一個生成器和一個鑒別器組成。生成器負責合成高分辨率圖像,鑒別器用于判斷給定的圖像是來自生成器還是真實樣本。通過一個二元零和博弈的對抗過程,使得生成器能夠將給定的低分辨率圖像復原為高分辨率圖像。
4 總結與展望
深度學習在圖像超分辨率重建領域已經展現出了巨大的潛力,極大地推動了該領域的蓬勃發展發展。但距離重建出既保留原始圖像各種細節信息、又符合人的主觀評價的高分辨率圖像這一目標,深度學習的圖像超分辨率重建技術仍有很長的一段路要走。目前,主要存在以下幾個問題:①深度學習的固有性約束。深度學習存在著需要海量訓練數據、高計算性能的處理器以及過深的網絡容易導致過擬合等問題。②類似傳統的基于人工智能的學習方法,深度學習預先假定測試樣本與訓練樣本來自同一分布,但現實中二者的分布并不一定相同,甚至可能沒有相交的部分。③盡管當前基于深度學習的重建技術使得重建圖像在主觀評價指標上取得了優異的成績,但重建后的圖像通常過于平滑,丟失了高頻細節信息。因此,進一步研究基于深度學習的圖像超分辨率技術仍有較大的現實意義和發展空間。

圖4 SRGAN的網絡結構
[1]Park S C,Park M K,Kang M G.Super-resolution image reconstruction:a technical overview[J].IEEE signal processing magazine,2003,20(03):21-36.
[2]Kim J,Kwon Lee J,Mu Lee K.Accurate image super-resolution using very deep convolutional networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition, 2016:1646-1654.
[3]Dong C,Loy C C,He K,et al.Image super-resolution using deep convolutional networks[J].IEEE transactions on pattern analysis and machine intelligence,2016,38(02):295-307.
[4]Shi W,Caballero J,Huszár F,et al.Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016:1874-1883.
[5]Ledig C,Theis L,Huszár F,et al.Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network[C]//CVPR,2017,2(03):4.
2095-6835(2018)23-0040-04
TP391.41
A
10.15913/j.cnki.kjycx.2018.23.040
*本文作者:人工智能開放創新平臺(chinaopen.ai)聯合學者
〔編輯:張思楠〕
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
